
Abstract
Infrared object detection plays a key role in tasks such as autonomous robot navigation, industrial inspection, and search and rescue. However, the small gray-scale difference between the object and the background region in the infrared grayscale image and the single gray-scale information lead to the blurring of the semantic information of the image, which makes the robot unable to detect the object effectively. To address the above problems, this paper proposes a robot visual infrared object detection (MFDTIA-Detection) based on multiple focus diffusion and task interaction alignment. The feature extraction module adopts a dual-stream fusion structure in the backbone network, which combines the local feature extraction of CNN with the global feature modeling of transformer. The task-aligned dynamic detection header enhances inter-task interaction by sharing convolutional and task-aligned structures, exploiting task interaction features to optimize detection accuracy while reducing the number of parameters to accommodate resource-constrained devices. Experimental results on public datasets show that the model in this paper improves precision by 1.3%, recall by 1%, mAP50 by 0.6%, and mAP50-95 by 1.4%.
Introduction
Computer vision, as an important field of artificial intelligence, is widely concerned by scholars at home and abroad. Among them, the object detection task aims to identify object categories and accurately locate their positions. Deep learning-driven object detection algorithms are widely used in autonomous driving, such as pedestrian detection, traffic sign recognition, and environmental monitoring. While deep learning-driven detectors perform well in visible-light scenarios such as autonomous driving, 1 they face serious challenges in low-light conditions where RGB sensors fail. This limitation highlights the unique value of infrared imaging—its stability under varying light conditions makes it a reliable performer in navigation, industrial inspection, and search and rescue missions.2–4 However, three intrinsic challenges that hinder infrared detection are: low grey scale contrast between object and background, sparse texture compared to visible light data and semantic ambiguity in inhomogeneous illumination.
The comparison between visible and infrared cameras in terms of imaging quality reveals significant differences. Visible light has an advantage when it comes to capturing texture and detail, allowing for clearer classification and localization of objects. In contrast, object detection in infrared images can be more challenging. For instance, in the presence of a strong light source, as shown in Figure 1(a), the background in the infrared image becomes more visible due to interference, but the grey scale difference in the area of strong light is smaller. In Figure 1(b), the vehicle in the distance is more distinguishable in the visible light image, while the texture and boundaries of the vehicle in the infrared image are harder to discern. Additionally, under low light conditions, as depicted in Figure 1(c), the infrared image provides clearer imaging. These observations highlight both the challenges and the necessity of object detection in infrared images.

Comparison of infrared and visible light images.
Traditional machine learning methods use a sliding window to select candidate regions and extract features, which are subsequently predicted by a classifier, but their feature extraction is complex, computationally intensive, and the recognition efficiency is low, making it difficult to meet the demand for high accuracy and high-speed response in robot detection. For this reason, deep learning-based object detection algorithms have emerged, which are mainly divided into two categories: anchor-based framework (Anchor-based) and anchor-free. Anchor-based algorithms improve recognition accuracy by guiding object position prediction through predefined bounding boxes and can be divided into two-stage and one-stage detection methods. Two-stage object detection algorithms, such as R-CNN, 5 Faster R-CNN, 6 and SPP-Net, 7 are usually divided into two main steps: firstly, generating candidate regions from the input image, and then using a classification network to classify and regress the positions of objects in these regions. In the case of R-CNN, for example, it treats the object detection problem as a classification task in four main phases: region extraction, feature extraction (using CNNs), classification (via SVMs), and location regression. Although R-CNN is highly accurate, it is difficult to meet the demand for real-time detection due to its complex and time-consuming training process. To compensate for this deficiency, single-stage object detection algorithms have emerged. Representative single-stage methods include the YOLO series8–11 and SSD. 12 Among them, the YOLO series, especially YOLOv1, for the first time transforms the object detection task into a regression problem, where a single network performs both category prediction and location estimation in a single stage. Compared with R-CNN, YOLO is more advantageous in terms of speed and generalization ability. The use of the FPN structure to achieve multi-scale prediction greatly improves the detection performance. Compared with the two-stage algorithm, the single-stage object detection algorithm has more obvious advantages in detection speed.
In traditional object detection, neck structures are usually extracted from different levels of features using a feature pyramid network (FPN). However, FPNs are designed with long signal transmission paths, and the information in the lower level features may gradually weaken when passing from the lower level features to the higher level features, resulting in the position information accuracy being affected. In this regard, it has been proposed that PANet 13 is unable to adapt to the object scale of different input images by fusion based on fixed weights and adds a bottom-up path consisting of a small number of layers, which effectively shortens the propagation path of the location information in the low-level features and improves the localization ability of the model. Later, a weighted bidirectional feature pyramid network BiFPN 14 was proposed, which achieves the fusion of multi-scale features by repeating the top-down and bottom-up paths. But they all ignored but neglected the effect of object scale on feature fusion. In addition, Silin Chen et al. proposed Info-FPN, 15 which improves object detection accuracy through multi-level feature fusion. The method includes a lateral connectivity module (PSM), a feature alignment module (FAM), and a semantic encoding module (SEM). Despite its uniqueness in optimizing the feature pyramid and reducing the aliasing effect, the complex spatial and channel transformations of PSM increase the overhead, the template matching mechanism of FAM is limited by the number and quality of templates, and the feature fusion is prone to semantic inconsistencies in scenarios with large semantic variations. Li Z et al. 16 proposed a flow-guided up-sampling module and a multi-feature attention module to improve FPN to alleviate the misalignment between multi-scale features, and this problem is also urgently needed to be solved by many researchers nowadays.
In traditional object detection models, most of them share the same features prior to the classification and localization tasks. However, due to the different goals of classification and localization, there are differences in the spatial locations that they focus on, with classification focusing on salient regions of the object and localization focusing on edge regions. This use of shared features can lead to feature conflict problems between classification and localization tasks, i.e., inaccurate bounding boxes may be generated while obtaining higher classification scores. In this regard, ATSS, 17 PAA, 18 and Fitness NMS 19 have been proposed to assess the quality of localization by adding additional branches, using either the Centerness score or the IoU score between predicted and true boxes. Although these methods can alleviate the feature conflict problem in the localization branch, the feature conflict problem in the classification branch remains unsolved. Later Y Zhang 20 et al. used unsupervised task oriented branching in a single stage detector species to mitigate the variability of semantic content in the image, and S Xu 21 et al. used feature extraction followed by feature alignment, but these benefits are limited and do not involve dynamic alignment of features.
In summary, considering the real-time and accuracy of the object detection algorithm, YOLOv11 without anchor frame is selected as the base network, and the object detection is improved for the restricted information flow of FPN, less size of CNN receptive field and feature interaction problems, and the specific contributions are as follows:
Aiming at the shortcomings of traditional FPN in multi-scale feature fusion, contextual information capture and cross-scale information processing, the multi-feature focused diffusion pyramid network (MFADN) is proposed. By introducing the MSFF module and FDM mechanism, this method ensures that features at each scale can contain more contextual information and enhance the perception in complex scenes. Aiming at the limitations of traditional CNN in long-range dependency capture, a novel two-stream mixed feature extraction module DSFFE (Two-stream Mixed Feature Extraction) is proposed, which combines the advantages of Convolutional Neural Networks (CNNs) and Transformer, fuses the local and global information more efficiently, and maintains the computational efficiency of the While maintaining the computational efficiency, it enhances the ability of global feature extraction. A dynamic task interaction alignment method (DTIA) is proposed to address the feature conflict and alignment problem between classification and localization tasks in object detection. Efficient interaction and spatial alignment of multi-task features is achieved by introducing a shared convolutional layer, a dynamic convolutional module (DCNv2) and an attention mechanism.
These contributions aim to enhance the detection performance of the algorithms to meet the needs of robots in real-world applications.
Method
In order to improve the recognition ability of the model for infrared object objects, this paper designs the dual-stream hybrid feature extraction module DSFFE to replace the feature extraction module in the backbone network, uses the proposed Multi-feature Focused Diffusion Pyramid Network (MFADN) to improve the FPN, and finally uses the Dynamic Task Interaction Alignment for the final classification and localization. Figure 2 illustrates the network structure of the MFDTIA-Detection method proposed in this paper.

Overall framework of proposed MFDTIA-detection.
Dual-stream fusion feature extraction
The model in this paper is based on YOLOv11, the original C3k2 module integrates a combination of C2f and C3 modules, the outer layer is dominated by a C2f structure and the inner layer is a C3 structure. Compared to the original design, Bottleneck's convolutional kernel size is adjusted to two convolutional layers of size 3, optimizing computational efficiency and speeding up feature extraction. However, the limitation of relying solely on convolution makes the capture of global information insufficient and the lack of attentional mechanism leads to weak extraction of details and long-range features.
To this end, this article proposes a novel dual-stream fusion feature extraction module DSFFE (Dual-stream fusion feature extraction), which aims to combine the advantages of CNN and Transformer, a structure that has received widespread attention in computer vision tasks due to its powerful global feature extraction capability. However, due to the high computational complexity of the Transformer structure, applying it directly to all channels leads to significant computational overhead. For this reason, the input feature map is divided into two parts, which are processed by CNN and Transformer, respectively, and local and global features are effectively fused by dividing the input feature map into two parts, which are processed by Convolutional Neural Network (CNN) and Transformer, respectively. The details are shown in Figure 3.

Dual-stream fusion feature extraction.
The former is responsible for local feature extraction and mainly consists of two depth-separable convolutions to reduce the computational effort while enhancing the information flow of the feature maps, while the latter utilizes MHSA (Multi-Head-Self-Attention) to exploit the multi-head strategy, which is able to capture the complex relations between features in different subspaces to enhance the global feature extraction capability. By using Transformer for only some of the channels, it reduces the computational cost while ensuring efficient feature extraction, and solves the difficulty of traditional CNN in capturing long-range dependencies effectively due to the limitation of its local receptive field. In addition, the introduction of Convolutional GLU enhances the nonlinear feature representation capability, which better captures the complexity and details of the data compared to the traditional feed-forward network (FFN). It also allows the number of Transformer channels to be adjusted according to the model size and specific application, further improving model adaptability and efficiency. The fusion of the final output allows the two to complement each other in terms of convolutional and global attention features to enhance feature representation. Figure 4 demonstrates a comparison between DSFFE and the original feature extraction module for two of the 32-channel feature maps of a certain layer of shallow network feature maps after visualization, it can be clearly seen that (b) focuses more on the edges and more on the figure itself compared to (a), which focuses more on the background, and (d) focuses more on the overall shape of the object and the background information compared to (c), which confirms that DSFFE focuses on both local and global features. The proposed DSFFE module demonstrates significant promise not only in the realm of object detection but also in other fields requiring precise feature extraction. The versatility of this method could be extended to applications such as medical imaging, where fine-grained detail capture is crucial for tasks like tumor detection or organ segmentation. In remote sensing, DSFFE could enhance the analysis of satellite images, improving feature extraction for land use classification or environmental monitoring. Furthermore, this method's potential can be expanded to autonomous driving, where the integration of local and global features is essential for real-time decision-making in dynamic environments. Its adaptability to multi-modal data also opens up new possibilities in areas such as multi-sensor fusion and cross-modal learning, further broadening its scope for future applications.

The comparison of feature map visualizations.
Multi-featured aggregated diffusion net
In traditional FPNs, feature maps are passed and fused through top-down paths, and although feature fusion is performed at different scales, features at each scale lack sufficient contextual information. Low-level features often lack global context, resulting in limited recognition of complex objects or scenes. Meanwhile, FPN relies on feature fusion at a single scale and may neglect fine-grained information across scales. In addition, top-down information flow makes it difficult for global information at the higher level to effectively diffuse to the lower level, and for detailed features at the lower level to propagate to the higher level, limiting the network's ability to comprehensively consider features at different scales, especially in tasks such as object detection, where the combination of detailed and global information is crucial.
Therefore, to address the limitations of insufficient multi-scale feature fusion, poor capture of contextual information, and cross-scale information processing in FPNs, Multi-featured Focused Diffusion Pyramid Network MFADN (MFADN) is designed and proposed to alleviate these deficiencies.
Its core innovation lies in the fact that through MSFF (Multi-Scale Feature Focus) and FDM (Feature Diffusion Mechanisms), the MFADN ensures that each scale feature can contain more contextual information to enhance context awareness in complex scenes. The foremost MSFF module is responsible for multi-scale aggregation processing of features. Its structure is shown in Figure 5. Firstly, P3 features are in the shallower network layer with higher resolution and have a higher number of channels, and P3 features are downscaled using Adown,
9
the reason is that it better preserves small object features by fusing high-level semantic features with low-level spatial features, avoiding feature loss due to downsampling, P4 is the feature in the middle layer, with a higher number of channels and resolution than P5, and is only downscaled using the 1 × 1 convolution to adjust the number of channels, P5 is the feature extracted at the deepest level with lower resolution, upsampling the P5 feature to double its size, and using 1 × 1 convolution to adjust the number of channels after upsampling as a way to ensure that features at different scales can be effectively fused. The formula is shown in (1–3), where




Overall framework of proposed MSFF.
After merging the features, since the size of the convolutional kernel determines the extent of the receptive field in traditional convolutional neural networks (CNNs), when the convolutional kernel is small, it can only capture the features in the local area and when the convolutional kernel is large, it can capture a large amount of contextual information. However, a single convolutional kernel size may not be able to capture detail and global information well at the same time, so the use of deep convolutional operations with different convolutional kernel sizes, and at the same time, when the scaling factor is 1, the dimensionality of the features is not changed to avoid unnecessary transformations of some input features, which makes the network able to process and capture local information at different scales to ensure that the features at each scale are effectively utilized. Finally, the feature maps after the depth-divisible convolution process are merged and weighted and summed, and the final feature map is obtained after the pointwise convolution process, and the residuals are connected with the original input. The formula is shown in (4), concat denotes the splicing of the model and kernel denotes the step size of the convolution kernel.

Multiple parallel depth convolutions are utilized to capture rich information across multiple scales, allowing multiple different features to be extracted at the same scale simultaneously, enhancing the fusion of multi-scale information. Through FMFD (Feature Multiple Focused Diffusion), the module sums the feature map outputs from different depth-separable convolutional layers to achieve weighted fusion. This summation strategy can effectively integrate feature information from different scales, which not only strengthens the information transfer between scales, but also promotes the mutual complementation of low-level and high-level features, and ensures the smooth diffusion of features in the network. Next, the fused feature maps are further processed using point-by-point convolution, which enhances the representation of global features, improves the model's ability to understand the global context, and thus enhances the model's ability to represent integrated features.
This mechanism enables features at each scale to combine contextual information from other scales, promotes feature interactions across scales, and strengthens the combined global and local feature representation. This approach helps to improve the accuracy of object detection and classification tasks. By introducing MSFF and MFFD, MFADN overcomes the deficiencies of FPN in feature context awareness, cross-scale information fusion, and feature propagation, and improves the network's ability to handle multi-scale features, thus enhancing the network's adaptability and accuracy in the object detection task. The proposed MFADN method demonstrates broad applicability in various computer vision tasks beyond object detection. It can be extended to semantic segmentation, where multi-scale feature fusion is critical for accurate pixel-level predictions. In addition, the method's ability to efficiently combine contextual information across scales makes it suitable for applications such as video analysis, where temporal and spatial feature fusion is required. Moreover, MFADN's scalable design allows it to be adapted to tasks involving large-scale or high-resolution data, such as medical image analysis or remote sensing, where both fine details and global context are essential for robust performance.
Dynamic task interaction alignment
Existing object detector heads typically use a single branch design, which can lead to a lack of interaction between the two tasks and inevitably some conflict between the classification and localization tasks in terms of feature sharing. This is due to the fact that they have different goals, leading to differences in the types of features each focuses on. Therefore, we propose a DTIA (Dynamic Task Interaction Alignment) approach with reference to TOOD, 22 which solves the problem of feature conflict and alignment through task decomposition, dynamic convolutional modules and attention mechanisms, while using a shared convolutional layer for all the tasks, resulting in a more lightweight structure. To address the inherent conflict between classification and localization tasks, we use a shared convolutional layer to extract common multi-scale features, which reduces the overall model complexity. The decision to utilize this shared layer stems from the observation that both tasks often operate on overlapping features, and sharing the convolutional layers can lead to more efficient utilization of available features. Additionally, using dynamic convolutional modules (DCNv2) allows for adaptive and spatially-aware feature manipulation, which enhances the performance of the localization task. This dynamic interaction between the tasks is facilitated through an attention mechanism, which allocates task-specific features to either classification or localization. By employing attention mechanisms, the model can focus on the most relevant features for each task, thus reducing conflicts and promoting better task alignment. The theoretical support behind this choice is based on the principle of multi-task learning, where shared representations improve feature sharing without significantly diminishing the task-specific performance.
Figure 6 shows the detailed structure of DTIA. Firstly, a feature extractor consisting of N consecutive convolutional layers inputs features for initial processing to provide common multi-scale features for classification and regression to be used for subsequent feature interactions. Where the convolutional layers are all combined with Group Norm to form a shared convolutional layer, significantly reducing the number of model parameters. Where
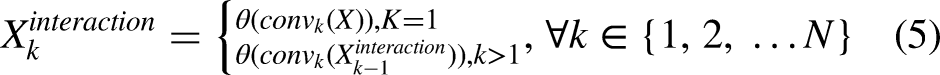

Overall framework of proposed DTIA.
Then, the features extracted from the shared convolutional layer of one of the layers are spliced with the extracted features. The spliced features are fed into two parallel layer attention decomposers and after global average pooling, specific features for classification and specific features for localization are extracted, respectively. Where the process of layer attention to compute features for different task interactions is shown in formula (6): where

Then, the localization regression branch achieves dynamic sampling of features by using DCNv2, generating offsets and masks, so that the regression features can be spatially and adaptively adjusted according to the shape and location of the object, and improve the regression accuracy to be spliced with the decomposed features. In this way, it solves the spatial alignment problem of the object at different locations, scales, and shapes. After the classification branch processes the tensor through 1 × 1 convolution, the ReLU activation function is used to make the network output have nonlinear expression ability, then through the 3 × 3 convolution layer sigmoid activation function, the probability map of classification alignment is generated to get the probability distribution, and finally, the classified features and the classification probability are aligned by multiplying them element by element, and the output contains bounding box prediction of each location and the corresponding classification Prediction. The proposed DTIA method demonstrates promising performance in real-world applications, particularly in resource-constrained devices. By utilizing a shared convolutional layer and reducing the number of model parameters, DTIA achieves a more lightweight structure, which is beneficial for deployment on edge devices with limited computational resources. Despite the reduced complexity, the dynamic task interaction alignment and attention mechanisms allow for efficient feature utilization, ensuring that both classification and localization tasks are handled effectively without significant loss in performance. This makes the method well-suited for applications such as mobile object detection and real-time surveillance on low-power devices.
Experiments
In order to verify the effectiveness and superiority of the proposed method, in this paper, experiments are conducted using the FLIR-ADAS 23 dataset, which is mainly used as an infrared image dataset for automatic driver assistance systems, and contains about 10,000 infrared images and about 1500 RGB images, and each image contains bounding box and category label annotations. The dataset can detect and differentiate between pedestrians, cyclists, animals, and motor vehicles. The IR images were acquired using a FLIRTau2 IR camera under challenging weather conditions such as complete darkness, smoke, bad weather, and glare, with a resolution of 640 × 512 per image. The dataset, which contains 60% daytime data and 40% nighttime data, provides a reliable basis for evaluating the detection performance of the IR image detection model in complex scenarios. This paper is divided into training set, validation set, and test set according to the ratio of 7:2:1. Figure 7 shows two infrared images and their corresponding 3D maps in the test set.

The three-dimensional characteristics of infrared images.
Evaluation metrics
This experiment uses the model itself metrics to measure the performance of the model in this paper, calculated as shown in formulas (7–9):
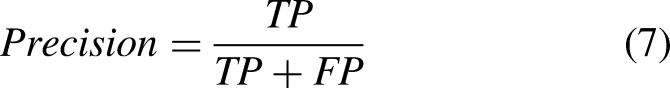


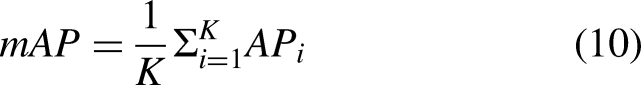
APi in equation (11) denotes the relationship between the value and the category index value, K denotes the number of categories of the samples in the trained dataset, which in this article has a value of 1, mAP0.5 denotes the average accuracy when the detection model IoU is set to 0.5, and mAP0.5:0.95 denotes the average accuracy when the detection model IoU is set to 0.5:0.95 (values are taken at intervals of 0.5). Parameter sizes, floating point operations (FLOP), and evaluation metrics were also used.
Experimental settings
The experiments were conducted on a hardware platform configured with Intel Xeon Silver 4214R CPU and NVIDIA GeForce RTX3080Ti GPU with Ubuntu18.04.5 operating system and torch-1.9.0 + cu111 deep learning architecture. The training period is set to be 200 epochs, the momentum is 0.937, the initial and final learning rate is 0.01, the weight decay rate is 0.005, the input image size is 640 × 640, the optimizer is selected as SGD, the data enhancement is done in a Mosaic way, the frame loss decay rate is 7.5, the classification loss decay rate is 0.5 and the number of samples per batch is 32.
Ablation experiments
In order to verify the effectiveness of the dual-stream hybrid feature extraction module DSFFE, multi-feature focused diffusion pyramid network MFADN and dynamic task interaction alignment detection head DTIA in the robotic vision infrared object detection model proposed in this paper, this paper takes YOLOv11n as the baseline model and conducts ablation experiments under the same experimental conditions, and the results of the experiments are shown in Table 1. On the basis of the baseline model, the baseline model is added gradually with three innovative modules, and the optimization effect of each module is compared according to the model evaluation index. The above experiments use mean average precision (mAP), accuracy, recall, and FLOPS as performance evaluation metrics. After using DTIA, the quasi-depreciation rate is significantly improved, while both mAP50 and mAP50-95 are improved, and the amount of parameters is reduced by nearly 10%, which indicates that DTIA can significantly improve the accuracy of classification and localization by extracting the total features of classification and localization first, and then performing dynamic alignment and interaction, and the number of parameters is reduced dramatically, and the light weight of the model makes it easier to Deployment. After using MFADN instead of the original FPN, the accuracy is improved by 2.6%, and both mAP50 and mAP50-95 are improved, which is attributed to its novel multi-feature focusing module and feature diffusion mechanism, where the features at each scale have detailed upper and lower contextual information and features with rich contextual information are diffused among different scales, which reduces the feature loss in the information transfer. After using DSFFE to replace the original feature extraction module, the accuracy is improved by 3.6%, and the mAP is also to be increased slightly, while the number of parameters is also reduced, which shows the effectiveness of dividing the feature map into two parts, which are processed by the CNN and Transformer respectively, to fully extract and fuse the local features. With the simultaneous inclusion of DTIA and DSFFE, the poor performance of DTIA recall is compensated. With the simultaneous addition of MFADN and DSFFE, the number of parameters is greatly reduced compared to MFADN alone because the whole model uses shared convolution several times, and the two modules enhance the feature extraction and fusion ability of the model, in order to make the accuracy, recall, mAP50, and mAP50-95 all improve. After adding MFADN and DTIA at the same time, each scale has richer contextual information after feature focusing, and then after the final dynamic feature interaction alignment, it makes the localization classification further enhanced, so the model has a good performance in all the indexes, and finally after adding MFADN, DTIA and DSFFE at the same time, it is the model of this paper, which is the model with good performance in the recall rate, mAP50 and mAP50-95 rise points are the highest, the accuracy is improved by 1.3% over the baseline model, and the number of parameters is only 5.1 M, these data further show that the model in this paper achieves a balance between lightweight and high performance of the model.
Comparison of results of ablation experiments.

Heatmap visualization
A heatmap is a visualization tool used to show the spatial distribution of data by indicating the magnitude of data values through different shades of color. In a heat map, the color of each cell reflects the magnitude of values or data density in the corresponding region. Typically, high values or dense regions are shown in warm colors (e.g., red), while low values or low-density regions are represented by cool colors (e.g., blue), and values in between are shown in shades such as green or yellow. In object detection tasks, heat maps provide a clear picture of how much attention the model pays to different regions in the image. Regions with high confidence are usually represented by brighter colors, while regions with low confidence are darker. Figure 8 demonstrates the comparison of the heat map of the model proposed in this paper with the baseline model. Where (a) and (b) are the images in the validation set, and (c–f) are the resultant images after visualizing the heat map on them, respectively. (c) has significant false and missed detections and covers the area (e) more accurately in comparison with (e), and (f) has a more complete region of interest in the heat map with fewer detections and darker brightness in the background region and brighter colors in the object region in comparison to (e), indicating that the model has higher confidence in object detection. And it shows that it can effectively reduce interference and focus on key features in complex backgrounds. It verifies that the present model is more capable of focusing on key regions and effectively mitigating the problems of false and missed detections when processing infrared images.

Comparison of heat maps.
Precision–recall curve analysis
In addition to heat maps, we also use precision–recall (PR) curves to evaluate the performance of the model. PR curves provide a more comprehensive evaluation, especially when dealing with unbalanced datasets. The x-axis represents recall and the y-axis represents precision. The larger the area under the PR curve, the better the performance of the model, as it shows the trade-off between precision and recall at different decision thresholds. The PR curves are shown in Figure 9, where our model has high precision and recall for each category under different thresholds. This result demonstrates the robustness of the model in dealing with small object detection.
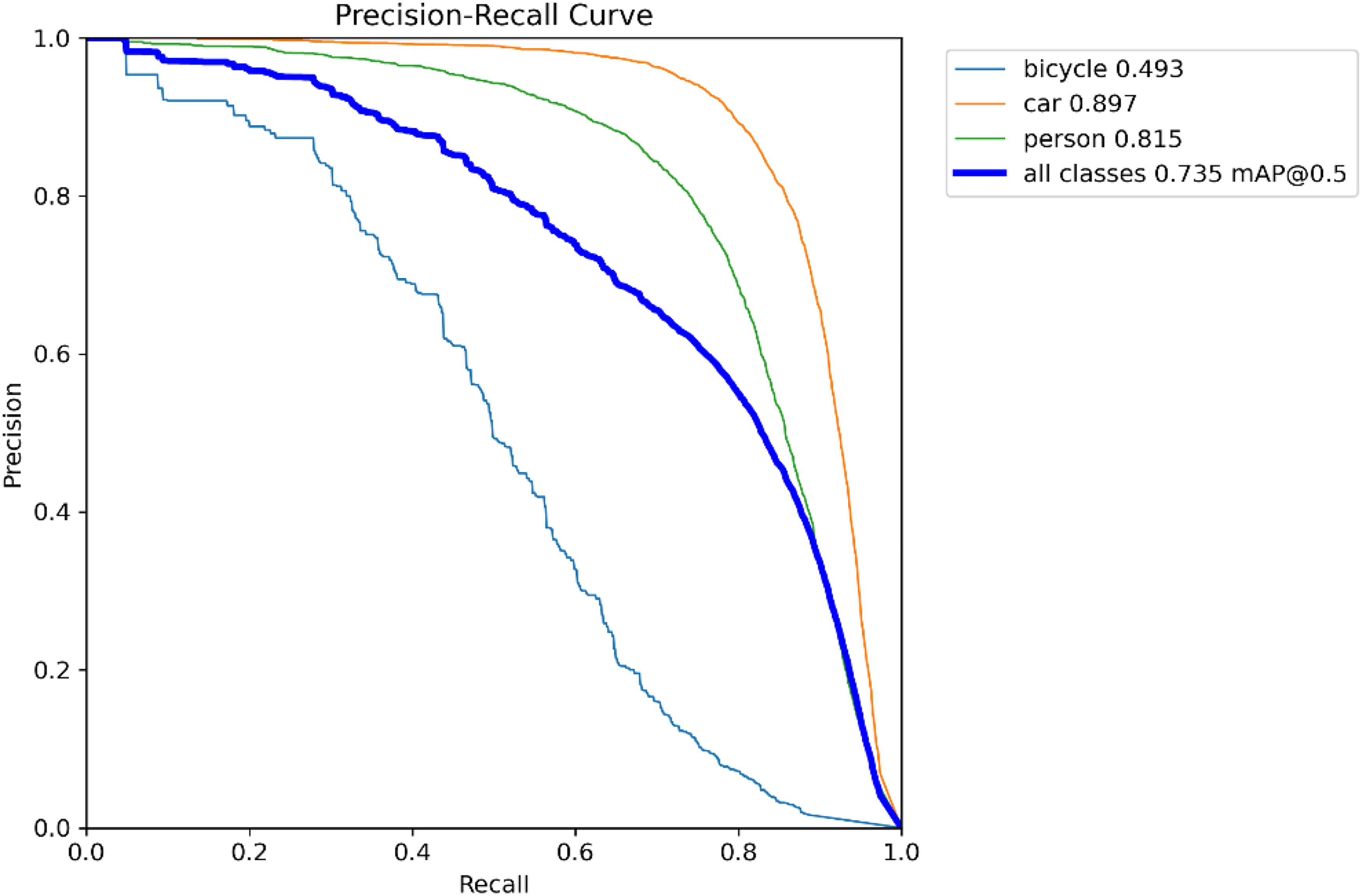
Pr curve plot.
Comparative experiments
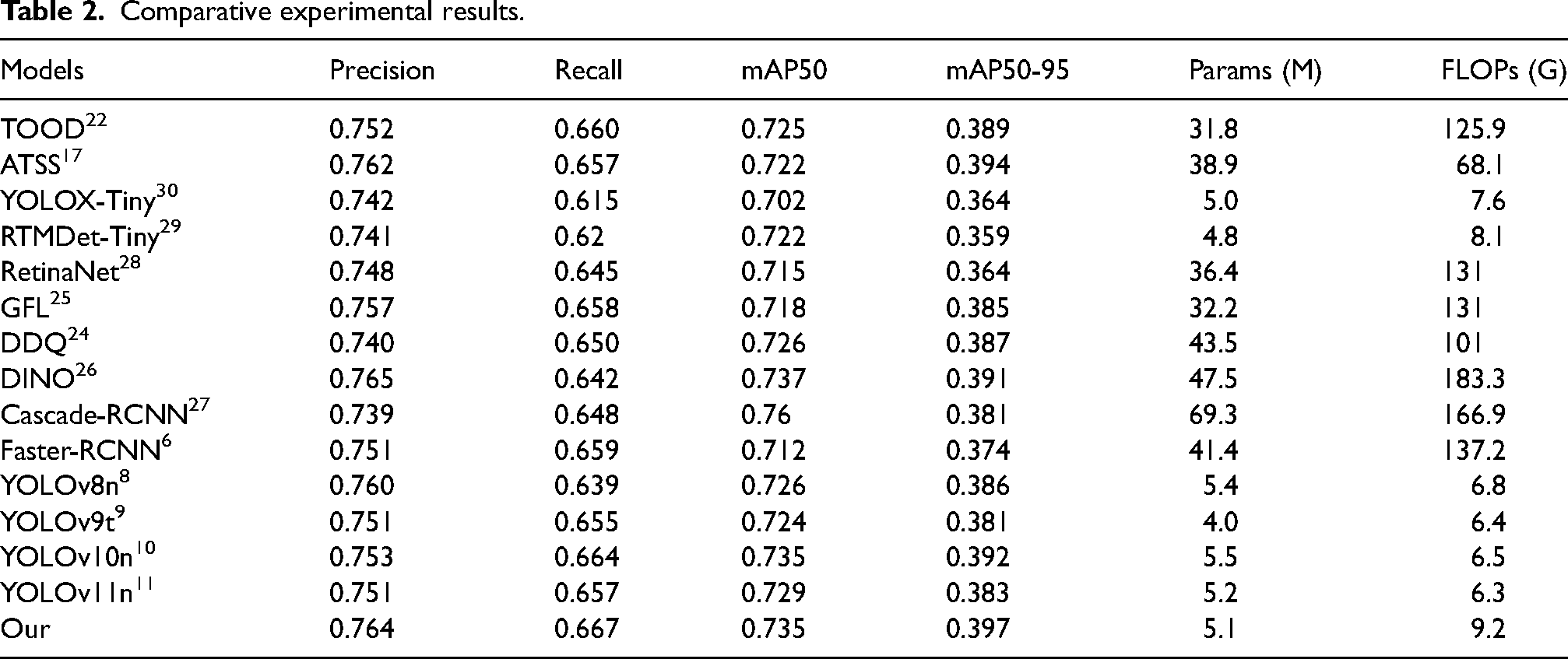
In this article, 10 different models are used in the comparison experiments of object detection, including Faster R-CNN, 6 DDQ, 24 TOOD, 22 ATSS, 17 GFL, 25 DINO, 26 Cascade-RCNN, 27 RetinaNet, 28 RTMDet-Tiny, 29 YOLOX-Tiny, 30 YOLOv8n, 8 YOLOv9t 9 YOLOv10n, 10 YOLOv11n 11 as well as the model proposed in this article (MFDTIA-Detection), all results were obtained in the open source library mmdetection. 31 Mostly ResNet-50 and FPN were used as the backbone and neck without any other modifications.
Table 2 shows that MFDTIA-Detection has the best recall and mAP50-95 when comparing with some of the current SOTAs, and in terms of the number of covariates, it is only a little bit more than YOLOv9t. In terms of the accuracy and the mAP50 metrics, TOOD demonstrates excellent performance, with which MFDTIA-Detection differs only by 0.01% or so, indicating the good effect of this model, which successfully maintains the lightweight while significantly improving the performance, taking into account the detection accuracy and computational efficiency.
Comparative experimental results.
Conclusion
This article proposes the MFDTIA-detection algorithm to address challenges in robotic infrared image detection, particularly false alarms, and omissions caused by tiny objects and image quality defects. By incorporating multiple focusing diffusion and task interaction alignment, our method significantly improves detection accuracy, outperforming current benchmark models. While substantial progress has been made, further optimization is needed, particularly in balancing algorithmic efficiency and accuracy. Future work will explore model compression techniques, such as pruning and distillation, to enhance performance without sacrificing accuracy.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, Anhui University of Science and Technology Graduate Student Innovation Fund Grants, University Synergy Innovation Program of Anhui Province, Opening Foundation of the State Key Laboratory of Cognitive Intelligence, (grant number 62076006, 2024cx2117, GXXT-2021-008, COGOS-2023HE02).
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.