
Abstract
This article introduces an approach aimed at enabling self-driving cars to emulate human-learned driving behavior. We propose a method where the navigation challenge of autonomous vehicles, from starting to ending positions, is framed as a series of decision-making problems encountered in various states negating the requirement for high-precision maps and routing systems. Utilizing high-quality images and sensor-derived state information, we design rewards to guide an agent’s movement from the initial to the final destination. The soft actor-critic algorithm is employed to learn the optimal policy from the interaction between the agent and the environment, informed by these states and rewards. In an innovative approach, we apply the variational autoencoder technique to extract latent vectors from high-quality images, reconstructing a new state space with vehicle state vectors. This method reduces hardware requirements and enhances training efficiency and task success rates. Simulation tests conducted in the CARLA simulator demonstrate the superiority of our method over others. It enhances the intelligence of autonomous vehicles without the need for intermediate processes such as target detection, while concurrently reducing the hardware footprint, even though it may not perform as well as the currently available mature techniques.
Introduction
Autonomous driving 1 has garnered significant interest from both the academic community and industry stakeholders, owing to its potential to transform mobility and transportation systems fundamentally. The SAEJ3016 standard 2 categorizes motor vehicles into six levels of automation, ranging from Level 0 (L0) to Level 5 (L5), and defines the corresponding provisions for road motor vehicles as follows:
No automation: The driver maintains full control of the vehicle while potentially receiving warnings or supplementary information. Driver assistance: The vehicle performs closed-loop control for either steering or longitudinal acceleration/deceleration, with the driver managing other aspects. Partial automation: The vehicle uses environmental perception data to execute closed-loop control over steering, acceleration, and deceleration, with the driver handling remaining tasks. Conditional automation: The autonomous driving system assumes all driving operations, with human intervention only upon system request. High automation: The motorized driving system performs all driving tasks, but within certain road and functional constraints. Full automation: The autonomous driving system is capable of handling any driving conditions without human intervention.
Conventional autonomous driving planning and navigation methodologies are based on a modular data flow approach.3–5 This approach comprises modules such as perception, positioning, planning and navigation control (PNC), remote control, and computer interaction. The data flow and communication between these modules are depicted in Figure 1. The PNC module is further divided into path planning, decision-making, motion planning, and motion control. While the modular approach simplifies the development of individual modules by breaking down complex driving tasks, it is prone to error propagation. For instance, in 2016, a Tesla vehicle’s perception module incorrectly identified a white tractor-trailer as a cloud, with tragic consequences. Moreover, the modular system’s demand for computational resources can lead to inadequate memory allocation for the PNC module, resulting in redundant computations and inefficient memory usage. These systems struggle with complex scenarios and often resort to discretization into finite-dimensional state machines, which may yield different decisions based on varying behavioral criteria. Overall, the majority of existing approaches concentrate on formal logic that delineates driving behavior within annotated three-dimensional geometric maps. This methodology can be challenging to scale effectively because it depends extensively on external mapping infrastructure, rather than primarily relying on an comprehension of the immediate surroundings.
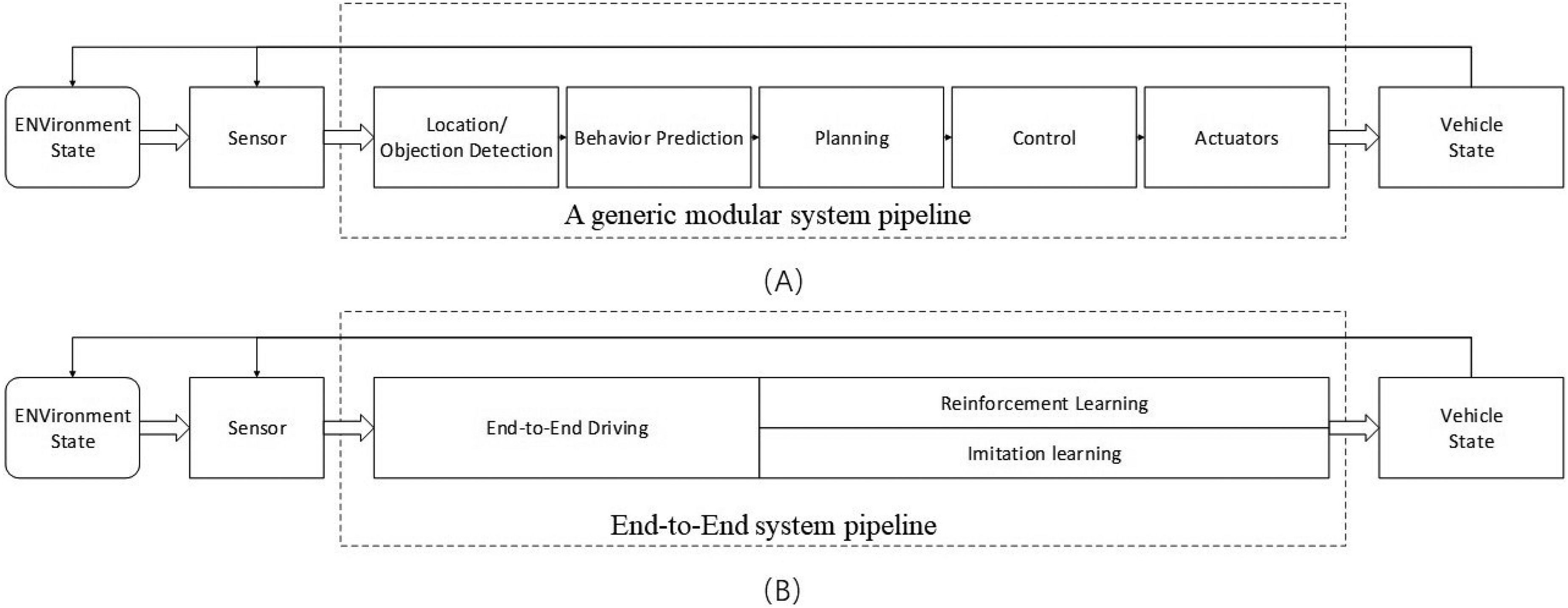
(A) A typical modular system pipeline, encompassing location or object detection, behavior prediction, planning, control, and actuators and (B) an end-to-end system pipeline focusing on reinforcement learning and imitation learning.
In reality, the scenarios encountered by autonomous vehicles are myriad and cannot be adequately captured by state machines. Encountering unforeseen situations can lead to confusion within autonomous driving systems. Furthermore, end-to-end systems offer an alternative approach to PNC, directly producing ego-motion from sensory inputs. Ego-motion can manifest as continuous actions of the steering wheel and throttle or as discrete actions such as acceleration or turning.
The end-to-end approach commences with data and learns behavior logic through imitation learning or self-learning, obviating the need for the vehicle’s dynamic model. The primary components of the end-to-end system include two learning methodologies: the imitation learning method based on supervised learning and the reinforcement learning method. Imitation learning extracts decision-making logic from expert data; however, its effectiveness is limited when faced with conditions not present in the expert dataset. Consequently, the behavioral logic of autonomous driving systems may not surpass the capabilities of human expert decision-making. Both traditional methods and imitation learning are constrained by human-centric thinking and are unable to transcend the bounds of human reasoning frameworks.
The autonomous driving system is conceptualized as an agent that employs reinforcement learning techniques. 6 The agent engages with the environment, garnering rewards in response to its actions. Its primary goal is to maximize cumulative rewards. By carefully designing incentives, we can align the objectives of autonomous driving with those learned through reinforcement learning, a process that mirrors human learning. Human drivers initially lack familiarity with a vehicle and learn through trial and error to identify the safest and most comfortable driving methods. They experience satisfaction upon mastering new skills or discovering new routes and guilt when causing accidents—these emotional responses are akin to the positive and negative rewards in reinforcement learning. The agent’s learning process, grounded in this concept, has the potential to exceed human learning capabilities. While driving, individuals can identify appropriate routes without depending on high-precision maps and navigation systems. In this article, we leverage reinforcement learning to facilitate autonomous driving navigation from the initial position to the termination point, negating the requirement for high-precision maps and routing systems.
This article introduces an approach aimed at enabling self-driving cars to learn to drive akin to human cognition. We implement the soft actor-critic (SAC) algorithm for planning and navigation from an initial to a termination position in autonomous driving negating the requirement for high-precision maps and routing systems. Our input is a multimodal state space, which includes high-quality images captured by cameras and state vectors comprising easily obtainable sensor data, such as speed and position. This multimodal state space provides the agent with a comprehensive understanding of the environment.
We leverage the variational autoencoder (VAE) algorithm to derive latent vectors from high-quality images, reusing them in place of the original images. This innovation addresses the drawbacks associated with the use of high-quality images, such as high memory usage, slow training speeds, and reduced training efficiency. Our method demonstrates superior performance in the CARLA simulation environment when compared to other approaches. Although it lags behind commercially available methods, it holds significant promise for autonomous learning and decision-making in autonomous driving. By utilizing high-quality images, we enhance the algorithm’s ability to garner information about the surroundings, facilitating migration from simulation to real-world environments.
The primary contribution of this research lies in proposing a novel method for autonomous driving planning and navigation negating the requirement for high-precision maps and routing systems that learns from scratch in a manner analogous to human drivers. This work establishes a foundational framework for the integration of true artificial intelligence in autonomous driving. By interpreting the planning and navigation task from a decision intelligence perspective, we enhance the autonomy of driving systems. However, our approach requires further development for application across all scenarios.
The remaining structure of this article is organized as follows: The “Related work” section on related work reviews the application and research status of reinforcement learning in autonomous driving and vehicle simulation environments. The “Deep reinforcement learning (DRL)” section details the principles of reinforcement learning algorithms, while the “Variational autoencoder (VAE)” section explains the VAE algorithm. In the “Components” section, we discuss the main components of reinforcement learning and VAE, along with their implementation. The “Experiments” section presents our method’s experimentation within the CARLA simulation environment and an analysis of the results. Finally, the “Conclusion” section summarizes the article and offers insights into potential future research directions.
Related works
In their 2021 paper published in Nature, Sutton and David Silver proposed that reinforcement learning could be applied in any domain where rewards are adequately designed. 7 While this perspective has sparked debate, primarily due to the complexity of reward design, it provides a theoretical basis for using reinforcement learning to achieve planning and navigation in autonomous driving systems that emulate human-like decision-making. Wayve, a UK-based startup, has focused on intensive learning for autonomous driving. In their 2020 study, ”Learn to Drive in a Day,” 8 they employed the deep deterministic policy gradient (DDPG) algorithm for autonomous lane-keeping. Initially, the authors used pre-trained agents within a simulator and later applied the pre-trained algorithms to physical vehicles for continued training on highways, using the distance traveled within a lane as a reward. The results indicated that the lane-keeping task could be achieved after approximately one hour of training on actual roads. Despite extensive research in reinforcement learning by scholars, there remains a scarcity of practitioners due to the challenges associated with convergence in the training process.
The process of continuous trial and error in practical training is scientifically unsound. This presents a significant challenge for researchers attempting to learn environmental models through offline reinforcement learning 9 and data collected from real-world vehicles. The discrepancy arises because the model is often a simulation environment derived from a constructor’s simulator, which can lead systems to equate the virtual world with the real environment.
To address this issue, the research community has adopted generative adversarial network theory, integrating an environmental discrimination process into the rendering phase to maximize the loss function between the real and rendered environments. In alignment with this principle, the Stanford team introduced the Gibson simulation environment in 2018,10,11 primarily utilized in indoor mobile robotics. Additionally, Zhou et al. 12 proposed the SMART simulation framework to simulate complex interactions among multiple autonomous vehicles, although it focuses on cooperative multi-agent interactions rather than providing detailed environmental information for individual agents, which is inadequate for our experimental requirements.
Although not tested on actual vehicles, we aimed for the highest possible accuracy in the virtual environment. We explored various simulation environments. The SMART simulator, 12 developed by Huawei, emphasizes multi-intelligence collaborative training; the Gazebo simulation 13 is geared towards indoor robotics but lacks realism; the Gibson simulation, 10 designed by Stanford, is centered on indoor robotic interactions but does not represent an urban environment; likewise, the donkeycar simulation, 14 created by MIT, also does not simulate urban settings. The CARLA simulation environment 15 stands out by offering realistic urban conditions with a diverse fleet of car models, enabling Sim2Real transitions.
Despite advancements in simulation environments, preliminary research in reinforcement learning for PNC remains essential. 16 For instance, Chae et al. 17 employed the deep Q-network (DQN) algorithm to interpret sensor data for navigating complex obstacle scenarios, automatically assessing collision risks, and implementing autonomous braking for safe and comfortable driving. Isele et al. 18 used DRL to safely navigate through unsignaled intersections, outperforming traditional heuristic methods and demonstrating active obstacle avoidance.
Wang et al. 19 applied Q-learning to enable a vehicle agent to adapt its behavior for intelligent lane changing under various conditions. Sallab et al. 20 utilized DQN and deep deterministic actor-critic to simulate lane-keeping in TORCS and to master autonomous maneuvering in complex curvature and interactive driving situations.
Current literature suggests that end-to-end planning and navigation modules in PNC research receive limited attention, primarily due to the novelty of reinforcement learning in autonomous driving and the scarcity of completed projects. An autonomous driving environment is significantly larger in scale compared to other agent simulations. To enhance the agent’s understanding of its surroundings, the state space incorporates both image data from cameras and a state vector containing vehicle speed, position, and other relevant data. We designed a reward function to facilitate autonomous navigation from an initial to a final destination negating the requirement for high-precision maps and routing systems.
Deep reinforcement learning
Reinforcement learning mimics one of the ways humans acquire knowledge and skills. DRL builds upon the principles of traditional reinforcement learning. 21 It leverages deep neural networks to approximate value functions and policy functions more effectively. Unlike traditional reinforcement learning methods that rely on linear functions and tabular representations to estimate these functions, as illustrated in Figure 2, DRL is particularly useful in scenarios such as autonomous driving, where the state space is too vast to be enumerated. In complex environments, the relationship between state and value spaces is inherently nonlinear, rendering simple linear approximations inadequate. Deep neural networks excel in capturing the underlying complexities of such relationships due to their high representational power.

(A) The interaction between an agent and its environment and (B) the reinforcement learning process. The use of a neural network facilitates the approximation of the policy or value functions.
Deep Q-network
The DQN algorithm22,23 represents a foundational value-based approach in which only the value function is employed to assess the quality of state-action pairs. It is an extension of Q-learning into continuous and high-dimensional spaces. In reinforcement learning, the state-action value


Where r represents the current reward,
In value-based approaches, a critic assesses the efficacy of behaviors. The ultimate policy
In DQN, the policy is entirely contingent on the Q-function. For a given state, DQN iterates over all potential actions within the action space, selecting the one with the highest Q-value. These state-action pairs underpin DQN’s implicit deterministic policy. The
Experience replay mitigates data correlation by introducing a replay buffer. This buffer captures data through interactions with the environment under a specific policy
Deep deterministic policy gradient
The DDPG algorithm, as described by Silver et al.,
24
concurrently learns the Q-function and the policy using off-policy data and the Bellman equation. It maintains consistency with the optimal action-value function,
For finite-dimensional discrete spaces, one can calculate and compare Q values for each action to determine the optimal policy. However, this enumeration is infeasible in infinite-dimensional continuous spaces. DDPG addresses this by optimizing the Q-function, which is differentiable with respect to the action space, thereby rendering the policy
DDPG utilizes deep neural networks to construct the Q-function and employs a MSE loss function to approximate the current and target networks, thus refining the Q-function’s estimation. The neural network primarily consists of parameters
DDPG also employs neural networks for policy network estimation, as discussed by Sutton et al.
25
The target policy network is instrumental in approximating the maximization problem associated with
Twin delayed DDPG (TD3)
The DDPG algorithm is known for its sensitivity to hyperparameter tuning and can exhibit instability in its learning process. A common issue in DDPG is the Q-function’s tendency to overestimate Q-values, which can lead to the degradation of the learned policy. In contrast, TD3 addresses this by simultaneously learning two Q-functions,

The Q-learning target’s actions are derived from the target policy
Soft actor-critic
SAC is an off-policy algorithm that optimizes stochastic policies. A key aspect of SAC is entropy regularization, which encourages the policy to balance the trade-off between expected returns and policy randomness, or entropy. This entropy term is closely tied to the exploration-exploitation trade-off: higher entropy promotes exploration, potentially accelerating learning, and helps prevent the policy from converging prematurely to suboptimal solutions.
The entropy H of a random variable x with probability mass or density function P is defined as follows:





Variational autoencoder
The VAE26,27 is fundamentally a method for density estimation based on latent variables. Although network design is not the primary focus in reinforcement learning, this article introduces an approach that utilizes high-quality images as inputs. High-quality images contain richer details compared to standard images commonly used in reinforcement learning tests. However, these images are larger in size, making them challenging for simple models to process. Moreover, it is impractical to input raw, high-resolution images directly into a system due to excessive memory requirements, which would limit the batch size during the training process of reinforcement learning algorithms. In this work, we employ a VAE to extract a latent vector from the original image, which is then used by the system to approximate the original image. The VAE estimates the parameters of a Gaussian mixture distribution using the expectation-maximization algorithm, with the primary objective being to maximize the probability


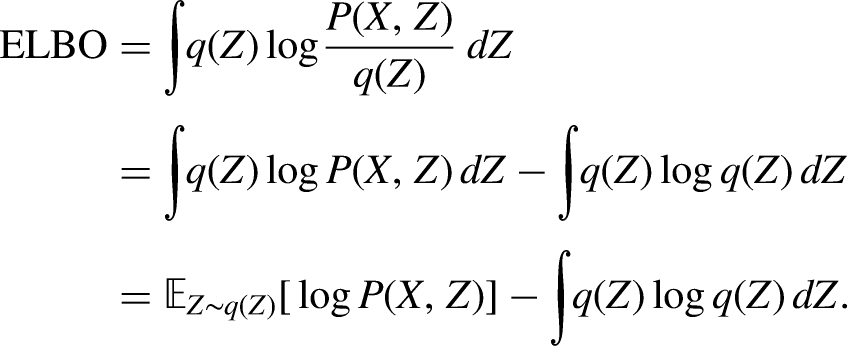

Components
This section delineates the modular constituents integral to the reinforcement learning process within the context of autonomous driving navigation negating the requirement for high-precision maps and routing systems, including the state space, action space, and policy network. Furthermore, it elucidates the training procedures for both the VAE and the reinforcement learning algorithm.
Environment
The agent engages with the environment, where it acquires the current state
In our research, the CARLA simulation environment is employed to emulate autonomous driving through urban landscapes. CARLA operates on a service-client architecture, necessitating the scripting of a client to facilitate network communication with the service and create a reinforcement learning environment. For our experiments, we utilize the TownHD10 map from CARLA, within which we establish a world with a physical town. We determine a starting point for the vehicle and a destination for navigation on the map. The objective is for the vehicle to autonomously traverse from the starting point to the designated destination negating the requirement for high-precision maps and routing systems.
As depicted in Figure 3, the Neolix autonomous logistics vehicle is equipped with a variety of sensors, including lidar, camera, collision sensors, an inertial measurement unit (IMU), and ultrasonic sensors. 29 In our setup, we employ only a visual sensor—a camera with a 60-degree field of view—to perceive the vehicle’s surroundings. Additionally, we incorporate a collision sensor to detect any collisions. The vehicle operates freely within the town, receiving real-time decisions from the agent. Training rounds conclude upon collision, and navigation is considered successful when the vehicle’s position is within one meter of the target position, at which point the termination state done is set to true.

The Neolix unmanned logistics vehicle is fitted with sensors such as lidar, camera, collision sensors, inertial measurement unit (IMU), and ultrasonic sensors.
Reward design
In reinforcement learning, the reward serves as the sole feedback from the environment to the agent, assessing the quality of the current state. Compared to supervised learning, the limited information provided by the reward makes the training process of reinforcement learning more gradual and challenging. The design of the reward mechanism is crucial in guiding the agent towards decisions that align with the objectives of the task. A significant challenge in reinforcement learning is determining whether the reward design is sufficient to steer the agent’s behavior in accordance with the intended goals. The design of reward mechanisms is often shaped by our profound familiarity with a given domain. In order to enhance the agent’s experiential learning, a reward system that integrates both dense and discrete rewards is implemented, instead of the traditional terminal state reward at the end of each episode. This is a solitary, sparse reward granted upon success or failure. Many scholars argue that learning is made more arduous due, in part, to the paucity of rewards associated with effort. Often, the impact of such meager rewards is not immediately realized. For instance, in the game of Go, the reward is only bestowed upon the determination of a winner between two players at the end of the game, with negative feedback being the sole indicator of reward, its timing in player evaluation remaining ambiguous.
In reward system design, a distinction is drawn between sparse and dense rewards. Dense rewards are provided at every frame. Initially, to motivate the vehicle to proceed, we define
To prevent the vehicle from idling and generating an abundance of irrelevant data, we have implemented an additional dense reward,
Upon collision or successful arrival at the destination, the episode concludes, and the vehicle reverts to the starting point to initiate a new data collection cycle. While the agent is theoretically motivated to pursue positive rewards and avoid negative ones, empirical observations suggest that the reward values should be tightly controlled. Excessive positive rewards can lead to an overestimation of the value function. Hence, it is crucial to constrain rewards within a specific range to preclude outliers that could skew the learning process. The rewards are aggregated according to their weighted coefficients:

State space
The state is derived directly from the visual sensor of a camera, and policies are generated from the raw image data. In considering the image size, we opt for a lower resolution that is resource-efficient, such as 64 by 64 pixels. The capacity of humans to extract meaningful features from these small images is overlooked, despite the reduced resource consumption and accelerated training pace that they offer. Smaller images inherently result in the loss of certain features. While humans may discern between two images based on nuanced details, these may be irrelevant for our purposes.
For example, the orientation of a pedestrian’s palm at an intersection might indicate their intended direction of travel, yet such granular details are not always pertinent. Low-resolution images may fail to capture such nuances, making high-resolution images more suitable for training decision-making algorithms. Utilizing high-resolution images as states not only facilitates the translation of our algorithms to real-world applications but also aids in the sim2real transfer learning process.
Nonetheless, a significant challenge arises with the use of large images. These images not only consume substantial memory but also lengthen the time required for model updates, potentially compromising the algorithm’s effectiveness. To maintain the intricacies of high-resolution images while simultaneously minimizing their memory footprint, an asynchronous training approach is a promising method. In this scheme, Process 1 is tasked with data collection, while Process 2 is dedicated to model training. These processes communicate through dedicated pipes, facilitating concurrent interaction with the environment and agent updates. This reduces the update latency and enhances training efficiency. Concurrently, the collected data is stored offline on a hard drive, with each frame’s information archived independently. However, we found that while this strategy mitigates memory usage, it fails to address GPU memory consumption. An excessive
The VAE provides a simplified representation of the image, utilizing the vehicle’s state information to generate an autonomous state vector that includes data such as speed and distance. This data is derived from the vehicle’s internal sensors, such as the IMU and odometer. By integrating the image state matrix, which correlates with speed, with a state vector containing acceleration, we construct the agent’s state space.
Action space
Reinforcement learning algorithms such as DDPG, TD3, and SAC are commonly applied to action spaces with a potentially infinite number of dimensions.
31
In the context of autonomous driving, the actions under our control are limited to acceleration, braking, steering, and gear shifting. For simplicity, we exclude the shifting action, precluding the agent from reversing the vehicle. CARLA provides a control interface with
The selected actions mirror those taken by human drivers, resulting in a two-dimensional action space:
Replay buffer
To facilitate the interaction between the agent and the environment, a five-dimensional tuple
To mitigate the challenge of excessive memory usage, we employed a dual-pronged approach. First, we established an offline localized replay buffer, as exemplified by Fu et al., 9 which serves as both the training and test datasets for the VAE. Specifically, we localized the data, storing each data tuple in the h5py format as an individual file. This method facilitates the creation of an offline localized replay buffer.
For the task of autonomous driving navigation, we selected an off-policy algorithm. The key difference between on-policy and off-policy algorithms lies in whether the policies employed for evaluation or improvement are identical to those generating the sampled data. This allows us to leverage offline data to refine and update the policy. However, during experimentation, we encountered a persistent issue of file corruption due to concurrent read-write operations over the same data file. Although our innovative use of the offline localized replay buffer effectively addressed the issue of large memory consumption, this approach was not fully compatible with the reinforcement learning training process. File locking could lead to process interlocks, resulting in a wait state that is inconsistent with the demands of parallel asynchronous training. Additionally, the import of large images could lead to excessive GPU memory usage, compromising training effectiveness and potentially causing crashes.
We redefine the state post-VAE processing of the original image as the latent state. Consequently, the original five-dimensional tuple
VAE training
We apply VAE to high-quality images to derive the corresponding latent vectors. This process allows us to reduce the dimensionality of the images while retaining their essential features. Utilizing a random policy to control the vehicle’s movement within the environment, we store the generated data from each frame in h5py files via offline localization. Each file contains a 5-tuple of data. The collected data is preserved within an offline localized replay buffer of size 32768, from which the VAE samples data to train its model.
As depicted in Figure 4, the VAE’s network structure comprises two sub-networks. The left sub-network is the Encoder, responsible for fitting
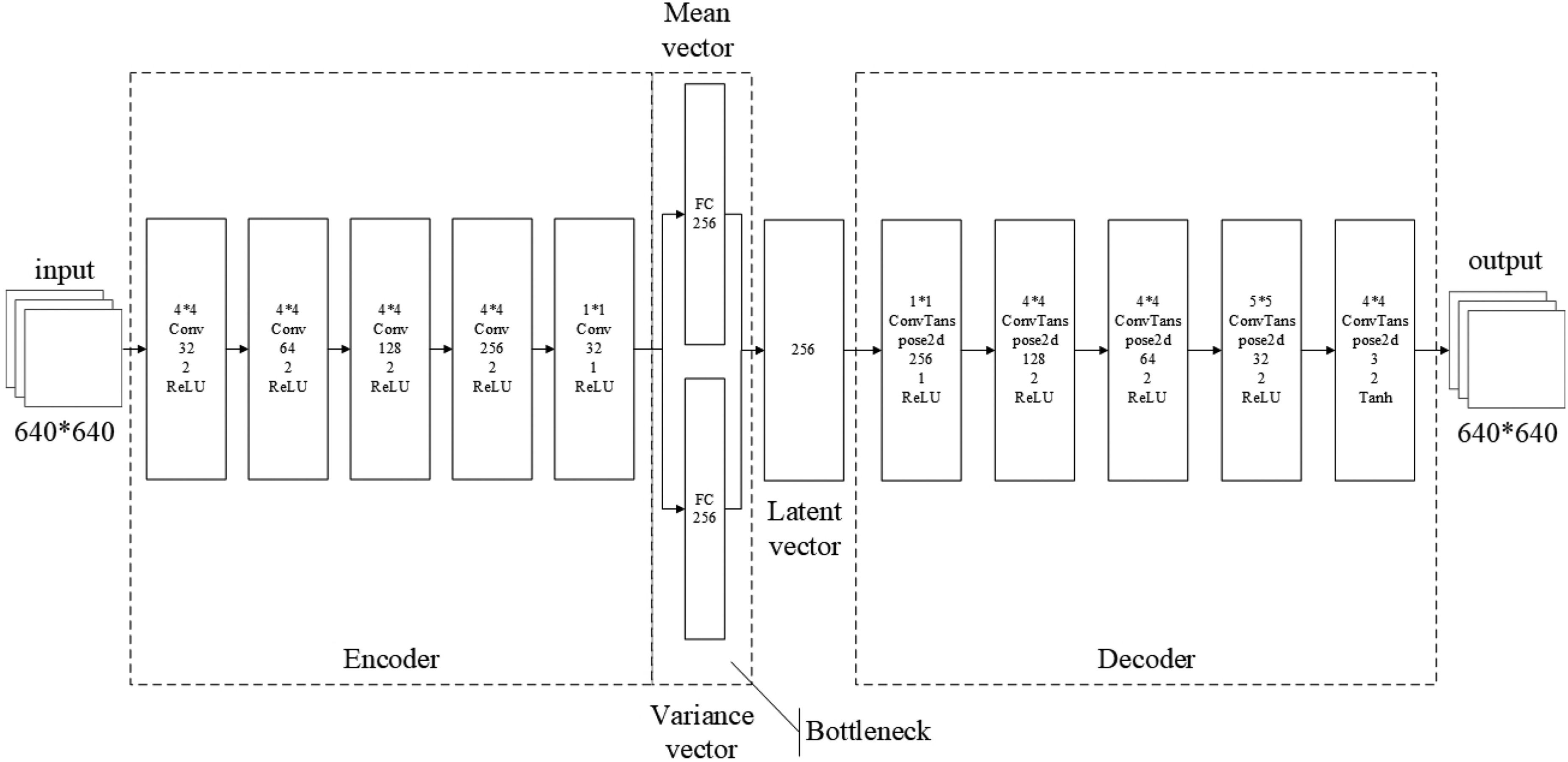
The architecture of the variational autoencoders (VAE) consists of two components: the encoder and the decoder. The mean and variance networks are employed to approximate the distribution of the latent vector.
We sampled a dataset

(A) An image captured by a camera placed in the CARLA environment for autonomous driving and (B) The processed image by the encoder and decoder modules of the variational autoencoders (VAE).
We decomposed the negative ELBO into two terms: the first term corresponds to the reconstruction loss, while the second represents the KL divergence. These serve as the loss functions for the encoder and decoder, respectively. We sought to minimize the sum of these two losses. Optimization was performed using stochastic gradient descent, with the network optimization process being equivalent to parameter estimation.
Reinforcement learning training
We developed an Agent to simulate vehicle driving within the CARLA environment. This Agent can represent either a human driver or an autonomous control system. The autonomous driving task was carried out in a town scenario simulated by CARLA, with the policy function
To enhance the richness of the state representation, we adopted a multi-modal state space. This included the latent state processed by the VAE and a vector state comprising multiple intrinsic states. We processed each modality separately using MLPs to generate 128-dimensional tensor vectors. These vectors were concatenated to form a new 256-dimensional tensor, which constituted the feature extraction layer. The output from this layer was used as input for three subsequent fully connected layers, with ReLU activation functions applied between them. The fully connected layers contained 256, 32, and four neurons, respectively.
In reinforcement learning, the actor network, as depicted in Figure 7, refers to the policy network, while the critic network, as shown in Figure 6, corresponds to the value network. Although these networks share an identical architecture, their distinct input and output characteristics reflect their differing objectives. The critic network receives state and action pairs as inputs and outputs the corresponding Q-values. Conversely, the actor network takes the state as input and produces either the distribution over actions or the actions themselves. It is imperative to train both networks simultaneously to enhance the critic’s ability to assess the policy and to enable the actor to derive a superior policy. Consequently, the parameters of these networks diverge.
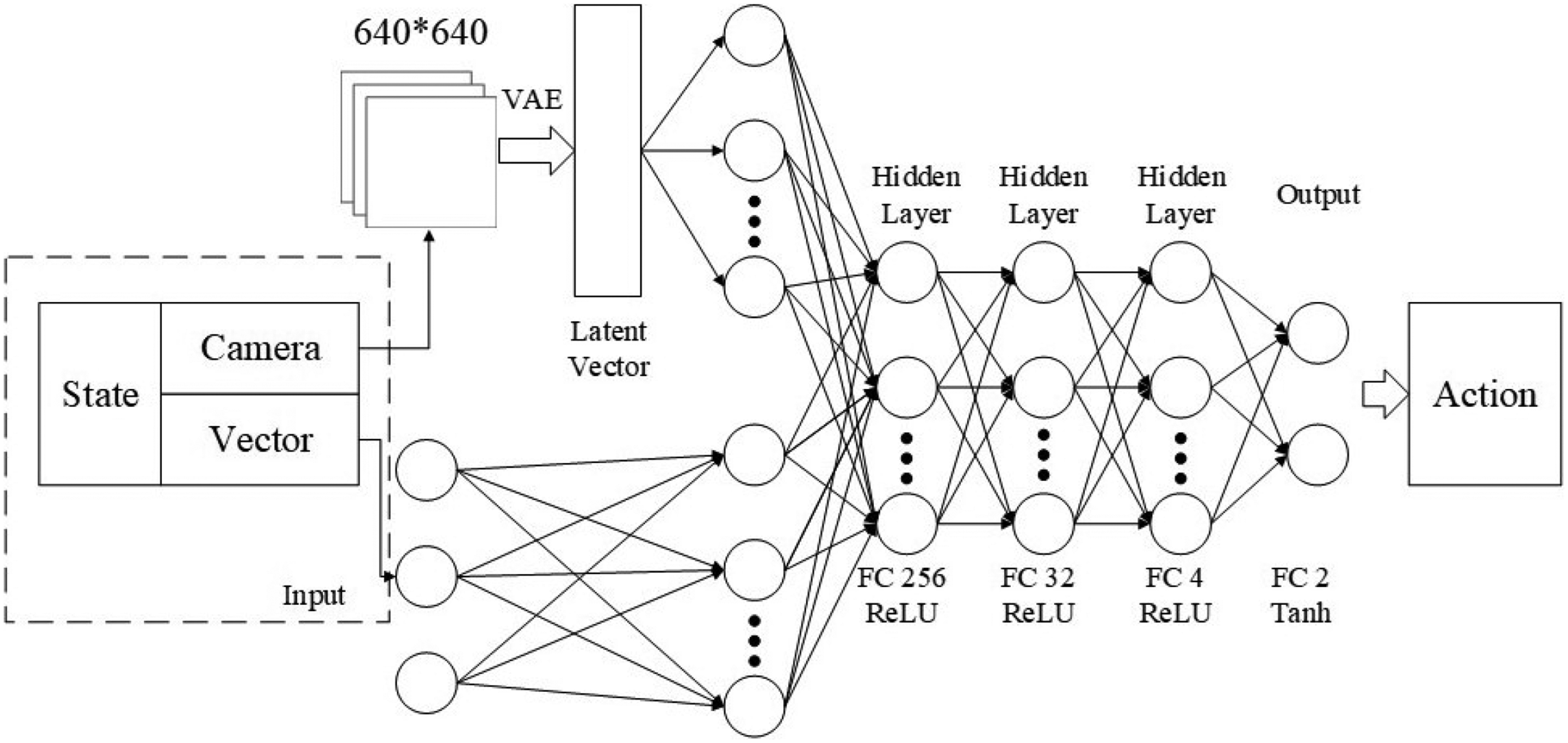
The actor-network: this network approximates the policy function using a neural network. It accepts states as inputs and yields actions or action distributions as outputs.

The critic network: this network employs a neural network to approximate the value function. It takes state and action pairs as inputs and produces Q-values as outputs. These Q-values are used to evaluate the quality of the policy.
Experiments
Conducting experiments in a real-world setting presents significant challenges. Locating an appropriate experimental site for autonomous driving and equipping it with autonomous vehicles capable of autonomous navigation negating the requirement for high-precision maps and routing systems is a complex task. Autonomous vehicles rely on images and other sensors to collect data about their environment, amassing relevant information during their operations. This data encompasses sensor information and environmental rewards for autonomous behavior. The process of driving autonomously involves continually refining the policy through trial and error until the optimal policy is discovered, allowing the vehicle to execute its tasks effectively. Achieving the optimal policy requires numerous updates, which can span more than a day. Furthermore, reinitializing the autonomous vehicle to its starting position at the beginning of each episode demands considerable time and effort. The frequent failures during trial-and-error training are unnecessary and unreasonable in the context of autonomous driving.
To address these challenges, we replicate the experimental environment within a simulation platform, as described in the “Environment” section. We construct a simulation environment on the CARLA platform that mirrors the real-world environment, leveraging the unreal engine for rendering. This simulation closely approximates the real environment, both visually and in terms of the system’s interactions. By using a simulation, we eliminate concerns over labor costs and potential vehicle damage. The simulation platform is established on a server running Ubuntu 20.04, equipped with an NVIDIA RTX 3090 graphics card, which supports model training and image rendering with its 24 GB of memory. The simulation environment is configured as depicted in Figure 8(A). It simulates a cityscape, complete with residential and commercial buildings, wide roads, traffic signals, and vehicles. For the purposes of this experiment, we choose to disregard traffic signals and regulations. Figure 8 illustrates the overall map of the environment, with point A serving as the starting position and point B as the destination.

(A) The TownHD10 scene within the CARLA environment in green, and (B) the corresponding map of TownHD10 in red.
We aim to enable autonomous vehicles to navigate from position A to position B negating the requirement for high-precision maps and routing systems. To this end, we employ the DDPG, TD3, and SAC algorithms for autonomous driving navigation. The experimental setting is based on the Town10HD map within the CARLA simulation environment. The weather conditions in this environment are characterized by clear skies, absence of wind, and represent a standard outdoor scenario. Comparative experiments were conducted in three stages. Initially, we ensured that all three algorithms utilized the same state input, and their image inputs were processed by an identical VAE model to obtain a consistent latent state representation.
Subsequently, each algorithm was subjected to the same number of update iterations and identical hyperparameters, as detailed in Table 1. This consistent setup facilitated a fair comparison among the algorithms.
Hyperparameters used in each algorithm for the experimental setup.

We evaluated the performance of the algorithms based on their success rate, mean episode length, and mean rewards, as presented in Figures 9 and Table 2. The success rate represents the proportion of successful episodes out of 200 trials. Mean episode length (mean_lens) denotes the average number of steps taken per episode, while mean_rewards indicates the average rewards accumulated over 200 episodes. “steps” refer to the number of training updates for the agent.

Experimental result curves obtained by the three algorithms: (A) the mean_rewards curve for DDPG, TD3, and SAC algorithms; (B) the mean_lens curve; and (C) the success_rate curve. DDPG is represented by the red curve, SAC by the orange curve, and TD3 by the green curve. DDPG: deep deterministic policy gradient; TD3: twin delayed deep deterministic policy gradient; SAC: soft actor-critic.
Comparative results of the experiments for each algorithm, including DDPG, TD3, and four variations of SAC: SAC_1 trained at 1 million time steps, SAC_2 at 1.5 million, SAC_3 at 2 million, and SAC_4 with low-quality image state input. PNC refers to the traditional modular planning navigation method.

DDPG: deep deterministic policy gradient; TD3: twin delayed deep deterministic policy gradient; SAC: soft actor-critic; PNC: perception, navigation, and control.
For the training process, DDPG, TD3, and SAC were all trained with the same hyperparameters as shown in Table 1. The red, green, and orange curves in Figure 9 represent the results of DDPG, TD3, and SAC, respectively.
In Figure 9(A), we compared the mean episode lengths of the three algorithms, which reflect the number of steps required to reach the end of each episode. We observed that DDPG and TD3 exhibited initial improvements, possibly due to a random policy at the early stages of the method selection. However, during the later stages of training, when faced with the same autonomous driving environment, these algorithms demonstrated similar performance. Their actions deviated in the later stages, often resulting in a loop of high-speed rotations and collisions, indicating a lack of effective policy learning.
Figure 9(B) reveals that the average rewards obtained by DDPG and TD3 tend to flatten out towards the end of training. In Figure 9(C), the success rates of the algorithms were compared, showing a success rate of zero for both DDPG and TD3. This indicates that these algorithms were unable to navigate from the initial to the final position in the designed environment.
From the comparisons in Figures 9(A) to (C), it is evident that the SAC algorithm significantly outperformed the others. The SAC algorithm appeared to successfully navigate from the starting point to the destination. SAC exhibited greater exploratory behavior than TD3 and DDPG. We identified biases in the action spaces of TD3 and DDPG and attempted to enhance their exploratory capabilities by adding random noise. However, these modifications did not overcome the significant deviations in training results, and the additional data collected did not contribute to improved policy learning.
In Table 2, the training phase is summarized through Figures 9 to 11. We have selected mean_rewards and success_rate as the key performance indicators for the algorithms.

This figure presents the experimental result curves obtained from the application of three algorithms. We denote the soft actor-critic (SAC) algorithm trained for 1 million timesteps as SAC_1, depicted by the red curve; for 1.5 million timesteps as SAC_2, represented by the orange curve; and for 2 million timesteps as SAC_3, shown by the green curve: (A) the mean_lens curves for SAC_1, SAC_2, and SAC_3. (B) the mean_rewards curves, while (C) the success_rate curves for these algorithms.

The depicted experimental result curves are the outcomes of two algorithms. SAC_1 represents the SAC algorithm with VAE, trained on high-quality images for 1 million timesteps, while SAC_4 signifies the SAC algorithm without VAE, trained on low-quality images for the same duration: (A) the mean lens curves for SAC_1 and SAC_4. (B) the mean rewards curves, and (C) the success rate curves for both algorithms. SAC: soft actor-critic; VAE: variational autoencoder.
We investigate how varying training durations might influence the experimental outcomes. As depicted in Figure 10, we employ three training durations: 1M, 1.5M, and 2M, which are denoted as SAC_1, SAC_2, and SAC_3, respectively. These algorithms are distinguished by the colors red, yellow, and green in the figure. We observe that training duration has a negligible impact on the mean_len and mean_rewards of the episodes shown in Figure 10(A) and (B). Figure 10(C) indicates that the success_rate was consistent in the initial stages of training and did not increase, but instead exhibited a sinusoidal pattern over time. Consequently, we conclude that extending the training duration is unlikely to enhance the success_rate.
In this study, we have consistently used high-quality images as inputs to extract a richer set of features. We employed VAEs to derive latent vectors from these images and construct a latent state space. We compared the efficacy of this state space with one utilizing
In the preceding paragraphs, we analyzed the algorithm by comparing training-phase parameter indicators. Subsequently, we evaluated the methods from the perspective of the evaluation phase, as presented in Table 2. Mean_rewards and success_rate were selected as algorithmic indicators. We employed the model saved after training for evaluation and testing purposes. In contrast to the training phase, the evaluation phase strategy is deterministic and lacks exploration. The model from the final training phase was tested 200 times to obtain mean_rewards and success_rate. Five rounds of testing were conducted to calculate an average. We observed that the success rate was significantly higher in the evaluation stage compared to the training stage when using SAC 1, SAC 2, and SAC 3. This is because, after model stabilization during training, the exploration process still introduces disturbances, increasing policy randomness. Furthermore, we found that SAC significantly outperformed both DDPG and TD3. The results indicate that increased training time does not necessarily lead to improved performance. The SAC algorithm with high-quality images as state input consistently outperformed its low-quality image counterpart in autonomous driving navigation tasks, demonstrating superior performance to DDPG and TD3. Our SAC algorithm successfully accomplishes autonomous driving navigation from start to finish in urban environments negating the requirement for high-precision maps and routing systems.
As depicted in the final row of Table 2, we have compared our proposed method with the traditional approach.
The traditional method, which is currently the most stability-deployed system in real vehicles (e.g. Dosovitskiy et al. 15 ), is referred to as planning navigation and control. According to the table, the PNC method exhibits the highest stability and success rate, which highlights the relative immaturity of our method. Additionally, the PNC method has the longest mean trajectory length, indicating that it requires the most time and that the trajectory planning module does not always generate the most optimal path. This underscores a limitation of the PNC approach, where errors in intermediate modules can affect the overall experimental outcomes.
Conclusion
We introduce a novel framework for autonomous driving planning and navigation, which endows autonomous vehicles with human-like driving capabilities. Our method utilizes reinforcement learning to enable autonomous navigation from initial to final destinations within urban settings negating the requirement for high-precision maps and routing systems, mimicking one of the ways humans learn to drive. Innovatively, we incorporate high-quality images and state vectors as multimodal inputs to learn policies from such imagery. Furthermore, we apply VAEs to address the memory-intensive requirements, low training efficiency, and complexity associated with high-quality images. Our method was tested in the CARLA simulation environment and demonstrated superior performance compared to other algorithms.
Although the success rate of our reinforcement learning-based autonomous navigation is lower than that of traditional methods, it is significant in the realm of autonomous learning and decision-making. The training process is particularly challenging due to the complexity of urban environments. Our approach relies solely on onboard cameras and sensors for environmental perception, eschewing the prior knowledge elements, such as lane markings and target recognition, used by traditional methods. This self-learning navigation technique has the potential to surpass human driving capabilities and is thus of profound importance.
In the context of autonomous driving agents, the current environment is complex, yet it remains straightforward for traditional methods and human drivers. This study establishes a foundation for future research, where we anticipate the application of reinforcement learning algorithms to achieve autonomous navigation in even more intricate settings. The existing reward function and state representation are not directly applicable to more complex environments. Therefore, we aim to enhance the generalizability and success rate of reinforcement learning algorithms in future research, primarily through improvements in reward design and state estimation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.