
Abstract
Teleoperation has become increasingly important for the real-world application of robots. However, in current teleoperation applications, operators need to visually recognize any physical deviations between the robot and themselves and correct its operation accordingly. Even when humans move their bodies, achieving high positional accuracy can be difficult for them, which can limit their speed of movement and place a heavy burden on them. In this study, we proposed a parameter optimization method for feedforward compensation of the link-length deviation and operator's habitual body movements in leader–follower control in 3D space. To optimize the parameters, we used Digital Annealer developed by Fujitsu Ltd, which could rapidly solve the combinatorial optimization problem. The objective function minimized the difference between the hand positions of the robot and targets. Simulations verified that the proposed method could reduce hand positional differences.
Introduction
Over the past few decades, the demand for robotic teleoperation applications in various sectors has increased, from industry to service robotics.1–3 Robotic teleoperation can be useful in complicated environments—including those with humans—because it can be difficult for robots to recognize the environment adequately, avoid collisions with furniture and humans, and automatically perform tasks.
Several studies have been conducted to improve robotic teleoperation. For example, controllers have been used to measure the target values of robots,4–7 some methods calculating joint angles by performing inverse kinematic calculations on the robot using the positional and posture information of a hand-held controller to manipulate the robot.8–10 These studies focused on the operability of the hand position, which was an important functional approach and was easy to implement. Wang et al. investigated the reaction times between joint-space and task-space commands using an exoskeletal motion-capture device. They confirmed that most subjects adapted to task-space mapping faster than to joint-space mapping after similar levels of practice. 11 However, because only the hand position and posture could be controlled, it was impossible to move only the elbow position to avoid obstacles in front of the target. To improve operability, it was necessary to consider the movements of the operator links and joints. Consequently, leader–follower controllers—known as master–slave controllers—have been used in various teleoperation applications. Here, the link positions, orientations, and joint angles of operators are measured using a motion-capture system or an inertial-measurement unit, the measured motions being used as robotic commands.12–15
However, in a conventional leader–follower controller, the operator must pay careful attention to the robot's movement, visually recognizing the robot's movement and modifying it sequentially. This can cause operator fatigue. Additionally, the speed of motion cannot simply be increased because of the delay in the robot's motion (as directed by operator) and the delay in the camera image used by the operator to recognize the robot's motion.
Owing to two types of gaps, an operator may have to observe the robot's movements. One is the gap in the number of joints, size, and speed of movement between the robot and the operator. If a robot is of similar size and has the same number of joints as an operator, the operator can easily control it. However, a humanoid robot of similar size and with the same number of joints as an operator can be extremely complex and expensive, making it difficult to introduce such a robot into the real world. The second gap is that between the operator's body image and the actual body when the operator moves their own body. Even when an operator moves their body, achieving high positional accuracy can be difficult without visual feedback. For example, when operators move their arms 30° to the right from the front without visual feedback, their arm tending to shift by a few degrees. In this study, we refer to this gap between the operator's imaginary position and the actual position of the operator's fingertip as a habitual movement.
In practice, only structural differences have been studied, and the compensation for habitual movements has not been studied. To compensate for the difference in the number of joints between an operator and a robot, a matching technique that reflects only the movements of the dominant joints in the movements of the robot joints has been used. 16 This method has also been employed in the operation of virtual reality characters. 17 Furthermore, if the link size of the operator and robot differ, extending an arm to a certain target can cause the operator and robot to adopt different hand positions, reducing operability. Nakamura et al. proposed a self-body image update method for augmented reality and investigated how operators learned body-link lengths. 18 Regarding the difference in the size of an operator and a robot, a method for measuring the link size of the operator in advance and reflecting it at the time of operation has been reported. However, considerable time and effort were required to perform these measurements in advance. 19
Some researchers have proposed a parameter optimization method for correcting differences in the link length of a robot and an operator for feedforward compensation in a leader–follower controller that synchronizes the robot with the movement of the operator. 20 To correct for the differences in link length between the operator and 2-joint 3-link serial robots, the shoulder and elbow joint angles were measured when the operators stretched their own hands to a predetermined target hand position. A target function was set to minimize the difference between these hand positions, such that the hand position normalized using the total arm length of the robot was equal to that normalized using the total arm length of the operator. After converting the minimization problem to a quadratic unconstrained binary optimization (QUBO) problem, optimization calculations could be performed.
However, when teleoperating a commonly used serial-link robot to optimize the parameters established for each joint angle, the hand position can involve a complex equation (potentially exceeding the third order) as the number of joints increases, making optimization using the QUBO method difficult. Additionally, because it can only be optimized for one type of preliminary motion in a 2D plane, robotic teleoperation requiring positional accuracy at multiple hand positions—such as the initial position of the object and the location of the object when the robot grasps it and places it in another location—is not possible. However, if optimization can be performed by simultaneously considering the preliminary movements of multiple target hand positions, the robot's hand positions will be closer to those intended by the operator. Furthermore, because the proposed method matches the target hand position with the operator's hand position when the operator performs a preliminary movement, even if the operator's hand position differs from that of the target owing to the operator's habitual movements, the target hand position can be achieved if the operator performs a habitual movement. If the proposed method could provide parameters that automatically compensate for such habitual motion, the load on the operator can be reduced.
In this study, we propose an optimization method for compensation parameters that decreases the influence of the operator's habitual movements and misalignment of the link length between the robot and operator when the robot is controlled in 3D space. Specifically, the compensation parameters were obtained by solving an optimization problem to minimize the deviation of the robot's hand position from the target hand position. By reflecting the optimized set of compensation parameters in real-time, the robot could be controlled as expected through natural motion without requiring visual feedback, thereby reducing the operator's mental burden and need for practice during operation (Figure 1).
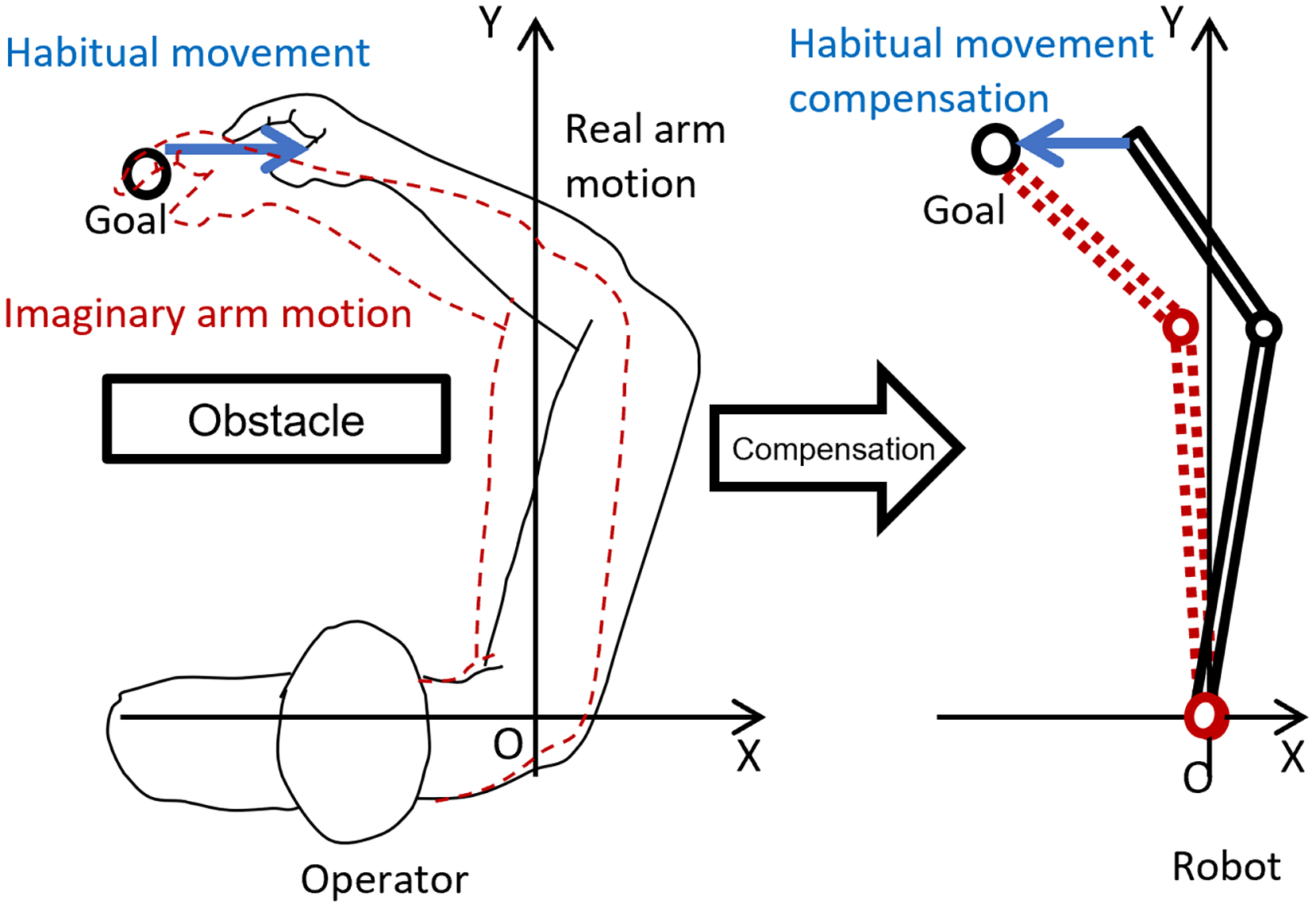
Schematic view of the proposed method. With the compensation parameters optimized by preliminary operations, the proposed method decreased the gap of the robot hand position to the target. The gaps are influenced by link length differences between an operator and a robot, and habitual movements—that is, the displacement between the operator's imaginary position and the actual position of the operator's fingertip.
Methods
Optimization framework to compensate for habitual movements
The proposed method comprises the following steps:
Preliminary operations for measuring habitual movement by comparing the predetermined target position and operator hand position. Compensation parameter optimization to minimize the impact of habitual movements. Teleoperation using the compensation parameters.
Compensation parameters multiplied by the hand position which are normalized by the operator's arm length was formulated. And the compensation parameters are used with the normalized hand position command value of the robot. To determine the compensation parameters before teleoperation, the operator performed a preliminary operation to create a dataset for the operator-normalized hand position relative to the operator's target-normalized hand position. Subsequently, the minimization problem of the difference between the operator's target-normalized hand position and the robot's target-normalized hand position could be solved to ensure that a parameter search was performed. This parameter mapped the operator-normalized hand position to the robot-normalized hand position in the 3D space.
Consider multiple targets—that is, hand movements—to connect each target position. For example, if two targets are considered, mapping can be performed to map a hand movement that connects two points using a straight line. When transforming multiple hand positions, it is necessary to compensate for the fact that the distance between the hand positions of the operator normalized by the arm length of the operator may differ from that of the target position. Additionally, even if the distance between multiple positions is accurate, if any hand position deviates from the target, it is necessary to shift the starting point of the hand movement to match this deviation. Consequently, the transformation equation in the X-direction can be expressed as follows:

In this study, the X-direction is referred to as the left/right direction, the Y-direction as the front/back direction, and the Z-direction as the up/down direction. Equation (1) can be used to perform independent calculations in each of the three directions of the robot's target-normalized hand position to correct the positions in each direction in the 3-D space, expressed as follows:

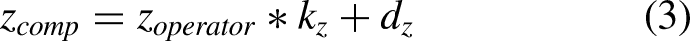
Implementation of Digital Annealer
Various parameter optimization methods have been proposed. The problem addressed in this study was the optimization of a combinatorial problem of the gain and offset parameters established to calculate a robot's target hand position in 3D space. Because it is comparatively fast and less likely to fall into local minimums, we used a new technology—that is, Digital Annealer, developed by Fujitsu Ltd—which could solve the combinatorial optimization problem quickly using a computational method that mimicked quantum annealing.
21
Using a digital circuit design inspired by quantum phenomena, Digital Annealer focuses on rapidly solving complex combinatorial optimization problems without the added complications and costs typically associated with quantum computing methods. This enables faster computation of QUBO than conventional methods, such as simulated annealing.
22
To describe the combinatorial optimization problem, the QUBO model can be expressed as follows:

In this study, the error between the target value of the hand position and the current value of the robot was minimized because the compensation parameter was set within a finite range. To achieve this, optimized compensation parameters were selected from this range. Moreover, the QUBO model was developed as a simplified model to handle compensation parameters based on the objective function and constraints. The objective function (

In equation (5), each gain and offset parameter can be discretized. In this study, the coordinates were set at the shoulder joint. To consider hand movements that have positive or negative changes, the hand position of the operator can be offset by the arm length of the operator, which can measure the hand position during arm stretching. In this study, the hand positions in the X- and Z-directions were offset. Therefore, equations (1)–(3) can be rewritten and expressed as follows:





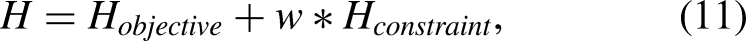
The translation from the optimization problem to the QUBO model comprises the following steps:
Formulate the energy function. Encode the integer variables with binary variables. Obtain the QUBO matrix from the coefficients.
Programming QUBO models for Ising machines can be difficult if the energy function is complicated, as equation (11) must be translated. To construct the QUBO model using equation (11), we used PyQUBO as the Python library.
23
Using this library, programming could be practically identical to the shape of the equation constructed using Steps (2) and (3). Consequently, users only construct an objective function. Digital Annealer was then used repeatedly for several iterations to minimize the energy of the model, solve the problem using the QUBO model, and determine the compensation parameters.
Experimental results
Simulation conditions
In the simulations, compensation parameter searches using Digital Annealer were performed on the prepared datasets at two points as a preliminary operation. The parameters used for Digital Annealer are summarized in Table 1.
Digital Annealer simulation parameters.

The number of iterations affects the time required to find the globally optimal solution without falling into a locally optimal solution. In the simulation, the number of iterations was set to 1,000,000 to find the optimal global solution. Moreover, Digital Annealer can increase the probability of obtaining an optimum solution. If no bit-flip candidate is found, escape from a local minimum state is facilitated by adding a positive offset to the energy. 21 To decrease the calculation time, the number of iterations and implementations in Digital Annealer must be increased. Consequently, the robot target-normalized hand position calculated using the obtained compensation parameters was then applied to the robot model, and each joint angle of the robot was calculated and driven using inverse kinematic calculations.
Link size compensation simulation
Through simulations, we verified whether the proposed method could be used for 3D spatial teleoperation fitting that did not require prior measurements of each link length of the operator. For example, if the operator moved their hand to the target-normalized hand position, similar to the preliminary operations, two sets of motion data were generated from the starting point to the goal point of the motion as both preliminary motions and teleoperation tasks. Optimization calculations were then performed for each motion. Simplified arm models of an operator and a robot were constructed, the average length of the operator's upper arm and forearm being 300 and 240 mm, respectively, the forearm length being approximately 80% that of the upper arm. 24
The robot arms were set to 300 mm for the upper arm and 150 mm for the forearm so that the link length ratio of the upper arm to the forearm was different from that of the operators. In parameter optimization, the operator hand position data in the prepared dataset were normalized using the total arm length calculated from the hand position when the operator extended their arm straight, and the operator-normalized hand position was used.
The experimental results summarized in Tables 2 and 3 show the obtained compensation parameters, target hand positions, robotic hand positions without compensation, and robotic hand positions when the compensation parameters were used for each dataset. The results of each simulation are shown in Figure 2. Under all experimental conditions, the robotic hand position is several cm away from the target without compensation; however, with compensation, the gap is reduced to approximately one cm. It is evident that the parameters obtained using the proposed method can be used for teleoperation at both target points with a high hand positional accuracy.

Simulation results of the link size compensation experiment. In each simulation, the left-hand graph shows the result for the start point, the right-hand graph showing the result for the goal point. The yellow point indicates the target position of the robot hand. The green links indicate an operator arm. The blue links indicate a robotic arm without compensation. The red links indicate a robotic arm with compensation.
Obtained compensation parameters.

Results of simulations with and without compensation.

Simulations to compensate for the habitual movements of an operator in 3D space
We verified, through simulations, that the proposed method could automatically compensate for inaccuracies in hand position caused by the operator's own habitual movements when moving their own body to control the robot. As in the previous experiment, we prepared the target motion and the operator's hand position coordinate data assuming that the operator moved their own hand in relation to the target-normalized hand position.
The optimization calculations were performed for each of five sets—that is, the operator-normalized hand position did not deviate from the target-normalized hand position at either of the two points; a deviation of 5% occurred to the right at both points; both points were 10% off to the right; one of the two points was 5% off to the right and the other was 5% off to the left, and one of the two points was 10% off to the right and the other was 10% off to the left. The operator model, robot model, and experimental methods were the same as those used in the previous experiments.
The compensation parameters and experimental results obtained are listed in Tables 4 and 5, respectively. The results of each simulation are shown in Figure 3.
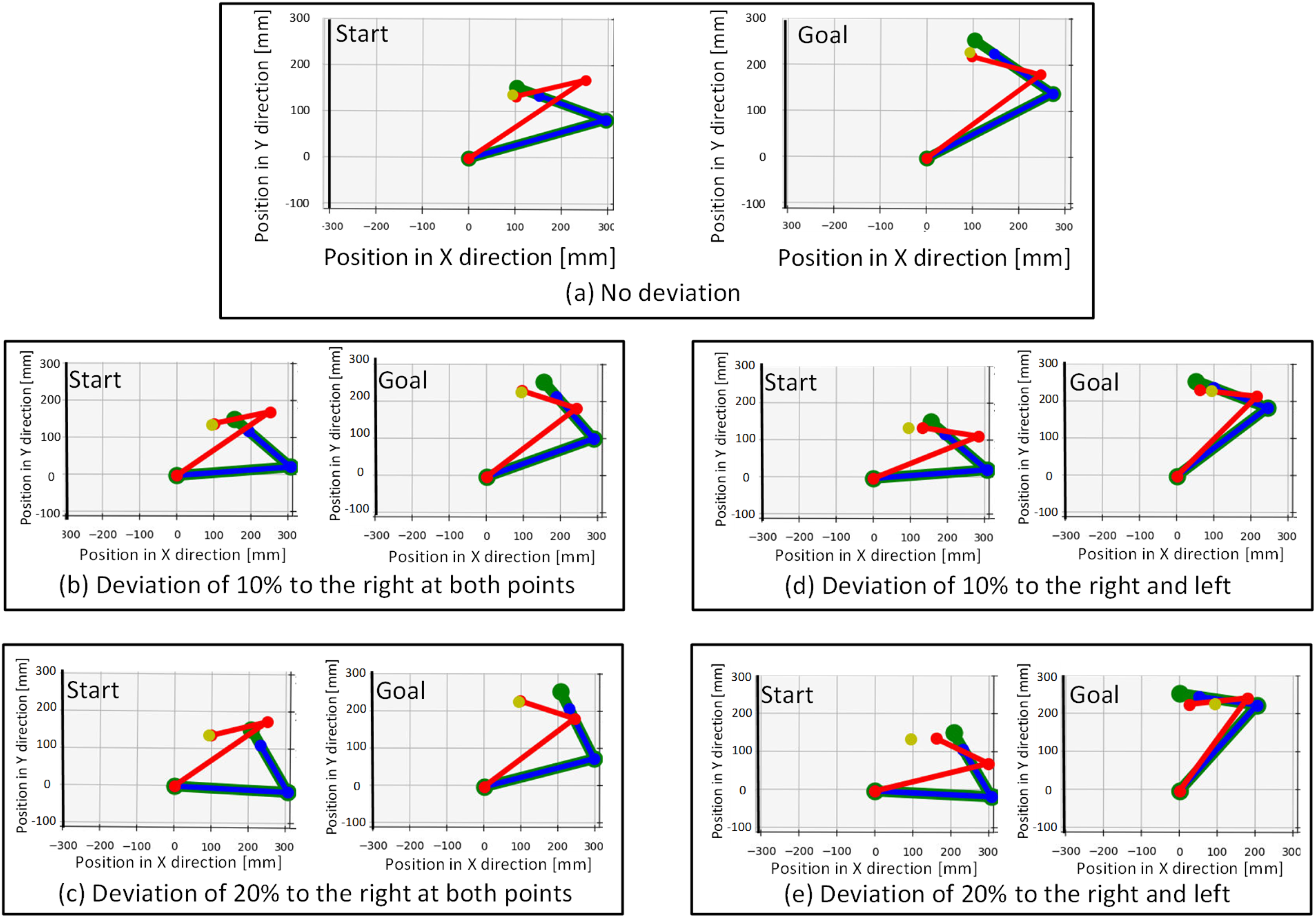
Simulation results of compensation for habitual movements in the horizontal plane. In each simulation, the left-hand graph shows the results for the start point and the right-hand graph shows the results for the goal point. The yellow point indicates the target position of the robotic hand. The green links indicate an operator arm. The blue links indicate a robotic arm without compensation. The red links indicate a robotic arm with compensation.
Obtained compensation parameters for habitual movements.

Simulation results of compensation for habitual movements.

Experiments to compensate for the habitual movements of operators
We verified that the proposed method could compensate for inaccuracies in hand position caused by the operator's own habitual movements. The motions of three subjects were measured using Microsoft Azure Kinect as a motion capture. Optimization calculations were performed based on average of the measured data with respect to the motion targets, and the robot command values were obtained by adapting the obtained parameters to the operator's motions. The robot model and experimental methods were the same as those used in the previous simulations.
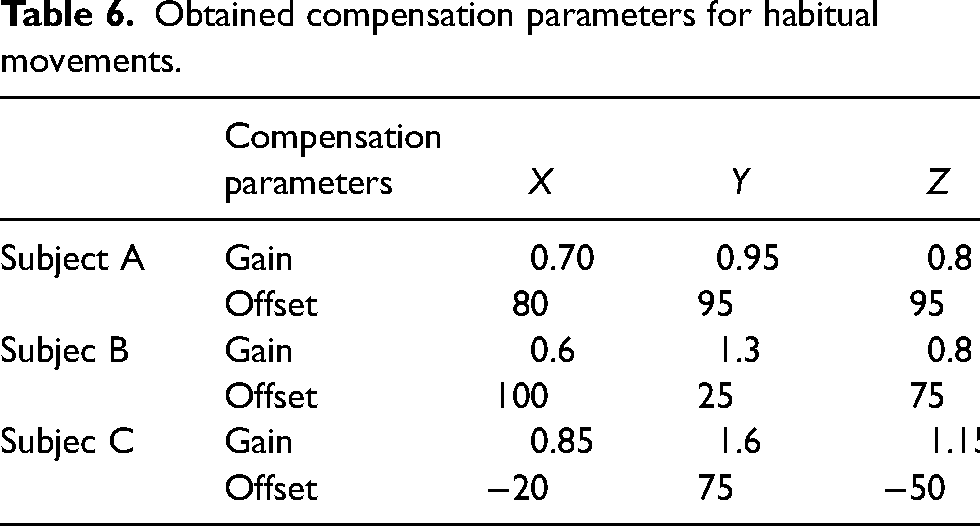
The compensation parameters and experimental results obtained are listed in Tables 6 and 7, respectively. The experimental results of one of the subjects are shown in Figure 4. As indicated by the displacement of the operator motion relative to the target position, the operator motion does not always reach the position desired by the operator in the brain because the operator motion involves habitual movements. Thus, the motion of the robot without compensation, which only uses the operator motion data, has a large displacement from the robot's target. On the other hand, the compensated robot motion is confirmed to be closer to the robot target.
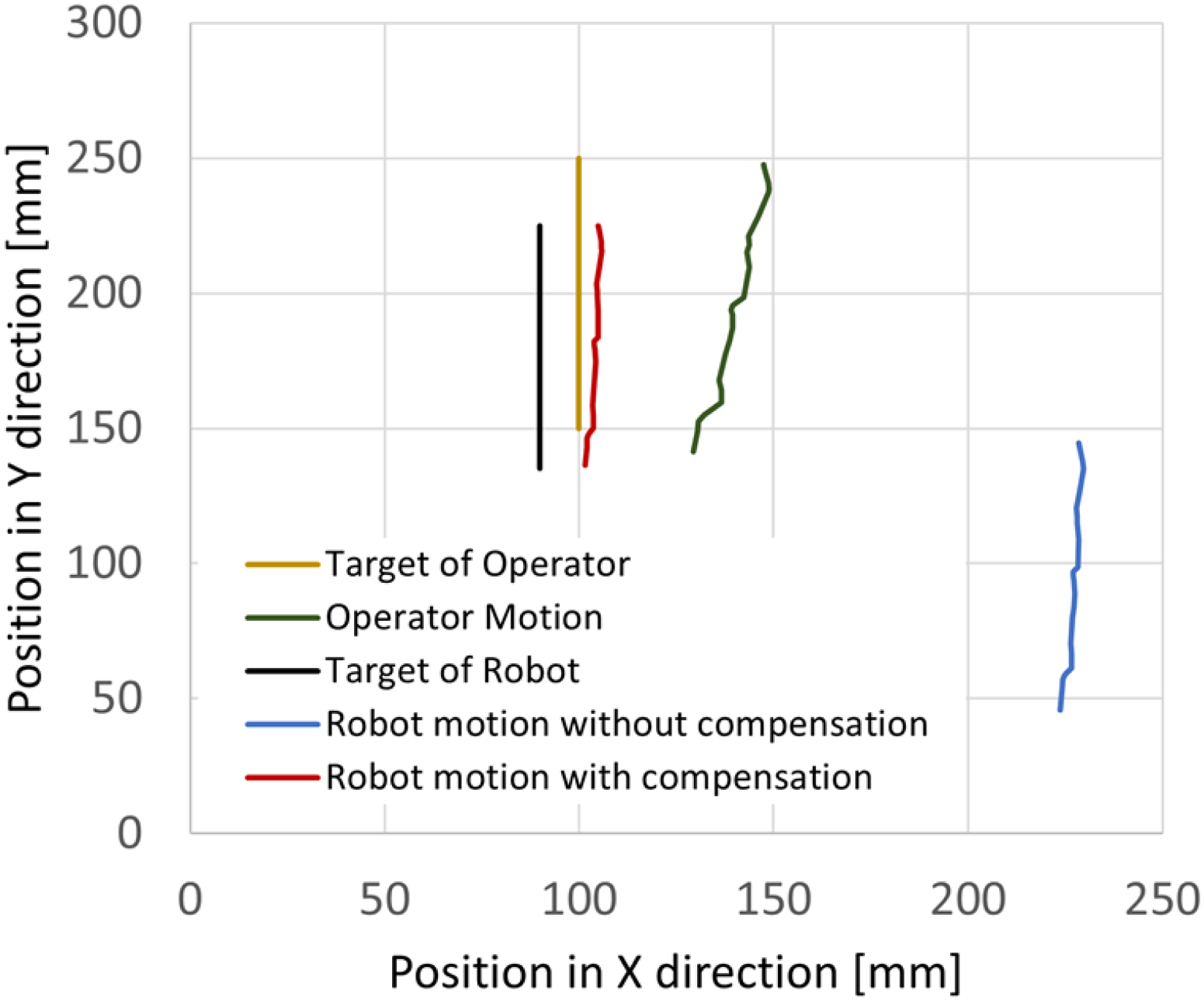
Experimental results of compensation for habitual movements in the horizontal plane.
Obtained compensation parameters for habitual movements.
Results of experiments with and without compensation.

Discussion
The proposed method could bring the robot's hand position closer to the target, even when the operator's hand position was incorrect relative to the target because of the operator's movements. However, if the direction of habitual movement was different for the target and the operator's hand positions at the two points, some positional errors remained, as the compensation parameters used in this study were gain and offset. Coordinate transformations using gain and offset values are part of the affine and homographic transformations frequently used in coordinate transformations. Moreover, a low number of parameter terms does not allow for deformations (such as rotation)—consequently, when two targets were used in this simulation, compensating for the slope of the line connecting the two target points and the line connecting the two robotic hand positions was not possible. Coordinate transformations that are more complex (including rotational and shear deformation) can be achieved by adding more parameters to the optimization calculations.
Various optimization, reinforcement learning, and deep learning techniques have been used in teleoperation to achieve high operability.25–27 In this study, we mainly focused on compensating for habitual movements, not the optimization techniques. Therefore, a comparison of the calculation overhead and accuracy with other methods could contribute to the field of robotic teleoperation applications.
Conclusions
Two main contributions of this study are as follows:
First, we proposed a parameter optimization method that automatically compensated for the differences in the link size and structure of an operator and robot when teleoperating a robot in 3D space. With existing leader–follower controllers, there have been cases in which the robot could not be controlled as intended by the operator owing to differences in the size and number of joints of the robot and operator. A previous study by the authors was limited to the horizontal plane and used a method to set compensation gains for the joint angles of a 2-joint robot. Hence, it could not be used to control an articulated robot in 3D space. However, the method proposed in this study did not optimize the joint angle. Instead, it optimized the hand positions in each direction in 3D space using compensation gains and offsets. Hence, it could be used in 3D space. Furthermore, differences in the robot structure could be compensated for by providing the robot with an optimized robot target position, performing inverse kinematics calculations within the robot. Consequently, the proposed method could be used regardless of the number of joints in the robot.
Second, the leader–follower controller automatically compensated for the operator's habitual movements when controlling the robot. The proposed method optimized the pose assumed by the operator while performing preliminary movements via teleoperation. Therefore, the operator was not required to hold the exact pose the robot was required to hold, enabling the operator to control the robot easily by considering their own physical operational habits. Consequently, a high degree of operability could be maintained, such as when operating a robot in an environment with obstacles and reaching a position that was blocked by an obstacle and was not visible to the operator. Since the operator does not need to recognize and adjust the position of the robot hand, it is expected to be easier to control the robot in environments with long visual delays, such as remote control in outer space. Moreover, the proposed method would be useful for teleoperation for reaching to objects which move fast because the proposed teleoperation does not need the visual feedback for an operator.
In the future, we aim to compare the calculation overhead and accuracy of the proposed optimization method with those of other methods and verify the operability and operator burden using the proposed method.
Footnotes
Acknowledgments
This study was conducted with the support of the Research Institute for Science and Engineering, Waseda University; the Human Performance Laboratory, Waseda University; the Future Robotics Organization, Waseda University; and as part of the humanoid project at the Humanoid Robotics Institute, Waseda University. It was also financially supported in part by the JSPS KAKENHI Grant No. 21K17832. We thank all of these for the financial and technical support provided.
Data availability
All data analyzed in this study have been included in the published article. Specific datasets are available from the corresponding author upon request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Japan Society for the Promotion of Science (grant number 21K17832).