
Abstract
In order to improve the working stability of brushless direct current motors (BLDCM), a diagonal recursive neural network (DRNN) control strategy based on Q-learning algorithm is proposed in this paper which is called as Q-DRNN. In Q-DRNN, DRNN iterates over the output variables through a unique recursive loop in the hidden layer, and its key weight is optimized to speed up the iteration. Moreover, an improved Q-learning algorithm is introduced to modify the weight momentum factor of DRNN, which makes DRNN have the ability of learning and online correction so as to make the BLDCM achieve better control effect. In MATLAB/Simulink environment, Q-DRNN is tested and compared with other popular control methods in terms of speed and torque response under different operating conditions, and the results show that Q-DRNN has better adaptive and anti-interference ability as well as stronger robustness.
Introduction
Due to its simple structure, high efficiency, long service life and low noise, BLDCM has been widely used in national defense, aerospace, robotics, and so on.1–5 BLDCM plays an important role in the modern motor control system. Therefore, it has important practical significance and application prospect to study the control strategy of BLDCM with fast response, strong regulation ability and high control accuracy.
PID control is one of the earliest linear control strategies with a long history. It is still the most commonly used control algorithm in industrial control system. In common, P (proportion), I (integral) and D (differential) can be combined into many kinds of controllers. In Jigang et al., 6 Wei et al., 7 Premkumar and Manikandan, 8 and Gundogdu and Komurgoz, 9 PI, PD and PID controllers are respectively used to control the speed of BLDCM. However, the uncertainties, nonlinearity and parameters manual adjustment of typical PI, PD or PID controllers make it difficult to determine the appropriate gain to achieve the optimal performance of the control system.
With the development of computer technology and intelligent control theory, various types of intelligent algorithm optimized PID controllers have been proposed in the last decades. In Ahmed and Rajoriya 10 and Afrasiabi and Yazdi, 11 the sliding mode controllers are proposed to realize the speed control of the motor. However, the chattering problem inevitably exists in the sliding mode control, which results in the overall performance degradation of the system. In Ramya et al. 12 and Premkumar and Manikandan, 13 fuzzy logic control algorithms are proposed, but the algorithms rely on expert knowledge rule base. In Demirtas, 14 genetic algorithm is used to optimize the gain of PI controller. However, the initial population of genetic algorithm may not be easy to determine. In Khubalkar et al. 15 and Badar et al., 16 particle swarm optimization (PSO) is adopted, but the presented algorithms have some problems such as slow convergence speed and local optimization. So many methods are proposed to simplify or improve them. The algorithms based on neural network have shown promising results.17–21
The PID gain updating algorithm based on neural network has been successfully applied to the control of servo motor, 21 computerized numerical control machine tool, 18 etc. In Xia et al., 22 a single neuron PI controller is designed for the control system of BLDCM. In Kumar et al., 23 a kind of PID controller based on neural network is proposed, which consists of a hybrid local recurrent neural network including at most three hidden nodes so as to form a structure similar to PID. The controller is easy to realize, but its number of parameters is difficult to be determined. Moreover, the training algorithm based on gradient descent is a time-consuming process. In Premkumar and Manikandan, 24 an Online fuzzy supervisory learning method based on RBFNN (Online-RBFNN) for BLDCM is presented. The fuzzy PID supervisory algorithm is applied to RBFNN. Compared with PID controller, Online-RBFNN has significantly smaller oscillation phenomenon and steady-state error, but its selection of fuzzy rules still needs to be optimized. In Premkumar et al., 25 aiming at the speed control problem of BLDCM, antlion algorithm optimized fuzzy PID supervised online recurrent fuzzy neural network based controller is proposed. The learning parameters of supervised online recurrent fuzzy neural network controller are optimized by using antlion algorithm. In Kang et al., 26 PSO is used to initialize the weights of the adaptive PID neural network controller, and the improved gradient descent algorithm is used to adjust the parameters of the PID neural network. The disadvantage of this method is that PSO takes a long time to initialize the PID neural network. Then, GA-PSO is used to optimize the online adaptive neuro fuzzy inference system (ANFIS) for the speed control of BLDCM in Premkumar and Manikandan. 27 The hybrid GA-PSO algorithm is used to optimize the learning rate, forgetting factor and the maximum decreasing momentum constant of the online ANFIS controller under different torque conditions of BLDCM, and the effectiveness of the method has been verified by simulation experiments. Moreover, the implementation of these controllers are relatively complicated in practical, so FPGAs (Field Programmable Gate Array) are usually used as high-speed hardware to run the controllers because of their offered parallel processing abilities as well as short execution time compared with traditional microcontrollers and DSPs (Digital Signal Processor).28,29
In recent years, machine learning (ML) has become a popular topic. Reinforcement learning is a branch of ML whose purpose is to find the optimal strategy that must be followed in the transition of some states so as to maximize the total return of the selected operation. 30 Q-learning is one of the most popular and successful reinforcement learning methods. 31 In Sarigul and Avci, 32 a learning system with general recurrent neural network topology based on Nadaraya-Watson kernel adopts Q-learning method to evaluate a fast and effective behavior selection strategy for reinforcement learning problems, and its effectiveness is verified. However, the Nadaraya-Watson kernel regression based recurrent neural network needs to deal with all samples, which deteriorates the overall control effect in case of high-dimensional samples.
Combined with the strong search ability of Q-learning and the advantages of DRNN such as recursive loop structure, dynamic mapping ability and adaptability to time-varying, this paper presents a control strategy Q-DRNN to improve the performance of BLDCM. Q-DRNN optimizes the key weight in normal DRNN, and introduces Q-learning to modify the weight momentum term factor so as to achieve better control effect. Q-DRNN has the ability of learning and online correction, which enhances the anti-interference (Anti-interference ability refers to the ability of the control system to maintain some characteristics under the condition of load and speed mutation.) and robustness of the system. In order to verify the effectiveness of Q-DRNN, its performance is tested and compared with neural network PID (NNPID) control method, 23 Online fuzzy supervisory learning method based on RBFNN (Online-RBFNN), 24 antlion algorithm optimized fuzzy PID supervised online recurrent fuzzy neural network (ALO-RFNN) based control method 25 and Q-learning optimized regression neural network (QLRNN) control method 31 under different operating conditions.
The rest of this paper is organized as follows: Section 2 introduces the mathematical model of BLDCM, Section 3 describes the proposed Q-DRNN in detail, Section 4 gives the simulation results, and Section 5 concludes this paper.
The mathematical model of BLDCM
The mathematical model is the basis of the performance analysis and control system design of the BLDCM. The differential equation model of the two-stage three-phase BLDCM is established in this section.
1. Voltage equation
According to the knowledge of motor science, the voltage equation of stator three-phase winding can be expressed as:

where
2. Torque equation
The torque equation is:

where
3. Equation of motion

where
4. Equation of state
The voltage equation can be rewritten as a state equation:

The equivalent circuit diagram of the voltage equation is shown in Figure 1:

Simplified three-phase stator equivalent circuit.
Based on the BLDCM model shown in Figures 1 and 2 shows the BLDCM speed control system.
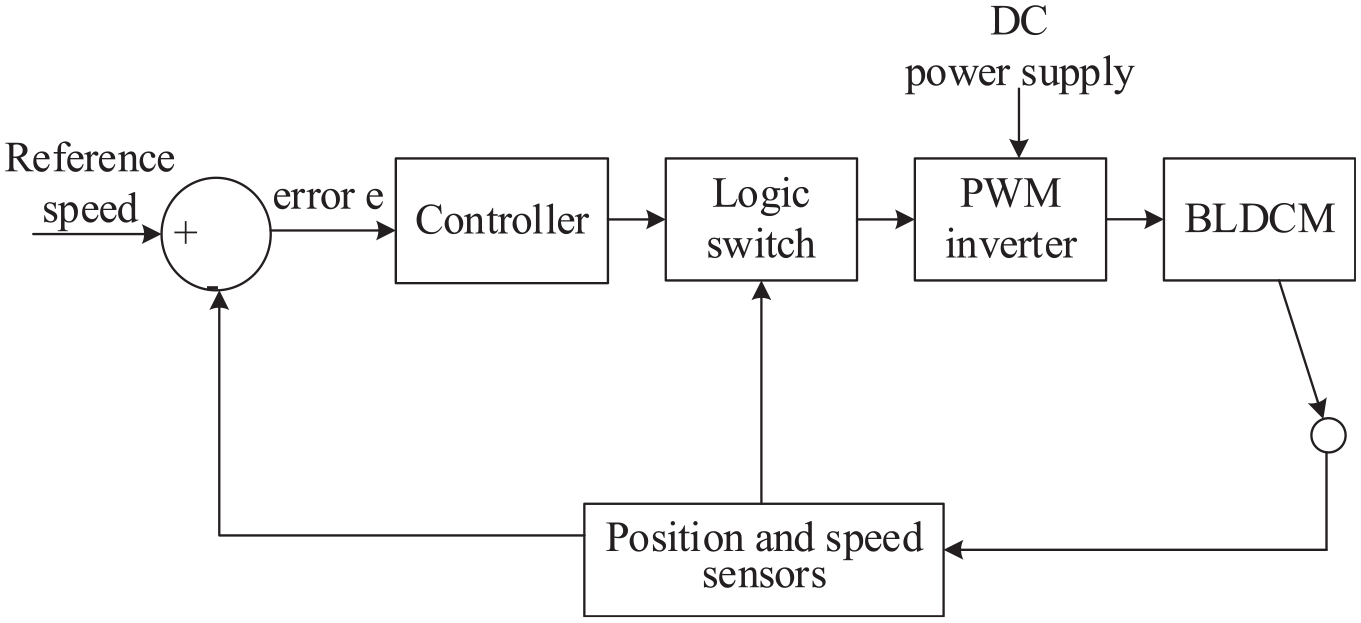
Control system of BLDCM.
The system consists of three-phase voltage source PWM inverter, three-phase BLDCM, controller, logic switch and motor measurement sensor.
The proposed control strategy
The control strategy proposed in this paper uses Q-learning algorithm to modify the weight momentum term fact of DRNN so as to improve the control effectiveness of BLDCM, which consists of three aspects: the design of DRNN, Q-learning algorithm and Q-DRNN controller. The detailed description of the control strategy is given as follows.
Design of DRNN
Consider the BLDCM as a discrete nonlinear system

where
The structure of the direct intelligent control system composed of a diagonal recurrent neural network is shown in Figure 3. Similar to feed forward neural network, the diagonal recurrent neural network is composed of input layer, hidden layer and output layer. The difference is that each neuron in the hidden layer has its own recursive loop. In Figure 3, the input and output of DRNN controller are



where,
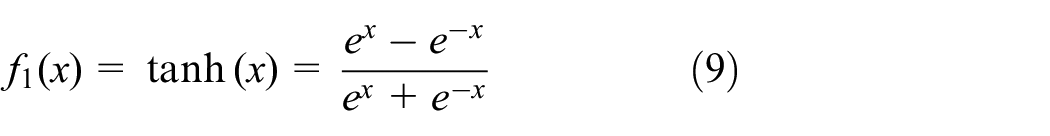


The control system of DRNN.
The system input can be expressed as

where K is the gain coefficient.
Q-learning algorithm
Q-learning algorithm is an iterative incremental online learning method. It enables the agent to select the optimal action sequence in the Markov decision-making process through the interaction with the external environment. 26 Figure 4 shows the principle of the Q-learning algorithm.
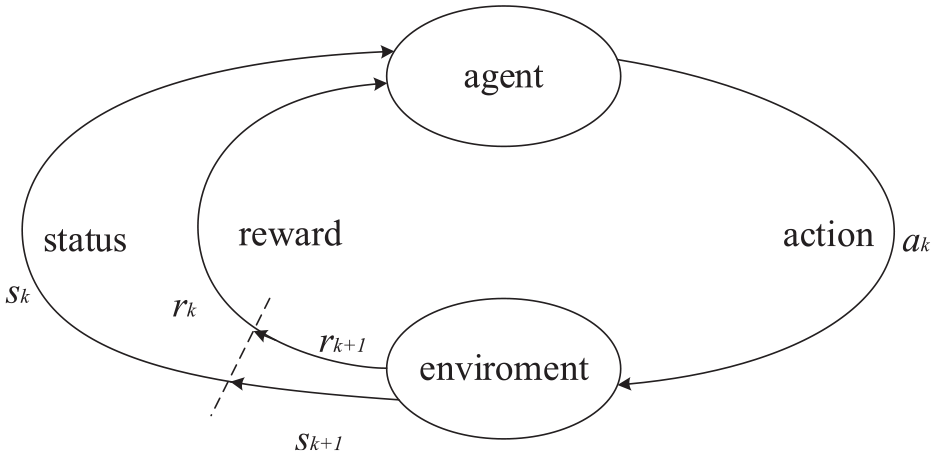
Principle diagram of Q-learning algorithm.
The value function of Q-learning is defined as follows:

where


where: Qk represents the k-th iterative value of the optimal value function Q*, α(0 < α < 1) is the learning factor, which controls the update speed of the action. The smaller the α value is, the larger the search space of the algorithm is, and the better the stability of the algorithm is. Q-learning algorithm always selects the action with the highest Q value in the current state, which is called greedy strategy

The disadvantage of Q-learning is that it is easy to converge to partial optimum, but not to global optimum. This is because the final Q value is not the optimal solution, so there are errors. In order to eliminate the errors, a tracking algorithm 25 based on probability distribution is used to construct a dynamic selection strategy. In this strategy, the probability of each action selected in the initial state is equal, but with the continuous iteration of the action value function, the higher the probability of action selected in the higher Q value is, and the action with higher probability is taken as the initial action in the next moment. The probability iteration formulas of this strategy are shown as follows:



where the value of
Design of Q-DRNN controller
In order to improve the control performance of BLDCM, the Q-DRNN controller is designed based on the combination of the strong search ability of Q-learning and the advantages of DRNN, such as its own recursive loop structure, dynamic mapping ability and adaptability to time-varying. The control structure is shown in Figure 5.

Q-DRNN controller for BLDCM.
In this paper, the iteration of Q value table is mainly carried out by the following formula:

where
For the given system, its performance index function is defined as

where C and D are weight matrix, m is the upper limit of the number of iterations,
The connection weights

where
In the process of Q-learning, the momentum factor correction term
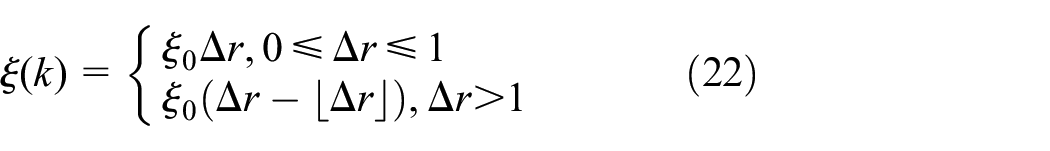
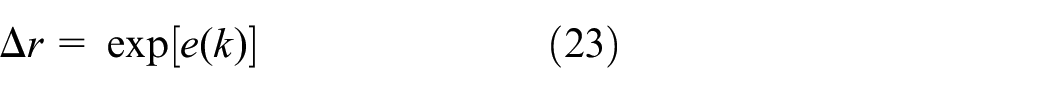
where
Calculate

Similarly,
For

It can be seen from equation (5) that for step k control

For all Q-learning, there is always a reward and punishment function. Here, the introduced reward and punishment function is related to the input of the system. Since the ideal goal of system error

where k1, k2 represents the lower limit and the upper limit of the integral.
After determining the reward and punishment function R(k), input state set and control action set, the online self-learning and dynamic optimization of Q-DRNN controller can be carried out according to the iterative formula of the algorithm. The steps are as follows:
Select the structure of Q-DRNN in advance, that is, select the number of input layer nodes and hidden layer nodes, randomly generate the initial values
After sampling, Yd(k) and y(k) are obtained, and e(k)=Yd(k)-y(k) is calculated; action a(k) is selected from action set by action probability distribution.
Normalize
According to formula (6), the output of Q-DRNN output layer is calculated, and the control law calculated at this time is
A reward signal R(k) is obtained from equation (27), and the Q value of Q-DRNN in this state is calculated.
Calculate the greedy action ag(k) according to equation (15).
Modify the weights
Update the action probability distribution according to equation (16–18).
Let k = k+ 1, return (2), until Qk converges to the optimal value function Q*.
Simulation results
In order to further verify the performance of Q-DRNN in the control system of BLDCM, the system model is established by using Matlab/Simulink toolbox, and the controllers under different operating conditions are simulated and compared with NNPID, 23 Online-RBFNN, 24 ALO-RFNN 25 and QLRNN. 31 The specifications of BLDCM are shown in Table 1.11,12,33
Specifications of BLDCM drive.

The given input speed of BLDCM is 3000 r/min, the number of DRNN nodes is 3-6-1, the number of hidden nodes is determined by a large number of simulation experiments, the initial weight is the random number of [–0.5,0.5] interval, the learning rate η = 0.05,
Speed and torque response with the absence of load
First, the tests are performed under the condition of absence of load, the sample time of the control system is Ts = 0.5×10−5 s. The speed response comparison curve and torque response comparison curve are shown in Figure 6(a) and (b) respectively.

Speed and torque response with no load: (a) comparison of speed response and (b) comparison of torque response.
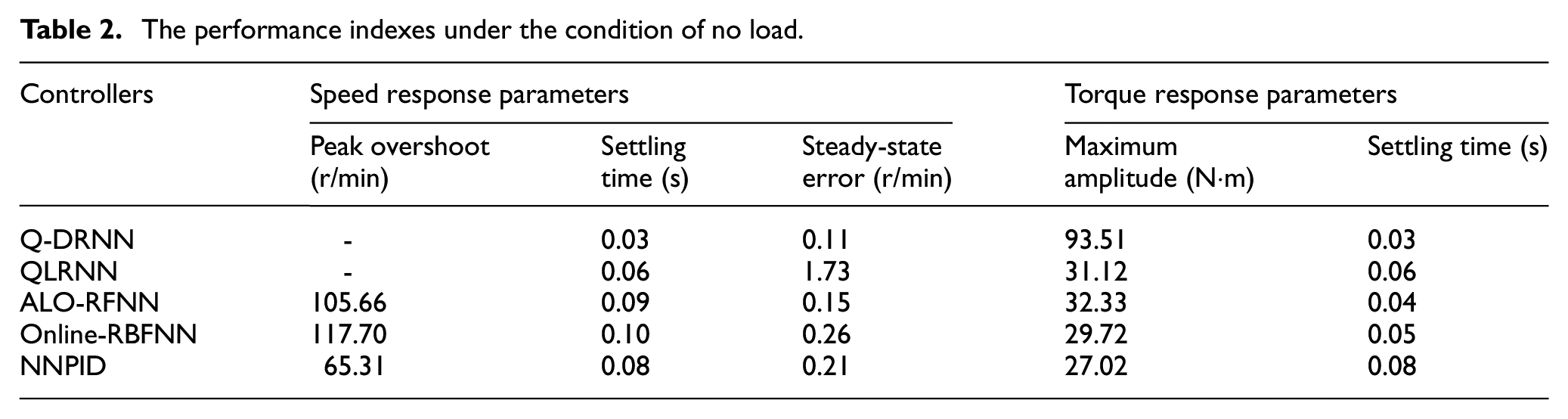
From Figure 6(a), it can be seen that the peak overshoot is 105.66, 117.70 and 65.31 r/min for the ALO-RFNN controller, the Online-RBFNN controller and the NNPID controller during the transient period, while no obvious overshoot occurs for QLRNN and Q-DRNN. During the steady-state period, the Online-RBFNN control algorithm has the longest setting time 0.10 s and Q-DRNN has the shortest setting time 0.03 s. Moreover, Q-DRNN has the lowest steady-state error 0.11 r/min. From the torque response curve in Figure 6(b), it can be seen that the Q-DRNN controller has the highest amplitude, but it recovers to a stable state at the fastest speed. Although the amplitude of the QLRNN controller, the ALO-RFNN controller and the Online-RBFNN controller is lower than that of the Q-DRNN controller, their chattering phenomenon is obvious, the setting time is longer, and the setting time of the NNPID controller is the longest. Specific performance indexes are shown in Table 2. Based on the comparison and analysis of the above controllers, it can be concluded that the control effect of Q-DRNN controller is better than that of other controllers.
The performance indexes under the condition of no load.
Speed and torque response with load
Next, the control system of BLDCM is operated with sudden change in load conditions to determine the advantages of Q-DRNN controller. The input speed of the control system is still 3000 r/ min, the sample time of the control system is also Ts = 0.5×10−5 s, and a load of 2 Nm is applied to the system at 0.2 s. Figures 7(a) and 8(b) respectively show the speed response curve and torque response curve under the condition of various loads.

Response curve under varying load conditions: (a) comparison of speed response and (b) comparison of torque response.

Response curve under varying set speed conditions: (a) comparison of speed response and (b) comparison of torque response.
As can be seen from Figure 7(a) that when the load is applied at 0.2 s, ALO-RFNN controller, Online-RBFNN controller and NNPID controller have obvious oscillation phenomenon, and only after a period of time can they recover stable, QLRNN controller also has some fluctuations, and finally it recovers stable. The minimum steady-state error, the minimum peak undershoot, and overshoot of Q-DRNN are 0.51 r/min, 0.83 r/min, and 0, respectively. Moreover, the recovery time of Q-DRNN is 0.02 s, which is the shortest. As can be seen from Figure 7(b) that at 0.2 s, the ALO-RFNN controller has the largest amplitude and only after a period of time can it recover to be stable, and the Q-DRNN controller has the smallest amplitude and is closer to 2 Nm. Therefore, Q-DRNN controller is better than other controllers. This also strongly reflects the anti-interference and robustness of the Q-DRNN Controller under the condition of various loads. The performance indexes in this condition are shown in Table 3.
The performance indexes under the condition of various loads.

Speed and torque response with various set speed
Finally, the control performance of Q-DRNN controller is verified under the condition of sudden change of speed, the sample time of the control system is Ts = 0.5×10−6 s.When the system runs to 0.2 s, the speed is reduced from 3000 r/min to 2500 r/min. The speed response comparison curve and torque response comparison curve in this state are shown in Figure 8(a) and (b) respectively.
As can be seen from Figure 8(a) that when the speed changes suddenly at 0.2 s, oscillation occurs for ALO-RFNN, Online-RBFNN and NNPID controllers. QLRNN controller has no obvious undershoot, after a period of time, it is stable. Q-DRNN controller has the minimum recovery time 0.03 s and the minimum steady-state error 0.56 r/min. As can be seen from Figure 8(b) that at 0.2 s, the amplitude of Q-DRNN controller is large, but it recovers to a stable state at the fastest speed. Although the amplitude of other controllers is lower than that of Q-DRNN controller, the stability time is longer. Combining the above performance indexes, it can be concluded that the control effect of Q-DRNN controller is better than that of other controllers. The performance indexes in this condition are shown in Table 4.
The performance indexes for varying set speed condition.

From the above three groups of simulation results under different control conditions, it can be concluded that all controllers can correctly track the set speed. However, the proposed Q-DRNN controller is superior to other controllers in terms of steady-state error, setting time and recovery time. Therefore, the Q-DRNN controller is proved to have better adaptive ability, anti-interference ability and strong robustness.
Conclusion
A novel control strategy called Q-DRNN by using Q-learning optimized DRNN is proposed in this paper for BLDCM to achieve better performance of speed and torque control. Q-DRNN obtains the abilities of self-learning and online correction by modifying the weight momentum factor and optimizing the key weight of DRNN, and then the control effectiveness is greatly improved. Under no load conditions, Q-DRNN is proved to have the minimum overshoot, the shortest recovery time and the minimum steady-state error of speed response whose values are 0 r/min, 0.03 s, 0.11 r/min respectively, as well as the shortest recovery time of torque response. Under with load conditions, Q-DRNN has the minimum peak undershoot 0.83 r/min, the shortest recovery time 0.02 s, the minimum steady-state error 0.51 r/min and the minimum amplitude 0.60 r/min. Under different set speed conditions, Q-DRNN has the shortest recovery time and the minimum steady-state error compared with other controllers. Therefore, Q-DRNN is significantly superior to other control methods.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work supported by Capital construction funds in the provincial budget of Jilin development and reform commission in 2019 (grant no 2019C054-4); National nature fund project (grant no 61803044); Science and technology development project of Jilin Province (grant no 20190802005ZG); Science and technology plan project of Jilin Province (20200201009JC).