
Abstract
Rolling bearings are the vital components of rotary machines. The collected data of rolling bearing have strong noise interference, massive unlabeled samples, and different fault features. Thus, a deep transfer learning method is proposed for rolling bearings fault diagnosis under variable operating conditions. To obtain robust feature representation, the denoising autoencoder is used to denoise and reduce dimension of unlabeled rolling bearing signals. For those unlabeled target domain signals, a feature matching method based on multi-kernel maximum mean discrepancies between source domain and target domain is adopted to get enough labeled target domain samples. Then, these rolling bearing signals are converted to multi-dimensional graph samples and fed into a convolutional neural network model for fault diagnosis. To improve the generalization of convolutional neural network under variable operating conditions, we combine model-based transfer learning with feature-based transfer learning to initialize and optimize the convolutional neural network parameters. The effectiveness of the proposed method is validated through several comparative experiments of Case Western Reserve University data. The results demonstrate that the proposed method can learn features adaptively from noisy data and increase the accuracy rate by 2%–8% comparing with other models.
Keywords
Introduction
Rolling bearings have been widely used in rotary machines. With long time and high-load operation, the rolling bearings are prone to injury and account for more than 50% of failures. 1 Thus, the fault diagnosis of rolling bearing plays a vital role in ensuring the effective operation of the mechanical system. The signals of rolling bearings include acoustic, motor current, vibration, and speed. 2 As vibration signals are usually easy to measure and can provide abundant dynamic information, it is commonly used in mechanical fault diagnosis. 3 Traditional machine learning (ML) algorithms have been widely employed in machine fault diagnosis, including artificial neural network (ANN), support vector machine (SVM), Bayesian network, and hidden Markov model (HMM).4–7 Nevertheless, those traditional methods require extensive domain expertise and prior knowledge, and the feature extraction is also limited in existing features or evaluation criteria. Thus, it is difficult to build a suitable model for complex fault diagnosis under variable operating conditions. 8
As a hotspot of ML research, deep learning (DL) models can learn multiple abstract representations of big data. 9 With the capacity of automatically extracting complex features, DL models have great potential to overcome the deficiency of traditional ML mentioned above. Several prevailing models, such as convolutional neural network (CNN), denoising autoencoder (DAE), deep belief network (DBN), and recurrent neural network (RNN), have been proposed.10–13 These DL models have great promise in many practical applications, including image recognition, natural language processing, and machine health monitoring.14–17 In the family of DL models, DAE is unsupervised learning algorithm based on an autoencoder (AE), while CNN is a supervised learning method. These two methods have been widely used because of their capabilities of learning complex features automatically from big data.11,18 However, they only perform well on the abundant labeled data that are generated under the same operating conditions. To overcome the problem of lacking labeled signals and misclassification under variable operating conditions, the demand of a fault diagnosis method with great generalization ability is generated.
Transfer learning (TL) is an important means to solve the issue of collecting enough labeled data in the ML field.
19
TL discovers the related features in the source task and obtains the feature mapping function
The main function of MTL is to improve the efficiency of the operation, while it is subject to limited upgrading generalization performance. FTL can use the features learned from the SD for TD analysis, but it requires a high similarity between the source and the target domains, and the distribution differences between two domains have a great influence on the classification accuracy.
Above all, a deep TL method is proposed based on CNN, DAE, and TL methods. DAE is used to reduce the sample dimension and noise interference of vibration signal. The vibration signals are transformed into multi-dimensional samples and brought into CNN for fault diagnosis. In order to improve the generalization ability of the CNN model, TL methods are used to initialize and optimize the model parameters. On the one hand, the MTL method is used to initialize the model parameters. On the other hand, through the error discrimination of the features in the source and target domains, the sample labels are initially obtained and applied for DL, so as to improve the generalization ability of FTL in the case of high distribution differences. The main contributions of this article lie in the following aspects:
The DL methods DAE and CNN are combined to process the labeled and unlabeled rolling bearing data with added noise.
The multi-kernel maximum mean discrepancy (MK-MMD) is adopted to measure the feature difference between SD and match the TD with the label of the SD.
FTL and MTL are combined to optimize the DL model for fault diagnosis of rolling bearings under various working conditions.
The rest of this article is introduced as follows: the theoretical background of DAE, CNN, TL methods is discussed in section “Theoretical background.” Section “The proposed model” presents the structure of the proposed fault diagnosis model, and related experiments are conducted to illustrate three parts of the model. Finally, the discussion and conclusion of this work are given in section “Discussion” and section “Conclusion.”
Theoretical background
In this section, we will introduce the model structure of DAE and CNN, and the definition of MK-MMD, which is usually used for feature-based migration learning.
DAE
In unsupervised learning, the most typical type of neural network is AE, which aims to get a dimensionality reduction feature



where

Structure of an autoencoder with a single hidden layer.
Traditional automatic encoders only rely on minimizing the error between input and reconstructed signal to obtain the implicit layer feature representation of input, but this training strategy may lead to over fitting and cannot guarantee the extraction of the essential features of data. The DAE with noise injection strategy enables to learn more about the essential characteristics of input data.
DAE accepts lossy data

The loss function diagram of denoising autoencoder.
CNN
CNN is one of the prevalent models for DL. Figure 3 illustrates the architecture of a typical CNN, which is a multi-stage neural network that contains many data processing layers, such as convolutional, activation, and pooling layers. The affine transformation is implemented as “Affine layer.” CNN uses convolutional layers and activation layers to extract features from the input, while the pooling layer plays a role in downsampling to make the network extract higher level features from a larger scale input. After several stacked layers of convolution and pooling, abstract features are extracted to make the classification. 29
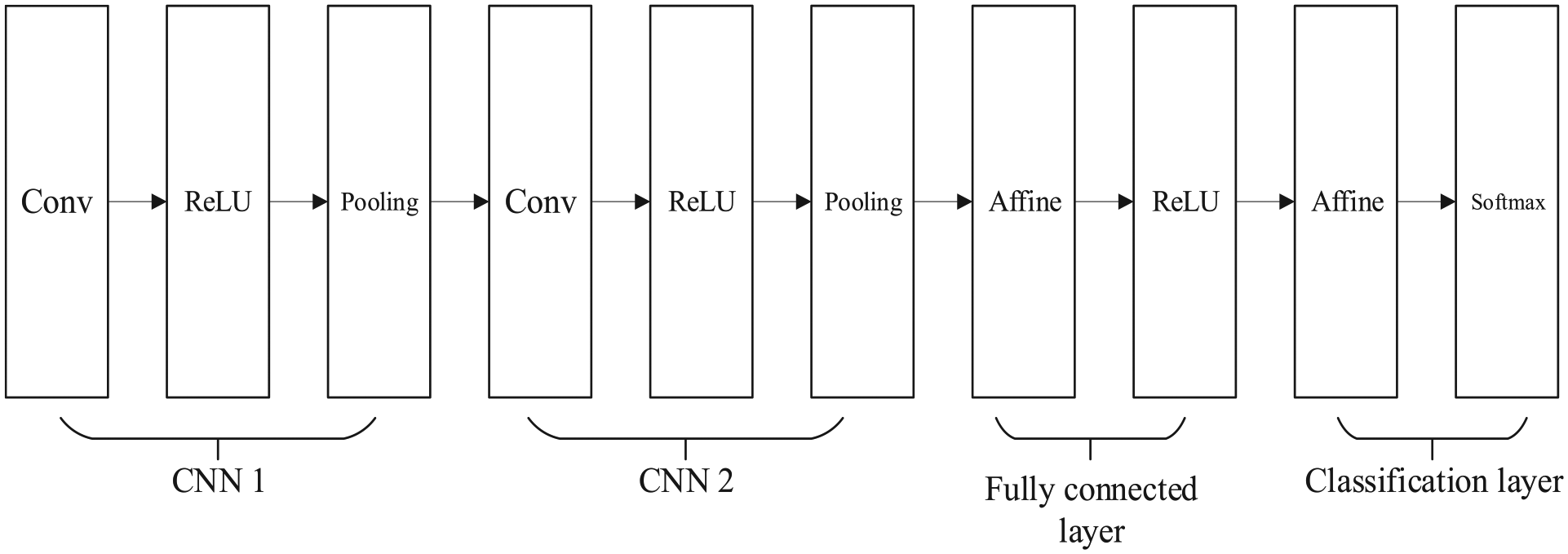
Architecture of a typical CNN.
The convolutional layers contain a number of filters, which convolute the input from the previous layer through a set of weights and compose a feature output, generally called as a feature map. The output of convolutional layers


where
The main purpose of the pooling layer is to compress the image and reduce the parameters by subsampling without affecting the image quality. The pooling functions include max pooling, mean pooling, or weighted pooling. The most commonly used max pooling function in CNN can be described as 31

where p is the output of the pooling layer; S is the pooling block size. The output will be S times smaller in each spatial dimension.
After multiple layers of convolution and pooling operations, the output is expanded to a fully connected layer. The softmax function is selected to achieve classification result. Assuming the classification task has K-label, the output of the softmax function can be calculated as follows 32
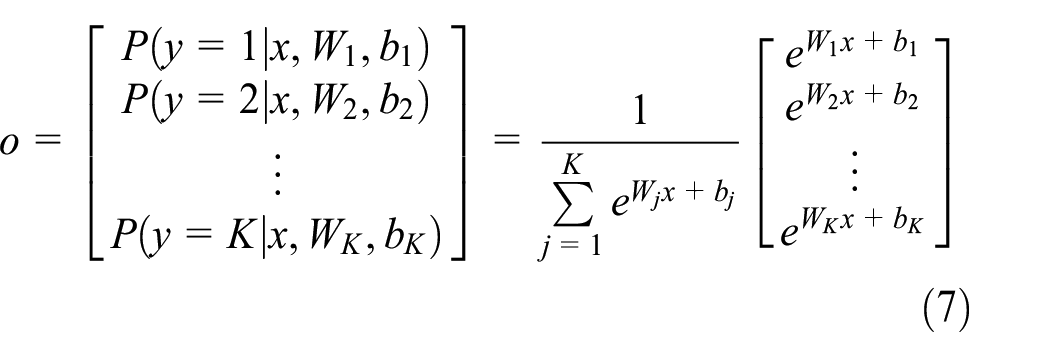
where w is the weight matrix; b is the bias matrix; and o is the output of CNN. w and b can be optimized by stochastic gradient descent (SGD) methods. 33
MK-MMD
The main challenge of TL is that there are no enough labeled samples in the TD. To resolve the problem, many researchers try to limit the deviation between the source and target domains. In this article, the MK-MMDs are applied in the proposed model to measure the error between the source and target domains.
Assume that

when
The multi-kernel k, which is defined as convex combinations of
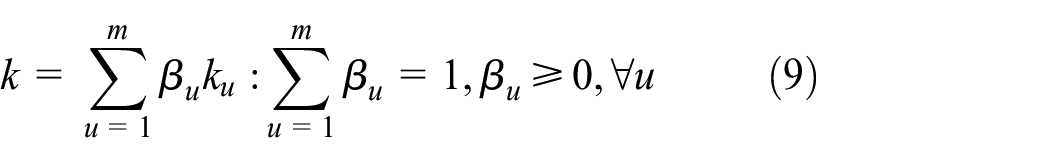
where
The proposed model
In this article, the proposed deep TL model is the combination of DL models and TL methods. The DL models contain DAE and CNN methods, while the TL methods include feature-based and model-based TL. As shown in Figure 4, the deep TL model includes three steps as follows: data preprocessing, feature matching, and fault diagnosis. First, the DAE model is used to denoise and reduce dimension of unlabeled rolling bearing signals. Second, the MK-MMD originating from FTL is used for feature matching of the source and target domains. Third, a CNN model is built for fault diagnosis of the SD, and initial layers in CNN can be transferred for fault diagnosis of the TD. Then, the MK-MMD of the fully connected layer between the source and target domains is added in loss function to fine-tune the CNN model. Based on the above principles, a deep TL model for rolling bearing fault diagnosis under variable operating conditions is established.

The structure of proposed model.
Data processing
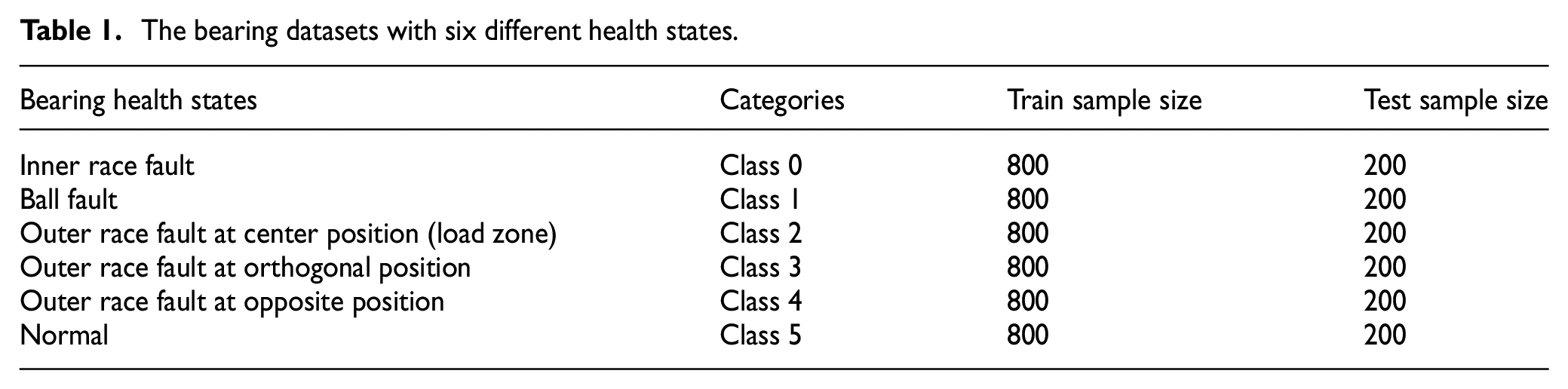
In this article, rolling bearing datasets of Case Western Reserve University are used for experiment. 36 Figure 5 shows the test stand of the bearing datasets. Figure 6 describes the structure of rolling bearing, which is composed of inner race, outer race, and ball. The bearing datasets with six different health states are listed in Table 1. In addition, the samples are randomly divided into training set and testing set according to the ratio of 4:1, and the cross-validation of training set is used to evaluate model performance.

Test stand for rolling bearings. 37

The structure of rolling bearing.
The bearing datasets with six different health states.
As shown in Figure 7, the bearing datasets contain vibration signals of multiple time series. In the real industrial environments, the sensory signals are contaminated by noise. The additive Gaussian white noise (AGWN) with various standard variances Gauss noise

Diagram of vibration signal.

Noise signal with
To have enough samples for training and testing classifiers, vibration signals are split into segments with the same length of 900. Then, the added noise signals are normalized in the range [0, 1] and transformed into image sample with size 30*30.
The DAE is applied to preprocess the samples with noise. Through the training of encoder and decoder, the samples with lower dimensions can be obtained. The DAE has stacked structure of 900-600-400-600-900, which reduces the sample dimension from 30*30 to 20*20. Figure 9 shows that after 50 epochs, the mean absolute error (MAE) between the original signals and decoder gradually decreases to 0.0034, which is small enough to meet the experimental requirements.

Mean absolute error of denoising autoencoder.
Feature matching based on MK-MMD
After getting the processed samples, a two-hidden-layer CNN model is built for fault diagnosis. The model parameters are listed in Table 2, where the input shape 1*20*20 means the 20*20 picture sample with 1 feature map. The SGD method and loss back propagation method are used for optimizing the model parameters.
Parameter setting of a CNN model with two hidden layers.
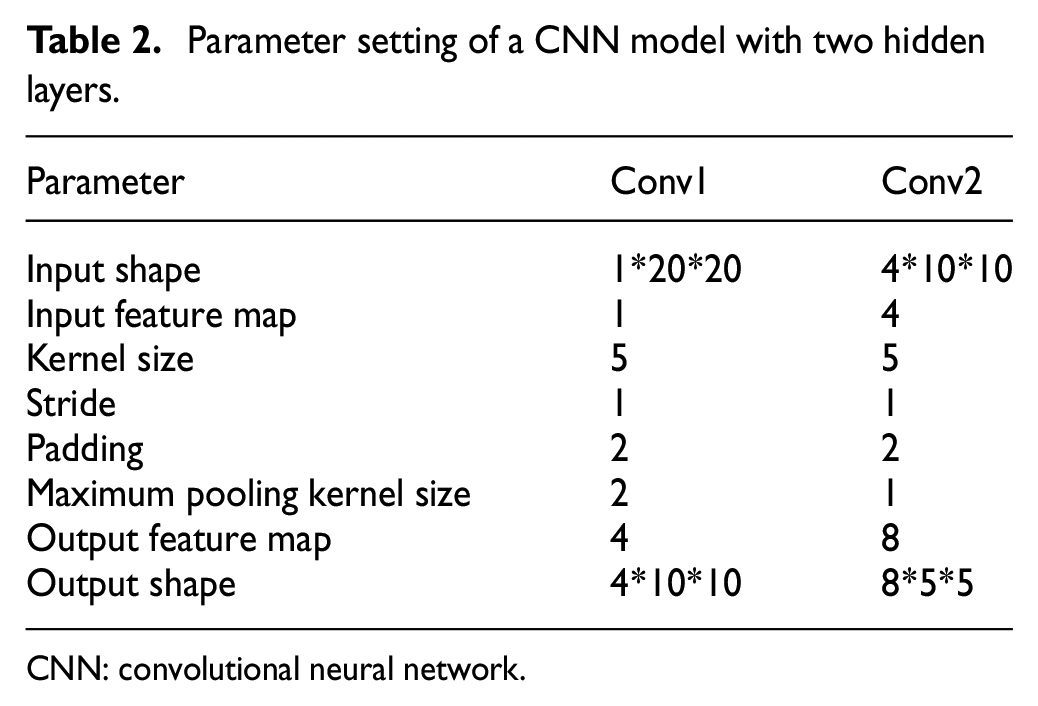
CNN: convolutional neural network.
Based on MK-MMD, a feature matching method can be used to deal with unlabeled TD. As shown in Figure 10, through calculating the MK-MMD between the unlabeled TD and SD with different categories, the category corresponding to the minimum value of MK-MMD is taken as the label of SD sample. Then, the labeled SD samples can be used for further deep TL.

Feature matching based on MK-MMD.
Fault diagnosis based on deep TL
By applying TL method in DL model, the trained parameters and feature mappings in source task can be adopted to fine-tune the model of target task. In this article, the usage of TL with the CNN brings robustness to the network performance under variable operating conditions.
The structure of TL-CNN is shown in Figure 11. The original two-layer CNN can be obtained by training SD samples. Then, the parameters of the trained CNN are transferred to train TD. After convolution and polling, the MK-MMD can be calculated comparing the fully connected layers of source and target domains. Then, it can be added into the loss function of deep neural network for parameter optimization.

The structure of TL-CNN.
Therefore, the optimization goal of the whole network is composed of two parts: classification error

where
According to the value of the output layer, the final fault diagnosis results can be obtained. Figure 12 describes the training loss, which gradually decreased to 0.037 after 150 epochs. Figure 13 shows the clustering graph of fully connected layer output, which can clearly distinguish six categories and achieve 98.8% classification accuracy.

The train loss of CNN.
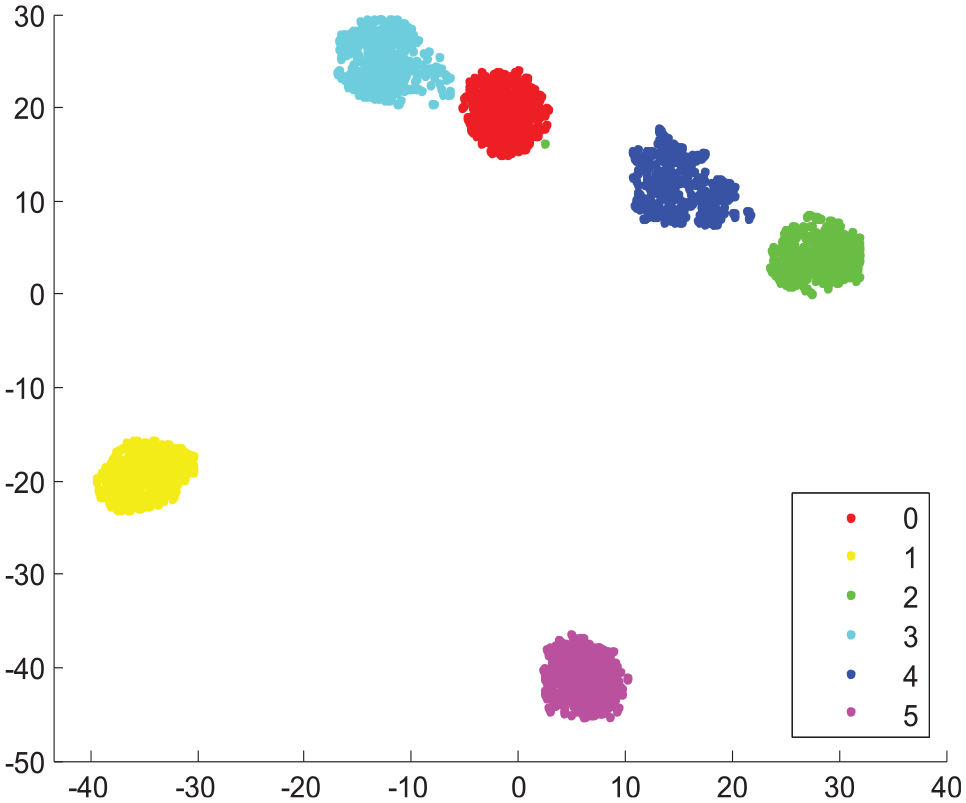
Clustering graph of fully connected layer output.
To testify the robustness of the proposed TL-CNN, different levels of noise are added into the TD samples. The cluster graphs achieved by the t-distributed stochastic neighbor embedding (t-SNE) method are shown in Figure 14. 40 With the increase in the noise level, the points in the clustering graph are more scattered, but they can still roughly distinguish the fault types and maintain high classification accuracy. It can be concluded that the proposed TL-CNN has clear cluster results and high classification accuracy under different noise levels.
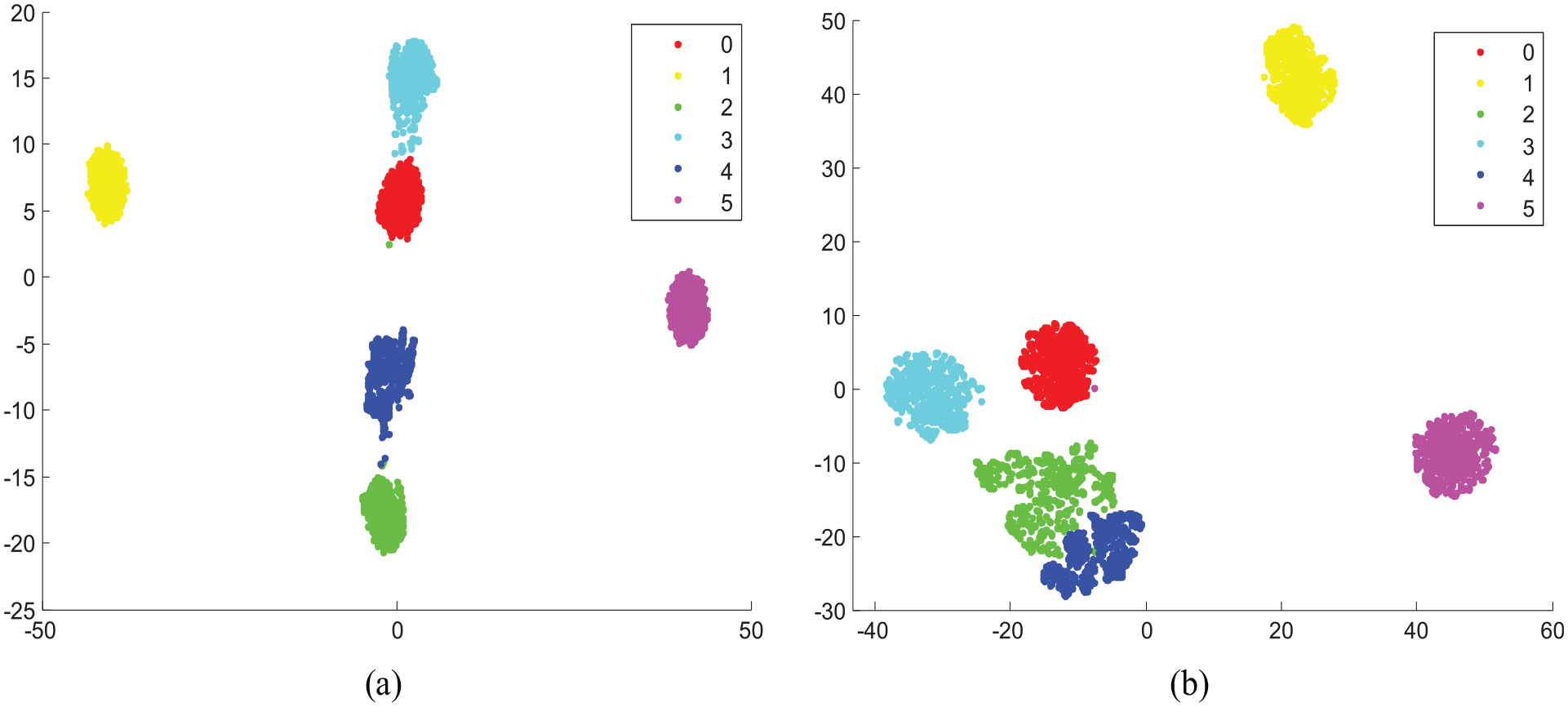
The clustering graphs of fully connected layer output with different noise. (a) Noise signal clustering graph with k = 1 (accuracy = 97.4%) and (b) noise signal clustering graph with k = 2 (accuracy = 94.1%).
Comparisons with individual DL model and traditional models
The effectiveness of the proposed TL-CNN model is validated by several comparative experiments. The SVM and ANN are classical supervised learning method, which has been widely used for fault diagnosis. DBN is the earliest DL method applied in engineering field. In addition, the CNN with model-based TL (MTL-CNN) and feature-based TL (FTL-CNN) is also selected as comparations. The parameter setting of comparison models is listed in Table 3. Besides SVM, other models have two hidden layers.
Parameter setting of comparison models.

TL: transfer learning; CNN: convolutional neural network; MTL: model-based TL; FTL: feature-based TL; DBN: deep belief network; SVM: support vector machine; ANN: artificial neural network.
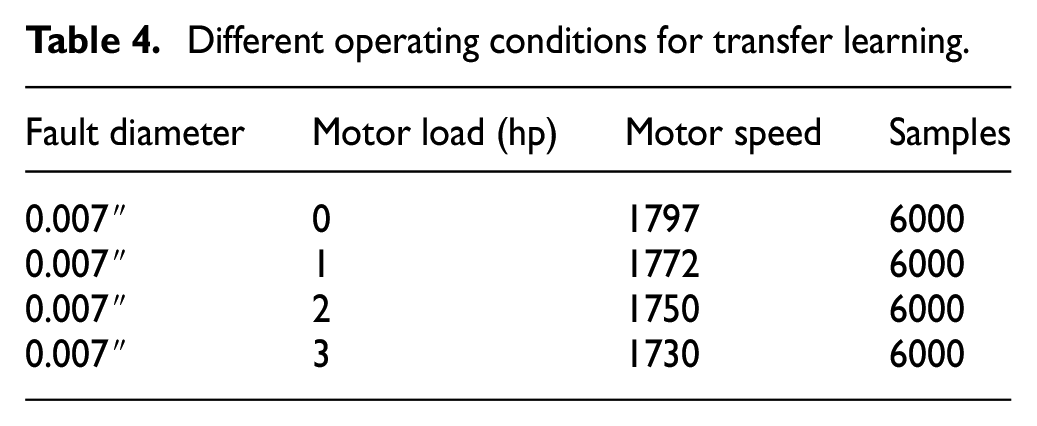
Table 4 lists different operating conditions. To testify the generalization of the proposed model, the datasets with four motor loads are selected as TD for TL.
Different operating conditions for transfer learning.
The classification accuracy with different motor loads and noise levels can be obtained in Table 5.
Classification accuracy (%) under different motor loads with two noise levels.

SD: source domain; TD: target domain; TL: transfer learning; CNN: convolutional neural network; FTL: feature-based TL; MTL: model-based TL; DBN: deep belief network; SVM: support vector machine; ANN: artificial neural network.
Under different operating conditions (see Figure 15), the TL-CNN has great generalization ability and can achieve higher fault diagnosis accuracy than other models. Under different noise levels (see Figure 16), the average accuracy of fault diagnosis can also be maintained at 96%, which is about 2%–8% higher than other models.

Comparative experimental results under different operating conditions.

Comparative experimental results under different noise levels.
Considering the engineering systems have low fault tolerance rate and big data, a little improvement of accuracy can bring huge benefits. Thus, the experimental results verify the effectiveness and feasibility of the proposed deep TL.
Discussion
Considering the noise contamination in real industrial environments, the DAE model is used to denoise and reduce dimension of unlabeled rolling bearing signals. The samples with more specific features can be obtained for further analysis. To get enough labeled TD signals, and reduce the complexity of TL for multiple fault classification, a feature match method based on MMD is adopted to compare the gap between source and target domains and choose the SD class with minimum MMD as the label of TD. To exert the powerful image processing ability of CNN, those rolling bearing signals are converted into multi-dimensional graph samples and fed into the CNN model for fault diagnosis. Based on TL, the model parameters of trained CNN with SD are transferred for training of TD. In addition, the MK-MMD of fully connected layer between source and target domains is added into loss function for optimizing the CNN model. Comparisons with individual DL model and traditional models demonstrate that the proposed TL-CNN has better generalization ability, when dealing with TD with different motor loads and fault diameters. Under different noise levels, the proposed model has great robustness, and the average accuracy of fault diagnosis can also be maintained at 96%, which is about 2%–8% higher than other models.
Conclusion
In this article, a deep TL method is proposed for rolling bearing fault diagnosis under variable operating conditions. First, DAE is used to denoise and reduce dimension of unlabeled rolling bearing signals and obtained the multi-dimensional picture samples. Second, a CNN model with several hidden layers is built for fault diagnosis of SD. Third, the trained CNN model parameters are used for the TD. In addition, the MK-MMD of fully connected layer between source and target domains is added into loss function for optimizing the CNN model. Finally, comparisons with individual DL model and traditional models demonstrate that the proposed deep TL model has better generalization ability and robustness and can maintain high fault diagnosis accuracy under variable operating conditions with noise.
Footnotes
Handling Editor: Francisco Gómez
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.