
Abstract
This work presents a novel method for addressing the bin picking problem with two significant contributions. First, we propose a specialized generator for synthetic labelled data tailored for bin picking applications. This synthetic data facilitates the training of deep learning models for detecting objects. Second, a parallel workflow to optimize cycle time is presented; this workflow leverages the robot’s motion to perform all cognitive computations. Experimental results demonstrate that models trained exclusively on virtual data achieve comparable performance when applied to real-world scenarios. Additionally, the proposed workflow effectively optimizes cycle time by ensuring uninterrupted robot movement throughout the process.
Introduction
In the current industrial context, robotics and artificial intelligence have risen as key enablers for process automation. The automation of industrial tasks brings several advantages to manufacturers, since physically demanding or dangerous tasks can be performed by robots instead of humans. This allows the reallocation of human resources to more suitable tasks while reducing costs and increasing productivity and competitiveness. In this scenario, industrial bin picking plays a central role in factory automation. 1
Bin picking is the process of unloading a container full of unordered pieces and placing them in a more controlled way. Despite its simple definition, bin picking poses a series of challenges that are non-trivial to tackle, such as piece localization, grasping pose computation, collision-free path planning, and motion control. 2 Bin picking has been a long research field in the robotics community, where we can distinguish two different research scenarios. On the one hand, academics focus on developing general algorithms for picking unknown daily-life light objects with general end effectors in uncontrolled environments. These developments are normally validated in laboratory prototypes, which implies a technology readiness level (TRL) of 3 or 4. On the other hand, industrial practitioners usually work with known pieces and custom-designed end effectors in more controlled contexts. Systems are validated in factory scenarios where the requirements are far more restrictive in terms of picking rate and cycle time. They target a TRL between 7 and 9.
The application of deep learning (DL) models is common in various steps involved in bin picking. However, the effectiveness of these models relies on large amounts of data, which are not always readily available. Additionally, the overall execution cycle is typically extended due to the high computational demands of the associated processes. The main contributions of this work are twofold. First, a generator of photorealistic synthetic labelled images, with a focus on industrial bin picking applications, is presented. This enables training vision models while avoiding tedious labelling tasks and transferring them to the real world. Second, a parallel picking workflow focused on cycle time minimization, which is agnostic to hardware and use case, is introduced. We believe this method could be generalized to other bin picking scenarios. To the best of our knowledge, this is a unique work that has been tested in a complete industrial environment. This work aims to bridge the gap between academia and industry by presenting a method that adapts academic algorithms to an industrial scenario.
Related work
The most singular and challenging phase of bin picking solutions compared with other industrial applications is the grasping pose calculation from visual data. A successful grasping pose is defined as a reachable and collision-free joint configuration of the robot that allows picking and retrieving an object. Kleeberger et al. 3 and Cordeiro et al. 4 review the existing literature on grasping point calculations and differentiate between model-based and model-free methods. On the one hand, model-based methods require the model of the object to be picked, and normally, they are composed of two steps: object localization and grasp point determination. On the other hand, model-free methods are data-driven and do not require a predefined model. These methods either deduce the grasping point directly from visual data in a single step or may involve additional steps, such as object localization, before determining the grasping point.
In recent years, DL models have been used for object localization, as Lee et al. 5 and Zhuang et al. 6 and for direct grasp point estimation, such as Zeng et al., 7 Zhou et al., 8 and Mahler et al. 9 Training these models requires a significant amount of labelled data, which can be challenging to obtain. A simple approach is to label the images manually, as in Zeng et al., 10 but it is a tedious process and requires a lot of time and effort. Other approaches generate grasping labels in a self-supervised manner, as in Pinto and Gupta 11 and Levine et al., 12 where the system infers the labels by trial and error; they still require a considerable amount of time.
A growing trend in data generation is the utilization of simulation environments to create labelled datasets. The primary advantage of this approach is that it provides a faster, safer, and less tedious method of obtaining labelled data. However, it has its drawbacks, such as the requirement for computer-aided design (CAD) models of the objects and the fact that simulated data is not a perfect replica of real-world data due to the simulation–reality gap.
Li et al. 13 generate a synthetic dataset for industrial bin picking using Blender and simulating the physical drop of the pieces with the Bullet (https://www.blender.org/). engine (https://pybullet.org/wordpress/). They increase realism with two adaptations. Firstly, they accommodate the background of the simulation to the real background. Secondly, they perform a grid search to choose the material properties, comparing real and virtual images and choosing the set of material properties with the highest similarity score. Selvam et al. 14 present a photorealistic synthetic dataset focused on bin picking based on Stillleben, 15 which is a rendering shader pipeline based on the PhysX simulator (https://github.com/NVIDIA-Omniverse/PhysX). It uses image-based lighting to add realistic illumination effects. They use objects of the YCB-Video dataset 16 that are highly textured daily-life objects. Kim et al. 17 proposed a method using a physics simulator to generate synthetic datasets with three-dimensional (3D) CAD models and automatic annotations for segmentation and pose estimation.
Many of the works devoted to bin picking address textured daily-life objects as they rely on popular benchmark datasets such as LINEMODE 18 and YCB-Video. 16 However, in industrial contexts, pieces are usually metallic, rigid, reflective, textureless, and they are often found in a more cluttered manner, leading to occlusions. There are certain datasets which focus on industrial pieces such as Hodan et al. 19 and Drost et al., 20 they capture real images employing high-cost sensors similar to real industrial applications, and the ground truth is obtained by an initial manual labelling followed by an automatic refinement. Yang et al. 21 create a dataset of very reflective industrial objects with high-cost sensors, where captures are taken before and after applying an anti-reflective spray. Depth maps of sprayed pieces present much less noise and fewer missing values. Labels are annotated manually, and visibility scores are obtained by rendering the segmentation mask of the object pose via perspective projection and comparing it with the visible pixels. Kleeberger et al. 22 expand the Sileane dataset 23 with some industrial parts composing a bin picking dataset of virtual and real images, two-dimensional (2D) and 3D data, labels, and visibility scores that are obtained automatically by comparing subsequent images. Virtual images are obtained in Coppelia robotics simulator (https://www.coppeliarobotics.com/), throwing pieces into the container one by one and taking captures and segmentation masks after each drop. Visibility scores of the objects are calculated by computing visible pixels in subsequent captures and dividing by the number of visible pixels in the first capture. For real images, the process is reversed, with a bin full of pieces, pieces are withdrawn one by one, and the mask is extracted by Iterative Closest Point refinement on the subtracted point cloud. The visibility threshold for real images is computed by rebuilding each real-world scene in simulation.
Compared with existing methods, we propose a generator of synthetic data designed for training vision models to operate on specific industrial components. In this work, we demonstrate that models trained purely on our virtually generated images can be transferred to real scenarios. Our approach is primarily focused on bin picking scenarios, but it has the potential to be extended to other applications.
As well as the grasping point estimation, there are other steps in the picking process that can benefit from an increase in performance. Within the industrial context, cycle time is an important factor. Several studies, such as Iversen and Ellekilde, 24 Ichnowski et al., 25 and Ellekilde and Petersen 26 aim to minimize cycle time from a path planning perspective, exploring the trade-off between planning time and motion time. However, little work has been done in improving the picking cycle by optimizing the picking logic. Several industrial works, such as Le and Lin, 27 Martinez et al., 28 and Kozák, 29 present a sequential workflow of capturing, processing, planning, and motion phases. In contrast with these works, we propose a picking workflow where some of these phases are executed in parallel, improving cycle time without affecting picking performance.
Problem formulation
The problem addressed in this work is a real industrial application that takes place in a manufacturing company in the automotive sector. The objective is to unload the pieces from the container and place them in smaller boxes. The pieces can be placed randomly in the small box as long as they are distributed evenly throughout the box. Once these smaller boxes are filled, they are dispatched through a conveyor belt. The container is deposited in the picking station by an automatic guided vehicle; therefore, there are small displacements between containers. The container enters the station with 1500 pieces. Pieces are metallic, with asymmetrical and non-convex shapes with certain protrusions and flat surfaces, see Figure 1(a) and (b).
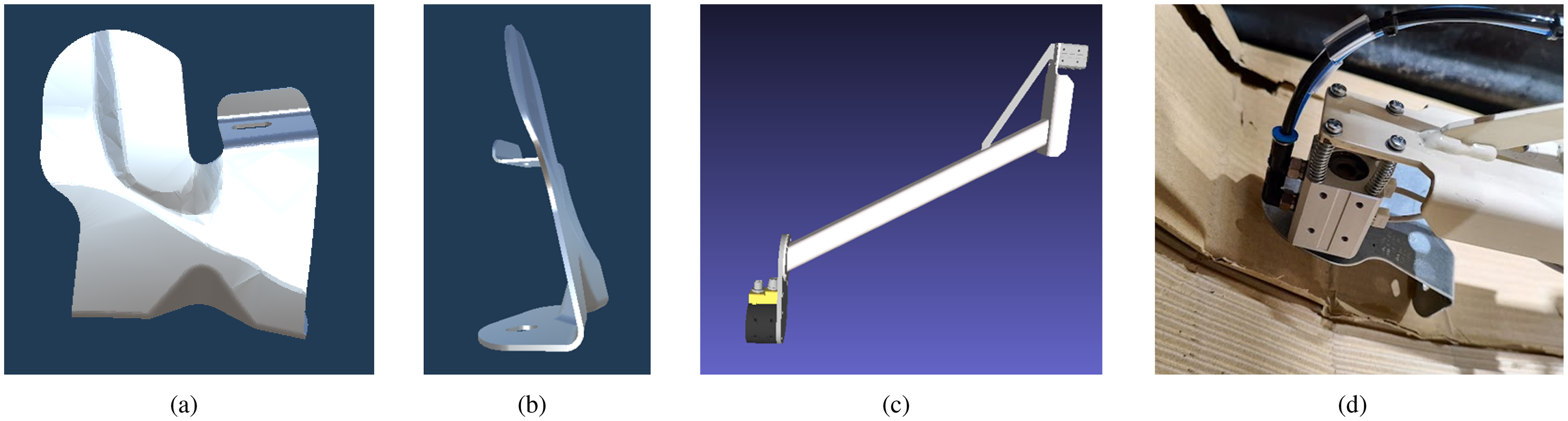
Designed tool and piece involved in the bin picking application. (a) Front view of the simulated piece. (b) Lateral view of the simulated piece. (c) Digital model of the tool. (d) Real model of the tool while picking a piece, four strings have been added to increase the tool compliance and allow applying pressure on the piece.
Application configuration
The selected robot for the task is a KUKA kr10r1100-2, an industrial robot arm with a maximum reachability of 1100 mm and a maximum payload of 10 kg. The tool is a pneumatic magnet, which supposedly has been designed according to the application requirements. It has a set of springs to add compliance in the picking, see Figure 1. The container dimensions are
The vision sensor is an Ensenso X-30 with a 1.6 MP resolution, located at a height of 2.3 m from the floor, facing the container perpendicularly. It is a structured-light system comprising a stereo camera and a texture pattern projector that facilitates point matching and enables 3D reconstruction. The output from these sensors is a 3D map, where each pixel corresponds to a 3D coordinate

Bin picking scenario. (a) Virtual scene used for development. (b) Real scene within an industrial environment.
The robot, along with other hardware components such as conveyors, sensors, and safety devices, is connected to a Beckhoff Programmable Logic Controller (PLC). This PLC is responsible for managing the system’s operations and ensuring compliance with current industry safety standards.
The computations of the proposed work are conducted on an external computer equipped with an i9-13059 processor of 2.2 GHz and 64 GB of RAM, which is connected to the Ensenso and the Beckhoff PLC via Ethernet (Transmission Control Protocol/Internet Protocol). The computed trajectories are sent to the PLC via Beckhoff Automation Device Specification. The PLC is in charge of the robot’s motion as well as sending motion completion notifications.
From the software point of view, the application is based on PickingDK, 2 which is a plugin-based bin picking framework. For developing purposes, the application was validated first on simulation using an extended version of the simulator described in Ojer et al. 30
Challenges
This case presents several significant challenges. The first challenge involves accurately locating the pieces that can be picked up. The random placement of the pieces within the container results in numerous occlusions, complicating their identification. Additionally, the cycle time of the process should be as short as possible and kept below 12 s. Finally, a particularly complex challenge arises from the non-convex shape of the pieces, coupled with their protrusions (as illustrated in Figure 1(b)). These features can cause the pieces to become tightly entangled, significantly hindering reliable and efficient extraction.
Cognition phase
The cognition phase involves interpreting the scene to gain a comprehensive understanding of the environment and making informed decisions based on that understanding. Its objective is to determine a set of collision-free trajectories that enable piece picking. This phase can be divided into two main processes, perception and path planning. Perception focuses on the understanding aspect, as its purpose is to detect target poses for object grasping, using information from the vision sensor. In contrast, path planning addresses the decision-making aspect by generating safe robot trajectories towards the identified grasping positions.
Perception
The proposed perception process involves two steps to determine the grasp poses: (1) instance segmentation for object localization; (2) grasping pose estimation from the segmented instances. This phase is fed with 3D and 2D information, which is provided by the selected sensor.
Many industrial components have textureless, metallic, reflective materials or matte black surfaces, which can lead to noisy outputs in 3D map reconstruction. This is particularly true for the target pieces in this case. Due to these challenges and the current limitations of DL techniques for 3D data, the proposed object localization performs instance segmentation on the 2D image.
Synthetic data generation
In order to train the instance segmentation models, there is a need for annotated data, which is costly and tedious to obtain. Therefore, the proposed approach generates synthetic labelled data in simulation in an effortless way.
The proposed data generator consists of a simulation of the pieces in the container and the sensor element of the scene. The simulated sensor acquires the 2D image along with the instance labels for each pixel in the image, as well as instance information such as instance ID and visibility scores. Our generator is based on Unity (https://unity.com/) and its perception package for automatic labelling. 31 Visibility scores are computed as the ratio of the visible pixel count and the estimated number of pixels that would represent the object if it were fully visible. This estimation is obtained from the object’s actual surface area and distance from the camera.
Domain randomization techniques are used to enhance robustness and generalization. The randomization extent is from the lighting properties such as intensity, temperature, direction, and from the material properties such as smoothness, reflectivity, and in some cases, colour. To generate images that closely resemble the real setup, a grid search is performed on lighting parameters to identify the configuration that maximizes the histogram correlation similarity measure with a reference image. The resulting parameter values are then used as the centre of a uniform distribution for randomization. The container model is also randomized from a predefined set of container models of the same size.
The data generation process is done as follows. Initially,

Synthetic generated images emulating a bin picking process where randomization is applied.
Additionally, once a dataset is generated, the proposed generator provides data augmentation techniques such as scaling, rotating, flipping, blurring, colour manipulation, etc., as well as some filtering options for the instance masks based on parameters such as mask area, aspect ratio, and visibility. Among these, the visibility score is particularly important since the less occluded an object is, the easier it should be to grasp.
Setting a higher visibility score threshold increases the likelihood of selecting less occluded objects. However, this can result in a smaller number of pieces being included in the dataset. Therefore, the choice of visibility threshold requires careful consideration, as it directly impacts the composition of the generated dataset. Therefore, the visibility threshold is a parameter that has to be carefully chosen, as it directly impacts the generated dataset, as shown in Figure 4.

Synthetic generated image and instance mask with different visibility threshold: (a) red–green–blue (RGB) generated images; (b) instance masks without visibility threshold; (c) with visibility threshold 0.7, and (d) with visibility threshold 0.97.
Once a labelled dataset is created, it can be used to train DL instance segmentation models. These models generate pixel-wise masks for each detected instance of the pieces, which allows a precise localization of the pieces.
Grasping pose estimation
The previous segmented pixel-wise mask in the 2D image can be projected onto the 3D map, achieving spatial segmentation of the piece.
Since the piece presents a flat metallic surface and the tool is a magnet, the target grasping point corresponds to the most centred point of the visible planar surface of the piece. This position is robust against system positioning errors, provides greater balance, and minimizes the bending of the piece.
With the previously trained instance segmentation model, the objects are localized in the 2D image. These pixel-wise masks are projected to the 3D map to obtain spatial masks. The grasping point estimation algorithm segments the planar surface from the spatial masks through plane fitting. Some candidates may be discarded based on the ratio of points that fit the plane. From the planar surface, a distance transform is applied to determine the distance from the edges, and the point with the greatest distance is selected for the grasping, see Figure 5. The grasping direction is computed as the normal of the fitted plane. Certain candidates are filtered according to the angle between the normal and the world
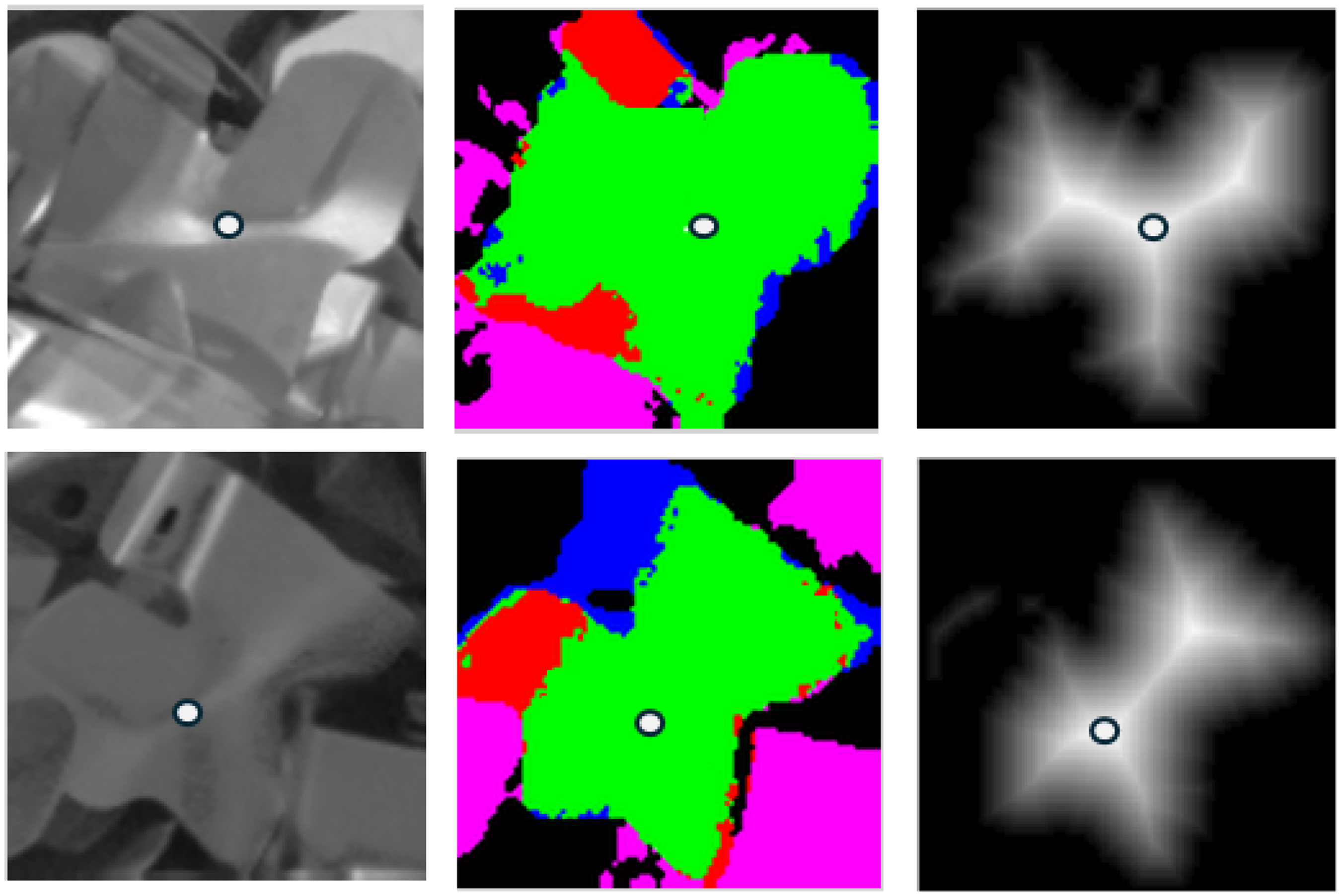
Grasping point estimation. The left column shows the two-dimensional (2D) image. The middle column represents the segmentation of the planar section. In this segmentation, green indicates the planar surface, red denotes points above the computed plane, blue represents points below the plane, and pink indicates points not belonging to the piece mask. The right column displays the distance transform applied to the edges of the planar region.
Path planning
To facilitate and accelerate path planning, it is recommended to establish predefined intermediate waypoints and collision-free trajectories. Therefore, the path planning task is constrained only to the variable poses of the process, such as the grasping pose.
To reduce computational cost, a collision model of the scene was created using simplified shapes, specifically convex shapes for static elements. Since the container’s position may vary slightly, it is detected using a vision sensor. Walls are added to the collision model as cuboids. All models incorporate a safety margin to account for potential robot positioning errors.
From the computed point–normal pairs, a collision-free joint configuration of the robot must be determined. Thus, different rotations around the
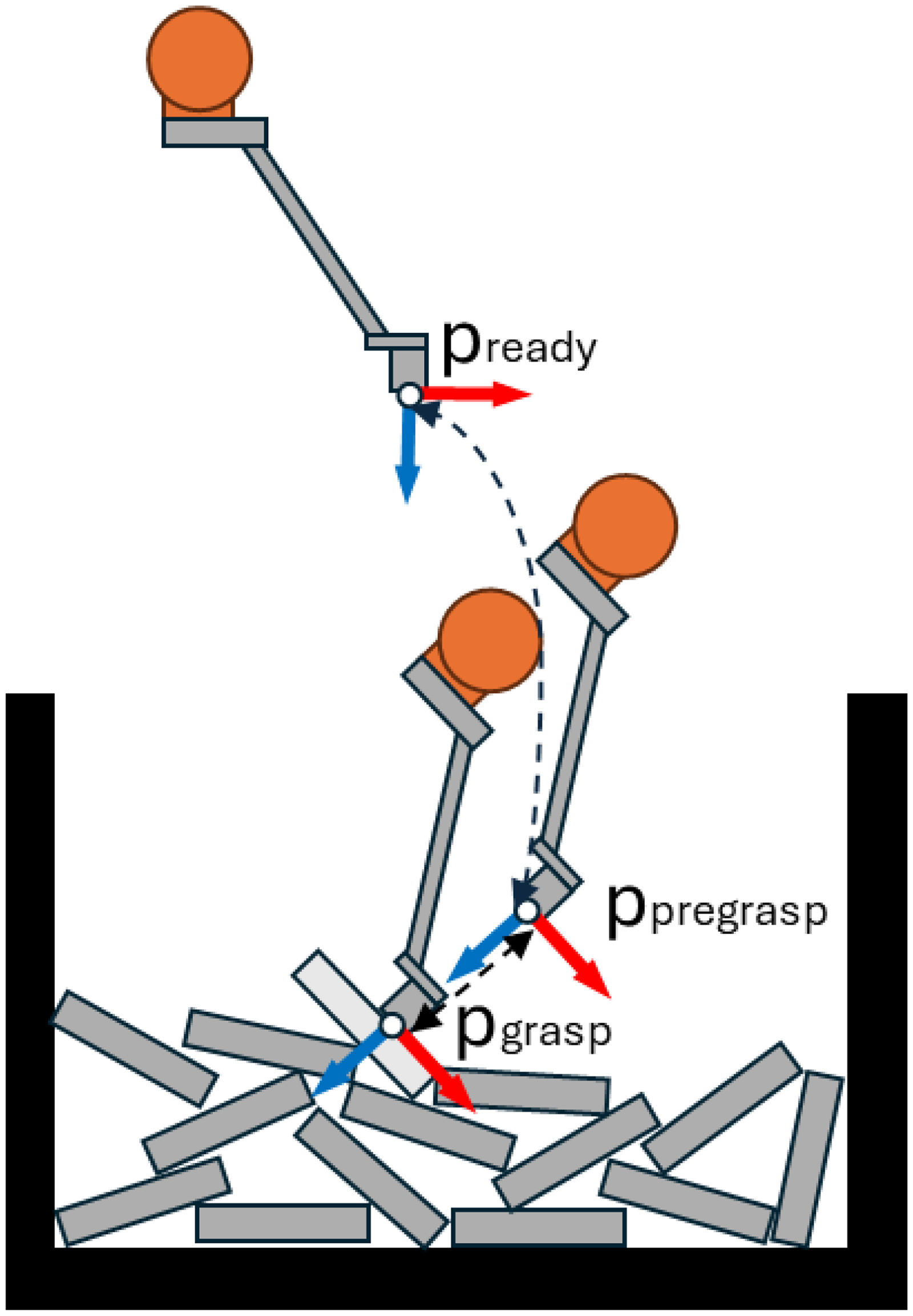
Waypoints to plan for.
Workflow optimization
This section presents the parallel picking workflow, which is related to the management of the different phases of the process, such as the cognition phase and motion execution. Its goal is to organize the process effectively and minimize cycle time.
Parallel workflow
This work proposes a parallel workflow to optimize the cycle time. The idea is to leverage the robot’s motion execution to simultaneously perform the perception and planning tasks. This approach works under the assumption that removing a piece from the container just affects the nearby region, but more distant regions remain unaltered. This assumption holds true for the majority of bin picking cases.
The proposed workflow consists of two parallel threads named the action thread and cognition thread. The action thread is responsible for managing the hardware. It captures visual information from the sensor and executes robot motions. The cognition thread handles cognitive tasks. It performs the perception phase to extract several grasping pose candidates, sorts them according to specific criteria, and computes the grasping trajectories. Path planning is performed starting from higher priority candidates, and if the trajectories are feasible, they are added to a database. Then, the neighbour candidates are removed. Candidates are removed if the distance to the already planned candidates is less than a threshold
This process is repeated iteratively until certain conditions are met, either there are no candidates left or trajectories for
The action thread captures data only when the capture flag is active, not during every iteration. After each robot motion execution, the action thread evaluates the size of the trajectory database. When the database size decreases to one, the action thread schedules the capture for the next cycle, activating the capture flag. Consequently, during the next cycle, the action thread captures data and immediately executes the remaining trajectory in the database. Meanwhile, the cognition thread processes the recently acquired visual information and computes the subsequent trajectories. This workflow is illustrated in Figure 7.
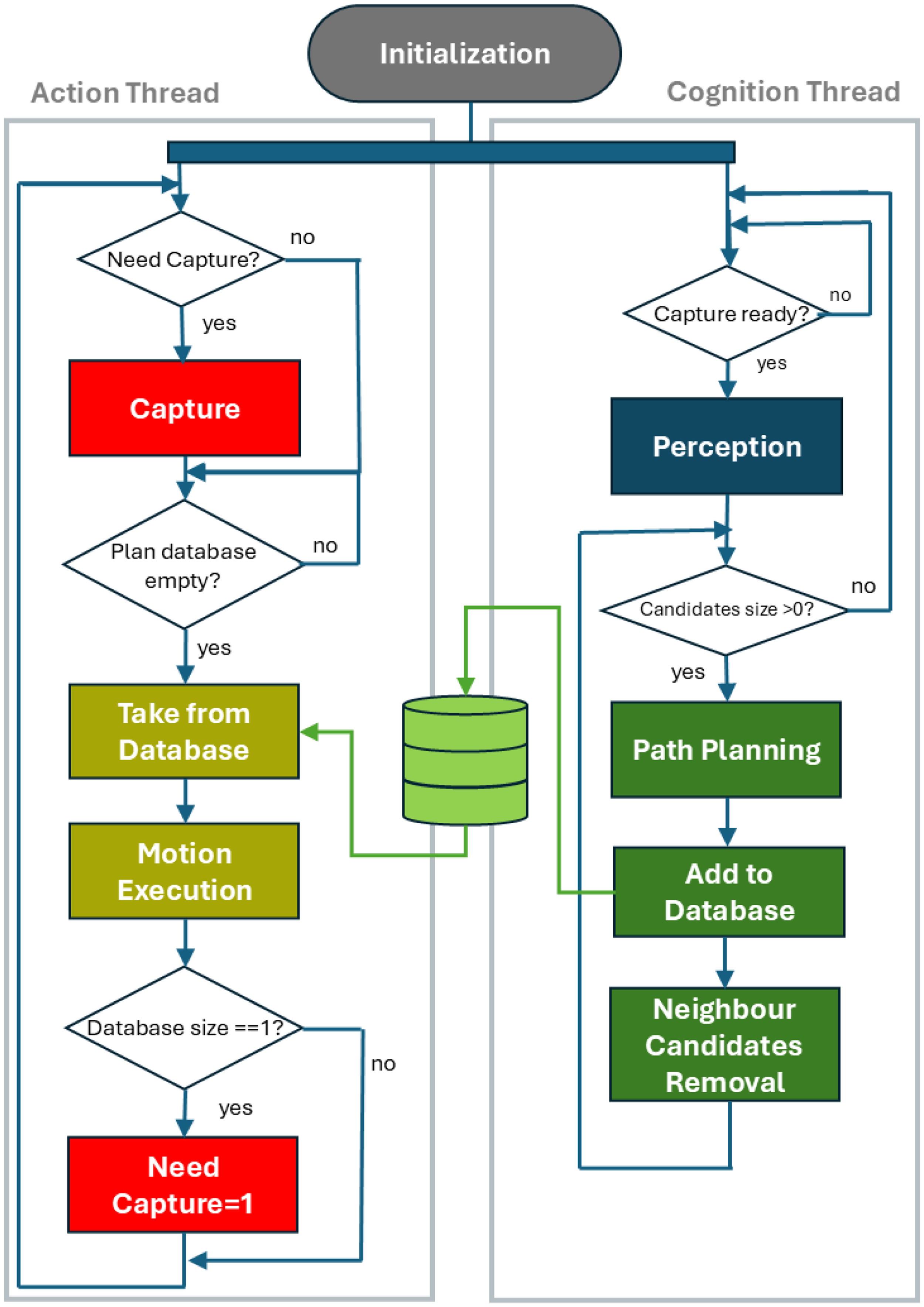
Proposed parallel workflow diagram.
Experiment 1: Evaluation of synthetic trained models
This experiment aims to validate the effectiveness of the proposed data generation scheme by evaluating whether instance segmentation models trained exclusively on synthetic data can achieve satisfactory performance on real-world data.
For this experiment, we use two different types of pieces. Piece A, the one mentioned in the problem formulation section, is located chaotically inside the container, see Figure 8(a). Piece B is a black, flat metal component with a Pacman-like shape. It is larger than piece A and is arranged in the container in nine stacked columns, see Figure 8(b)

Pieces used in Experiment 1, piece A is (a) and piece B is (b).
We fine-tuned two widely popular instance segmentation models, such as YOLOv5s-seg 33 and Mask R-CNN 34 with a backbone ResNet50, both of which are pretrained with Common Objects in Context. For YOLOv5-Seg, the recommended hyperparameters were used for the stochastic gradient descent (SGD) optimizer, including an initial learning rate of 0.01 with cosine decay. A batch size of 12 and a maximum of 100 epochs were chosen to adapt to our computational resources. Similarly, for Mask R-CNN, the default/recommended parameters were applied: SGD was selected as the optimizer, with an initial learning rate of 0.02, a warm-up, and a multistep decay learning rate scheduler. A batch size of eight and a maximum of 100 epochs were chosen.
Ground-truth masks of the real images are manually labelled by an expert. It is important to note that the manual labelling is only used to obtain the ground truth for the evaluation phase, but the models are fine-tuned using pure synthetic data from the previously explained generator. The intersection over union (IoU) metric is used for model evaluation.
Results on chaotic scenario
In this case, where pieces are randomly placed, manual labelling could be quite subjective since the operator cannot ensure which piece can be retrieved visually. Therefore, two labelling strategies are followed. The first focused on pieces with complete visibility that were theoretically easier to pick, while the second adopted more relaxed constraints, including many partially visible pieces. To consider a correct match between ground truth and predicted instances, an IoU threshold of 0.8 is fixed since detection accuracy is important due to the posterior picking process.
In this case, the manual labelling process consists of two steps. First, an expert manually selects the bounding boxes. These bounding boxes are then fed into the segment-anything-model 35 to generate the segmentation masks. Then, the expert reviews the generated masks, discarding defective ones.
A dataset is generated with

Instance segmentation on the real images with YOLOv5s-Seg model; (a): manually labelled strict masks, (b): model trained with 0.7 visibility threshold, (c): model trained with 0.9 visibility threshold, (d): model trained with 0.97 visibility threshold.
Results on the relaxed dataset.

Results on the restricted dataset.

The tables indicate that models with higher visibility thresholds demonstrate higher precision but lower recall. This was somewhat expected since the number of detections is expected to be lower. At the same time, precision over the relaxed dataset is higher, while recall is greater for the strict dataset. A higher recall in the restricted dataset indicates that most retrievable pieces are detected, though some may not be truly graspable. In contrast, the higher precision in the relaxed dataset means that many of the detected pieces are indeed pickable, but not all pickable pieces are detected. These results suggest that the generated dataset lies in between strict and relaxed assessments of the expert. The choice of the appropriate visibility threshold will depend on the impact of false positives and false negatives in the application. Overall, YOLOv5s-seg outperforms Mask R-CNN across all evaluated metrics.
Results stacked scenario
In the case of piece B, a training dataset is generated with

Left column: generated synthetic images. Middle column: all generated labels. Right column: filtered labels with visibility threshold 0.7.
These pieces are intended for a controlled drop, which requires the generated masks to be highly precise. While the objects are easily identifiable, the main challenge lies in obtaining an accurate mask. As a result, the evaluation metric will focus on detection accuracy with a matching IoU threshold of 0.9. The labelling process for the test set is fully manual, with the operator drawing the ground-truth mask.
The obtained metrics are shown in Table 3. Again, the YOLOv5s-seg model offers better performance, but both models achieve acceptable results. The detection is quite accurate as it can discriminate the top pieces from the stack, see Figure 11 for detection results on real images.

Computed masks of a real image (piece 2) with YOLOv5s-seg model.
Results on piece B.

As a result, it can be observed that both trained models deliver acceptable performance when trained with the synthetic data generated by the proposed generator. In this case, the YOLOv5s-seg model outperforms in every metric.
Experiment 2: Evaluation on a real bin picking scenario
In this experiment, the main purpose is to evaluate the effectiveness of the proposed picking workflow in a real industrial bin picking application. While the previous experiment focused on independently validating the localization models, the current use case integrates these models into a complete operational pipeline. Thus, a secondary objective is to analyse how the interconnection between the different modules of the bin picking application affects the overall performance.
According to the previous results, the selected instance segmentation model is YOLOv5-seg. Model inference takes place in the cloud as a separate service called during the perception phase. From the detected grasping poses, our strategy is to prioritize candidates with the greatest relative height in the robot’s coordinate system, based on the intuition that these candidates are likely to be on top of the pile, thus offering greater clearance and facilitating grasping, see Figure 12. In this experiment, the maximum number of picked pieces per photo,

Grasping point candidates marked as targets, along with their segmentation mask. Target colour indicates grasping priority, red represents higher priority, and white represents lower priority. The green lines denote the container limits.
Figure 12 displays detected grasp candidates from an image.
The drop pose for the pieces is defined by a joint configuration where the tool is centred directly above the centre of the output box. During each iteration, random displacements are applied in the
Based on the results obtained in the previous section, a decision was made to initiate the picking process using a model trained with a high visibility threshold (0.9). This model focuses on pieces that appear easier to detect and grasp. As overall piece visibility decreases, the model’s detection performance may decrease until very few or no pieces are detected. When the number of detections from a single photo drops below a predefined value, the model is switched to one trained with a lower visibility threshold (0.7). This strategy aims to prioritize easier grasps at the beginning of the process while maintaining a consistent number of detections when pieces are less visible.
Results on cycle time
During the picking process, the start and end times of each step of the picking workflow were recorded, as well as the total cycle time. In this experiment, two other picking workflows were compared with the proposed one. Workflow 1 is the traditional picking workflow used in Le and Lin, 27 where for each capture, a single piece is retrieved from the bin. In Workflow 2, for each capture, multiple pieces are retrieved, as in Martinez et al. 28 and Kozák. 29 Workflow 3 corresponds to our proposal that enhances Workflow 2 through parallel computation between steps. For each workflow, a total of 100 cycles were performed. Phase and cycle average times are summarized in Table 4, and phase time distributions are shown in Figure 13.

Visual phase cycle times between different picking workflows. Workflow 1 (a), Workflow 2 (b), and Workflow 3 (c). Vertical purple lines denote the cycle ending time.
Summary of cycle times of the different approaches.

For each workflow, a total of 100 cycles are performed. Phase and cycle average times are summarized in Table 4. Phase time distributions are shown in Figure 13.
The fastest cycle time is achieved by the proposed approach, with a reduction of up to 42% with respect to Workflow 1 and of about 30% relative to Workflow 2. However, our method relies on the assumption that picking objects only has a local effect on the scene, which holds true for Workflow 2 and Workflow 3. Workflow 1 does not have this limitation, as it captures images for every picking. Nevertheless, this assumption applies to the vast majority of real-world cases.
The bottleneck of the proposed method lies in the action thread, see Figure 13(c). Thus, future improvements in cycle time should address the motion phase. In our work, the motion phase was managed by the PLC, and it was beyond our scope. It is observed that the capture time from our proposed method takes a longer time. A reason could be that the use of threads decreases the performance of the libraries used to acquire the data. However, the action thread will always be constrained by the mechanical limits of the system.
Results on picking accuracy
In this experiment, we let the system run for a total of 663 cycles using Workflow 3, while manually annotating whether each piece was actually retrieved or not. The obtained results are expressed as a picking success rate within a moving average of size 50, see Figure 14. During the initial steps of the container unloading process, the success rate is around 90%, but it decreases as the container gets emptier. The overall average success rate is around 75%.
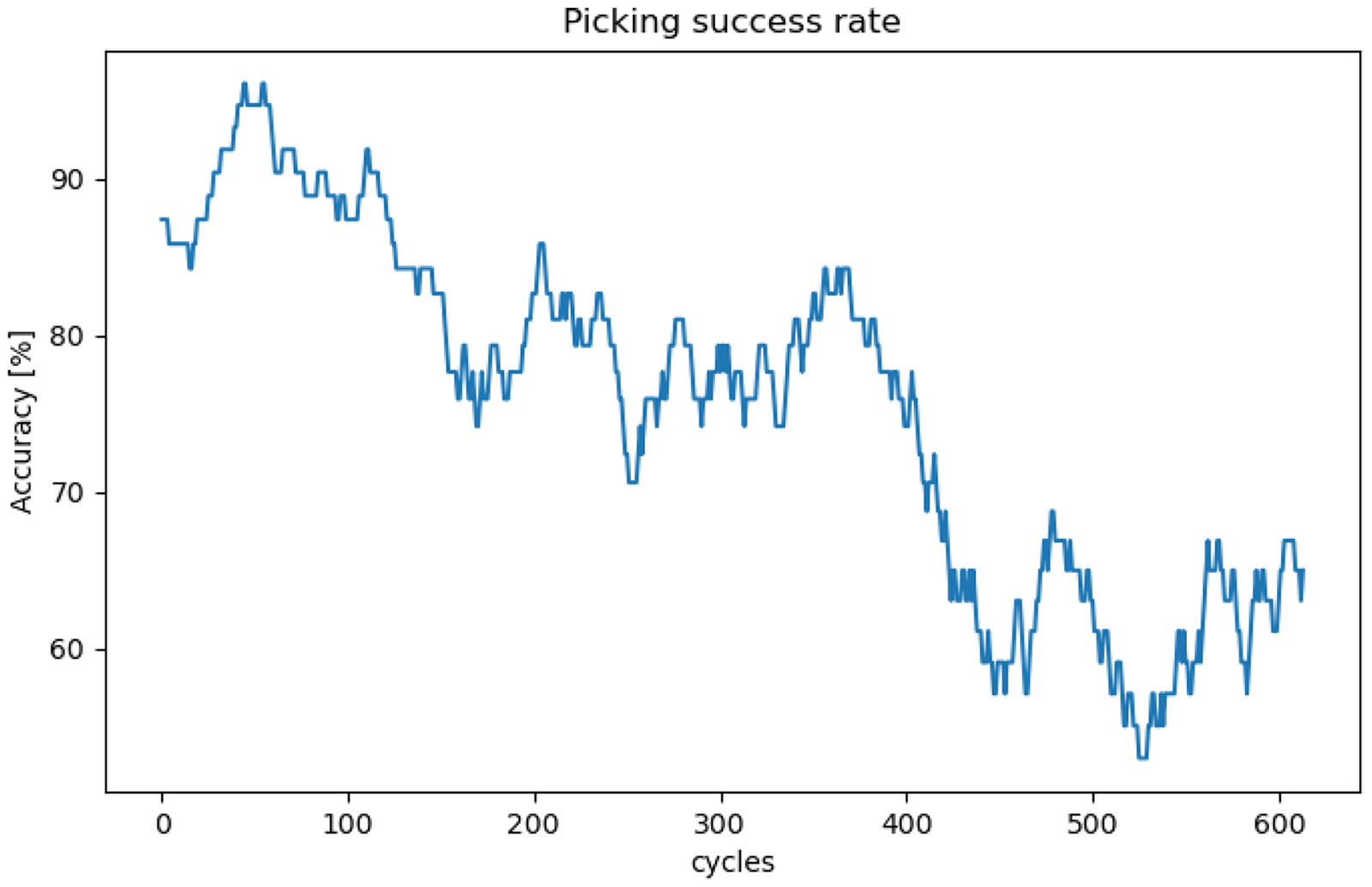
Moving average of the picking success rate.
The decrease in the success rate is attributed to the pieces becoming intertwined. When a piece is stuck, even if the system positions the magnet correctly and attaches to the piece, the retraction trajectory may cause another piece to obstruct the movement, leading to the piece falling. At the beginning of the picking process, the top parts are looser and more accessible. However, the weight of these pieces is supported by the pieces underneath, and this pressure leads them to interlock, making successful picking more difficult.
In this particular case, determining in advance which pieces are blocked by others is challenging because the blocked part may not be visible to the sensor. We observed that some pieces with high visibility, which presumably seem pickable, might actually be trapped, while others with lower visibility that appear more difficult to pick may not be obstructed, see Figure 15 for some examples.

Candidates with slight occlusion, where it is difficult to determine if the picking will be successful or not. The top row corresponds to successful retrievals, whereas the bottom row corresponds to failed retrievals.
The proposed grasping selection strategy does not take into account previously attempted candidates, and therefore, when a candidate with a high priority is blocked, it will cause a failure on the next attempts, as the position of the candidate remains. Thus, multiple picking failures were due to the repetition of blocked candidates. However, there were some cases where, after several trials, the system was able to successfully unblock and pick the target piece. This might suggest that higher magnetic power could improve performance. Additional failures occurred due to collisions of the tool with nearby pieces during the approach movement. These collisions sometimes caused neighbouring pieces to shift, altering the orientation of the target piece and preventing full contact with the magnet. Redesigning the tool to ensure that only the magnet part protrudes further could potentially mitigate these collisions.
A video showing the bin picking application can be found in this link (Video: https://vicomtech.box.com/shared/static/ahogug6et30cqnzh2sxxso8jp80gh9ut).
Discussion
The performed experiments validated the two primary contributions of this work. First, a successful transfer learning of instance segmentation models using purely synthetic data was demonstrated and validated in a real-world scenario. The proposed models showed satisfactory performance on two different types of pieces. Second, the proposed parallel workflow significantly reduces cycle times compared to traditional approaches, which provides a crucial advantage in industrial bin picking applications.
However, the overall system’s success rate was limited by the specific complexities of this bin picking application. In our experiments, piece entanglement hindered successful retrieval, even with accurate grasping. This highlights the complex interplay between piece morphology, grasping strategy, and physical system limitations.
Diagnosing errors in a holistic bin picking system remains challenging. Nevertheless, the experiments provided valuable insights and suggested several potential improvements. For example, the grasp selection strategy could be revised to account for previously attempted pieces, either through heuristic methods or learned policies. Additionally, redesigning the tool in order to make the magnet more prominent or increasing its magnetic power could help resolve blockages caused by certain pieces.
Notwithstanding, it is very difficult to diagnose a complete bin picking application since it performs as a holistic system. For example, in the first experiment, the ground-truth masks of the pickable pieces were labelled manually by an expert operator. Expert knowledge is limited as it can label a piece that cannot possibly be picked or vice versa. However, when isolating the vision task from the rest of the application, it may be appropriate to identify certain pieces based on their visibility alone. Then, posterior phases such as grasping pose estimation or the grasping selection strategy should be in charge of deciding whether to attempt to pick each identified piece.
A valid ground truth for the complete system can be extracted when a piece is correctly retrieved from the container, but when a failure occurs, identifying the specific component responsible for the error is challenging. What remains clear is that refining the bin picking process requires intensive testing on the final setup. In Experiment 2, the localization, grasp pose estimation, and path planning functionalities operated as intended, resulting in the robot successfully picking the piece. However, errors during the retrieval motion suggest a potential limitation in the proposed grasp selection strategy. To address this, intelligent selection strategies that incorporate information from previous grasp attempts could offer an improvement over heuristic approaches. However, validating these strategies could be a tedious process.
As mentioned, obtaining feedback on the operation’s outcome can be highly beneficial. From a software perspective, image comparison between consecutive captures could potentially serve as a feedback mechanism. However, through experimentation, we discovered that this approach is more challenging than initially anticipated. Specifically, when the system successfully grasps the piece but fails during the withdrawal motion, the surrounding area is altered, and the target piece shifts relative to the previous image. In an industrial setting, this feedback system must be highly robust. Therefore, alternative solutions may involve hardware enhancements, such as incorporating presence or force sensors into the tool or adding weight sensors to the output conveyor.
The selection of parameters
Despite these challenges, the proposed methods demonstrate the potential for generalization to other bin picking applications. The proposed data generator can be used to generate synthetic data, facilitating training for object detection and instance segmentation models. Moreover, the parallel workflow is hardware-agnostic and suitable for a wide range of applications.
Conclusion and future work
In this work, we have presented a method to solve a bin picking problem. The development of the industrial application demonstrated that the system design helps bridge the gap between academic proposals and industry needs, particularly in (but not limited to) bin picking scenarios. This method is characterized by two main contributions.
First, a synthetic data generator is proposed. This generator generates photorealistic labelled data, which can later be used to train DL models for the instance segmentation task. In the first experiment, we demonstrate that models trained purely on the generated synthetic data can effectively transfer to real-world data in the bin picking context.
Secondly, a parallel workflow is proposed. This workflow leverages the robot motion execution to perform perception and planning tasks for the upcoming cycles. The experiment shows that the total cycle time is minimized to the sensor capture and robot movement times. Therefore, our method optimized the cognitive tasks, and the resultant cycle time is bounded by the hardware behaviour. Besides, this parallel workflow is agnostic to the hardware and the use case. Therefore, it can be generalized to other bin picking applications.
Our future work will focus on enhancing picking effectiveness through self-improvement. By incorporating real-time feedback on system performance, the system could autonomously learn from its errors and update its policies during the production process. This approach holds significant promise for industrial applications, potentially reducing reliance on manual heuristic design and validation periods while maintaining productivity.
Furthermore, implementing a comprehensive data logging system for the bin picking application would be beneficial. This system would record captured images, performed motions, grasping candidates, and grasp outcomes to generate historical data. This data could then be used, for example, to automatically label real-world images for improved model training or to refine the grasping selection strategy based on previous errors.
Another approach to addressing the entanglement problem is to have the robot perform specific motions, such as pushing, pulling, and shaking, to dislodge or separate entangled pieces. However, the correct configuration of these motions presents a significant challenge, as it requires extensive training, potentially with numerous real-world trials or sophisticated simulations, to learn robust and reliable disentanglement strategies across various scenarios.
Supplemental Material
Footnotes
Funding
This work has been carried out under the PTAS program funded by the Government of Spain.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.