
Abstract
The model predictive control trajectory planner is a popular and effective robot local motion planner. However, it is challenging to satisfy real-time requirements and implement them on embedded platforms due to their high complexity of solving and reliance on optimization solvers. This letter reports a lightweight and efficient two-stage solving algorithm for the model predictive control planner. Firstly, the general form of the model predictive control local planning problem was specified and simplified by the motion primitives. Then, a two-stage solving method of multi-layer perceptron pre-solving and particle swarm optimization re-optimizing is developed after splitting the cost function into two pieces. An multi-layer perceptron neural network was designed and trained offline to learn the solution of the model predictive control local planner without considering obstacles after selecting the inputs and outputs. Next, to accomplish obstacle avoidance, the particle swarm optimization algorithm re-optimizes the trajectory based on the outputs of the neural network. The experiment results demonstrate that the multi-layer perceptron-particle swarm optimization algorithm can quickly and accurately solve local planning problems, guiding robots to complete global paths with the same efficiency as expert solvers. The average solving time has been reduced by over 90%, enabling the robot to increase its control frequency or adopt higher-quality complex motion primitives. The multi-layer perceptron-particle swarm optimization algorithm can also be used for various robots and motion primitives, with a wide range of potential applications.
Keywords
Introduction
Motion planning is an important part of the robot system, bridging the gap between task execution and attitude control, which can be divided into global and local motion planning. 1 Local motion planning is responsible for guiding the robot to follow the global path efficiently and stably in shifting environments with a detailed kino-dynamics model.
Optimal-based methods, one type of commonly used method, transform the problem into a high-dimensional constrained optimization problem, such as the time elastic band (TEB), 2 model predictive control (MPC), 1 polynomial curve method, 3 Bézier curve method, 4 etc. In recent years, MPC local planner has been studied intensively and applied successfully on robots such as unicycles, 5 unmanned aerial,6,7 ground,8,9 and ships 10 vehicles. The forward prediction module enhances the completeness of trajectories and the stability of robots’ attitudes, while rolling optimization permits the planner to adapt to environmental changes and correct numerous errors, resulting in high-quality trajectories and an improvement in the robot’s stability and robustness. However, the MPC trajectory problem of robots is frequently a nonlinear optimization problem with multiple constraints, making it challenging to satisfy the real-time operation requirements. Incorporating the high-dimensional dynamic model and extending the predicted horizon can further enhance the planners’ performance, improving fast-moving 8 and obstacle avoidance 11 abilities, even achieving aggressive driving in hard field environments, 9 but increasing the solving complexity. Linearization is a commonly used technique to reduce optimization complexity but at the expense of solution quality.8,11 The model predictive path integral (MPPI) method gets the optimal trajectory by parallel sampling calculation but puts requirements on hardware such as graph processing unit (GPU). 9 Obstacle avoidance makes optimization more challenging to meet the real-time requirement. Hard constraint methods, such as the corridor method, 7 add more constraints, while soft constraint methods complicate the optimization gradient. 3 Nonlinear optimization problems usually require professional solving libraries such as IPOPT, 12 CasADi, 13 and Acados, 14 which are difficult to deploy on embedded platforms or lightweight operating systems. At the same time, the volume of high-performance computers is not conducive to the miniaturization of robots.
Sampling-based motion is another type of local planner that has good real-time performance at the expense of optimality. Some relevant technologies have been introduced to expedite the solving of the MPC local planner. First, motion primitive 1 uses a few parameters to encode long trajectories, to construct an efficient search tree to find the optimal trajectory.15–17 The designated motion primitives generate the mapping between state and action space. Robot models were taken into account to assure trajectory implementability when designing motion primitives. Some researchers have used optimization techniques to find the optimal trajectory in the motion primitive space. 18 Low space dimension enables quick optimization solutions, but multiple times solving the boundary value problem (BVP)19,15,16 which converts motion primitives into trajectories, incurs additional time consumption. The second technique is the pre-solving dataset and look-up method.20,21 Sample and solve to construct a trajectory dataset offline at first. In actual operation, the best trajectory can be quickly sought in the table. However, this method has two disadvantages: the solution quality is limited by the sampling precision. Reducing the sampling interval may increase the consumption of storage space and the difficulty of searching. 22 Neural networks and imitation learning technologies have the potential to solve these issues. Using trajectory datasets as a guide, neural networks are capable of learning trajectory planning abilities due to their ability to match any nonlinear function. Currently, researchers have used neural networks to generate trajectories of robots with starting and ending points 23 or get the planning skills from human manipulation datasets. 24
The environment in which robots are located is continually changing, posing challenges to the input of environmental data into neural networks to accomplish obstacle avoidance. Some scholars use deep neural networks to process images 25 and point cloud 26 information to avoid obstacles, but they often need human teaching 24 or reinforcement learning. 26 Worse, the sampling and training are difficult and have no advantage in solving time. To accomplish obstacle avoidance, we adopted a re-optimization to construct a two-stage solution, which can simplify complex problems by focusing on different aspects during different stages of the solution, 27 producing effective solving.
The innovations of this letter can be summed up as follows: ① For the model prediction trajectory planner, a lightweight fast-solving algorithm called multi-layer perceptron and particle swarm optimization (MLP-PSO) is proposed with two stages: pre-solving and re-optimization, which does not require the complex code library and can be implemented on lightweight processors. ② An multi-layer perceptron (MLP) network was designed and trained to imitate the solvers without considering obstacles to achieve fast and accurate optimization. ③ Experiments have demonstrated that this algorithm can precisely solve MPC motion planning problems while reducing average optimization time by at least 90%, enabling the robot to increase its control frequency or adopt higher-quality complex motion primitives. Moreover, this algorithm is suitable for various robots and motion primitives.
The rest of the article is organized as follows. The “MPC local planner with motion primitive” section introduces the system framework and the construction of the MPC local planner with motion primitive. A detailed description of the MLP-PSO algorithm is presented in the ‘‘MLP-PSO algorithm” section. In the “Implementation and experimental robots” section, the implementation of the algorithm and experimental robots are represented. The experiments and results can be found in the “Results” section. The “Conclusion” section is the conclusion and future work of this article.
MPC local planner with motion primitive
This section begins with an overview of the mobile robot’s planning and control system. Then, establish and simplify the MPC local planning problem with motion primitives.
System framework
As depicted in Figure 1(a), the planning and control system of mobile robots often utilizes a hierarchical control structure. The global planner is responsible for finding feasible paths between the current location and the terminal. Based on the global path and the local cost map, the MPC local planner generates smooth trajectories and motion commands, avoiding time-varying obstacles. The motion controller executes commands and eliminates interference.

(a) The whole framework of robot planning and control system (b) The framework of MPC local planner with MLP-PSO algorithm. MPC: model predictive control; MLP-PSO: multi-layer perceptron and particle swarm optimization.
Figure 1(b) shows the structure of the MPC local planner. After obtaining global path
Motion primitive
The robot can be described by the following model:

If the robots’ inputs are generated according to specific rules of the motion primitive, the entire input sequence can be reproduced by solving the BVP problem with initial and terminal states. Then, the robot’s state sequence can be predicted by the kino-dynamic model. Therefore, there is a one-to-one correspondence between the trajectory and terminal system states.1,6 Using terminal state as a motion primitive

Model predictive local planning
The model predictive local planning problem can be expressed in the following general form of the MPC problem:




Focus on the cost function, the first item enables the robot to follow the global path, while the second item enables the robot to drive at the reference speed with minimal turning consumption. Finally, the local cost map created and renewed by signed distance field (SDF) technology is introduced to implement gentle constraints for obstacle avoidance. The local cost map rasterizes the environment, resulting in the lower the grid value, the further it is to the obstacle. So minimizing this item can guide the robot away from obstacles. The difference between grids generates gradients for optimization.
MLP-PSO algorithm
In this section, the overview of the MLP-PSO algorithm is described first, followed by the details of each module.
Algorithm overview
The cost function of MPC local planner can be divided into two parts as follows:



The cost function value of one real problem. The whole cost (under) is the superposition of states cost
If the MPC problem is solved in an obstacle-free environment, the cost function degenerates into
The MLP-PSO algorithm solves local planning problems as shown in Algorithm 1. Firstly, we execute a forward traversal along the global path for a certain look-ahead distance from the present position of the robot to get the goal point (line 1). This look-ahead distance is determined by the robot’s maximum velocity and predictive horizon. Then, acquire the pre-solution by the MLP network (line 2). The MLP result is used for forward simulation to acquire predicted trajectories (line 3). If the trajectories are obstacle-free on the local cost map, the MLP result can be output directly to the control module (lines 4 and 5), and the optimization is finished. If not, the PSO algorithm is used for re-optimization to avoid obstacles (lines 7–23).
After obtaining the optimal motion primitive, the optimal control sequence is obtained by solving the BVP problem. Subsequently, the predicted trajectory is generated by applying this control sequence to the robot’s dynamic model, facilitating tasks such as collision detection and output visualization. If the predicted trajectory indicates a potential collision, the control sequence will not be sent to the motion controller, and an emergency stop command will be issued instead.
The MLP network and PSO algorithm can be decomposed into algebraic operations without the need for complex code libraries. Therefore, the MLP-PSO algorithm can be deployed on multiple platforms, including some lightweight processors.
Problem simplification
In this subsection, the MPC local planning problem is transformed into a simpler form.
First, according to the
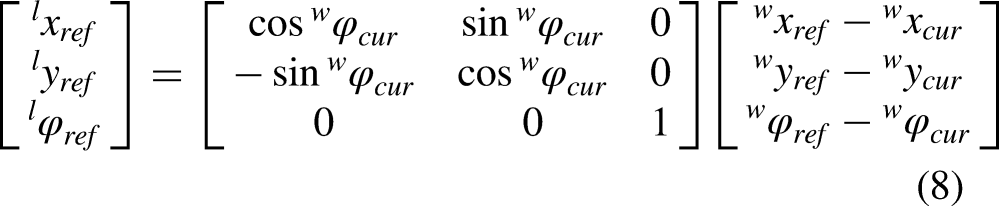
Thus, after two steps, the robot tracks a target point


Related figures about MLP-PSO algorithm: (a) The reachable position of the robot on a certain predicted horizon. Each arrow represents a goal
MLP neural network
The global optimal solution for optimization problems is a function of the inputs and parameters. The existence of variable constraints, nonlinear links, and generation rules of motion primitives makes the analytical function of optimization problems either nonexistent or challenging to find and express. Thanks to imitation learning, the neural networks can directly adapt the result function and learn control policy from the result dataset, cloning the solution procedure. An MLP network was designed in this study.
Figure 3(b) depicts the structure of the MLP neural network, which has nine inputs and two outputs. The inputs are goal position
MLP-PSO algorithm.

To satisfy the calculation of the MLP network, the inputs and outputs are normalized to
Compared to traditional look-up methods, the MLP neural network’s result is continuous on state space, producing more accurate results by fitting for non-sampled points. And the MLP method only requires the storage of the network’s parameters (hundreds of floating-point numbers) without the need to store complex search trees or look-up tables, thereby saving a significant amount of space. The computation cost of forward propagation is also superior to that of searching in complex trees.
Sampling and training
The sampling space is a nine-dimensional space composed of neural network inputs. The sampling only needs to be carried out within the boundary, and points outside the sampling place can be normalized to the boundary. The sampling can be divided into two steps: first, uniform sampling to assure coverage, followed by adding white noise with a standard deviation as a sampling interval to points to improve randomness. Each sampling point can be converted into an MPC problem and solved by mature solvers such as IPOPT 12 to get the result.
The dataset can be divided into a training set and a testing set with a ratio of 7:3. The MLP neural network is trained with a weighted mean-square error (WMSE) loss on velocity and angular velocity based on backpropagation and batch training algorithms. The batch size was set to 200, and the training cycle was 1000. The lossfunction of training is
The MLP network employs the dataset as a teacher to imitate the solver. The trained MLP network can be regarded as a solver for a specific optimization problem.
PSO algorithm
PSO is an intelligent search technique that optimizes the cost function by utilizing the motion of particles. The discrete cost function can be optimized directly due to the direction of particles, which only depends on the values of the previous and subsequent iterations. The PSO algorithm suits the forward prediction-rolling optimization scheme of the MPC and has been widely used for solving nonlinear MPC problems.28,32
The particle swarm is initialized randomly near the result of the MLP network, which is also the initial global optimal result (lines 7–9). Then, the optimal solution is searched through iteration. In each iteration, for each particle, the BVP problem is solved to get the full input sequence of the robot (line 12). Then, utilize the prediction model and cost function
The process of a re-optimization is shown in Figure 3(c). It can be seen that as the optimization goes on, the robot’s trajectory moves away from obstacles, getting the optimal result considering obstacles. Because the MLP network produces approximations, the PSO algorithm can get the optimal result much more quickly than optimizing directly.
Implementation and experimental robots
In this section, we first outline the deployment steps of the MLP-PSO method onto the robot, followed by the presentation of the car-like robot and spherical robot used for testing.
Implementation
For any robot, the deployment of the MLPPSO method involves the following steps:
Establishing the robot model and selecting appropriate motion primitives based on the model. Formulating the model predictive trajectory planning problem and simplifying it by motion primitives. Determining system state boundaries and sampling rules to create multiple planning problems, solving them by mature solvers to obtain planning results and form the complete dataset. Partitioning the dataset into training and testing sets for training the MLP neural network. Deploying the trained MLP neural network and PSO algorithm on the robot platform.
By forming the new dataset, and adjusting the MLP network’s inputs and outputs, adaptation to more robots can be achieved, such as quadcopters in
Car-like robot
The car-like robot is one of the most common unmanned ground vehicles (UGVs), which achieves free motion on the X-Y plane by changing the steering angle of the front wheels, as shown in Figure 4(a). To ensure the smoothness of the trajectory, Jerk limited trajectory (JLT)33,34 is introduced as the motion primitive, and the terminal constraints of its BVP problem are the terminal velocity 


(a) The motion diagram of the car-like robot. (b) The
Spherical robot
The spherical robot is an innovative type of special operation robot with large application potential in field exploration, security patrol, planet exploration, etc. 35 As shown in Figure 5(a), our laboratory has developed a spherical robot driven by a 2-DOF pendulum. By adjusting the output torque of two motors to adjust the position of the pendulum, the spherical robot can achieve motion on the X–Y plane.
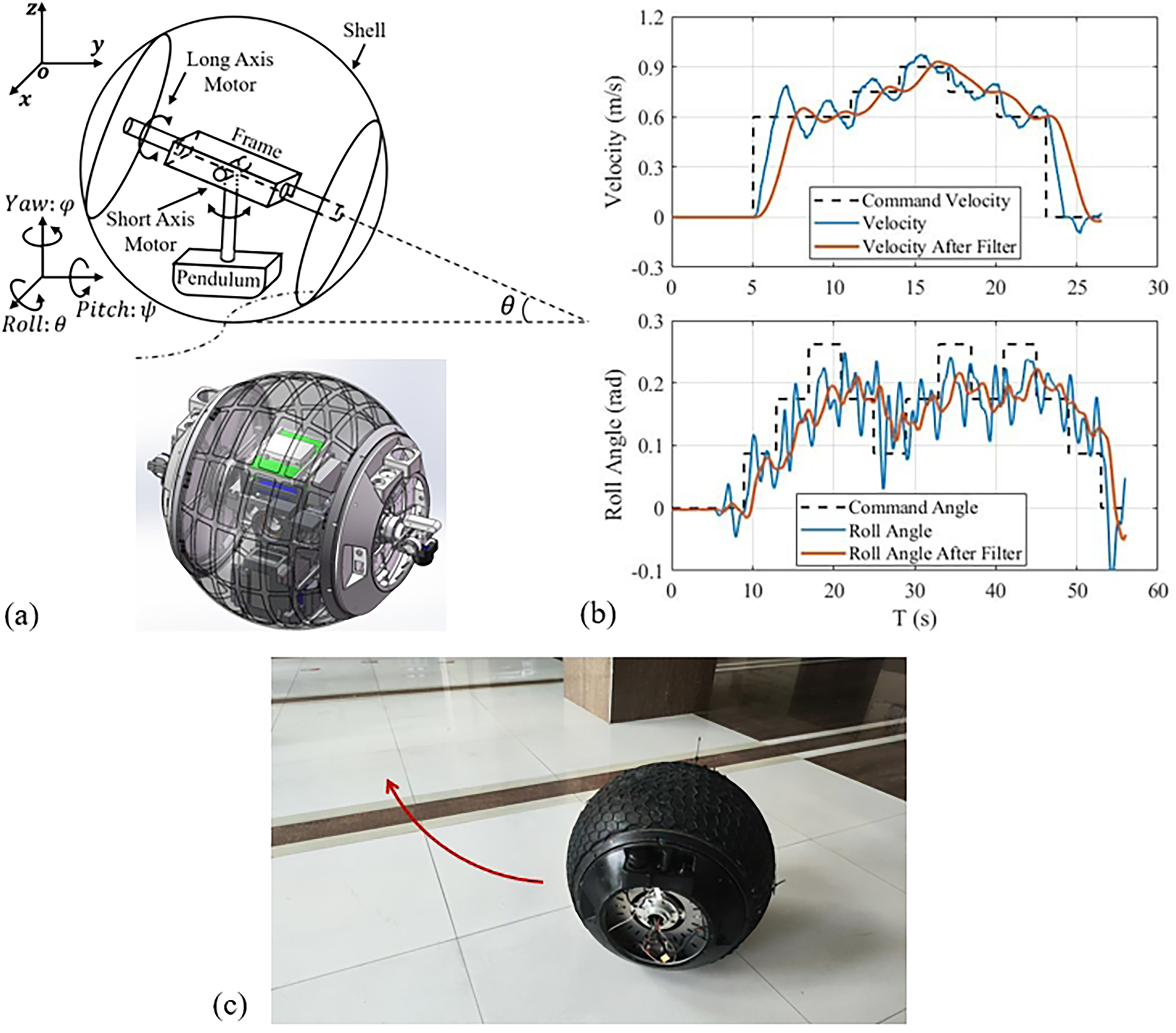
(a) The motion diagram and design drawing of the spherical robot. (b) The control effect of the attitude controller. (c) The physical drawing of the spherical robot and the real-world test scenario.
The characteristics of the spherical robot,36,37 including strong nonlinearity, under-actuation, non-holonomic, and a high time latency, present challenges for the planning control system. It has been determined that the attitude controllers of velocity 

Results
In this section, the details of the MLP training are presented first. Next, the solution accuracy of the MLP-PSO algorithm was evaluated using arbitrarily generated data. After deploying the algorithm to the car-like (in the simulator) and spherical robot (in the real world), the effect and time consumption of the MLP-PSO and traditional solvers (PSO for car and IPOPT for spherical) are compared experimentally. Two types of robots can verify the universality of the MLP-PSO algorithm, and the physical spherical robot experiment can verify the realistic feasibility. Subsequently, the spherical robot is used to evaluate the obstacle avoidance ability of the MLP-PSO algorithm.
Sampling, training, and testing all run in a single thread on a mini PC with an Intel i7-8559U CPU (2.70 GHz, quad-core 64-bit) and 32G RAM.
The MPC local planner runs at a frequency of 10 Hz on robots, which is a commonly used frequency of the local planner.6,8,10 The frequency of the global planner is 1 Hz, so there might be multiple global paths in the resulting figure.
MLP training results
The predictive horizon of the MPC local planner is set to 2 s. After the offline sampling and generation of the dataset based on the pre-experiment parameters, two pre-solving MLP networks are trained for selected motion primitives of the car-like and spherical robot. Table 1 displays the dataset size, time consumption, and training error.
The details of MLP training.

MLP: multi-layer perceptron; RMSE: root mean square error.
After 1000 cycles of training, the root mean square error (RMSE) of velocity
Solution accuracy
In this section,
The solution accuracy of multi-layer perceptron and particle swarm optimization (MLP-PSO) algorithm.

The obstacle-free scenario only requires the application of the MLP network, whereas the obstacle environment necessitates re-optimization with the PSO algorithm.
No matter what the robot is or whether there are obstacles in the environment, the average errors of velocity
Overall, accuracy tests demonstrate that the MLP-PSO algorithm satisfies the accuracy requirements necessary for practical implementation and can be implemented on robots for further testing.
Car-like robot experiment
The car-like robot completes multiple curved paths in a complex corridor environment by
The reference velocity

(a) The diving result (blue line: global paths; red line: driving path), velocity curve, and angular velocity curve of the car-like robot with two different solvers. (b) The diving result (blue line: global paths; red line: driving path), velocity curve, and roll angle curve of the spherical robot with two different solvers.
The results of experiments.


PSO: particle swarm optimization; MLP-PSO: multi-layer perceptron and particle swarm optimization; IPOPT: Interior Point OPTimizer, pronounced IP-Opt; MLP: multi-layer perceptron.
It can be seen from the results that the MLP-PSO algorithm can drive the robot along the global path with the same performance as the traditional solver, with no significant differences in statistics (errors < 5%) and curves. The curves demonstrate that the robot’s
As for time consumption, the MLP-PSO algorithm is clearly superior. In total implementation time, the MLP-PSO algorithm is 93.2% less than traditional methods. The obstacle-free scenario only requires the MLP network, with an average solving time of 0.142 ms, which can be negligible. In obstacle scenarios, re-optimization is required, with an average total solving time of 2.594 ms, which is also 87.4% faster than traditional methods. Based on the function running count, it is evident that scenarios with and without obstacles are nearly equally represented. As a result, the final average solving time is approximately the mean of these two conditions. In extreme circumstances, the improvement is more obvious. Traditional methods may require around 95 ms maximum and can only plan at 10 Hz. While the MLP-PSO algorithm requires < 8 ms, enabling the local planner’s operating frequency to be increased to 20 Hz, 50 Hz, or even higher. This also allows for the use of more complex motion primitives to meet higher control demands.
From the trajectory, it can be observed that the complexity of the robot traversed areas varies, with both wide and narrow areas. The small solving time variance result indicates that complex environments with multiple obstacles do not significantly increase the solving time. The soft constraint obstacle avoidance method makes multiple obstacles generate more optimization gradients on the map rather than imposing complex constraints, which has minimal impact on the solving complexity.
The car-like robot experiment demonstrated the MLP-PSO solver’s significant advantage in reducing solving time compared to traditional solvers. This reduction greatly alleviates the load on the robot’s controller. Furthermore, the experimental results further confirmed that the MLP-PSO algorithm meets the accuracy requirements.
Spherical robot experiment
The spherical robot, shown in Figure 5(a), was utilized to conduct
The task is an 8-figure multi-point patrol with eleven waypoints. The
The results indicate that the IPOPT solver and MLP-PSO algorithm can both solve the local planning problem, guiding the spherical robot to complete the patrol task effectively and in a stable state. There is no significant difference between the two methods’ statistics and result trajectories. Under the commands given by the MLP-PSO algorithm, the non-holonomic, non-linear, under-actuated, and critically stable spherical robot can achieve smooth acceleration and deceleration based on the actual conditions in order to increase efficiency. The roll angle can also be adjusted on command to achieve turning without violent oscillation or divergence.
The average solving time for the MLP-PSO algorithm is 0.107 and 2.827 ms in obstacle-free and obstacle environments, which is 99.3% and 82.2% less than traditional methods. The benefits are readily apparent. From the count of function runs, it can be seen that there are fewer obstacles in the spherical robot experiment. Thus, the overall average solving time decreases substantially (around 98.3%). Furthermore, the maximum solving time is < 5 ms (a decrease of 94.1%), which is a significant improvement over the IPOPT solver (64.03 ms).
In conclusion, experiments on car-like and spherical robots demonstrate that the MLP-PSO algorithm can effectively solve the model-predictive trajectory planning problem to guide the robot running along the global path with the same performance as the traditional solver, reducing the solving time by more than 82% even in complex environments. The substantial reduction in solving time highlights the superiority of the MLP-PSO algorithm compared to traditional methods. Tests conducted on two different types of robots demonstrate the algorithm’s general applicability, while the real-world experiment with the spherical robot validates its practical feasibility and superiority.
Obstacle avoidance experiment
In the experiments, two kinds of robots successfully avoided obstacles, especially the car-like robot running in the narrow corridor. From Figure 6(a), it is evident that the global path (blue line) did not account for the width of the robot, which may guide the robot to turn very near to the obstacle and cause collisions. The PSO algorithm re-optimized the trajectory to guide the robot away from the obstacle when it reached the turning point. After moving away from obstacles, the robot returned to the global path quickly. In conclusion, the MLP-PSO algorithm can achieve obstacle avoidance, and the soft constraint scheme is effective.
Conclusion
This article proposes a two-stage solving method called MLP-PSO for model predictive trajectory planners, addressing the challenges posed by complex models and long predicted horizons. At first, to quickly solve the standard MPC planning problem, an MLP neural network was trained on an offline dataset to imitate the solver without considering obstacles. Then, the obstacle avoidance task is accomplished by the PSO algorithm employed for re-optimization. Experiments have demonstrated that the solving quality of the MLP-PSO algorithm is identical to that of traditional solvers. Guided by the commands from the MLP-PSO algorithm, robots can effectively complete global paths while satisfying the predetermined requirements of the local planner. The MLP-PSO algorithm has a significant advantage in solving complexity and time consumption than the traditional method, reducing the average solving time by > 90%. The maximum solving time is < 10 ms, making it possible to improve moving performance by increasing the planning frequency to 20 Hz and higher or adopting higher-quality complex motion primitives.
Moreover, the MLP-PSO algorithm is suited for various robots and motion primitives. As for application, the MLP-PSO algorithm has a notable advantage in that it does not rely on code libraries, allowing MPC local planners to be deployed on low-performance processors and embedded platforms. This helps to achieve lightweight, miniaturization, and cost reduction of robots.
MLP-PSO offers a potential optimization method for complex MPC planning problems that cannot be solved in real time on robot platforms. We will try this application in the future. In addition, the application field of the MLP-PSO algorithm can be broadened by increasing the prediction horizon, adding robot and motion primitive types, and integrating dynamic models and constraints.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Rotunbot (Hangzhou) Technology Co., Ltd fund and the Zhejiang University Global Partnership Fund.