
Abstract
Although advancements in red–green–blue-depth (RGB-D)-based six degree-of-freedom (6D) pose estimation methods, severe occlusion remains challenging. Addressing this issue, we propose a novel feature fusion module that can efficiently leverage the color and geometry information in RGB-D images. Unlike prior fusion methods, our method employs a two-stage fusion process. Initially, we extract color features from RGB images and integrate them into a point cloud. Subsequently, an anisotropic separable set abstraction network-like network is utilized to process the fused point cloud, extracting both local and global features, which are then combined to generate the final fusion features. Furthermore, we introduce a lightweight color feature extraction network to reduce model complexity. Extensive experiments conducted on the LineMOD, Occlusion LineMOD, and YCB-Video datasets conclusively demonstrate that our method significantly enhances prediction accuracy, reduces training time, and exhibits robustness to occlusion. Further experiments show that our model is significantly smaller than the latest popular 6D pose estimation models, which indicates that our model is easier to deploy on mobile platforms.
Introduction
Six degree-of-freedom (6D) object pose estimation aims to estimate the rigid transformation from the coordinate system of an object to the coordinate system of the employed camera. It is one of the core steps used in a wide range of robotic tasks, such as grasping objects 1 and operating tools. 2 A key challenge in 6D object pose estimation is occlusion, where objects of interest are partially or fully hidden, hindering accurate pose estimation due to missing or obscured features. Handling such common real-world scenarios is vital for robust pose estimation models. The occlusion problem has been historically approached in various ways. Early methods3,4 relied on local feature matching, which could handle occlusion to some extent but was limited by viewpoint changes and performed poorly on texture-less objects. With the rapid development of deep learning in computer vision, several works use convolutional neural networks (CNNs) on red–green–blue (RGB) images to solve the occlusion problem. Two main categories of approaches have been developed: one-stage5,6 and two-stage methods.7–9 The former methods directly regress the 6D pose of an object from input images, and the latter methods first establish three-dimensional to two-dimensional (3D to 2D) correspondences and then use the Perspective-n-Point (PnP) algorithm to calculate the 6D pose of the object of interest. Two-stage methods generally have stronger robustness to occlusion, with a representative method being Pixel-wise Voting Network (PVNet). 7 It first uses a CNN to predict the directional vector from each pixel to the key points. Then it acquires the positions of the key points through vector voting. This voting mechanism enables it to learn the relationship between different parts of an object, thereby allowing occluded key points to be reliably recovered by visible parts. Despite having higher accuracy than traditional methods, these RGB-based methods have limited performance in occlusion scenes due to their lack of depth information.
With the emergence of consumer-level RGB-depth (RGB-D) cameras, more recent approaches have turned to using RGB-D images to address this problem. Incorporating depth information enables these methods to outperform those that only use RGB images in occluded environments. Early works10–12 use depth information to refine previous estimations with the iterative closest point (ICP) algorithm or directly use depth information as an additional channel in their network architectures for RGB images. However, ICP is time-consuming, and due to the difference between the depth feature space and the color feature space, the depth information is not fully utilized. More recently, DenseFusion 13 uses different networks to extract color and geometry information and then densely fuses the extracted results at the pixel level to perform pixel-wise pose estimation, achieving great performance. However, this approach merely extracts features from each point individually, discarding the local information in the point cloud. Furthermore, Zhou et al. 14 and He et al. 15 used PointNet++ 16 to extract the local geometric features of the object, but all neighbor processing operations in PointNet++ are isotropic, which limits the geometric feature extraction performance of the network. Although the decent achievements of 6D pose estimation methods based on RGB-D images, a persisting challenge lies in effectively leveraging the color information in the RGB images and the geometric information in the depth images. Indeed, this represents a pivotal aspect in tackling the 6D object pose estimation under occlusion conditions.
Another challenge faced by deep learning-based 6D pose estimation algorithms is that they often have many model parameters and high computational complexity, which limits their deployment on mobile platforms with limited computing resources and small storage spaces. In addition, these methods often require hundreds of epochs to converge, which increases their time costs in practical applications.
In this paper, we introduce an end-to-end 6D object pose estimation method with a two-stage feature fusion module that can efficiently leverage the color and geometry information in RGB-D images. We find that when observing an object under heavy occlusion, human beings can simultaneously perceive the object’s appearance and geometric information and infer the whole pose from a local part. Therefore, we first extract color features from RGB images and integrate them into the target point cloud to obtain a point cloud with rich appearance information. Then, we process the point cloud with an anisotropic separable set abstraction network (ASSANet)-like network to obtain some local features and one global feature. The global feature is concatenated with each local feature to obtain the fusion features, and each fusion feature independently predicts the 6D pose with an associated confidence score. We choose the pose with the highest confidence as the final output. Finally, the pose is further improved via the iterative refinement module in Wang et al. 13 To further reduce the model size, we design a lightweight network based on a changed ShuffleNet V2 for color feature extraction. The proposed method is evaluated on three benchmark datasets: LineMOD, 17 Occlusion LineMODm 18 and YCB-Video. 11 The experimental results show that our method exhibits better performance than competing approaches on all datasets. Moreover, our model is much smaller than the current popular 6D pose estimation methods, highlighting its suitability for deployment on mobile platforms.
The contributions of this work can be summarized as follows:
We design a two-stage fusion module that can fully leverage two complementary data sources from RGB-D images, which makes it robust for handling heavy occlusion in 6D object pose estimation tasks. We propose a lightweight color feature extraction network that significantly reduces our model’s size and computational cost. The experimental results obtained on the LineMOD, Occlusion LineMOD, and YCB-Video datasets show that our method achieves significantly boosted performance.
Related work
Pose estimation with RGB data
Since RGB images are easy to obtain, many studies use only RGB images for pose estimation. Traditional methods1,19 generally perform pose estimation based on key point extraction and matching algorithms. Such methods are often sensitive to cluttered backgrounds and light changes. With the great success of deep learning technology in 2D vision, many tasks have used deep learning for estimating poses from RGB images. PoseNet 20 was the first method to use a CNN to solve the 6D pose estimation problem and can adapt to the environment well. SSD-6D 6 discretizes the rotation space into a classifiable set of viewpoints and transforms the 6D pose estimation task into a classification problem. However, these two methods are highly dependent on time-consuming pose optimization operations to improve their performance. In contrast, EfficientPose 21 introduces the EfficientDet 22 structure to construct a pose estimation framework for directly predicting the 6D attitudes of objects. The utilization of a novel 6D enhancement strategy allows it to achieve better performance without optimization. Deep-6DPose 5 adds a pose estimation branch to a mask region-based CNN 23 to directly estimate the 6D poses of objects without any postprocessing processes.
Compared with the direct prediction of 6D object poses, establishing a 2D to 3D correspondence and taking it as the indirect expression of a pose to calculate the corresponding 6D pose often yields more accurate results. BB8 24 predicts the 2D projections of the vertices of a 3D bounding box to construct the 2D to 3D correspondence. Similar to BB8, YOLO-6D 25 uses a single-shot neural network to directly detect the key points of an object. PVNet 7 adopts a key point location strategy based on voting. It first trains a CNN to predict the direction vector from each pixel to the key point and then uses the vector of pixels belonging to the target object to vote on the key point position. Yu et al. 26 proposed an effective loss based on PVNet to achieve more accurate vector field estimation results by incorporating the distances between pixels and key points into the target. However, these methods cannot be trained in an end-to-end manner. Therefore, Single-stage 27 and GDR-Net 28 both established 2D to 3D correspondences but attempted to learn the PnP algorithm in an end-to-end fashion. However, due to the loss of geometric information caused by perspective projection, RGB-based methods are sensitive to illumination changes, serious occlusion situations, and cluttered backgrounds.
Pose estimation with depth/point clouds
The emergence of inexpensive depth sensors has led to some methods that use point clouds or depth data. These methods take point clouds or depth images as inputs and utilize 3D CNNs or point cloud networks for geometry feature extraction to estimate 6D poses. VoxelNet 29 and Frustrum PointNets 30 are both PointNet-like structures that have achieved great performance on the KITTI benchmark dataset. Zhang et al. 31 first used PointNet to extract high-dimensional features from an input 3D point cloud, then performed feature dimensionality reduction and fusion, and finally regressed the corresponding 6D pose. However, the lack of object appearance information limits the performance of these methods in challenging scenes.
Pose estimation with RGB-D data
With the rapid development of hardware, the use of RGB-D information to estimate the 6D poses of objects has gradually become a hot research direction. PoseCNN 11 estimates 6D poses from RGB images and then uses depth images to refine the poses. However, this refinement process is time-consuming and cannot be trained together with the pose estimation network. Li et al. 12 used depth information as an additional channel of a network constructed for RGB images, ignoring the difference between the depth feature space and the color feature space and thus failing to fully utilize the RGB-D information. Recently, DenseFusion 13 uses a CNN and PointNet 32 to process the data acquired from RGB and depth images, respectively, and performs pixel-wise fusion. However, this approach discards the local information in the point cloud. A deep point-wise 3D keypoints voting network for 6 degrees of freedom pose estimation (PVN3D) 15 predicts the depth information for key points to convert these key points from the 2D space to the 3D space and optimizes the 6D pose estimation process according to the geometric information of the object of interest itself. Furthermore, Zhou et al. 14 and He et al. 15 used PointNet++ 16 to extract local geometric information from a point cloud. However, PointNet++ treats all local points equally, which limits the extraction of geometric information. In contrast, we use an ASSANet-like 33 network to efficiently extract the geometric information from a point cloud and perform both color-depth and local–global fusion to obtain a better representation of the observed RGB-D information.
The proposed method
This paper aims to estimate the 6D pose of a known object from an RGB-D image. The 6D pose represents the camera coordinate system’s translation and rotation transformations relative to the original object’s world system. Generally, rotation and translation are represented by a rotation matrix
Overview of the network
Our overall network architecture, shown in Figure 1, is mainly divided into three stages. In the first stage, the input RGB-D image is semantically segmented to obtain the target region. During the second stage, we first use a lightweight network to extract color features from the RGB image and integrate the extracted color features into a point cloud (converted from depth maps) according to the corresponding relationships between the depth maps and color maps for color-depth fusion. Then, an ASSANet-like network is used to extract several local features and one global feature from the target point cloud, and the global features are copied and fused with each local feature for local–global fusion. The fusion features are sent to a pose predictor network to obtain the corresponding 6D poses with their confidence scores in the last stage. We choose the 6D pose with the highest score as the final output. In addition, we add a refinement network in Wang et al. 13 to obtain a better estimation. Each part of Figure 1 is described in detail in the subsequent sections.

The overall framework of our approach. The input RGB-D image is segmented to obtain the target region. The color features extracted by a lightweight network are fused with the point cloud, and several local features and one global feature are extracted from the point cloud. Then, we fuse the global feature with the local features and send the fused features to the pose predictor network to obtain the corresponding 6D poses. Finally, we add a refinement network to obtain a better estimation. RGB-D: red–green–blue-depth; 6D: six degree-of-freedom; CNN: convolutional neural network; PSP: pyramid scene parsing; ASSANet: anisotropic separable set abstraction network.
Preprocessing
Before performing feature extraction, we first segment the target region derived from the input image. According to the segmentation results, we crop the RGB image and convert the depth image to a point cloud using the camera’s internal parameters. Since this part is not our focus, we directly adopt the segmentation network provided by Xiang et al. 11
Color feature extraction and color-depth fusion
The cropped image is passed through a color feature extraction network to produce pixel-wise color embeddings. Unlike previous works,13,14 we design a lightweight feature extraction network for color feature extraction, which reduces the number of parameters and the computational complexity of the model. This network comprises a variant of ShuffleNet V2, 34 a pyramid scene parsing (PSP) module 35 and four upsampling layers, as illustrated in Figure 2. The original ShuffleNet V2 unit for spatial downsampling, shown in Figure 3, uses DWConv and a channel random mixing strategy to reduce the model size. Among the calculations of ShuffleNet V2, the 1 × 1 convolution accounts for most of the complexity. The 1 × 1 convolutions before and after DWConv are mainly used to fuse the information between the channels or change the dimensions. Since we do not need to change the dimensionality here, we only need one 1 × 1 convolution to compensate for the lack of DWConv for conducting information fusion between channels. Therefore, we crop the 1 × 1 convolution after DWConv in branch 2 to further reduce the computational cost.

Structure of our color feature extraction network. RGB: red-green-blue; PSP: pyramid scene parsing.

The original ShuffleNet V2 unit for spatial downsampling. DWConv: depthwise convolution; BN: batch normalization; ReLU: rectified linear unit; Conv: convolution.
Specifically, the cropped RGB images of size
Geometric feature extraction and local–global fusion
Effectively extracting local geometric information from point clouds is a challenging task. Previous methods14,15 typically employed PointNet++ to extract information from the point cloud, yet PointNet++ treats all local points in an isotropic manner. In contrast, we use a network based on the anisotropic separable set abstraction (ASSA) module to deal with the target point cloud. The ASSA module performs set abstraction operations in separate directions independently, facilitating the capture of anisotropic patterns and enhancing the performance of local information extraction. Furthermore, the ASSA module is more efficient and has a faster inference speed, which aligns with our intention to create a lightweight and efficient model. As shown in Figure 4, this module consists of five layers: a subsampling layer, a grouping layer, a geometry-aware anisotropic reduction layer, and two multilayer perceptron (MLP) layers. Specifically, taking the resulting point cloud of size
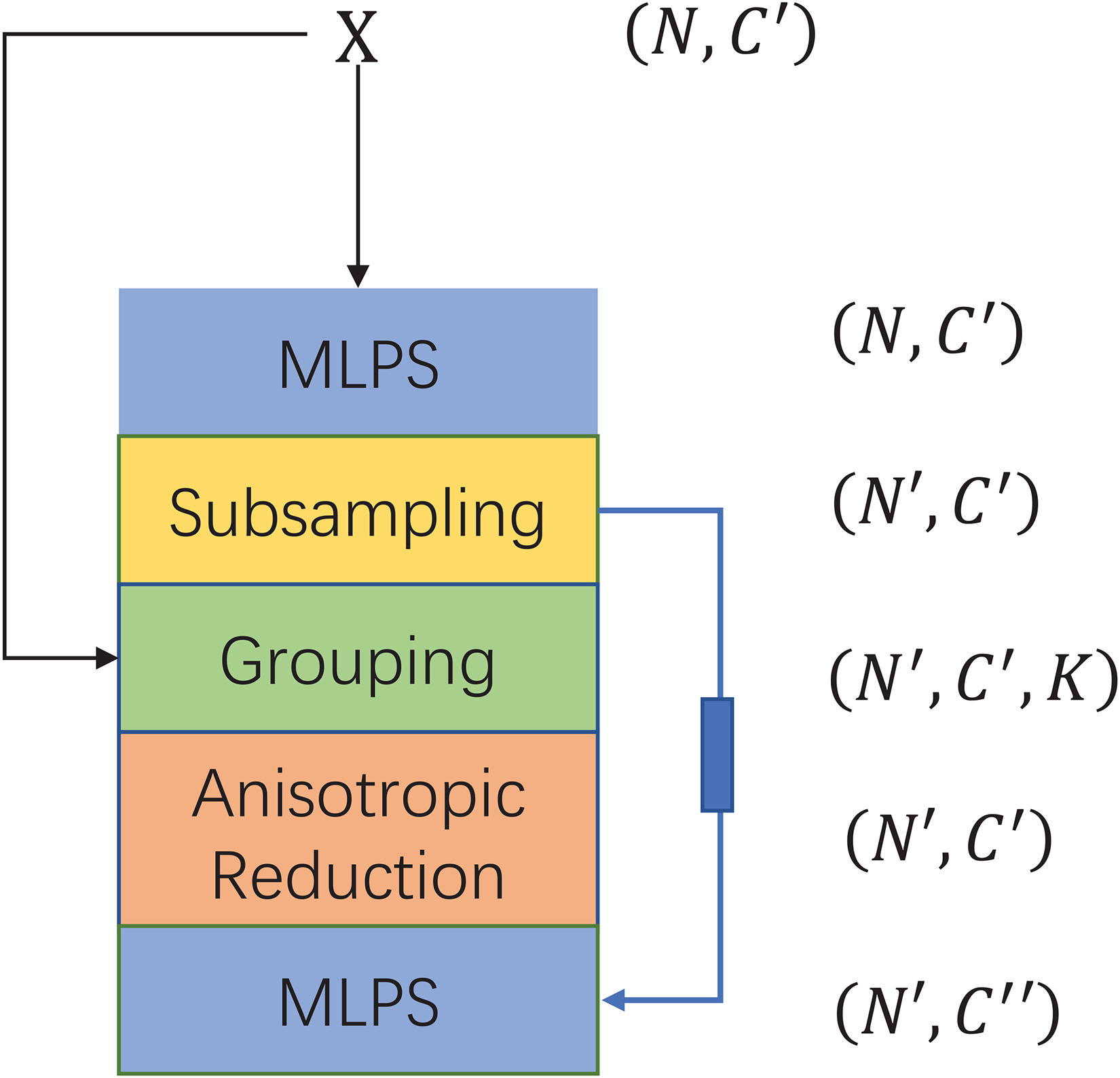
ASSA module. ASSA: anisotropic separable set abstraction; MLP: multilayer perceptron.
Our geometric feature extraction network consists of three ASSA modules. The second module outputs
Pose estimation and refinement
Pose estimation
We feed the obtained fusion features into a pose prediction network to obtain 6D poses. This network has three branches. Each branch consists of three 1 × 1 convolution layers and outputs the predicted rotation parameter R, translation parameter t, and confidence c. Each fusion feature independently predicts a 6D pose and a corresponding confidence score. We choose the pose with the highest confidence as the final output. This process enables the model to independently predict the pose from various local regions, each offering a distinct perspective. Thus, even when parts of the object are obscured, the model is capable of inferring the overall pose from regions that are less occluded. The final pose is determined based on the prediction with the highest confidence score, derived from these diverse local assessments. This method effectively leverages local information to navigate the challenges posed by severe occlusion, ensuring accurate pose estimation despite the object’s partial visibility.
Pose refinement
We further optimize the predicted pose to improve the resulting pose estimation accuracy. The standard ICP optimization algorithms are time-consuming and cannot be trained in an end-to-end manner. Therefore, we adopt the iterative refinement structure in Wang et al.,
13
which is fast and can be jointly trained with our main network for end-to-end pose estimation. The refinement process is shown in Figure 5. The structure of the refinement network is similar to that of the main network except that our fusion module outputs only one global feature instead of fusion features. The global feature goes through two small regression networks composed of fully connected layers to return a single pose. Specifically, the input point cloud is first transformed according to the initial pose predicted by the pose prediction network. Then, the transformed input point is fed with the original color feature into a refinement network to obtain a residual pose. Finally, we transform the target point cloud again according to the residual pose and send it to the next iteration. After T iterations, we concatenate the results of each iteration to obtain the final pose estimate:


The pose refinement procedure. ASSANet: anisotropic separable set abstraction network; 6D: six degree-of-freedom.
Loss functions
During the training phase, we define two different loss functions for symmetric and asymmetric objects. For asymmetric objects, to minimize the average offset between the point cloud randomly sampled on the object model for the real pose and the point cloud of the corresponding object in the predicted pose, the loss function is defined as:

Symmetric objects can have the same appearance under different poses in RGB-D images. Therefore, another loss function is introduced to minimize the average distance between each point in the predicted object model and the closest points in the object model for the real pose. The loss function is as follows:


Experiments
Datasets and metrics
We adopt the average distance ADD
17
and ADD-S
11
metrics, which are commonly used in 6D pose estimation, to evaluate our method. The ADD metric is defined as the mean pairwise distance between the model points transformed by the predicted pose


Implementation details
The color feature extraction network takes an RGB image of size
All experiments are performed on an Intel Core i9-10900X CPU@3.70 GHz × 20 with a single NVIDIA GeForce RTX3090 GPU. The training and test sets division is the same as the previous work. 14
Evaluation conducted on the LineMOD dataset
Table 1 lists the quantitative evaluation results obtained for all 13 objects in LineMOD dataset. As can be seen, the performance of RGB-D-based methods is generally better than that of the RGB-based methods. Our method achieves an accuracy of
Quantitative 6D pose evaluation results obtained on the LineMOD dataset in terms of the ADD(-S) metric. Objects with bold names are symmetric.

6D: six degree-of-freedom; RGB: red–green–blue; RGB-D: RGB-depth; PVNet: pixel-wise voting network; PoseCNN: pose convolutional neural network; DeepIM: deep iterative matching; CPDN: coordinates-based disentangled pose network; DPOD: 6D pose object detector and refiner; PVN3D: a deep point-wise 3D keypoints voting network for 6D pose estimation; FFB6D: a full flow bidirectional fusion network for 6D pose estimation.
Evaluation conducted on the Occlusion LineMOD dataset
The quantitative evaluation results obtained for all eight objects in the Occlusion LineMOD dataset are reported in Table 2. Hinterstoisser et al.
38
only use depth images, while the other methods use RGB-D images. As the table shows, our method outperforms DenseFusion
13
and the approach of Zhou et al.
14
by
Quantitative 6D pose evaluation results obtained on the Occlusion LineMOD dataset in terms of the ADD(-S) metric. The bold value in each row represents the best performance achieved for one object category.

6D: six degree-of-freedom; PoseCNN: pose convolutional neural network; ICP: iterative closest point.
Evaluation conducted on the YCB-Video dataset
Table 3 shows the results obtained for all 21 objects in the YCB-Video dataset. The percentages of ADD-S AUC values that are <0.1 m and ADD-S values that are <2 cm are used to measure the performance of these methods. All methods use the same segmentation masks as those in PoseCNN to ensure fairness. As seen from the table, our method outperforms PoseCNN + ICP and DenseFusion by

Visualization of the poses estimated by our method. The left panel shows the input images and the right panel shows the resulting 6D pose images.
Quantitative 6D pose evaluation results (ADD-S<2 cm and AUC) obtained on the YCB-Video dataset.

6D: six degree-of-freedom; AUC: area under the ADD-S curve; PoseCNN: pose convolutional neural network; ICP: iterative closest point.
Time efficiency results
Training time
A 6D pose estimation algorithm based on deep learning often needs to train for hundreds of epochs to achieve good results. This excessively long training time limits the practical applications of these methods. Figure 7 shows the average accuracies and errors yielded by DenseFusion,
13
the approach of Zhou et al.
14
and our method on the LineMOD dataset during the first 10 training epochs. As we can see, our method can achieve a higher accuracy rate and a smaller error than those of the other two methods under the same number of training epochs. Most importantly, our approach can achieve 90+

Training curves. (a) and (b) show the accuracy and average error on the LineMOD dataset over the first 10 training epochs, respectively.
Inference time
On the GTX 3090 GPU, our method takes 0.017 s for pose estimation and 0.007 s for refinement. With 0.03 s for prior instance segmentation, the overall runtime on the LineMOD dataset is approximately 0.054 s, which can meet the requirements of real-time applications.
Model size results
Table 4 shows the comparison between the size of our model and those of the latest popular 6D pose estimation models. As we can see, the parameters of our model are
Comparison of our model with the latest popular models in terms of model size.

PVN3D: a deep point-wise 3D keypoints voting network for 6 degrees of freedom pose estimation; FFB6D: a full flow bidirectional fusion network for 6D pose estimation; MB: megabyte.
Ablation experiments
We conduct a series of ablation studies on the LineMOD dataset to verify the effects of different parts of our model.
Table 5 compares our model’s parameters, memory space, floating point operations (FLOPs), and accuracy under different color feature extraction networks. Compared to ResNet34+PSPNet and the color feature extraction network in DenseFusion, our color feature extraction network reduces the number of model parameters by
Comparison among different versions of our model using different color feature extraction networks on the LineMOD dataset in terms of accuracy and model complexity.

GFLOP: giga floating point operation.
The changes induced in the FLOPs and accuracy produced on the LineMOD dataset according to the number of local areas.

FLOP: floating point operation; GFLOP: giga FLOP.
Conclusions
In this paper, we introduce an end-to-end network for estimating an object’s 6D pose from RGB-D images. We develop a two-stage feature fusion module to better leverage the color and geometry information in RGB-D images, which is particularly advantageous in dealing with occlusion environments. This module first extracts color features from the given RGB images and combines them into a point cloud for color-depth fusion. Then, it uses an ASSANet-like network to extract several local features and one global feature from the point cloud for local–global fusion. Furthermore, to reduce the complexity of our model, we developed a lightweight network based on ShuffleNet V2 for color feature extraction. Experimental results obtained on LineMOD, Occlusion LineMOD, and YCB-Video datasets demonstrate that the proposed approach can increase the overall accuracy of estimated 6D poses. Furthermore, our model is significantly smaller than the latest popular models for 6D pose estimation, making it suited for applications on mobile platforms with limited computational resources. In the future, we will apply the end-to-end advantages of our method to the field of self-supervised learning.
Footnotes
Acknowledgement
We would like to thank the anonymous reviewers and the editor for their comments.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (62373016) and the Open Projects Program of the State Key Laboratory of Multimodal Artificial Intelligence Systems (MAIS-2023-22).