
Abstract
Diagnostic health monitoring without prior knowledge is still a hard problem in the prognostic and health management field. A multivariate diagnostic health monitoring strategy is proposed based on telemetry data for in-orbit spacecrafts with component degradation. Compared with the existing univariate or direct diagnostic health monitoring methods, multivariate diagnostic health monitoring methods can avoid constructing one-dimensional synthesized health index and setting empirical thresholds for different health states. In our developed strategy, a deep forest algorithm combined with an effective feature extraction approach and fuzzy C-means clustering algorithm is proposed to achieve more accurate assessment of the current health state. First, a partitioning window is utilized to deal with the raw telemetry data and then features which have high monotonicity and trends are extracted for diagnostic health monitoring. Then, a fuzzy C-means algorithm is used to handle unlabeled telemetry data and determine states of degrading component. Finally, a deep forest classifier is adopted to obtain the prognostic model for online probabilistic diagnostic health monitoring. Verification results on a simulated spacecraft attitude control system can demonstrate the effectiveness and feasibility of the proposed multivariate diagnostic health monitoring strategy.
Introduction
Prognostic and health management (PHM) technology is important to various spacecrafts for successful task management, orbital maintenance, and service life prolongation. PHM technologically focuses on predicting the health status of a system by assessing the deviation from the expected normal operating condition. The deviation is usually caused by faults, failures, or component degradations. 1 Specifically, PHM can be used for two purposes: 2 diagnostic health monitoring and prognostic health monitoring. Diagnostic health monitoring is to evaluate the current health status of a component, subsystem, or system, whereas prognostic health monitoring is to predict the future trends of the degradation process and the remaining useful life. This article focuses on developing a novel and effective strategy for diagnostic health monitoring of in-orbit spacecrafts.
The existing diagnostic health monitoring approaches are generally classified into three major categories: physical model-based approaches,3–5 data-driven approaches,6–8 and hybrid approaches.9–11 Physical model-based approaches require the physical understanding of the object and can be successfully applied to material-level or component-level objects. However, these techniques are rarely used for macro levels, such as systems or subsystems. Because obtaining system-level models for diagnostic health monitoring with affordable efforts is difficult or even impossible in many large-scale applications. Data-driven approaches fulfill diagnostic health monitoring using data mining, pattern recognition, and machine learning techniques to the accessible life cycle data of the object. Hybrid approaches are developed based on available multi-source information, including physical model, operating data, or expert knowledge. For in-orbit spacecrafts, many telemetry data containing rich information on the health states are available. Therefore, data-driven approaches are usually utilized for the diagnostic health monitoring of spacecrafts.
Data-driven approaches for diagnostic health monitoring can be further categorized into the following groups: univariate health index–based approaches, 12 direct approaches, 13 and multivariate approaches. 14 Univariate approaches need to establish a one-dimensional (1D) synthesized health index (SHI) using linear regression, 15 principal component analysis (PCA),2,16 and Mahalanobis distance.17,18 The thresholds for identifying different health states of the devices or systems during their life cycles must be predefined. However, constructing effective SHIs and defining accurate thresholds are difficult because of time-varying operating condition, environment, noisy measurements, and high-level uncertainties in real applications. The direct approaches achieve diagnostic health monitoring by matching the current observation trajectories with the most similar historical trajectories. However, complete run-to-failure data are rare, and similarity searching 19 can be time-consuming, for systems with numerous variables. Multivariate approaches7,20,21 are newly emerging techniques that automatically divide the health degradation process into several stages using unsupervised clustering algorithms and then label the current health state by searching the nearest cluster. Compared with the former two approaches, the multivariate approaches do not need to establish a 1D SHI, predefine the thresholds of different health states, or have a large number of similar historical samples. However, the existing multivariate approaches rarely consider the uncertainties of different health states and health state switching process. Moreover, many unsolved problems still exist in real applications. 20
For in-orbit spacecrafts, the health-relevant telemetry data often have the following features:
1. Multi-dimensional degradation signals.
We take attitude control system (ACS) as an example. The ACS contains controller, flywheel, and other components. Therefore, the collected telemetry data from ACS is multi-dimensional. In addition, one component degradation signal can influence other components due to the failure propagation of closed-loop structure. These component signals having degradation features are called multi-dimensional degradation signals.
2. Multi-domain degradation features.
The degradation feature of one component signal may not be evident due to noise masking and closed-loop compensation. Therefore, the raw signal should be excavated in multiple domains (time, frequency, and time–frequency domains). These excavated features of one component signal may directly reflect the degradation phenomenon. This is called multi-domain degradation features.
3. Huge unlabeled and unbalanced data.
No indicator can directly represent the health states or transitions between different health states due to the lack of available prior knowledge. This is called unlabeled problem. In addition, the telemetry data are not well balanced temporally or spatially, which is called unbalanced problem in the field of machine learning. For example, abundant data can be found for health or subhealth status during their life cycles, whereas the data close to the failure stage of degradation is extremely rare.
4. High-level uncertainties.
Spacecrafts’ health monitoring is affected by various sources and high-level uncertainties. Spacecrafts have different in-orbit tasks, which usually change orbit altitude and condition environment. This kind of uncertainty is induced by environmental and operational conditions. Furthermore, ground station observation limit, closed-loop compensation, and different initial stages are also the sources of different uncertainties. In addition, the difficulty of constructing SHIs and the dynamics of health thresholds also cause these uncertainties.
A feasible and effective data-driven diagnostic health monitoring strategy for in-orbit spacecrafts is needed to solve the following basic problems:
How to extract multi-domain health-degradation-relevant features from massive multivariate telemetry data?
How to deal with huge unlabeled and unbalanced telemetry data of spacecrafts?
How to deal with the uncertainties in telemetry data?
In order to solve the shortcomings of the existing multivariate approaches and real application restricts, a feasible and effective multivariate diagnostic health monitoring strategy for in-orbit spacecrafts based on deep forest is proposed in this article. First, a multi-domain feature extraction and evaluation method is proposed to automatically extract health-degradation-relevant features. A fuzzy C-means clustering (FCM) algorithm is then utilized to deal with the huge unlabeled and unbalanced telemetry data of spacecrafts by dynamically dividing the health states into four stages. Finally, a deep forest classifier is adopted for the probabilistic assessment of health states, and the probabilistic results can represent the uncertainties of health state switching process.
The remainder of this article is organized as follows. Section “Multi-domain degradation feature extraction and evaluation” presents a multi-domain degradation feature extraction method. Then, a multivariate diagnostic health monitoring approach is proposed in section “Multivariate diagnostic health monitoring based on deep forest classifier,” using a deep forest classifier combined with an FCM algorithm. Verification results are shown in section “Verification,” by a simulation platform of satellite ACS with gyroscope degradation. Finally, conclusions are drawn in section “Conclusion.”
Multi-domain degradation feature extraction and evaluation
Degradation feature extraction and evaluation are the foundation of diagnostic health monitoring. In general, the features with high monotonicity and trends can reflect the degradation of a system’s health performance. In this section, multi-domain features are extracted from the telemetry data. Given that the multi-domain features of each variable can be highly redundant, feature evaluation is necessary to select the most representative features and guarantee the efficiency of the proposed method. In this article, a strategy (Figure 1) is proposed. This strategy contains telemetry data preprocessing (data compression), multi-domain feature extraction, and feature evaluation (smoothing, feature selection, cumulative sum, and normalization).

The strategy of multi-domain degradation feature extraction and evaluation.
Telemetry data preprocessing
The available telemetry data can be arranged into three-dimensional (3D) data

The schematic of telemetry data.
When
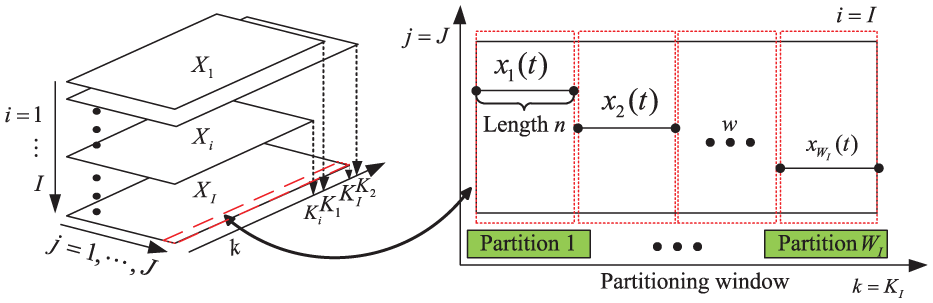
Partitioning window for data compression.
Multi-domain feature extraction
Time-domain features
In this section, each time series
Time-domain statistical characteristic parameters.

Frequency-domain features
In-orbit spacecraft’s telemetry data often exhibit complicated periodicity due to its orbital period, the observation period, and the rhythm of day and night. The health degradation process may be influenced by certain periodical features, so frequency-domain features should be extracted to reveal some useful information uncovered in the time-domain features. In this article, five typical frequency-domain features22,23 are listed in Table 2. Frequency center, mean square frequency, and root mean square frequency show the position changes of the main frequencies. Root mean square frequency, variance frequency, and root variance frequency describe the convergence degree of the spectrum power.
Frequency-domain statistical characteristic parameters.

Time–frequency-domain features
For non-stationary and non-periodic signals, time–frequency-domain analysis is more suitable than time-domain or frequency-domain analysis. The most common approaches of time–frequency-domain analysis are empirical mode decomposition (EMD), wavelet transform (WT), and wavelet packet transform (WPT). EMD is time-consuming and is not suitable for plenty of telemetry data. Compared with WT, WPT is a precise signal analysis method. Therefore, the WPT is adopted, and a four-level wavelet packet decomposition22,24 is employed according to engineering experience in this article. The length of partitioning window is enough for the four-level wavelet packet decomposition. Figure 4 shows the fourth-level WPT decomposition of the time series signal

where integers
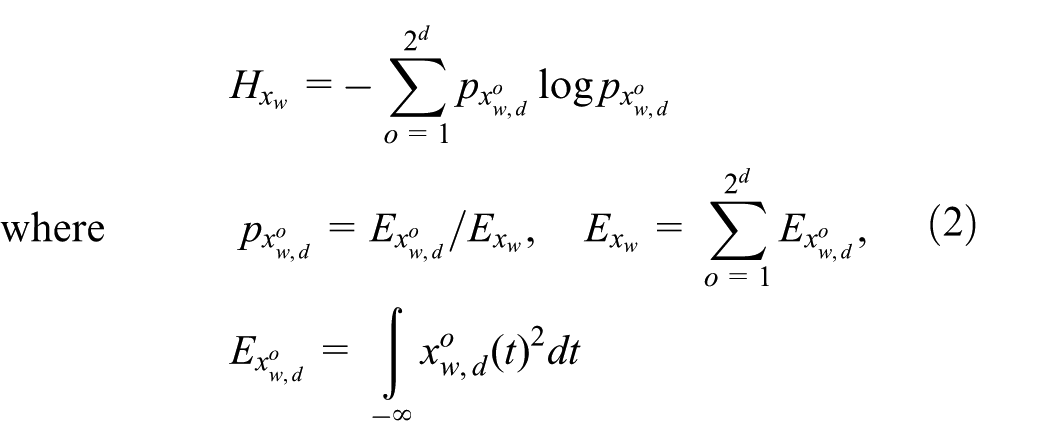
where

Diagram of four-level wavelet packet transform.
Feature evaluation
This section aims to eliminate the redundant features and maintain the most representative features to guarantee the efficiency of the online diagnostic health monitoring. Therefore, the main steps contain data smoothing, correlation calculation, feature selection, cumulative sum, and normalization.
First, feature smoothing 25 is suitable for feature selection and cumulative sum. The local regression using weighted linear least squares and a first-degree polynomial model 26 is then adopted. This method has the simplicity of the traditional linear regression and the flexibility of nonlinear regression.
Second, Spearman correlation coefficient method
27
is employed for feature selection. Spearman correlation analysis is an unsupervised feature selection method that does not have specific data condition, as compared with two other correlation analysis methods (Pearson and Kendall). Figure 5 shows the correlation calculation process of multi-domain features. Twenty-three multi-domain features

where
Correlation calculation process of multi-domain features.
Other time series correlation coefficients are calculated similarly as above, and 23 correlation coefficients
The feature selection for variable J can be considered as a multi-objective optimization problem that contains two constraint conditions. One is that each correlation coefficient absolute value of feature l in sample i must be greater than threshold

where
Third, the extracted features are calculated using a cumulative sum function.
25
The sum function furnishes a running total for a given time series
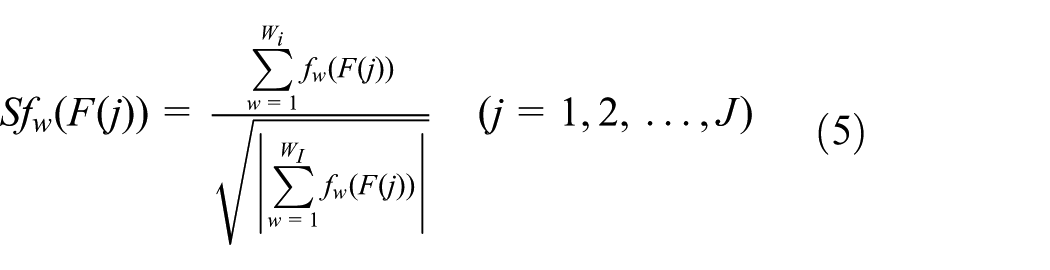
where
Finally, to solve the uncertainties caused by different initial stages and lengths of data sets, we reshape the 3D data


Normalization of three-dimensional data.
Multivariate diagnostic health monitoring based on deep forest classifier
Key idea
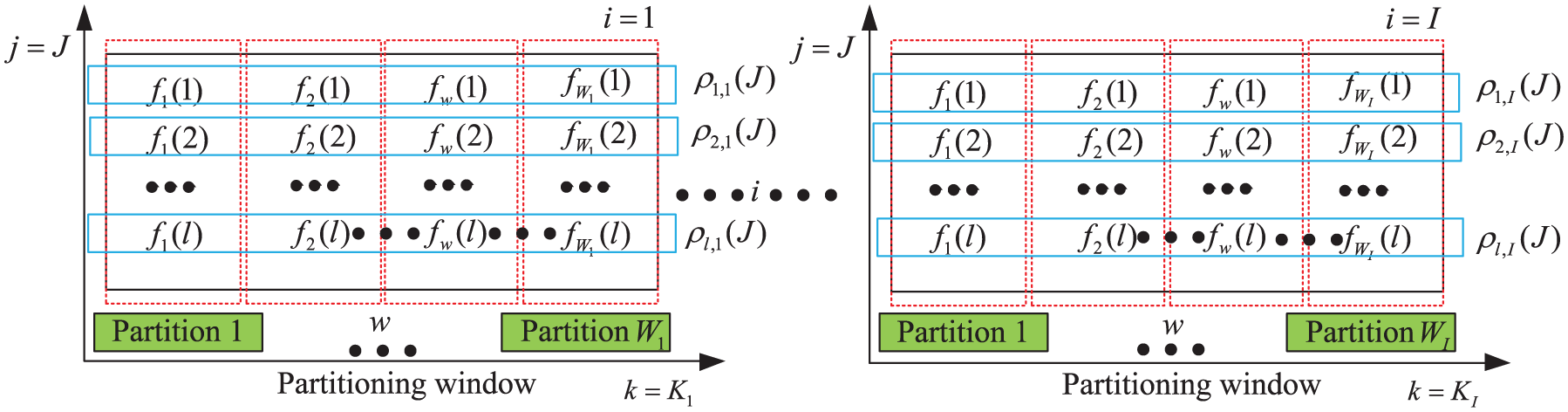
In multivariate health monitoring, the deep forest classifier 29 combined with FCM is adopted to assess the current health state, as shown in Figure 7. This method can be divided into two phases. Phase I provides the FCM algorithm for health state classification and avoids directly defining the empirical thresholds of different health states. Four health states (normal, slight damage, medium damage, and failure) are defined in this article. Phase II utilizes the deep forest classifier for offline training and online health state assessment.
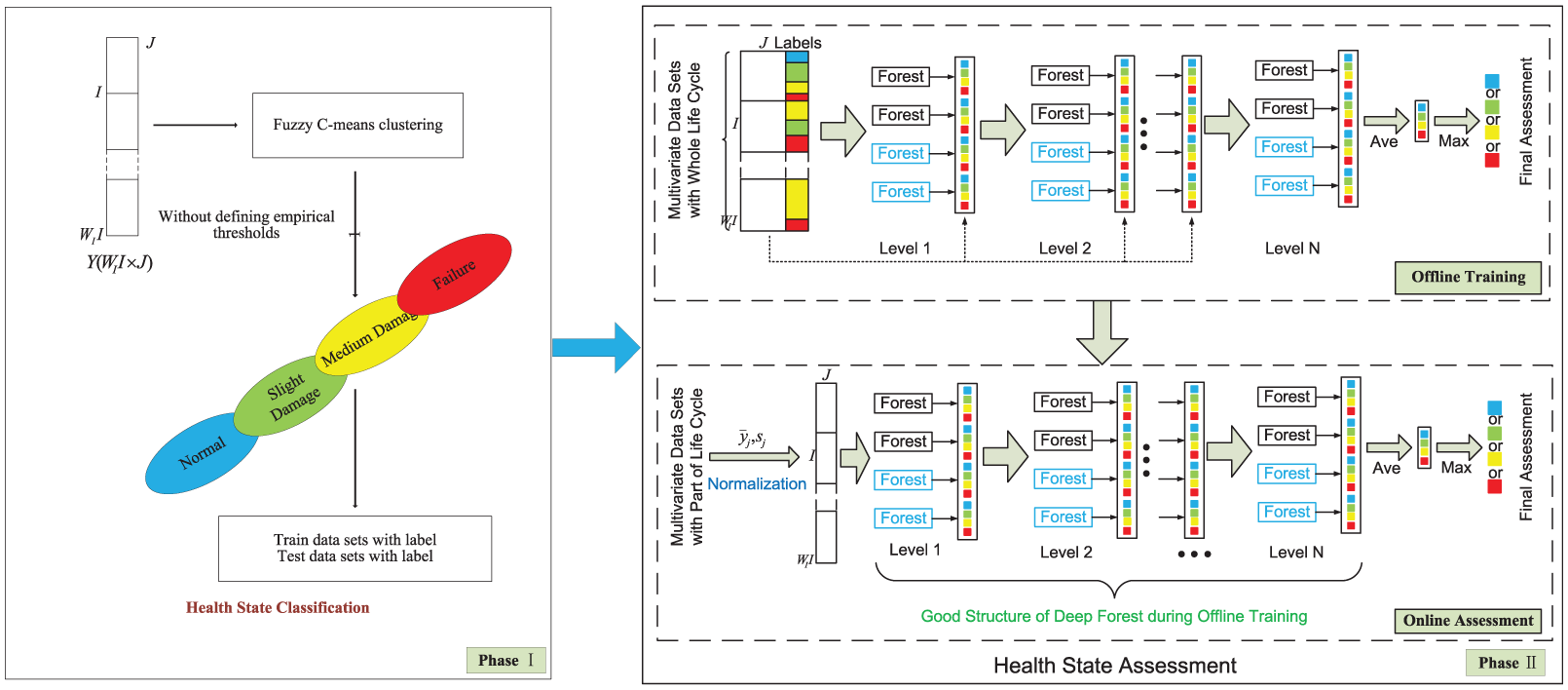
The scheme of multivariate diagnostic health monitoring based on deep forest.
Health state classification
Defining the different health states of degradation process is necessary to enhance the precision of multivariate diagnostic health monitoring modeling without expert knowledge. Moreover, dealing with the uncertainty of transitions among different health states is also important.
Therefore, we apply the FCM algorithm to solve this uncertainty due to fuzzy sets. FCM 30 is a clustering method that allows one piece of data to belong to two or more clusters. FCM is frequently used in pattern recognition. This clustering algorithm can also divide the expanded 2D-normalized data sets of degradation into four dynamic discrete health stages: normal, slight damage, medium damage, and failure, rather than static ones based on fixed values 31 and the assumed continuous observations.31–33 The method is suitable for degrading machinery, and the detailed descriptions of FCM are given below.
Given the 2D data sets

where b is set to 2;
Fuzzy partitioning is applied through an iterative optimization of the objective function as shown above, with the update of the cluster centers


This iteration stops when
Step 1: initialize
Step 2: at k-step, calculate the centers vectors
Step 3: update
Step 4: if
Diagnostic health monitoring
In Figure 7, the diagnostic health monitoring is divided into offline training and online assessment. In the offline training, data sets with whole life cycles are trained to acquire and save the good structure of deep forest. In the online assessment, data sets with part of life cycles are first normalized using
The deep forest classifier is inspired by the layer-by-layer structure of deep neural network. This algorithm employs a forest cascade structure, including two complete-random forests (black)
34
and two random forests (blue)
35
in each level as shown in Figure 7. Each complete-random forest or random forest contains huge complete-random decision trees or random decision trees. The number of trees in each forest is a hyper-parameter, and the value will be given later. Each complete-random tree is generated by randomly selecting a feature in each tree node. The tree then grows until each node contains the same instance or has no more than 10 instances. Similarly, each random decision tree is generated by selecting the optimal Gini value in

where
If the given sample set V is divided into

The
Each level cascade receives a feature vector generated by its previous level and outputs the processed feature vector to the next level. This cascade structure can usually guarantee to achieve a global solution.
Figure 8 gives the brief algorithm flow of deep forest classifier. The algorithm flow mainly contains multi-gained scanning, first-layer forest, and forest concatenate. In multi-gained scanning, the training data sets, and labels entered are divided into training samples and validation samples. Then, the algorithm uses sliding windows to cut time series sets, similar to convolutional neural network (CNN). In the first-layer forest, the time series sets are used to train random and complete-random forests. The out-of-bag estimation is then calculated. In forest concatenate, a new level is extended, and the accuracy of the cascade layer is evaluated. The assessment probabilities of this cascade layer are then provided, and the performance improvement is evaluated. If the performance is not obvious evident, then the assessment results are outputted. Otherwise, the forest concatenate is continued.

Algorithm flow of deep forest.
The deep forest can give a probabilistic assessment result. First, we introduce how each forest can generate possibilities of different classes as illustrated in Figure 9. In a forest, the input is the preceding-level feature vector and each tree can estimate the percentage of different classes at its leaf node. The forest can then generate the whole class distribution by averaging the above estimations of all trees. The generated class vector of different forests in the level is the input feature vector of the next level. When the performance improvement is not evident (similar to the above), the averaging class vectors of all forests in the last level become the final different class distributions. Finally, the maximum of different class distributions is the probabilistic assessment result. In this article, the parameters of the deep forest algorithm are shown as follows

where n_cascadeRF is the number of complete-random forests or random forests in a cascade layer; n_cascadeRFtree is the number of trees in a single random forest in a cascade layer; cascade_test_size is the split fraction for cascade training set splitting; and tolance is the accuracy tolerance for the cascade growth.

Probabilistic results of deep forest.
In conclusion, the implementation details of the deep forest based diagnostic health monitoring can be summarized in Algorithm 1.

Verification
ACS simulation platform
In this section, we utilize the ACS simulation platform to simulate and produce telemetry data. The minisatellite team (belongs to College of Astronautics, Nanjing University of Aeronautics and Astronautics) used stochastic hybrid automata (SHA) method to exploit the platform in MATLAB Simulink environment. This platform can simulate environmental disturbance, fault injection, and component degradation. Several control algorithms and fault diagnosis methods are studied and verified theoretically based on this platform before TX-1 minisatellite is sent into space.
This platform contains seven modules: PD control; four-inclined reaction wheel; triaxial magnetorquer; satellite kinematics and dynamics; triaxial star sensor; fiber optic gyroscope subsystem; and environment disturbance and orbit as shown in Figure 10. The symbol description of this platform is listed in Table 3. We use the platform to simulate the gradual degradation of gyroscope subsystem (Figure 11). The gyroscope subsystem is a hot-backup structure and has two gyroscopes in each axis. In each simulation, we stop the simulation and record the telemetry data when two gyroscopes in any axis have broken down. The variables of indexes 4, 8, 13, and 14 are 13 simulated telemetry data. The sample period is 10 s.

Diagram of simulation platform.
Symbol description of ACS simulation platform.

ACS: attitude control system.

Configuration of gyrosystem.
In this article, nine samples
Data processing
Each sample produced by the above platform is 3–5 GB, which severely affects the processing speed of health diagnostic health monitoring algorithm. Therefore, features that can define degradation must be extracted for data processing.
In this section, we explain the process of feature extraction and evaluation in detail by taking the variable

Raw data of
First, the partitioning window technology is adopted for data compression. The window length is set to 8460

Several time-domain features of

Frequency-domain features of

Feature extraction of
Second, according to equations (3) and (4), the value of
Optimal features of telemetry variables.

Finally, the cumulative sum of the wavelet packet energy entropy is calculated by equation (5), and the result is shown in Figure 15(b). For the variable
Diagnostic health monitoring
In the offline training, the whole extracted features of different samples are first normalized by equation (6) uniformly, and the mean and variance of this normalized are saved. Second, FCM is utilized to label different health states as shown in Figure 16. The labels of health states are injected by FCM to deal with the unlabeled and unbalanced data. In Figure 16, “1” represents normal state, “2” represents slight damage state, “3” represents medium damage state, and “4” represents failure state. In the two top images of Figure 16, the black solid line represents the labeled health states (actual states) by FCM. The red imaginary line presents the training result using the deep forest classifier. In the two bottom images of Figure 16, the blue solid line represents the health probability of corresponding top data in the same time. From Figure 16, the accuracy rates of offline training are all above 95%, and only several misclassifications are found in the transitions among different health states. In addition, the probabilistic results of transitions among different health states are low and can accurately reflect the uncertainty of transitions among different health states. Finally, the good structure of forest in offline training is saved for online health state assessment.
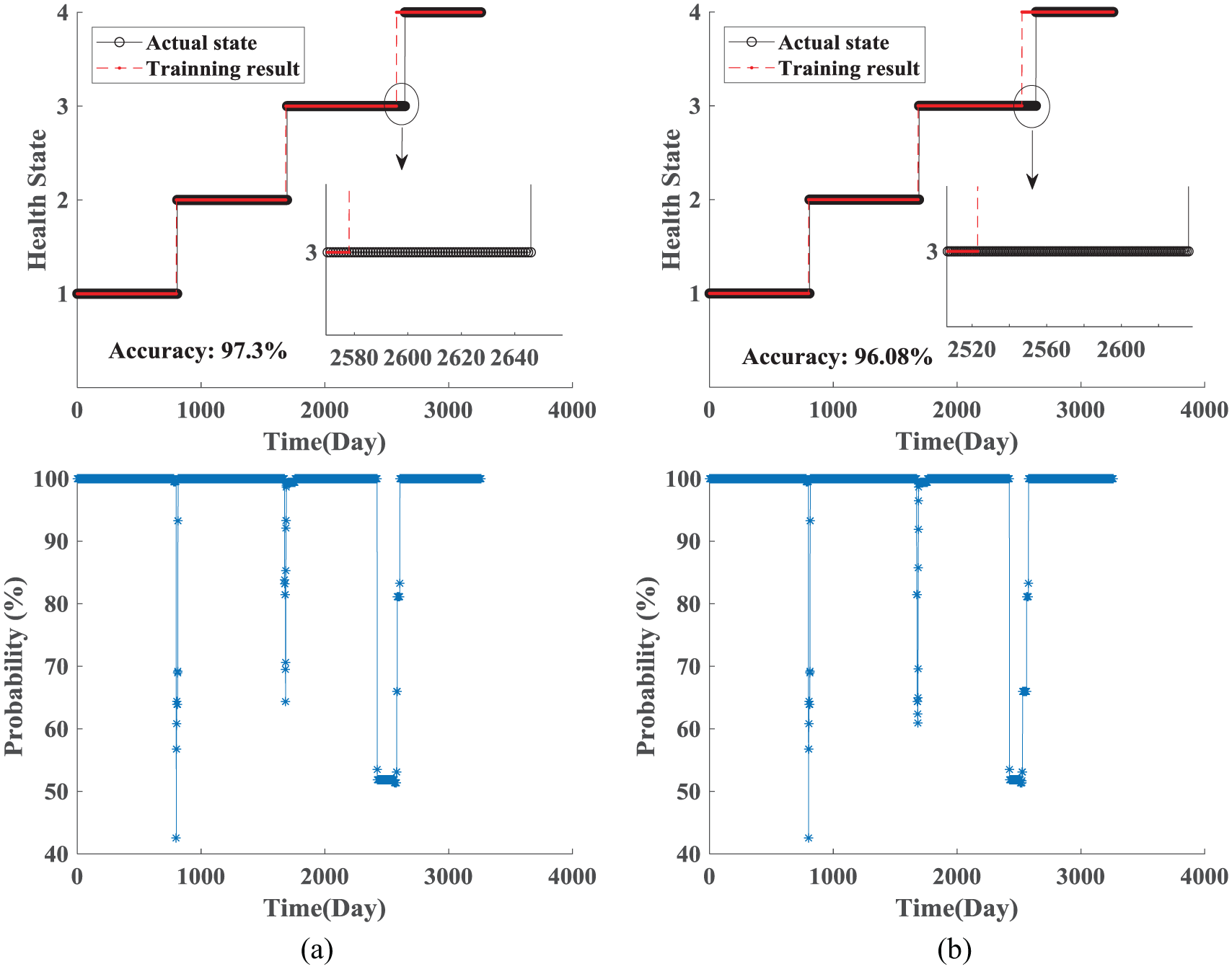
Offline training: (a) sample 1 and (b) sample 2.
In the online health state assessment, we first utilize the saved mean and variance to normalize the rest samples, which are parts of life cycle from the normal stage to the end of the third stage. Second, the well-trained structure of forest in offline training is adopted to assess the current health state of the rest samples. Finally, the results of online health state assessment are shown in Figure 17. From Figure 17, the accuracy rates of online prediction are all above 90%, and few misclassifications are found between the transition points before 2500 days. In addition, the health states are assessed as failure state in advance, and the corresponding probabilistic results are lower than 75%. In fact, the low probability indicates that the system is not in a real failure state. The change of health state will be accepted only when the probabilistic value becomes 90%. These results show the benefits of the proposed method.

Online health state assessment.
According to all these results, either offline training or online prediction shows that the probabilistic multivariate diagnostic health monitoring is better than general methods. Deep forest classifier can be successfully applied for health state assessment.
Conclusion
The multivariate diagnostic health monitoring, combined with effective feature extraction, FCM, and deep forest classifier, has been proposed to solve the problem of SHI construction and empirical thresholds setting in the PHM field. This method can extract multi-domain health-degradation-relevant features from a given mass of multivariate telemetry data, and can deal with unlabeled and unbalanced spacecraft telemetry data and the uncertainties in these data. The offline training and online health state assessment results on the simulated ACS of a spacecraft reveal the feasibility and effectiveness of the proposed strategy.
However, prognostic health monitoring is as important as diagnostic health monitoring in the PHM field. Its main purpose is to predict the trend of the next degradation stages and even the remaining useful life. In the future, the prognostic health monitoring will be considered.
Footnotes
Handling Editor: Nuno Maia
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Nature Science Foundation of China under grants 61873122 and 61673206, Equipment Pre-research National Defense Science Technology Key Laboratory Foundation under grant 61422080307, Key Laboratory of Spacecraft Fault Diagnosis and Maintenance on Orbit, and Postgraduate Research & Practice Innovation Program of Jiangsu Province under grant KYCX18_0300.