
Abstract
The mold is referred to as the heart of the continuous casting machine. Mold-level control is one of the keys to ensuring the quality of a high-efficiency continuous casting slab. This article addresses the failure of the mold-level prediction model in the actual production process to overcome the impact of noise. To improve the accuracy of mold-level prediction, a novel method for mold-level prediction based on the multi-mode decomposition method and the long short-term memory model is proposed. First, empirical mode decomposition of the mold-level data is performed. The actual eigenmode component number K is obtained through the calculation of the mutual information entropy of the eigenmode components. Then, we perform a K-based variational mode decomposition on the mold-level data. The noise dominant component is denoised by the calculation of the mutual information entropy of the eigenmode components. Moreover, the long short-term memory model is used to predict the noise dominant component and the information dominant component after denoising. Finally, the predicted result is subjected to variational mode decomposition reconstruction to obtain the predicted mold-level data. The experimental results show that compared with the other methods tested, the model has better prediction efficiency, prediction accuracy, and generalization ability. It provides a new idea for mold-liquid-level prediction and continuous casting blank quality assurance.
Keywords
Introduction
The mold is referred to as the heart of the continuous casting machine. 1 Mold-level control is the basis for stable production operations, avoiding steel leakage and steel spillage. The fluctuation of the mold level is disturbed by many factors. 2 It has the characteristics of nonlinearity, variation with time, and uncertainty. These manifest as many disturbances in production operations, such as sudden-speed abrupt changes and time-varying and nonlinear disturbances in the sliding nozzle due to wear and clogging. The mold-level model is shown in Figure 1.

Mold-level model.
Accurate mold-level control is a key factor in ensuring the quality of the slab. It is an important reference for speed control, roll gap control, mold secondary cooling water control, and plug control. During the continuous casting process, fluctuations in the mold level cause many problems. If the mold level fluctuates too much, first it will cause impurities on the surface of the mold. Surface defects and internal defects of the slab are generated, which affect the surface and internal quality of the slab. Second, it will affect the casting speed, affecting productivity and the production rhythm. Eventually, it will cause the slab and the continuous casting machine to stick together, damage the tundish slide, and even cause downtime. Accurate prediction of the mold level thus occupies an important position in the continuous casting production process.
In order to maintain the stability of the mold level, many scholars have conducted research on mold-level control in recent years. The main methods are proportional–integral–differential (PID) control, fuzzy control, adaptive control, and so on. M Dussud et al. 3 developed a fuzzy controller based on expert knowledge for process control when the mold level is disturbed. In Hesketh et al., 4 an adaptive controller was applied to control the mold level. The controller was embedded in a real-time control program based on a PC. It combines the filter, noise model, and other technologies and provides a new method for the control of the mold level. In De Keyser,5,6 the results of applying model predictive control to mold-level control were presented and compared with standard PID control. The results showed that model predictive control can improve the accuracy of mold-level control. In Kong et al., 7 different adaptive predictive control methods for online parameter identification were simulated and studied. The advantages and disadvantages of the adaptive predictive method and the standard PID controller were compared. Mold-level prediction is often used to regulate the flow of liquid steel in the continuous casting line part of the process of making steel. K Dekemele et al. 8 proposed a novel inferential control strategy; this work improved the current operation and indicated that real plant implementation is feasible. D Copot et al. 9 proposed a fractional-order control design with adaptive laws. A real-time embedded control setup and interface to industrial standard devices was tested to illustrate the implementation aspects of the proposed fractional-order control. Traditional mold-level control uses methods such as neural networks and generalized prediction. However, the continuous casting production process is a strong coupling and nonlinear process with many interference signals, which leads to a decrease in prediction accuracy, and these methods thus cannot meet the requirements of continuous casting production.
In recent years, signal processing methods have developed by leaps and bounds, and many scholars have conducted extensive research on the prediction of time series. In 1998, Huang et al. 10 proposed empirical mode decomposition (EMD). EMD is an adaptive decomposition method without a prior matrix. 11 Since the introduction of EMD by Huang, it has been widely used in the biomedical,12,13 speech recognition, 14 system modeling,15–17 and process control18,19 fields. In recent years, a new signal processing method called the variational mode decomposition (VMD) technique has enriched the signal denoising method. K Dragomiretskiy and D Zosso 20 proposed a VMD method. VMD is a completely nonrecursive VMD model. It finds the center frequency and bandwidth of each decomposition component by iteratively searching for the optimal solution to the variational model, adaptively splits the frequency domain of the signal, and effectively separates the components. Compared with the EMD method, VMD effectively avoids mode aliasing and boundary effects, adaptively implements frequency-domain splitting and effective separation of components, and has better noise and sample rate robustness. Y Zhang et al. 21 proposed short-term wind power prediction based on a quantile regression average and a VMD-based hybrid model. S Lahmiri 22 proposed a method for signal denoising combined with VMD and discrete wavelet transform.
Recurrent neural networks (RNNs) are deep learning neural networks that differ from traditional feedforward neural network (FNN). Introducing directional loops into the RNN structure enables the extraction of associated information in the sequence data and is widely used in fields such as natural language processing due to its superiority in processing sequence data. However, if there is a long-term dependency between the samples, there will be a gradient disappearance problem. Long short-term memory (LSTM) is an improved neural network for this problem. The LSTM neural network was proposed by Hochreiter and Schmidhuber 23 and improved by Graves et al. 24 There are three gates in the LSTM neuron structure, namely, the input gate, output gate, and forget gate, which are used to filter useful information from historical data. LSTM-based systems can learn language translation,25,26 robot control,27,28 image recognition,29,30 and so on.
VMD is an excellent signal decomposition method. Compared with EMD, VMD has a complete mathematical theory basis and has no pattern aliasing and boundary effects inherent. Combined with the adaptive decomposition characteristics of EMD, the VMD method is improved. The method proposed in this article no longer requires prior knowledge compared to the wavelet transform (WT) method. LSTM is a time series prediction method based on the deep learning computing framework. Compared with the traditional support vector machine (SVR), the prediction efficiency is higher and the prediction accuracy is better. Therefore, this article studies the time series prediction performance of the hybrid methods of VMD and LSTM.
This article mainly combines multi-mode decomposition (MMD) and LSTM to predict the mold level. First, the mold level is decomposed by EMD, and the eigenmode component number K is obtained by calculating the mutual information entropy (MIE) of the intrinsic mode functions (IMFs). Second, the mold-level data are decomposed based on the K-based VMD. The high-frequency and the low-frequency IMF boundaries are obtained by calculating the MIE of the eigenmode component, and wavelet threshold denoising (WTD) is performed on the high-frequency IMFs to provide denoising. Finally, the LSTM model predicts the processed IMFs, and the prediction result is reconstructed to obtain the predicted mold level. The layout of this article is as follows: The second section introduces VMD, LSTM, and MIE. The third section introduces the MMD-LSTM model. The fourth section compares the results of various methods. The fifth section discusses the results. Finally, our conclusion is presented.
Basic algorithms
The basic principle of VMD
VMD is a new type of signal decomposition method. This method redefines an AM–FM (amplitude modulation–frequency modulation) signal as an eigenmode component. Its expression is

where phase ϕk(t) is a nondecreasing function, Ak(t) is the instantaneous amplitude of uk(t), and Ak(t) ≥ 0. ωk(t) = ϕ′ k (t), which is the instantaneous frequency of uk(t).
In the interval range of [t − δ, t + δ], uk(t) can be regarded as a harmonic signal with amplitude Ak(t) and frequency ωk(t), and
The difference between VMD and EMD is that VMD is based on solving the variational problem. In the process of obtaining eigenmode components, the variational model principle is used to minimize the sum of the estimated bandwidths of each eigenmode component. The optimal solution of the constrained variational model is found. The center frequency and bandwidth of the eigenmode component are updated in the process of solving the variational model. The signal band is adaptively segmented based on the frequency domain of the signal itself. Furthermore, a narrow-band eigenmode component is obtained.
The variational constraint model is as follows
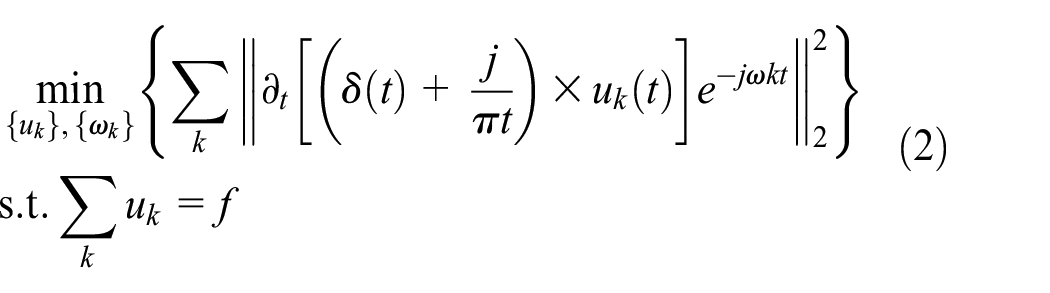
where
We introduce the Lagrange function as

where α is the penalty factor, λ is the Lagrange multiplier, and
The problem of solving the original minimum value can be transformed into the saddle point of the extended Lagrange expression by the alternating direction method; this is the optimal solution of the above formula



where
Therefore, the original signal can be decomposed into K IMFs.
The calculation process of the VMD algorithm is as follows:
Step 1. Initialize
Step 2. n = n + 1, execute the entire loop;
Step 3. Execute the loop k = k + 1 until k equals k, then update
Step 4. Execute the loop k = k + 1 until k equals K, then update
Step 5. Use
Step 6. Given the discrimination condition ε > 0, if the iteration stop condition is satisfied, all the cycles are stopped and the result is output, and K IMFs are obtained.
The basic principle of LSTM
In the LSTM neuron structure shown in Figure 2, let x = [x1, x2, x3, …, xt] be the input timing signal and xt be the input of the neuron at time t. Let y = [y1, y2, y3, …, yt] be the corresponding output target and yt be the output at time t. Let c = [c1, c2, c3, …, ct] represent the state information of the neuron and ct be the state matrix of the neuron at time t. Then, the LSTM memory unit calculation process can be expressed as follows



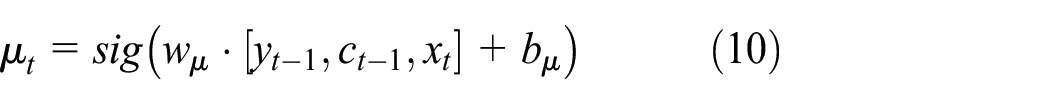
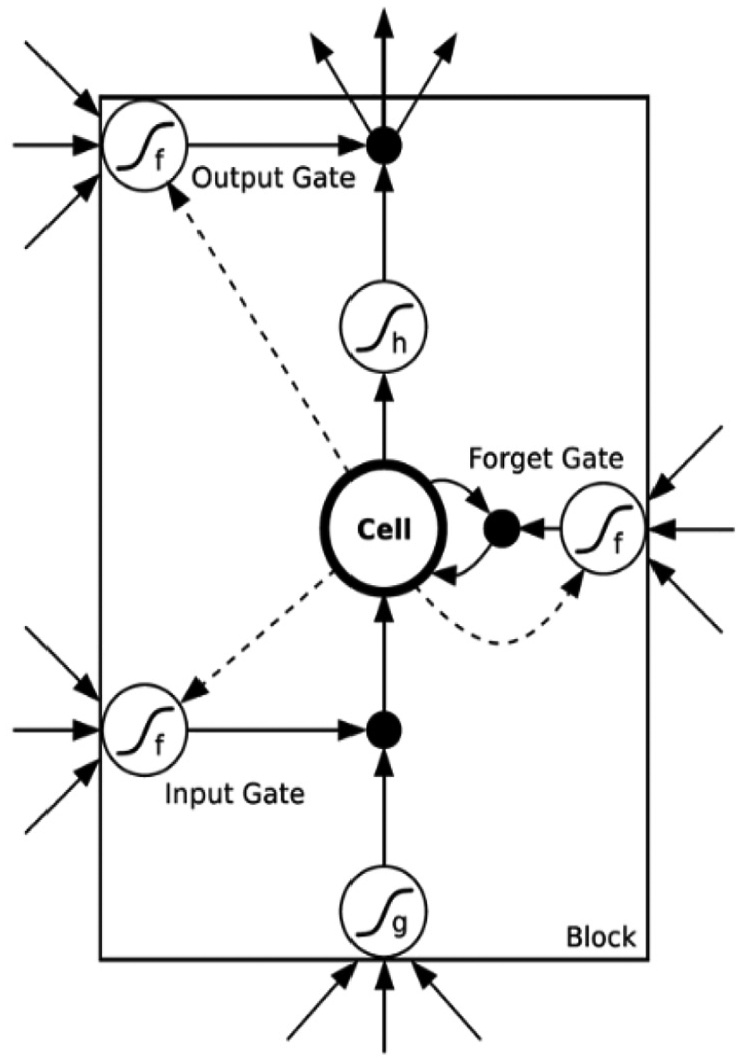
The long short-term memory (LSTM) block structure.
In these formulas, wi, wf, wo, and wμ represent the input gate, forget gate, output gate, and neuron state matrix in the neuron structure, respectively; bi, bf, bo, and bμ represent the corresponding offset constants; and sig(·) represents the sigmoid function.
According to the formula above, the LSTM neuron structure expression in Figure 2 of the neuron state ct and the output yt is as follows


where ⊗ represents matrix point multiplication.
MIE
After VMD decomposition, the mold-level signal s(t) can be expressed as
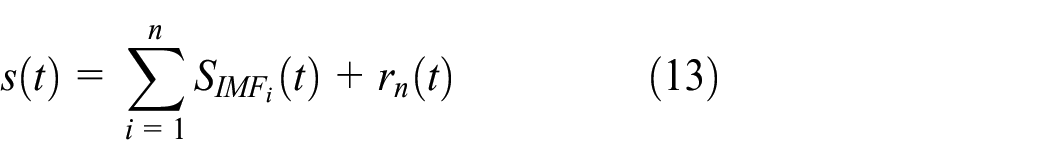
where SIMFi(t) represents the IMF, the frequency of which is ranked from high to low and rn(t) represents the residual, representing the average trend of the signal. We modify equation (1) to

where
MIE is used to measure the statistical dependence between two random variables. Its expression is
If the high-frequency component is noise interference and the low-frequency component is an effective signal, the MIE relationship between the IMFs can be used to identify the boundary between the high-frequency and low-frequency components. The IMF characteristics obtained by the VMD show that the dependence of the high-frequency noise on each IMF is gradually reduced, and the dependence of the low-frequency effective signal on each IMF is gradually enhanced. Therefore, it can be assumed that the high-frequency component and the low-frequency component are partially statistically independent of each other. It is known from the characteristics of MIE that the MIE between two independent random variables should be equal to 0. Therefore, when calculating the MIE between each adjacent IMF, a local minimum value occurs, and only the first local minimum value is searched to obtain a boundary between the high-frequency component and the low-frequency component. Thus, the following search objective function can be obtained

where k is the high-frequency component, and the low-frequency component is decomposed into the IMF serial number.
Mold-liquid-level prediction based on MMD-LSTM
Since the mode number of the original signal decomposition in the VMD algorithm is an a priori knowledge estimation, there is a certain randomness which may lead to error in mode decomposition. Based on the characteristics of EMD adaptive decomposition, the original signal is decomposed, and the MIE between the IMFs is analyzed to determine the effective mode number K.
The single-mode decomposition method has a certain denoising effect on the signal-to-noise separation of noise signals, but there are also various problems that may lead to the loss of effective information and incomplete noise removal. In this article, the denoising algorithm of the hybrid method is proposed, and the noise dominant component generated by single-mode decomposition is further denoised so that the signal is separated from the noise and the effective information is retained as much as possible. In addition, the algorithm can improve the denoising effect and performance indicators of the mode decomposition method.
Although the traditional prediction algorithm can perform simple prediction, the prediction accuracy is low, the robustness is poor, and the prediction requirements of nonlinear and non-Gaussian distributed data cannot be met. The advanced LSTM algorithm proposed in this article is used to predict the time series of IMF, which can improve the accuracy of prediction and the generalization ability of the model. The MMD-LSTM flowchart is shown in Figure 3. The steps of the MMD-LSTM algorithm are shown in Table 1.

Multi-mode decomposition (MMD)-LSTM flowchart.
MMD-LSTM algorithm steps.

MMD: multi-mode decomposition; LSTM: long short-term memory; IMF: intrinsic mode function; EMD: empirical mode decomposition; MIE: mutual information entropy; VMD: variational mode decomposition; WTD: wavelet threshold denoising.
Test analysis
Data source
In order to express the applicability, superiority, and generalization capability of the model application clearly, mold-level data of actual process parameters collected from the continuous casting machine developed by the China National Heavy Machinery Research Institute Co., Ltd (Xi’an, China) are used in this article. There are many uncertain disturbance factors in the control process of the mold level, and the disturbance may change constantly at any time. Most of the disturbances are nonlinear and nonstationary, and the long-term prediction model is difficult to establish. This article asserts that a mold-level prediction model is important for mold-level control to propose new ideas to improve continuous casting automatic control.
A continuous casting production process data acquisition graph is presented in Figure 4. The time interval Δt = 0.5 h and the sampling frequency is 3 Hz.

Mold level.
The main technical parameters of the continuous casting machine are shown in Table 2.
Main technical parameters of the continuous casting machine.

MMD-LSTM-based mold-liquid-level prediction
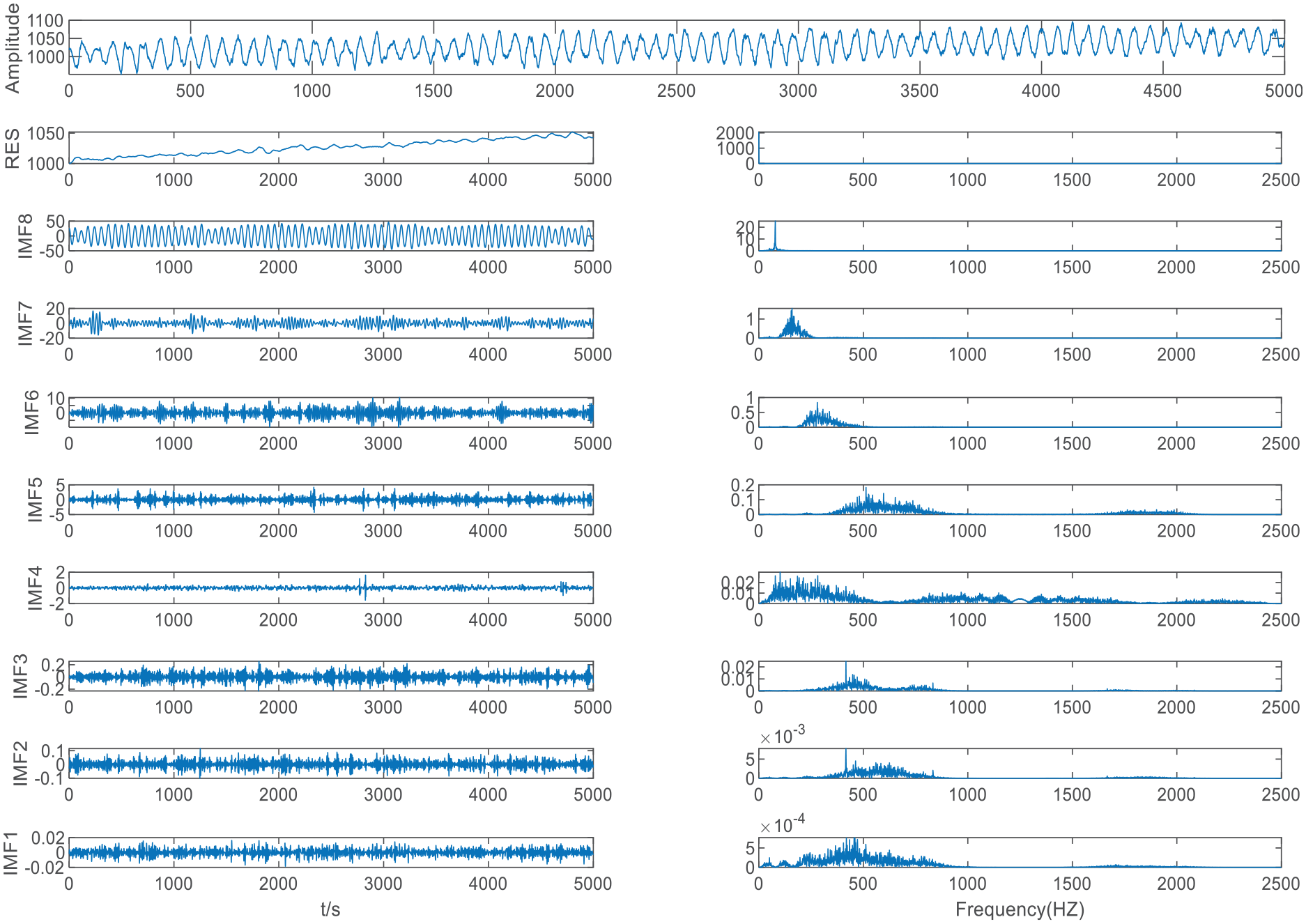
First, the mold-liquid-level data were EMD decomposed, as shown in Figure 5.

Mold-level decomposition results by EMD.
As shown in Table 3 and Figure 5, the MIE of IMF (2–3) was 0.7567, which was the first local minimum MIE between IMFs by EMD, so IMF3 is the boundary line between high-frequency IMFs and low-frequency IMFs. The high-frequency IMFs were seen as a mode, while the other IMFs were seen as different modes separately, and we determined that K = 9. The mold-level signal was decomposed using VMD based on K = 9.
MIE between IMFs by EMD.

MIE: mutual information entropy; IMF: intrinsic mode function; EMD: empirical mode decomposition.
As shown in Table 4 and Figure 6, the MIE of IMF (4–5) is 1.4114, which is the first local minimum MIE between the IMFs by VMD, so IMF5 is the boundary line between the high-frequency IMFs and the low-frequency IMFs; thus, we performed WTD denoising on the first five IMFs.
MIE after VMD.

MIE: mutual information entropy; VMD: variational mode decomposition; IMF: intrinsic mode function.

Mold-level data VMD results.
As shown in Figure 6, by selecting K = 9 as the mode component number for VMD decomposition, we were able to clearly separate the original signals and avoid modal aliasing. It can be seen from the spectrum diagram that the IMF3–IMF7 frequency bandwidth is relatively long and the noise is serious, so WTD was performed on these IMFs.
As shown in Figure 7, the first five IMFs’ center frequencies were significantly reduced and the amplitudes were also significantly reduced.
Wavelet threshold denoising (WTD) results of IMF1–IMF5.
It can be seen from Figure 7 that the IMFs after WTD have a more pronounced center frequency and a much narrower frequency band. IMF1–IMF5 and the other IMFs after WTD were reconstructed using VMD to obtain the denoised signal. This method had a good denoising effect and effectively retained the effective information of the original signal.
The LSTM prediction was performed on each IMF, and the predicted IMFs were obtained and reconstructed.
As shown in Figure 4, the collected time series contained 5000 points. On the basis of normalizing the original data, the training set, validation set, test set, and their labels and samples were divided.
We selected a window of length A and segmented it from the data origin. Each segmentation can produce a continuous time series with length A. Each time the segmentation is completed, the window slides n points to the right for the next segmentation. When the length of the remaining data is less than A, the sliding stops. The experimental results show that the network accuracy and efficiency are best when A is 20 and n is 1. After segmentation, 4981 continuous time series of length 20 were obtained. The last one of each sequence was the label value and the first 19 were the sample values, and the original data set was established based on them.
Of the data in the data set, 90% were used as training data to train the network, and the remaining 10% were used as a test set to test the performance of the network. In order to control and adjust the parameters in the training process, data from the training set (10% of the total data) were used as a verification set. The sizes of the training set, verification set, and test set were as follows:
Training set: (4033, 19, 1);
Verification set: (449, 19, 1);
Test set: (499, 19, 1).
The basic structure of the network is shown in Figure 8. The first layer of LSTM contained 128 neurons with 66,560 parameters, and the second layer contained 256 neurons with 394,240 parameters. In order to reduce the dimension of the output results, Linear was used as the activation function in both LSTM layers. Then, we connected the Dropout layer and set its rate to 0.5 to prevent overfitting and to improve the network generalization ability. Finally, the full connection layer was connected to make the output be 1, that is, to achieve single-step prediction. This layer contained 257 parameters, and the total number of parameters of the network was 461,057. Mean square error (MSE) was selected as the loss function, the more efficient Root Mean Square Prop was selected as the optimization operator to accelerate the learning of the network, and the initial learning rate was set at 0.001.

Basic structure of LSTM.
We set the amount of training data for each batch to 50, and the final validation and training curve stabilized to the lowest value when the epoch number reached 100. The training time was about 610.3 s.
The construction and training of the neural network was based on the Keras framework with Tensorflow as the back end.
The detailed structural parameters of LSTM are shown in Table 5.
Detailed structural parameters of LSTM.

LSTM: long short-term memory.
In Figure 9, there is a comparison between the VMD-LSTM-predicted mold-level data and the actual mold-level data. As shown in Figure 10, in the mold-level data prediction, three different methods were used for predictive performance comparison and the parameters of the three different methods are shown in Table 6.

VMD-LSTM-predicted mold-level data compared to the original data.
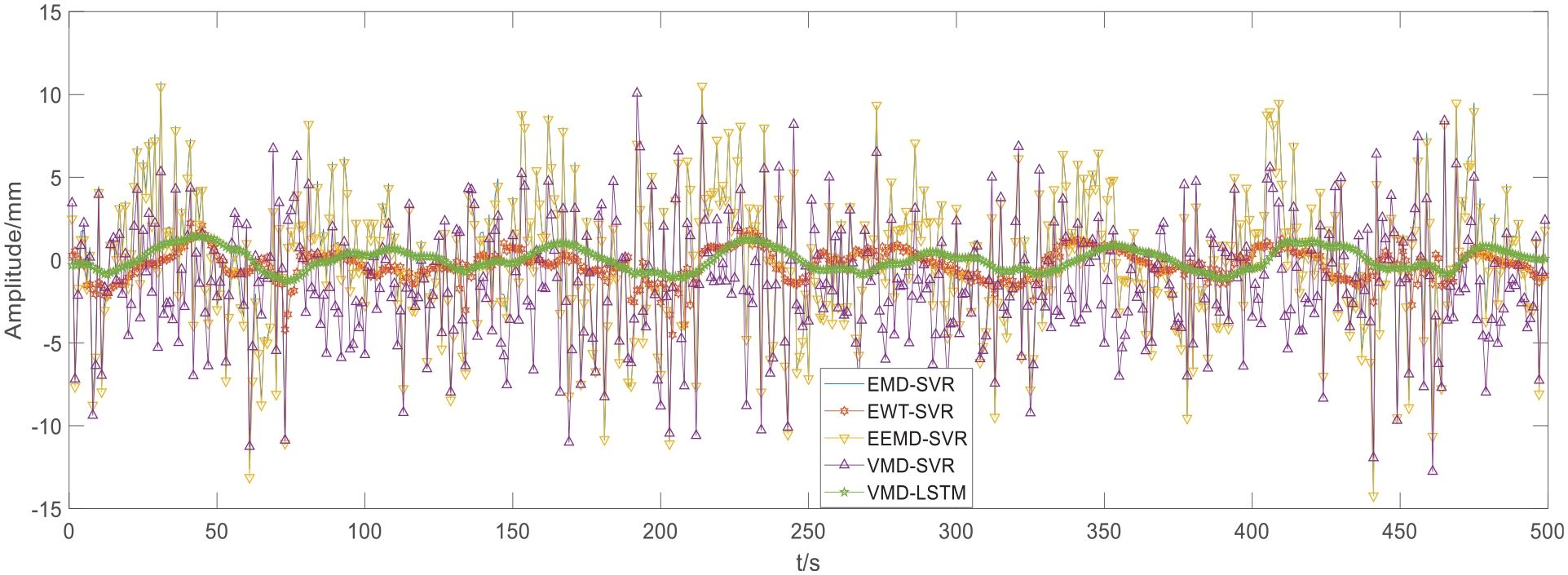
Comparison of the mold-level prediction error of the three methods.
Parameters of the three different methods.
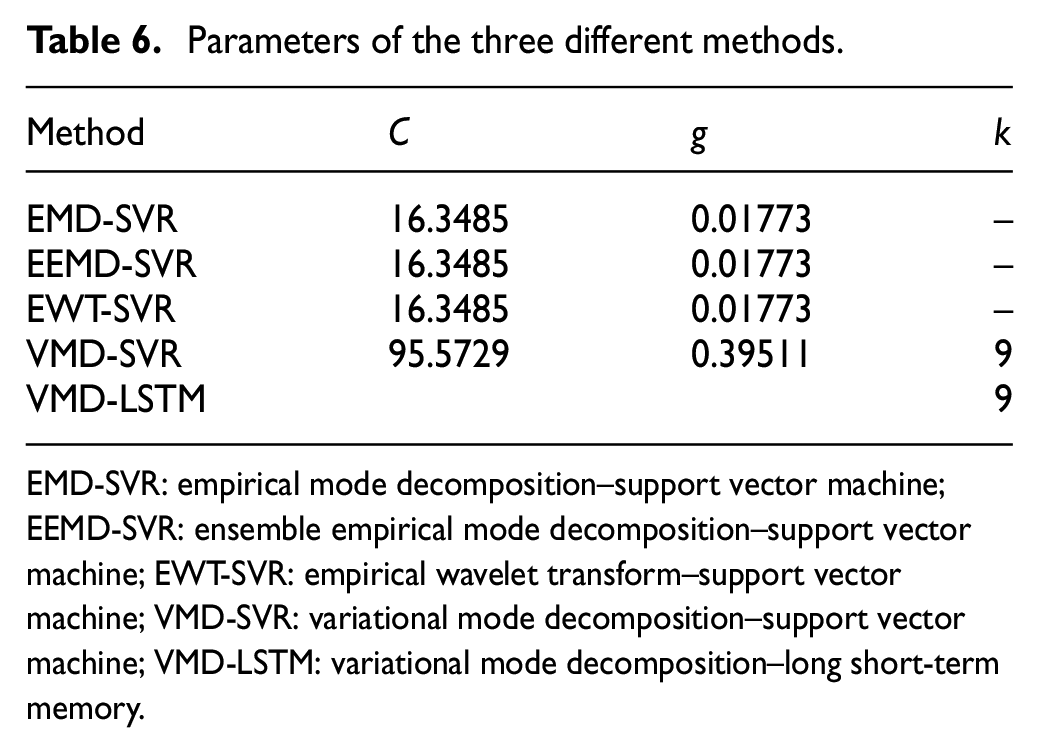
EMD-SVR: empirical mode decomposition–support vector machine; EEMD-SVR: ensemble empirical mode decomposition–support vector machine; EWT-SVR: empirical wavelet transform–support vector machine; VMD-SVR: variational mode decomposition–support vector machine; VMD-LSTM: variational mode decomposition–long short-term memory.
Analysis of prediction results
In this section, the following three statistical indicators are used to verify the performance of the five hybrid prediction algorithms, and the optimal hybrid prediction model suitable for predicting the mold steel level of the mold is selected.
The correlation coefficient is calculated as

The correlation coefficient is used to reflect the statistical relationship between the variables. The larger the correlation coefficient is, the better the performance of the algorithm is.
The formula of root mean square error is

The root mean square error reflects the degree of dispersion of the data set, and the deviation between the observed value and the true value is measured. The smaller the root mean square error is, the better the performance of the algorithm is.
The formula of mean absolute error (MAE) is

The average error is the average of the absolute errors, which better reflects the actual situation of the prediction error. The smaller the average error is, the better the performance of the algorithm is.
Here Pi and Ai are the ith predicted mold-level data point and the original mold-level data point, respectively, and n is the total number of predictions.
Table 7 and Figure 11 show the advantages of the VMD-LSTM method from two different perspectives. Table 7 and Figure 11 show that VMD-SVR shows better performance than MMD-SVR because VMD shows better decomposition performance than EMD, and VMD-LSTM shows better performance than VMD-SVR because LSTM shows better prediction performance than SVR. VMD-LSTM’s root mean square error is the smallest, which shows that the model has stronger robustness; its MAE is the largest, reflecting that VMD-LSTM prediction is the most accurate; moreover, mean absolute percentage error (MAPE) considers not only the error between the predicted value and the real value, but also the ratio between the error and the real value, which shows that the VMD-LSTM model has the highest prediction accuracy.
A comparison of the prediction model test results.

RMSE: root mean square error; MAE: mean absolute error; EMD-SVR: empirical mode decomposition–support vector machine; EEMD-SVR: ensemble empirical mode decomposition–support vector machine; EWT-SVR: empirical wavelet transform–support vector machine; VMD-SVR: variational mode decomposition–support vector machine; VMD-LSTM: variational mode decomposition–long short-term memory.

A comparison of prediction model test results.
It can be seen from Table 7 and Figure 11 that, among the SVR-based hybrid methods, VMD-SVR shows better performance than EMD-SVR. The four indicators are all the best and the prediction performance has been greatly improved. Among the VMD-based hybrid methods, VMD-LSTM shows better performance than VMD-SVR.
The VMD-based hybrid methods show better performance than the SVR-based hybrid methods because VMD has a better data decomposition effect than EMD and empirical wavelet transform (EWT), which can effectively decompose the original signal into different narrow-band signals, thus effectively avoiding the boundary effect of EMD and improving the signal prediction.
Among the VMD-based hybrid methods, the R value of VMD-SVR is close to that of VMD-LSTM. The MAE of VMD-LSTM is 0.9833, which is better than that of VMD-SVR. The performance of VMD-LSTM prediction is better than that of VMD-SVR, LSTM uses an advanced deep neural network framework for calculations, and predictive models exhibit superior predictive performance compared to SVR. The VMD-LSTM hybrid method greatly improves the prediction accuracy compared to the traditional algorithm and shows a strong generalization ability and robustness.
Conclusion
In this article, a novel method for mold-level prediction is proposed. The algorithm combines multiple pattern decomposition algorithms, MIE, and deep learning. It is a prediction algorithm with more adaptive denoising and strong robustness. The algorithm uses a variety of mode decomposition methods to simplify complex mold-level data. The MIE is used to determine the real mode number, the high-frequency IMF threshold, and the low-frequency IMF threshold. In addition, the mold-level data are effectively denoised while saving as much information as possible. Furthermore, the IMF prediction is carried out using a powerful deep learning tool, the LSTM model. Finally, the predicted mold-level data are obtained. The contributions of this article are as follows:
In this article, an MMD-LSTM prediction method is proposed.
In the field of mold-level prediction, the MMD-LSTM prediction algorithm is used for the first time.
By experimenting and comparing the predicted data with the actual signals, the proposed algorithm is shown to be a better prediction algorithm with stronger robustness and powerful generalization ability when compared with the other algorithms.
Although the efficiency and accuracy of the proposed method have been greatly improved, LSTM as a deep learning method consumes a large amount of computational memory. We will improve the cost of the LSTM in the future.
Footnotes
Acknowledgements
Qi Gao, Hang Zhao and Yanni Zheng are acknowledged for their valuable technical support.
Handling Editor: James Baldwin
Author contributions
W.S. conceived and designed the research; Z.L. performed the experiment and wrote the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by the National Natural Science Foundation of China (No. 51575429).