
Abstract
This paper introduces CLAM, a hybrid deep learning framework that integrates CNNs, LSTMs, and Attention Mechanism (AM) for straightforward multi-step stock trend forecasting. By leveraging CNNs for spatial feature extraction, LSTMs for capturing temporal dependencies, and AM for dynamically focusing on relevant data, CLAM significantly outperforms traditional models in predictive accuracy. Evaluated on diverse stock datasets from different industries, CLAM demonstrates an average reduction of over 80% in MAE and RMSE compared to standalone CNN, LSTM, and fused CNN-LSTM. The model’s ability to capture both short-term and long-term trends is particularly advantageous for real-time financial trading, resulting in 75% trend prediction accuracy, with most cases witnessing consecutive accurate forecasts of flash crashes or uptrends, which aids in strategic investment decisions and risk management. Code and data are available at: https://anonymous.4open.science/r/CNN-LSTM-AM-AB13/src/CLAM.ipynb.
Introduction
Concerning the evolving industrial landscape, technological innovation and financial strategy intersection has become vital (Porter, 1985). Artificial Intelligence (AI) is leading this transformation, with advanced neural network architectures such as Convolutional Neural Networks (CNNs) (LeCun et al., 1998), Recurrent Neural Networks (RNNs) (Mikolov et al., 2010), Long Short-Term Memory Networks (LSTMs) (Hochreiter & Schmidhuber, 1997), and Transformers (Vaswani et al., 2017) driving advancements in healthcare (Esteva et al., 2019) and meteorology (Ham et al., 2019) is well-recognized. Nevertheless, its influence on finance is the most promising (Nguyen et al., 2015) as the digital economy amplified the role of Machine Learning (ML) in financial markets, where predictive modelling is essential for forecasting stock prices (Gu et al., 2018) and informing investment strategies (Henrique & Sobreiro, 2019). Recovering from the pandemic, the need for precise financial predictions has grown strongly (Sharif et al., 2021). Investors increasingly rely on algorithmic modelling to navigate through market complexities, thereby capitalizing on opportunities from quantitative trading of stocks (Hagenau et al., 2013).
Traditional models such as ARIMA (Autoregressive Integrated Moving Average) (Box et al., 2015), SARIMA (Seasonal ARIMA) (De Gooijer & Hyndman, 2011), and Linear Regression (Montgomery et al., 2012) are predicated on the assumption that historical patterns and trends can effectively predict future stock prices. However, the non-linear nature of stock movements often introduces significant biases in these models (Tsay, 2005), which tend to oversimplify complex financial dynamics by assuming fixed data variance and linearity (Cont, 2001). This simplification overlooks critical factors influencing stock prices over time, such as macroeconomic indicators (Fama, 1981), market sentiment (Baker & Wurgler, 2006), and herd behaviour (Bikhchandani et al., 1992). The emergence of Machine Learning (ML) and Deep Learning (DL) models has addressed many of these limitations (Hochreiter & Schmidhuber, 1997). Techniques like Support Vector Machines (SVM) (Vapnik, 1995), Decision Trees (Breiman et al., 1984), and Random Forest Regression (RFR) (Liaw & Wiener, 2002) have advanced the ability to capture non-linear relationships by integrating multiple features and learning from large, complex datasets (Chong et al., 2017). DL, as a subset of ML, has further transformed forecasting with deep neural architectures like CNNs (LeCun et al., 1998), RNNs (Mikolov et al., 2010), and LSTMs (Hochreiter & Schmidhuber, 1997), employing hierarchical end-to-end learning that excels in handling unstructured data and scaling with increasingly large time series datasets (Zhu et al., 2018). Additionally, hybrid models that combine elements of traditional statistical methods with ML and DL techniques are reshaping the forecasting landscape (Zhang et al., 2017). These hybrid approaches, by integrating multiple modalities, enhance feature extraction and provide deeper insights into data irregularities (Wang et al., 2019) for a more robust financial system. Nonetheless, despite their improved accuracy, ML and DL models bring challenges such as overfitting (Hastie et al., 2009), interpretability issues (Lipton, 2018), and the necessity for large datasets.
Building on this concept, this paper introduces the CLAM model to forecast the weekly trend of financial assets. CLAM is a hybrid deep learning architecture that combines stacked layers of
This paper is organized as follows: Section “Literature Review” reviews financial forecasting literature, emphasizing the limitations of traditional models and advances in hybrid approaches. Section “Methodology” outlines the data processing, metrics, and CLAM architecture. Section “Experiments and Results” describes the experimental setup, model comparisons, and performance results. Section “Discussion” discusses the findings and potential improvements. Finally, Section “Conclusion” summarizes and suggests directions for real-time financial trading applications. CLAM is built on our previous publications (Anh & Ha, 2024a, 2024b; Anh et al., 2024).
Literature Review
Related Work
The stock market represents a complex system influenced by a wide range of often unrelated factors, such as psychological behaviour and economic conditions. Among various forecasting models, the Back Propagation Neural Network (BP-NN) has been shown to outperform others, such as ARIMA and Random Forest Regression (RFR), in predicting the one-year stock prices of Chinese vaccine manufacturers (Chen et al., 2015). This outcome is particularly beneficial for investors within the pharmaceutical sector. Additionally, a combination of Seasonal ARIMA and Extreme Gradient Boosting (SARIMA-XGBoost) has demonstrated impressive accuracy in forecasting the Indian Stock Index (Mahajan & Sinha, 2020), reflecting the potential of hybrid models in achieving high predictive performance. Similarly, the RFR model has been effective in predicting stock prices of companies listed on Indian exchanges, further indicating the utility of ML models in financial forecasting (Bhuriya et al., 2017). These traditional ML approaches have proven effective, but the advent of Deep Learning, a subset of ML, has introduced a new level of precision in model development by autonomously learning hierarchical data representations (LeCun et al., 2015). To advance stock market prediction, Wang et al. (2019) introduced a model that combines the LightGBM algorithm with wavelet packet decomposition (WPD) to filter out data noise before forecasting the Shanghai Composite Index. This hybrid approach successfully predicted the market trend over a 10-day period, surpassing the performance of ARIMA and Support Vector Regression (SVR) (Wang et al., 2019). Furthermore, the integration of CNNs to enhance LSTM networks has led to major improvements in short-term prediction accuracy, showing a 25% increase on the CSI300 index (Qin et al., 2017). A more advanced hybrid model, combining CNN, BiLSTM, and Efficient Channel Attention (ECA), showed strengths in predicting long-term trends by leveraging spatial and temporal data processing (Zhang & Xu, 2020).
Alternatively, combining LSTM and Gated Recurrent Unit (GRU) networks has yielded superior predictions of the S&P500 adjusted closing price, outperforming models that rely solely on GRU, LSTM, or Multilayer Perceptron (MLP) architectures (Li et al., 2020). The success of these hybrid models underscores the importance of carefully engineered combinations, which can significantly enhance the precision and reliability of stock price forecasts (Pang et al., 2020). Ultimately, constructing an effective forecasting model goes beyond selecting the most advanced architectures; it also requires the integration of appropriate mathematical and physical principles to analyze complex, chaotic systems that exhibit unpredictable and non-repetitive patterns due to their sensitivity to initial market conditions (Mantegna & Stanley, 1999). As a result, the inclusion of the Attention Mechanism (AM) has revolutionized the time series field (Bahdanau et al., 2014). AM allows models to focus on the most relevant features within the data across multiple time intervals by selectively weighting the importance of different inputs. Hence, AM can improve the accuracy of predictions, especially in models like Transformers, where it serves as a core component (Vaswani et al., 2017). Therefore, attention-based models and their variants (Lim et al., 2021; Zhou et al., 2021) have advanced financial time series forecasting with their large multi-head attention mechanism.
Leveraging the potential of AM, recent studies highlight both significant and contentious advancements in time-series forecasting. Staffini (2022) introduced a Deep Generative Adversarial Network (DGAN) architecture, combining a CNN-BiLSTM generator and a CNN-based discriminator optimized via the WGAN-GP framework, for multi-step FTSE MIB stock price forecasting. DGAN improved Mean Absolute Percentage Error (MAPE) by 30% compared to ARIMAX-SVR, Random Forest, and LSTM models (Li et al., 2023). Staffini later developed MASTER (Market-Guided Stock Transformer), integrating market-guided gating, intra-stock and inter-stock aggregation, and AM to dynamically capture momentary and cross-time stock correlations, achieving a 13% improvement in ranking metrics and a 47% boost in portfolio-based metrics over state-of-the-art models on Chinese stock market datasets.
Furthermore, Ji et al. (2024) introduced Galformer, which features a generative decoding mechanism for efficient long-sequence predictions and a hybrid loss function. Galformer outperformed ARIMA, LSTM, and Transformer variants on the CSI 300, S&P 500, DJI, and IXIC stock indices. Despite these advancements, Transformers, while excelling in extracting semantic correlations in natural language processing, may struggle with the temporal relationships critical for time-series data due to their permutation-invariant self-attention mechanism. Across nine real-world datasets, Zeng et al. (2022) demonstrated that a set of simple, one-layer linear models significantly outperformed Transformer-based models in long-term time-series forecasting. Similarly, partial AM-based models combined with external engineering have become an emerging trend in recent studies (Ferdus et al., 2024; Guan et al., 2023; Wang et al., 2024; Yu, 2024).
While BiLSTM-integrated variants (Chen et al., 2021; Staffini, 2022; Zhang & Xu, 2020) have shown promising results, the Bidirectional LSTM architecture is genuinely designed to process information in both forward and backward directions. Nonetheless, in real-time financial time series analysis, models typically use past data to predict future outcomes, as future data is not available at the time of prediction (Cipra 2020).
Theoretical Background
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) were introduced as a type of feedforward neural network that excels in tasks such as image processing and natural language processing (NLP) (Shahriar, 2021). CNNs have also proven effective in time series prediction (Wibawa et al., 2022). The ability of CNNs to utilize local connectivity and weight sharing reduces the number of parameters, leading to more efficient learning models. A typical CNN architecture consists of three primary components: convolutional layers, pooling layers, and fully connected layers (Mann & Kalidindi, 2022). Each convolutional layer comprises multiple convolutional kernels, with the operation of these layers described by equation (1). The convolutional layers extract features from the input data, but this often results in high-dimensional feature maps. Therefore, to address this thus decreasing the computational cost, pooling layers are employed after the convolutional layers to reduce the dimensionality of the features (Zhao et al., 2024) (Figure 1)
CNN architecture (Shahriar, 2021).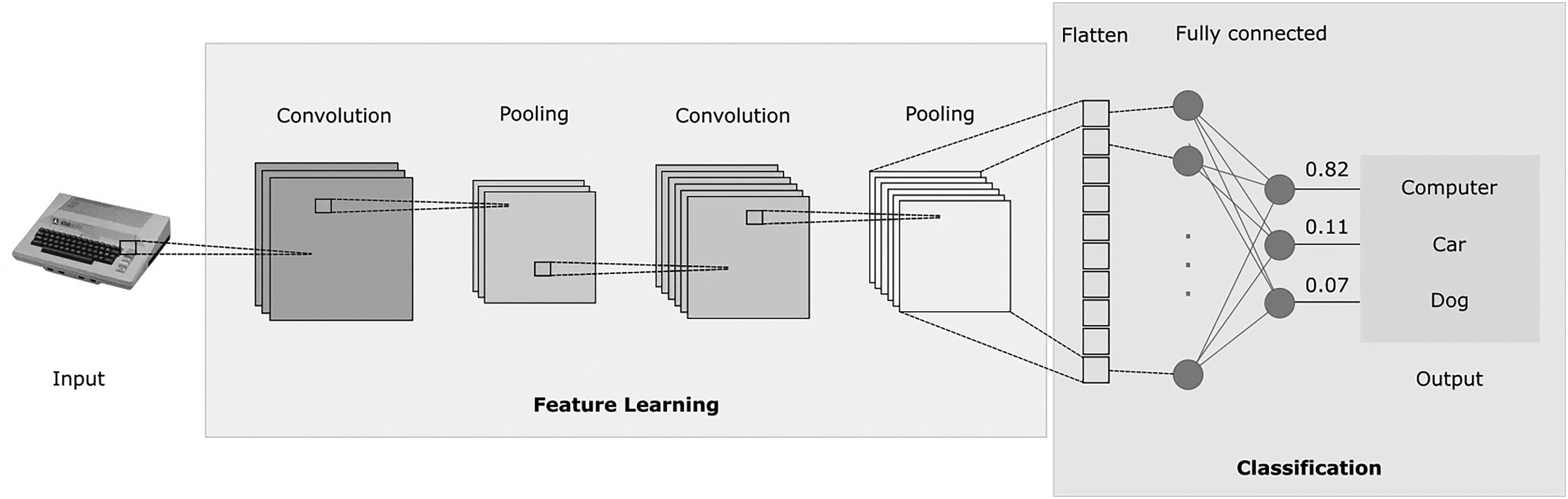
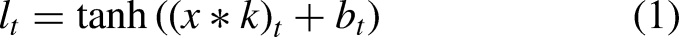
In this equation,
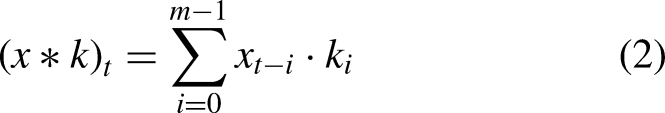
Long Short-Term Memory
Long Short-Term Memory (LSTM), introduced by Hochreiter and Schmidhuber (1997), was designed to address the challenges of gradient explosion and vanishing gradients in Recurrent Neural Networks (RNNs) (Zucchet & Orvieto, 2024). Unlike the standard RNN, which consists of a single repeating tanh module, LSTM includes four interactive components, making it more effective in capturing long-term dependencies (Hochreiter & Schmidhuber, 1997). Accordingly, the core of LSTM is its memory cell, which is regulated by three gates: the forget gate, the input gate, and the output gate. These gates control the flow of information and update the cell state, which are outlined as follows (Figure 2):
The forget gate determines what portion of the previous cell state The input gate updates the cell state with new information, determined by: The cell state The output gate decides the next hidden state Finally, the output of the LSTM is computed as:
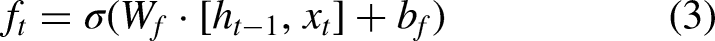
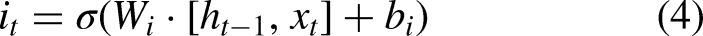
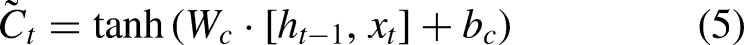
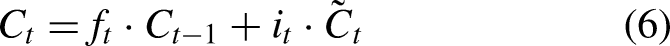
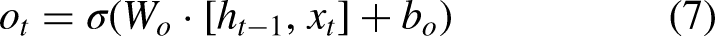

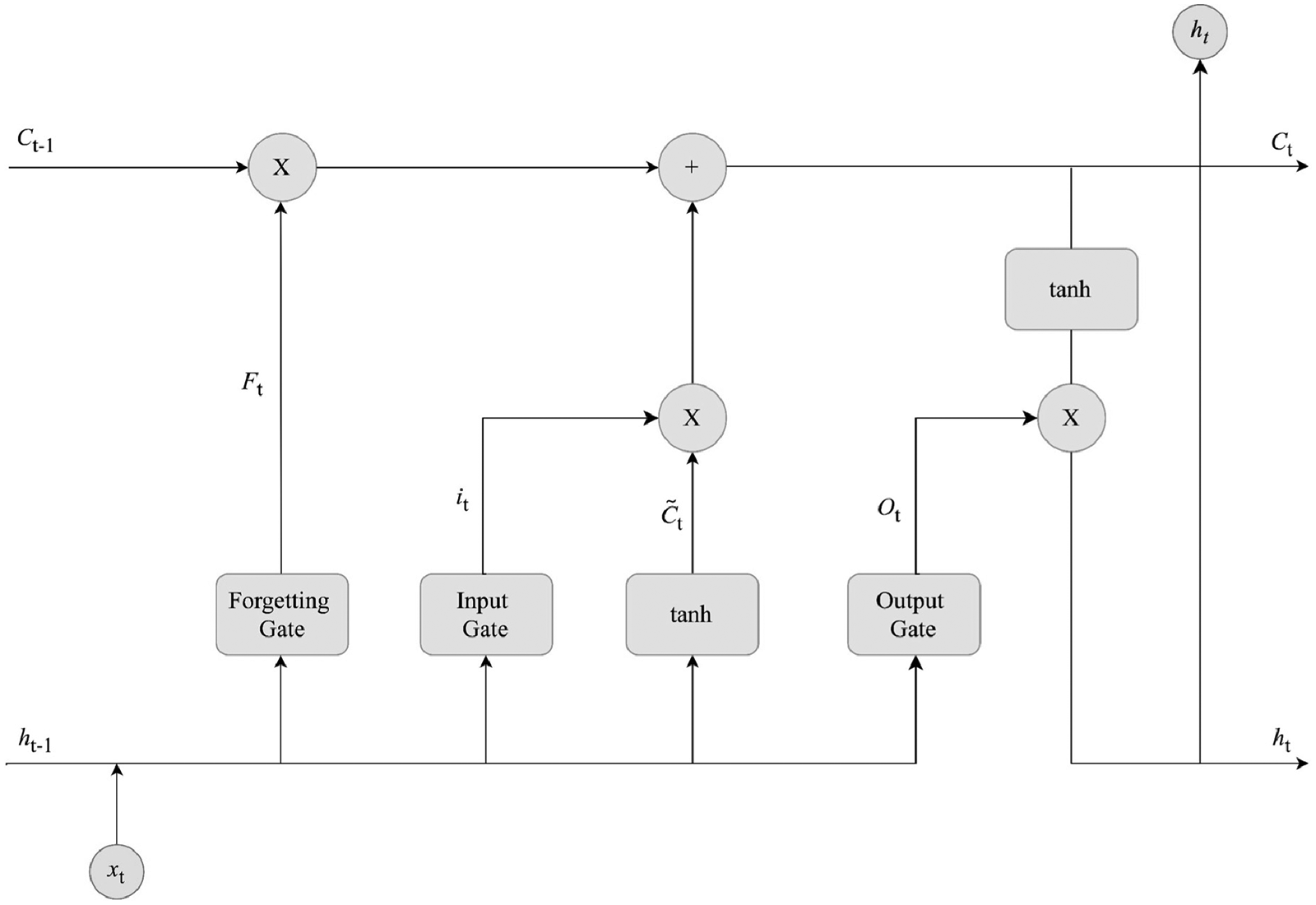
LSTM architecture.
Attention Mechanism
The Attention Mechanism (AM), introduced by Treisman and Gelade (1980), optimizes models by focusing on the most relevant information within large datasets. By calculating the probability distribution of attention, AM highlights key inputs, effectively enhancing traditional models based on human visual attention principles. This mechanism prioritizes important information while disregarding less relevant details, thus efficiently allocating attention. The AM calculation process, as illustrated in Figure 3, can be divided into three main stages:
The similarity between the Query (output feature) and Key (input feature) is calculated using: The similarity score The final attention value is calculated through a weighted summation over all the input vectors (or Values):
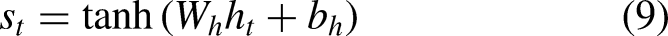
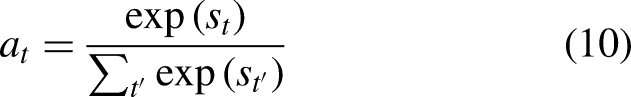

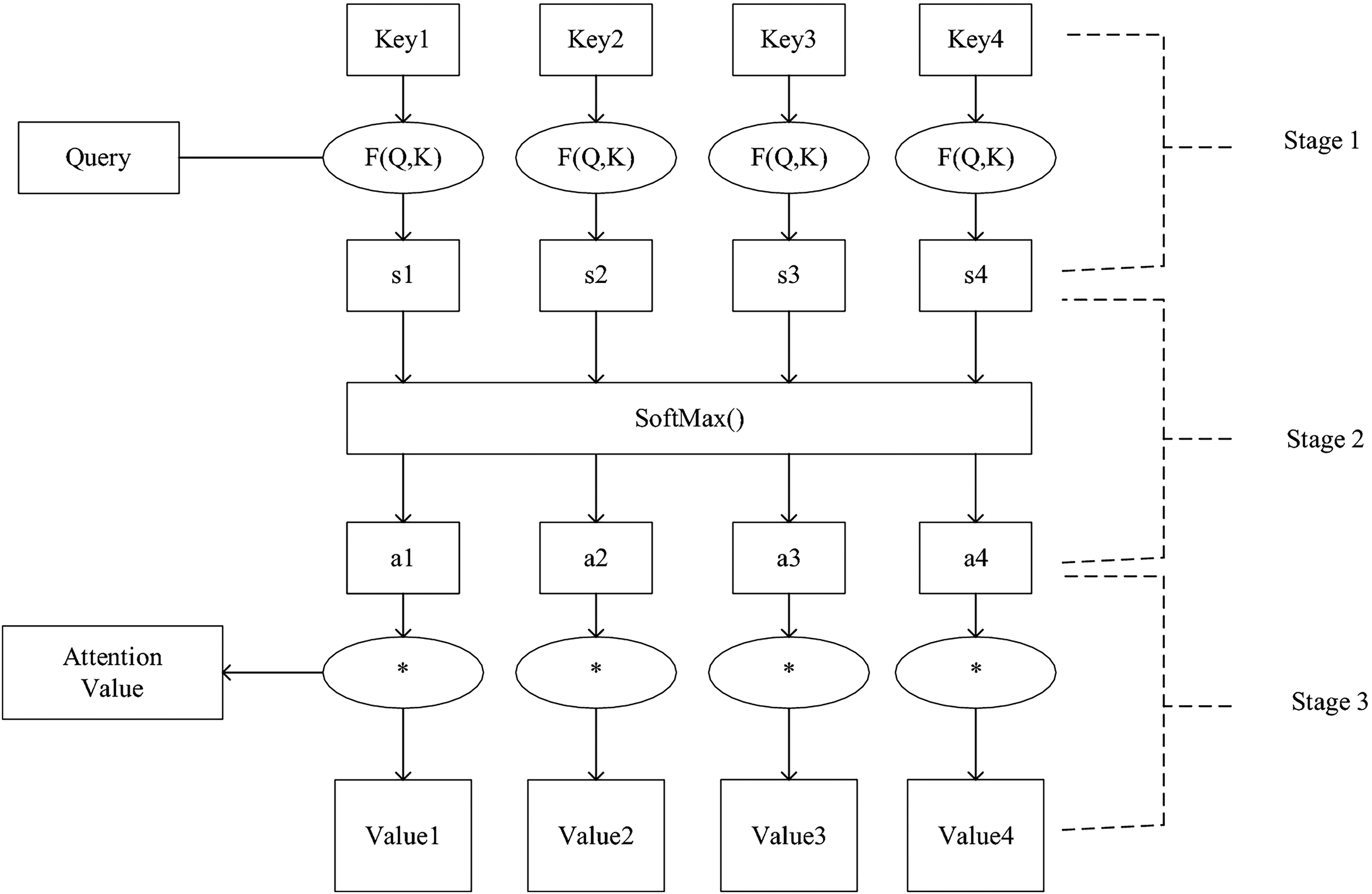
AM architecture (Lu et al., 2020).
Methodology
Data Collection and Evaluation Metrics
The OHLCV stock data, sourced from Yahoo Finance’s S&P 500 Index, are categorized into two groups: Pharmaceuticals (AbbVie Inc., ABBV; Johnson & Johnson, JNJ) and Financials (Goldman Sachs Group Inc., GS; Citigroup Inc., C). This categorization is based on the fundamental differences between pharmaceutical companies and financial institutions, presenting a unique challenge for forecasting models. Pharmaceutical stocks are sensitive to abnormal events (e.g., lab innovations, private research, cure development), whereas financial stocks are more influenced by periodic events (e.g., political debates, fiscal policies, human psychology). Additionally, CLAM employs a standard train-validate-test split ratio of 80:10:10. This means 80% of the data is used for initial training, 10% for validation and fine-tuning, and the remaining 10% for testing. The dataset’s timeline is structured with a train/val/test period from July 19, 2004, to July 12, 2024 (20 years - 5,031 observations). We then provide an out-of-sample forecast starting on July 13, 2024, predicting the next financial week, to justify CLAM’s prowess. Consequently, the out-of-sample (OOS) period spans July 15, 2024, to July 19, 2024 (5 observations). The OSS dataset was gathered separately from others.
The experiment concludes on July 20, 2024, ensuring that the data remains unseen during training to fully avoid the possibility of data leakage. The Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are selected as evaluation metrics due to their effectiveness in identifying predictive errors in univariate analysis. MAE (12) provides the average magnitude of forecasting errors, serving as a straightforward measure of overall prediction accuracy, which is particularly crucial in the volatile stock market. RMSE (13), on the other hand, emphasizes larger errors, highlighting discrepancies that could have significant financial consequences. Mean Squared Error (MSE) is used as the loss function to measure the average squared difference between the predicted values and the actual target values, quantifying the model’s prediction accuracy. Thus, greater errors indicate a larger deviation in price predictions.
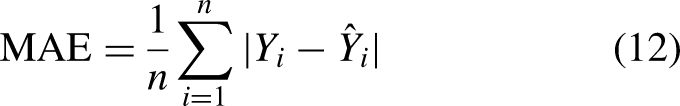
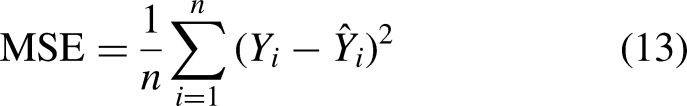
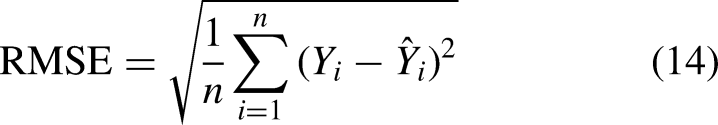
CLAM: CNN-LSTM-AM
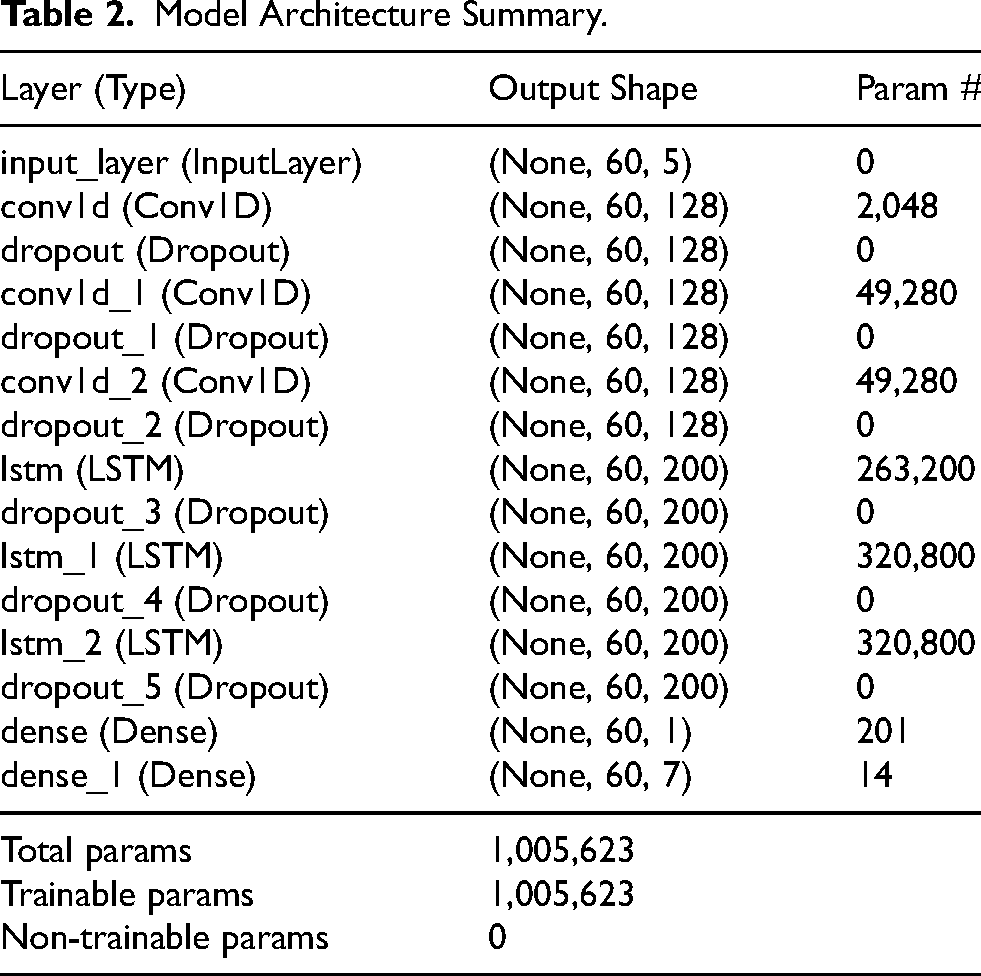
Overall, the synergistic design of CLAM, accumulating triple-stacked layers of CNN, LSTM, and a customized AM layer, enables the model to systematically extract local patterns, learn temporal dependencies, and focus on the most critical information in the sequence. Each component is carefully configured to address the unique challenges posed by financial time-series data, such as non-linearity, volatility, and nonstationarity across various data nature (Figure 4).
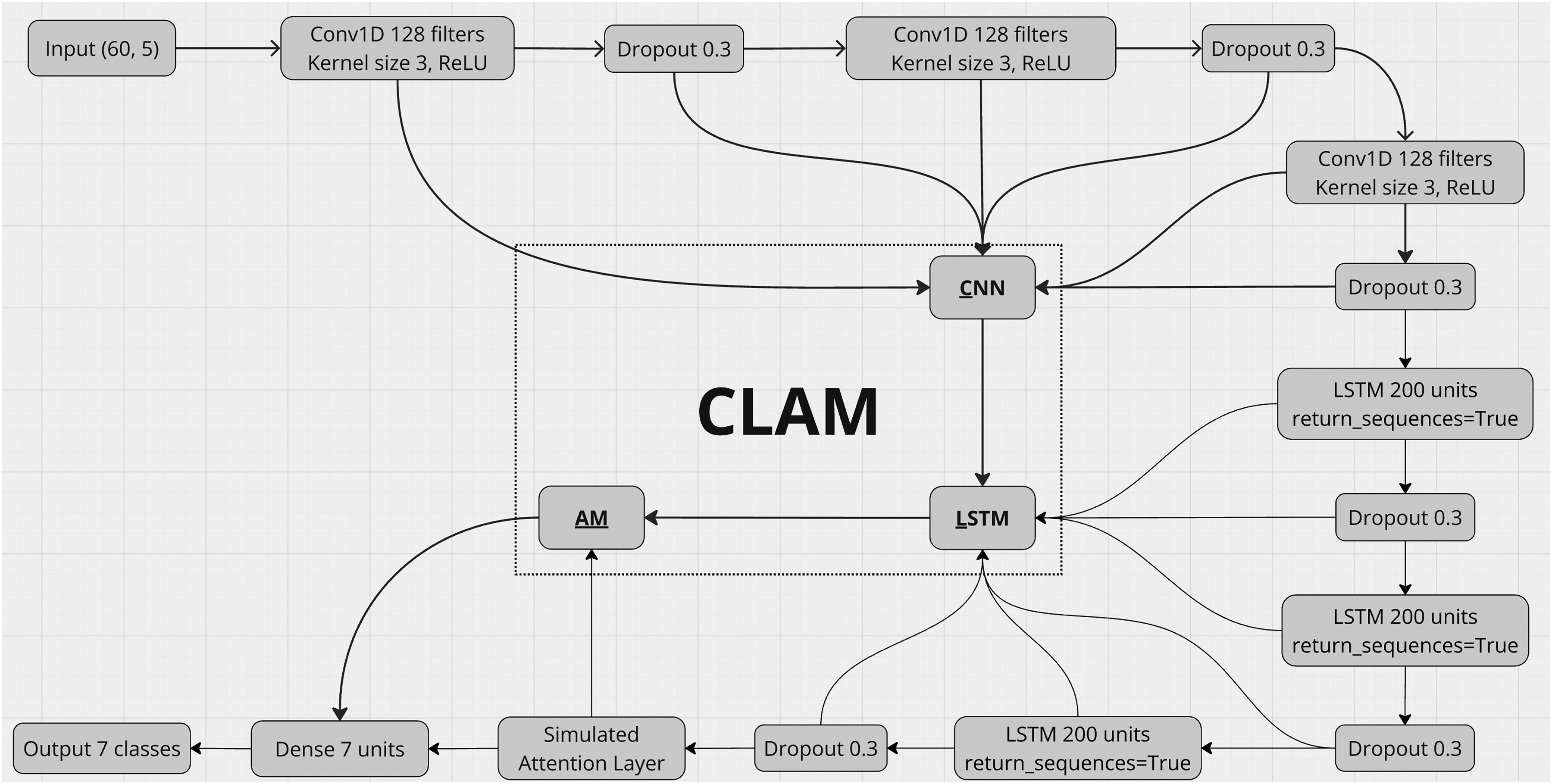
The proposed CLAM hybrid architecture.
Firstly, the input data, which includes normalized features including
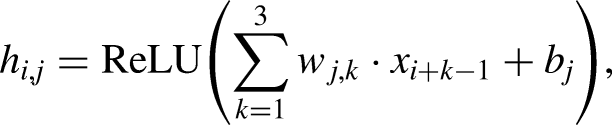
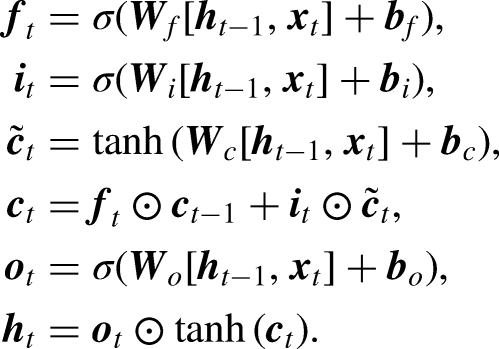
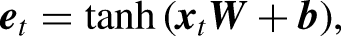
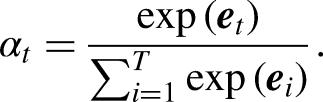
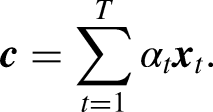
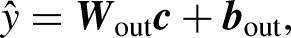
Hyperparameter Tuning Summary.
Model Architecture Summary.
Experiments and Results
Experimental Process
Our experimental procedure (Figure 5) began with the initialization of random number generators in both NumPy and TensorFlow libraries, ensuring consistency and reproducibility by setting a seed value of 42. The stock datasets, loaded from 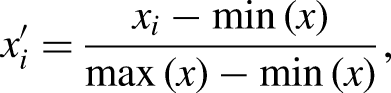
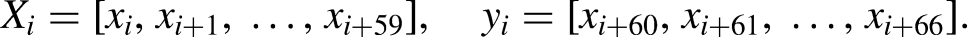

Full experimental process.
In addition,
Hyperparameter Tuning
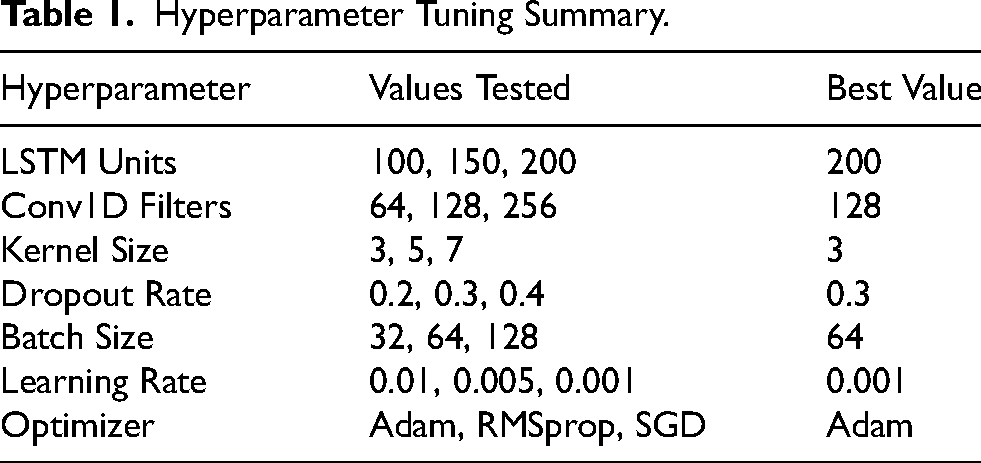
As illustrated in Table 1, a wide spectrum of values was tested across essential hyperparameters, including LSTM units, Conv1D filters, kernel size, dropout rate, batch size, learning rate, and optimizer selection. This exhaustive tuning process was essential to strike the delicate balance between model complexity and generalization, with a specific focus on avoiding overfitting, a common pitfall in deep learning models. The selection of 200 LSTM units, for instance, was the result of a careful trade-off. While a smaller number of units (such as 100 or 150) led to faster convergence, these configurations consistently underperformed in capturing the complexity of the sequential data, as evidenced by higher validation errors. Conversely, larger configurations, such as 256 Conv1D filters, introduced unnecessary computational overhead without a commensurate improvement in performance, highlighting the diminishing returns of increasing model depth and width. In addition, the kernel size of 3 was particularly effective in capturing localized temporal patterns, contrasting with larger kernels that diluted the model’s ability to focus on fine-grained features.
Moreover, the dropout rate of 0.3 was determined to be optimal after observing that lower rates led to overfitting, while higher rates hindered learning, reducing the model’s capacity to generalize. The choice of a batch size of 64 was similarly contrasted against smaller and larger batch sizes, where smaller batches resulted in noisier gradient estimates and larger batches slowed down the training without significant gains in accuracy. The learning rate of 0.001, coupled with the Adam optimizer, offered the best balance between learning speed and stability, particularly when compared to other optimizers like RMSprop and SGD, which either converged slower or required more tuning.
Performance Comparison
The results in Table 3 confirm CLAM as the top-performing model across all datasets and metrics. For ABBV, the MAE of 0.008 represents a 90.9% reduction compared to LSTM-AM’s 0.088 and an impressive 93.2% over CNN’s 0.117. While LSTM-AM improves upon CNN-LSTM by 16.2% and CNN by 24.8%, its gains are modest compared to CLAM. On the C dataset, the MAE of 0.012 surpasses LSTM-AM’s 0.097 by 87.6% and CNN-LSTM’s 0.115 by 89.6%. Even with attention mechanisms, LSTM-AM reduces CNN’s error by only 28.1% (0.135 to 0.097), falling short of the reductions achieved by CLAM. For GS, CLAM achieves a MAE of 0.017, 81.3% lower than LSTM-AM’s 0.091 and 86.9% better than CNN’s 0.130. The JNJ dataset, characterized by lower overall errors, still highlights CLAM’s effectiveness. Its MAE of 0.019 reduces errors by 78.9% relative to LSTM-AM and 83.5% compared to CNN. These patterns demonstrate CLAM’s ability to capture temporal dependencies and adapt across datasets.
Model Performance on Train and Test Sets.
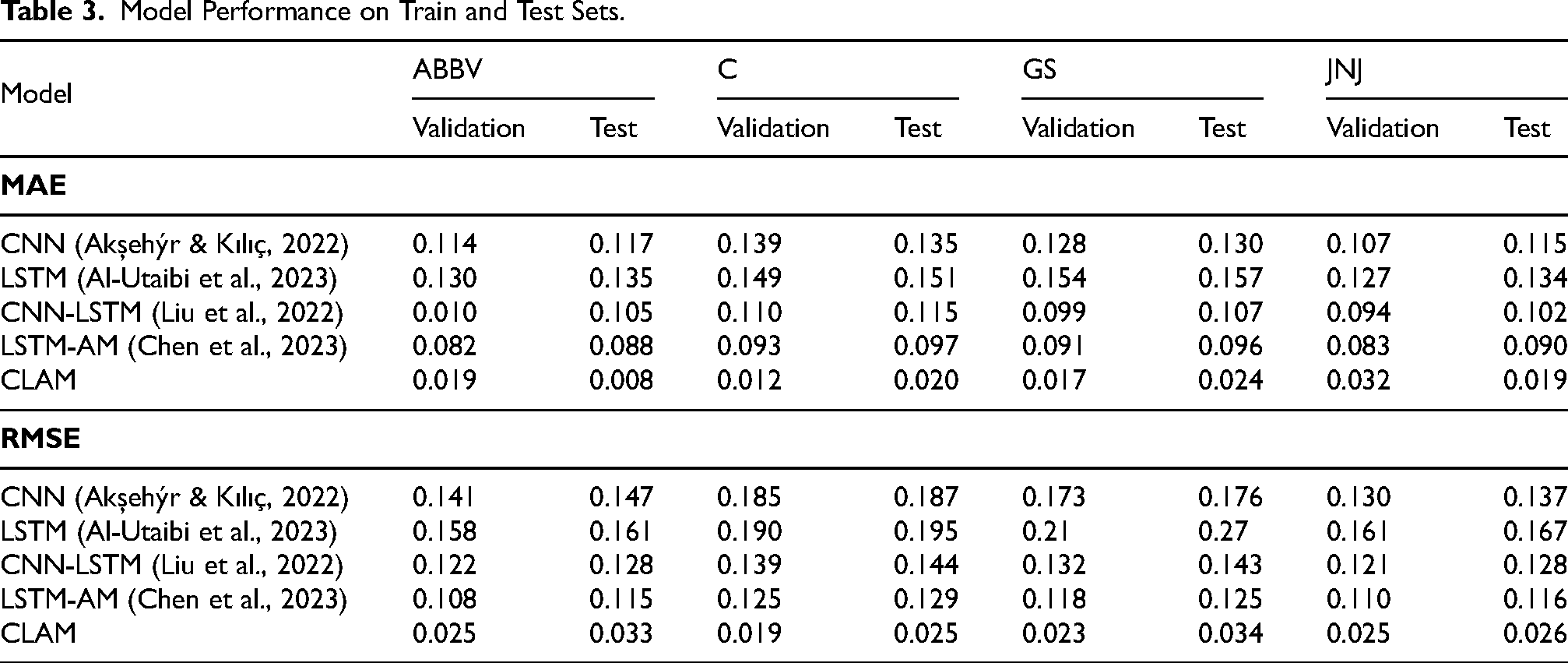
RMSE metrics reinforce these trends. For ABBV, the RMSE of 0.025 is 77.5% lower than LSTM-AM and 83.0% below CNN. On C, it outperforms LSTM-AM by 79.4% and CNN by 86.5%. GS and JNJ datasets show similar advantages, with reductions exceeding 80% over LSTM-AM and CNN. Although LSTM-AM offers significant improvements over simpler models, it consistently lags behind CLAM, which delivers unmatched accuracy and robustness. CLAM remains unmatched in precision and consistency among others. Results show diverse gaps between validation and test results. An inspection of the error metrics was conducted to justify CLAM efficient training.
CLAM Inspection
Training and Validation
The training process (Figure 6) for ABBV shows effective learning, with MAE dropping from 0.10 to 0.025 by epoch 20, and validation MAE stabilizing around 0.025 by epoch 65. RMSE decreases from 0.16 to below 0.04, indicating strong generalization. For stock C, the training MAE quickly declines from 0.045 to 0.020 by epoch 10, while validation MAE stabilizes around 0.015 by epoch 30. Both MAE and RMSE converge near 0.010 and 0.02, respectively, by epoch 60, reflecting robust learning. In GS, training MAE drops to 0.03 by epoch 10, with validation MAE stabilizing at 0.02 by epoch 30. RMSE similarly decreases below 0.03, confirming effective model performance. For JNJ, the training MAE drops to 0.03 by epoch 5, with validation MAE stabilizing around 0.03 by epoch 10. RMSE decreases to 0.04 from epoch 10 onward, showing effective learning dynamics.
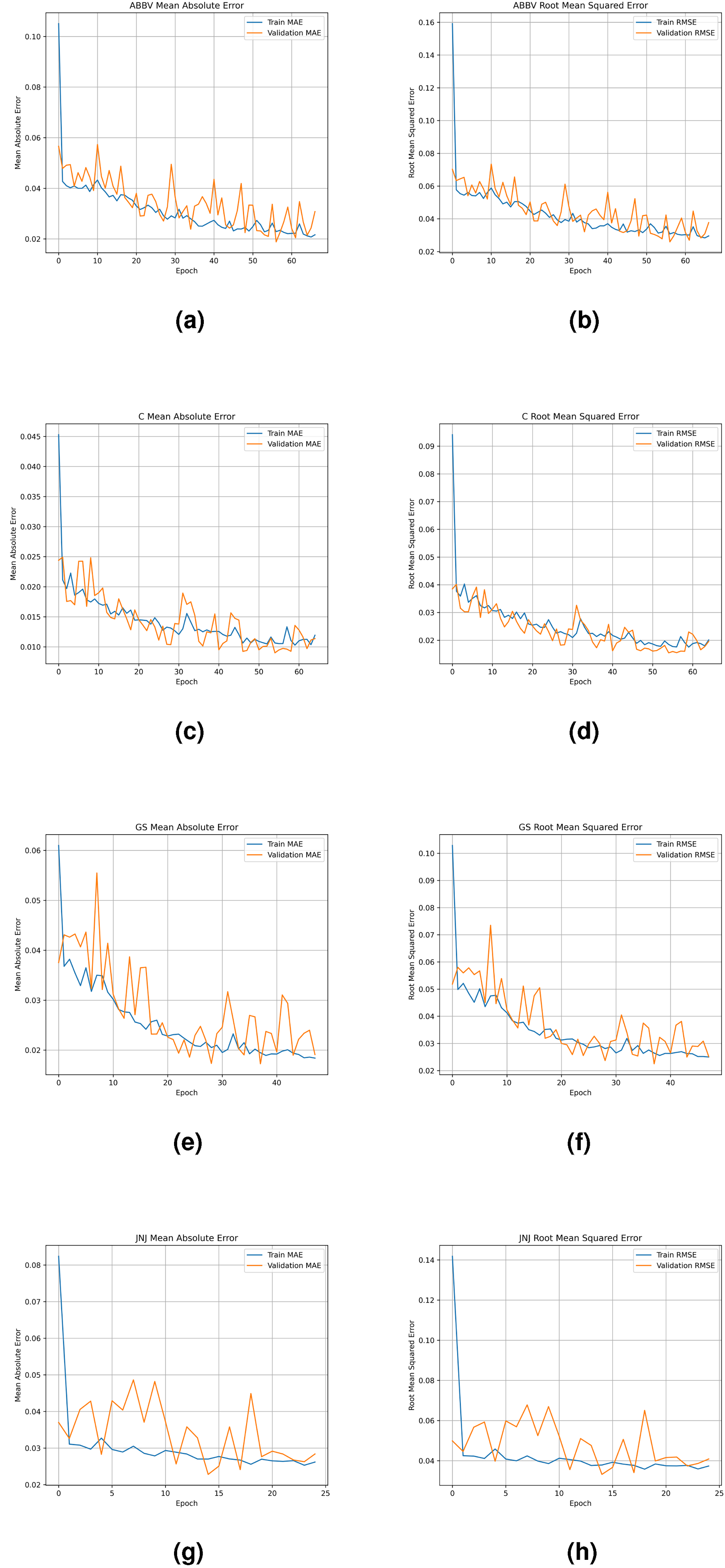
Summary of MAE and RMSE for different datasets. (a) MAE of ABBV; (b) RMSE of ABBV; (c) MAE of C; (d) RMSE of C; (e) MAE of GS; (f) RMSE of GS; (g) MAE of JNJ and (h) RMSE of JNJ.
Table 4 evaluates the CLAM’s performance by analyzing Standard Deviation (SD) (Rowberry, 2021), T-Test (Emerson, 2023), and P-Value (Kwak, 2023) between the test sets and the actual sets of stocks. For ABBV, CLAM achieves a Test SD of 0.010, a strongly negative T-Test value of
Significance Analysis for CLAM.

Trend Forecasting
Finally, CLAM is deployed into real-world scenarios for outsample forecasting generation (Figure 7), then contrasted with the end-period value in the OOS dataset. By leveraging historical price patterns, CLAM aims to capture shifts in market momentum, labelling trends as “UP” if the next day’s price is expected to rise and “DOWN” if it is expected to fall. This approach reduces the influence of short-term noise.
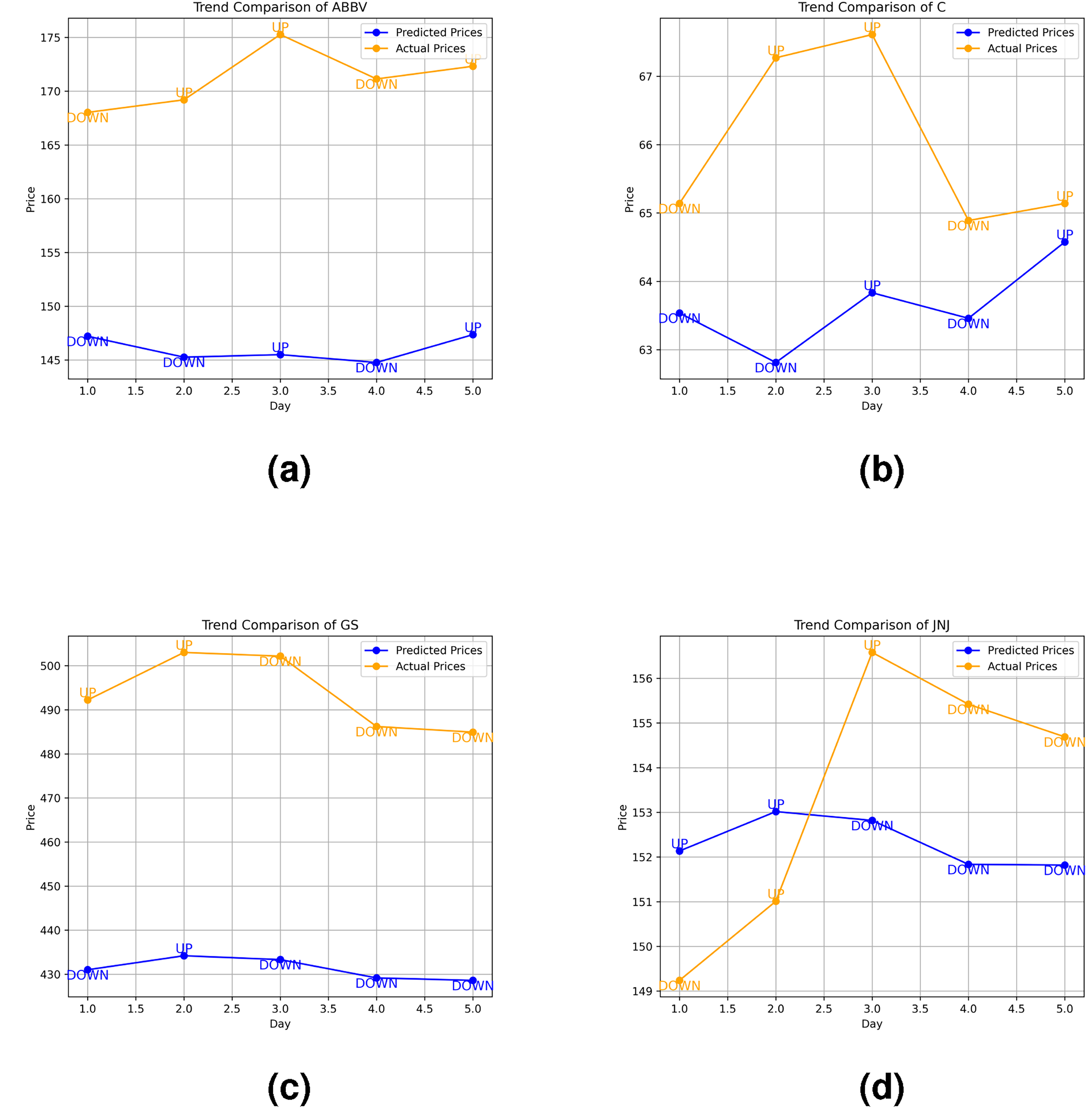
Forecasting results for stocks. (a) ABBV forecasting results; (b) C forecasting results; (c) GS forecasting results and (d) JNJ forecasting results.
For ABBV, CLAM successfully identified the immediate downtrend on Day 1 (Monday), a day typically marked by high volatility and investor reactions post-weekend. Although it initially missed the recovery on Day 2, it adjusted and accurately predicted the upward trend on Day 3. CLAM then continued to forecast the correct trend for the final two days, resulting in three consecutive accurate predictions and capturing the overall uptrend of ABBV, achieving an accuracy of 80%. In the case of C, CLAM once again identified the initial downtrend on Monday but failed to predict the following day’s trend. However, it redeemed by precisely forecasting the trend for the last three days consecutively, with minimal price deviation, leading to an overall accuracy of 80%. Concerning GS’s case, despite missing the initial rise on Day 1 (after the weekend), CLAM consistently predicted the correct trend for the remaining four consecutive days, successfully capturing the overall downtrend for the week and once again achieving 80% accuracy. Finally, for JNJ, while CLAM effectively captured the overall downward trend, it struggled with consistency, failing to predict the trends on Days 1 and 3. Nevertheless, it accurately captures the sharp decline in the final two days, resulting in a 60% accuracy for JNJ.
Overall, CLAM achieved an average trend forecasting accuracy of 75% across pharmaceutical and finance stocks. The model demonstrated strong performance in most cases, particularly in forecasting consecutive trends, and identifying immediate downtrends. The test was conducted as proof of CLAM’s promising applicability in real-time intraday trading systems. As outsample data did not exist during the training and forecasting processes, the remarkable output could have optimized investors’ trading portfolios by alerting a hold, buy, or sell position (Dichtl, 2018) one week ahead of the S&P 500 market, reducing investment risks.
Discussion
Summary of Findings and Contributions
Our research demonstrates that the integration of stacked deep learning layers in the CLAM model, comprising Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), and Attention Mechanisms (AM), significantly outperforms traditional standalone models. This superiority is attributed to CLAM’s advanced feature extraction and attention mechanisms, which enhance the LSTM architecture’s inherent ability to capture long-term dependencies in time series forecasting. As a result, CLAM achieves an average reduction of over 80% in MAE and RMSE compared to conventional models such as CNN, LSTM, CNN-LSTM, and LSTM-AM. Additionally, our experiments indicate that in 3 out of 4 cases, CLAM successfully forecasts the correct trends for 3-4 consecutive days, capturing market downturns on the opening day, which tends to be unpredictable due to abnormal traders’ behaviour.
Finally, CLAM achieves a 75% accuracy rate in stock trend forecasting. This highlights the potential of hybrid models in time series forecasting, demonstrating that attention-based deep learning hybrids like CLAM are particularly well-suited as live-trading indicators for investors focused on weekly trends. Hence, CLAM enhances decision-making processes in financial trading, providing a robust and lightweight tool to forecast short-term movements in the global equity market.
Limitations and Recommendations
Our study is grounded in raw OHLCV data of stock prices, which offers ease of access but also introduces potential market biases. This limitation arises from the model’s inability to account for external economic or financial factors, such as extreme events, technical indicators, or government policies, all of which are crucial drivers of stock prices. Additionally, since our research primarily focuses on trend detection, the CLAM architecture is not fully optimized for value trading, where precise price gaps are critical. As a result, CLAM’s potential may extend further and be more robust than demonstrated in its current form. We encourage researchers to expand upon our work by developing deeper hybrid models or employing explainable models to study stock trends effectively. In addition, practitioners are advised to enhance data collection processes by incorporating data from stock indexes and integrating relevant technical trading indicators, thereby uncovering more intricate stock patterns within the raw target features.
Conclusion
This study introduced the CLAM model, a hybrid combination of Convolutional Neural Networks, Long Short-Term Memory networks, and Attention Mechanisms designed for multi-step stock price trend forecasting. The model demonstrated significant improvements in predictive accuracy, with an average reduction of over 80% in MAE and RMSE compared to traditional models. CLAM’s ability to effectively capture complex temporal dependencies and its robust performance across various stock datasets highlight its potential as a valuable tool in financial forecasting. The findings of this research suggest that CLAM is particularly well-suited for short-term trend forecasting, providing accurate and timely predictions that can assist investors and traders in making informed decisions.
The model’s design, which integrates feature extraction and attention mechanisms, offers a significant advancement over existing approaches. Moreover, there are several promising directions for further research. Future studies could explore enhancing CLAM’s adaptability to different market conditions, such as varying levels of market volatility or the impact of external economic factors. Integrating CLAM with other financial analysis techniques, such as sentiment analysis or candlestick pattern recognition, could also improve its predictive capabilities. Real-time deployment of CLAM in live trading environments of daily stocks or hourly cryptocurrency prices is another area that warrants investigation for real-time performance assessment.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.