
Abstract
This article presents a novel learning-based optimal control approach for dynamic control of continuum robots. Working and interacting with a confined and unstructured environment, nonlinear coupling, and dynamic uncertainty are only some of the difficulties that make developing and implementing a continuum robot controller challenging. Due to the complexity of the control design process, a number of researchers have used simplified kinematics in the controller design. The nonlinear optimal control technique presented here is based on the state-dependent Riccati equation and developed with consideration of the dynamics of the continuum robot. To address the high computational demand of the state-dependent Riccati equation controller, the distilled neural technique is adopted to facilitate the real-time controller implementation. The efficiency of the control scheme with different neural networks is demonstrated using simulation results.
Introduction
Continuum robotics has made considerable strides in recent years and currently encompasses a diverse variety of applications and technologies. In contrast to most traditional robots comprising rigid linkages, continuum robots (CRs) have flexible parts that enable them to deform continuously, making them ideal for applications requiring intricate motions, ranging from industrial maintenance to surgical operations and space deployment systems. 1 –7
CRs provide a number of benefits over rigid robots, that is, they can operate in restricted and congested environments and manipulate a variety of shapes and types of objects owing to their flexibility without excessive mechanical parts complexity.
Despite the benefits of CRs discussed above, modeling and control of CRs present difficult challenges due to the high level of dynamic complexity, coupling, and nonlinearity. In general, the deformation of CRs may be represented by a suitable kinematics model, which is also a focus of study in the literature; however, such models do not give insight into dynamic behavior. Furthermore, the high-speed movements and inertia decrease the robot’s kinematic model accuracy significantly. Therefore, for accurate control it is necessary to explore the CR dynamic model to analyze the relationship between driving force and bending deformation. 8
In the literature, four approaches for dynamic modeling of CRs have been presented, including Lagrangian method, 9 Cosserat rod theory, 10 constant deformation, 11 and center of gravity. 12 The Lagrangian technique is used for dynamic modeling of the CR in this work, because of its computational efficiency and ease of real-time implementation. 13 However, the Lagrangian approach described in He et al. 9 lacked a general formulation and relied predominantly on Taylor series expansion and several curve fittings to simplify the CR equations. For these reasons, an appropriate technique (adapted from Samadikhoshkho et al. 13 ) is required to handle CR modeling issues in the initial stage of designing the controller.
An effective dynamic control strategy is also required to deal with the system’s complicated behavior. Numerous prior publications have concentrated on the kinematic control of cable-driven CRs, 14 with only a few addressing their dynamic control. 15 –17 The inherent difficulty in designing a controller for a dynamic model is the primary reason that a limited number of works exist on dynamically controlled CRs. More studies have been conducted on the dynamic modeling and control of pneumatically actuated robots 18 –20 than on cable-driven robots. 21 –23
Along with model-based control strategies for CRs, there are model-free control methods that utilize machine learning. 24 Machine learning research to control CRs often employs a supervised learning technique 25 –29 or reinforcement learning (RL). 30,31 Supervised learning approaches are predicated on having the correct answer to the issue available and attempting to learn from it. In Giorelli et al., 25 a feed-forward neural network was trained to learn the inverse kinematics of a cable-driven CR. An experimental study with the same approach 25 was again conducted by Giorelli et al. 26 In Xu et al., 28 the inverse kinematics of the robot was determined using three regression methods, including extreme learning machine, Gaussian mixture regression, and k-nearest neighbors regression. In Bern et al., 29 a neural network was trained to learn the forward kinematics of a soft robot; and an optimal open-loop controller was designed using a gradient-based optimization method.
In RL, a learning agent is rewarded after each action; and this reward indicates how beneficial the activity was. The objective of RL is to discover an optimal policy that maximizes the agent’s cumulative reward over the course of an episode. A reinforcement approach based on a Q-learning algorithm was employed in You et al. 30 to control a soft manipulator in a 2D plane. In Liu et al., 31 proximal policy optimization algorithm was used for locomotion control of a soft snake robot.
RL has several drawbacks. For example, solving a problem with RL requires an appropriate reward function, which can be very challenging to formulate. In addition, every RL algorithm has several hyper-parameters, such as discount factor and time horizon, that significantly affect the solution and need to be carefully tuned. In the present work, a supervised approach is developed based on a specific type of nonlinear optimal control scheme, the state-dependent Riccati equation (SDRE) technique, 32 to optimally control a CR’s dynamics. An optimal control strategy should leverage the flexibility of CRs to advance present applications and incorporate online application in congested, dynamic, and unstructured environments. 33
Although SDRE is a powerful control method that is a nonlinear generalization of the linear quadratic regulator controller, it has rarely been used in the past due to its high computational cost, particularly prior to the development of fast computers and learning approaches in recent years. For example, neural SDRE control of the dynamics of a satellite’s attitude 34 is a recently developed solution for real-time application of the SDRE method. The dynamics of a CR are more complex than those of a satellite, making SDRE control design and implementation for CRs more challenging. To the best of the authors’ knowledge, no optimal SDRE control strategy has yet been developed for CRs due to the complexity of their dynamics.
The purpose of this article is to introduce a novel end-to-end learning-based strategy for dynamic control of a cable-driven CR. Following the training of neural networks to replicate the SDRE controller, the knowledge distillation (KD) method 35 is used to train smaller networks on the basis of previously trained larger ones. Although KD has been mostly applied to classification issues, here it is modified for the regulation challenge. KD enables training smaller networks with fewer parameters while leveraging prior knowledge from larger networks. Additionally, it has a regularization impact that may help networks achieve greater generality. The impact of several network designs is investigated to determine the best effective architecture and learning technique for neural SDRE control of CRs.
Dynamic modeling
Dynamic modeling of a tendon-driven CR, shown in Figure 1, is provided in this section by adapting from Samadikhoshkho et al. 13 and focusing exclusively on the CR described in that work.
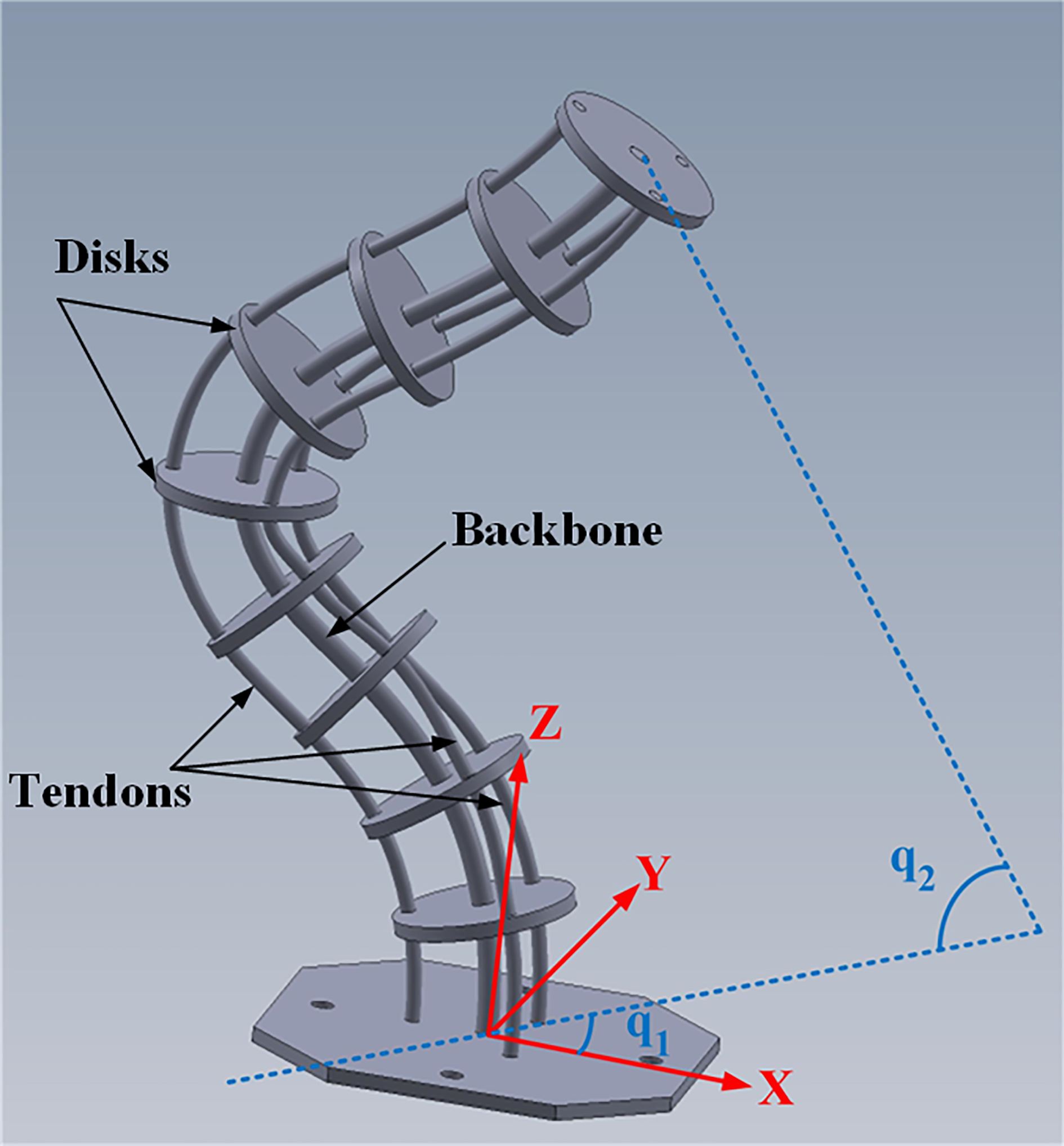
Continuum robot rendering of components and end-effector angles.
Controllable degrees of freedom for a tendon-driven CR are denoted by vector

where q 1 is the horizontal angle of the end-effector with respect to X-axis in the XY plane, and q 2 is the vertical angle of the end-effector with respect to the Z-axis.
To model a flexible continuum arm, it is first necessary to consider a section of the CR and find its kinematics and energy functions. Then, by taking the integral along the length of the CR, the dynamics of the CR can be derived using Euler–Lagrange theory. The position of the end-effector can be determined by rotating the flexible arm coordinate (given by the flexible beam model
9
) about the Z-axis by the angle q
1. In addition, the end-effector orientation (rotation matrix) can be found by performing three rotations around the Z-axis for angle q
1, the Y-axis for angle q
2, and the Z-axis for angle
The rotation matrix between a point of arm at section s and the base of the arm

where vectors
The angular velocity of each section of arm

where

where
By considering Euler–Lagrange formulation, equation (5), a dynamic model of the robot can be derived. To define the Lagrangian of the system,

The kinetic energy of the robot consists of two parts. The first part is related to the main backbone denoted by

Kinetic energy of the backbone at each section s,

where
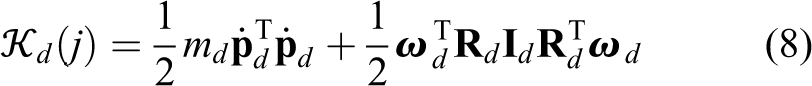
where



in which h, n, md
, and

where l is the length of the backbone.
By using equations (3) and (4), the total kinetic energy can be written as

where

Similarly, the potential energy of the robot

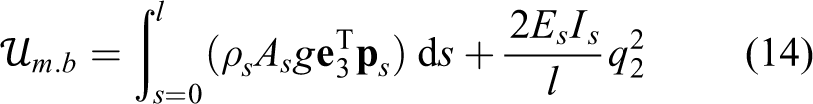

where g is the acceleration due to gravity, e 3 shows direction of gravity, and Es denotes Young’s modulus of the main backbone. Potential energy storage in cables is neglected.
Finally, using equations (11) and (13) to (15), the dynamic model of the system is derived as equation (16)

where
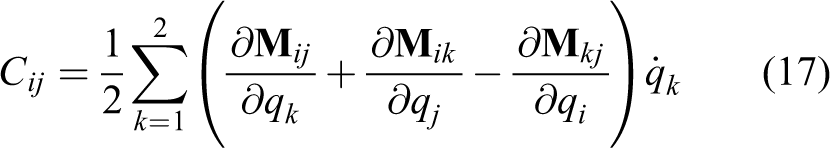

Although the CR has an infinite number of degrees of freedom, only two angles of the end-effector can be controlled by the robot actuators pulling tendons. Therefore, the end-effector position can be changed by adjusting the end-effector angles. Three tendons are responsible for controlling the tendon-driven CR under consideration. The first tendon actuator is positioned along the X-axis, while the other two are each placed at an angle of 120° with respect to the first tendon. Based on the horizontal angle of the end-effector, two tendons should function. Tendons 1 and 2 should be activated if q
1 is between 0° and 120°. Similarly, tendons 2 and 3 should be involved for
The relation between the control signal and tendons tensions

where
Control design
This section discusses the development of the model-based optimal control and learning approach for controlling a CR.
State-dependent Riccati equation
The presented model of the CR in the preceding section reveals a high degree of nonlinearity in the system dynamics. Therefore, linear control techniques may be inapplicable to such a nonlinear system. To deal with the nonlinearity issue and to improve the robustness of the controller, the SDRE approach is suggested to compute the control’s optimal solution at each time step.
To design the controller, it is necessary to first describe the nonlinear equations in a pseudo-linear form with state-dependent coefficients. It is common to express the pseudo-linear structure in the form shown in equation (20); however, a new representation is required to adapt the equations for CR dynamics, as seen in equation (21)

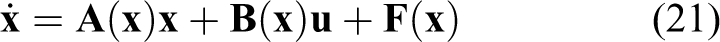
For optimal reference tracking problem of the system presented in equation (21), the error vector is defined as
The control problem is to find the optimal solution for the system by minimizing the following performance measure (cost function), J

where
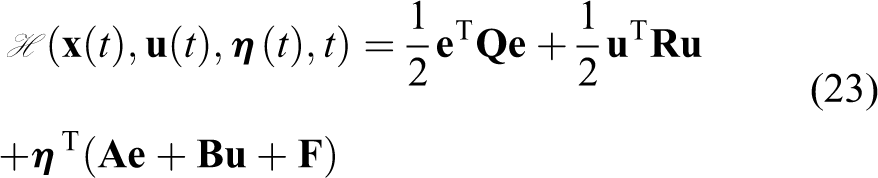
The optimal control gain can be derived by finding the solution for equation (24) (as stated in Kirk 38 ).
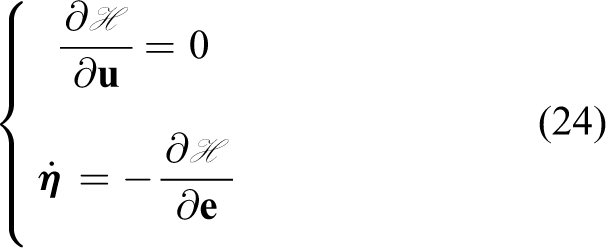
which results in


By defining
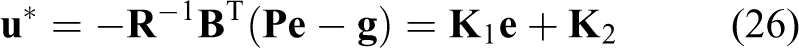
where
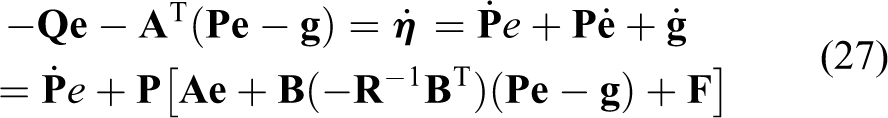
which can be rearranged as

The solution of equation (28) leads to the following equations


The expression in equation (29a) is a well-known Riccati equation, which can be solved for steady-state conditions (to facilitate its real-time application) as seen in equation (30) by setting

By solving the Riccati equation and finding

Finally, having

Also, the quadratic form of the CR equation, equation (16), can be rewritten by expressing equation (21) as

Data acquisition and learning procedure
This work employs a supervised approach to solve the reference tracking problem. Supervised learning aims to estimate the mapping between given input–output pairs, which can then be used to predict the output for any new input. In the scenario under consideration for CR control, the mapping to be estimated is an SDRE controller that receives the dynamical system’s state variables and desired states as inputs and produces the appropriate control signals as outputs.
The training data are generated by the SDRE control technique presented in the previous section. Since there is a reference tracking problem for CR control, both state vector

To train the network, inputs are randomly generated within the appropriate range, and the corresponding outputs are calculated by the SDRE controller. The output of each sample has two potential alternatives, both of which are tried. The first option is to predict the SDRE control gains,
Several types of neural networks can be used to address regression issues, and the problem setup should determine the most appropriate one. The input to the SDRE controller for the CR is a vector with no spatial link between its members, that is, the order of the vector elements is chosen arbitrarily before deriving the dynamical system governing equations of motion. Additionally, because there are no temporal trends in the data, all samples are independent and identically distributed. This is because the SDRE controller computes the control signal only based on the system’s present state and disregards past states. The present work uses multilayer perceptron (MLP) neural networks.
A schematic structure of a simple MLP artificial neural network with input size n, output size c, and two hidden layers is shown in Figure 2. In each neuron (shown as circles in Figure 2), input
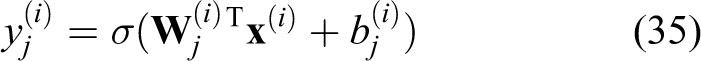
where the input of layer

A multi-layer perceptron neural network—input, layers, and output.
Following training, the neural network is expected to perform well not only on the training data but also on previously unseen test data. This is referred to as generalization, and it is one of the most challenging aspects of machine learning. Another critical issue in particular applications, such as control of CRs, is the size of the neural network (number of parameters). Reducing size of the network can increase its generalization and speed up its execution; however, simply decreasing the size is frequently not a wise approach, because it reduces the network’s complexity and capability to learn increasingly more complicated tasks.
KD 35 is a technique for training smaller networks based on what a larger network has already learned, similar to the concept of fitting data to functions or reducing the order of a set of governing differential equations. Initially, KD was presented as a solution to the classification problem. According to KD, when a large network is trained to solve a classification task, the layer preceding the softmax provides an appropriate embedding for the input data. Hinton et al. 35 recommended concurrently training a smaller network that predicts this embedding and labels the sample. This approach is adopted for CR control in this article.
KD begins with training of a large neural network (teacher network) to solve the regression issue by minimizing the mean squared error (MSE) between network outputs and desired outputs. As indicated in Figure 3, a smaller network (student/distilled network) is then trained in such a way that its output layer accurately predicts the desired outputs, while one of its hidden layers predicts the embedding,

where



The proposed knowledge distillation structure.
Notably, the teacher is not trained during the student network’s training, and back-propagation is performed only on the student network.
In a regression problem with c outputs, there are two types of neural network architectures based on their outputs. The architecture can be either a single network with c outputs or a set of c separate networks with a single output. For KD, if the teacher network is trained with the second scenario (separate networks for outputs), then they can either be distilled separately or the foremost can be merged and then distillation is performed. The performance of these different scenarios will be compared in simulation results section.
The Block diagram of the closed-loop system is shown in Figure 4, in which Controller and System refer to the trained neural network and the dynamic model of the system presented by equation (33), respectively.

The suggested Block diagram for the closed-loop control of CRs. CR: continuum robot.
Simulation results
Simulation was used to assess the efficiency of the proposed neural-based SDRE control approach for tendon-driven CRs with the exact specification as Samadikhoshkho et al. 13 Several networks were trained and compared to determine the best neural controller structure for this CR.
The input dimension of all networks is eight, including four states and four error variables. Different neural network cases are considered as follows: a single network with output of the control signal two networks with output of u
1 and u
2; two teacher networks with outputs of u
1 and u
2 trained separately, then merged and distilled to a single student network with the output of two teacher networks with outputs of u
1 and u
2 trained and distilled separately to networks with outputs of
In case (1), the network has three intermediate (hidden) layers with 500, 500, and 100 neurons while the output layer has two neurons. In case (2), both u 1 and u 2 networks have three intermediate layers and an output layer with 200, 100, 50, and 1 neuron, respectively. In both cases, intermediate layers have “PReLu” activation function.
In case (3), for both u 1 and u 2 networks, networks from case (2) after eliminating their last layers are used. This architecture is shown in Table 1. To form the teacher, networks u 1 and u 2 are concatenated so that the output has two components. This teacher network is then distilled into the student network with the architecture shown in Table 2.
Architecture of each branch of the teacher network (based on u 1 and u 2)—case (3).

Architecture of distilled network—case (3).

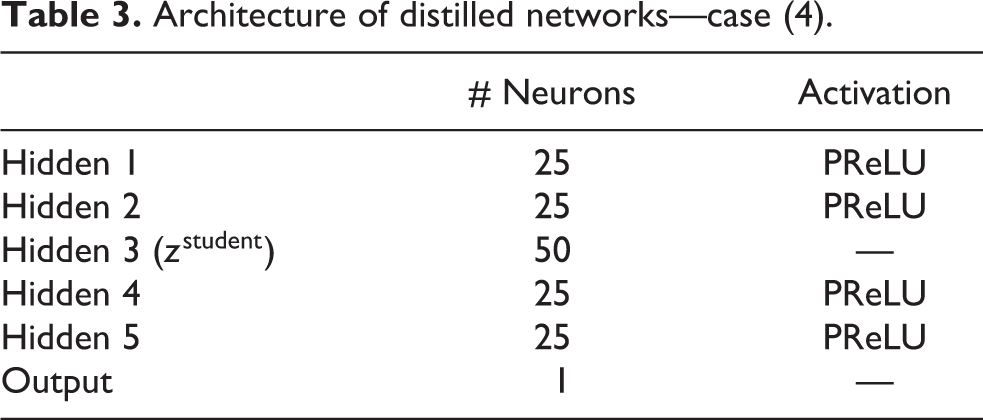
In case (4), each teacher network is identical to that of case (3); however, they are separately distilled to networks with architectures presented in Table 3. Then, these separately distilled networks are augmented and used as controller. Each distilled network has 4130 trainable parameters, which is significantly less than the teacher network with 26,953 parameters.
Architecture of distilled networks—case (4).
Distillation loss in equation (38) is defined as MSE between the output of the third hidden layer of the u-network and the third hidden layer of the distilled network, both of which have a dimension of 50. The student loss is defined as MSE between the output of the distilled network and the ground truth.
To evaluate the performance of the proposed neural network controllers, the following desired trajectory for a circular motion of the end-effector is considered

The control signals (tendon tensions) and end-effector angles, q 1 and q 2, for the results obtained from various neural controllers, as well as those of the model-based SDRE controller, are illustrated in Figures 5 to 9.

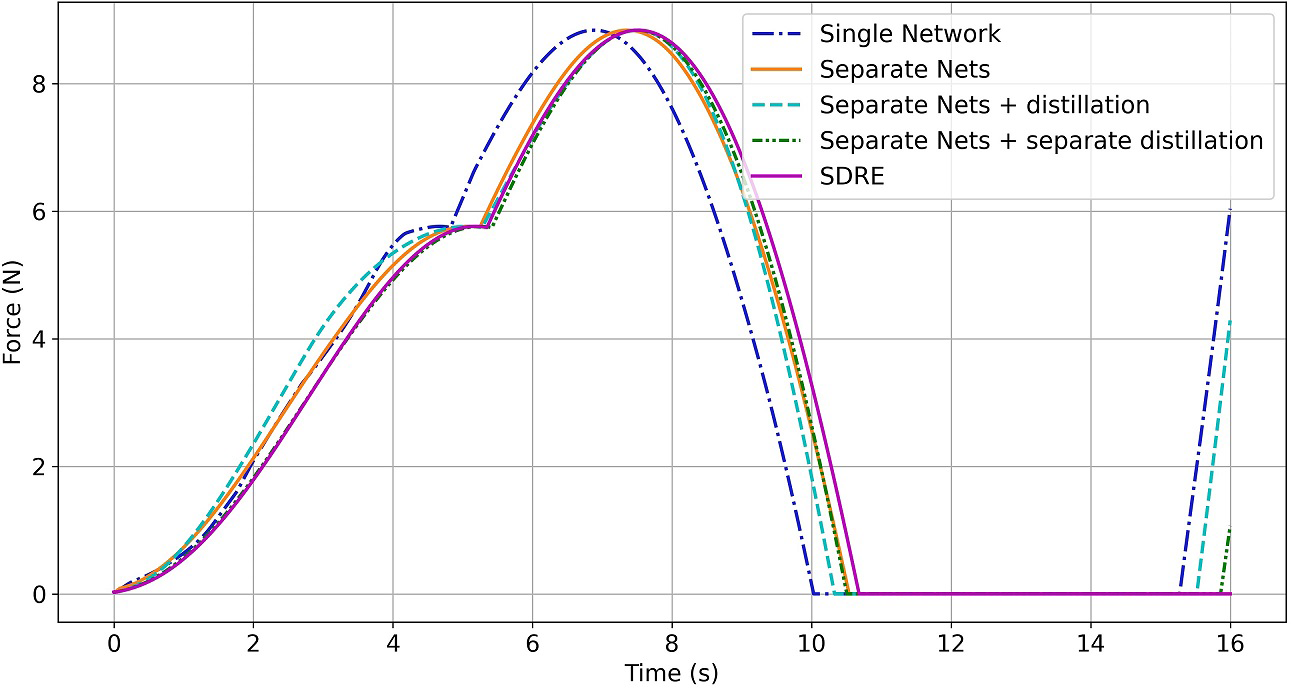
The first tendon force (F 1): comparison between SDRE, single and separate networks, and single and separate distilled networks.
The second tendon force (F 2): comparison between SDRE, single and separate networks, and single and separate distilled networks.

The third tendon force (F 3): comparison between SDRE, single and separate networks, and single and separate distilled networks.

Continuum robot state: q 1 (rad). Comparison between SDRE, single and separate networks, and single and separate distilled networks.

Continuum robot state: q 2 (rad). Comparison between SDRE, single and separate networks, and single and separate distilled networks.
The MSEs of angles q 1 and q 2 in different cases with respect to those of the SDRE controller are compared in Table 4.
MSE of angles.

MSE: mean squared error.
The results in Figures 5 to 7 indicate that case (2) (two separate networks without distillation) and case (4) (two separate networks with separate distillation) perform better than other cases. Additionally, deviation from the ideal SDRE control signal is large in case (3) (two separate networks with a single distillation), although the error is greatest in case (1) (single network without distillation). As seen in Figures 8 and 9, all cases perform well for the angle q 2. However, cases (4) and (1) perform the best and worst in terms of angle q 1 control, respectively. Cases (2) and (4) have very similar performance, but case (4) has very fewer parameters. This result supports the claim that the distilled network can be implemented as a digital controller with a higher sampling frequency on the same hardware.
It can be interpreted that in the multi-output regression problem of CR control, it is preferable to train a network separately for each output to obtain the best performance. As well, when one network with several outputs is trained for such a problem, all of the outputs are functions of some mutual weight (i.e. the parameters of shared layers). This complicates network training. Additionally, distillation should be performed independently on each network for the same reason.
Conclusions
The present work uses neural networks with KD to replicate a powerful but computationally expensive SDRE to optimally control the challenging dynamics of CRs for the first time. While many prior efforts on CR control have focused on the kinematics of the robot, the present work employs the dynamics of the system described by the Lagrangian approach. Different setups for neural network and KD were explored in this respect, and it was found that training a separate network for each output and distilling those networks independently produced the best results for a simple CR in simulation. The comparison between the precise SDRE controller and the neural SDRE controller without KD shows that the trained distilled neural SDRE controller requires less computation. To address time-consuming and labor-intensive process of collecting and classifying data from the real world, all neural networks in this work are tuned using synthetic/simulation data. The proposed controller is applicable to all types of CRs whose models are presented using the Lagrangian technique.
Nomenclature

Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.