
Abstract
Fault diagnosis is of great significance to improve the production efficiency and accuracy of industrial robots. Compared with the traditional gradient descent algorithm, the extreme learning machine (ELM) has the advantage of fast computing speed, but the input weights and the hidden node biases that are obtained at random affects the accuracy and generalization performance of ELM. However, the level-based learning swarm optimizer algorithm (LLSO) can quickly and effectively find the global optimal solution of large-scale problems, and can be used to solve the optimal combination of large-scale input weights and hidden biases in ELM. This paper proposes an extreme learning machine with a level-based learning swarm optimizer (LLSO-ELM) for fault diagnosis of industrial robot RV reducer. The model is tested by combining the attitude data of reducer gear under different fault modes. Compared with ELM, the experimental results show that this method has good stability and generalization performance.
Keywords
Introduction
In recent years, the number and use time of industrial robots have continuously increased, leading to an increase in fault frequency. For continuous production systems, it is of great significance to carry out the fault diagnosis of industrial robots to improve their reliability. 1 The rapid identification of fault types is beneficial to the improvement of production efficiency of industrial robots in the field of application, loading and unloading.
Many researchers have focused on the application of machine learning methods such as support vector machines, 2 convolutional neural networks, 3 deep belief networks, 4 and sparse autoencoders 5 in the field of fault diagnosis. Wu et al. 6 proposed a convolutional neural network algorithm for end-to-end fault diagnosis. Zhang et al. 7 proposed deep fuzzy echo state networks and a deep hybrid state network for machinery fault diagnosis. Isham et al. 8 put forward a parameter optimization method for variational mode decomposition using a differential evolution algorithm for multi-fault identification. Wang et al. 9 combined transient modelling and parameter identification to detect the fault characteristics of rotating machines. Luo et al. 10 presented a hybrid system for the fault diagnosis of rolling element bearings. Zhang et al. 11 proposed a residual learning algorithm to improve the network training for the fault diagnosis of rotating machinery. Li et al. 12 combined variational mode decomposition and a deep neural network for the fault diagnosis of planetary gears. Zheng et al. 13 established a variable prediction model for rolling bearing fault feature classification.
In terms of the fault diagnosis of industrial robots, Jaber et al. 14 used a time-frequency signal analysis method based on the discrete wavelet transform to extract the most significant features related to faults and used an artificial neural network to perform fault classification. Freyermuth 15 proposed a method for the early diagnosis of mechanical faults in industrial robots in the form of nonlinear differential equations. Anand et al. 16 proposed a method for the fault detection and isolation of industrial robots based on hybrid intelligence.
Because gradient learning algorithms with a complex iterative process are used to train neural networks, the training speed of deep neural networks is generally low. To address this problem, Huang et al. 17 proposed the extreme learning machine (ELM), which uses the Moore-Penrose generalized inverse to calculate the output weights after random selection of the input weights and hidden biases. It has a good learning speed performance 18 and can overcome disadvantages such as local minimization, an inappropriate learning rate, and the overfitting of traditional feedforward neural networks. However, compared with the traditional gradient descent algorithm, the ELM uses many hidden nodes. 19
The use of an ELM for fault diagnosis faces two major challenges: (1) random network parameters lead to poor generalization performance, (2) the model falls into overfitting due to the existence of redundant hidden nodes. 20 Evolutionary algorithms have been used in many studies to improve the conditions of ELM parameters. Gao et al. 21 proposed a method for the mechanical fault diagnosis of high-voltage circuit breakers based on hybrid feature extraction and integrated ELM (IELM). Chen et al. 22 used a summation wavelet ELM (SW-ELM) for fault classification and location estimation. Rodriguez et al. 23 combined an ELM and stationary wavelet transform to perform rolling bearing fault diagnosis. Chen et al. 24 used complementary ensemble empirical mode decomposition and an ELM to propose a fault diagnosis method suitable for engineering applications.
ELMs have been optimized with algorithms including particle swarm optimization (PSO), 25 competitive swarm optimization (CSO), 26 and differential evolution (DE). 27 Xu and Shu 28 proposed an ELM model based on PSO evolution. Eshtay et al. 29 presented a CSO-ELM, which uses CSO to optimize the parameters of the classical ELM and a regularized ELM for medical classification problems. Zhu et al. 30 put forward a new ELM that uses DE to select input weights and shows a good generalization performance. Cao et al. 31 proposed an improved crow search algorithm to optimize the extreme learning machine. Wen 32 put forward ant colony optimization algorithm and extreme learning machine network for wind turbine.
The fault diagnosis of industrial robot RV reducer is a complex problem, and ELMs require a large number of parameters to solve problems. However, for ELMs with a complex network structure, there are still problems such as slow learning speeds and poor stability. In this paper, the main contributions of this work include: (1) this work adopts low-cost attitude sensor for data acquisition; (2) a new method of level-based learning swarm optimizer with extreme learning machine (LLSO-ELM), which uses LLSO to quickly obtain the optimal input weights and hidden biases of ELM; (3) compared with ELM algorithm, this method has high prediction accuracy and generalization performance for attitude data of industrial robots under different fault modes.
The remainder of the paper is organized as follows. Section 2 introduces the proposed LLSO-ELM algorithm, Section 3 describes the experimental setup and data processing, Section 4 discusses the experimental results, and Section 5 summarizes the findings.
Methods
Extreme learning machine
ELMs are fast learning algorithms for single hidden layer feedforward neural networks. 33 Different from the back propagation algorithm based on neural networks, ELMs randomly select the input weights and hidden biases and then calculate the output weights using the Moore-Penrose generalized inverse; hence ELMs have a faster training speed. Their architecture is shown in Figure. 1.

The ELM framework.
For a classification problem, it is assumed that an n-dimensional dataset has N samples, which can be divided into m categories. The training sample is set to
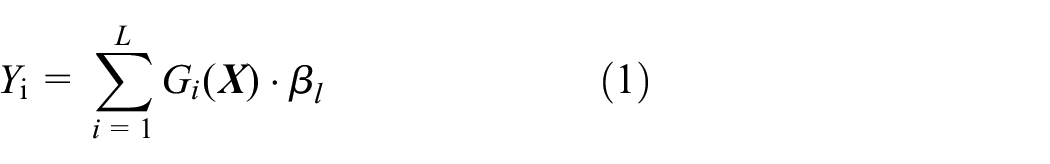
where L is the number of hidden neurons, and

where g is an activation function, wl (




The loss function can be described as below:

Because the input weight α and the hidden layer node bias b have been randomly determined, the output weight matrix

where
Level-based learning swarm optimizer algorithm
When solving large-scale optimization problems, optimization algorithms are prone to fall into local optimality and premature convergence. The LLSO proposed in 2017 can effectively search for the global optimal solution for large-scale problems.
34
The LLSO has two main ideas, namely, a level-based learning (LL) strategy and paradigm selection. The particles in the social learning particle swarm optimization (SL-PSO) algorithm
35
are sorted according to their fitness values and then divided into NL levels using the LL strategy. The better particles have higher levels, and their corresponding levels have smaller subscripts. If L
i
represents the ith layer, L
1
is the highest layer containing the best particles. Higher-level particles may contain more useful information, which can be used to guide the lower-level particles to search for the global optimal region. Assuming that the size of the particle swarm is NP, the number of particles per layer is LS, then the total number of layers is NL = NP/LS, and the dimension is D. The architecture for the LL strategy is shown in Figure 2. First the particle swarm is sorted in ascending order of fitness, then the particle swarm is divided into NL levels, and finally particles of level Li (

Schematic architecture of the LL strategy.
Low-level particles need to learn from high-level particles. A key problem is how to select two paradigms at higher levels. The paradigm selection strategy provides a method for selecting paradigms and considers the exploration and exploitation of particles, which are two key evaluation indicators of large-scale optimization.
36
The process of paradigm selection for particles of level Li is summarized as follows: (1) randomly select rl1 and rl2, where


where Xi, j is the jth particle in Li, and vi, j is its velocity.
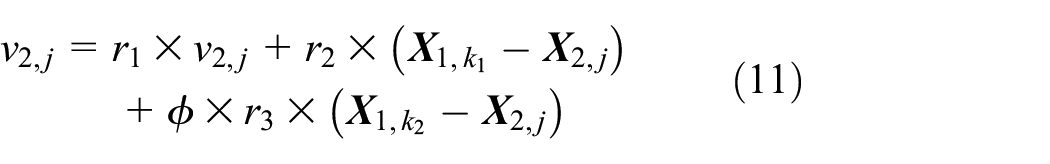

The particles in L1 contains the best solutions in the swarm, so they directly enter the next generation swarm. In the LLSO algorithm, good particles are retained to be learned, and bad particles are allowed to explore, which not only maintains the diversity but also accelerates the convergence of the particles and achieves large-scale optimization.
As the simplicity of particle swarm optimization algorithm is maintained in LLSO, the time complexity of LLSO calculation is very simple. First it takes O (NPlog(NP)+NP) to sort the swarm and divide the swarm into NL levels for each generation. It takes O (NP×D) to update particles in all levels except those in the first level that go directly to the next generation. In terms of space complexity, LLSO requires much less space than PSO because it does not store a personal optimal position for each particle, which takes O (NP×D) space. In conclusion, compared with the classical particle swarm optimization algorithm, LLSO maintains a higher computational efficiency in both time and space.
LLSO-ELM algorithm
In ELMs, the input weights and hidden biases are randomly selected. Random parameters can lead to more hidden neurons and poorer generalization performance. Therefore, we propose a hybrid LLSO-ELM method, which is achieved by using the LLSO to search for the optimal parameters of the ELM. Because of the full connection mode between the input layer and the hidden layer in the ELM, weight and bias optimization are a large-scale optimization problem. The LLSO has been convincingly verified in solving large-scale optimization problems.
Particle encoding and fitness are two key issues in the optimization of the ELM parameters by the LLSO. In the LLSO-ELM, particles are composed of the weight vector of the input layer and the bias vector of the hidden neurons. A particle
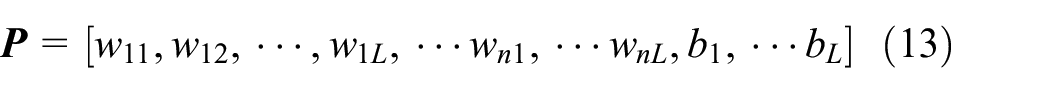
where L is the number of hidden neurons, and n is the dimension of the input dataset. The length of the particle, LenOfParticle, can be expressed as
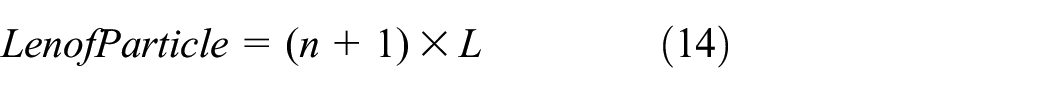
Fitness is used to evaluate the quality of particles. The smaller the value, the better the classification effect. For classification problems, the fitness value can be calculated by the following formula:

where Acc refers to the ratio between the number of correctly classified samples and the total number of samples obtained by using ELM algorithm classification after the LLSO algorithm seeks for the optimal parameters.
Basic flowchart of the LLSO-ELM algorithm
The specific flowchart of the LLSO-ELM algorithm is shown in Figure 3. The overall steps are as follows:

Flowchart of the LLSO–ELM algorithm.
Experiment and data processing
To verify the effectiveness of the proposed LLSO-ELM algorithm, the RV reducer gear of the industrial robot is selected to work under different fault conditions, and attitude sensors are used to collect data from the industrial robot. The experimental setup is shown in Figure 4. An industrial robot (BRTIRUS1510A) with an RV reducer gear (Qinchuan) was used in the experiment.

Experimental setup.
The industrial robot is mainly used in the industrial fields of loading and unloading and injection moulding, which has a maximum load capacity of 10 kg and a maximum arm length of 1500 mm. The robot has six degrees of freedom and is composed of a pedestal, upper arms, elbows, and forearms. An RV reducer gear is installed at each joint for drive. On axis J2, the RV reducer gear is connected to the pedestal and upper arm of the robot, respectively. The sun gear is connected to the motor on one end and meshed with the planetary gear on the other end, so that the motor drives the rotation of the forearm. Similarly, the reduction gear on axis J3 is installed in the same way as that on axis J2.
The attitude data of the six-axis industrial robot is collected through attitude sensors, which can measure three-axis acceleration, three-axis angular velocity, three-axis magnetic field, and three-axis angle signals and can operate at 40–80°C. The attitude sensors have an acceleration resolution of 0.01 g, an angular velocity stability of 0.05°/s, and a sampling frequency of 100 Hz. The attitude sensors are installed on axes J1 and J6 of the robot, respectively.
The fault components of the industrial robot are the gears of the J2 and J3 axis reduction gears. The most common faults during the gear drive process are pitting faults, broken tooth faults, and crack faults. In our scheme, to simulate different fault modes, the sun gear and planetary gear on axes J2 and J3 of the industrial robot were preset with different faults, which were used as failure modes, as shown in Figure 5. Table 1 lists a total of six failure modes that were set in this study, including normal, broken tooth of the sun gear on axis J2, crack of the planetary gear on axis J2, broken tooth of the planetary gear on axis J2, pitting of the sun gear on axis J3, broken tooth of the sun gear on axis J3, and crack of the planetary gear on axis J3.

Fault modes of the RV reduction gear: (a) normal planetary gear, (b) planetary gear with crack, (c) planetary gear with broken tooth, (d) normal sun gear, (e) sun gear with broken tooth, and (f) sun gear with pitting.
Failure modes setting the experiment.

In the experiment, the robot was set up with a fixed trajectory using a teach pendant, with the rotation set to a low speed (600 r/min) and the load set to a heavy load (9.6 kg). In each experiment, the coordinates of the industrial robot were first zeroed. Each axis was then moved back and forth three times within a set range of angles in turn, and each experiment was repeated 10 times. To better analyse and compare the effectiveness of the proposed algorithm, different fault modes were combined. To compare the classification effects of different fault types, the classification patterns are described as follows. There are three types of ABC pattern (defined as C3), four types of ADEF pattern (defined as C4), five types of ABCDE pattern (defined as C5), and seven types of ABCDEFG pattern (defined as C7). At the end of an experiment, the data from the attitude sensors at the six axis ends were simply processed, that is, one data point was taken every 200 points. Finally, a total of 6480 samples were collected for each pattern, with nine channels of data for each sample. In the subsequent fault diagnosis experiment, the entire dataset was divided into two parts: the training dataset (80%) and the test dataset (20%).
Experimental results and discussion
Each type of dataset was trained and tested nine times. Through parameter setting experiments, the parameters of the LLSO-ELM were set as NP = 100, NL = 10, LS = 10, MAX_FIT = 4510, ϕ = 0.5, and L = 80. The prediction accuracy of each dataset is shown in Table 2 and Figure 6. As seen, the LLSO-ELM has a higher prediction accuracy than the ELM for most of the datasets and a lower accuracy only for very few cases, but the difference between the two is very small. Therefore, the LLSO-ELM method has a high classification accuracy and a stable performance.
Prediction accuracy comparison of the LLSO-ELM and ELM methods for each dataset.


Result comparison of the LLSO–ELM and ELM methods for each dataset.
To demonstrate the superiority of the proposed LLSO-ELM, we compared it with the ELM. There is no empirical rule for setting the number of hidden neurons in an ELM. For comprehensive comparison, we conducted experiments by changing the number of hidden neurons in the LLSO-ELM and the ELM. In the experiment, each algorithm started with 50 hidden neurons, and 10 more hidden neurons were added each time until the number of hidden neurons reached 100, when the experiment ended. Both algorithms were run in the same operating environment as described above. Figure 7 shows the average prediction accuracies of the LLSO-ELM and the ELM with different numbers of hidden neurons for each dataset. It can be seen that the proposed LLSO-ELM outperforms the ELM for each number of hidden nodes. In addition, the prediction accuracy of the LLSO-ELM exceeds 78%, so the LLSO-ELM has a more stable performance.

The average prediction accuracies of the LLSO–ELM and the ELM with different hidden neurons for each dataset: (a) C3, (b) C4, (c) C5, and (d) C7.
Conclusion
The LLSO-ELM method has been proposed in this study for the mechanical fault diagnosis of industrial robot reducer gear. To further improve the generalization performance of ELMs, we have designed the LLSO-ELM model and used the LLSO to optimize the input weights and hidden layer biases of the ELM. The experimental setup consisted of a six-axis industrial robot, attitude sensors, and other components and was mainly used to collect the attitude data of the industrial robot in different working modes. Furthermore, these attitude data were combined into a variety of datasets to analyse the performance of the LLSO-ELM and compare it with that of the ELM. The experimental results have shown that the proposed LLSO-ELM algorithm has a high prediction accuracy for the fault diagnosis of reducer gear in six-axis industrial robots, and it also has a stable performance when set up with different numbers of hidden neurons, which is of great significance for further research on other parts of industrial robots.
In the future research, we will further combine the ELM algorithm with other metaheuristic algorithms for comparison, such as ant colony, monarch butterfly optimization (MBO), earthworm optimization algorithm (EWA) and other optimized extreme learning machines.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the National Natural Science Foundation of China (51975121), and the Postdoctoral Science Foundation of China (2019M652881), and the Department of Education of Guangdong in China (2018KTSCX224).