
Abstract
In real production manufacturing process, there are many disturbances (e.g. machine fault, shortage of materials, tool damage) which can greatly interfere the original scheduling. These interventions will cost production managers extra time to schedule orders, which increase much workload and cost of maintenance. On account of this phenomenon, a novel system of data mining–based disturbances prediction for job shop scheduling is proposed. It consists of three modules: data mining module, disturbances prediction module, and manufacturing process module. First, in data mining module, historical data and new data are acquired by radio frequency identification or cable from database, and a hybrid algorithm is used to build a disturbance tree which is utilized as a classifier of disturbances happened before manufacturing. Then, in the disturbances prediction module, a disturbances pattern is built and a decision making will be determined according to the similarity between testing data attributes and mined pattern. Finally, in the manufacturing process module, scheduling will be arranged in advance to avoid the disturbances according to the results of decision making. Besides, an experiment is conducted at the end of this article to show the prediction process and demonstrate the feasibility of the proposed method.
Introduction
With the development of manufacturing domain especially for the industry 4.0, producers pay more attention to the intelligent manufacturing and smart manufacturing. 1 To achieve the goal and prompt local enterprises’ operation ability in a keen competitive environment in the global markets, the function of responding flexibly to disruptions and faults in manufacturing process is obviously urgent and important. 2 Lacking the ability of prediction of emergencies will delay the actual time and cause the large loss of throughput, which has a direct effect on industries’ development and manufacturing process. Thus, manufacturing systems especially for discrete machine driven systems should acquire real-time data and predict the special accidents by mining knowledge from historical data. 3 In the manufacturing, predictability can be sorted into two classes according to the sequence happened in process: before the decision making of scheduling and during the products manufacturing. Predicting before scheduling can avoid task tardiness and other unnecessary loss, while during manufacturing, real-time signals can indicate the potential faults and these failures are usually associated with disturbances. Therefore, the ability of disturbance prediction in job shop is becoming increasingly important and can optimize job shop control, improve the allocation of resources, and reduce manufacturing cost.
Recently, many small and medium industries add sensors into real manufacturing process, which enables senior managers to get data easier. 4 These data are useful for line controllers to choose an appropriate dispatching rule and to schedule or reschedule orders in time. However, most of them only focus on finding appropriate algorithms to improve the efficiency of scheduling. 5 , 6 So, today’s scheduling frameworks usually lack the function of predicting disturbances or potential faults to schedule orders in advance. During these years, data mining as an advanced data treatment technology attracts more and more academicians and practitioners to use to serve for manufacturing field and it provides a chance to solve scheduling problems at the same time.7–9
Within the context, a novel framework of disturbances prediction for job shop scheduling based on data mining is proposed. It avoids the risk of extra time and effort when unexpected events occur and provides the managers a reference of disturbances to adjust the original plan and schedule in a low error probability strategy. This study discusses two main problems: (1) to train and build the relationship between data and disturbances pattern and (2) to propose the model of data mining–based disturbances prediction for job shop scheduling.
The remainder of this article is organized as follows: the “Literature review” section presents a brief literature review about scheduling and data mining research. In the section “Data mining–based disturbances prediction,” an overview of data mining, disturbances, and concept of data mining–based disturbances prediction for job shop will be described. The “System architecture” section introduces the architecture of the system and several key technologies and procedures. A hybrid algorithm which is used for data mining in job shop is elaborated in the section “The proposed hybrid algorithm.” Then, the section “Experiment” provides experimental results to validate the feasibility of this method. Finally, conclusions and future work are presented in the section “Conclusion and future work.”
Literature review
The research on scheduling and rescheduling problems has been investigated for a long time. Even now, many academicians and practitioners still study the algorithm itself to improve the ability of scheduling system. Zhang et al. 10 investigated low-carbon scheduling problems using a hybrid NSGA-II algorithm. Qiao et al. 11 proposed three rescheduling strategies and a new fuzzy petri net-based reasoning method for rescheduling. Karthikeyan et al. 12 used a hybrid discrete firefly algorithm combined with local search to solve multi-objective flexible job shop scheduling problems. Tay and Ho 13 analyzed the usage of genetic algorithm and optimized the objectives of makespan, tardiness, and mean flow time. Zhao and Yuan 14 presented polynomial time algorithm and Liu and Ro 15 also provided a pseudo-polynomial time optimal algorithm but with a constant factor approximation algorithm and a fully polynomial time approximation scheme. Liu et al. 16 designed a hybrid heuristic algorithm to solve single machine scheduling. Most of them were keen to investigate new algorithms and use them to optimize the single objective or multi-objective problems regarding scheduling in workshop.
However, there are many disturbances that happen in real manufacturing and the traditional static scheduling politics cannot satisfy producers’ requirements. To solve this problem, we should learn the classification of these disturbances or disruptions. Liu et al. 17 divided them into two parts: dominant disturbances (elements which influence the normal process directly) and recessive disturbances (elements which affect the normal process over time). The explicit definition will be introduced in the following section. Most papers focused on the solution of dominant disturbances. Lv and Qiao 18 integrated process planning with scheduling and considered the improved evolutionary algorithm into the rescheduling strategies while considering three dominant disturbances. Katragjini et al. 19 also considered three different dominant disruptions and sought a good balance between schedule quality and stability. In this article, the proposed method provides a new perspective of seeking the above balance based on the prediction system to achieve a better scheduling method in advance. Dong and Jang 20 investigated rescheduling for single disturbance of machine breakdown on a job shop and optimized the objective of mean tardiness. Liu and Zhou 21 analyzed the rework disruption and summarized the relationship between scheduling efficiency and stability. On the contrary, Wang and Jiang 22 developed a rescheduling decision mechanism for recessive disturbances, which solved the problem of time accumulation error (TAE). The above researchers stressed the importance of flexible or dynamic scheduling and made the scheduling system become more robust in an actual manufacturing environment.
The term of big data emerged as the time required the replacement of equipment and the addition of data collector; hence data processing in manufacturing became increasingly important. Besides, the technology of radio frequency identification used into real-time control in workshop also greatly improved the pace of usage of big data in the manufacturing.23–25 Other functions like the analysis of big data can improve the performance of cyber-physical system 26 and the management of product lifecycle. 27 According to the recent literature, data mining as a key technology of processing of big data has become an efficient and a useful method which can preprocess data and extract knowledge from data set. 28 , 29 The framework of big data mining in scheduling was introduced by Ismail et al. 30 Shahzad and Mebarki 31 also developed the module of data mining using hybrid simulation–optimization approach. Data mining can be sorted into two definitions: classification and clustering. Besides, it has many key algorithms like C4.5, BBN, k-means, SVM, and BP. Adibi and Shahrabi 32 investigated the variable neighborhood search combined with k-means for job shop scheduling, while Chen et al. 33 used k-means clustering into extracting performance rules of suppliers in the manufacturing industry. The method of selection of dispatching rules using C4.5 algorithm was presented by Wang et al., 34 and Metan et al. 35 applied the decision tree into real-time selection of scheduling rules and minimized average tardiness. Senvar et al. 36 also investigated the method of data mining to optimize tardiness with three inputs: processing time, release dates, and due dates. Most of them were committed to using data mining to select dispatching rules to optimize job shop processing, but not using data mining to predict disturbances to avoid post scheduling. Ji and Wang 37 are the only research team who used RapidMiner, a tool of data mining, to mine potential machine fault (a dominant disturbance in job shop) in an exhaustive literature search, but lack the application of theoretical algorithm. In this article, a new framework of data mining–based disturbances prediction in job shop will be introduced, and the algorithm will also be analyzed in the following context. In conclusion, data mining has been used widely in manufacturing and it also reflects the necessity of prediction of disturbances for shop floor scheduling.
Data mining–based disturbances prediction
Problem description
In an ideal production processing or for the requirement of lean manufacturing, a part is continually processed between two different machine tools without any breakdowns. So, once it is finished by a machine tool, it will be transferred to the next operation. Figure 1(a) simply shows the time flow of a part i under the different operations. In the first operation, it costs the time of
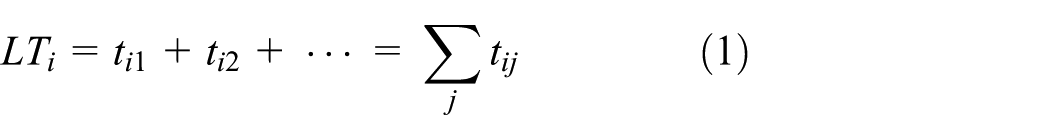

where

From formula (3), the whole actual processing time in factories can be seen as the sum of ideal planned processing time and the invalid/unnecessary time PDT caused by disturbances which will be classified in “Classification of job shop disturbances” section. To solve time delay caused by PDT and to make up for the gap between real production and ideal lean production, the aim of this article is to minimize or eliminate PDT to make the value of

Time flow of the process: (a) Ideal time flow of the process, and (b) Real time flow of the process.
A new method to cope with the problem and reduce the gap between the actual time and the ideal time is proposed—data mining, which is also referred to as knowledge discovery in databases, means a process of nontrivial extraction of implicit, previously unknown and potentially useful information (such as knowledge rules, constraints, regularities) from data in databases. 38
Algorithms used in data mining
To better understand data mining–based disturbance prediction, it is necessary to introduce data mining algorithms in this article not only because there are not too many examples and literature on the usage of data mining in job shop but also to learn how to choose an appropriate algorithm to solve scheduling problems of the job shop. Methods employed in data mining are closely associated with machine learning. The principal methods are summarized as follows:
Apriori algorithm: it is the most famous mining algorithm of association rules. By computing the support of item sets under the multiple scanning of database, it can find all the frequent item sets and form the association rules.
Decision tree: it is a flowchart-like structure in which each internal node represents a “test” on an attribute (e.g. whether a coin flip comes up heads or tails), each branch represents the outcome of the test, and each leaf node represents a class label (decision taken after computing all attributes). The paths from root to leaf represent classification rules. 39 It is commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal, but is also a popular tool in machine learning. C4.5 is the representative algorithm in decision tree. 40
Bayesian classification algorithm: it is an inference method to research uncertainty. Unlike classical probability which represents objectivity, its cognition refers to personal estimation and changes with one’s subjective perception. Naive Bayes and Bayesian Belief Networks (BBN) are two methods of Bayesian classification algorithm.
Artificial neural network algorithm: it simulates biological neuron by artificial method and the module includes multiple inputs, weights, and a single output. A well-known pattern called M-P module is created combining artificial neural network basic module with inspirit function. There are several main network modules like BP, Hopfield, Kohonen, RBF, CP, and Boltzmann machine.
Support vector machine: it developed based on VC of statistical theory and minimum structure risk principle, leading to a trade-off between complexity of model and learning ability.
K-means and K-medoids: they are both clustering algorithms based on distance. K-means are sensitive to noise but K-medoids can greatly reduce this impact.
For the advantages of good readability and fast classification of decision tree and high classification accuracy of Bayesian classification algorithm, this article adopts these two algorithms to predict disturbances in job shop, which will be elaborated in “The proposed hybrid algorithm” section.
Classification of job shop disturbances
In real manufacturing, unexpected disruptions usually disturb the normal process of scheduling. In another words, it is necessary to learn the differences between various disturbances. On one hand, disturbances can be classified into two main categories: resource-related and job-related. 21 Resource-related disturbances include machine breakdowns or suspensions, blocking or deadlock, material shortages or delays in supply chain, tool failure, and so on. Job-related disturbances include the arrival of new jobs, job changes or delays, changes of priorities, rework, and so on. On the other hand, they can be divided into two different categories: dominant disturbances and recessive disturbances. 17 Here, dominant disturbances refer to machine breakdown, rush orders, and shortage of material supply that play a decisive role in the normal operation of the production system. Recessive disturbances refer to those disruptions that influence the operation of the system until the accumulation of a certain time (e.g. TAE, the cumulative number of new jobs, accumulation of workpiece in machining buffer).
In order to better learn the disturbances of job shop, an all-round disturbances classification is proposed. It could be divided into three parts: accumulating error, resource-related, and job-related disturbances. Accumulating error disturbances represent the above recessive disturbances which could be calculated by comparing the difference between actual process time/amounts and planned process time/amounts. However, they are mainly evaluated during or after the manufacturing process. So, this article concentrates on the remaining two disturbances. For example, machine breakdown and tool failure which are associated with resources can be predicted by comparing the testing data with the training data of machine tool. Rush orders linked with jobs can also be predicted at the time of special occasions and the state of workshop.
Concept of data mining–based disturbances prediction
Once the disturbances are classified, the potential disturbances pattern could be represented by a set of data attributes. Besides, the jobs, operations, and resources can all be replaced by datasets. The disturbances pattern will be acquired by the method of data mining from training data.
There are two scenarios of data mining–based disturbances prediction in a real manufacturing job shop: (1) the original manufacturing plans, represented by a series of data attributes, are compared with disturbances pattern and (2) the real-time data are collected by wireless transceiver and cable and then form the new data attributes to compare the disturbances pattern. This article concentrates on the original manufacturing plans compared with disturbances pattern. Figure 2 depicts the concept of data mining–based disturbances prediction. After the comparison of testing data and disturbances pattern, a difference index will be obtained, which provides a reference for validity of original manufacturing plan.

Concept of data mining–based disturbances prediction.
System architecture
To prevent the failure of the original plan before manufacturing and to avoid the breakdown of machines during processing, an approach of data mining–based disturbances prediction is thus proposed for job shop scheduling. Figure 3 depicts the system architecture with three modules.
Data mining module: it is the most significant part of the whole system, which determines the following reliability of disturbances prediction and decision making. There are two sources of data analysis: existing data in database and new data produced by real-time manufacturing process. Existing data can be used into data analysis right now and real-time data also will be added into data analysis to reinforce the ability of data analysis system. First, these data form identifiable and uniform data set after data cleaning, data integration, and attributes selection. This process is also known as data preprocessing which will benefit the following data mining. Then, a hybrid algorithm is used to acquire the auto-updating classifier to distinguish and predict disturbances. The algorithm will be introduced in section “The proposed hybrid algorithm.”
Disturbances prediction module: after the classification of data, disturbances pattern is built and data produced in real-time manufacturing process will be compared with the mined disturbances pattern. Besides, the original manufacturing plans represented by data attributes can also be tested by this classification module. The difference between mined pattern and data attributes will be calculated and it provides a reference to the severity of disturbances which is a standard of scheduling adjustment or normal scheduling.
Manufacturing process module: it is the final stage of the system, which executes the decision after the disturbances prediction. According to the difference index, if it exceeds the expected value, the original scheduling plan will be suspended and adjusted within the limitation of makespan. Otherwise, the scheduling will not be changed.
To explain the data mining clearly and implement this ideal, it is necessary to introduce the following key sub-function modules in detail, like database and data attributes.
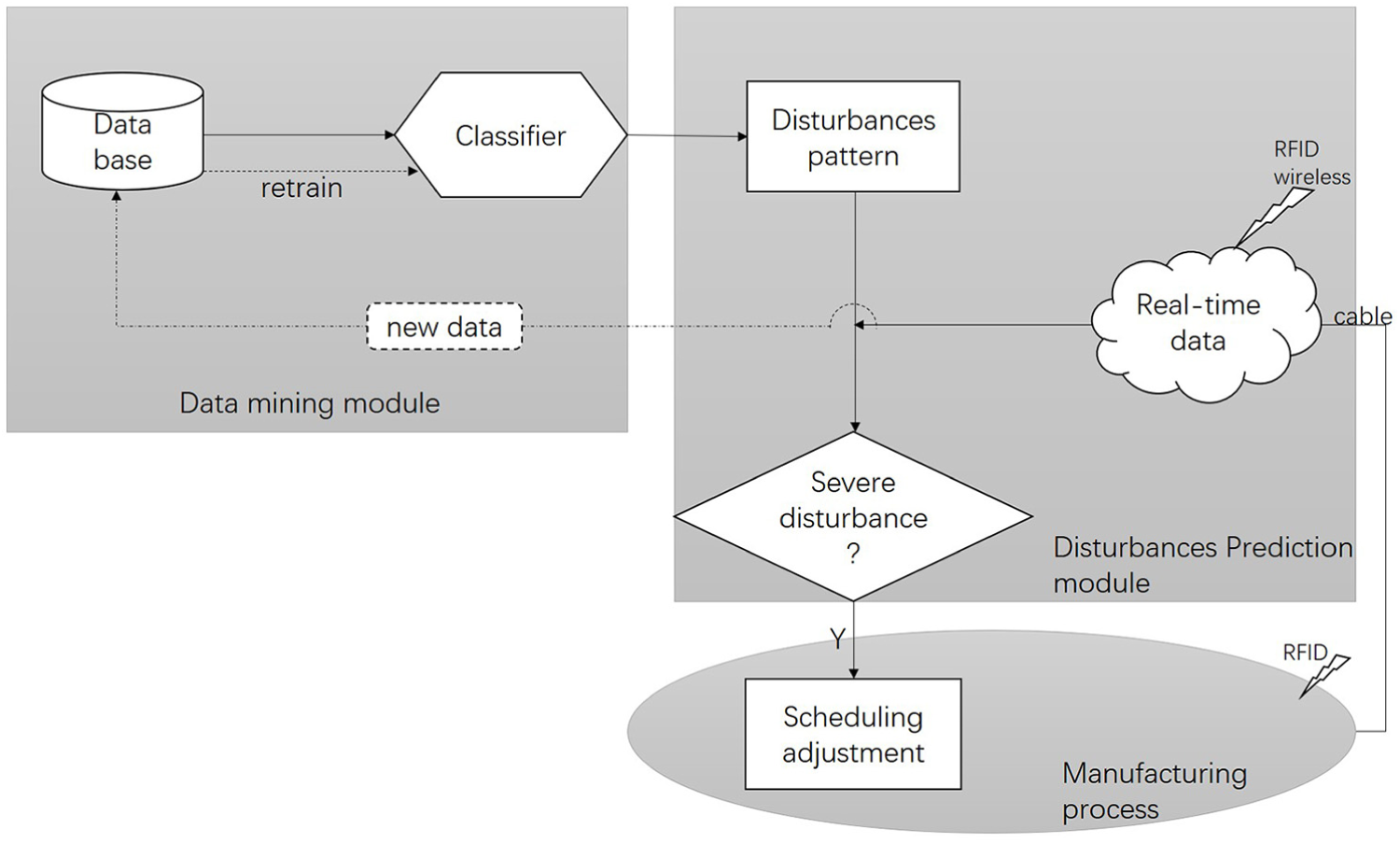
Architecture of data mining–based disturbances prediction.
Database
Database is the foundation of data mining module. Because of the abundant data in job shop and the object of different disturbances prediction, data should be divided and stored into different databases. Combined with the actual production environment, this article provides a way to divide the database of job shop: (1) machining process database (mpDB) and (2) resources and jobs database (rjDB). The mpDB refers to the data about actual manufacturing process, and covering completion time, state of workpieces, and state of machines and cutting tools, which addresses the feature of dynamic. The real-time data produced in actual manufacturing process are usually stored in this database. However, the rjDB stores those fixed data, and covers the information of machines, cutting tools, workpieces, jobs, quality, and workers.
Data attributes
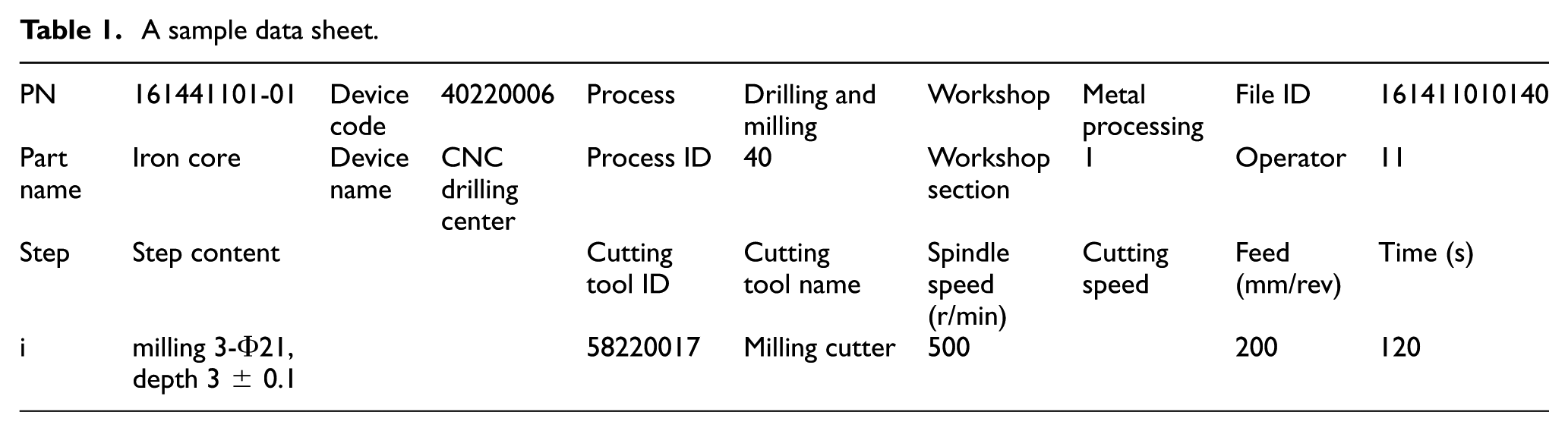
Data attributes are the general input of a classifier. In this part, the elaboration of data attributes and attributes selection will be introduced. The attributes of job shop data include the information about machines, cutting tools, workpieces, jobs, process, completion time, quality, and workers. The attributes of machines refer to device name, code, quantity, power, fault, and maintenance recordings, which are stored in rjDB. The attributes of process refer to cutting parameters, cutting fluid, pressure, and fixture information. These attributes are closely associated with the technological requirement and are usually fixed to store in the rjDB. The other attributes like cutting tools, workpieces, jobs, and workers are simple to understand and they are also stored in the rjDB, while the completion time, quality, and the completed quantity are all dynamic and therefore they are stored in mpDB. A sample data sheet of an industry is shown in Table 1, which only lists a set of classical attributes. Any of the above attributes may be the parameters that determine the disturbances prediction, and data mining is to find people’s unknown, potentially useful, hidden rules from these massive data through various algorithms such as correlation analysis, cluster analysis, and timing analysis. While different problems or different models may lead to different deterministic parameters, the following introduces an overall method of attributes selection in the majority of algorithms.
A sample data sheet.
While confronted with a group of attributes, attributes selection is obviously important, which selects the optimal attributes with the number of M from the attributes set with the number of N (N > M). There are two difficulties: (1) to select a separability criterion as the standard of optimal attributes selection and (2) to search an algorithm to acquire the optimal attributes from attributes set. The exhaustive method is often accepted, which calculates all the separability criterion of the whole combinational situation in the case of selecting M optimal attributes from N attributes. This method is available if the value of N is small. Otherwise, the approach is to find a search algorithm, such as sequential forward selection, sequential backward selection, and l-r method which combines the above two ways.
It is also essential to execute data cleaning after acquiring data attributes and forming the data set of different values. For example, incomplete data, wrong data, inconsistence in source coding, and field overloading. Although some commercial tools (Weka, RapidMiner) support the procedure of data cleaning, only limited numbers of cleaning are available. Therefore, we may write customized program for this step catering to different customers’ requirements in the future.
The proposed hybrid algorithm
To solve the accurate classification of abundant data in job shop, a hybrid algorithm which combines naive Bayes with decision tree is proposed in this article. There are two common methods: (1) naive Bayes with the integration of decision tree to construct a classification module and (2) decision tree combined with naive Bayes to output a decision tree, which is employed in this article. The classification accuracy rates were verified by Farid et al. 41 on datasets from UCI machine learning repository, so the following will mainly introduce the concrete induction of hybrid decision tree used into job shop.
Decision tree
The basic decision tree algorithm is ID3 algorithm which uses the highest information gain as attribute selection node. The information gain is composed of the difference between entropy and conditional entropy. The equation is as follows

where, X is a training dataset, A represents the attribute set, entropy(X) is the entropy of data X, entropy(X, A) is the conditional entropy of data X under the classification of attribute A. The expressions of entropy and conditional entropy are as follows

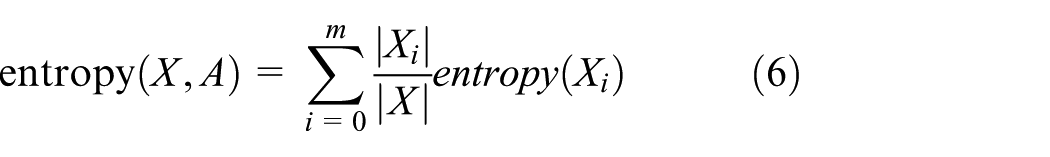
where
However, the ID3 algorithm is based on the classification of discrete data. To overcome this shortcoming, C4.5 algorithm was proposed by Quinlan 42 in 1993. The core difference is the proposal of information gain ratio, which utilizes gain ratio as the criterion for selecting attributes. The expression is as follows
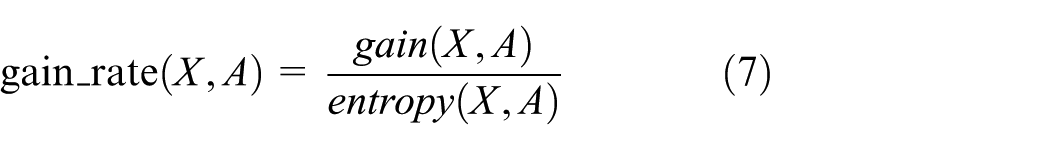
Naive Bayes
The method of naive Bayes actually converts the problem of assigning the sample X of the unknown category to the category
Suppose the sample space has m categories
Hybrid algorithm
It is based on C4.5 algorithm. Given a training dataset
Before the construction of decision tree, the algorithm adopts the preprocessing of naive Bayes to classify each training sample. It first calculates prior probability
After using naive Bayes to remove unexpected instances from training data, we acquire an updated dataset with noise free data and subsequently begin to construct a decision tree. The first step is to select the best spitting attribute with the maximum information gain ratio as the roof node. Then its child nodes and branches will be generated and added to the decision tree. The algorithm will continue to follow this classification method to produce new branches until all the leaf nodes belong to the same class or the child property value is empty. The main procedure of proposed algorithm is described as follows.

Experiment
In this section, we describe the experiment environment, test datasets, and show the outcomes of the proposed method which will focus on the disturbance prediction before manufacturing. The real-time prediction with scheduling adjustment is similar to the prediction at the beginning of process for data mining.
Experiment environment
In this experiment, there are two jobs with four machine tools, and the Gantt chart corresponding to the representation of a feasible scheduling is illustrated, as shown in Figure 4(a). The abscissa represents time and the ordinate means machine tools.

The representation of a disturbance happening in job shop: (a) An original scheduling, (b) a disturbance happening in an operation, and (c) scheduling after disturbance prediction.
There are many disturbances in real manufacturing, such as tool damage, personnel absence, and rush orders. In theory, these can be classified or aggregated through a large amount of data analysis to obtain the regularity of these events. Usually, scheduling is closely related to the availability of machine tools. In this experiment, machine tool failure as a key dominant disturbance is proposed and two benchmarks from Ji and Wang
37
instances are carried out to illustrate the problem. Two jobs with four operations
Details of two operations.

Datasets
Because of the fact that the real industry data are not available to the authors at the time of conducting this experiment, three hypothetic data sheets (I, II, and III) with different sample sizes are generated randomly by MATLAB using random function to validate the system. Figure 5 lists parts of data of scenario I, and the label of attributes is “result” which means whether the manufacturing is qualified or machine tool is normal. It does not mean only the above attributes determine the prediction of machine failure. Here, we cite examples of machining to illustrate the feasibility of the proposed method of predicting job shop disturbances based on data mining and to prepare for subsequent scheduling adjustments in advance. The experiment was conducted using a machine with an Intel i5 Processor 2.7 GHz processor and 8 GB of RAM. Because of the requirement of compatibility, we implemented this algorithm in Eclipse for Java coding. The basic code of naive Bayes and tree algorithm is derived from Weka3, which is an open source software and a popular data mining development platform. Weka3 contains a complete data mining processing flow from preprocessing to visualization. The data mining algorithms could be used directly in Weka3 or coded by ourselves.

Sample data sheet I.
Results
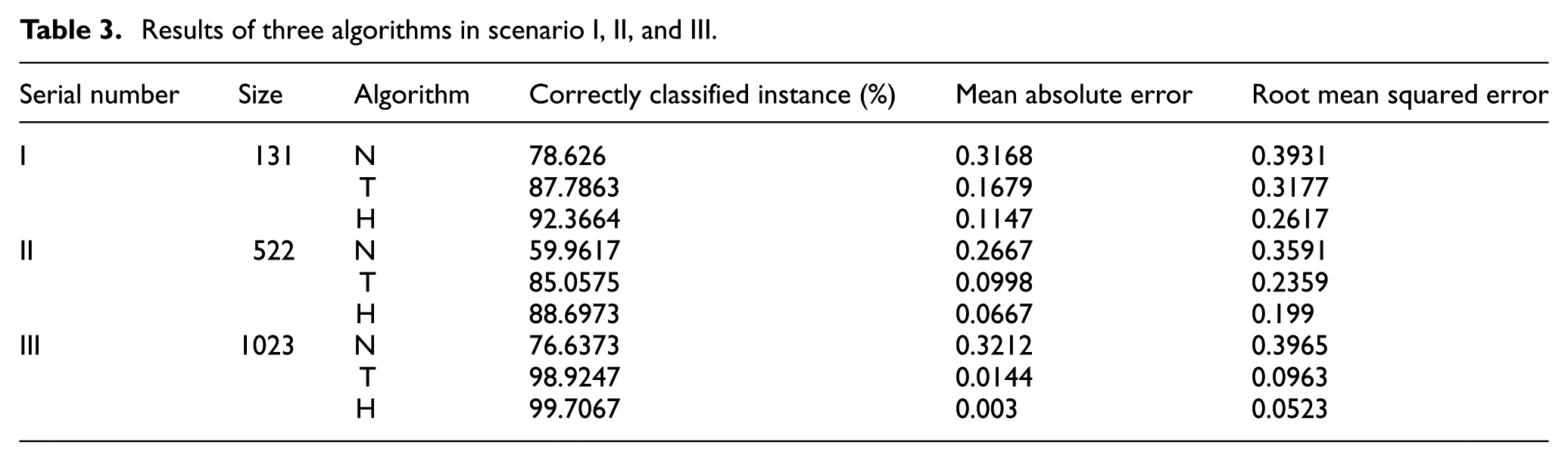
We evaluated the hybrid algorithm against existing naive Bayes and Decision Tree classifiers under 10-fold cross validation. Table 3 lists the experimental results of the above three different sizes of samples. Algorithm N means naive Bayes, algorithm T means decision tree, and algorithm H represents the proposed hybrid algorithm. From Table 3, regardless of the probability of correctly classified instance or the rate of error, the proposed hybrid algorithm shows a good feasibility and accuracy in disturbances classification under these three different sample sizes.
Results of three algorithms in scenario I, II, and III.
Below we use scenario I to specify the superiority of the algorithm and the feasibility of data mining–based job shop disturbance prediction method. First, Figure 6 summarizes the classification accuracy of the basic NB and DT classifiers, and the proposed hybrid algorithm in scenario I. The results in Figure 6 show that the hybrid algorithm outperforms the other algorithms for mean absolute error and root mean squared error. The values are 0.11 and 0.26, respectively, which are lower than the result of naive Bayes (0.32, 0.39) and Decision tree (0.17, 0.32). In the column of detailed accuracy by class, the outcomes of hybrid algorithm are also better than the results of other two algorithms, the parameter descriptions can be referred in the official website of Weka (https://www.cs.waikato.ac.nz/ml/weka/documentation.html). On one hand, the results are in line with Farid’s conclusion which had a good classification accuracy in Adibi and Shahrabi. 32 On the other hand, the algorithm has also been proved to be well applied into job shop.

The classification accuracies and precision for naive Bayes, tree, and hybrid algorithm with 10-fold cross validation: (a) Naive Bayes, (b) tree algorithm, and (c) hybrid algorithm.
The visualization of outcome is depicted in Figure 7(a), which is almost the same with the output in Figure 7(b) using RapidMiner, a commercial data mining software which has a better visualization in the market. From the results, if operation

the error probability is more than 90%, symbol “e” means an error and symbol “s” means a success (see Figure 7(b)) and this operation of Job1 has a high risk of break which delays the makespan from T1 to T2 (Figure 4(b)). The extra time “T2 – T1” is the PDT, maybe a maintenance which caused by a machine fault.

Result of classification: (a) Classification results obtained under the experiment, and (b) Classification results obtained under the RapiderMiner.
While it is viable if operation
Conclusion and future work
In this article, a novel framework of disturbance prediction based on data mining for job shop scheduling has been proposed. Compared with post scheduling, this method is a prior prediction, avoiding possible disturbances and eliminating the PDT or maintenance time, which has been be proved in the “Experiment” section. Compared with the literature that used data mining and applied into job shop, previous papers usually used data mining as a tool to discover dispatching rules rather than to find out those potential disruptions. This article provides us with a new perspective on the issue of job shop scheduling. After obtaining the disturbances that may occur before processing under the data mining method, we replace the corresponding objects that affect the scheduling in time and finally conduct the regular scheduling. Such a simple method is used to prevent the unstable factors before manufacturing, which greatly reduces the complexity of the scheduling strategy and algorithm, and even bypasses the dynamic scheduling.
The disturbances, such as machine breakdown, rush orders, and maintenance state, can be predicted at the beginning of manufacturing. Within the context, the jobs are replaced with a set of data attributes which is compared with disturbance pattern by training data analysis. The proposed system can be divided into three parts, that is, data mining module, disturbance prediction module, and manufacturing process module where the new arrangement of scheduling is made. Moreover, the details of each module are introduced, together with disturbances classification, data processing, and some other data mining technologies.
To solve the key technology of data mining of job shop, a hybrid algorithm is proposed which combines decision tree with naive Bayes. Before the construction of decision tree, using naive Bayes can remove unexpected data and improve the accuracy of training data classification. Finally, an experiment is used to demonstrate the feasibility and applicability of the proposed disturbance prediction system based on data mining.
Future research in this area will include multi-disturbances prediction, such as rush orders, machine breakdown, and maintenance, where the excellent disturbances pattern is built. Besides, collecting data from real-world manufacturing is also very necessary due to the fact that meaningful data are unavailable at the time of performing this case, due to proprietary data protection.
Footnotes
Handling Editor: Tatsushi Nishi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research work presented in this article is under the support of China Scholarship Council with Grant No. 201706790094.