
Abstract
Based on improved complete ensemble empirical mode decomposition with adaptive noise (ICEEMDAN) algorithm and kernel online sequential extreme learning machine (KOSELM) algorithm, a new hybrid short-term traffic flow prediction model (ICEEMDAN-KOSELM-ARIMA) for signalized intersections is proposed according to the current and historical traffic flow data. First, traffic flow historical time series are decomposed by ICEEMDAN algorithm for the purpose of improving the prediction accuracy. Several intrinsic mode functions could be obtained by the decomposition process. Then, permutation entropy algorithm is employed to analyze the random properties of intrinsic mode function components. According to the different random properties of intrinsic mode functions, different prediction models can be built. On this basis, KOSELM prediction models are established for the intrinsic mode function components with big randomness. And auto-regressive integrated moving average (ARIMA) prediction models are built for the intrinsic mode function components with small randomness. Finally, an actual signalized intersection is selected to verify the effect and performance of the hybrid prediction model proposed in this article. Results show that compared with other models, the new proposed hybrid prediction model can effectively improve prediction accuracy, of which prediction errors are the lowest and fitting effect with actual values is the best.
Keywords
Introduction
It has been well known that with the rapid development of economy, vehicles increase dramatically, which leads to increasingly serious traffic congestion problem. As one of the effective means to solve traffic problems, intelligent transportation systems (ITS) has become a hot research topic gradually. Traffic control system and traffic guidance system are two important subsystems of ITS, which are both built based on real time and accurate prediction of traffic state. However, traffic flow prediction is the basis of the traffic state prediction. Therefore, reliable traffic flow prediction becomes more and more important for ITS.
Generally speaking, traffic signal control cycle is usually within 3 min and guidance cycle is usually 5 min. Although traffic flow acquisition equipment has been becoming more complete, the real-time collected information still has certain hysteresis for efficient traffic control and guidance systems. Accurate short-term traffic flow prediction can provide prospective traffic flow information for the formulation and optimization of intelligent traffic signal control and guidance schemes and meet the real-time demand of traffic data. The prediction accuracy of short-term traffic flow is directly related to the effect of traffic control and guidance. However, the inherent resilience, uncertainty, and nonlinearity of traffic flow are a difficult problem that high-precision short-term traffic flow prediction needs to overcome. In addition, the rapid development of ITS also puts forward higher requirements for traffic flow prediction. As a consequence, researching efficient and accurate short-term (usually 5 min) traffic flow prediction method is of great significance to the whole ITS.
Short-term traffic flow prediction usually takes real-time traffic flow information of the intersection and road section to forecast the traffic flow in the future period progressively with proper methods and technologies, in order to achieve the goal of dynamic traffic flow prediction. The predicted traffic flow can provide basis for selecting optimal path, balancing road network traffic flow, optimizing management schemes and improving signal control strategies.
In recent years, there have been many researches in the field of short-term traffic flow prediction. And a variety of prediction models have been set up, which could be divided into four types in general:
Statistical theory prediction models, which mainly use traditional mathematical statistics method to forecast traffic parameters such as traffic flow, speed, and travel time. The models are implemented based on the same statistical characteristics between the predicted data and the historical data. Typical statistical models have been developed and applied for years, such as multiple regression model, 1 auto-regressive moving average (ARMA) model, 2 auto-regressive integrated moving average (ARIMA) model, 3 Kalman model,4,5 and nonparametric regression model. 6
Nonlinear prediction models, mainly based on nonlinear theories such as chaos theory, self-organization theory, coordination theory, and dissipative structure theory. The models are established by bringing chaotic attractor and fractal concepts in and employing phase-space reconstruction and digital ecological simulation methods. The established typical models include chaos theory model 7 and wavelet theory model. 8
Intelligent prediction models, which are based on modern intelligent algorithms through training historical data. They include artificial neural network (ANN) model,9–11 fuzzy logic model, 12 echo state network (ESN) model, 13 support vector machine (SVM) model, 14 and deep belief network (DBN) model. 15
Hybrid prediction models, which can improve the overall accuracy through integrating several single prediction models. Some hybrid models have been proposed, represented by SSA-ELM model, 16 EMD-PSO-SVR model, 17 WNN-MAR-VOA model, 18 and GFMNB-K models. 19
A brief summary of the four types of models is shown in Table 1.
A brief summary of the four types of models.
Among the numerous models above, chaos theory, neural network, and support vector machine all have obvious advantages in the analysis of complex nonlinear and uncertain systems. But most of the traditional neural network models always use gradient descent algorithm, more vulnerable to local optimum, and slow learning speed.
The extreme learning machine (ELM) algorithm put forward by Huang et al. 20 can solve the problem above effectively. As a new kind of single hidden-layer feedforward neural network algorithm, ELM has fast learning speed and good generalization performance. Therefore, it has been widely applied in engineering problems. On the basis of ELM algorithm, Liang et al. 21 proposed an improved algorithm which was referred as online sequential extreme learning machine (OSELM). The generalization ability of the algorithm could be improved by training historical data in batches. Besides, the new algorithm was applicable to variable samples. Due to the fact that data missing and errors are inevitable in the actual collection and transmission of traffic flow, partial training should be carried out according to the real-time data acquisition situation. Therefore, OSELM algorithm could satisfy the robustness need of practical application well. On this basis, Scardapane et al. 22 brought kernel function into OSELM algorithms and put forward kernel online sequential extreme learning machine (KOSELM) algorithm. Approximate linear dependence (ALD) method belonging to kernel adaptive filter (KAF) was applied to screen training data online. Therefore, KOSELM algorithm could be used to predict traffic flow and satisfy the robustness requirement.
In addition, it has been well known that traffic flow data at intersections are non-stationary time series, affected by many factors. So, priori analysis on fluctuation characteristics of traffic flow could contribute to improving prediction accuracy. As an adaptive decomposition method for analyzing nonlinear and non-stationary signals, empirical mode decomposition (EMD) 23 had the multi-resolution advantages of wavelet transform and overcame the drawbacks of selecting wavelet and decomposition scale. But the disadvantage of EMD method was prone to arising modal aliasing phenomenon. In order to overcome the shortcoming, Wu and Huang 24 put forward ensemble empirical mode decomposition (EEMD) method. However, the results still included a certain amount of residual noise. Complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) 25 method was the improvement of EEMD, which solved the problem of adding different signal noises to different intrinsic mode function (IMF) components and the reconstruction errors were almost zero. This technique has been applied to several research fields such as biomedical engineering, 26 seismology,27,28 and building energy consumption. 29 Despite this, CEEMDAN algorithm still needed to be improved. There were still residual noise components in the decomposition components. In addition, components had been assumed in the early signal decomposition stage. In order to overcome the above shortcomings, Colominas et al. 30 improved CEEMDAN algorithm and proposed improved complete ensemble EMD (ICEEMDAN) algorithm to obtain less noise and make sequence decomposition more efficient. Thus, there are reasons to believe that ICEEMDAN algorithm can be applied for priori analysis on fluctuation characteristics of traffic flow effectively.
The main objective of this article is to propose a new hybrid short-term traffic flow prediction model named ICEEMDAN-KOSELM-ARIMA employing ICEEMDAN algorithm and KOSELM algorithm, combined with ARIMA algorithm, to improve prediction accuracy of short-term traffic flow. The KOSELM-ARIMA model can achieve a better prediction performance for the reason that the original traffic flow data have been decomposed and the random properties are analyzed by ICEEMDAN-PE algorithm. The novelty of the proposed model is highlighted in the following aspects:
The ICEEMDAN algorithm as a relatively novel adaptive decomposition method is first employed to decompose traffic flow time series data and obtain multiple IMF components.
The permutation entropy (PE) algorithm as an effective randomness and dynamic mutation characteristic analysis method is applied to analyze the randomness of IMF components.
According to different random properties of IMF components, hybrid short-term traffic flow prediction process and model are established.
KOSELM prediction models are built for the IMF components with big randomness, and ARIMA prediction models are built for the IMF components with small randomness.
Several different prediction models are constructed, respectively, to compare and analyze the prediction performance for a real signalized intersection.
The rest of this article is organized as follows. Section “Traffic flow decomposition and random property analysis based on ICEEMDAN-PE algorithm” formulates traffic flow decomposition and random property analysis based on ICEEMDAN-PE algorithm, including traffic flow decomposition by ICEEMDAN algorithm presented in section “Traffic flow decomposition by ICEEMDAN algorithm” and random property analysis by PE algorithm presented in section “Random property analysis of decomposed traffic flow sequences by PE algorithm.” In section “Hybrid traffic flow prediction model based on ICEEMDAN-KOSELM-ARIMA,” hybrid traffic flow prediction model is established based on ICEEMDAN-KOSELM-ARIMA, including KOSELM prediction model building presented in section “KOSELM prediction model building” and hybrid prediction model building presented in section “Hybrid prediction model building.” In section “Model verification,” the model proposed in this article is verified by choosing a typical intersection, including traffic flow sequence decomposing by ICEEMDAN algorithm and randomness analysis in section “Traffic flow sequence decomposing by ICEEMDAN algorithm and randomness analysis by PE algorithm” and prediction model building and results analysis presented in section “Prediction model building and results analysis.” And prediction results are compared with other traditional models. Section “Conclusion” reveals the conclusions and recommendations for future research.
Traffic flow decomposition and random property analysis based on ICEEMDAN-PE algorithm
Traffic flow time series of intersection is decomposed by ICEEMDAN algorithm first. In order to analyze the random characteristics of traffic flow IMF components, PE algorithm is employed to calculate permutation entropies according to the diversity of different IMF components, preparing to establish prediction models.
Traffic flow decomposition by ICEEMDAN algorithm
The constraint of Fourier transform is gotten rid of by EMD algorithm fundamentally, which gives a good interpretation of instantaneous frequency. Unlike wavelet transform, the decomposition of EMD method does not need a priori basement. And signal time sequences can be broken down into a number of IMF components with adaptability. The IMF components own different scales and have little impact on each other. As the signal sequences change, the IMF components obtained by EMD method change. Then, the interference or coupling relationship between system feature information can be simplified. 23 In conclusion, the nature of EMD method is to decompose original sequence in accordance with the fluctuations in different scales and obtain IMF components with different amplitudes. By adding adaptive white noise in each stage of decomposition, the only allowance is calculated by CEEMDAN algorithm to gain IMF components. 23 However, ICEEMDAN algorithm 30 defines the true mode as the difference between the current residue and the average of its local means by estimating the local means of each signal plus noise realization.
The original traffic flow sequence is represented by
Step 1. Same as EMD method,
23
the first residue sequence is calculated through the local means of the decomposition results

Step 2. The first IMF component can be calculated in the first stage (

Step 3. Calculate the second traffic flow residue sequence and set it as the average local means of the flow sequence
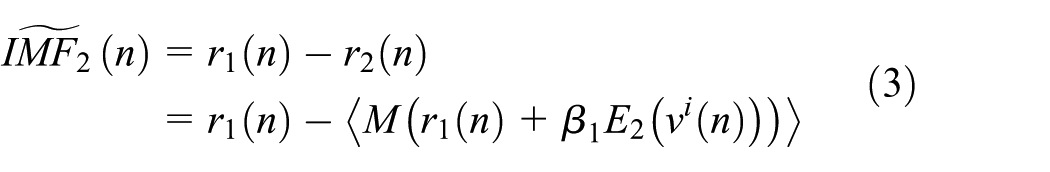
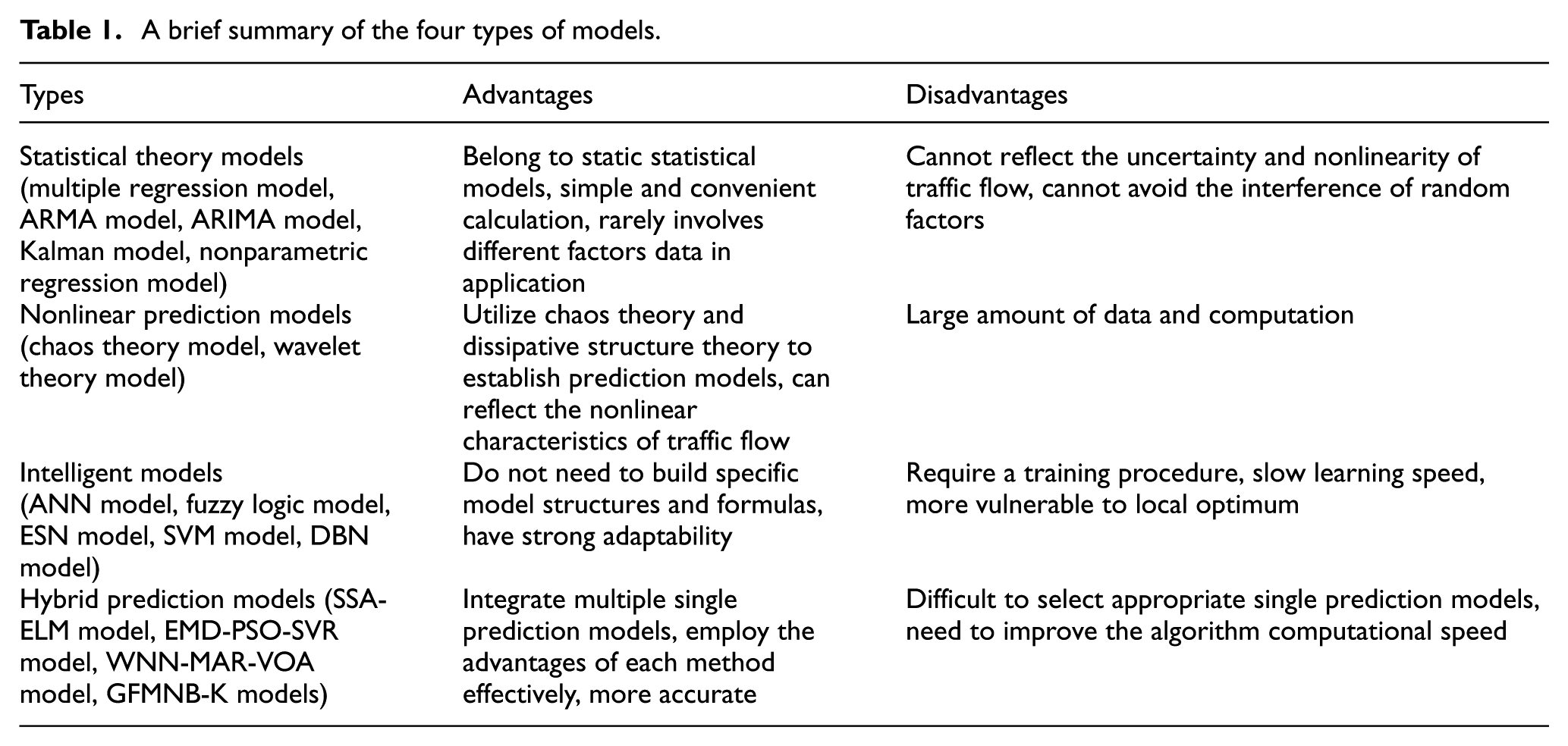
Step 4. Similarly, the

Step 5. Calculate the Kth modal components as formula (5)

Step 6. Return to Step 4 to continue the algorithm. When the obtained residue sequence cannot be decomposed, the algorithm is over.
From the steps above, it is not hard to find that the decomposition process of ICEEMDAN algorithm is complete and the original traffic flow sequence can be decomposed precisely.
Random property analysis of decomposed traffic flow sequences by PE algorithm
It is known that traffic flow time series is usually non-stationary, leading to several IMF components decomposed by ICEEMDAN algorithm. In order to reduce computing scale, PE algorithm is employed to analyze the random properties of traffic flow IMF components. The IMF components with different randomness are put into different prediction models and prediction results would be added together to obtain final prediction values.
PE algorithm is a new algorithm, proposed by Bandt and Pompe 31 in recent years to measure the complexity of system. Similar to Lyapunov index, Kaplan–Yorke dimension, and correlation dimension, permutation entropy is also used to characterize randomness and dynamic mutation characteristics of time series. The concept of PE algorithm is simple and computing speed is fast. Besides, it has strong anti-interference ability, especially suitable for nonlinear data. Because of the high sensitivity to the change of time sequence and good robustness, PE algorithm has been widely applied to many kinds of time series. 32 It is well known that traffic flow at signalized intersection is a typical data which has a certain randomness and non-stationary. As a result, PE algorithm is suitable for analyzing the randomness of traffic flow decomposed sequences. The specific calculation steps are as follows:
Step 1. Phase-space reconstruction theory is applied to process the IMF sequences

where m and
Step 2. Take each row of matrix Y above as a component. Then, a total of K components could be obtained. By the phase-space reconstruction theory, formula
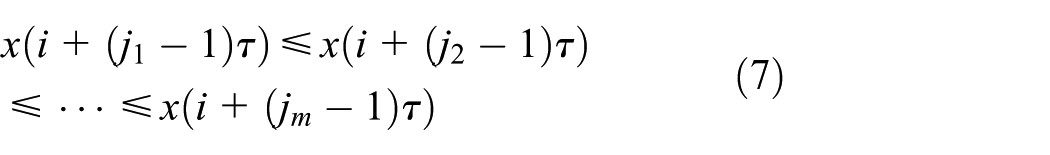
where

where formula
Step 3. Calculate the appearing probability of each symbol sequence

From the formula above, it can be concluded that when

where
Through the steps above, the permutation entropy of each IMF component can be calculated. Considering the decomposition results of ICEEMDAN algorithm comprehensively, the randomness of IMF components can be analyzed which provides the basis for establishing hybrid prediction models.
Hybrid traffic flow prediction model based on ICEEMDAN-KOSELM-ARIMA
According to the randomness of IMF components analyzed by PE algorithm, the IMF components with big randomness are put into KOSELM prediction models and the other IMF components with small randomness will be put into ARIMA models. Through adding multiple traffic flow prediction results together, the final predicted traffic flow can be gained.
KOSELM prediction model building
The original kernel extreme learning machine (KELM) algorithm is an offline algorithm, which needs to obtain all the training data before the algorithm starts. However, the calculation of matrix inverse process in the learning algorithm will be larger when dataset is too large, leading to insufficient storage. Furthermore, the samples of time series are often obtained in a single or group in prectical problems, which requires real-time online learning. OSELM algorithm is the improvement of ELM algorithm. Current batch data are the only input in training process. Network weights are updated without repeating to scan historical data, having strong generalization ability. Based on the two algorithms, kernel fuction is brought in OSELM algorithm and KOSELM algorithm is proposed, which can filtrate training data online. 22
The input parameters of the algorithm are kernel function
Step 1. Initialize matrix Q using the first sample as formula (11)

Step 2. Calculate the weight vector
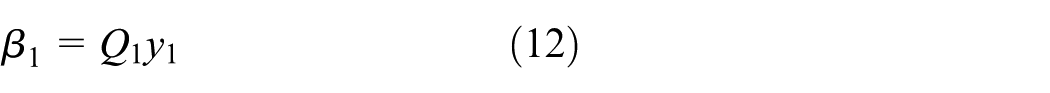
Step 3. Calculate the kernel function matrix of each sample, from the second sample

Step 4. Calculate the intermediate variable matrix

Step 5. Calculate the coefficient

Step 6. Calculate and update matrix

Step 7. Calculate filter error

Step 8. Update weight vector

Step 9. Return to Step 3 to continue the algorithm. The whole algorithm will end until the nth sample
In the steps above, variables
Hybrid prediction model building
Through the analysis above, intersection short-time traffic flow hybrid prediction model ICEEMDAN-KOSELM-ARIMA could be built, of which the specific process is shown in Figure 1.

Process of hybrid short-term traffic flow prediction model (ICEEMDAN-KOSELM-ARIMA).
First, ICEEMDAN algorithm is applied to decompose the original intersection traffic flow time series as shown in section “Traffic flow decomposition by ICEEMDAN algorithm” and several IMF components are obtained. In order to calculate the permutation entropy of each IMF component, PE algorithm is employed as shown in section “Random property analysis of decomposed traffic flow sequences by PE algorithm.” According to the difference of permutation entropies for IMF components, the randomness of IMF components can be analyzed.
In order to improve prediction accuracy, IMF component sequences are normalized as formula (19) before building prediction models

where
After normalization, the IMF component sequences with big randomness are put in KOSELM prediction models and the IMF component sequences with small randomness are put in ARIMA prediction models. Multiple prediction results of traffic flow sequences would be obtained.
Use formula (20) to get converse normalized results of the predicted IMF components
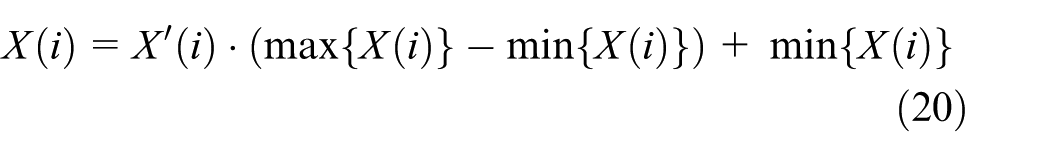
Add the results of each IMF component sequence together to get the final traffic flow prediction results.
Model verification
A typical intersection is selected to validate the proposed short-term traffic flow prediction model. The geometry characteristic information of the intersection which has four import approaches in total is shown in Figure 2. The intersection adopts pre-timed signal control scheme. There are two phases. The first phase is used to release the straight traffic flow in eastern and western approaches. The second phase is used to release the straight and left traffic flow in southern and northern approaches.
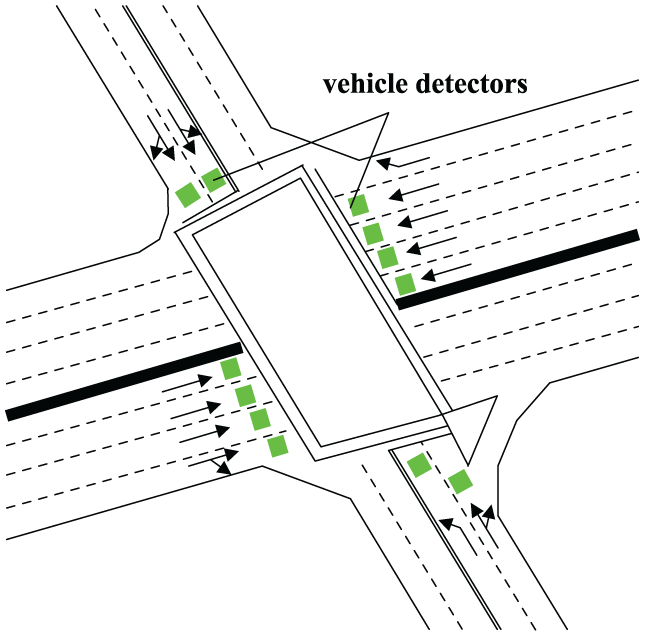
Geometry information of the intersection.
Under the influence of various factors such as signal timing, intersection traffic flow often has some characteristics of nonlinearity and uncertainty. In addition, it can be found that traffic flow has similar cycle characteristics by drawing time series curve of collected traffic flow within a certain time. What is more, the traffic flow and change rules of working days (Monday to Friday) are more similar, which is the same as the characteristic of traffic flow on weekends (Saturday and Sunday). It has been well known that one of the main applications of intersection traffic flow data is signal timing parameter optimization. And traffic flow is usually distinguished through driving direction. Therefore, traffic flow data of five continuous working days with 5 min interval are collected and analyzed by taking the straight flow in eastern approach as an example.
The original traffic flow data collected by vehicle detectors are preprocessed first. Threshold value method is employed for detecting and eliminating abnormal data, and the missing data are repaired based on historical data. Through data processing, a total of 1440 traffic flow data points can be obtained. Among the data, the 1152 traffic flow data points of the first four working days are used to establish the prediction model and the 288 traffic flow data points of the fifth working day are applied to validate the prediction performance of the proposed model. The intersection traffic flow distribution characteristic of the straight flow in eastern approach at the interval of 5 min is shown in Figure 3.

Traffic flow distribution at the interval of 5 min.
Traffic flow sequence decomposing by ICEEMDAN algorithm and randomness analysis by PE algorithm
Through MATLAB programming, ICEEMDAN algorithm is employed to decompose the original intersection traffic flow sequence. The input data of the algorithm are 5 min traffic flow time series and output is IMF components. The decomposition results are shown in Figure 4, in which symbols IMF1 to IMF9 indicate nine IMF components of intersection traffic flow decomposed by ICEEMDAN algorithm. In the decomposition process of intersection original traffic flow time series, 500 groups of white noise signal are added, of which the standard deviation is 0.2. From Figure 4, it can be concluded easily that the original traffic flow sequence can be decomposed into nine IMF components of which the randomness properties are different, providing basis for the construction of subsequent hybrid prediction model.

Intersection traffic flow data decomposition results by ICEEMDAN.
Relative percentage errors of the traffic flow sequences decomposed by ICEEMDAN algorithm are demonstrated in Figure 5. Figure 6 shows the iteration boxplot of IMF components. From the figures, it can be easily concluded that the decomposition relative percentage error of original traffic flow time series is very small, reaching a level of 10−12. From Figure 6, it can be seen that the iteration times of IMF components decrease with the decomposition process until it reaches zero. It illustrates that the traffic flow sequence is decomposed completely, which proves the effectiveness of the model.
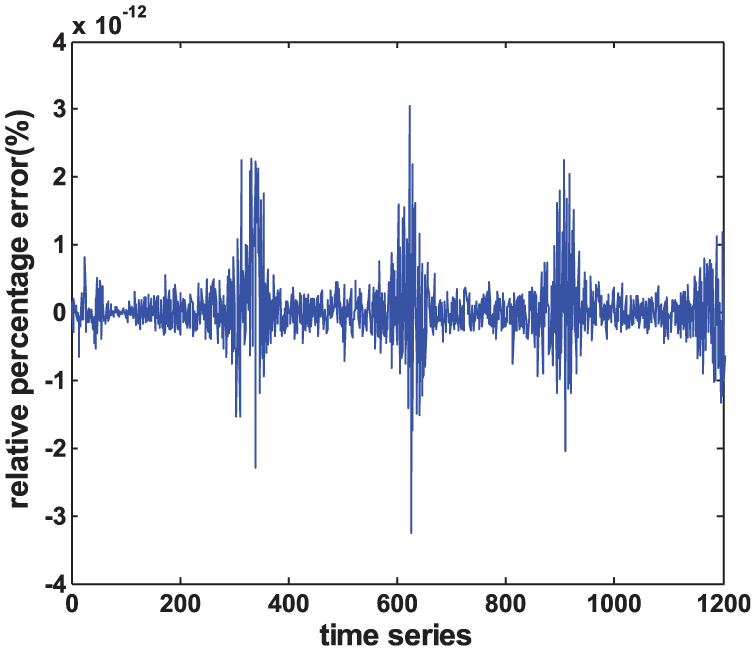
Relative percentage errors of ICEEMDAN algorithm.

Iteration boxplot of IMF components.
As stated earlier, in order to reduce computing scale and improve running efficiency, the randomness of IMF components needs to be analyzed. As a result, permutation entropies of IMF components are calculated by applying PE algorithm. First, each IMF component is dealt with phase-space reconstruction. For improving computing efficiency, embedding dimension is set to
Permutation entropy values of IMF components.


Standardized permutation entropy values of IMF components.
Taking the decomposition results and permutation entropy values into account, random characteristics of IMF components are analyzed. From Table 2 and Figure 7, it is not hard to find that the permutation entropy of IMF1 is the biggest. Furthermore, with the increase in IMF component number, permutation entropy values decrease, which shows that the randomness of IMF sequences weakens gradually. The components from IMF1 to IMF4 have the bigger randomness, mostly affecting the prediction results. As a consequence, the components are put into KOSELM prediction models, respectively. The permutation entropy values of IMF5 to IMF9 are smaller, indicating the randomness is weaker. So, the components from IMF5 to IMF 9 are put into ARIMA prediction models, respectively. In conclusion, two types of prediction models are built to realize the hybrid prediction of traffic flow at signalized intersection.
Prediction model building and results analysis
In order to establish intersection traffic flow prediction model, traffic flow single-step rolling prediction method is employed, using historical data to predict the traffic flow of the next moment. Take the traffic flow sequence 2 h before the predicted point as the model input. And the predicted traffic flow sequence would be the model output. Based on the above rules, 1152 traffic data points of the first four working days could build 1128 input–output datasets, making up training set of the model. Traffic flow dataset is divided into training set and test set and the ratio is 4.
To verify the effectiveness of the proposed model in this article, several different prediction models are constructed, respectively, to compare and analyze the prediction effects, including traditional ARIMA model, BP model, ELM model, and KOSELM model. In addition, considering the integrity of validation, ICEEMDAN-ELM model and ICEEMDAN-KOSELM model are built to prove the effectiveness of the ICEEMDAN algorithm. It is known that ARIMA model is suitable for stationary time series and it requires difference processing for non-stationary time series to transform it into a smooth sequence. It is worth noting that apart from ARIMA model, other models are all intelligent learning models.
Original traffic flow sequence is applied to build ARIMA, BP, ELM, and KOSELM prediction models. Decomposed intersection traffic flow subsequences obtained by ICEEMDAN algorithm are used to construct ICEEMDAN-ELM model, ICEEMDAN-KOSELM model, and ICEEMDAN-KOSELM-ARIMA prediction model. SPSS software is employed to establish ARIMA prediction model, while MATLAB software is used to build other prediction models.
ARIMA prediction model requires stationary sequences, so the data should be analyzed for stationarity. We all know that traffic flow data sequence is usually non-stationary which is also proved by drawing autocorrelation graph and partial autocorrelation graph. However, the sequences after first-order difference processing are stable generally. Experiment also shows that the first difference sequence is stationary. Therefore, ARIMA (p, 1, q) model can be established for the original sequence. After repeated tests, the prediction model is determined to be ARIMA (1, 1, 1). To establish BP prediction model, a typical single-layer neural network model with 10 hidden layer neurons is selected in this article. The network is trained for 1000 epochs and the minimum error of training goal is set to 0.001. Training display frequency is set to 10 and learning rate is set to 0.1.
It is known that ELM algorithm generates the connection weight between input layer and hidden layer randomly, as well as the threshold value of hidden layer neurons. Moreover, no adjustment is needed in the training process. A unique optimal solution can be obtained by setting the neuron number of the hidden layer only. Therefore, for ELM prediction model, the only parameter to be determined in advance is the neuron number of the hidden layer which is denoted by L. Cross-validation method is used to select optimal parameter L which has the minimum error. Through experiment, the optimal hidden layer neuron number L for ELM model is set to 30. Since short-term traffic flow prediction is attributed to regression and fitting problems, the parameter application TYPE is set to the default value 0. Sigmoid function is chosen as the activation function.
Besides, to build KOSELM model and the proposed hybrid prediction model in this article, “rbf” is selected as the kernel function type. Moreover, kernel parameter is searched uniformly in the range
Four predictive evaluation indexes are chosen to compare and analyze the prediction effects of each model, including mean absolute error (MAE), mean absolute percentage error (MAPE), mean square error (MSE), and equal coefficient (EC). The evaluation indexes can be calculated as formulas (21)–(24)




where
Traffic flow prediction effect curves for different models are shown in Figure 8, and absolute error curves are shown in Figure 9. In Figure 8, the X-axis represents the 24 hours on the fifth day of which the traffic volume needs to be predicted. The Y-axis represents the traffic volume at the interval of 5min. In Figure 9, the X-axis represents the real value of traffic flow and the Y-axis represents the predicted value obtained by different prediction models. Table 3 shows the comparisons of prediction performance indexes of different prediction models. From Figure 8, it can be easily concluded that compared with other prediction models, the fitting degree between the predicted traffic flow values and the real traffic flow values of the proposed hybrid ICEEMDAN-KOSELM-ARIMA prediction model is the best. Figure 8(a)–(d) indicates that the prediction performance of KOSELM model is superior to other models including ARIMA model, BP model, and ELM model. Through Figure 8(c)–(f), it can be concluded that for the same model, the prediction accuracy of the models with ICEEMDAN sequence decomposition process is significantly improved.
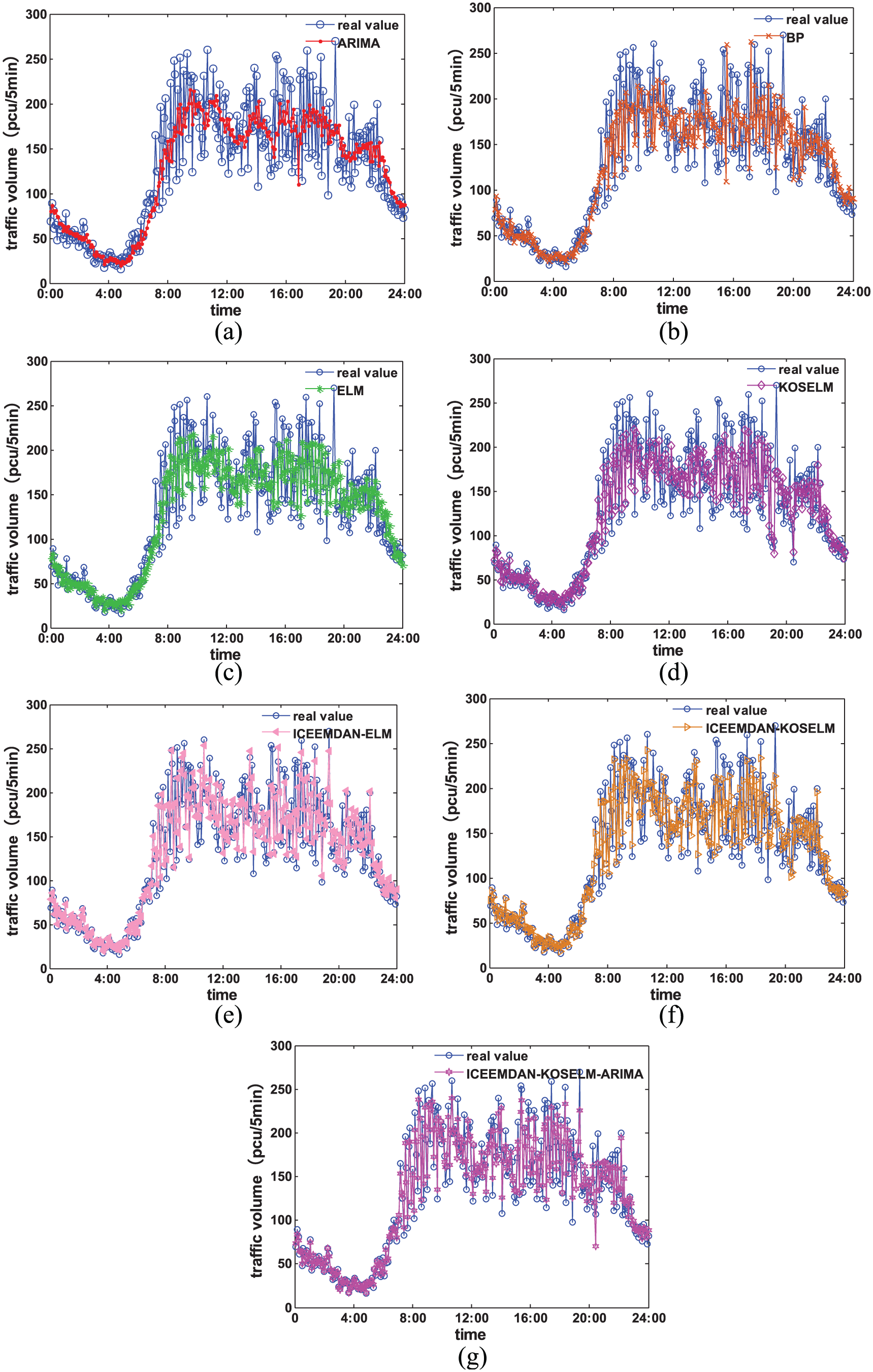
Prediction results of different models.

Comparison between predicted traffic flow values and real values of different models.
Comparisons of prediction performance indexes of different prediction models.

MAE: mean absolute error; MAPE: mean absolute percentage error; MSE: mean square error; EC: equal coefficient; ARIMA: auto-regressive integrated moving average; BP: backpropagation; ELM: extreme learning machine; KOSELM: kernel online sequential extreme learning machine; ICEEMDAN: improved complete ensemble empirical mode decomposition with adaptive noise.
From Figure 9, the prediction fitting degree of ARIMA model to real value is the lowest, and the prediction deviation degree is the highest. The prediction fitting degree of BP model, ELM model, and KOSELM model to real values is improved gradually, of which deviation degree is still high compared with ICEEMDAN-ELM model and ICEEMDAN-KOSELM model after sequence decomposition process. The proposed hybrid prediction model ICEEMDAN-KOSELM-ARIMA performs better than ICEEMDAN-ELM model and ICEEMDAN-KOSELM model, with the minimum prediction errors. It proves that the proposed hybrid model could make use of the advantages of KOSELM model in dealing with sequences having big randomness and ARIMA model in dealing with sequences having small randomness. In conclusion, the prediction deviation degree of ICEEMDAN-KOSELM-ARIMA to real values is lowest, proving the validity of the model.
In addition, Table 3 shows that the MAPE and MSE values of the proposed ICEEMDAN-KOSELM-ARIMA model are both lower than other models, indicating that the prediction errors are the least and the prediction accuracy is the highest. Although the MAE values of ICEEMDAN-KOSELM-ARIMA model are slightly higher than ICEEMDAN-KOSELM, other indicator values are better than ICEEMDAN-KOSELM model. Besides, EC value for the new proposed model is 0.957, which is greatly higher than that of traditional ARIMA model (0.898). Compared with other models, the EC value is the most closest to 1, indicating that the prediction performance is the best and has better stability. In terms of the same model, the model which is processed by ICEEMDAN algorithm has better prediction performance.
In conclusion, the hybrid intersection short-term traffic flow prediction model based on ICEEMDAN-KOSELM-ARIMA model has good prediction performance and can meet prediction requirements.
Conclusion
Focused on historical intersection traffic flow time series, a new hybrid short-term traffic flow prediction model based on ICEEMDAN-KOSELM-ARIMA is put forward in this article. Considering the nonlinear and stochastic characteristics of intersection traffic flow, original flow sequence is decomposed by ICEEMDAN algorithm first. To analyze the random properties of IMF components, PE algorithm is employed to calculate the permutation entropies. Then, different prediction models are established according to different randomness of IMF components. KOSELM prediction models are established for the IMF components with big randomness. ARIMA prediction models are established for the IMF components with small randomness. The multiple predicted results are added together to obtain the final predicted traffic flow. Finally, traffic flow data of five consecutive working days at a typical intersection are collected to validate the performance of the new proposed hybrid model. In order to compare the model effect, several prediction models are built. Results show that compared with other classical prediction models, the performance indexes of the proposed model in this article are lowest and has the best fitting degree to actual values. Besides, the absolute error range of the model based on ICEEMDAN-KOSELM-ARIMA is less than other models, improving prediction accuracy effectively. Then, the effectiveness of the algorithm in this article is proved.
In this article, many parameters are evaluated according to the existing literature in establishing the prediction models. Besides, the traffic dataset used in this article is a little bit limited. The verification data used for the proposed model are only the traffic flow at the intersection. And the traffic flow has obvious periodic characteristics. Limited by the experimental conditions, the proposed model has not been verified by freeway traffic flow in this article. Because of the limitations, it is advisable to build different traffic flow prediction models by taking parameter optimization into consideration with more field data collection efforts in the future research. Moreover, model verification will be carried out for traffic flow data with different periodic characteristics and freeway traffic flow data.
Footnotes
Acknowledgements
The authors thank the valuable comments from the editor and reviewers.
Handling Editor: Crinela Pislaru
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been supported by the National Key Technology Research and Development Plan Project (Grant No. 2014BAG03B03).