
Abstract
For automated robotic manufacturing, a key aspect of monitoring is the identification and segmentation of core actuation processes captured in sensor logs. Once segmented, the behavior of an industrial system during a particular actuation can be tracked to detect signs of degradation. This study presents a technique for performing such an analysis through a combination of machine learning techniques designed to work with an acoustic monitoring system. A spectrogram-based convolutional neural network (CNN) is first trained to identify and segment primary motion classes from acoustic data. Unsupervised clustering and feature-space analysis are then employed to further separate the data into motion sub-classes beyond the capabilities of the CNN. This approach was evaluated on acoustic recordings of a Selective Compliance Assembly Robot Arm (SCARA) system. The developed CNN performed primary robotic motion segmentation with a maximum actuation identification accuracy of 87% when compared to validation data. The unsupervised clustering process had mixed success in distinguishing more fine-grained motion sub-classes due to strong variances in signal energy for some sub-classes. Further refinement is required for improved segmentation accuracy as well as automatic feature generation. The application of this process for life-cycle system monitoring is discussed as well.
Introduction
Industrial manufacturing equipment often requires extended operation for maintaining fabrication tolerances as well as production capacity. 1 These systems demand persistent monitoring and maintenance. Conventional approaches rely on operator intuition; however, remote health monitoring techniques are increasingly applied due to caustic fabrication environments.
Industrial robots are complex mechanical systems that combine components such as motors, bearings, linear rails, and brakes. These systems typically perform a variety of actuations in 3D Cartesian space. These actuations produce measurably discernible acoustic signatures from various combinations of engaged mechanical hardware that should be identifiable through an acoustic monitoring system. Conceptually, changes in system performance stemming from mechanical degradations should be identifiable as well, with changes in acoustic harmonic content indicating progressive machine wear or damage. Frequently, only limited labeled data is available for algorithm training and model fitting, often with only weak labels that do not fully describe the complete range of system responses. This paper investigates how to develop a monitoring system under such conditions by combining deep supervised machine learning with unsupervised similarity analysis. This combined approach is then evaluated through a case study implementation.
Prior work
While monitoring industrial components using auditory characteristics has been studied, numerous practical challenges for monitoring systems in realistic environments persist. Several recent comprehensive literature surveys have outlined various challenges in remote monitoring.1–3 These surveys highlight the move toward data-driven approaches that minimize the need for statistical parameterization of monitored phenomena, as well as a reduction in the sensitivity of results to variations in feature engineering and extraction. Across a range of industrial applications, researchers have illustrated the benefits of employing customized deep and reinforcement learning strategies for robotic sensing and perception.4–7
With regards to acoustic monitoring, distinct audio features that can be used to classify events as well as damaged mechanical states are often difficult to determine. Signal features correlating with damage are often weak in amplitude compared to other recorded operations, 8 and deviations reflecting damage are not fully understood. Expert knowledge is often required to generate features and categorize audible dynamics corresponding to mechanical wear. Moreover, unique features must be separable, distinctive, and representative for audio signature classification.1,9–12 There have been a variety of studies on generating such features,1,9,10,12–14 however such features are typically domain dependent. Audio-based features suitable for noisy environments are debated in literature. While features derived from mel-frequency cepstrum coefficients (MFCC) have been used in a variety of sound classification studies, other descriptors have outperformed MFCCs in high noise environments. 10 Bach et al. 15 suggested that other feature sets, such as amplitude modulation, can outperform MFCCs with noise corrupted signals in speech detection.
To mitigate this problem, modern machine learning methods can be employed. 2 Many machine learning methods are at least somewhat insensitive to variations in feature quality. In particular, deep neural network learning models often mitigate the need for rigorous feature engineering at all, one of the advantages that motivated their development.16–18 Recently, a variety of studies have considered using a spectrogram representation of an acoustic signal as a neural network input, rather than the raw time series data. A spectrogram is generated through short-time Fourier transform procedures, and this data representation can capture evolving harmonic content over time across a broad range of the available frequency spectrum. The most effective deep learning method for such inputs has been shown to be a convolutional neural network (CNN). 10 A CNN, as opposed to a conventional feed-forward network, is ideal for such applications due to its inherent shift-invariance. In a CNN, a series of convolutional kernels (filters) are learned, such that both spatial and temporal relationships are captured. In the context of a spectrogram, this allows a CNN to identify frequency response signatures that do not occur on a repeatable cycle. Segmentation of acoustic events using a spectrogram-based CNN has been shown effective across many application domains, however the effectiveness of such methods is reliant upon large and exhaustive data sets for CNN model training.10,19–22 Specific concerns and justifications for using convolutional neural networks (CNN) in environmental sound classification were presented in Piczak, 23 most notably that the limited data sets available in such applications require alternative approaches when compared to state of the art speech recognition.
Other researchers have addressed challenges in the comparative analysis of audio content through unsupervised machine learning. Such approaches seek to extract key signal signatures, or identify similarities between signals, in a manner that does not require explicit statistical training data for model fitting. This work has often taken the form of feature similarity analysis or data clustering through methods such as k-means clustering. In the context of acoustic waveforms, researchers have focused on creating unsupervised methods to autonomously identify similarities in audio recordings.24,25 MFCC features were extracted from partial spectrogram segments from the full-length waveform. The feature vectors from the partial segmentations were compared, resulting in a cosine similarity heatmap. The authors then used the mapping as both a visual tool and similarity comparison between waveforms. The study in Jang et al. 26 documents how unsupervised spectrogram features could be extracted from an encoding layer in a deep autoencoder network and clustered to determine different audio sources. The two-fold approach suggested extracted spectrogram features allowed for separable classification. The concept of unsupervised analysis has been studied for robotic systems, for example with autonomous vehicles. 27 Researchers have also explored approaches for combining unsupervised clustering with supervised audio classification in application spaces such as emotion recognition and the analysis of animal vocalizations,28–31 though the concept has not previously been considered for industrial system monitoring.
Alías outlined several limitations for direct implementations of CNN architectures and spectrograms related to classifying audio content. 13 Harmonic content is generally complex and spatially separable in the frequency axis, often requiring transforms for optimal kernel mapping. Limitations directly adapting image processing based CNNs to audio-based classification were discussed in Fanioudakis and Potamitis. 21 Spectrogram content often contains a rectangular aspect ratio – different than traditional, square CNN inputs. This critical difference prevents the re-purposing of CNNs trained for image classification using techniques such as transfer learning.
Overall, a general survey of prior work indicated that deep neural networks, particularly CNN variants, are viable and effective for segmenting acoustic signals. Additionally, prior work reflects the value of using spectrogram representations as network inputs based on additional invariance to temporal distortions. Furthermore, studies indicate that features present in spectrograms contain viable information relevant for audio classification and analysis. However, the use of such approaches for acoustic-based remote health monitoring, particularly in combination with unsupervised analysis approaches, has not been extensively studied.
Research contribution
In this work, we propose and develop a new approach for the segmentation and analysis of robotic actuation signatures from acoustic recordings. Inspired by recent advancements in combining a CNN and unsupervised clustering for speech recognition,28,29 this approach combines a convolutional neural network designed for asymmetric spectrograms with unsupervised feature space analysis, in order to provide a more nuanced understanding of system behavior than can be accomplished with either method alone. The overall concept is to use deep learning to provide high-level segmentation on weakly labeled monitoring data, of the type commonly found in industrial applications. Unsupervised analysis via feature similarity and clustering are then used to provide insights into intra-class variances that would not be possible using only supervised learning.
The CNN architectures presented here are based on conventional architectures for square image inputs, however they are modified to accommodate the asymmetric nature of spectrogram inputs. No claims are made regarding the optimality of the presented CNN architectures. Rather, one goal of this work is to illustrate a generalizable approach to accomodating asymmetric spectrograms in industrial monitoring systems that employ deep learning.
As an illustrative example, this combination of supervised and unsupervised analysis is then used to capture and quantify instances of robotic motions embedded within recordings of a manufacturing facility. Recordings from a SCARA-series (Selective Compliance Assembly Robot Arm) (Figure 1) were leveraged for model training and testing, as well as for assessment of the similarity analysis. Such robots are widely used in manufacturing for tasks such as material transitioning. 32 Such an approach could be used to track system changes arising from progressive wear and damage across an array of similarly deployed systems. As such, this study also serves as a case study on the capabilities and challenges of acoustic monitoring in industrial settings.

Example of a SCARA robotic arm and associated Cartesian reference frame.
The remainder of this study is organized as follows. Presented first is a discussion of the behavior of the robot used for model development, as well as a preliminary study using less complex network architectures that motivated the need for both a deep network and a convolutional architecture. This is followed by the development and delineation of both the deep learning and similarity analysis components of the methodology, and then by an experimental analysis of the methodology on the previously mentioned SCARA-series robot motion recordings. The paper concludes with a discussion of the findings and avenues for future work.
Preliminary study
For clarity, the behavior of the SCARA-series robot used for prototyping and development is presented here. Primary SCARA robotic actuations can be generalized as a series movements within a Cartesian coordinate system. As shown in Figure 1, these primary motions include y-axis (base movement), x-axis (arm extension/retraction), and z-axis (body extension/retraction) motions. Limited harmonic content emission and associated operator intuition with regards to z-axis motion limited the scope of this study to analyzing y- and x- axis actuations. Each motion class had a duration of approximately 1 s.
Primary motions can be further subdivided into separate subclasses. Each subclass describes a physically different actuation along the same axis of travel. For example, class (1a) describes motion from point A to point B whereas subclass (1b) describes motion from point B to point A. While these actuations are similar in nature, each motion generates slightly different mechanical responses and thus acoustic emissions. Similarly, x-axis actuations include combinations material loading and transition movements. However, many of these secondary actuation classes occur only sporadically. As a result, it was impractical to attempt to classify them through a supervised machine learning approach, given the lack of relevant labeled training data. A methodology to distinguish these secondary classes through feature-space analysis of segmentations is presented later.
These actuations were recorded using a dbx RTA-M microphone, at a sampling frequency of 48 kHz, in a enclosed manufacturing bay containing a single SCARA-type robotic tool. The microphone was omni-directional, with a flat frequency response between 20 and 20 kHz. A 4-min audio recording containing a variety of actuations was used for training data. An additional 11-min audio recording, aligned with corresponding video data, was used as final validation data as well. Visual analysis of the resulting spectrograms of these recordings shows that primary motion audio signatures are distinct and frequent enough to be potentially distinguishable through supervised machine learning, however they occur over drastically different frequency ranges and with broad variations in power. For instance, y-axis motions are visually observable in a band ranging from 0 to 20 kHz, while x-axis motions are observable from 23 to 24 kHz (Figure 2).

Spectrogram representations of SCARA actuations captured in audio recordings.
Preliminary work was conducted to investigate classification of primary SCARA motions through artificial neural network (ANN) models. Analogous to the procedures outlined later, segmented training data consisting of primary SCARA motions was labeled and inputted to varying ANN architectures – as visually described in Figure 3. Two architectures were evaluated: a shallow network consisting of a single hidden layer (Figure 3(a)) and a deeper network comprised of three hidden layers (Figure 3(b)).The duration of primary actuations (

Preliminary study: tested feedforward network architectures.
The labeled data sets were manually created by trained operators. The total data set included 3310 audio samples. For model training, 692 audio samples for each of x-axis, y-axis, and ambient noise classes were used, with a waveform length of 49,153 points per sample. A validation set (10% of withheld training data) consisting of 77 segmentations of each class was aggregated as well. To reduce potential overfitting from class size imbalances, motion classes were capped to the minimum number of segmentations recorded (in this case y-axis motion) and sampled without replacement to reach the identical size. The process is analogously discussed in the subsequent CNN architecture development section.
The resulting performance of these models is shown in Figure 4. Lower energy actuations (x-axis) were consistently confused with noise states (visualized in Figure 3(a)) and the addition of hidden layers provided only a slight improvement as described in Figure 3(b). The minimal improvement, despite increasing architecture layers, possibly indicates data overfitting rather than increased classification accuracy. These results suggested a more sophisticated architecture was required due to the complex relationships present in actuation signals and the broad variations in representations between y and x-axis motions.

Preliminary study: confusion matrices for shallow/deep network classification.
Methodology
Similar to relevant prior literature, a convolutional neural network (CNN) was designed to perform segmentation of primary motion classes from an unlabeled spectrogram. From these segmentations, unsupervised feature similarity analysis and k-means clustering are then performed to identify secondary motions. This combined method offers unique advantages. Convolutional neural networks enable unsupervised learning of critical feature representations, reducing systematic bias from manual feature engineering. Additionally, complexity inherent within robotic movement data as well as non-stationary environmental noise suggests that contextual information from spectrograms can be exploited. However, due to the limited labeled data available for actuation sub-classes, the training data could only be divided into primary groups, necessitating the need for the unsupervised feature analysis. However, this two-step analytical approach has the benefit of being generalizable to a wider range of SCARA implementations, as the primary motions are somewhat universal in their acoustic response signatures, whereas secondary class signatures are not.
Spectrogram dataset development
A review of the relevant literature indicated that signal pre-processing via filtering was not advisable; simplistic techniques to isolate noise and characteristic information can unintentionally decrease acoustic emission. 8 Preliminary experiments also indicated that isolating and correcting for wide-spectrum environmental noise was infeasible and could potentially obscure valuable data. Furthermore, extensive signal pre-processing for initial segmentation would bias resulting approaches to the SCARA unit data employed for testing, limiting extensibility to other robotic systems.
Spectrograms were generated using a Blackman-Harris window of 4096 waveform data points, overlap of 2048 data points, and 8096 Discrete Fourier Transform (DFT) points. Input spectrograms were fixed with 4097 (height) × 25 (width) dimensions, with regards to the resulting temporal-frequency bins of the spectrograms. These dimensions stemmed from the shortest known event duration (1.1 s). Due to the fixed length of the spectrogram input and variability between sub-class y-axis motion duration, some training examples were unintentionally split into overlapping sections. While introducing redundant information potentially biases network training by overfitting, several other benefits may be introduced. The variation in training set may outweigh bias introduced in redundant overlapping sections, as mentioned in Piczak. 23 Moreover, the CNN will realistically encounter similar, partially obscured spectrograms during segmentation in operation.
The training set consisted of 1360, 769, 1181 training examples of noise, y-axis, and x-axis motions, respectively. Training data sizes were kept constant. For example, training a 3-class classifier CNN between y-axis, x-axis, and noise used 769 examples as the maximum training set size; the other classes were randomly sampled, without replacement, to match the minimum training set amount. Keeping the training data count consistent further prevented overfitting bias. The final training dataset contained 2076 spectrogram samples with 231 samples (10%) withheld for validation.
Spectrogram normalization was first used to limit spectrogram variability. Across 3000+ test spectrograms, minimum, and maximum temporal-frequency bin values were calculated and used as boundaries. All training and test spectrogram temporal-frequency were rescaled from a minimum bound of −14.68 and maximum bound of 5.89 to values between 0 and 255, making the spectrograms a more image-like data type and enabling a wider range of network activation functions. A similar mapping procedure was successfully implemented in Dennis. 10
CNN architecture development
To the authors’ knowledge no established CNN architecture exists for spectrogram training as reaffirmed in previously mentioned studies. Moreover, due to domain-specific requirements, other spectrogram specific architectures were unsuitable for direct application. Due to the high resolution and frequency dependent spacing in training spectrograms, an empirical study was conducted to evaluate general trends among candidate CNN architectures. A hyperparameter sensitivity study addressing convolutional kernel dimensions was performed; however, an exhaustive parameter search for an optimal architecture was considered outside the scope of the current work and requires future study.
A key consideration in the development of the CNN architecture was the highly asymmetric aspect ratio of the spectrogram inputs, a relatively understudied topic when compared to the exhaustive body of literature on developing CNNs for square aspect ratio image inputs. Prior work in developing CNN architectures suggested either extracting key excitation regions within spectrograms or scaling spectrogram inputs, in order to accommodate standardized CNN architectures with square aspect ratios.10,21,22 However, the dependence on coupled wide-band frequency and temporal content meant that this approach was infeasible, and necessitated the development of the customized CNN architectures presented in this work.
These architectures are based on the well-known LeNet and AlexNet CNN architectures due to their simplicity and flexibility. 33 These CNN models use five successive convolutional layers with kernel mappings that range from 11 × 11, 5 × 5, and 3 × 3. 33 Due to initial difficulty with model convergence, likely due to the skew of the spectrogram inputs, a sixth convolutional layer was added. The dimensions for padding, stride, and receptive fields in the convolutional layers were adjusted to account for the asymmetric input. Other hyperparameters were tuned empirically. The authors note that this approach was designed to explore applicability, but not necessarily the optimization, of convolutional nets for diagnostic analysis of spectrograms.
Three architectures were developed in order to understand how varying convolutional kernel dimensions impacted asymmetric spectrogram segmentation. The architecture construction does not vary dramatically among the three models, as the goal was to identify trends in symmetric/asymmetric filter sizes for the asymmetric spectrogram inputs. Padding, kernel, and layer dimensions were determined based on reducing dimensionality to a minimized, 1-D, fully connected softmax layer. Each architecture was of comprised of six hidden, convolutional layers. While literature studies vary on optimal network size using CNNs for spectrogram analysis, 4–6 stacked hidden layers are common in spectrogram based classification, and motivated the CNN models designed in this work.34–39 Models with fewer than six layers suffered from convergence issues and are not considered further here. Initially, square kernel sizes varying between (5,5) and (3,3) were implemented for CNN architecture #1, and were varied empirically for subsequent architectures.
Hyperparameters were identified empirically, using the AlexNet model as a baseline for exploring variations. The training rate for stochastic gradient descent with momentum (SGDM) was held to 0.001. The maximum epoch number was held at 1000 while minibatch size was kept constant at 64 samples. Max pooling layers were intentionally omitted with all tested architectures. While the down-sampling procedure provided feature translational invariance, the reduction in parameters also decreased the potentially learnable feature space and degraded performance. These behaviors were discussed in Sabour et al., 40 Zhou et al. 41 and Yu et al. 42 To reduce the computation time, a stride corresponding to five temporal-frequency bins, or 0.264 s, was specified. While a CNN may benefit from over-fitting prevention methods such as dropout, these steps were omitted for simplicity; as stated in the future work section, such augmentations require a separate and thorough study. The complete list of CNN parameters is presented in Tables 1 to 3.
CNN architecture # 1: square convolutional kernels.

CNN architecture # 2: asymmetric convolutional kernels designed to captured known acoustic phenomena.

CNN architecture # 3: asymmetric convolutional kernels designed to capture wideband acoustic phenomena.

Architecture #1
The first tested architecture was based on CNNs developed for image processing, with square kernels applied to the asymmetric spectrogram inputs.20,21 Smaller initial kernel sizes (5 × 5) were used to understand the effects of rectangular kernel dimensions. While smaller than ImageNet (11 × 11), and GoogleNet (7 × 7) first layer kernel dimensions, 43 the architecture was generally representative of smaller, local features embedded in the spectrogram’s time-spectral relationship.
Architecture #2
For the second architecture, a 9 × 7 input kernel was chosen due to the minimum spacing between features in an observed “cupping” phenomena present in x-axis motions (Figure 2(b)). This was considered the smallest asymmetric kernel dimension to completely capture the visual signature in training data.
Architecture #3
This architecture demonstrates the highest asymmetry tested. An initial 25 × 5 kernel dimension with large vertical strides attempted to capture more frequency dependence among temporal-frequency bins. However, the horizontal component of kernel filters should capture some temporal harmonic content.
Segmentation extraction
The outputs of the softmax network layer provided the basis for classification. Overlapping segmentations shared between classes was potentially problematic. To handle class bounding box overlap between x- and y- actuations, any overlapping boundary times were averaged. While a simplified approach, the method allowed for a separation of independent segmentations. Other bounding box methods such as fuzzy classification are possible and are a potential avenue for future work.
Unsupervised analysis
Feature engineering
Once segmented into primary motion classes via CNN, the corresponding audio waveforms are further discriminated through feature engineering and unsupervised analysis. Derived from corresponding audio waveforms with varying lengths, features are calculated from time, statistical, and spectral domains. These features include peak amplitude, average amplitude, mean square, root-mean square, zero-crossing rate, variance, standard deviation, kurtosis, crest factor, skewness, and k-factor.
Frequency data between 4 and 24 kHz was empirically known to contain the most useful harmonic information to discriminate between actuation classes. However, comparing peak frequency content became immediately problematic due to motion complexity and diffuse noise concerns. As shown in Figure 5, relevant peak finding in the presence of wideband noise is almost impossible due to the variation in spectral content between sub-class samples. While optimal filtering techniques would require further, comprehensive study, a widely adopted acoustic smoothing technique was implemented.44,45 Savitzky-Golay filtering, with a 3rd order model and 101 regressive points, was used to filter spectral content. The least-squares smoothing operation was chosen due to its application in retaining peak harmonic content and higher frequency dynamics with high noise concerns. 46 While not rejecting as much noise as other autoregressive models, the method relatively retains peak widths adequately for this exploratory study.

Frequency response and spectral distribution of a segmented acoustic waveform (Class 1a actuation) without smoothing.
Peak estimates were difficult to directly compare due to spectral distribution even after filtering. As shown in Figure 6, even smoothed frequency responses demonstrated visual indicators with differing peak content including peak locations, magnitudes and peak number. Typical peak finding procedures were insufficient to capture seemingly discriminate frequency content through energy signatures. After numerous attempts, peak amplitude(s) features were intentionally omitted. Spectral moments were subsequently used as a metric for evaluation and considered more robust despite corrupting noise. Analogous to the statistical features from the time domain response, kurtosis, crest factor, k-factor, and skewness were applied on the FFT response data between 4 and 24 kHz. These new features described statistical moments in the spectral domain. The procedure demonstrated discriminating information in spectral distributions between unfiltered (Figure 5(b)) and filtered (Figure 7(a)) segmentations. General differences between two subgroups’ spectral content can be captured from these filtered distributions; Figure 7(a) and (b) provides the reader with a visual representation of these differences. A final concatenated feature set is shown in Table 4. Principal components were then computed to find features of maximum variance for clustering and similarity analysis. Principal components were chosen to represent at least 95% of the variability present in the feature set.
Unsupervised features.
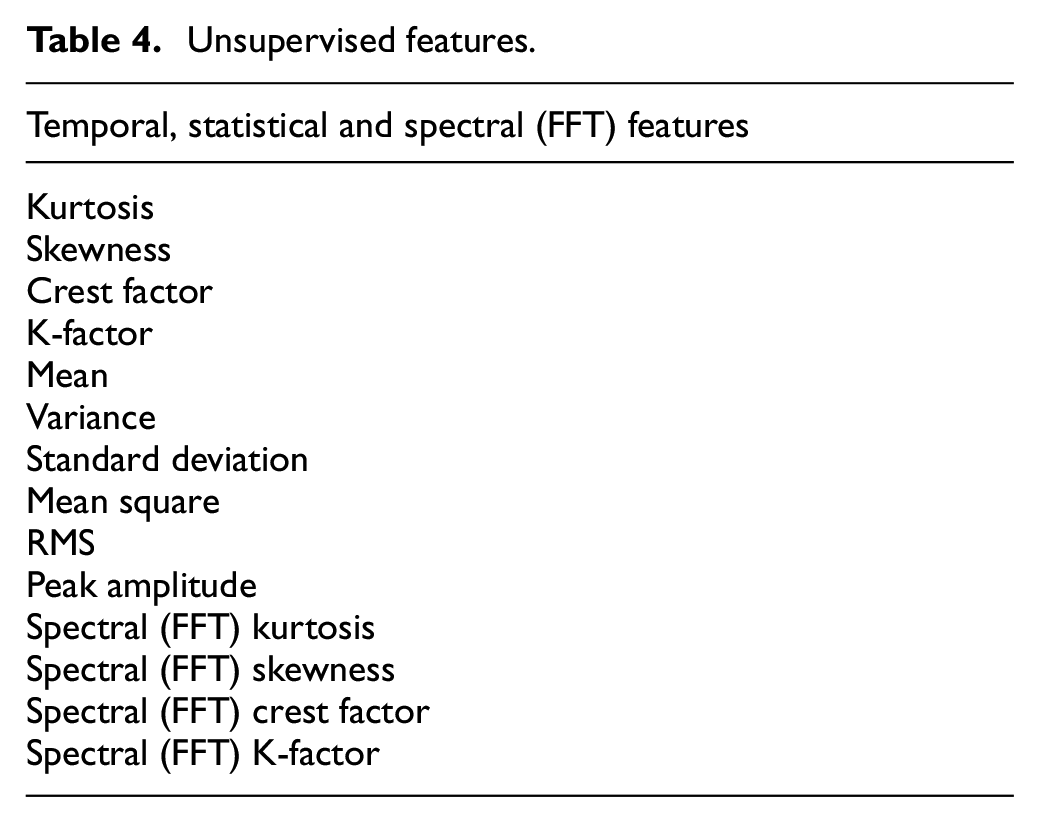

Illustration of differences in spectral responses between y-axis sub-classes after signal smoothing.

Spectral distributions for Class 1 actuations.
After feature extraction, several unsupervised methods were evaluated for assessing similarity between segmented sub-classes. Seven y-axis and eight x-axis actuation sub-classes were observed in the labeled ground-truth dataset. The cosine similarity, or the inner product between sub-class feature spaces, was calculated as a metric invariant to the dimensionality of the feature space (equation (1)).

The parameter
K-means clustering was then used to further delineate primary motion segmentations based on the extracted feature set. While other works discuss the k-means algorithm in depth,47–49 the clustering procedure attempts to minimize distances between translatable centroid locations for a set of feature vectors describing a range of actuation events. This distance is computed as:

The angular distance,
Results
Supervised classification
Due to the sliding window nature of the spectrogram inputs, a classification accuracy metric based on bounding box area was employed, based on the work in Fanioudakis and Potamitis. 21 Overlapping false-positive and false-negative areas were calculated from differences between labeled actuation locations in a validation spectrogram and CNN classification results. Waveform segments shared by known actuation durations and classification were recorded as overlapping area percentage. Actuation data not captured by classification resulted in a false-negative area percentage. Audio segments incorrectly classified as actuations resulted in a false-positive area percentage. The results from each architecture was presented in Tables 5 and 6.
Validation on ground truth spectrogram (y-axis motions).

Validation on ground truth spectrogram (x-axis motions).

Tables 5 and 6 highlight architecture differences in discerning x-axis and y-axis motions. Architecture #3 demonstrated the highest overlapping area percentage and F1 score in y-axis classification, while architecture #2 had the lowest classification accuracy for y-axis motions. Architecture #2 falsely classified 8.7% of spectrogram data as y-axis motions while missing nearly 45% of known actuation durations. Architecture #3 additionally held the lowest false positive and false negative area during y-axis classification. Results for x-axis motions differed slightly. While architecture #1 was still clearly inferior, architecture #2 showed improved performance in capturing x-axis actuations. However, the increase in accuracy was accompanied by the highest false positive rate. Architecture #3 again had the highest F1 score.
The results suggest that classification accuracy is somewhat dependent on kernel dimensions. Highly asymmetric spectrogram input kernels demonstrated the best compromise in accuracy for y and x-axis classification. The result in Table 5 suggests that harmonic complexity in y-axis motions was better captured with skewed kernels with dominating frequency content. Smaller kernel dimensions demonstrated a lower classification accuracy with respect to discriminating known y-axis actuations. However, this trend is not followed with x-axis actuations – harmonic content may be captured with smaller kernel dimensions.
Figure 8 describes the difficulty in delineating feature edges with bounding box methods. While the method cleanly identified 87.1% of y-axis motions (architecture #3), y-axis segmentations corrupted by noise artifacts degraded classification accuracy, particularly near the boundaries of actuation initiation and termination.

Example of poor classification around actuation transitions with wideband noise.
The trained CNN architectures had difficulty distinguishing differences between x-axis motions from y-axis motions at the boundaries of event transitions. This may be due to several phenomena including a similar feature-space for both events. This may have led to segmentation bias during y–x transitions; spectrograms with overlapping x/y transitions were biased toward a probability of y-axis motions (architecture #3) or toward x-axis motions (architecture #2). Sharp, wideband noise arising from neighboring mechanical phenomena during production processes were observed in both x- and y-axis segmentations. These artifacts were observed to degrade classifier accuracy as well, as was to be expected.
The results suggest a supervised approach to actuation classification from acoustic signals is feasible, given sufficient training data and accounting for the necessary asymmetry of the convolutional layers. An exhaustive hyperparameter search to determine optimal convolutional kernels and network topology would ultimately lead to increased classification accuracy than what is presented here. Unforeseen noise artifacts and other factors not experienced in the CNN training set may have additionally contributed to an architecture not fully representative of SCARA sub-classes.
Due to its more consistent performance, CNN architecture #3 was used for the analysis of the unsupervised methodology. The trade-off in x-axis classification overlap was acceptable given the higher y-axis classification accuracy along with lower false positive and false negative percentages among certain classification tests.
Unsupervised clustering
Analysis of y-axis motions
Cosine similarity analysis was conducted between each segmentation for y-axis motions, illustrated as a heat-map visualization of similarity in Figure 9. A numeric score of zero (dark blue color) indicates perfect similarity. As dissimilarity between segmentations increases, the numeric similarity score increases toward 1 and red shading.
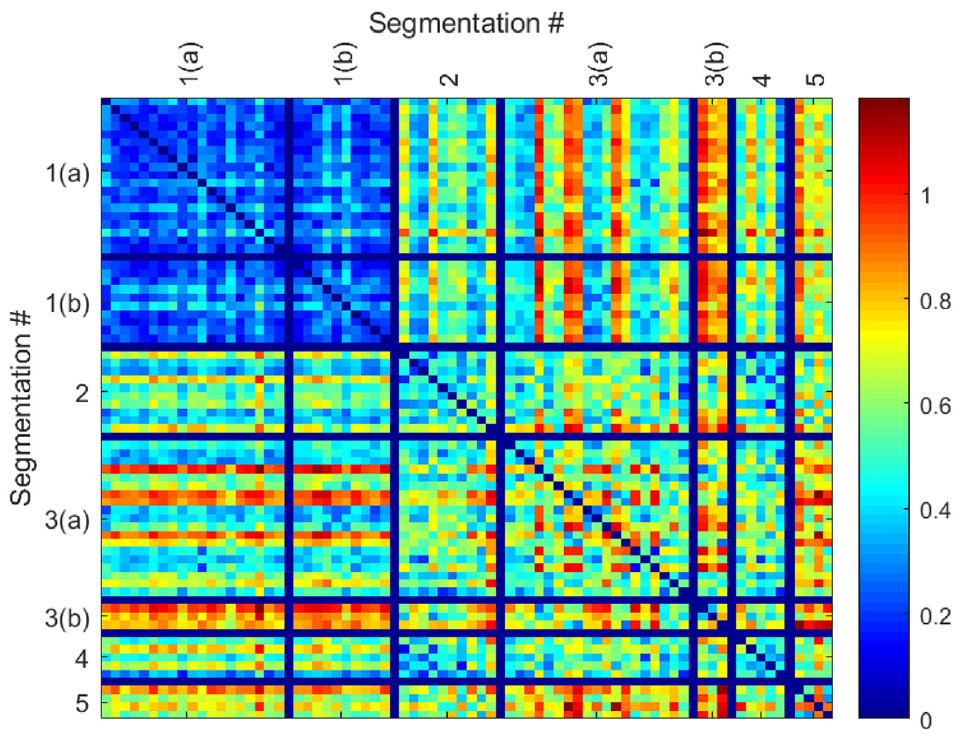
Cosine similarity heatmap for y-axis motion sub-classes.
An evaluation of this similarity yields several insights. Actuation sub-classes 1(a) and 1(b) are mechanically similar and dissimilar from other actuations, and this is clearly evidenced in the similarity results. Actuation sub-class 2 is relatively similar to other motions in its category; however, it shares some similarity with subclass 4. Subclass actuation 5 is distinctly dissimilar from the other actuation sub-classes. Subclass 3(a) and 3(b) are not clearly distinguished through cosine similarity. Notably, several outliers are present in each subclass, potentially due to incorrect segmentations or noise-corrupted results.
After similarity analysis, k-means clustering was employed to separate primary classes, as a point of comparison with the cosine similarity results. As discussed previously, principal component analysis was conducted on segmentation features before applying k-means clustering, with six principal components comprising 96.2% variability in the feature set. The first and second principal components were subsequently plotted with respect to their corresponding subclass labels in Figure 10.

Relationships between first two principal components for y-axis motion sub-classes.
When looking at a three cluster segmentation, certain actuation sub-classes were naturally clustered with their inherent segmentation labels. While perfectly separated clusters were not observed, certain trends became evident. Figure 11 describes the qualitative assessment of clusters. Firstly, actuations 1(a) and 1(b) shared a cluster. Corresponding with the cosine similarity visualization, these subclass actuations share similar feature spaces. Furthermore, these subclasses shared relatively dissimilar principal component spaces compared to groups 2–5. Sub-class 5 was partially separable from other subclasses. Other subclasses such as 3 and 5 are relatively tightly clustered with respect to their neighboring segmentations. Importantly, it was observed that visually separable clusters may be impossible with the chosen engineered feature set, reinforcing the results of the cosine similarity analysis.

Results of k-means clustering on segmented y-axis motions (3 centroids).
Increasing the number of clusters to 7, the number of known actuation sub-classes, did not improve results (Figure 12). Because some motion subclasses share similar principal component space (and are mechanically similar as well), it was not possible to separate them.
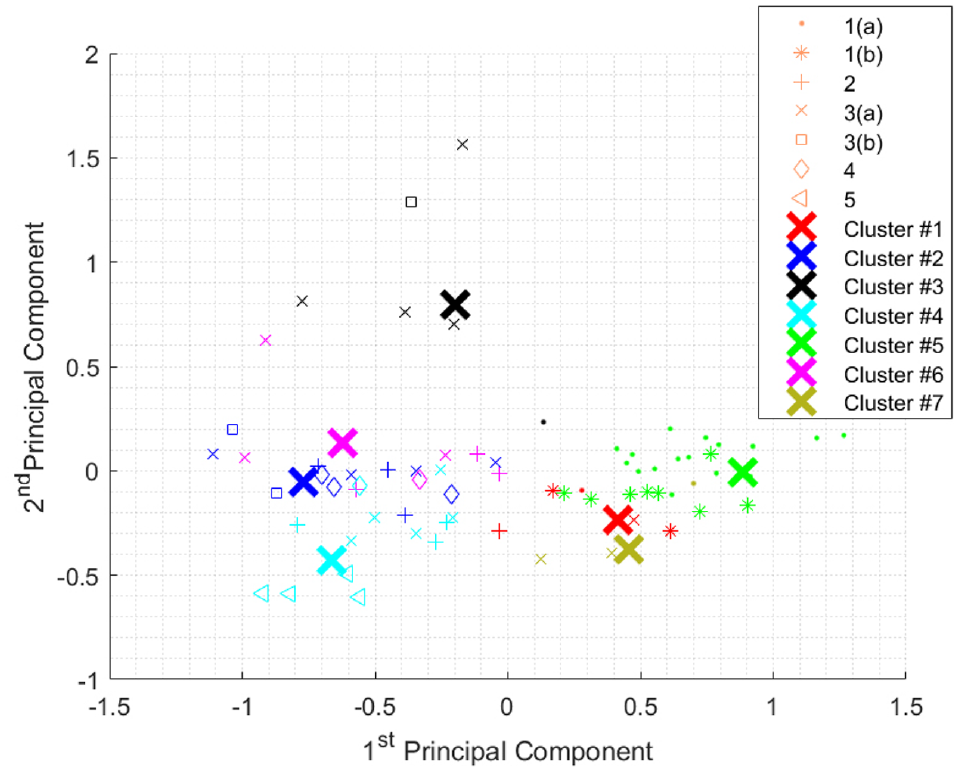
Results of k-means clustering on segmented y-axis motions (7 centroids).
As with the similarity analysis, the mixed accuracy suggests other contributing factors. Noise artifacts may have contributed to potential feature set outliers. Both PCA and k-means are sensitive to noise, suggesting a more robust algorithm could better reject variations present in segmentation. Other feature sets as well as fuzzier classification attempts (for instance a Gaussian mixture model) may address this issue. However, the results show the potential to isolate some key actuation sub-classes in an unsupervised regime.
Analysis of x-axis motions
X-axis segmentations were subsequently analyzed (Figure 13). Compared to y-axis segmentations, most x-axis segmentations were not as easily separable into the eight known actuation sub-classes. The majority of blue-shaded regions and high similarity scores suggests that the x-axis motion features do not contain enough discriminating information. Considering that they are lower power events and manifest in a smaller frequency band than the y-axis motions, this performance was anticipated. Some outlier segmentations were identified due to their higher dissimilarity scores, particularly in sub-classes 1 and 2.

Cosine similarity heatmap for x-axis motion sub-classes.
Similar to the y-axis clustering, x-axis actuations were grouped using the k-means algorithm with angular distance metrics. The two highest principal components, depicted in Figure 14, depict the general inseparability of these segmentations, as well as the fact that X-actuations are predominately determined by a dominant principal component. Clustering x-axis segmentations reflect the inseparability of extracted features leading to over-segmentation, see Figure 15.

Relationships between first two principal components for x-axis motion sub-classes.
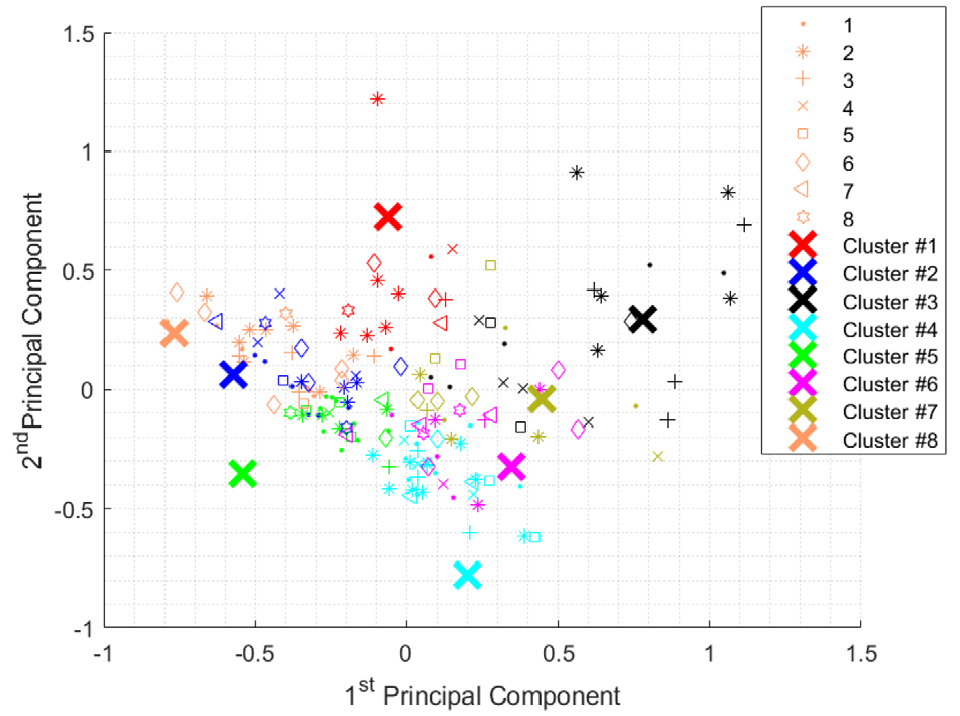
Results of k-means clustering on segmented x-axis motions (8 centroids).
Sources of error
Several potential error sources were noted which may have negatively impacted results. Without an exhaustive hyperparameter study, sub-optimal neural network architectures may have contributed to reduced classification accuracy. Furthermore, deep-learning techniques are notoriously data hungry – and the relatively limited training set may have unintentionally contributed to segmentation error. Omitting overfitting concerns, unintentional training set bias was possible. The proposed methodology is also dependent on the bounding box approach to handling overlapping segmentations, which could potentially be improved. Noise in the acoustic recordings also likely impacted classification results. Lastly, user-defined ground-truth labels may have errors, which would have explained some of the strong outliers within the x-axis similarity analysis.
Discussion
This work presents three potential CNN architectures to explore spectrogram classification; however, numerous architectures are possible or more optimal, particularly if a larger set of training data is available. It is worth emphasizing that the rapid advancement of deep neural network research makes determining an optimal architecture difficult. Rather, the goal here is to illustrate a generalized approach that can be adopted and optimized as the field of research evolves. The architectures introduced demonstrated adequate performance, and more importantly, feasibility. However, no claim to computational optimality is made here. A more in depth study on the impacts of asymmetric convolutional kernels is also needed. A fuzzier segmentation algorithm may also be required in high noise spectrogram cases where class labels are ambiguous, or where actuations occur nearly simultaneously. Bounding boxes may have introduced unintentional bias between neighboring y- and x- axis segmentations and the results suggest refining this aspect of the approach. Non-stationary noise present in the manufacturing environment tended to corrupt spectral features significantly, including peak definition and overall energy. Optimal filtering may present one potential improvement, and smoothing the FFT responses yielded an empirical improvement for other spectral features such as spectral moments.
Further refinements in feature generation are similarly required. The selected feature set was based on features sets that have had demonstrated success in other applications, but their use may require additional work for domain specific implementation. Automatic and more nonlinear feature set generation approaches could be employed, such as those provided by a convolutional autoencoder.
The presented approach has a few key limitations worth noting. The CNN architectures presented here were designed for spectrograms with heavily skewed aspect ratios (4097 × 25). Spectrogram inputs that approach a 1:1 aspect ratio may lead to dramatically different system behavior or CNN architectures. Additionally, the unsupervised analysis performed better on signals that manifested across a wide band of frequencies due to the featurization methods employed. This is best shown through the illustrative examples, where the performance for y-axis motions was shown to be superior when compared to x-axis motions. Narrow band signal manifestations would likely require additional signal processing or different featurization methods.
Conclusion
This study demonstrated that a combination of deep supervised and unsupervised machine learning techniques could identify and classify robotic sound events in a realistic manufacturing environment. A supervised convolutional neural network architecture was developed to isolate primary actuation instances from an arbitrary length spectrogram. Using ground-truth, labeled spectrogram data, 87.1% of y-axis and 84.2% of x-axis motions were successfully segmented. Asymmetric convolutional kernels yielded the most consistent results.
Once the primary actuations were segmented, an unsupervised similarity analysis based on cosine similarity or k-means clustering was able to distinguish primary y-axis actuations into smaller sub-classes, though this was not possible for low-power x-axis motions. Despite limitations, including challenges with mechanically similar actuation sub-classes, noise, and possible mislabeled data, this approach showed reasonable efficacy.
Future work will look at how to improve the feature selection process through the use of an autoencoder. This will be followed by a study on how this process can be used to track and quantify progressive wear and deterioration in a mechanical system that cannot be detected through conventional outlier-based damage detection strategies.
Footnotes
Acknowledgements
The authors would also like to thank members of the Lattanzi Research Group for their contribution and input to this project.
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Portions of this work were supported by a grant from the Office of Naval Research (No. N00014-18-1-2014). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the Office of Naval Research.