
Abstract
Bearings are the core components of ship propulsion shafting, and effective prediction of their working condition is crucial for reliable operation of the shaft system. Shafting vibration signals can accurately represent the running condition of bearings. Therefore, in this article, we propose a new model that can reliably predict the vibration signal of bearings. The proposed method is a combination of a fuzzy-modified Markov model with gray error based on particle swarm optimization (PGFM (1,1)). First, particle swarm optimization was used to optimize and analyze the three related parameters in the gray model (GM (1,1)) that affect the data fitting accuracy, to improve the data fitting ability of GM (1,1) and form a GM (1,1) based on particle swarm optimization, which is called PGM (1,1). Second, considering that the influence of historical relative errors generated by data fitting on subsequent data prediction cannot be expressed quantitatively, the fuzzy mathematical theory was introduced to make fuzzy corrections to the historical errors. Finally, a Markov model is combined to predict the next development state of bearing vibration signals and form the PGFM (1,1). In this study, the traditional predictions of GM (1,1), PGM (1,1), and newly proposed PGFM (1,1) are carried out on the same set of bearing vibration data, to make up for the defects of the original model layer by layer and form a set of perfect forecast system models. The results show that the predictions of PGM (1,1) and PGFM (1,1) are more accurate and reliable than the original GM (1,1). Hence, they can be helpful in the design of practical engineering equipment.
Keywords
Introduction
Bearings are among the components most commonly used and most prone to failure in marine propulsion shafting. Their working state can directly affect reliable navigation of the ship. Accordingly, accurate early warnings of bearing degradation can help decision-makers to formulate appropriate measures to avoid accidents. Liu 1 proposed a bearing life prediction method based on the Weibull proportional hazard model (WPHM). This method predicts the root mean square (RMS) and kurtosis of bearing vibration signals, which can represent various failure modes of bearings, 2 and uses them as covariates in the WPHM to predict the remaining lifetime of the bearing. Therefore, the establishment of a robust and accurate model to predict the characteristic quantities of bearing vibration, to improve the prediction of bearing life, has become a critical task. Many prediction methods based on big data have been studied and applied, including neural networks and support vector machines. However, the implementation of these methods requires a large amount of initial data as support. Moreover, because of the working environment of marine propulsion shaft bearings, it is not realistic to obtain a large amount of bearing vibration data. Therefore, a method that can predict data from a small amount of initial data is crucial.
The gray theory was first proposed by Professor Deng 3 in 1982. The gray model (GM (1,1)) is the most important model in gray prediction theory and has led to many achievements in prediction. Different from the general prediction methods based on a large amount of historical data, GM (1,1) can find internal rules from a small number of data sequences containing random numbers and random disturbances. This allows more practical analyses and predictions by starting from the signal itself. Although GM (1,1) has been widely adopted in recent years, its predictive performance needs to be further improved. Optimization and upgrading operations of GM (1,1) have been carried out by many experts and scholars worldwide. These operations can be roughly divided into three types. In the first type, algorithms are used to perform optimization calculations on the parameters of GM (1,1) itself to improve the prediction accuracy.4–6 In the second type, the data processing mode of the model itself is improved according to different forms of the sequence of objects (monotone, oscillation, dispersion, etc.).7–10 In the third type, GM (1,1) is combined with another reliable theoretical model to overcome the shortcomings of GM (1,1) and improve its prediction accuracy.11–13 However, these strategies have some shortcomings. In the first strategy, the parameters to be optimized are often not fully considered, and the influence of historical errors on subsequent data prediction is not considered. The second strategy has poor generalization ability and can only be used for special data sets. The third strategy does not integrate the advantages of the first and second strategies and does not systematically combine the existing optimization methods.
Based on the above issues, we address the following points in this study:
Because the final mathematical prediction model of GM (1,1) involves three parameters (initial conditions
Considering the influence of historical relative errors generated by unfitted unit prediction data on the final prediction value in the process of sequential training of GM (1,1), the influence is fuzzy and cannot be expressed by a quantitative relation. 15 Therefore, we introduce the theory of fuzzy mathematics to deal with the historical error generated by GM (1,1) prediction.
The object studied by the system is always developing and changing, and the effects of external factors on the system are uncertain. The Markov model is suitable for the prediction of random state transition processes in economics, passenger, desert, microorganism, and other objects with irregular development.16–20 Therefore, the Markov model is combined with GM (1,1) to compensate for the defects of gray prediction theory in the processing of data with large jump. 21
Therefore, GM (1,1) is selected in this study as the basis of the combined model. First, the PSO algorithm was used to iteratively optimize the three parameters of GM (1,1) to form PGM (1,1). Second, fuzzy mathematical theory was used to fuzzy-correct the prediction data error of PGM (1,1). Finally, by combination with the Markov model to predict the next data state, a new combination prediction model called the PGFM (1,1) was developed. The new combined model can be used to predict the RMS data of bearing vibrations. The data prediction results show that the new model has better prediction ability of the development trend of ships bearing vibration signal characteristic quantities and can provide reliable data for relevant decision-makers.
The rest of this article is organized as follows: Section “Methodology” introduces relevant algorithms and theories involved in PGFM (1,1), including GM (1,1), PSO algorithm, fuzzy mathematical theory, and Markov model. Section “PGFM (1,1) combined model” describes the specific calculation flow of the PGFM (1,1) method. An empirical study is described in section “Empirical study”. Finally, the corresponding discussions and conclusions of this study are given in section “Conclusion”.
Methodology
In this section, all relevant models and theories involved in the newly proposed PGFM (1,1) are introduced, including the gray prediction model GM (1,1), PSO algorithm, fuzzy mathematical theory, and Markov model.
Standard GM (1,1) model
GM (1,1) has a significant effect on the data prediction of the gray system. Its features of simple modeling, small demand for data samples, and easy solution have led to its application in an increasing number of engineering fields. 22
The calculation process of GM (1,1) is shown in Figure 1.

Calculation flow of traditional GM (1,1).
Step 1: Set the original data sequence to

Step 2: The generation number of adjacent values based on the first-order accumulation generation sequence is established as follows

where

Step 3: The gray differential equation of the gray modeling is defined as

where a is the development coefficient and b is the gray action quantity, both of which are the parameters to be calculated.
Into matrix representation

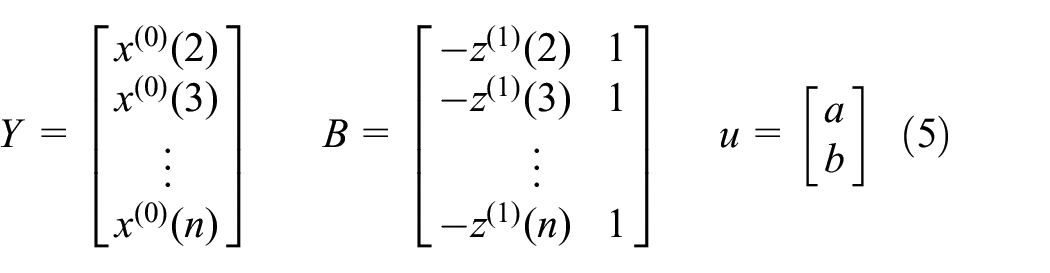
Parameters a and b are obtained by least-square fitting as follows

Step 4: We express the white equation (shadow equation) corresponding to the gray differential equation of the gray prediction model as follows

Solving equation (7), we obtain

Then, we express equation (8) in discrete form as follows

Step 5: Finally, the predicted value of GM is obtained by subtracting the previous number from each layer as follows

PSO
PSO is essentially a random search algorithm and belongs to the area of emerging intelligent optimization technology. It is an efficient parallel search method with good generality and a reasonable number of preset variables. Its working principle is shown in Figure 2.

Updating mode of particle swarm location in each generation.
In the PSO, the potential solution of each optimization problem is referred to as “particle,” whose fitness is determined by the optimized function. Each particle has a “velocity,” which determines its optimal direction and distance; the solution is obtained by following the current optimal particle. The main operation of the algorithm is to update the particle velocity and position according to equations (11) and (12) and gradually converge to the ideal position of the objective function 23


In equations (11) and (12), c is the learning factor (acceleration constant), r is a uniformly random number [0,1], and w is the inertia weight.
The meanings of the terms of equation (11) are briefly described in Figure 2. The first term represents the inertia, which indicates the tendency of a particle to maintain its previous state of motion; the second term represents the self-cognition, which indicates the tendency of a particle to move toward its best position according to historical data; and the third term represents the social cognition, which indicates the tendency of particles to cooperate with each other to move back to the optimal group or adjacent location.
Fuzzy mathematical theory
The concept of fuzzy recognition was proposed long before the appearance of fuzzy mathematics. Its objective is to determine the type of recognized object on the premise that various standard types are known. Fuzzy recognition consists of three steps: extracting features, establishing membership functions, and establishing recognition criteria.
24
We define the value range of the data as U and conduct fuzzy state divisions
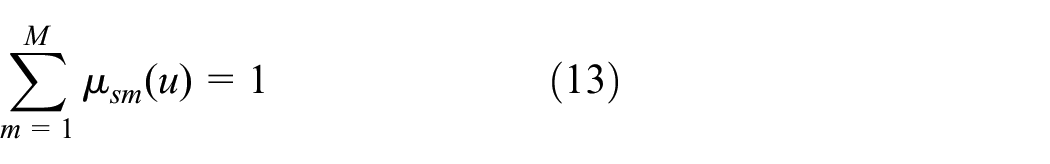
where
Markov
The core of Markov prediction theory is the establishment of the state transition probability matrix

PGFM (1,1) combined model
The standard GM (1,1) has some error in the data fitting prediction, which is mainly attributed to the insufficient accuracy and rationality of parameter selection in the prediction model. Accordingly, a parameter optimization method (the PSO algorithm) is introduced to iteratively optimize the “problem parameters” in the standard GM (1,1) to form the PGM (1,1). Subsequently, because there remain relative errors of different sizes between the predicted and actual values of PGM (1,1) and because the influence of historical errors on subsequent data prediction cannot be expressed quantitatively, fuzzy mathematical theory is introduced to deal with the influence of historical errors. Finally, because GM (1,1) is suitable for sequences with obvious changing trends and has a poor effect on data with large random volatility, a Markov model is applied for the prediction of state transition behavior of random processes, which makes up for the defect of GM (1,1), introduces the complementary advantages of the two theories,25,26 and forms the PGFM (1,1). The PGFM (1,1) workflow is shown in Figure 3.

Flowchart of PGFM (1,1).
The specific operations of PGFM (1,1) are as follows:
Step 1: The standard GM (1,1) predictive mathematical model is established according to the procedure described in section “Standard GM (1, 1) model.”
Step 2: PSO is used to optimize the initial conditions
Step 3: The relative errors between the actual data and the predicted data fitted by PGM (1,1) are calculated to obtain the data error sequence
Step 4: The value range
Step 5: The fuzzy state transfer coefficient from state

Step 6: The fuzzy state transition frequency


Step 7: With the final time variable
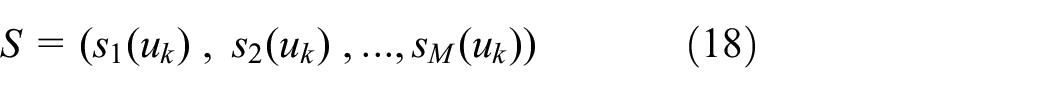
Step 8: The fuzzy vector B and fuzzy correction


where
Step 9: Finally, the predicted value of the next state after error correction is obtained as follows

Empirical study
Accurate and reliable prediction of the bearing vibration characteristic quantity provides data that support decision-makers to develop both maintenance plans and early warnings of the deterioration of the bearing running state, preventing unnecessary economic losses. Therefore, the development of an accurate, efficient, and robust forecasting method is important. In this section, the results of the predictive analyses performed with GM (1,1), PGM (1,1), and PGFM (1,1) with the same set of data are reported, and their advantages and disadvantages are discussed.
GM (1,1) analysis
The RMS of bearing vibration signals is usually considered an indicator of bearing life, because it can comprehensively and accurately reflect the trend of bearing life degradation. In addition, the traditional gray prediction model has been widely used in the field of engineering data prediction. To verify the effectiveness of GM (1,1) in the prediction of the bearing decay performance index, we consider 10 sets of data (bearing vibration signals’ RMS) from the full-lifecycle degradation experiment of bearings reported in Liao et al. 2 In this experiment, an acceleration sensor with model DYTRAN 3035B, sensitivity of 100 mV/g, and measuring range of 50 g was used to conduct signal sampling at equal time intervals in a sampling environment with a sampling frequency of 25.6 kHz and a sampling time of 0.1 s through the data acquisition card NIDAQ. The RMS values of 10 sets of bearing vibration signals were obtained as follows

The RMS values of the 10 sets obtained were 0.3234, 0.3715, 0.5032, 0.5982, 0.7145, 0.9035, 1.0385, 1.0772, 1.3093, and 1.5239. The first nine sets of data were taken as the original input data of GM (1,1), and the 10th set was used for model validation. Based on the operation steps of GM (1,1), gray modeling was carried out to obtain the gray prediction mathematical model

The mathematical model was used for data prediction and fitting, and the obtained data were compared with the experimental data, as shown in Table 1. It can be seen that the GM can be applied to the prediction and calculation of the RMS of the vibration signals, which are indicators of bearing decay. However, its prediction effect is not sufficient and produces large errors.
RMS data predicted by traditional GM (1,1).

RMS: root mean square; GM: gray model.
PGM (1,1) calculation and analysis
The traditional method for the calculation of the parameters of GM (1,1) is too simple, and its accuracy, reliability, and robustness are insufficient. In this section, the “two-step” iterative optimization of the initial conditions
PGM (1,1) calculation
Equation (10) is the final prediction expression of the data of GM (1,1). Through observation, it can be concluded that this equation only contains three parameters (initial conditions
The minimum sum of the squares of the difference between the error of the fitting data and the actual data is taken as the fitness function of PSO:
PSO algorithm parameter settings.

In this environment, the optimization calculation is carried out as follows:
Optimization order 1: With

Optimization order 2: With the original parameters of the traditional GM a and b, PSO is performed to iteratively optimize the initial condition

PGM (1,1) analysis example
The values of the optimized gray prediction models are predicted using equations (24) and (25). The fitting data results are shown in Table 3, and the comparison of the effect of the errors is shown in Figure 4
Results obtained with different optimization orders.

RMS: root mean square; GM: gray model.

Comparison diagram of model optimization errors.
From Table 3 and Figure 4, it can be seen that the two optimization orders have some effect on the parameter optimization of the traditional GM (1,1). Furthermore, the optimization effect of order 2 is significantly greater than that of order 1. The reasons for this are discussed in the remainder of this section.
The optimization order 1 is used to obtain
With optimization order 2, the parameters a and b of the traditional GM (1,1) are used to optimize the initial condition
PGFM (1,1) calculation and analysis
The influence of the relative error between the predicted and actual values of PGM (1,1) on the subsequent data prediction is fuzzy. In addition, the gray theory cannot process large jump data efficiently. Therefore, the fuzzy mathematical theory was considered to deal with the historical error, and the shortcomings of the traditional GM (1,1) were compensated by introducing the Markov model; the combination of the traditional GM (1,1) with the Markov model is referred to as the PGFM (1,1).
PGFM (1,1) calculation
To verify the superiority of the combined model, a prediction analysis was carried out for the same set of data. The PGM (1,1) model prediction error sequence is 0, 0.1548, 0.0258, 0.0102, −0.0099, −0.0833, −0.0664, 0.0537, and 0.0149, as listed in Table 3. The relative error range




Relative error fuzzy state graph.
The fuzzy state coefficient of each error data is calculated based on the relative error and membership function, and the results are shown in Table 4.
Fuzzy state coefficients.

The state transition matrix P is calculated from the data in Table 4 using equations (15)–(17)


Given the fuzzy vector
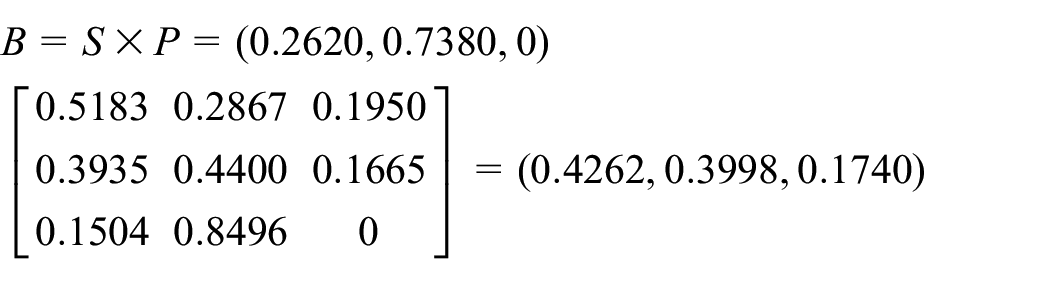
According to equation (20), the relative error’s fuzzy correction

Using

PGFM (1,1) analysis example
The measured value of the 10th group measured in the experiment is 1.5239. With the traditional GM (1,1), the data of the 10th group were predicted to be 1.5621 with a relative error of 2.51%. With the PGM (1,1) model, the data of the 10th group were predicted to be 1.555, with a relative error of 2.09%. Finally, by combining PGM (1,1) with PGFM (1,1), the state of the 10th group of data was predicted to be 1.5317 with a relative error of 0.51%. It can be seen from the fitting effect and prediction accuracy of the same group of data shown in Figures 6 and 7 that with the gradual improvement of the traditional GM, the working accuracy of the newly formed composite model PGFM (1,1) is significantly higher and is closer to the engineering test data accuracy.

Data fitting effect of groups 8–10.

Comparison of the 10th group of data errors.
Nevertheless, the proposed PGFM (1,1) also has disadvantages in the calculation process. As PGFM (1,1) involves many steps, the operation process is relatively complex. The combined model is composed of a GM (1,1) and a one-step Markov state transition matrix, so it can accurately predict only the next state value. Although the prediction accuracy is improved, its computational complexity is high, and its scalability is insufficient.
Discussion
In section “Empirical study,” GM (1,1) is modified to PGM (1,1), which, in turn, is modified to PGFM (1,1) to predict and analyze the RMS vibration data of the full cycle life of the same set of bearings. The results showed that with the gradual improvement of the prediction method, the prediction accuracy of the 10th group of data as the validity test of the prediction model is gradually improved. Accordingly, it is proved that the proposed model is more suitable for the prediction of characteristic quantities of bearing vibration signals and can provide a powerful database for the accurate calculation of bearing residual life based on the WPHM.
GM (1,1) is less computationally expensive, and its predicted data can reach the basic standard. Therefore, it is suitable for the prediction of components’ characteristic quantities with low accuracy requirements. Compared with GM (1,1), PGM (1,1) increases the parameter correction step of the PSO algorithm, improves the prediction accuracy, and can meet the requirements of more engineering applications. PGFM (1,1) model is complex, and its prediction accuracy is higher than that of GM (1,1) and PGM (1,1). Therefore, this model is more suitable for predicting characteristic quantities of engineering structural components with high precision requirements. In general, with the modification of GM (1,1) to PGM (1,1) and then to PGFM (1,1), the accuracy, effectiveness, reliability, and applicability of the model become higher, but its complexity increases, as shown in Figure 8.
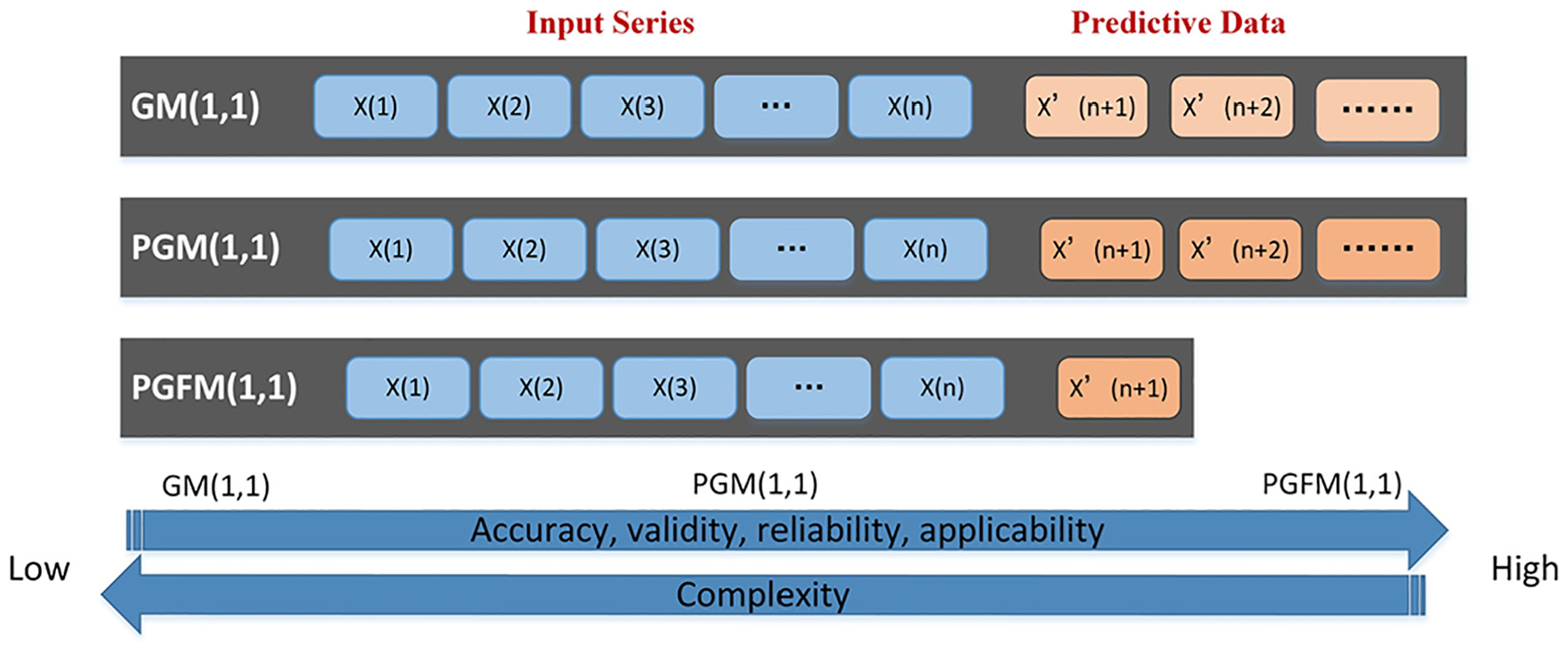
Diagram of the prediction models’ characteristics.
Considering the disadvantages of PGFM (1,1) and the advantages of PGM (1,1), we proposed a combination of the two models. First, PGM (1,1) can be used to predict the parameters that can represent the remaining lifetime components before the component fails. Then, the same parameters can be predicted with PGFM (1,1) for confirmation. The latest collected state data can be predicted by PGFM (1,1) to obtain more realistic prediction results.
Conclusion
Effective prediction methods are important to determine the running state of bearing equipment and formulate effective maintenance strategies. Although GM (1,1) is simple because it relies on a small amount of data for prediction, its prediction accuracy remains unsatisfactory. In this study, we analyzed the shortcomings of the original GM (1,1) in the prediction of parameters that can represent the state of bearings of marine propulsion shafting. Based on the traditional gray theory and combining the advantages of PSO, fuzzy mathematical theory, and Markov models, a new combined prediction model named PGFM (1,1) was proposed.
This proposed model has the following advantages: (1) it can be used to explore the internal law of time series and state transition sequence data and predict the future state; (2) it has a higher ability to predict the RMS vibration characteristics of bearings, which can guide maintainers and provide information on the future running state of the bearing; and (3) although PGFM (1,1) involves many theories, its operation is easy to understand and convenient for the compilation of specific programs; therefore, it can be easily applied to practical problems in many engineering fields.
The limitation of PGFM (1,1) is its applicability. (1) If the input data are not regular, the prediction accuracy can be poor. (2) Because PGFM (1,1) is a one-step Markov matrix established with a small amount of data, it is unable to predict the subsequent multi-set of data. However, PGM (1,1) can be used to predict multiple sets of dat. (3) Furthermore, the model is suitable for the prediction of one-dimensional time series, but not for multivariate or high-latitude data.
In future research, other theories can be considered for the modification of GM (1,1) to simplify the operation steps and improve the multi-step prediction ability.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Zhejiang Provincial Natural Science Foundation of China under Grant no. LY20E090002 and Zhoushan City Science and Technology Planned Project under Grant no. 2018C21018.