
Abstract
Point cloud semantic segmentation based on deep learning methods is still a challenge due to the irregularity of structures and uncertainty of sampling. Color information often contains a lot of prior information, whereas the existing methods do not attach more importance to it. To deal with this problem, we propose a novel hard attention mechanism, named color-guided convolution. This convolution operator learns the correlation between geometric and color information by reordering the local points with color-indicated vectors. In addition, the global feature fusion is proposed to rectify features selected by the feature selecting unit. Experimental results and comparisons with recent methods demonstrate the superiority of our approach.
Introduction
With the strong ability to reflect real scenes, three-dimensional (3D) data are getting more and more researchers’ attention. A point cloud is the main format of 3D data, and the semantic segmentation of the point cloud is the essential work for scene understanding, which is the key to the development of robots, autonomous driving, virtual reality, and remote sensing mapping. Inspired by the successes of deep learning methods in two-dimensional (2D) images and one-dimensional texts, many researchers have applied these techniques to analyze 3D point clouds. 1,2 Unfortunately, it is difficult to use point clouds as direct input because they are intrinsically unstructured and disordered. 3
The key of current deep learning methods for the semantic segmentation of point cloud is to construct ordered structures and then apply convolution operators to them. Recent research studies on construction methods can be mainly summarized as projection mapping, constructing graphs, and modeling local context.
Multi-view method 4 and its variant 5 –7 project a global point cloud onto a regular structure, such as a 2D image. Two-dimensional convolution will be done on mapping results. Due to the self-sealing nature of the object’s spatial surface, it is likely to be many-to-one mapping, which means prone to occlusion. Furthermore, this mapping rule is artificially selected, and distortion is inevitable. The method in Maxim et al. 8 projects the local point cloud onto its tangent plane, then processes the projected image with two-dimensional convolution, and then adopts more reasonable projection rules but still relies on the estimation of the tangent plane. The voxel-based methods 9 –11 project point clouds onto 3D grids in Euclidean space. Sparse representation-based classification methods, 12 for example, hash map, were also used to improve the retrieval performance. However, the convolution kernels of voxel-based methods and sparse representation-based classification methods are strictly limited to the grids, and the fine local structures are ignored by kernels. Although the above methods have achieved certain performance, information loss is inevitable, especially for local details, which play a decisive role in the understanding of complex scenes.
Graph convolution methods have also been applied to the point cloud segmentation task. 13 –15 These methods process unstructured data by constructing an adjacency relationship of point clouds, and the convolutions are performed on the graph adjacency relationship. The spectral CNN method 15 enables weight sharing by parameterizing kernels in the spectral domain spanned by graph Laplacian eigenmodes. This spectral convolution usually requires expensive computations, and a spectral CNN model learned on one graph cannot be transferred to another graph that has a different Laplacian matrix. The authors in the literature studies 13,16 define convolutions directly on a graph with local neighbors in a spatial domain, and the problem is formulated as a prediction on graph-structured data. However, their convolution weights are mainly generated according to the predefined local coordinate system, while neglecting the structure of the objects for semantic segmentation.
PointNet 17 is the milestone to directly deal with the raw point cloud with the neural network. It inputs the whole point set into a shared multilayer perceptron, named MLP, for convolution. Although PointNet can handle unordered points, there are no local geometric contexts in PointNet, and sampling noise is not considered. The performance of PointNet is moderate. However, the authors of PointNet++ 18 integrate deep hierarchical feature learning on point sets with local context in the network. It is achieved by applying iterative farthest point sampling and ball query to group input points. KD-network 19 first builds a KD-tree on input point clouds and then the hierarchical groupings are applied to model local dependencies in points. RSNet 3 models in point clouds and designs the slice pooling layer to project features of unordered points onto an ordered sequence of feature vectors. Then, RNNs can be applied to them. PointCNN 20 proposes to transform neighboring points to the canonical order and then applies convolution. KCNet 21 improves the PointNet model by defining a set of learnable point set kernels for local neighboring points and presents a pooling method based on a nearest-neighbor graph. All these methods achieve promising results and show the ordered structures of local context are very important for point cloud semantic segmentation. However, there is still a gap between the performance of point cloud semantic segmentation and color segmentation of 2D images based on deep learning methods.
All the above methods focus on handling only geometric features on local point sets or parts of point clouds without using any color features. In human perception, sometimes color can be superior to geometric features when color can instantly make objects distinguished from the surrounding environment. Some researchers introduce the color information of point clouds into semantic segmentation. The authors in the literature 3,21 use special context to reorganize points and take RGB as extra features. The work from Jiabao et al. 22 proposes a semi-supervised prediction model, which exploits the improved unsupervised clustering algorithm to establish the fuzzy partition function, and then utilizes the neural network model to complete the future information prediction. The work from Jiachen et al. 23 proposes a fully connected attitude detection network (FADN), which combines neural networks and traditional algorithms for 3D attitude angle estimation. FADN provides a whole process from the input of a single frame image in the industrial video stream to the output of the corresponding 3D attitude angle estimation. The convolutions of TangentConv 8 are applied to them. However, the orientation of the tangent is estimated according to the local shape curvature, which is not stable because of curvature estimation in the local region. TangentConv evaluates convolutions on virtual tangent planes at every point and finds that adding RGB information can significantly improve the scores on Semantic3D. In addition, TangentConv takes additional depth, height, and normal information and combines them with color information, which means the combination of color and geometry is important for segmentation. The work from Verdoja et al. 24 presents a novel fast method for 3D colored point cloud segmentation, and it starts with supervoxel partitioning of the cloud. Then, it leverages a novel metric exploiting both geometry and color to merge the supervoxels iteratively to obtain a 3D segmentation where the hierarchical structures of partitions are maintained. The work from Wang et al. 25 produces predictions for points by similarity groups. The above four works simply regard original RGB as an input feature directly and require additional processing to obtain the improvement of performance.
To sum up, most of the existing works of point cloud semantic segmentation ignore the color characteristics of point clouds. Some works directly take the color information as the input and neglect the vital role of color in recombining geometric information. Usually, the change of color often reflects the change in the spatial characteristics of objects. Making full use of color information can strengthen spatial characteristics. How to explore the inner relationship between color and geometry in local contexts is very important to semantic segmentation.
In this article, we propose a novel network, color guided convolutional network (CGCN), which takes color information to refine the ordering of the local point set. CGCN directly takes point clouds as inputs and outputs semantic labels. Our local context ordering of points and feature is achieved by color distribution. The color-guided directions are shown in Figure 1.

Reorganization of three directions in local neighborhoods. (a) Lighter color means a smaller cosine distance to the direction vector and (b) points are selected in each direction.
Performing the color processing in the local neighborhood of the point can not only keep the spatial continuity of point clouds but also guide the orderly sampling of local points according to the color features so that the subsequent convolution operator can extract the color features of the object more effectively. The proposed CGCN achieves efficient point cloud segmentation by learning the features where the color changes. Specifically, the segmentation results are better for points in different categories with different colors. Our method is demonstrated to be effective and applicable to indoor and outdoor scenes with a backbone network, like PointNet++.
18
Furthermore, the segmentation performance of the method in scenes with simple texture and color changes has a great improvement as shown in the section “Experiments.” To summarize, our main contributions are as follows: We propose a simple and efficient method for the reorganization of a local structure by color information. We propose a novel network, named CGCN, to encode detailed geometric features where the color changes. Furthermore, the interaction of geometry and color is explored to make information fusion for semantic segmentation. With the proposed CGCN, the color-spatial-fusion model for semantic segmentation is trained end to end and performs best among others with the same backbone network.
In the following parts of the article, details about the CGCN are presented in the second section. The third section reports all experimental results and the fourth section concludes.
Color guided convolutional network
The point clouds are unordered point sets with a format like
Considering the fact that geometry and color are not in the same distribution, we apply a network architecture to deal with geometric feature learning and color feature auxiliary encoding and use two cross paths to learn point coordinates and point color information, respectively. The network for coordinate information has more parameters to fit the complex geometric features of objects. The other network is relatively simple because the color information is an effective feature of semantic segmentation and too many parameters may bring overfitting. In fact, color information gives the relative position of objects from one or more categories. In local neighbors, indicator vectors represent this relationship. Furthermore, geometry and color information are merged for global fusion. Color information contributes to learning the distribution of points from different categories in geometric space, so as to get better semantic segmentation.
Framework of CGCN
In Figure 2, we give the presentation of our framework, which consists of two interlaced feature-encoding paths, the local encoding part and the color encoding part. The two encoding paths build several hierarchical feature abstraction levels. Each encoding level is composed of local fusion and color-indicated modules. The outputs of shared-MLP and color-indicated modules fuse together and are sent to the next level. After feature encoding, the extracted features are then fed to the feature interpolation module to obtain recovered features of a higher resolution. Then, the recovered features at each level are linked to the encoded feature from the same resolution and sent to the next interpolation part. Afterward, the recovered geometry and color features for each point are followed by fully connected (FC) layers. Finally, the fused global features are followed by FC layers, and the prediction of each point is obtained.

Illustration of our CGCN architecture. CGCN: color guided convolutional network.
The color-indicated module is the main function module in CGCN and is detailed in the next section. This module takes a
Color-indicated module
The key point for dealing with color information is how to use the color feature while there is a weak correlation or non-correlation between color consistency and geometric consistency. That means objects of the same or similar colors may be spatially independent. For example, a wooden door is the same color as a wooden table, but they are completely different in geometry and separated in space. We put the color-processing module in local neighborhoods, which can keep the continuity in space. In addition, color information gives the straightforward relative position of local points. Our encoding module is based on this relative position and digs local distributions of color and points. From this relative position, we get three vectors
Points and feature selecting unit
This part is the first step for color-encode in local neighborhoods of every sample point. The inputs of this unit are the unordered point clouds

where
From ordered
The first direction in
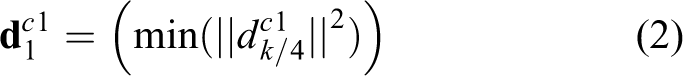
To reflect the whole special context, the second direction

Vector
For points with different labels in a neighborhood,
After getting the orientation vectors, the points
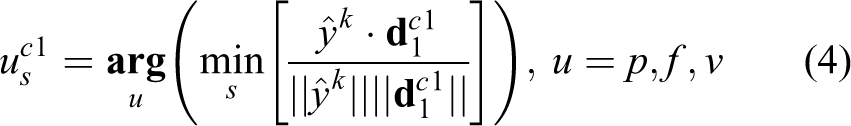
The points in neighborhoods are encoded by the angles between relative position and color-indicated vector. With the same process, points, which are close to, and corresponding features are also selected and reordered as shown in Figure 3. For points with the same labels in a neighborhood, these vectors lead to the sample of points with various colors. The three directional vectors describe a distinct distribution of color, and they are rotation-invariant and robust to illumination effect.

Reordered points in three directions.
Color-indicated convolution
As shown in Figure 4, the first layer in color-indicated encoding is the convolution of ordered vector



Color indicated module. c1 and c2 are components of the color.
Here,



Feature decoding and loss function
For better recovery of geometric and color features, a color feature interpolate module is used to decode points with distinct color features and point features. The interpolate method is shown in Equation (10). The color features fj
are from l layer to
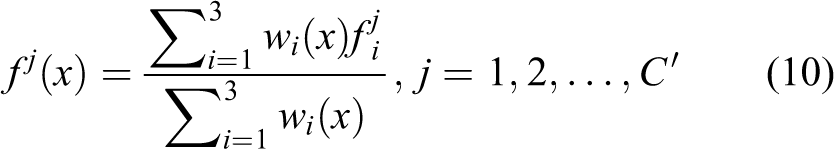

Here,
As shown in Equation (12), the first term of the loss function is the added four-order regular term. The second term is the cross-entropy loss, which measures the error between the predicted value and the true value

Here,
Experiments
Segmentation of benchmarks
Before being fed into CGCN, the point cloud needs to be processed. In real scenes, color information shows the design style or the type of material. However, the effect of the light may distort the real color to some extent. So, we hope preprocessing of color information can decrease noise as much as possible. To obtain such an effective and mutually independent color descriptor, we convert the color from RGB to HSV and just ignore the third component in HSV. From real-life experience, hue is the primary way to judge the difference between objects with various colors. Moreover, saturation is the secondary way. Thus, we choose these two components to complete preprocessing.
We evaluate the performance of CGCN on the Stanford 3D data set (S3DIS) 26 and Semantic 3D. 27 Two metrics, mean intersection over union (mIOU) and mean class recall (mRec), are used to measure the segmentation performance.
Training and inference details
Moreover, the number of neighbor points k is set to 32 for all data sets. The base learning rate was set to 0.001. The Adam solver is adopted to optimize the network with momentum set to 0.9. The above parameters in the part “Key parameter studies,” and , are the hue and saturation components of color, which means we translate color format from RGB to HSV and we only adopt the first two components of HSV. In the color-convolution block, there are two
Evaluation of S3DIS
For the S3DIS data set, the scenes are first divided into smaller cuboids using a sliding window of a fixed size on

Sample segmentation results on the S3DIS data set. From top to bottom are the input scenes, ground truth, results produced by PointNet, and results of CGCN. CGCN: color guided convolutional network; S3DIS: Stanford 3D data set.
Test on area 5 (S3DIS).

The best performance are marked in bold. S3DIS: Stanford 3D data set; mIOU: mean intersection over union; MRec: mean class recall.
Table 2 presents the k-fold results onS3DIS. As shown in the results, our proposed CGCN can achieve the best performance with the semantic segmentation mean recall of 68.4%. Compared with the MLP- and RNN-based methods, 3 we get a 1.9% improvement in mRec and 1.3% improvement in mIOU.
Results of different approaches on Semantic3D.

The best performance are marked in bold. mIOU: mean intersection over union.
Evaluation of Semantic3D
The Semantic3D data set consists of 15 point clouds for training and 15 for testing. We only use the 3D coordinates and color information to train and test CGCN. The training/testing split in Hugues et al. 29 is used here to measure the generalization ability.
Table 3 shows the segmentation results on Semantic3D, and our CGCN exerts advances in several categories, such as manmade terrain, natural terrain, and low vegetation. The color at the boundary of these objects changes, and the geometric structures of these categories mentioned above are relatively simple compared with other hardscapes. The segmentation result of buildings is not as good as expected. The prime reason is that different styles of buildings have different color distributions. In addition, the arrangement of windows brings trouble to get a stable color-indicated vector. We believe that the significant progress in combining geometry and color information depends on the efficient color-indicated encoding.
Test on 6-fold CV (S3DIS).

The best performance are marked in bold. S3DIS: Stanford 3D data set; mIOU: mean intersection over union; MRec: mean class recall.
According to the experimental results, the color-indicated module in CGCN picks out some points with color changes and becomes a good supplement to the segmentation of geometric features, especially for those objects with distinct color differences and few textures. However, when an object is similar in color to its surroundings, such as a column, the color-indicated module learns unstable noise. In the S3DIS data set, some doors have the same color as the walls, which brings a barrier to the segmentation of doors and walls. For outdoor scenes, compared with other categories of objects, the color texture of cars is more complex and diverse, and its segmentation accuracy is relatively low.
Key parameter studies
The proposed color-indicated encoding module is very important in our CGCN. In this section, we further deeply validate the effects of various parameters choices. In particular, several key parameters are considered: (1) the power in ordering operation, shown in Equation (1), and (2) the number of the selected points
Power in ordering operation
This hyper-parameter t is used to measure the change of various color components. It controls the offset to the mean t value of color components from k neighbors. In Table 4, we list the results of different values, 0, 1, and 2, with different ordering strategies of offsets. The results in Table 3 show that the power of
Results of different t and m values on S3DIS (area 5).
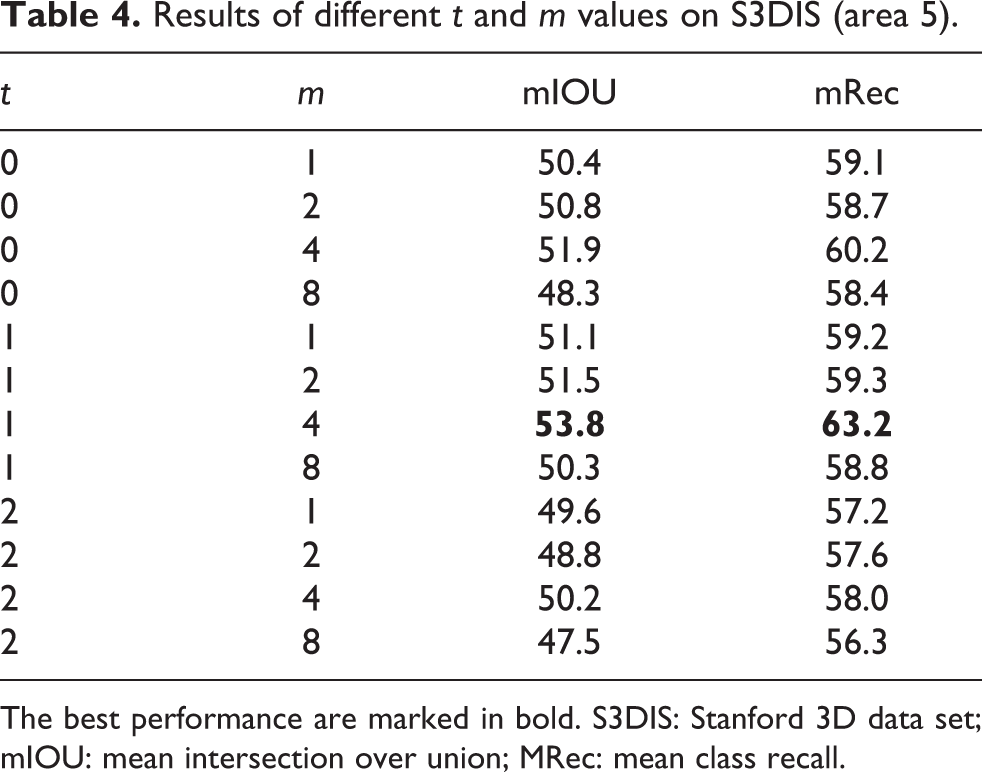
The best performance are marked in bold. S3DIS: Stanford 3D data set; mIOU: mean intersection over union; MRec: mean class recall.
Number of selected points
The number of selected points means how many points to choose in three directions. If the value m in
Conclusion
In this article, we propose an efficient 3D segmentation network named CGCN. The key idea is to select points in local neighborhoods with color differences and guided vectors. More importantly, those vectors are only decided by color distribution and thus rotation-invariant. Experimental results show that CGCN achieves an effective combination of color and geometric information and can be applied to the semantic segmentation of large indoor and outdoor scenes.
Footnotes
Author contribution
Jing Yang and Haozhe Li contributed equally to this work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China [Grant No. 2020AAA0108100], the National Natural Science Foundation of China [Grant Nos. 62073257 and 62141223], and the Key Research and Development Program of Shaanxi Province of China [Grant No. 2022GY-076].