
Abstract
Existing autonomous underwater vehicle (AUV) path planning algorithms are rapidly developing and perform well in solving optimal paths. However, the performance of these algorithms in real environments is significantly worse than that in simulated environments due to the influence of currents in real marine environments. To this end, this paper proposes an algorithm that improves the fusion of perturbed flow field and deep reinforcement learning and adds the influence of random currents to the environment, which further improves the overall accuracy of AUV obstacle avoidance in dynamic environments and enhances the AUV's adaptability to the real environment. This study also compares the results obtained using four fused deep reinforcement learning algorithms simulated in different scenarios, and the results show that the proposed algorithm can enable AUV to realize dynamic path planning in unknown environments.
Introduction
Autonomous underwater vehicles (AUVs) have been widely used in underwater rescue, unknown water exploration, and hydrological observation. 1 With the continuous exploration of human beings into marine resources, AUVs have become the main tool for exploring the ocean. 2 How to realize dynamic obstacle avoidance and calculate the optimal path of AUV in an unknown environment has become a hot research topic. 3 Currently, the main algorithms for path planning are Dijkstra's algorithm, A* algorithm, 4 ant colony algorithm, 5 genetic algorithm, particle swarm optimization algorithm, 6 artificial potential field method, 7 and reinforcement learning algorithm. 8
The origin of reinforcement learning algorithms can be traced back to 1911 when Thorndike proposed the Law of Effect: a behavior that makes an animal feel comfortable in a certain scenario enhances the association (reinforcement) with this scenario, and when this scenario is reproduced, this behavior of the animal is more likely to be reproduced; and the reverse is true. In 1956, Bellman 9 proposed the dynamic planning method. In 1977, Werbos 10 proposed adaptive dynamic planning methods. Until the late 1980s and early 1990s, artificial intelligence, machine learning, and other technologies began to be widely used, and reinforcement learning began to receive attention. In 1988, Sutton et al. 11 proposed the temporal difference (TD) algorithm and in 1992 Watkins et al. 12 proposed the Q-learning algorithm. Rummery et al. 13 proposed the SARAS algorithm in 1994, Bersakas et al. 14 proposed a neural dynamic programming method for solving optimal control in stochastic processes in 1995, Kocsis et al. 15 proposed the confidence upper tree algorithm in 2006, Lewis et al. 16 proposed the adaptive dynamic programming algorithm for feedback control in 2009, 2014 Silver et al. 17 proposed deterministic policy gradient (DPG) algorithm, 2016 Google DeepMind 18 proposed A3C method.
Deep learning is a type of neural network technology. Deep learning can perceive, but cannot make decisions; while reinforcement learning can make decisions, but cannot perceive. Deep learning is a type of artificial neural network that uses training samples as input to the network and solves problems through the network's own learning ability. Reinforcement learning is a kind of unsupervised algorithm, its main idea is to let the network through the environment of random action learn the strategy and finally get the optimal strategy, to solve the problem. The combination of the two has made great progress in theory, so deep learning and reinforcement learning are combined to generate a new type of learning algorithm, namely deep reinforcement learning, whose basic idea is to allow the network to randomly draw samples from the environment and train itself to solve a specific problem. It is a method for solving a series of decision-making problems by applying deep learning algorithms to reinforcement learning problems. Behnaz Hadi 19 proposed two new methods for end-to-end motion planning and control of AUVs using deep reinforcement learning algorithms with the help of actor-critic structure. Literature 20 proposed a hierarchical deep Q-network (HDQN) approach for 3D path planning of AUVs and introduced the idea of an artificial potential field to improve the sparse reward problem.
For the avoidance of complex obstacles on the opposite side, literature 21 first proposed the interfered fluid dynamical system (IFDS) method, which is simple in modelling, small in computation, and easy to deal with complex terrain and different obstacles. In this paper, we combine the improved IFDS with a deep reinforcement learning algorithm and add the influence of ocean currents, hoping to improve the planning capability of AUV further. The structure of this paper is as follows: “Algorithm description” introduces the algorithms used in this study, “Experimental work and results” discusses the simulation results, and “Conclusion” concludes the paper.
The IIFDS-DRL algorithm proposed in this study combines an enhanced perturbation flow field model with deep reinforcement learning techniques to optimize AUV operations in random ocean currents. Its key contributions include:
Path Planning Optimization: The IIFDS-DRL algorithm efficiently plans paths in complex underwater environments and dynamically adjusts to changing flow conditions, thereby enhancing the efficiency and safety of mission operations. Enhanced Autonomous Navigation: Leveraging deep reinforcement learning, the algorithm enables real-time learning and optimization of obstacle avoidance strategies, ensuring rapid responses to variable dynamic obstacles and maintaining operational safety and stability. Improved Mission Efficiency: Compared to traditional methods such as A* algorithm, ant colony optimization, and rapidly-exploring random tree (RRT) algorithm, the IIFDS-DRL algorithm demonstrated superior efficiency and accuracy in path planning during experimental validations, effectively supporting various AUV mission operations in challenging underwater environments. Practical Utility and Application Prospects: Beyond academic research, the algorithm offers innovative technical solutions for practical applications in fields such as marine science research and resource exploration, advancing the capabilities and applications of autonomous underwater robotics.
Algorithm description
Improved IFDS (IIFDS)
Algorithm flow
One way to depict obstacles is as standard convex bodies.
22
Buildings and hills are examples of topographical impediments that can be reduced to rectangles, cones, cylinders, hemispheres, or combinations of these shapes. Motion obstructions in the form of incursions can be visualized as balls. A barrier can be represented uniformly as:
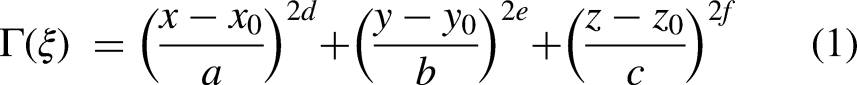
Using a matrix

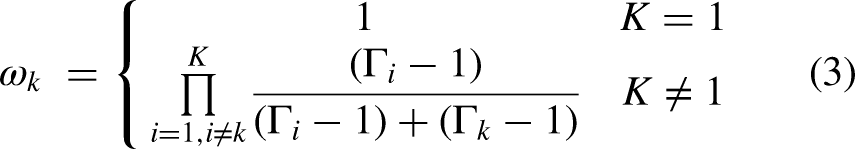

In the above equation

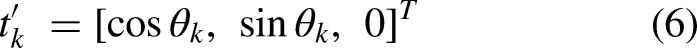

Consider dynamic barriers to obtain the perturbed fluid velocity:

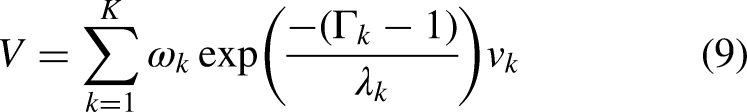

Improvement advantage
IFDS flows around an object often only in one plane, IIFDS adds a tangential matrix that can be varied by parameters to flow around the object in all directions. The improved rendering is shown in Figure 1.

(a) IFDS and (b) IIFDS.
Deep reinforcement learning
The deep reinforcement learning algorithm used in this paper is combined with IIFDS to deep reinforcement learning algorithm to adapt to the environment in real time and automatically adjust the parameters of IIFDS. In this paper, four classical algorithms of deep reinforcement learning are used, which are DDPG, PPO, TD3, and SAC. The overall structure of the study is shown in Figure 2.

Overall structure.
DDPG
The model consists of a four-layer neural network.
24
Actor's current network is based on the agent's state

DDPG.

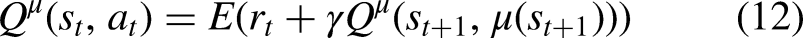
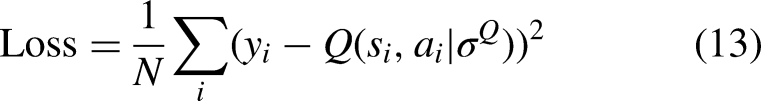

Use the U function to make a measure of the current network's strengths and weaknesses:


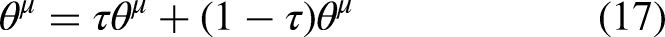
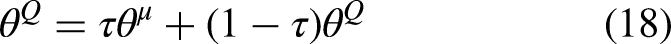
PPO
PPO is characterized by self-adaptation and good stability. 25 It is a policy gradient algorithm. In practice, it is difficult to form an effective strategy because the difference between old and new strategies is too large. The method can iteratively update a small number of samples during multiple rounds of training, thus effectively solving the problems of difficulty in determining the step size and large update bias. The framework of the PPO algorithm is shown in Figure 4.

PPO.
PPO algorithm critic network update method is not much different from the traditional actor–critic (AC) algorithm, the actor network uses a new method so that the number of training times can be reduced and can also achieve good results.
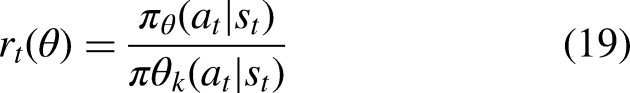

TD3
The framework of the TD3 algorithm is shown in Figure 5. The TD3 algorithm is based on the AC structure and improves the DDPG algorithm in the following three ways to address the problem of overestimation of Q by critic networks:
Two critic networks are used for Q-value estimation and the target critic networks are used for prediction, respectively. When updating, the smallest of the outputs of the two target networks is utilized to construct the TD error as shown in equation (21), thus avoiding the problem of overestimation:
TD3. The critic network uses a step-by-step update model, while the actor network uses delayed updates (updating the critic network multiple times before updating the actor network) to reduce variance and make the critic more stable; In equation (21), a positively distributed noise as in equation (22) is added to the target action to enhance the robustness of the model and thus improve the prediction accuracy.

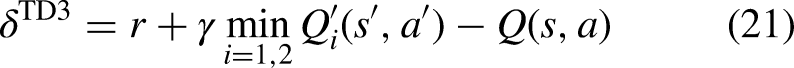

SAC
The benefits of the SAC deep reinforcement learning algorithm include high stability and a large exploration space. It is based on the maximum entropy principle and the AC framework. The maximum entropy principle allows the agent to learn a stochastic policy that enables it to explore a greater number of behaviors in situations where there are multiple optimal or suboptimal behaviors. To explore more potential optimal paths, as shown by equations (23) and (24), the SAC algorithm differs from conventional algorithms by incorporating the entropy parameter H.


Experimental work and results
Basic settings
The experimental environment was set up with six kinds of dynamic obstacles as shown in Table 1. Randomly oriented and randomly sized currents were set up in the environment to simulate the underwater environment, and the size and direction of the currents were reset every time the environment was refreshed. The single dynamic obstacle motion schematic and multiple obstacle motion schematic are shown in Figure 6. We implemented four algorithms, IIFDS-DDPG, IIFDS-PPO, IIFDS-TD3, and IIFDS-SAC, as a comparison, and all algorithms were set with the same default parameters, and the parameter designs are shown in Table 2. The experiments were run on Python 3.8.

The (a) single dynamic obstacle motion schematic and (b) multiple obstacle motion schematic.
Obstacle settings.

Parameter settings.

We use the following two criteria to assess the planning path.
Step: The AUV chooses an action based on the policy at predetermined time steps. The state transition function is then used to determine the next location. The number of steps indicates how many interactions and how much time are involved. Distances and reward values: This study employs uniform grid coordinates for ease of use and consistency. We measure the total path length and compute the grid distance between two adjacent points on the track. Additionally, we track any changes in the reward value during the training phase.
Validity
We utilize four algorithms to train learning on six dynamic obstacles, and Figure 7 records the experimental results. At the beginning AUV's action selection is randomized, it explores its surroundings and obtains reward values through random actions. In the previous rounds, the reward values are low, and as the number of training sessions increases, the reward values of AUV for various dynamic obstacles gradually increase. It is easy to see that the reward value of the IIFDS-DDPG algorithm increases but there is still a fluctuation of the reward value after learning, while the reward value of both IIFDS-PPO and IIFDS-TD3 algorithms tends to be stable (around 50). The overall stability of IIFDS-PPO is better than IIFDS-TD3, but the training time of IIFDS-TD3 is only a quarter of that of the IIFDS-PPO algorithm. The IIFDS-SAC algorithm can converge to a stabilization value, but the stabilization value is worse compared to the other three algorithms. Comparing the average rewards of the four algorithms for the six dynamic obstacles in each round is shown in Figure 8. It can be found that the IIFDS-PPO algorithm is faster and has the best overall stability, and the IIFDS-SAC algorithm stabilizes after finding an optimal solution, and the performance depends on the size of the optimal value found.

Training of four algorithms on six obstacles.

Average reward.
Results testing
Four dynamic obstacles are selected in the environment and the ocean currents are reset to simulate the four algorithms with the same parameters. The obstacle avoidance routes of the four algorithms are shown in Figure 9. All four algorithms can avoid obstacles and reach the target point accurately.

The obstacle avoidance routes of the four algorithms.
The AUV travel distances in the four algorithms are shown in Table 3, where IIFDS-TD3 has the shortest distance in operation, followed by IIFDS-PPO.
Final distance.

Variable speed multi-obstacle tests
In reality, the movement of underwater obstacles is usually variable speed and unpredictable. To address this unknown situation, a set of comparison experiments was included to test the feasibility of the algorithm by changing the speed of the dynamic obstacles from uniform to randomly refreshed at every step ranging from one-tenth of the AUV speed to three times the AUV speed, and keeping the rest of the experimental conditions the same as before. The test results are shown in Figure 10.

Variable speed dynamic obstacle test results.
The results of the variable speed dynamic obstacle test are shown in Table 4. The overall performance of the algorithm decreases compared to the uniform speed dynamic obstacle, but the results show that the algorithm is still effective in the face of obstacles with unknown speeds. The test results also prove that PPO is more stable than the other three algorithms and has the ability to face different dynamic obstacle environments.
Final distance.

It can be seen that IIFDS-PPO is more stable than the other algorithms, and IIFDS-SAC is not as effective as the previous three algorithms in variable speed dynamic multi-obstacle environments, and the reason for this is that the SAC algorithm is not very good at the task of training the optimal near-edge actions.
Algorithmic advantages
To demonstrate that the IIFDS-DRL algorithm is indeed superior in path planning, we compare the algorithm with three traditional path planning algorithms. Traditional algorithms often fail to reach target points in the presence of unknown currents and dynamic obstacles. To compare their performance, various static obstacle environments were established. The IIFDS-DDPG algorithm was chosen as the variant of IIFDS-DRL with a larger discrete dispersion.
The experimental conditions were consistent across the four algorithms, with results displayed in Figure 11. The traditional methods selected for this study include the A* algorithm, ant colony optimization (ACO), and the RRT algorithm. The A* algorithm extends Dijkstra's approach to identify the least costly path between two vertices in a graph, allowing traversal through various connected nodes, each with an associated edge cost. The Ant Colony algorithm, introduced by Marco Dorigo in 1992 in his PhD thesis, is a probabilistic method that finds optimized paths by mimicking the behavior of ants searching for food. Ants preferentially select paths with higher pheromone levels, creating a positive feedback loop. Meanwhile, the RRT algorithm is widely utilized in robotic motion planning, focusing on generating viable paths by randomly sampling and effectively exploring the environment.

Performance comparison between IIFDS and conventional algorithms.
The final distances of the four algorithms are shown in Table 5. The experimental comparisons clearly demonstrate that the algorithm proposed in this paper significantly outperforms traditional algorithms such as A*, RRT, and ACO in the domain of path planning. In various complex environments, the proposed algorithm in this paper consistently exhibits higher efficiency and superior path-planning capabilities.
Final distance.

Ocean current impact tests
Although ocean currents vary greatly in time and space across the vast ocean, their flow velocity and direction are relatively stable within certain specific sea areas. A stream function is defined to model non-circulating but time-varying ocean currents in these regions.
26
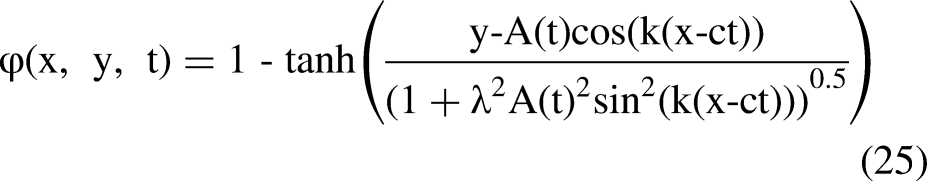

A spatial complex cyclic eddy is also established for path planning simulation studies. The current velocity in grid (x, y) is represented by 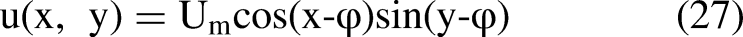


Ocean current impact tests.
Conclusion
In this paper, we present IIFDS-DRL, an AUV path-planning method that incorporates the effects of stochastic currents. First, we build a simulated underwater environment containing dynamic obstacles and then test it using IIFDS combined with four common deep reinforcement learning algorithms. The results demonstrate the superiority of the method. The ocean current information gives the IIFDS-DRL algorithm intelligence, and the multiple training of deep reinforcement learning gives the algorithm stability, which makes the AUV reach the target point accurately and quickly. However, there are still some problems, regarding the energy consumption of the AUV and the more complex situations in the real world are still issues to be investigated and overcome.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Teaching Research and Reform Project of Graduate Education of Tianjin Polytechnic University in 2022, 2023 Tianjin Polytechnic University University Teaching Fund Project, Tianjin Student Innovation and Entrepreneurship Fund Project in 2023 (grant numbers YBXM2207, KG23-06, 202310060036).