
Abstract
Predicting depth from a single image is an important problem for understanding the 3-D geometry of a scene. Recently, the nonparametric depth sampling (DepthTransfer) has shown great potential in solving this problem, and its two key components are a Scale Invariant Feature Transform (SIFT) flow–based depth warping between the input image and its retrieved similar images and a pixel-wise depth fusion from all warped depth maps. In addition to the inherent heavy computational load in the SIFT flow computation even under a coarse-to-fine scheme, the fusion reliability is also low due to the low discriminativeness of pixel-wise description nature. This article aims at solving these two problems. First, a novel sparse SIFT flow algorithm is proposed to reduce the complexity from subquadratic to sublinear. Then, a reweighting technique is introduced where the variance of the SIFT flow descriptor is computed at every pixel and used for reweighting the data term in the conditional Markov random fields. Our proposed depth transfer method is tested on the Make3D Range Image Data and NYU Depth Dataset V2. It is shown that, with comparable depth estimation accuracy, our method is 2–3 times faster than the DepthTransfer.
Introduction
Depth estimation from a single image is an important issue in 3-D scene understanding. From Figure 1, it is easy for people to understand its 3-D structure; however, it is still a hard task for current computer vision systems to do so, due to lack of reliable cues, such as stereo disparity and motion.

Depth estimation from a single image: Input images and depth maps estimated by our method. Color indicates depth (red for far and blue for close).
Scene depth is essential for a variety of tasks, ranging from 3-D modeling and visualization to robot navigation. Many challenging computer vision problems have proven 1 –5,31,32 to benefit from the incorporation of depth information, such as RGB-D visual odometry, 1 semantic labellings, 2 pose estimations, 3 3-D shape representation, 4 and 2.5-D object recognition. 5
In addition to parametric methods 6 –9 for extracting depths, many nonparametric depth sampling approaches 10,11 have also been proposed to automatically convert monocular images into stereoscopic images with good performances.
Karsch et al., 11 by exploiting the availability of a set of images with known depth, proposed a nonparametric algorithm (DepthTransfer) for depth estimation. Depth in the input image is estimated by first retrieving similar images from this set and then followed by depth warping and fusion. However, the nonparametric depth sampling 11 is very slow, which has to spend a lot of time and memories on computing the SIFT flow. Even though the SIFT flow computation is based on a coarse-to-fine scheme, its time complexity is still O(n2 logn) (suppose an image has n2 pixels). In addition, the weights of the data term in the energy formation in the work of Karsch et al. 11 are assigned by comparing pixel-wise SIFT descriptors, which are not discriminative enough for accurate matching during the SIFT flow computation.
In this article, we propose a novel sparse SIFT flow algorithm, which is of sublinear time complexity and much faster than the SIFT flow. In addition, a reweighting technique is introduced where the variance of the SIFT flow descriptor is computed in every pixel and used for reweighting the data term in conditional Markov random fields (CRFs). Our experimental evaluation shows that our depth estimation algorithm not only speeds up the computation but also achieves comparable depth estimation accuracy compared with the original DepthTransfer on the Make3D data set and outperforms state-of-the-art depth estimation approaches on the NYU data set, as demonstrated in section “Experimental evaluations.”
The rest of this article is organized as follows: Section “Related work” introduces the related works. The proposed sparse SIFT flow algorithm and the reweighted confidence are elaborated in section “The proposed approach.” Section “Experimental evaluations” reports the experimental results, and the final section gives the conclusion.”
Related work
Depth extraction from single images has received a lot of attention in recent years. Hoiem et al. 9 created convincing-looking reconstructions of outdoor images by assuming planar scene composition. Simple geometric assumptions have proven to be effective in estimating the layout of a room. 12,13 Saxena et al. 6,7 predicted depth from a set of image features using linear regression and a CRF and later extended their work into the Make3D 8 system for 3-D model generation. Their approach first oversegmented the images into many superpixels, and then the 3-D position and orientation of each pixel were inferred via energy minimization under the Markov random field (MRF) framework.
Recently, Fouhey et al. 14 presented an approach to infer 3-D surface normals from a single image using the primitives that were visually discriminative and geometrically informative. They also introduced mid-level constraints for 3-D scene understanding in the form of convex and concave edges in the study by Fouhey et al. 15 Ladicky et al. 16 combined contextual and segment-based cues and built a regressor in a boosting framework by transforming the problem into a regression of coefficients of a local coding. Hane et al. 17 presented an approach to incorporate a surface normal direction classifier into a continuous cut formulation to extract a depth map from unary potentials for different labels. Baig et al. 18 proposed a depth recovery mechanism “im2depth,” which was lightweight enough to run on mobile platforms while leveraging the large-scale nature of modern RGB-D data sets. Konrad et al. 19 proposed a novel depth estimation method that achieved higher performance on indoor scenes.
Convolutional networks have been applied with great success to depth extraction from single images. Eigen et al. 20 addressed this task by employing two deep network stacks: one is to make a coarse global prediction based on the entire image and the other is to refine this prediction locally, which can combine global and local information from various cues. Eigen and Fergus 21 proposed to use a multiscale convolutional network to predict depth from a single image. Wang et al. 22 presented a novel convolutional neural network (CNN) architecture for surface normal estimation. Liu et al. 23,24 presented a deep convolutional neural field model based on fully convolutional networks and a novel superpixel pooling method, combining the strength of deep CNN and the continuous CRF into a unified CNNs framework. Li et al. 25 estimated the depth from single images by a regression on deep convolutional neural network features combined with a postprocessing refining step using CRF.
Karsch et al. 11 used the nonparametric method 10 to infer depth from a single image by exploiting the availability of a set of images with known depths. Depth in the input image was then estimated by first retrieving similar images from this set and optionally warping their depth using the SIFT flow. 26 Then, this method combined these warped depth maps into an objective function to smooth the resulting depth. More recently, Liu et al. 27 explored continuous variables to represent the depth of image superpixels and discrete ones to encode relationships between neighboring superpixels. The depth estimation was formulated as an inference in a high-order, discrete–continuous graphical model, which is realized using particle belief propagation. Later, the same group 28 exploited the structure of the scene at different levels of details to learn depth from a single image.
This article focuses on the classical methods about learning depth from single images, and its mechanisms are different from the deep learning based. DepthTransfer has shown great potential in estimating depth from a single image; however, it requires a lot of time and memories during the SIFT flow computation. In addition, the weights of the data terms are not discriminative enough for accurate matching during the SIFT flow computation. In order to solve these two problems, an accelerating algorithm and a reweighting technique are proposed in this article.
The proposed approach
The proposed approach for pixel-level depth estimation from a single image is outlined in Figure 2. Given a database of the known mapping relationship between RGB images and depth images, a data-driven technique is used to learn the depth of the input RGB image. First, the global generalized search trees (GIST) features are extracted from the input RGB image, and k-NN method is used to search for the most similar k RGB images as candidates in the database. Then, we use the SIFT flow method to encode the dense mapping relationship between the candidate RGB images and the input RGB image and warp the candidate depth images to the input depth image. In order to speed up the computation, a novel sparse SIFT flow method is proposed to replace the classical SIFT flow technique, assuming that the distribution of a depth image is similar to the distribution of the gradient of the converted gray image. The depth estimation is formulated as a maximum a posterior (MAP) problem in the CRFs. In order to further improve the estimation accuracy, we propose a discriminative feature extraction method to reweight the data term of the CRF.
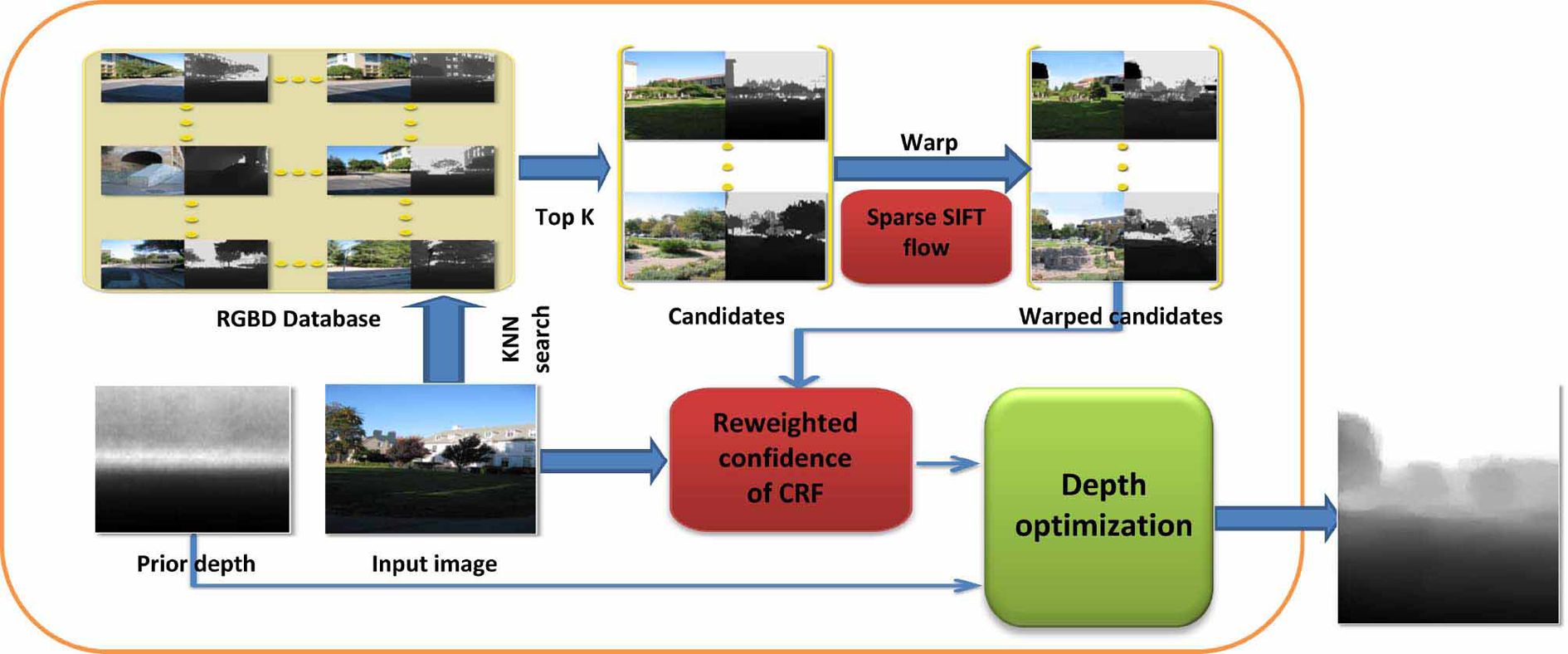
The pipeline of our approach to estimate depth from a single image.
Sparse SIFT flow
SIFT flow 26 adopts a coarse-to-fine flow matching scheme to improve the time performance. It first estimates the flow at a coarse level of image grids, then, gradually propagates and refines the flow from coarse to fine. Suppose an image has n2 pixels, the complexity of SIFT flow is O(n2 logn). In order to reduce the time complexity, instead of using multiple cores or graphic processing unit (GPU) to program, we propose to randomly sample instances, and then, use those instances as a sparse representation. The flow chart of the sparse SIFT flow is shown in Figure 3.

The sketch map of our sparse SIFT flow.
Given two m × n RGB images, we sample them to form two four-layer pyramids, respectively, as shown in Figure 3. The number of the pyramid layers in the sparse SIFT flow could be greater than or equal to 4. We use publicly available data sets: the Make3D data set and the NYU v2 Kinect data set, whose sizes are 345 × 460 and 480 × 640, respectively. Due to the size of the images in the data sets for estimating depth from single images, the pyramid used in this article is coded to have four levels. In addition, the SIFT flow used in the study by Karsch et al.
11
is also coded to have four levels. This computation framework is top-to-bottom. Every pixel of the two images is represented by a 128-dimensional SIFT descriptor. First, we match the top two images with a size of
To further accelerate the computation, we propose a method to compute the dense flow using a bilinear upsampling from the upper layer to the lower layer, as shown in Figure 3. We implement bilinear interpolation at the second, the third, and the top flows, respectively, and the corresponding results are reported in Table 3. Here, we take the bilinear upsampling of the “second flow” with a size of
Since the SIFT flow 26 is dense and smooth, we perform the linear interpolation first in one direction and then in the other direction. In this way, we can preserve the smoothness of the image as shown in Figure 4.

(a) A Mars satellite image, (b) the same image taken 4 years apart, (c) result of SIFT flow, and (d) result of our sparse SIFT flow.
Below is an example of the bilinear interpolation for the flow map. Given a function f, and four points (0, 0), (0, 1), (1, 0), and (1, 1), the interpolation at (x, y) is

Reweighted confidence
The posterior distribution Pr(x|D) for the input image data D over the labelling of the CRF follows a Gibbs distribution and can be written as
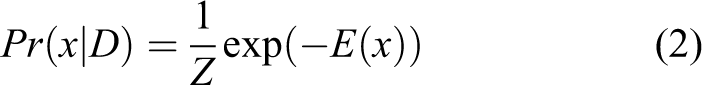
where Z is a normalizing constant and x is a depth map.
Then, an energy function can be formulated as the sum of unary and pairwise potentials

where i is the i th pixel in the image V and j is the neighbor pixel of i in Ni.
We use the same pairwise potential in CRF and use the same prior term to initialize the depth as in the study by Karsch et al. 11 By analyzing the data term in the study by Karsch et al., 11 we find one problem about the weight of the data term. As shown in equation (4), the weight of the data term in equation (3) is a matching score of pixel-wise SIFT descriptor. It is worth noting that the SIFT descriptor in equation (4) is different from the study by Lowe, 29 since we do not localize the multiscale space extreme and eliminate the low response. In other words, we use SIFT descriptor to represent every pixel without extracting the SIFT features in the image. When the descriptor is not discriminative, it makes no sense and even yields a wrong result
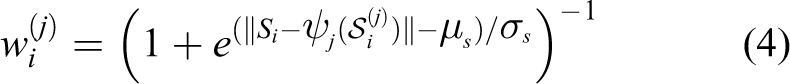
where Si is the SIFT feature vectors at pixel i in the input image and
For the sake of eliminating the wrong matches in SIFT flow, we propose a novel method to identify the best match. As shown in Figure 5(a), it is easy for human to see that AA', BB', and CC' are matching pairs. When we use the SIFT flow, however, AC' and CA' are also considered as potential matching pairs, since the two points are in identical smooth areas, whose SIFT descriptors are approximately same. This is an issue in low discriminative metric. In order to obtain a more reasonable and more accurate estimation, we should increase the matching weight of B and B' and reduce the matching weights of the other two pairs.
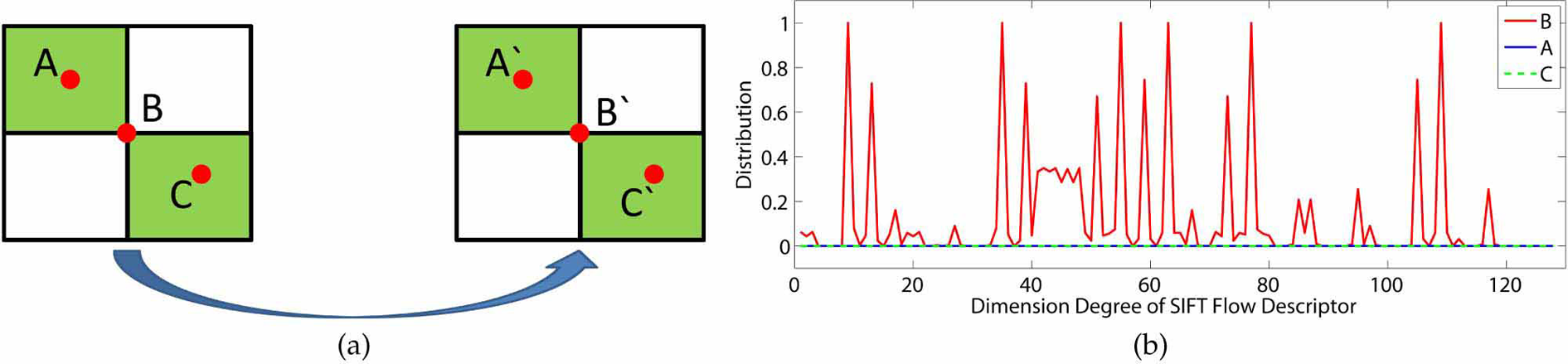
(a) The sketch map of three matching pairs and (b) the distributions of the SIFT flow descriptor in A, B, and C.
Suppose the feature used in equation (4) is not distinctive, we cannot generate a confidence weight to formulate data term even if the matching score is very high. Can we estimate the discrimination by using per pixel feature descriptor? To answer this question, we propose a novel method to reweight the confidence of the CRF by combining distinctive metric of features.
The feature descriptor of a pixel is extracted as follows: the neighborhood of the pixel is divided into a 4 × 4 cell array, the orientation is quantized into eight bins in each cell, and a 4 × 4 × 8 = 128 dimensional vector is obtained as the SIFT representation for a pixel. Intuitively, if the neighboring area is smooth, there will be a single or no peak in SIFT flow descriptor. When the texture of the neighboring area is rich, there will be more than one peak in SIFT flow descriptor. As shown in Figure 5(b), the distribution of the SIFT flow descriptor in the points A and C has no peak and is flat, while the one in the point B has more than one peak. Inspired by this intuition, we use variance to describe the discrimination of the SIFT flow descriptor and then reweight confidence of the data term in the CRFs.
The confidence weight of the data term is redefined as

where v(xi) is the variance of the SIFT flow descriptor in pixel i. We set μs = 0.5 and σs =0.01.
We reweight the confidence of the data term in the CRFs and name it as reweighted confidence.
Experimental evaluations
The experimental computer configuration is 3.7 GHz Intel CPUs with 32 GB memory. The proposed method is tested in both outdoor and indoor scenes. In particular, the proposed method is evaluated using two publicly available data sets: the Make3D data set
8
and the NYU v2 Kinect data set.
30
In addition, the DepthTransfer
11
algorithm and two baseline methods are also implemented on the same data sets. We use Matlab, R2014a programming language to implement the referred algorithms. The following three commonly used error metrics are used for quantitative evaluations Average relative error (rel): Average Root mean squared error:
where D denotes the estimated depth, D∗ denotes the ground truth depth, and N denotes the total number of pixels in all images.
Sparsity
In order to study the relationship between the sparsity and the computation cost and learning accuracy, we made a comparison among three sparsity experiments. According to Figure 3, we implement the bilinear interpolation at the second, third, and top flows, respectively, whose sparsity is increasing. The proposed method with different sparsity is tested on the Make 3D database and the NYU v2 Kinect data set, and corresponding results are shown in Figure 6. It is evident that with the increase of the sparsity of the sparse SIFT flow, the computation cost is decreasing, while the estimation accuracy remains almost the same. For the sake of preserving the accuracy of the depth extracted from single images, the second flow is chosen to implement the bilinear upsampling in the following experiments.

The Make 3D data set and NYU data set are implemented bilinear interpolation at second flow, third flow, and top flow, respectively. (a) Average relative error, (b) average log10 error, (c) root mean squared error, and (d) time performance.
Evaluations on Make3D data set
The Make3D data set contains 534 images with the corresponding depth maps, and it is partitioned into 400 training images and 134 test images. All the images are resized to 460 × 345 pixels in order to preserve the aspect ratio of the original images. The corresponding results by the proposed method and three state-of-the-art algorithms are reported in Table 1, and a plot of the depth errors is shown in Figure 7(a). It is evident that the proposed method is much faster than the DepthTransfer, and the speed-up ratio is about 2.170. At the same time, we achieve similar performance as the DepthTransfer and better performances than Make3d. 8 Figure 8 provides some qualitative comparisons of our depth maps with those estimated by the DepthTransfer using the data set. It can be seen that the maps estimated by our method and the DepthTransfer 11 are visually similar.
Depth reconstruction errors and running times on the Make3D data set.

rms: root mean squared; rel: relative error; italics are error metrics, which are used for quantitative evaluations.


Qualitative comparison on the Make 3D data set: (first row) four example images, (second row) the corresponding ground-truth, (third row) the corresponding results of the DepthTransfer, 11 and (fourth row) the corresponding results of the proposed method.
In addition, we evaluated the effectiveness of our reweighted confidence scheme using the Make 3D database. We implement the proposed method with and without the reweighted confidence scheme. The corresponding results are shown in Table 2.
Performance comparison between the reweighted confidence and non-reweighted confidence on the Make3D data set.
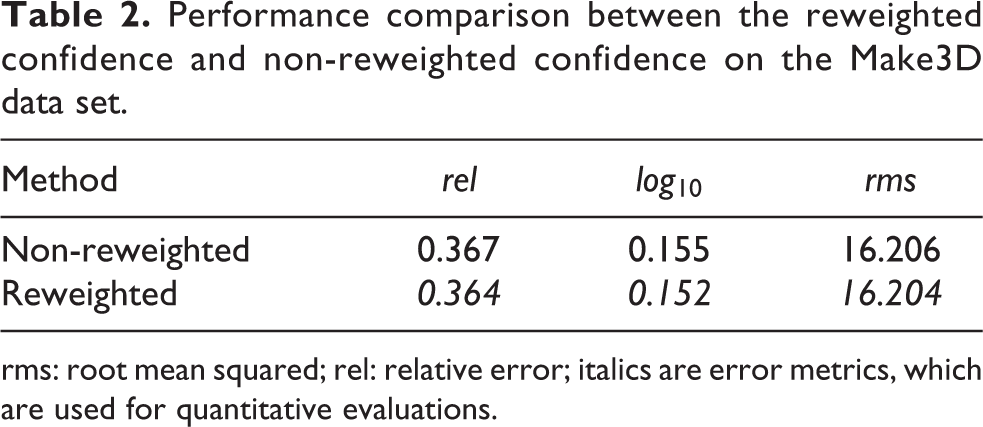
rms: root mean squared; rel: relative error; italics are error metrics, which are used for quantitative evaluations.
Evaluations on NYU depth data set
The NYU depth data set consists of 1449 indoor RGB-D images captured using a Kinect. It is randomly partitioned into 1086 training images and 363 test images. Holes from the Kinect are disregarded during training (candidate searching and warping) and are not included in our error analysis.
The proposed method with the sparse SIFT flow and the reweighted confidence is tested on the NYU data set, and the corresponding results are reported in Table 3. In addition, the computation errors and time by Karsch et al., 11 Make3d, 8 discrete–continuous, 27 and Zhuo et al. 28 are also reported in Table 3, and a plot of the depth errors is shown in Figure 7(b) at the same time. It is noted that our method is faster than the DepthTransfer, and the speed-up ratio is about 2.10. At the same time, Figure 9 provides some qualitative comparisons of our depth maps with those estimated by the DepthTransfer using the data set. It can be seen that the estimated maps by our method and the DepthTransfer 11 are visually very close.
Depth reconstruction errors and running time on the NYU depth data set.

rms: root mean squared; rel: relative error; italics are error metrics, which are used for quantitative evaluations.

Qualitative comparison on the NYU data set: (first row) four example images, (second row) the corresponding ground-truth, (third row) the corresponding results of the DepthTransfer, 11 and (fourth row) the corresponding results of the proposed method.
Furthermore, the effectiveness of our reweighted confidence scheme is also evaluated on the NYU database. The proposed method with and without the reweighted confidence scheme is implemented, whose corresponding results are reported in Table 4.
Performance comparison between the reweighted confidence and non-reweighted confidence on the NYU depth data set.
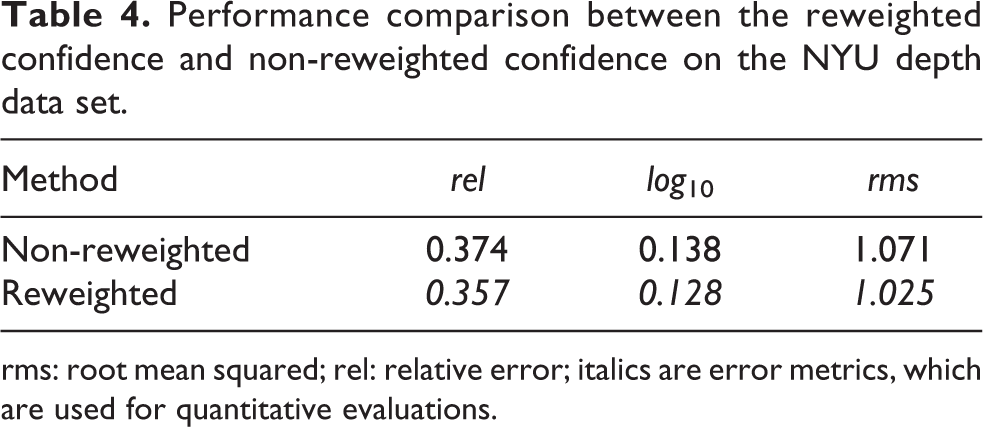
rms: root mean squared; rel: relative error; italics are error metrics, which are used for quantitative evaluations.
Discussion of the reweighted confidence
After implementing the reweighted confidence on the Make 3D data set, the quantitative gains are marginal, as shown in Table 2. However, we show a significant improvement on the NYU v2 Kinect data set with the reweighted confidence scheme, as reported in Table 4. In order to make a clear deep analysis, the variance of every pixel in data sets is computed using the SIFT flow algorithm, as shown in Figure 10. Figure 10(a) shows the average variance of the every test image and Figure 10(b) shows the variance histogram of the every pixel in the test data set. Inspired by Figure 5, the pixel with large variance is weighted with significant confidence, and the small variance pixel is given the small weight, as shown in equation (5). Therefore, the depths estimated from large variance data set could have a big improvement with the reweighting scheme. As shown in Figure 10, the statistical variance of the NYU v2 Kinect data set is higher than the one of the Make 3D, and the average variance of the two data sets is small, which are coincidence with the reweighted confidence scheme. By analysis of the statistical variance of the data sets, the reweighting scheme is helpful in improving the depth accuracy when the variance of images is large.

(a) The average variance of the every test image and (b) the variance histogram of the every pixel in test data set.
Conclusion
In this article, we have studied the optimization problem of the DepthTransfer by exploiting the availability of a pool of images with known depth. The complexity was reduced from subquadratic to sublinear by the proposed sparse SIFT flow, while preserving the accuracy of the DepthTransfer by reweighting the confidence of the data term. Extensive experimental evaluations demonstrated the effectiveness of the proposed approach. In the future, we will further study the edge depth inference to obtain a more distinctive sketch of scene.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (XDB02070002) and National Natural Science Foundation of China under grant nos 61421004, 61333015, 61573351, and 61283282.