
Abstract
For robot systems, robust facial landmark detection is the first and critical step for face-based human identification and facial expression recognition. In recent years, the cascaded-regression-based method has achieved excellent performance in facial landmark detection. Nevertheless, it still has certain weakness, such as high sensitivity to the initialization. To address this problem, regression based on multiple initializations is established in a unified model; face shapes are then estimated independently according to these initializations. With a ranking strategy, the best estimate is selected as the final output. Moreover, a face shape model based on restricted Boltzmann machines is built as a constraint to improve the robustness of ranking. Experiments on three challenging datasets demonstrate the effectiveness of the proposed facial landmark detection method against state-of-the-art methods.
Keywords
Introduction
Facial landmarks encode significant information about face shape deformation. Accurate detection of facial landmark points has aroused great interest, owing to its importance in such applications as human identification, facial animation, and facial expression recognition. It has been proven that the performance of face recognition can be remarkably elevated when using extra facial landmark locations. 1,2 Although several methods have been proposed for facial landmark detection, facial point estimation for real-world images with facial expressions, poses, or occlusion has always been a challenging problem, since current approaches struggle to handle the outliers that are generated under these conditions.
Previous work on facial landmark estimation, such as active shape modeling 3 and active appearance modeling, 4 focuses on explicit modeling of the shapes of objects. However, these methods tend to fail under the condition of large pose variations or facial expressions, especially for occluded faces in real-world applications. In general, they suffer from poor generalization performance and slow training. Even on datasets “in the wild,” they still cannot deliver state-of-the-art performance.
Lately, popular cascaded-regression-based approaches, such as the supervised descent method 5 and models based on cascaded pose regression 6,7 and local binary features, 8 have achieved similar state-of-the-art performance. Under the supervised descent method, scale-invariant feature transform features or histogram of oriented gradient (HOG) features are utilized for facial landmark detection by learning descent directions that minimize the mean of a non-linear least squares function. Models based on cascaded pose regression 6,7 select random ferns as primitive regressors instead of using a single regression, as done under previous methods. The robust cascaded pose regression model 9 is an improvement of the cascaded pose regression model for handling occlusions and large shape variations by detecting occlusions and using shape-indexed features; this method is more robust. Methods based on local binary features help realize facial landmark detection by learning the local binary features, which can be discriminated independently, and utilize the features to learn a global linear regression for the final output. All of these methods have achieved the state-of-the-art results on the most challenging datasets available currently. Nevertheless, such cascade regression methods are highly sensitive to the initialization. If the initial face shape differs too much from the ground truth, the performance of the cascade regression method will decrease, especially for extreme poses and expressions.
Some approaches estimate the pose by first detecting the eyes and mouth independently and then choosing the best initialization. However, such methods are highly sensitive to occlusion. Cui et al. 10 uses eyes and mouth to form a triangle, which designates the rough facial pose direction. Nonetheless, the dependency of the triangle and pose direction is not strong enough to ensure the robustness of the prediction. Burgos-Artizzu et al. 9 propose a smart restart scheme that can alleviate the shortage to some extent.
In addition, it seems like a good strategy to implement several initializations. By setting several different poses as the initializations instead of using the mean face shape (derived from training data), which is always far from the ground truth, and then estimating face landmarks independently based on these initializations using a cascade regression method, there would be a higher probability of approximating the ground truth. Cao et al., 6 Burgos-Artizzu et al., 9 and Yang et al. 11 attempt to initialize with several shapes and then calculate the average value of the outputs as the final result. However, the accuracy of the median value is still unsatisfactory. Based on this intuition, our research group aims to propose a novel strategy to rank these estimates and obtain the final shape output by predicting the probability that an estimate will approximate the ground truth. Unfortunately, it is difficult to calculate the probability directly from the appearance, because the robustness of prediction is not strong enough, owing to variations in the facial appearance, especially in the more challenging images. In addition, it is difficult to rank results when there is not much difference in the landmark estimates.
To address these problems, a novel ranking method is proposed to select the best estimate. Firstly, a score variable is defined to measure the deviation of a predicted landmark value from its true value. To predict the score more accurately, a deviation evaluation model based on two-level regression is put forward, which has the capacity of distinguishing estimates that are only slightly different by utilizing local appearance information. Secondly, a deviation evaluation model based on a prior shape model is used to calculate the reconstruction errors for measuring the difference between the typical face shape pattern and each face landmark estimate.
However, training a face shape model is still challenging, because it is difficult to capture face shapes in different poses or with different facial expressions. Recently, the use of restricted Boltzmann machines (RBMs) and their variants has been proposed to solve this challenging problem and have achieved outstanding results. 12,13 It is worth mentioning that most RBM-based models that can handle the pose problem are difficult to train. In this article, a brief and effective model based on conditional Boltzmann machines 14 is applied to capture face shape patterns with different poses and facial expressions, which are then embedded in the ranking model as constraints to improve robustness.
The major contributions of this research are described as follows.
In contrast to using the median value of the several shape estimates as the final output, like most current methods, we propose a novel ranking model, which selects the best shape by estimating the deviation of a predicted landmark value from its true value.
A deviation evaluation model based on two-level regression is trained to distinguish two similar estimates by utilizing local appearance information.
A deviation evaluation model based on an RBM-based shape model is utilized to calculate the reconstruction error to evaluate the global shape deviation, which can help rank the shape estimates robustly.
This method is evaluated using Annotated Faces in the Wild (AFW), IBUG, and Caltech Occluded Faces in the Wild (COFW) datasets. 9,15,16 The algorithm in this article shows results that are comparable with or better than state-of-the-art methods.
The rest of this article is organized as follows. The details of the proposed robust facial landmark detection method are described. Experimental result are then presented, and compared with state-of-the-art methods. Then follows a discussion of the impact of the facial landmark detection method to image-based applications. The article concludes with a summary of this research work and its future extensions.
Proposed method
Overview of the proposed method
The general framework of the proposed method is shown in Figure 1, which includes three major parts: (1) a pre-processing module for facial landmark detection; (2) a cascade regression module for estimating the facial landmarks; and (3) a ranking model for estimating the deviation between a predicted facial landmark and its true value.
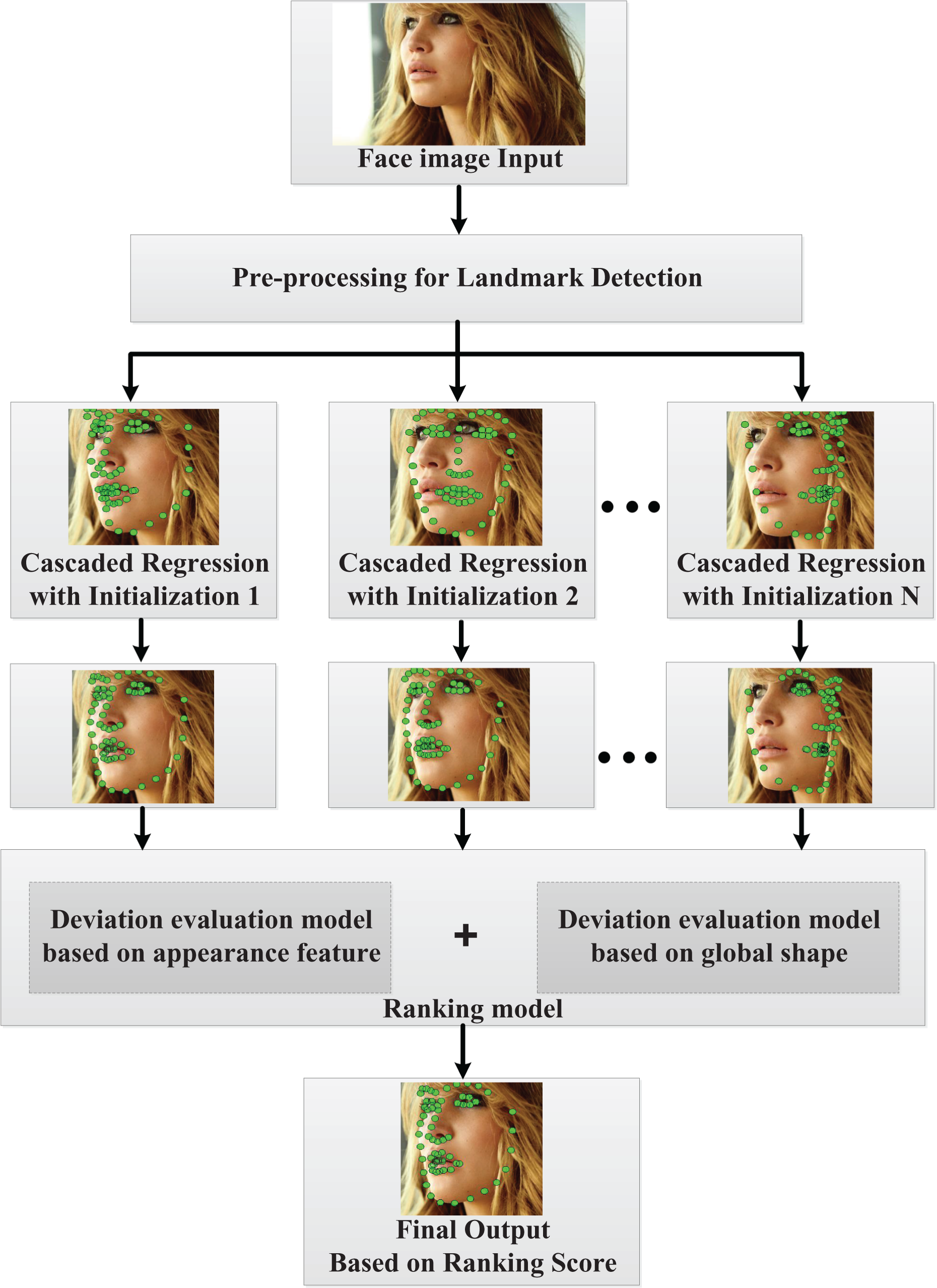
Overall procedure for the proposed method.
In the first step, for a test face image, it is necessary to crop and resize all faces to a unified scale by utilizing the pre-processing module for facial landmark detection. After the pre-processing procedure, we have a new face image with unified size and the face bounding box.
In the second step, a cascade regression module is used to estimate facial landmarks by starting from an initial shape. In this method, to overcome the face poses problem, N face shapes under different poses are set as the initializations, based on which facial landmarks are estimated independently with the cascade regression module. After this procedure, N facial landmark estimates corresponding to different initializations are obtained.
The final step is to select the best estimate, which is closer to the real value, from N facial landmark estimates by utilizing our ranking module. Since we do not have the ground truth landmark locations for any test images in real application, the truth deviation between the predicted facial landmarks and the ground truth landmarks cannot be obtained. Therefore, in this module, we establish two deviation evaluation models on the basis of appearance and shape information, separately, to estimate the deviation between the predicted facial landmarks and the ground truth. After combining the two deviation evaluation results, a ranking score can be obtained, and the estimate with the minimum score is output as the final landmark detection result.
Pre-processing for facial landmark detection
The pre-processing flow of the cascaded-regression facial landmark detection method is shown in Figure 2. Firstly, the face is detected using the OpenCV face detector. Then the image is cropped based on the bounding box proposed by the face detector. In the following procedure of facial landmark detection, the HOG feature is extracted within a fixed-size region around each landmark. Nonetheless, this fixed-size region can be different, owing to the different pixel densities of images. For example, a 50 pixel × by 50 pixel region may cover the whole face part or only the mouth part in different images. Thus, it is necessary to resize all faces to a unified scale by normalizing the images to the mean shape.

Pre-processing steps for landmark prediction.
Cascaded regression
Algorithm 1 shows the main process of the cascaded-regression method. The n facial landmarks of an image can be expressed as a shape vector

Specifically, the method starts with an image I and an initial shape estimate S0. The regressor RK computes a shape increment ΔSK to update the shape until the last iteration. At the T th iteration, the shape is estimated through

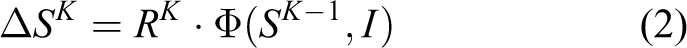
where I is the image and

Facial landmark detection results in different iterations.
Learning the multi-initialization cascaded-regression model
Generally, the traditional cascaded-regression method sets the initial shape as the mean face shape of training images. On the one hand, the mean face shape is closer to the facial shapes under different poses, and the corresponding model can cover most kinds of situation; on the other hand, accuracy will be more or less sacrificed for each single shape.
To solve the problem, the initialization should be discriminative for different facial shapes. It needs to be emphasized that the discriminative strategy is not used in the test part, so a rough pose estimate method is proposed. Instead of training a classified model, it is preferable to utilize the triangle formed by the eyes and nose from the ground truth shape to choose the initialization, as shown in Figure 4. To estimate the linear regression function with parameter R in each iteration, a standard least squares formulation is employed. Specifically, given N training examples
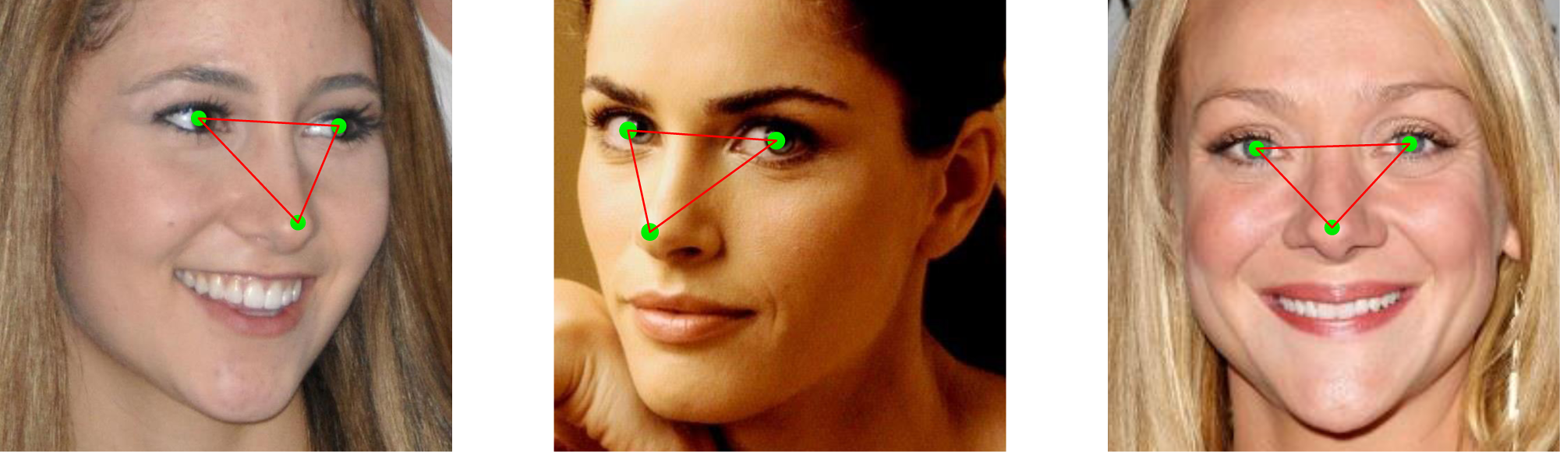
Selection of the initialization by utilizing the triangle formed by the eyes and nose.
To obtain each regressor
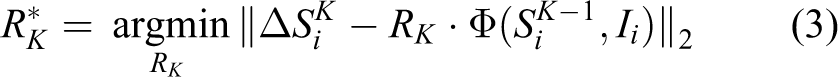
wherein I is the image,
Ranking model
To reduce the influence of the initialization, it is chosen to set several different poses as the initializations, instead of using the mean face shape; independent estimation of face landmarks according to these initializations is then achieved through cascaded regression. The goal of this facial landmark detection algorithm is to determine the best estimates as the final output.
Figure 5 gives an example of the detection results with five initializations. Although there are significant differences between these results, it is still difficult for a computer vision system to distinguish which one is closer to the ground truth value because we do not have the true landmark locations for any test images in real application. Fortunately, as we can see in in the leftmost and rightmost images of Figure 5, for the same landmark, the local appearance around each landmark location is widely divergent. This kind of difference can help us evaluate the deviation between the predicted facial landmarks and the ground truth landmarks by using the local appearance features because human beings have similar local appearance features around the same landmarks. In this method, a deviation evaluation model based on two-level regression is proposed to establish the mapping relationship between the appearance features around the i th landmark and the deviation of a predicted value from its true value. A HOG feature describer is applied to represent the appearance features of the local patches centered at each landmark locations. The model is explained in detail in the next section.

An example of the detection results with five initializations.
Referring again to Figure 5, obviously, the central and rightmost images present the worst results. As the features of the local patches centered at the current landmark locations are totally different from those of the other three images, it is easy to exclude these two estimates.
Meanwhile, the remaining three images have similar features around the landmarks, and it is difficult to distinguish them just by the appearance features. By observing the detection result in the fourth image, we can find that, although the features around landmarks are “ballpark”, the global face shape does not look like a normal human face.
For the second image, the landmark location of the nose does not match the 45° profile face. In fact, many studies have reported particular patterns for human face shapes under differential facial expressions and poses. This provides an opportunity for us to calculate the difference between the typical face shape pattern and each face landmark estimate. This strategy can also help in estimating the deviation of a predicted landmark value from its true value.
In this method, a deviation evaluation model based on a global shape model is proposed to establish the mapping relationship between the face shape and the deviation of a predicted landmark value from its true value. The evaluation model needs a prior face shape to capture face shape patterns with different poses. In this method, an effective model based on conditional Boltzmann machines can be utilized to model the face shape pattern, and then calculate the reconstruction errors that measure the difference between the typical face shape pattern and each face landmark estimate. The model is explained in detail in the next but one section.
To combine the two deviation evaluation models, a score variable is defined as P, which measures the level to which the landmark estimate approximates the ground truth to rank each estimate. The ranking score prediction depends on the local appearance and the current shape. Then the score P can be calculated as
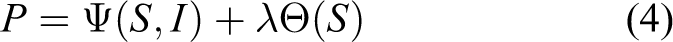
where I is the image, S denotes the current predicted landmark value, Ψ(S, I) represents the deviation evaluation model based on appearance features, and the deviation evaluation model based on global shape is expressed by Θ(S). The weight of each model is determined by λ. The two parts of the function can be trained separately.
Deviation evaluation model based on appearance feature
To encode the appearance information, the HOG features of the local patches centered at the i th landmark locations S are utilized and denoted as Φ(S, I). The deviation evaluation model Ψ(S, I) based on appearance feature can be expressed as

where I is the image, and Φ(S, I) denotes the HOG features of the local patches centered at the current landmark locations. A linear regression function with parameter TK is utilized to predict the deviation of a predicted value from its true value based on the appearance features Φ(S, I).
In experiments for this research, it was found that a single regressor can effectively exclude estimates that are widely different from the ground truth. However, it has too weak and poor performance in ranking similar estimates. Although the face shape model is utilized to help enhance the robustness of the ranking model, there are still a number of failure cases. This is because it is too difficult to regress all kinds of N estimates.
In fact, massive training data that are widely different from the ground truth should be utilized to cover as many kinds of feature as possible. The advantage is that any kind of failing estimation can be excluded even if it has a perfect shape, and the disadvantage is that estimation accuracy will be sacrificed. It is significant to acquire a good regressor that can accurately cover all kinds of estimates. For this purpose, it is advised to acquire the regressor T through a second-level regression.
Unlike cascaded regression, the HOG features are invariable at the two levels. It is only relative to SK−1 that they no longer change. The Ψ(S, I) regression function can be changed to

where I is the image and Φ(S, I) denotes the HOG features of the local patches centered at the current landmark locations. The two-level regression, T1 and T2, should be trained based on different datasets. To estimate the linear regression function with parameters T1 and T2, a standard least square formulation is also utilized.
To estimate the linear regression function with parameter T in each iteration, a standard least square formulation is adopted. Before introducing the training process, it is necessary to describe the definition of the ground truth feature score

where si is the i th landmark of the corresponding estimate and
Two training sets are prepared for the two-level regression. To estimate T1, the proposed cascaded-regression model is utilized to detect all the training data for the cascaded regression RK under N different initializations, and the results are regarded as the first training set. Then the feature scores are calculated through equation (4) and the two lowest scores are rejected. The corresponding shape estimate is put into the second training set.
Again, given the training image and the currently estimated landmark locations S, we can calculate the appearance and shape features Φ and the ground truth score. Then T could be estimated as

where I is the image, Φ(S, I) denotes the HOG features of the local patches centered at the current landmark locations, and
Deviation evaluation model based on global shape
The deviation evaluation model Θ(S) based on global shape can be expressed as

where Si is the i th landmark of the corresponding estimate and
Although human faces are different in both the size and shape of facial components, such as the size of eyes and the contour of mouth, the position distributions of facial feature points are similar. Therefore, there are many patterns for human face shapes. In fact, if the prior face shape pattern function E(Si) can be obtained, the difference between the ground truth value and the estimates can be measured, as shown in Figure 6.
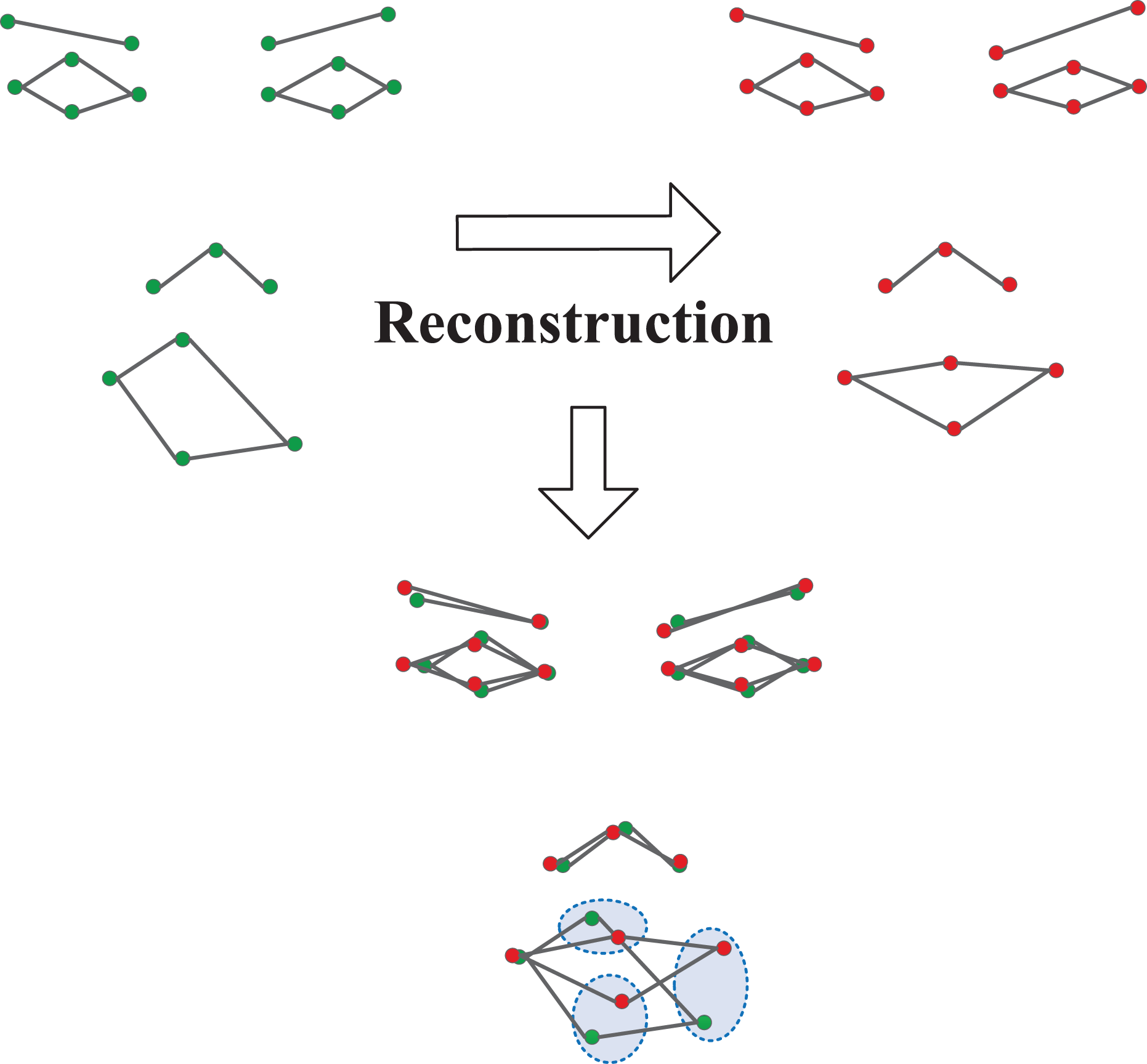
Reconstruction errors.
Prior face shape models have been proven helpful in improving facial point detection accuracy, as they make it possible to evaluate the quality of the estimates and constrain and correct the corruptions. However, building a strong probabilistic model of face shapes is still challenging because of its complex properties.
Recent research has shown that RBMs can also be used to model shapes. 14,17 A deep Boltzmann machine (DBM) has been constructed to capture face shape variations caused by facial expressions for near-frontal views, and facial points can be tracked robustly and accurately in case of significant changes in facial expressions and poses using this model. 12,13 Nevertheless, this method is too complex and difficult to learn. In this article, a model based on a conditional RBM 14 is advocated and utilized to construct a face shape prior model based on the landmark labels of the training data.
As shown in Figure 7, the proposed face shape model consists of two parts: pose-DBM and front-RBM. The model describes the joint probability distribution of the visible unit vector S and hidden unit vector H1, with a conditional RBM, which depends on the hidden input Z2, where Si is the facial landmark estimate achieved by using the cascaded-regression method and Z1, Z2, and H1 are binary hidden nodes. In pose-DBM, a two-layer DBM extracts the pose information, and the hidden nodes Z2 represent the head pose variations of the current face shape. In front-RBM, H1 captures the shape variations of the estimate.
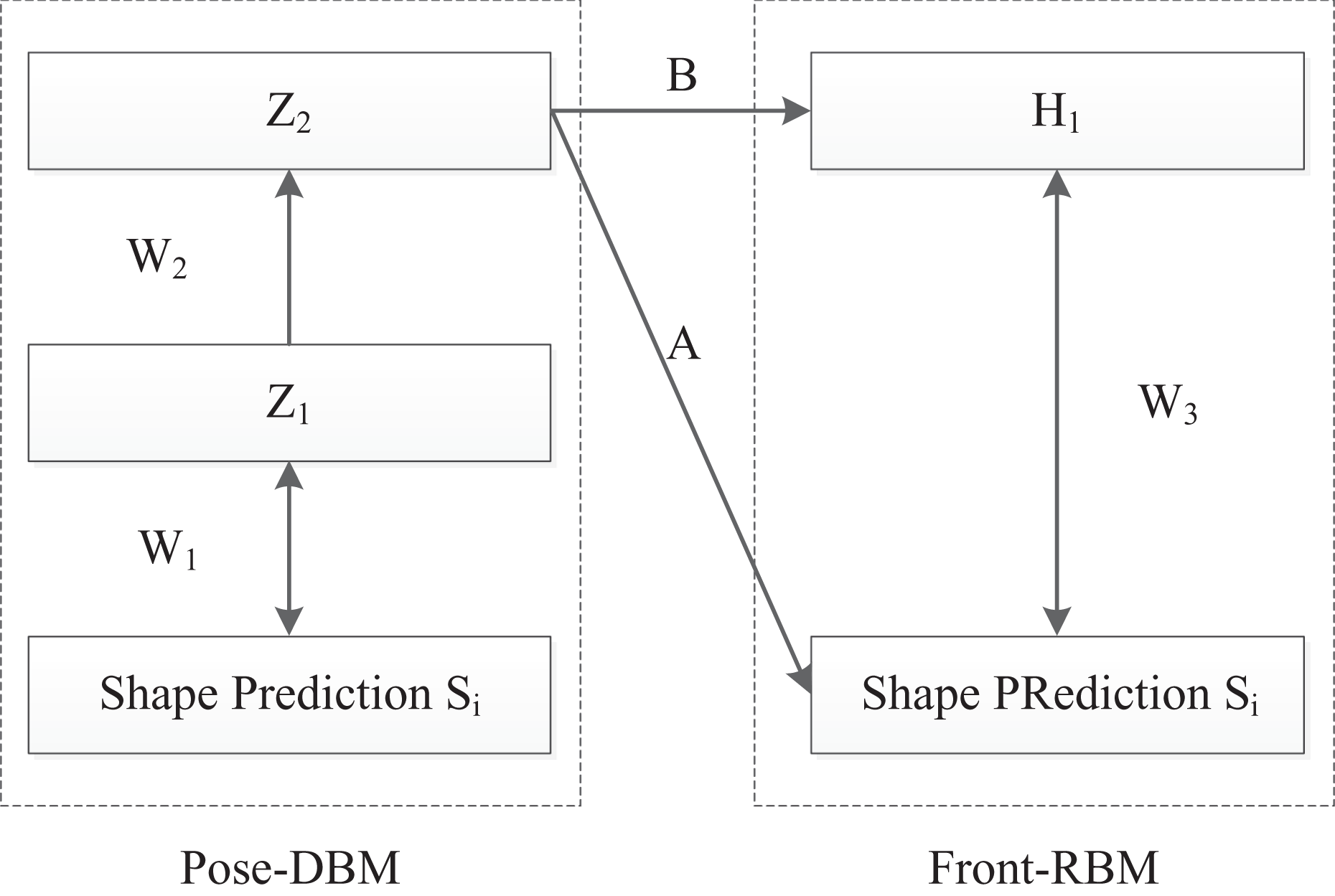
Proposed face shape model.
This face shape mode is built to represent the function E(Si). Based on the pretrained pose-DBM and the front-RBM, a Markov-Chain-Monte-Carlo-based Gibbs sampling method is used to generate samples for the reconstruction Ri
according to the face shape estimation Si (Figure 8). Then the reconstruction errors can be calculated as

Markov Chain Monte Carlo Gibbs sampling scheme.
Figure 9 presents the module that evaluates the quality of the face shape estimate by calculating the reconstruction Ri from the shape Si

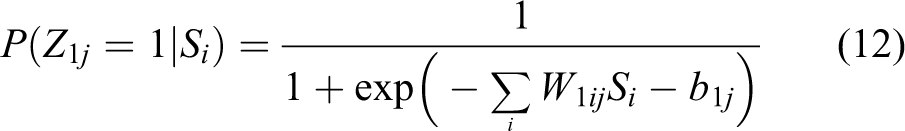
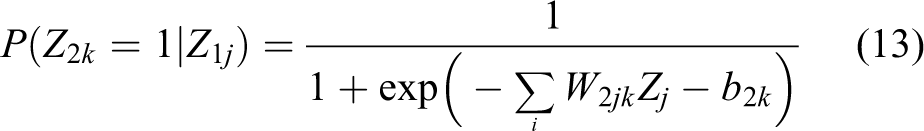
where the symmetric weight W1ij connects visible nodes S to hidden unit Z, W2jk connects hidden nodes Z1 to hidden unit Z2, and b1j and b2k are the bias of hidden nodes Z1 and hidden unit Z2.

Graphical depiction of the face shape estimate evaluation module.
Then the hidden layer H1 for the front-RBM can be calculated as the regulation of conditional Boltzmann machines. The hidden units are determined by both the input received from the current observation and the input Z2. The effect of Z2 on each hidden unit can be viewed as a dynamic bias

where the symmetric weight Bjk connects hidden unit Z2 to hidden unit H and bj is the bias of hidden nodes H.
The hidden layer H1 can be written as
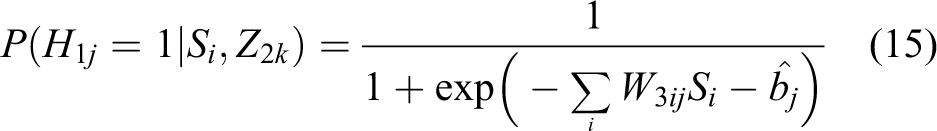
where the symmetric weight W3ij connects visible unit S to hidden unit H and
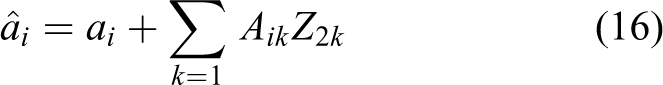


where the symmetric weight Aik connects hidden unit Z2 to visible unit S, ai is the bias of visible unit S, and
The parameters

Focusing on the learning processing for conditional Boltzmann machines, a contrastive divergence algorithm 19 is chosen to help learn this model. The parameters θ are learned by maximizing the log-likelihood function:
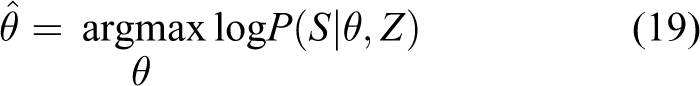
The contrastive divergence algorithm 19 is utilized in this learning work





where 〈〉data is an expectation with respect to the data distribution and 〈〉recon is with respect to the distribution of “reconstructed” data. Through an alternate sampling between the hidden visible units for K times, this reconstruction data can be obtained.
Experiment results
Implementation details
For learning the face shape model, the training sets of the HELEN and LFPW datasets and images from part of the Multi-PIE database are used. The Multi-PIE database [20] was collected in a laboratory environment, and contains 337 subjects imaged from 15 viewpoints and under 19 illumination conditions with six expressions: neutral, smiling, surprised, squinting, disgusted, and screaming. The ground truth coordinates of the facial landmarks in these datasets were annotated manually by human beings, and coordinate values are measured in pixels.
It is easy for us to calculate the distance between the landmark estimate and the ground truth coordinates. We call this distance the “errors”; obviously, the smaller the error, the more accurate the detecting results. However, the faces can be dramatically different, owing to scale variations in the images; for example, for a 50 pixel × 50 pixel patch, we may retrieve the whole face part from a small face and only the nose part from a large face. Therefore, it is necessary to normalize the error using the distance between the pupils (the centers of the eyes). We define this distance the inter-ocular distance error. The error is calculated as the distance between the landmark estimate and the ground truth, normalized by the inter-ocular distance error, which is defined as

where
Performance evaluation on AFW dataset
The AFW dataset 16 was randomly sampled from Flickr images. This dataset consists of 337 face images with large variations in both face viewpoint and appearance (for example, aging, sunglasses, make-up, skin color, and expression). Each face is labeled with 68 landmarks. The training part of the experiment used the training images of the LFPW and HELEN datasets, with 2811 samples in total.
Figure 10 and Table 1 show the comparison with the results of the supervised descent method. This latter method is one of the most classic cascaded-regression-based approaches. In fact, our multiple-initializations-based method is an improvement on the supervised descent method. We use the same HOG feature, and the similar cascaded-regression framework. The primary dissimilarity is that we propose a ranking strategy to select the best shape estimate. To prove the validity of our algorithm, the supervised descent method is the obvious choice for comparison. As can be seen, based on the limited comparable results on the AFW dataset, the performance of the proposed method on the challenging dataset is better than the state-of-the-art supervised descent method. Furthermore, this proposed face shape model is effective in helping to enhance the robustness of the facial landmark detection model. We also divided the faces in the AFW dataset manually into indoor (219 faces) and outdoor (118 faces) images. We performed experiments on the indoor and outdoor databases separately to determine whether there exist differences when using the method to process images taken indoors and outdoors. Figure 10 shows the resulting images compared with those obtained using the supervised descent method and ground truth; as we can see, our detection method has significant advantages over the supervised descent method.

Comparison results on AFW. Top row: supervised descent method; middle row: proposed method; bottom row: ground truth.
Comparison using AFW dataset.

AFW: Annotated Faces in the Wild.
Table 2 displays the mean error under different initializations. It can be clearly seen that the error decreases gradually with increase in number of initialization; this indicates that this multi-initialization strategy is effective for images with a large variety of poses. However, although a method using different initial poses has improved accuracy, computational costs increase. In this experiment, we find that most estimates can be eliminated in early iterations of the cascaded regression. This means that the number of iterations for different initializations can be different in the cascaded-regression module. For instance, in Figure 5, it is easy to eliminate the third, fourth, and fifth images at the second iteration but the first two images cannot be distinguished until there are four iterations. Inspired by this, instead of setting a fixed number of six iterations, as used in the supervised descent method, we change it in the ranges of [2:4]. A comparison of detection speeds for different numbers of initializations using the AFW dataset is shown in Table 2. It can be clearly seen that five initializations is the best choice, according to the errors and computational costs. Our results were obtained using a i7-4770 CPU and MATLAB.
Comparison of detection speed on AFW dataset.

Performance evaluation on IBUG dataset
The IBUG dataset is the most challenging dataset in 300 Faces In-the-Wild Challenge (300-W) dataset; it was created for facial landmark detection in the real world. 15 All the images in this database contain faces with extreme poses and expressions. However, it only provides training images. For comparison with recent work, the training images of the LFPW, HELEN, and AFW databases, with 3148 samples in total, were chosen for the training part of the experiment, following the experimental method of Ren et al. 8 The testing set consists of 135 images altogether. Landmark annotations in this experiment followed the Multi-PIE 20 68 points mark-up.
The comparison is shown in Table 3. It is worth mentioning that the results of the supervised descent method, explicit shape regression method, robust cascaded pose regression method, and local binary features method are quoted from Ren et al. 8 Table 3 shows that the performance of the proposed method on the challenging IBUG dataset is better than those of other state-of-the-art methods. As this facial landmark detection method focuses on handling image with head different head poses, the approximate frontal face image is not optimized. Moreover, the local binary features method is much better than HOG descriptors. On this basis, a better result is still achieved. Therefore, it can be concluded that the proposed method has a strong ability to handle difficult poses on this challenging dataset.
Comparison with the IBUG dataset.

aReported results from the original articles.
Figure 11 shows the comparison with the resulting images. The supervised descent method is one of the most classic cascaded-regression-based approaches and the code of the supervised descent method algorithm and its parameters are publicly available. Since we use the same HOG feature as, and a similar cascaded-regression framework to, the supervised descent method, this method was selected for comparison. Ren et al. 8 have published their well-trained model with results using the training images of the LFPW, HELEN, and AFW datasets, with 3148 samples in total, so we can obtain the resulting images, as shown in the second row of Figure 11. For the other algorithms listed in Table 2, we could not guarantee that we would obtain similar results to the original articles, because the parameters of these models were not published. Therefore, to be fair, we do not show resulting images for the other two algorithms listed in Table 3.

Comparison results for the IBUG dataset. First row: supervised descent method; second row: local binary features method; third row: proposed method; fourth row: ground truth.
Referring to Table 3, we can see that the local binary features method has been the most efficient algorithm so far, because it uses local binary features which are learned in the training stage. Although this method is much faster than the conventional HOG feature method, we note that the local binary features method needs to train hundreds of thousands of trees, which greatly increases the computational costs in the training stage. In addition, the speed of the local binary features method, 8 which is quoted from the original article, is implemented in C++ in the original article, which is much faster than MATLAB. We believe that if we incorporate the learning-based feature in our framework in future, the accuracy and efficiency of our method can be improved considerably.
Performance evaluation on COFW dataset
As a more challenging dataset, the COFW dataset [9] includes images with large variations in shape and occlusions due to differences in pose and expression. All 1007 images are annotated using the 29 landmarks. A total of 1345 images for 845 LFPW and 500 COFW faces were selected for the training part of the experiment. The remaining 507 COFW faces were used for testing.
Table 4 exhibits the comparison between the proposed method and recent state-of-the-art methods, including the cascaded-regression copse method, 21 supervised descent method, 5 robust cascaded pose regression method, 9 and explicit shape regression method. 6 Compared with other cascaded-regression methods, the proposed multi-initialization scheme is very effective in further decreasing the mean error.
Comparison on COFW dataset.
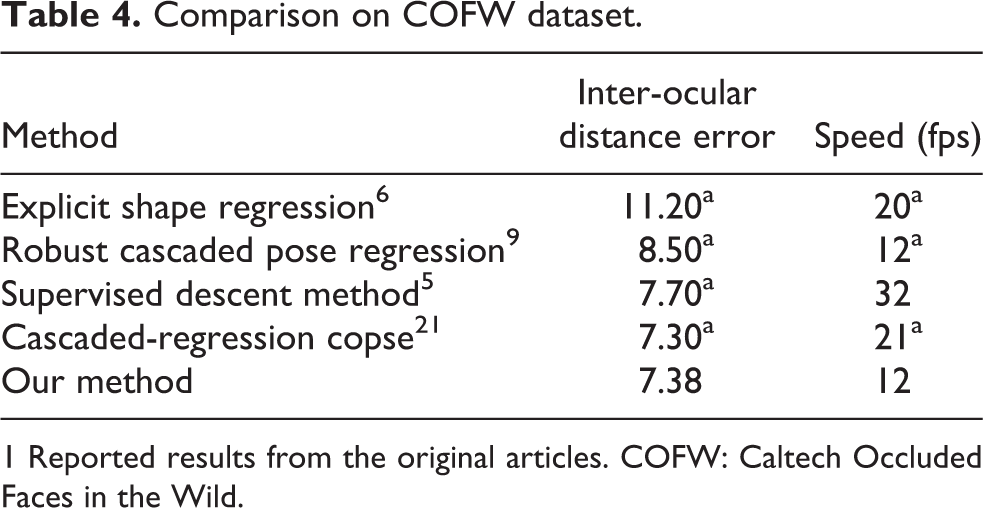
1 Reported results from the original articles. COFW: Caltech Occluded Faces in the Wild.
As the model can iteratively predict the landmark occlusions, the result presented by Feng et al. 21 is better than this research result. Importantly, the reason may lie in the fact that the average landmark occlusion for the COFW dataset is > 23%, for which no countermeasure is designed in our model.
Applications with robust facial landmark detection
Automatic facial landmark detection has been an active area in computer vision during the past decades. Although there have recently been tremendous improvements in the facial landmark detection algorithms on “in-the-wild” images, what kinds of applications can be newly achieved using the facial landmark detection method are rarely discussed. In this section, we discuss the impact of the facial landmark detection method on image-based applications in three major areas: (1) face recognition; (2) facial animation; (3) facial expression recognition.
Face recognition
For a robotic vision system, face recognition is the basis of access controls or video face spotting. In addition, as social networking services develop, the automatic organization of photo collections based on accurate face recognition, which Google and Facebook have begun to apply, is becoming more and more popular. Formerly, with detected facial landmarks, human facial shapes and appearance feature around key points could be utilized for facial attribute analysis. Recently, with the development of deep learning in computer vision, feature extraction and classification can proceed simultaneously, and it seems as if the procedure of facial landmark detection is no longer needed.
However, in reality, face images are often taken under such conditions as different viewpoints, lighting, rotation and occlusion, which significantly decrease the performance of face recognition. To overcome these problems, in general, three succeeding steps need to be applied in face recognition: face detection, face alignment, and face recognition. In the first step, face detection is utilized to search the coarse location of faces in an image. In the second step, face alignment, utilizing landmark localization for geometric face normalization can increase the performance of face recognition very effectively, owing to the geometric invariance of the human face. The importance of face alignment has been demonstrated; 1,2 it can be seen that a face alignment step clearly improves the performance of face recognition. It is should be stressed that, as one of the best face recognition systems, designed by Google, FaceNet, 2 which is based on deep learning, also greatly enhances its performance when using extra face alignment. It has fully proved the importance of automatic facial landmark detection in face recognition.
Facial animation
The generation of realistic facial animations for virtual characters is frequently used in film and game production. With the development of virtual reality technology, this form of facial animation simulation can be more and more popular through online games. Generally, to synthesize facial expressions more convincingly, many sensors should be attached on the human face, which greatly limits the scope of its application. Recently, benefiting from facial landmark detection algorithm, facial landmarks are used as the input to drive the animation of a virtual character. 22 In the course of implementation, once the facial landmarks are attained, the rigid transformation and facial expression parameters are calculated from the detected landmarks, and they are then transferred to a digital avatar to generate the corresponding animation. Considering our facial landmark detection method, because our algorithm has better robustness for images of different face poses, we believe it can help to enhance the performance of facial animations generation.
Face expression analysis
Facial expression recognition is another important application with our robust facial landmark detection method. With the detected facial landmark, the human facial shape and the appearance of features around the key points can be utilized for facial expression analysis. In real-world applications, people tend to move their heads when they make the corresponding expressions. Furthermore, depending on the camera position, facial images can be taken from multiple views. For these reasons, facial expression recognition should be robust to the multiple poses of faces. Depending on our algorithm, which can handle images of faces in different poses robustly, we believe it can help to enhance the performance of facial expression recognition.
Conclusions
In this article, an initialization based on multiple poses for robust facial landmark detection is proposed. Several different poses are set as initializations to estimate face landmarks independently, using a cascade regression method. To pick out the best estimate, they are ranked by probability, calculated based on appearance and shape information in each iteration. An RBM-based face shape model is trained to improve the robustness of the ranking. Finally, experiments using three challenging datasets show that the proposed method performances better than state-of-the-art methods.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This project was funded in part by a scholarship from the China Scholarship Council, from whom we would like to acknowledge support. Furthermore, this work was sponsored by the National Natural Science Foundation of China (Grant no. 61401117). In addition, Yongqiang Li is partly supported by the National Natural Science Foundation of China (no. 61402129) and Postdoctoral Foundation Projects (nos. LBH-Z14090 and 2015M571417).