
Abstract
Large-scale sheep farming has conventionally relied on barcodes and ear tags, devices that can be difficult to implement and maintain, for sheep identification and tracking. Biological data have also been used for tracking in recent years but have not been widely adopted due to the difficulty and high costs of data collection. To address these issues, a noncontact facial recognition technique is proposed in this study, in which training data were acquired in natural conditions using a series of video cameras, as Dupo sheep walked freely through a gate. A key frame extraction algorithm was then applied to automatically generate sheep face data sets representing various poses. An improved MobilenetV2 framework, termed Order-MobilenetV2 (O-MobilenetV2), was developed from an existing advanced convolutional neural network and used to improve the performance of feature extraction. In addition, O-MobilenetV2 includes a unique conv3x3 deep convolution module, which facilitated higher accuracy while reducing the number of required calculations by approximately two-thirds. A series of validation tests were performed in which the algorithm identified individual sheep using facial features, with the proposed model achieving the highest accuracy (95.88%) among comparable algorithms. In addition to high accuracy and low processing times, this approach does not require significant data pre-processing, which is common among other models and prohibitive for large sheep populations. This combination of simple operation, low equipment costs, and high robustness to variable sheep postures and environmental conditions makes our proposed technique a viable new strategy for sheep facial recognition and tracking.
Introduction
Inner Mongolia and its surrounding areas are the primary producers of the sheep industry. Recent technological advances have driven large-scale developments in this field, with automated sheep identification and tracking becoming high priorities. 1 Currently, individual identification in large sheep farms primarily relies on the use of barcode and electronic ear tags, which can be difficult to implement and maintain. 2–3 In addition, ear tags can be easily lost or difficult to read and suffer from poor anti-counterfeiting performance. 4 As such, techniques such as retinal imaging, iris imaging, and DNA testing have been proposed for sheep identification in recent years. 5 However, the difficulty of collecting biological data and the high cost of required processing equipment has prevented these methodologies from being widely adopted. In contrast, facial recognition relies on the uniqueness of facial features, which are relatively simple to acquire and can be identified using multiple criteria, including position, distance, angle, quantity, shape, and mode. The rapid development of artificial intelligence in recent years, and the similarity between human and animal facial features, has also led to increased activity in this field. 6 –8
For example, Chenyin et al. 9 proposed a giant panda face recognition model based on a back propagation neural network, which used only simple color features and texture-based statistical features. However, these data could not fully describe images of giant pandas, as the recognition rate only reached 80%. Okafor et al. 10 proposed a face recognition algorithm for wild animals based on deep learning and a visual vocabulary bag. Statistical features and color information in images of wildlife were also used, achieving a recognition rate of up to 96.72%. Kozakaya et al. 11 proposed a methodology to detect cat faces using two heterogeneous feature cascade classifiers to extract all possible positions of detected frames. However, the number of false positives was high, with a fixed recall rate of 76%. Du and Zhang 12 utilized image segmentation and mathematical morphology to develop an automated positioning method for macaque facial images. This technique could automatically locate the eyes, mouth, and other features of rhesus monkeys. However, while it successfully produced contours, it was also easily affected by variable lighting conditions and shadows. Ernst and Kublbeck 13 used field data acquired by remote video cameras to detect faces and recognize individual species of African apes, chimpanzees, and gorillas. The algorithm searched candidate boxes and verified important features using a combination of real Adaboost and invariant feature types under different illumination conditions, achieving a detection accuracy of more than 80%. Keyang et al. 14 developed a pig face recognition algorithm based on weighted sparse low-rank component encoding, in which an adaptive gamma correction model was proposed to reduce the influence of varying illumination. A residual function was also constructed to improve recognition performance in images with excessive amounts of dirt, achieving a recognition rate of 94.12%. Each of these techniques utilized significant differences in facial features to identify varying species. However, sheep in the same pasture are mostly half-parents, with a high degree of facial similarity that complicates identification.
Thus, to address the challenges of sheep recognition, Corkery et al. 15 held sheep heads fixed and cleaned their faces to acquire images with a consistent posture. The data were then manually screened and a cosine distance classifier was implemented as part of independent component analysis, achieving a recognition rate of up to 96%. However, this approach is time-consuming and not conducive to large-scale production. Similarly, Bin et al. 16 manually cropped and framed images of sheep to produce training data, achieving a recognition accuracy of 91% with the VGGFace neural network. However, this technique requires extensive manual intervention as data must be processed and annotated using candidate boxes. Yang et al. 17 used a cascaded pose regression framework to locate key signs in sheep faces and extract triple interpolation features. As a result, more than 90% of sheep could be successfully identified using facial markers. However, this approach suffered from similar issues with the calibration of key points in the case of excessive head posture changes or significant occlusions.
While these studies achieved high accuracy, they required significant amounts of data pre-processing, which would be prohibitive for large sheep populations. These and other limitations were addressed in the current study through a combination of strategies, the novel contributions of which can be described as follows: Video data were collected in natural environments, thereby avoiding the need for time-intensive pose restrictions or extensive pre-processing of training images. A key frame extraction algorithm was used to automatically generate image data sets from sheep face video footage. An improved MobilenetV2 neural network module was used to enhance semantic information contained in the extracted features.
Classification and recognition using this method produced high accuracy and low processing times. The proposed model also offers simple operation, low equipment costs, and high robustness, which are more suitable for large-scale industrialized sheep farms.
The remainder of this article is organized as follows. The second section provides descriptions of the data collection process, feature extraction, the generation of training data sets, and construction of the proposed O-MobilenetV2 network. The third section describes the results of validation experiments used to assess network classification performance, including quantitative comparisons with comparable algorithms (i.e., EfficientNet, MobilenetV2, and VGG16). The fourth section concludes the article.
Materials and methods
Materials
A total of 107 Dupo sheep with an average age of 8 months were selected as the research subjects. Dupo lambs grow rapidly and the weight of a mature 4-month-old can reach 36 kg. The height and size of these lambs make them suitable candidates for facial classification and recognition testing. As part of this process, three DS-IPC-B12-I cameras were installed on fixed fence channels at the breeding farm of Hailiutu Science and Technology Park of Inner Mongolia Agricultural University. The cameras were installed in different positions to provide high-definition pictures, as shown in Figure 1. Camera parameters included 2 million effective pixels, a resolution of 1920 × 1080, a video frame rate of 25 fps, an RJ45 10M/100M adaptive Ethernet port, support dual bit stream, and mobile phone monitoring. The sheep were allowed to naturally walk one-by-one through a passage, with each sheep remaining in the camera frame for 10s of video recording time. Sheep faces were imaged from different angles, with a resolution of 1080p at 30 frames per second. Three sets of data were collected as a result and used for network model training, testing, and verification.

The structure of the fixed fence channel. Labels indicate the cameras (1), fixed fence aisle (2), fence channel entrance (3), and fence channel exit (4).
Data set processing
All experiments in this study were conducted on a personal computer (PC) with an NVIDIA GeForce GTX 1060 graphics card and an Intel (R) core (TM) i7-6700 CPU processor. Software was run on the Windows10 operating system using Anaconda 3, Tensorflow (GPU 2.2.0), and Pycharm64. Video footage acquired by the three cameras was processed using a key frame extraction algorithm (SSIM) to avoid overfitting caused by the high similarity between the front and back frames of sheep face data. 18 A total of 5350 images were collected from 107 sheep (50 images for each sheep), with sizes of 224 × 224 × 3. The data were then classified and stored as training and test sets using a ratio of 8:2 (4280 training images and 1070 test images), such that no overlap existed between the training and test data. A sample sheep face set is shown for the 23rd sheep in Figure 2. A verification set was then constructed by randomly selecting images from the training and test sets. Multiple augmentation operations (e.g. rotate, zoom, cut, scale, shear, translate, salt-and-pepper noise, 19 and Gaussian noise 20 ) were then applied to expand the data and prevent overtraining. 21 Figure 3 shows an example of a front-facing image for the 23rd Dupo sheep; Figure 4 provides an example of a side-facing image for the 8th Dupo sheep; and Figure 5 displays the result of data augmentation for the 23rd Dupo sheep.

A sample sheep face data set.

An example of a front-facing image for the 23rd sheep.

An example of a side-facing image for the 8th sheep.

Examples of facial images after data enhancement and augmentation.
Methods
Convolutional neural networks (CNNs) 22 –24 are commonly used in deep learning and can easily identify various local features in images, exhibiting high invariance to deformations such as stretching, translation, and rotation. Each hidden layer node in a convolutional neural network (CNN) is only connected to local pixels in an image, which significantly reduces weight parameters required by the training process. More importantly, CNNs adopt weight sharing, which can reduce model complexity and training costs. 25
VGG16 network
The visual geometry group (VGG) network model 26 solved a problem with 1000 unique categories and target location anchoring at the ImageNet classification and positioning challenge in 2014. The VGG16 network architecture, shown in Figure 6, includes a feature extraction layer with five modules and a filter size of 3 × 3. Image features of size 224 × 224 × 3 were input after gradual extraction using 64, 128, 256, 512, and 512 convolution cores. The full connection layer was composed of two groups of 4096 neurons and activation units in the hidden layer consisted of ReLU functions. Results were acquired using a softmax classification layer with 1000 neurons. Multiple convolution layers with smaller convolution cores (3 × 3) were used to replace larger convolution cores, thereby reducing the number of parameters from 25 to 18 and increasing the network depth. This process was equivalent to additional nonlinear mapping, which improved the fitting and expression capabilities of the network. 15

The VGG16 network structure.
MobileNetV2
MobileNet
27
is a lightweight terminal neural network offering smaller volume, fewer computations, and higher accuracy. The basic unit of MobileNet is a separable operation consisting of depthwise and pointwise convolution layers. Batch normalization and ReLU activation operations are then applied after each convolution layer.
28
This depthwise separable convolution structure plays the same role as standard convolution operations used in feature extraction, though the number of calculations and model parameters are reduced significantly. In this formulation, Df denotes the side length of the input characteristic graph, while Dk is the side length of the convolution kernel. Both the length and width of the characteristic graph and convolution kernel are therefore equivalent. The number of input channels and output channels are represented as M and N, respectively, and the resulting calculation cost for standard convolutions is then given by

where it is evident that a depthwise separable convolution achieves the same effect as a standard convolution layer, though with less space and lower time costs. 29 A linear bottleneck and inverted residual structures were employed in the MobilenetV2 to optimize basic network units, as shown in Figure 7. The building blocks (i.e. bottleneck layers) in MobilenetV2 included residual bottleneck depthwise separable convolutions. Contrary to the regularization and separability of traditional convolution blocks, the depth of the output layer is advantageous for both expressability and network capacity. As such, the basic units of MobilenetV2 are suitable for more efficient memory management.

The MobilenetV2 network structure.
EfficientNet
The primary purpose of EfficientNet is to acquire rational configurations for three parameters: network depth (d), network width (w), and network image input resolution (r), using a neural architecture search.
30
While empirical evidence suggests network performance can be improved by increasing these three values, excessive increases can cause additional problems, including the following. Increasing network depth by adding more layer structures can produce richer and more complex features. However, a disappearing gradient may complicate training if the network is too deep. Increasing network width by including more convolution cores (i.e. adding channels to the characteristic matrix) can produce increasingly fine-grained features and simplify training. Unfortunately, deeper features can also be difficult to learn in networks with large widths and shallow depths. Increasing network image resolution can potentially produce more fine-grained feature templates. However, accuracy gains will inevitably decrease for very high input resolution, which increases calculation costs.
The structure of EfficientNet can be divided into nine stages. The first is an ordinary convolution layer (including batch normalization and a Swish activation function) with a convolution core size of 3 × 3 and a step distance of 2. Stages 2–8 are repeatedly stacked MBConv structures. The ninth stage consists of an ordinary 1 × 1 convolution layer, an average pooling layer, and a fully connected layer, as shown in Figure 8. To explore the effects of the parameters d, r, and w on the final accuracy, we abstract the operations in EfficientNet as follows

where s.t. represents a limiting condition, ⊗ denotes the continuous multiplication operation, Fi indicates an operator, X is the input characteristic matrix, and Hi , Wi , and Ci denote the height, width, and channel value for X, respectively.

The EfficientNet network structure.
O-MobilenetV2 network
An illustration of the calculation costs for MobilenetV2 is provided in Figure 9, where lines are connected between the input and output to demonstrate their dependency. The number of lines roughly represents the number of convolutions in the spatial and channel domains. MobilenetV2 also uses an inverted residual structure in which, prior to the deep convolution layer, the input is fed into a Conv1×1 to reduce the number of channels in the feature graph. A depthwise convolution leading to a Conv1×1 point convolution then increases the number of channels in the feature graph.

A visual representation of MobilenetV2.
The number of input channels was set to M = 6 and the number of output channels was required to be 256. The number of calculations in a standard CNN is then

where the number of input channels is six, the size of the convolution kernel is 3 × 3, and the number of output channels is 256. As a result, the total number of calculations in MobilenetV2 is given by

MobilenetV2 adopts a modular architecture that is similar to a Resnet residual unit (bottleneck version), replacing deep convolutions in the Conv3×3 with depthwise convolutions. The number of required calculations was further reduced by approximately eight-ninths by omitting convolutions in the channel domain. This study introduces a modified MobilenetV2 architecture, presenting an improved version (O-MobilenetV2) requiring fewer computations and offering higher accuracy. As a result, the proposed model is more suitable for real-time sheep facial recognition, as illustrated in Figure 10.

A visualization of calculations in O-MobilenetV2.
Since MobilenetV2 adopts a point convolution–deep convolution–point convolution structure, its computational complexity and parameter quantities follow a deep convolution–point convolution structure. The residual network architecture used by MobilenetV2 also adopts sequential cascading to better retain output characteristics after deep convolutions. Unlike the drop–rise framework used in MobilenetV2, O-MobilenetV2 includes an inverse residual module and adjusts the order of the model architecture, so the input first represents spatial information in a deep separable convolution. The number of required calculations is then reduced through information transfer between the point convolution coding channels in a Conv1×1. A deep convolution (Conv3×3) is then added to acquire feature expression effects for richer input information. Finally, a Conv1×1 point convolution is used to avoid feature zeroing and input information loss. Calculation costs in the O-MobilenetV2 are therefore given by

where the number of input channels is six, convolution kernels have sizes of 1 × 1 and 3 × 3, and the number of output channels is 256. The number of calculations required by the proposed O-MobilenetV2 model (580) is thus approximately 36% the number required by a conventional MobilenetV2 and only approximately 4% the number required by standard CNNs (13824), thereby representing a significant reduction in computational complexity.
This improved MobilenetV2 further modifies the order of the model architecture by adding a Conv3×3 with M = 6 input channels. Images are initially passed through a depthwise convolution performed independently in the spatial and channel domains. The first point convolution (Conv1×1) also plays a role in reducing the dimensions of the input channel, allowing higher accuracy to be achieved with the same calculation costs, by adding a deep convolutional model (Conv3×3). Finally, the dimensions of the output channel can be restored, and a characteristic graph can be acquired through a second point convolution (Conv1×1). The proposed O-MobilenetV2 thereby reduces the number of calculations required in MobilenetV2 by nearly two-thirds, as a sequential cascade mode is adopted between each convolutional layer. In addition, combination with a Resnet model architecture further improved calculation accuracy. ReLU activation functions were used after the depthwise and pointwise convolutions (Conv1×1) to better demonstrate the nonlinear modeling capabilities of our network, prevent a vanishing gradient, reduce dependency between parameters, and alleviate overfitting. A batch norm (BN) layer was also added prior to the ReLU activation function to prevent gradient explosion, accelerate the convergence rate, and improve model accuracy, as indicated in Figure 11.

The deep separable convolution model.
The ReLU activation function can be defined as follows

where X indicates the input and f(x) denotes the output. O-MobilenetV2 retains the advantages of deep separable convolutions in MobilenetV2, which can reduce the number of required convolutions. Furthermore, information in each channel can be completely preserved by adjusting the order of the model architecture and adding a deep convolution (Conv3×3), thereby providing more reliable sheep facial features for recognition. The CNN models discussed above were compared experimentally to verify the effectiveness of O-MobilenetV2, which adopted a softmax classifier with 107 classes. Here, pi (i = 1, 2,…, 107) represents the discrete probability of 107 nodes in the softmax layer, h is the activation of nodes in layer 2, w is the weight of connections between nodes in layer 2 and the softmax layer, and ai (i = 1, 2,…, 107) is the output of corresponding nodes. As a result

wherein the pi term can be calculated as follows

indicating that 107 possible probabilities exist and categories corresponding to the maximum probability form the final prediction category. Softmax classifiers offer high generalizability for the classification of big data and high-dimensional features, making them suitable for sheep facial features.
Experimental results and analysis
Constructing model features
CNNs exhibit several beneficial characteristics, including simplicity, scalability, and domain transferability. 31 In this study, various CNN models were applied to sheep face images, including VGG16, MobilenetV2, EfficientNet, and O-MobilenetV2. The data to which these CNNs were applied are unique, as they exhibited various facial poses. While open-source databases of sheep images have been developed previously, 32 they have exclusively provided fixed-pose forward-facing image samples. Figure 12 shows the results of facial feature classification for the 31st front-facing image of the 23rd Dupo sheep using the proposed O-MobilenetV2 network. Figure 13 shows similar results for the 8th side-facing image of the 8th Dupo sheep using O-MobilenetV2. These visual feature map results demonstrate that highlighted areas of sheep face thermodynamic images are primarily concentrated in the back contour, eyes, ears, nose, and mouth. The data distribution in highlighted areas emphasizes these features and lays a foundation for achieving more accurate recognition. This approach offers high generalizability and efficiently solves the problem of feature expression in the field of sheep face recognition.

An example of a characteristic thermodynamic diagram for a front-facing sheep model.

An example of a characteristic thermodynamic diagram for a side-facing sheep model.
Network training and evaluation
This study involved the use of four network models: VGG16, MobilenetV2, EfficientNet, and O-MobilenetV2, for classification experiments including 107 front- and side-facing images of sheep faces in natural environments. Training accuracy and loss were then evaluated and compared for each of the four networks discussed above. The best performance was achieved using the O-MobilenetV2 structure, demonstrating the proposed CNN can effectively improve recognition rates in classification tasks. Parameter settings for the four network models used in classification are listed in Table 1, while Table 2 provides a comparison of the accuracy and training loss. It is evident that if the parameters remain constant, as is the case in a lightweight network, the number of instances in which MobilenetV2 or O-MobilenetV2 read discontinuous memory at runtime is less than that of an ordinary neural network. In addition, the runtime on a GPU was shorter than that of VGG16 and EfficientNet. Furthermore, to verify that O-MobilenetV2 achieved better performance, 107 sheep data were trained using the same set values as the first three network model parameters. Corresponding results included an accuracy of 95.88%, a loss of 0.00598, and an iteration time of 196 ms for each group. These values demonstrate that O-MobilenetV2 offers high robustness, low runtimes, and high accuracy for the classification and recognition of sheep faces in natural environments.
Parameter comparisons for various CNNs.

CNNs: convolutional neural networks.
Training results for various CNNs.

CNNs: convolutional neural networks.
Algorithm performance was further evaluated by plotting the accuracy as a function of epoch number, as shown in Figures 14 to 17. Specifically, Figure 14 displays the accuracy of four different models applied to front-facing sheep images, in which it is evident that O-MobilenetV2 converges much faster than EfficientNet. Figure 15 shows the same results for side-facing images, in which it is clear O-MobilenetV2 is more stable than VGG16 and MobilenetV2. This stability is further evident in Figure 16, which shows training loss produced by each algorithm for front-facing images. Figure 17 shows the same results but for side-facing images, in which the stability of O-MobilenetV2 is obvious compared to other algorithms that oscillate dramatically.

A comparison of training accuracy for various CNNs applied to front-facing sheep images. CNNs: convolutional neural networks.

A comparison of training accuracy for various CNNs applied to side-facing sheep images. CNNs: convolutional neural networks.
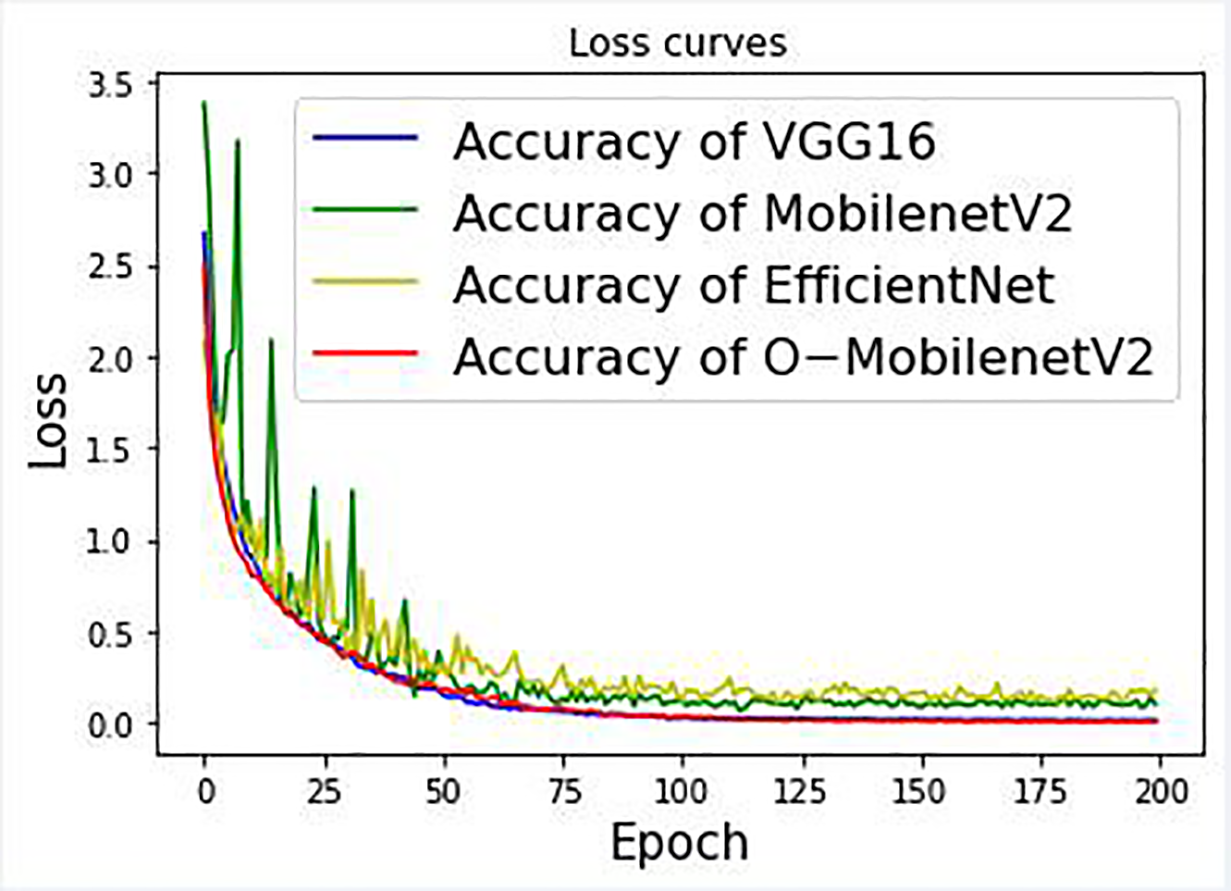
A comparison of training loss for various CNNs applied to front-facing sheep images. CNNs: convolutional neural networks.

A comparison of training loss for various CNNs applied to side-facing sheep images. CNNs: convolutional neural networks.

The accuracy of various CNNs. CNNs: convolutional neural networks.

Training loss for various CNNs. CNNs: convolutional neural networks.
Experimental results and analysis
This study has demonstrated that collecting images of sheep as they pass through a fixed fence channel under natural conditions is both feasible and accurate. Facial recognition technology was successfully implemented, achieving competitive identification performance. The improved O-MobilenetV2 proposed as part of the study combines a standard CNN with the design of an inverse residual module. It first introduces spatial information in a deep separable convolution and then uses the transmission of information between point convolutions (Conv1×1) and coding channels to reduce the number of required calculations. Adding a deep convolution (Conv3×3) also produced richer feature expression effects. Feature zeroing and information loss were then avoided using the Conv1×1.
Validation experiments were conducted in which face images were randomly selected and input to the networks discussed above. O-MobilenetV2 achieved better performance for sheep face classification and recognition than comparable algorithms, offering higher recognition accuracy, shorter recognition time, and strong robustness to the surrounding environment. As shown in Tables 1 and 2, the total number of parameters required by O-MobilenetV2 was only 2.9M, which is approximately 69% of the number required by MobilenetV2 (4.2M), approximately 55% of the number required by EfficientNet (5.3M), and approximately 2% of the number required by VGG16 (138M). The corresponding time per step was only 196 ms, which is approximately 71% that of MobilenetV2 (277 ms), approximately 63% that of EfficientNet (309 ms), and approximately 54% that of VGG16 (361 ms). These improvements demonstrate the benefits of our proposed methodology.
Conclusion
In this study, sheep facial information was acquired in a noncontact, stress-free, natural environment. Digital image processing technology was then utilized to synthesize specific characteristics and model parameters, thereby extracting facial features with strong generalizability and useful semantic information. Compared with existing sheep recognition, this method simplifies the identification process, is more humane, and meets the requirements of digitization and automation for large-scale sheep industries. The proposed O-MobilenetV2 also offers improved performance with fewer calculation requirements and utilizes a wider short connection to transfer more information from input to output. This provided an increased gradient return, thereby ensuring that separable depthwise convolutions were processed in high-dimensional space and facilitating richer feature expressions.
This study did include some limitations, as data were acquired using the same gate passage in each instance. As such, certain issues that have been problematic in previous studies, such as highly variable external environments (e.g. excessive amounts of mud or dirt on sheep faces, poor lighting, etc.) and occlusions (e.g. poor weather, foreign objects in the video frame, etc.), were not specifically addressed. While the nature of continuous video collection may eliminate some of these issues, the robustness of O-MobilenetV2 in these and other problematic conditions will be the subject of a future study. As demonstrated, this approach exhibits higher recognition accuracy, higher robustness, shorter runtimes, and enhanced anti-counterfeiting performance, providing a convenient new strategy for animal face recognition and tracking.
Supplemental material
Supplemental Material, sj-pdf-1-arx-10.1177_17298806231152969 - Sheep face recognition and classification based on an improved MobilenetV2 neural network
Supplemental Material, sj-pdf-1-arx-10.1177_17298806231152969 for Sheep face recognition and classification based on an improved MobilenetV2 neural network by Yue Pang, Wenbo Yu, Yongan Zhang, Chuanzhong Xuan and Pei Wu in International Journal of Advanced Robotic Systems
Supplemental material
Supplemental Material, sj-pdf-2-arx-10.1177_17298806231152969 - Sheep face recognition and classification based on an improved MobilenetV2 neural network
Supplemental Material, sj-pdf-2-arx-10.1177_17298806231152969 for Sheep face recognition and classification based on an improved MobilenetV2 neural network by Yue Pang, Wenbo Yu, Yongan Zhang, Chuanzhong Xuan and Pei Wu in International Journal of Advanced Robotic Systems
Supplemental material
Supplemental Material, sj-pdf-3-arx-10.1177_17298806231152969 - Sheep face recognition and classification based on an improved MobilenetV2 neural network
Supplemental Material, sj-pdf-3-arx-10.1177_17298806231152969 for Sheep face recognition and classification based on an improved MobilenetV2 neural network by Yue Pang, Wenbo Yu, Yongan Zhang, Chuanzhong Xuan and Pei Wu in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Inner Mongolia Autonomous Region (2020BS06010) and the Science and Technology Planning Project of Inner Mongolia Autonomous Region (Grant No. 2021GG0111).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.