
Abstract
Rehabilitation devices such as actuated exoskeletons can provide mobility assistance for patients suffering from paralysis or muscle weakness. In order to improve the well-being of patients, the control design of exoskeletons is of paramount importance and highest priority. In this paper, we present a sliding reinforcement learning (RL) method control for an upper-limb exoskeleton, enabling it to learn following a desired trajectory in the Cartesian space. The deep deterministic policy gradient (DDPG) using an actor-critic architecture is employed to continuously adjust the non-singular terminal sliding mode control (NSTSMC) control inputs, based on previous experiences. The designed actor network learns the policy and the critic evaluates the quality of the actions chosen by the actor. The robustness of the proposed approach is studied when the system is subjected to random disturbances. The simulation results demonstrate that the proposed approach based on the RL method effectively fulfills exoskeleton tracking tasks. Moreover, a comparative analysis with the standard NSTSMC, computed torque (CT), and RL-based CT shows the superiority of the proposed approach in terms of position tracking error. These findings are further confirmed by various performance evaluation metrics.
Keywords
Introduction
Spinal cord injury
1
is one of the common causes of paralysis. It involves damage to the spinal cord which is responsible for receiving and sending signals between the brain and the rest of the body. As the injury cuts the connection between the brain and the part below the injury, it may lead to a tetraplegia which affects all four limbs of the body. For this reason, new rehabilitative techniques using robotic devices as exoskeletons have been proposed with the main aim of enhancing the quality of life of the affected patient. A comprehensive systematic review of the classification of upper limb robot devices and different control strategies has been presented in Narayan et al.
2
In this work, we are interested in the control of the upper-limb exoskeleton. In order to provide a passive arm movement therapy, the role of the control is to drive the system ensuring that the upper-limb exoskeleton reaches and maintains a desired position. For this purpose, various control approaches are proposed in the literature, we can classify them into two categories. The kinematic control strategies are non-model-based approaches and dynamic control strategies that consider the model of the system in the design of the control approach. The advantages of the kinematic control as proportional–derivative (PD),
3
proportional–integral–derivative,
4
and model free
5
are the simplicity and require less computational time. However, classical PD control laws are effective for systems with constant parameters, but they may be inadequate and less robust for nonlinear systems with variable parameters and varying dynamic characteristics. However, they may lead to poor performance and instability. Dynamic control as computed torque (CT),
6
sliding mode control (SMC),7–10 model predictive control,11,12 Feedforward-RISE,
13
and adaptive approaches14–16 are known for their robustness to variations in system parameters and external disturbances. However, they need more computation time, few studies consider the model of the upper limb and some control approaches may provide a high control input. Recent times have seen a diverse range of successes in reinforcement learning (RL) methods where video games are one of the most popular applications. RL is a branch of machine learning that was started in the 1950s by the British mathematician Turing
17
discussing the possibility of computers being intelligent. It represents methods that facilitate adaptive autonomy by allowing agents to autonomously learn policies that optimize rewards through interactions with the environment.
18
The idea was inspired by the sequential decision-making processes observed in living beings as humans and animals. Q-learning and its variant algorithms stand out as some of the most employed RL algorithms in the field of robotics and path planning. In Lin and Hwang,
19
a Q-learning process was used to consider kinematic constraints and maintain the balance of the biped robot during imitation. During the learning process, the robot determines its actions according to a learned policy then a reward function provides feedback for the robot’s actions, offering a positive or negative reward based on its state (maintain of loss balance) after performing the action. Another work based on Q-learning was proposed in Khlif et al.
20
for a path planning of mobile robot combining
Concerning exoskeleton robot control, there are few published works on this subject. In Yuan et al., 23 a method called dynamic movement primitives based on RL is designed to provide motion generation in a walking exoskeleton robot and to transform the trajectory from the Cartesian space to the joint space. The work proposed a Q-learning approach based on a polynomial neural network employed for estimating the Q-function in order to improve the control performance. Rose et al. 24 use the DDPG where the control torque inputs are learned for the exoskeleton hip, knee, and ankle joints directly from the observed joint information.
In contrast to earlier classical control approaches in control for rehabilitation robots, our study makes a significant contribution by introducing an enhanced nonlinear sliding mode controller that leverages the benefits of SMC and RL within the Cartesian space of manipulation. Our choice is selected according to the interesting aspect of SMC called the non-singular terminal SMC (NSTSMC). 25 This method is designed to guide the system states to a predefined set of sliding surfaces, making the closed-loop response insensitive to uncertainties in internal parameters and external disturbances. The work in Jellali et al. 25 presents a SMC for (upper-limb exoskeleton of Laboratoire Images, Signaux et Systèmes Intelligents (LISSI)) introduced in Cartesian space and designed for passive functional rehabilitation. This control law not only ensures the robustness and precision of the system control but also enhances the system’s convergence velocity by guaranteeing convergence of the system dynamics to the equilibrium state in finite time and with a significant reduction in a chattering phenomenon. The approach also eliminates the singularity problem associated with conventional terminal SMC. Our proposed approach based on DDPG can be considered as an extension of the contribution proposed in Jellali et al. 25 Moreover, we demonstrated the advantages of using the DDPG agent using another control approach, namely the CT method. The results showed an improvement in the system response despite the system being subjected to higher disturbances than those considered during the training process. The robustness of the proposed method is studied where evaluation metrics have been computed for four controllers namely, RL-based-NSTSMC, RL-based-CT (RL-CT), NSTSMC, and CT. This paper is organized as follows, section “Control of three degrees of freedom (3 DOF) upper-limb exoskeleton in Cartesian space” describes the general dynamic model of the exoskeleton and the non-singular SMC. In section “Reinforcement learning (RL)”, an overview concerning RL and the DDPG algorithm is presented, followed by a detailed description of our proposed approach. In the next section, simulation results and discussion are presented. In the last section, conclusion and future works are presented.
Control of three degrees of freedom (3 DOF) upper-limb exoskeleton in Cartesian space
To control an exoskeleton in passive rehabilitation, the planning trajectories in Cartesian space is often more convenient as the tasks involve specific end-effector trajectories such as following a line or a circle. Moreover, this makes it easier for the patient to interact with the robot.
In this section, we will describe the general dynamic model of the upper-limb exoskeleton (see Figure 1) in Cartesian space, followed by a concise description of the non-singular terminal sliding mode controller proposed in Jellali et al., 25 wherein the work of this paper can be considered as an enhancement of the approach.

Three degrees of freedom (3 DOFs) upper-limb exoskeleton: (a) kinematic diagram and (b) top view.
Exoskeleton modeling
The dynamic model of the upper-limb exoskeleton can be described as follows:

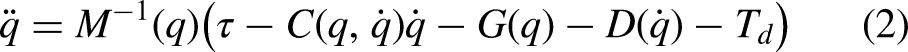

This yields:
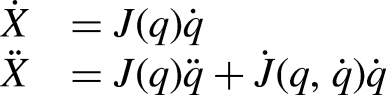
Non-singular terminal sliding mode controller
The design of the sliding mode controller involves a two-step process. Initially, a control law denoted by
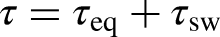

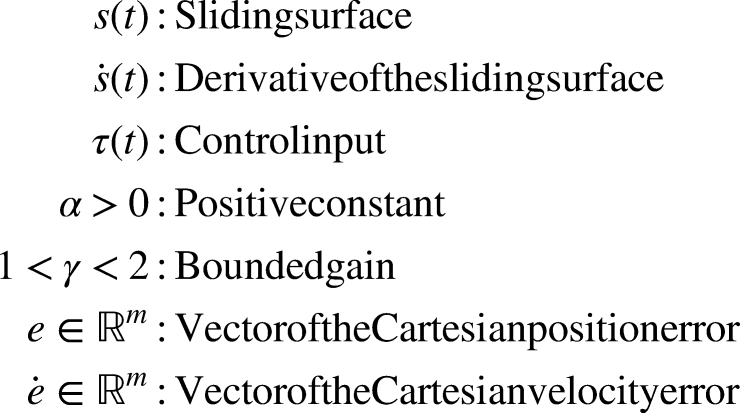


Figure 2 shows the general schema of the NSTSMC in Cartesian space. Tuning NSTSMC to achieve the desired performance in Cartesian space, by balancing between fast convergence and avoiding the chattering, can be a delicate and difficult task. In order to overcome the drawback of robust gains that may lead to a chattering effect when they are significantly larger than the external disturbance, it was necessary to adaptively adjust the control gains with respect to the external disturbance. This may be automatically accomplished by adjusting the input torque. In the next section, we will propose a new approach based on RL algorithm.

The bloc diagram of non-singular terminal sliding mode control (NSTSMC) in Cartesian space.
Reinforcement learning (RL)
In this section, we will provide a comprehensive overview of RL, followed by a detailed description of the DDPG algorithm that we intend to adopt in our proposed control approach.
Brief review
The problem of RL is supposed to be a simple formulation of the learning through interaction problem in order to achieve a goal. The learner and decision-maker are referred to as the agent. The environment is the entity with which it interacts, encompassing everything external to the agent.
26
The agent and environment interact constantly, where the agent chooses actions and the environment responds to these actions and presents new situations to the agent. The environment also gives rise to special numerical values namely rewards that the agent tries to maximize over time. The agent–environment interaction is present in Figure 3. The basic idea behind the RL, as explained in several references, is that at each time step

Agent–environment interaction.
The {state, action, reward} principle can be formulated as a Markov decision process (MDP) problem. MDP is defined as a mathematical framework for modeling decision-making. A Markovian decision process is described by:
State Reward function The transition state probability The discount factor Policy ( The value function ( The Q-value (
Algorithms of RL can be categorized into three classes namely (i) value-based as State-Action-Reward-State-Action and Q-learning agent, (ii) policy-based as policy gradient (PG) agents or (iii) actor-critic as proximal policy optimization, deep Q-network, DDPG. The first one learns optimal action-value function
Deep deterministic policy gradient (DDPG)
The DDPG is a model-free, online, off-policy RL algorithm. A model-free RL algorithm is when the agent learns to make decisions and take action without having an explicit model of the environment’dynamics describing how this latter will respond to its actions. The difference between off-policy and on-policy is that off-policy learning occurs when the agent learns from experiences generated by a different policy. In other words, the learning and target policies are different. On-policy learning, on the other hand, involves learning from experiences generated by the current policy that is being optimized. A DDPG agent is an actor-critic RL agent that searches for an optimal policy that maximizes the expected cumulative long-term reward. The summary of training steps is presented by the following main steps and summarized on the DDPG Algorithm 1.
Initialize the actor and critic networks with random weights. Initialize a replay buffer to store experiences. At every time step, the DDPG adjusts the properties of the actor and critic. It records previous experiences using a circular experience buffer. Select an action using the current policy (actor network), adding exploration noise to the action. Execute the action in the environment, observe the reward and next state. Store the experience tuple (state, action, reward, next state) in the replay buffer. If the replay buffer has enough experiences, sample a mini-batch of experiences randomly from the buffer. For each experience in the mini-batch:
Update the critic network by minimizing the critic loss. Update the actor network using the PG to maximize the expected discounted reward. Update the target actor and critic network Repeat the process for a set number of episodes or until convergence.
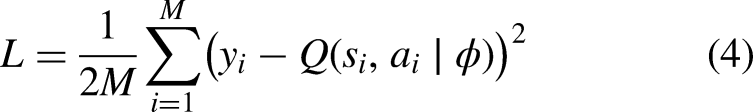
The pseudocode of DDPG algorithm

The proposed approach
The problem of rehabilitation control is transformed into an optimal control problem, aiming to design an iterative controller to ensure that the exoskeleton’s motion trajectory is capable of following the desired training movement. Integration of RL with SMC might be beneficial in control systems where RL is used to adapt and learn the optimal control policy while SMC control provides robustness and external disturbance rejection. In SMC, accurate mathematical models of the upper-limb exoskeleton are often required. RL algorithms, in contrast, can operate with less precise dynamic models and in cases where the system dynamics are not fully known. This aligns with our control case, as the model of the exoskeleton may be known a priori, but the model of the upper limb may not be. The task of RL in a continuous action space MDP can be defined as a tuple of states, actions, transition probabilities, policy, rewards, and discount factor

Bloc diagram of the proposed approach.
State space representation
In this case, the DDPG agent receives a state observation 
Reward
The reward function, R, plays an important role in RL as it provides evaluative feedback for the system to learn the optimal policy. A well-designed reward function can not only expedite the learning processes but also enhance the quality of learning. Therefore, it is highly important to design an appropriate reward function. In this approach, a method for immediate reward for the studied robotic system is proposed. Based on the characteristics of the tracking control for the exoskeleton, the immediate reward at time step 
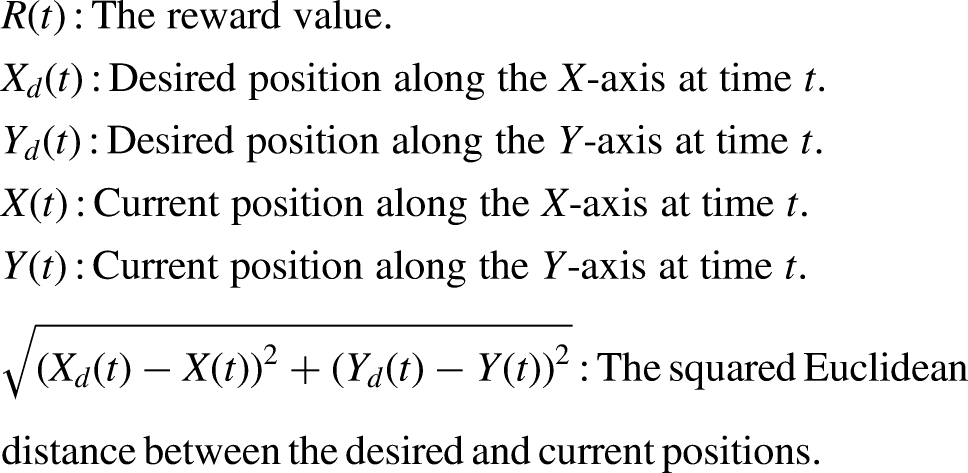
Action space representation
In this application, we opt for RL to autonomously adapt the amplitude of the SMC input, represented in section, denoted by 

DDPG architecture
The DDPG model is implemented using the RL toolbox of Matlab Math work. Training and agent options and hyperparameters are adjusted as indicated in Tables 1 and 2. The critic and actor networks are depicted in Figure 5. The architecture of the critic network involves fully connected layers, rectified linear unit (ReLU) layers, combining the information from the state and action paths, ultimately leading to a single output representing the Q-value of the critic. The input layer expects input data of size

The critic and actor networks.
Parameter settings of both training and agent.

Parameter settings of critic and actor modules.

The architecture of the actor network takes observations as input and produces continuous actions as output. It consists of fully connected layers with ReLU activation functions and a final layer with a hyperbolic tangent (tanh) activation to map the output to a bounded range. The created actor is a deterministic actor representation using a specified network. Firstly, the input is represented by an input layer for the observation of size
Results and discussion
In this section, training and test results are provided. The training duration for
The description of the scenario: before the training process, a uniform random noise is added for
Training results
The evolution of the reward and average reward are depicted in Figure 6. The average and episode reward vary significantly during the initial episodes of training as the agent is learning from experiences. This variation is a known step of the RL process, where the agent initially explores the environment to gather information before gradually shifting toward exploiting the knowledge it has gained to maximize rewards. During these early episodes, the agent undergoes both exploration and exploitation phases, which are critical for effective learning. Exploration allows the agent to try out different actions to discover their effects and gather diverse experiences, leading to fluctuations in the rewards obtained. On the other hand, exploitation involves using the acquired knowledge to select actions that are expected to yield higher rewards, contributing to more stable and increased reward patterns over time. We can notice the episodes where there is a clear distinction between exploration and exploitation by analyzing the reward trends and trajectories. In episodes dominated by exploration, the trajectories may appear more unstable as the agent tests various actions, while in exploitation episodes, the trajectories tend to be more focused and directed toward the goal.

The evolution of episode and average reward.
This behavior is verified by plotting the trajectories of some episodes, as depicted in the trajectories paths in Cartesian space (

Trajectory per episode.
A clearer view of the agent’s performance and learning progression is presented in Figure 8, which illustrates the evolution of the Cartesian tracking error per episode. This figure highlights the changes in tracking accuracy over time, showing how the agent’s performance improves as it learns. We can notice that the best results are obtained in the last episodes of training, where the tracking error converges rapidly to zero, indicating that the agent has effectively learned to follow the desired trajectory with minimal deviation. In contrast, during the exploration process, illustrated by episodes 1, 100, 184, and others, the tracking error is significantly higher. This poor tracking is a reflection of the agent’s exploratory actions, where it prioritizes learning over immediate performance. As training progresses and the agent transitions from exploration to exploitation, the tracking error decreases, demonstrating the agent’s improved capability to perform the task accurately. This progression demonstrates the importance of the exploration phase in the learning process, allowing the agent to acquire the necessary knowledge to achieve optimal performance in later stages.

Evolution of tracking error per episode.
To sum up, some episodes may yield lower rewards, while others display an upward trend in episode rewards. Based on the reward structure in our approach, higher rewards signify that the actual trajectory is closer to the desired one. When this occurs, the agent is in an exploitation phase; otherwise, it is engaged in exploration.
Simulation results and comparative study
In the test process, a comparative study is conducted between four control approaches. The first controller is the CT approach. The control design of CT is presented in the Appendix. The second controller proposed by Jellali et al. 25 is the NSTSMC presented in section “Non-singular terminal sliding mode controller.” In the third and fourth schemes, we used the RL approach to adapt both control input signals for the CT and NSTSMC approaches. The fixed control gains for both approaches are summarized in Table 3. The simulation time is equal to 120 s for all controllers.
Control gain setting.

CT: computed torque; NSTSMC: non-singular terminal sliding mode control.
To validate the effectiveness of control approaches, a higher random noise within the interval [
Random noise included after training for all controllers.
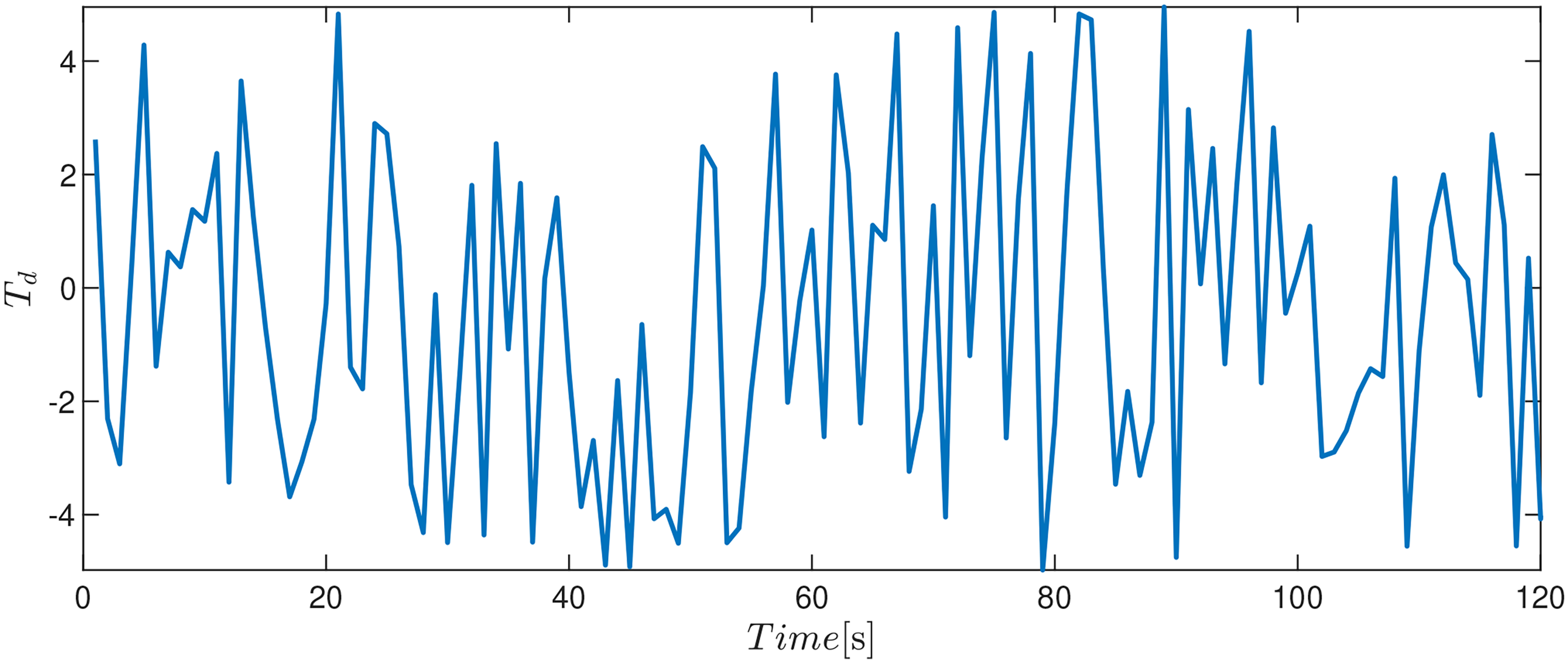
In this section, a comparative study is presented under the same parameters and initial conditions. All controllers are compared for the case of disturbance rejection. We selected desired trajectories different from that used in training where 

Comparative study between non-reinforcement learning (RL)-based methods and RL-based methods.

Cartesian coordinates and position errors of non-reinforcement learning (RL)-based methods and RL-based methods.
Summary of computed metrics.

CT: computed torque; RL: reinforcement learning; NSTSMC: non-singular terminal sliding mode control; ISE: integral squared error; RMSE: root mean square error; ITSE: integral time-weighted square error; IAE: integral absolute error.
Conclusion
In this paper, we propose an RL-based sliding mode approach to control a 3DOF exoskeleton. By interacting with an environment, the proposed DDPG agent provides an action in the exoskeleton to adjust the gain of the non-singular SMC by automatically adjusting the control input signal. Simulation results of the proposed approach have shown promising results. The proposed approach RL allows the upper-limb exoskeleton to adapt to changing environments and conditions and perform well, even in the presence of high random disturbances. An enhancement has been achieved compared to the original NSTSMC approach. Based on several performance evaluation metrics, we also demonstrated that this approach is effective even when replacing the controller with another one, such as the CT method. Future work may be extended to active rehabilitation by performing a collaborative task between the patient and the exoskeleton using a multi-agent approach.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.