
Abstract
This article proposes a novel fuzzy model for solving fuzzy multi-objective permutation flow shop scheduling problem with fuzzy processing time. Specifically, two fuzzy objectives, that is, the fuzzy makespan and the fuzzy total flow time, are taken into account in this model simultaneously. In addition, to solve fuzzy multi-objective permutation flow shop scheduling problem, an efficient algorithm called fuzzy multi-objective local search-based decomposition is proposed. In order to generate a high quality and diverse set of initial solutions, a problem-specific Nawaz–Enscore–Ham heuristic approach is incorporated into the framework as an initialization. Then, two perturbation strategies with different strength are adopted to find better solutions and to avoid local optimum as well. Besides, a ranking concept based on fuzzy number centroid is provided to compare with fuzzy solutions. After that, a restart strategy is employed to change the searching space when the best solution has not been improved for a certain number of iterations. Finally, we conduct an extensive computational study on Taillard benchmarks to compare the proposed fuzzy multi-objective local search-based decomposition with the fuzzy NSGAII. Experimental results demonstrate that the fuzzy multi-objective local search-based decomposition algorithm is both effective and efficient in solving the fuzzy multi-objective permutation flow shop scheduling problem.
Keywords
Introduction
In recent years, scheduling problems have played an important role in both manufacturing system and traffic arrangement. Among them, the permutation flow shop scheduling problem (PFSSP) has received growing attentions for its fundamentally theoretical value, and the widespread applications in production and living of our daily life.1–4 As for the objectives of PFSSP, a variety of criterions have been presented according to different considerations, such as performance-oriented optimizations 1 (makespan, flow time, tardiness, earliness, idle time, etc.), energy-related optimizations 5 (energy consumption, peak power load), and environment-aware optimizations 6 (carbon footprint reduction). Since most real-world scheduling problems are naturally formulated as multi-objective problems, it is of great significance to settle the multi-objective permutation flow shop scheduling problem (MOPFSSP) within a reasonable time. Also note that the classical MOPFSSP cannot model some practical conditions owing to the fact that they are incapable of depicting the uncertain processing time. Thus, we focus on modeling and solving the MOPFSSP with fuzzy processing time in this article, which makes the model more suitable for real scenarios.
As is known to all, numerous of researchers have proposed exact methods, heuristic and metaheuristics for solving MOPFSSP.7–19 Recently, the multi-objective local search algorithm based on decomposition (MOLSD) 20 was proved to be an efficient one for solving such a problem. After that, a novel general multi-objective decomposition-based estimation of distribution algorithm using Kernels of Mallows models was introduced by Zangari et al. 21 In 2018, Ruiz et al. 22 first used a metaphor-inspired method called iterated greedy algorithm to gain better results. We can see that the researches on MOPFSSP are sustained, illustrating the importance of this problem.
When considering the model of MOPFSSP in a real scenario, it is easy to find that the concepts of imprecision and fuzziness exist in real manufacturing system due to the uncertain processing time. Thus, the certain model is inappropriate to represent such problems. For instance, the certain progress time in a real factory could hardly be obtained if it has multiple functions. In this situation, it is reasonable to use fuzziness concept such as the fuzzy process time to depict the model. 23 Fortunately, a lot of achievements have been provided24–38 for solving the fuzzy multi-objective permutation flow shop scheduling problem (FMOPFSSP). Over the past few years, an increasing number of researchers focused on the FMOPFSSP. Javadi et al. 39 proposed a fuzzy multi-objective linear programming model to solve the multi-objective flow shop scheduling problem with no-wait constraints in a fuzzy environment. In this article, the author attempts to minimize two objectives simultaneously, that is, the weighted mean completion time and weighted mean earliness. Wu 40 paid attention to the fuzzy flow shop scheduling problem in which the processing time and due date are uncertain. Nakhaeinejad and Nahavandi 41 proposed an interactive method for solving the multi-objective fuzzy flow shop scheduling problem with the aim to minimize makespan, mean flow time, and machine idle time simultaneously. Later, Behnamian and Fatemi Ghomi 42 performed a bi-level algorithm, including random key genetic algorithm and particle swarm optimization algorithm, for the bi-objective hybrid flow shop scheduling problems with fuzzy processing time, sequence-dependent setup times, and due dates.
Different from those papers mentioned above, in this article, a novel fuzzy model of the FMOPFSSP with two fuzzy objectives, that is, the fuzzy makespan and the fuzzy total flow time, is proposed. As is known to all, fuzzy makespan and fuzzy total flow time are classical conflicting objectives as traditional FMOPFSSP suggests. Therefore, we cannot optimize them simultaneously. For solving the FMOPFSSP, an efficient algorithm called fuzzy multi-objective local search-based decomposition (FMOLSD) is proposed. In the algorithm, at first a problem-specific Nawaz–Enscore-Ham (NEH) heuristic approach is incorporated into the search framework to improve some individuals. Then, two perturbation strategies are adopted to find better solutions and to avoid local optimum as well. Besides, to compare with fuzzy solutions, a ranking concept based on fuzzy number centroid is provided. After that, a restart strategy is employed to change the search space when the best solution is not improved after a certain search number of iterations. Finally, the influence of some parameters of this algorithm is investigated by some numerical experiment results, and the comparisons on some benchmark instances are proposed with FNSGAII which can be viewed as a fuzzy version of NSGAII. The results demonstrate that the FMOLSD algorithm is effective and efficient in FMOPFSSP.
The rest of this article is organized as follows. Some concepts of fuzzy number and multi-objective optimization problems are given in the “FMOPFSSPs” section. In the “FMOLSD Algorithm” section, the details of the algorithm FMOLSD would be described. In the “Computational Experiments and Results” section, the results of the computational experiments are displayed. At last, a conclusion will be given in the “Conclusion and Future Work” section.
FMOPFSSPs
In this section, some concepts and operators of fuzzy numbers will be introduced, together with the definition of the FMOPFSSP. To make the definition easily understood, a simple yet intuitional example will be given as well.
Operations on fuzzy numbers
In fuzzy context, fuzzy numbers can describe the extent to which people feel shocked when an event happened. The larger a fuzzy number is, the less extent to which people are shocked. On the contrary, a small fuzzy number indicates that people feel much shocked by the event that is happening. Thus, it is appropriate to represent an uncertain problem with fuzzy numbers. First, the definition of the fuzzy set is given as follows. 43
Definition 1
If a function denotes
In Definition 1,
There exists a number x in real set R, that makes
if if
If
After introducing the definition of fuzzy number, the form of fuzzy number used in this article will be presented next.
The fuzzy number has various forms such as triangular fuzzy number and trapezoidal fuzzy number. To understand the fuzzy number form, the triangular fuzzy number and the trapezoidal fuzzy number are displayed in Figure 1. A triangular fuzzy number is denoted as
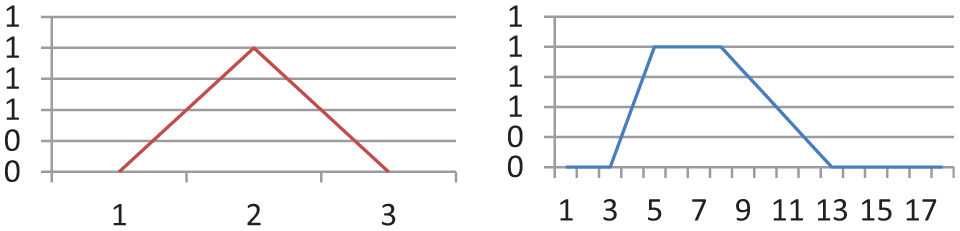
A triangular and trapezoidal fuzzy number.
In addition, several operators of the fuzzy number is adopted in this article, named the addition operation, the max/min operation. An operator “⊕” in this article is similar to the addition operation in Hu et al.
44
Two fuzzy numbers are denoted as

Due to the definition, equation (1) can maintain the fuzzy number property.
44
In order to compare two fuzzy numbers, two operators are adopted in this article, defined as
Ranking fuzzy numbers have been wildly concerned due to the difficulty of comparing two fuzzy numbers. Recently, there have been lots of academic papers focusing on this problem. Among them, a useful and easy approach based on the centroid of fuzzy number is adopted to compare two fuzzy numbers. 45
In Wang et al., 45 the formula of calculating the centroid of a trapezoidal fuzzy number is denoted as follows

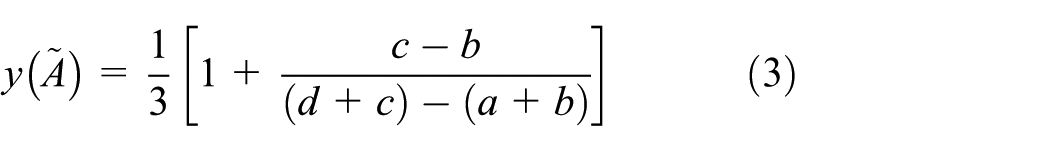
where
The FMOPFSSP with fuzzy processing time
An optimization problem with multi-objectives can be described as follows

where
Based on these, the FMOPFSSP can be stated as follows: there are n jobs and a set of m machines. Each job will be processed on each machine. The uncertain processing time of the job i on the machine j is denoted by

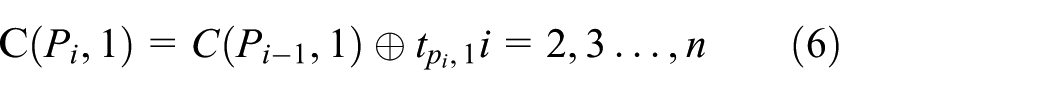

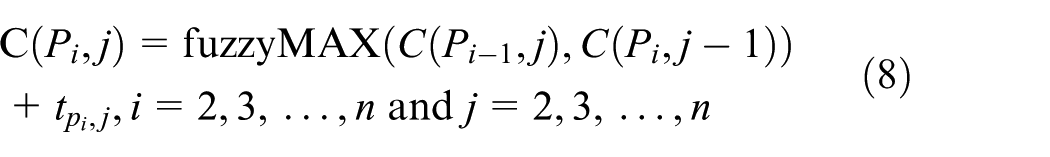
Then the two objectives, that is, fuzzy makespan and fuzzy total flow time, can be defined as


Now take the FMOPFSSP with two jobs and two machines as an example. The description is below in order to make the mechanism clear:
Job 1: machine 1 (3, 4, 5, 7), machine 2 (2, 4, 7, 10),
Job 2: machine 1 (2, 4, 6, 9), machine 2 (6, 7, 9, 11).
All the processing time in this example is trapezoidal fuzzy number. If the job scheduling is {job 1, job 2}, the start time of job 1 on machine 1 is (0, 0, 0, 0). The start time plus the processing time of job 1 on machine 1, which is (0, 0, 0, 0) ⊕ (3, 4, 5, 7), is (3, 4, 5, 7). It is the finish time of job 1 on machine 1. As no setup time constraints are required, so (3, 4, 5, 7) is the start time of job 1 on machine 2. Therefore, the finish time of job 1 on machine 2 is (3, 4, 5, 7) ⊕ (2, 4, 7, 10) which equals (5, 8, 12, 17). The start time of job 2 on machine 1 must be executed after the finish time of job 1 on machine 1. So the result is (5, 8, 11, 16). As formula (8) says, the start time is the larger one between (5, 8, 12, 17) and (5, 8, 11, 16). According to formula (2), the horizontal coordinate of the centroid of (5, 8, 12, 17) is 10.58. The horizontal coordinate of the centroid of (5, 8, 11, 16) is 10.09. Therefore, the start time of job 2 on machine 2 is (5, 8, 12, 17) because it is larger. Afterward, the finish time of job 2 on machine 2 is (5, 8, 12, 17) ⊕ (6, 7, 9, 11) = (11, 15, 21, 28). Finally, we get the results: the makespan equals (11, 15, 21, 28) and the total flow time is (16, 23, 33, 45).
FMOLSD algorithm
Decomposition technique
The decomposition technique in this article refers to multi-objective evolutionary algorithm based on decomposition,
46
which has been proved efficient in solving multi-objective scheduling problems. To deal with fuzzy problems, some operators are adopted in the decomposition technique. First, the weighted sum approach makes the multi-objective problem into a single objective problem. In addition, the weighted vectors are denoted as
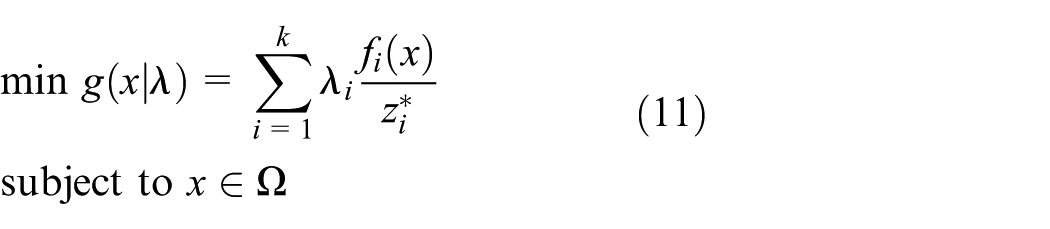
where
Main algorithm framework
The FMOLSD framework is given in Algorithm 1, called FMOLSD.

In line 1, the population is initialized where each individual is a feasible solution and each individual has a weight vector. The weight vectors transforms the multi-objective optimization problem to a single objective optimization problem.
In line 2, the NEH heuristic approach 20 is employed to make more outstanding individual. It is not used for each individual because the quality and diversity of the population should be maintained.
In lines 5–7, the set

Lines 8–41 describes the main work of FMOSLD. In line 10, the LocalSearch_insert is a function to get the best new individual among all the neighborhoods when a randomly selected job r is moved to the far left position. The neighborhood structure of one individual is defined as exchanging two adjacent jobs on it. From lines 11 to 25, if the new individual is not better than the old one, a further local search will be performed to get a better individual. In lines 26–35, if the new individual is better, we seek for higher quality solutions based on it. To be specific, the new individual will be operated by two levels of perturbations. If the individual is in
In heavy perturbation process, two random segments of individuals are chosen and swapped to get a new individual. The function of heavy_perturbation is shown in Algorithm 3. When talking to the light perturbation, a random job is chosen and then inserted into another random position. The function of light_perturbation is given in Algorithm 4.


Computational experiments and results
In this section, the parameter tuning and the efficiency verification experiments are conducted on a well-known data set. Then, detailed experimental results and discussion will be given.
Data set and performance evaluation
As shown in Table 1, the data set used in this article is obtained from Taillard, 47 which is generally employed in MOPFSSP. It has 90 instances with different sizes so that a full test on the performance of one algorithm can be achieved. However, the original data set does not consider the characteristics of fuzzy processing time. Therefore, they are modified by changing the exact time to fuzzy time randomly in a small range. Due to the characteristic of fuzzy processing time, the execution time should not be exact. Moreover, the randomization of instances is the most popular way to verify the performance and robustness of newly proposed algorithms.
The detail of data set.

Two commonly used indicators, named Hypervolume indicator and set coverage (C-metric) indicator, 20 are adopted in this article to measure the distribution and quality of the pareto set.
Hypervolume Indicator (IH): This metric calculates the hypervolume in the objective space that is dominated by at least one solution of the non-dominated set. It should be noted that all the objective values need to be normalized into [0, 1] so that each objective has a similar impact on IH.
Set Coverage (C(X, Y)): Suppose X and Y are two pareto fronts of a problem, then C(X, Y) is defined as the percentage of the solutions in Y that are dominated by at least one solution in X as follows
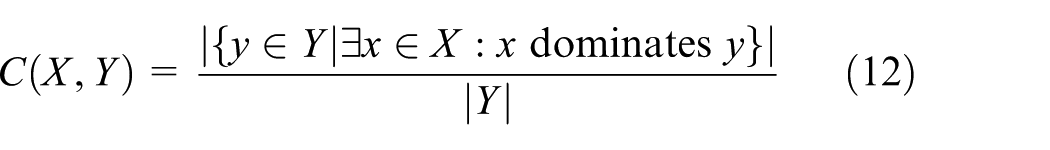
Experimental environment and parameter settings
All programs are coded in C++, and the running environment is a PC with an Intel 3.30 GHz CPU, 4GB RAM. The limit time of running is 1000 s. The parameters are stable in the whole process once it is deterministic. The population size N is set to 75 and the maximum number of local search nls is 250 according to the experiments. Other parameters are chosen as the same as Li and Li
20
does. The weight vector set is
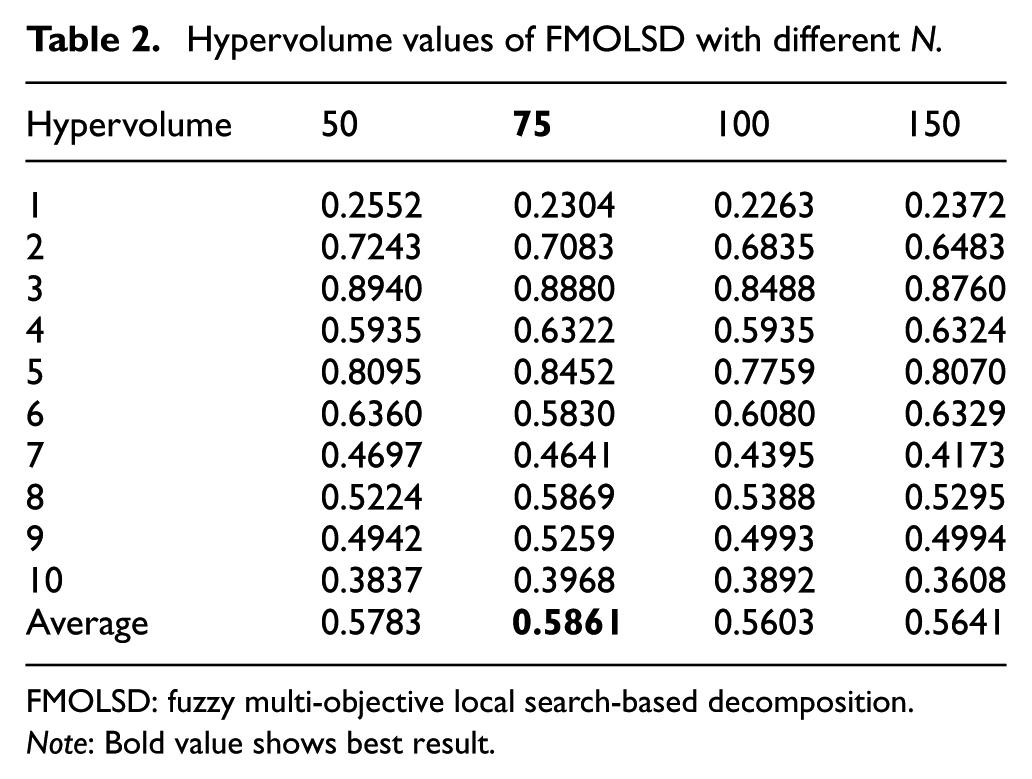
To determine the most appropriate population size, N is set as 50, 75, 100, and 150, respectively. In order to avoid the over-fitting phenomenon, only fuzzyTa051 to fuzzyTa060 are used as the test instances. The results are displayed in Table 2. It shows that when N = 75, the best average hypervolume value can be obtained. When the population size is too large, the convergence of the population needs more time, while a smaller population size will bring deficient searching on the whole space. Therefore, setting N to 75 is the best choice for FMOLSD in a certain running time.
Hypervolume values of FMOLSD with different N.
FMOLSD: fuzzy multi-objective local search-based decomposition.
Note: Bold value shows best result.
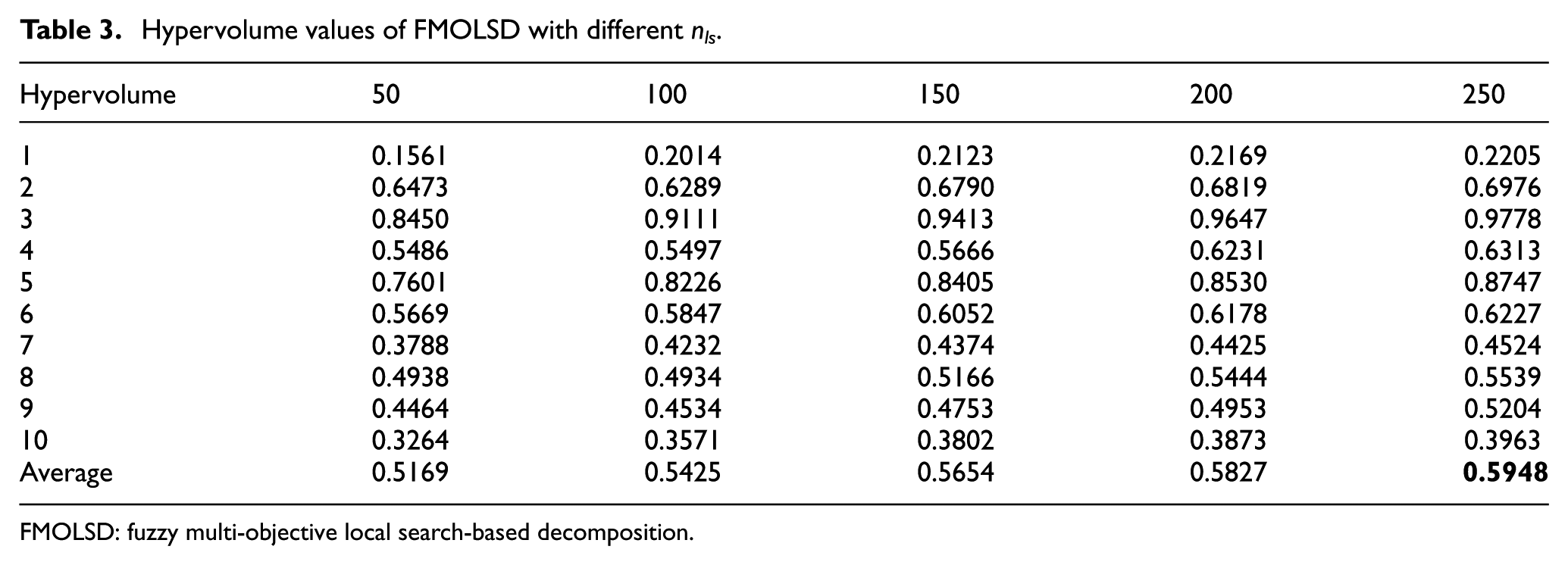
Another important parameter is nls. The larger nls is the better results it can produce. But a large value of nls often needs more computational time. So we test nls as 50, 100, 150, 200, 250, respectively. Table 3 shows the consequence that FMOLSD gets the best result when nls is set 250. Note that there is no need to examine larger nls because of the time limit of the whole framework.
Hypervolume values of FMOLSD with different nls.
FMOLSD: fuzzy multi-objective local search-based decomposition.
Comparison results
This subsection will demonstrate the comparison experiments between FNSGAII and the proposed FMOLSD. FNSGAII is short for Fuzzy NSGAII, which is slightly modified for fuzzy problems. 48 In this way, we can compare our proposed algorithm with the classical NSGAII fairly. In Figure 2, it is clearly seen that the FMOLSD shows dominating superiorities to FNSGAII on the quality of solutions. FMOLSD generates the pareto front in the range of (525,000, 555,000) for total flow time, and (6725, 6900) for makespan on fuzzyTa090, while FNSGAII only attains solutions within the scope of (1,660,000, 1,670,000) and (25,150, 25,375). As for the other benchmark fuzzyTa010, the two objectives of FMOLSD are ranging between (13,200, 14,300) and (1140, 1210), while they are (49,000, 52,100) and (4200, 4425) for FNSGAII. Therefore, FMOLSD dominates FNSGAII on all instances. The values of C-metric of each data set also inflect the same conclusion as Figure 2 does, which are outlined in Table 4.

Distribution of result on fuzzyTa010 and fuzzyTa090 by FMOLSD and FNSGAII.
Coverage values between FMOLSD and FNSGAII.

FMOLSD: fuzzy multi-objective local search-based decomposition.
In summary, all of the results mentioned above show that our algorithm is able to produce more widely distributed solutions as well as higher quality of the pareto set than FNSGAII.
Conclusion and future work
In this article, a novel fuzzy model of FMOPFSSP is addressed with two fuzzy objectives, that is, fuzzy total flow shop time and fuzzy makespan. To solve this problem, a new framework FMOLSD is developed using three efficient strategies, that is, the insert-based local search, two-level perturbation methods, and the restart technique. Comparative experiments are carried out on well-known benchmark instances against the FNSGAII, to verify the performance of FMOLSD. The results in the experiment have pointed out that FMOLSD gains a significant edge in terms of the approximation and distribution of the pareto front.
As for future work, one concern is to solve large-scale FMOLSD problems, where more efficient methods should be designed. For example, reduction rules, sampling techniques, or effective heuristics. Another interesting topic may be the practical extension of FMOLSD, such as fuzzy hybrid flow shop scheduling problems and fuzzy blocking flow shop scheduling problems.
Footnotes
Handling Editor: Wanli Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.