
Abstract
Decomposing the large-scale problem into small-scale subproblems and optimizing them cooperatively are critical steps for solving large-scale optimization problem. This article proposes a cooperative differential evolution with utility-based adaptive grouping. The problem decomposition is adaptively executed by the two mechanisms of circular sliding controller and relation matrix, which consider the variable interactions on the basis of the short-term and long-term utilities, respectively. The circular sliding controller provides baselines for the subproblem optimizer. The size of the sliding window and the sliding speed in the controller are adjusted adaptively so that the variables with higher activeness can be optimized extensively. The relation matrix–based grouping strategy enables interacted variables to be grouped into the same subproblem with higher probabilities. The novelty is that decomposition is conducted as the optimization process without extra computational burden. For subproblem optimization, we use a self-adaptive differential evolution operator that adaptively adjusts the parameters to guide the search to the optimum solutions of the subproblems. Experiments on the benchmarks of CEC2008 and CEC2010, and practical problems show the effectiveness of the proposed algorithm.
Keywords
Introduction
High-dimensional optimization problems can be found in many engineering fields, so effective and efficient optimization algorithms are always in demand.1,2 Evolutionary computation has emerged as an intelligent computing discipline for optimization problems; it contains a large number of heuristics that not only have strong robustness and global search ability but also do not require domain knowledge. Thus, the evolutionary computation has been shown to be successful in many applications. However, many of them are still plagued by “curse of dimensionality,” 3 which means that their performance will deteriorate when applied in high-dimensional environments.
To solve high-dimensional optimization problems, a natural solution is to adopt cooperative coevolution (CC),4,5 which is a framework based on divide-and-conquer. The CC algorithm has shown good performance on separable problems but degenerates on nonseparable problems.6,7 Thus, research and development on CC algorithms for nonseparable optimization problems have attracted attentions of researchers.8,9 Essentially, the CC algorithm simplifies the complexities of problem through decomposition, 10 and the performance is sensitive to the decomposition strategy. 11 Based on how to deal with the variable interactions, the existing algorithms can be classified into three categories. Generally, the algorithms performed without considering variable interactions are effective for separable problems but have difficulty in solving problems with interacted variables.12,13 On the other hand, the algorithms performed by considering variable interactions implicitly or explicitly provide opportunities to solve problems with interacted variables.5,14 However, the object-oriented strategies for extensively exploring the variable interactions as well as avoiding extra computational efforts to the algorithms are still required. Moreover, as the interactions among subproblems impose impact on the algorithm’s performance, 15 the strategies of co-adapting the subproblems are also required.
In order to address the aforementioned issues, we propose a cooperative differential evolution with utility-based adaptive grouping (CoDE-AG). For problem decomposition, the strategies of circular sliding controller (CSC) and relation matrix (RM) are proposed. In the controller, the variables to be optimized are arranged in a loop, and the variable window covers a subset of the loop. While optimizing, the variables covered by the window are optimized, and the variables outside of the window are kept constant. For optimization of all the variables, the window slides after the optimization of each subproblem. Since different subsets of the variables have different surface landscapes and require different computational efforts, the size of the window and the sliding speed are self-adapted. The window size that has good performance will have higher probability to be adopted for the next cycle. Meanwhile, the variable subsets are identified as active, regular, and inactive regions. The active and regular regions imply that the variables have probabilities being interacted, and the sliding speed will be slow when the window covers them. The inactive regions imply that the variables are not interacted, and the sliding speed will be fast when the windows cover them. In order that they are optimized with latent interacted variables, the permutations of the variables belonging to different inactive regions are rearranged for the next cycle. Moreover, to improve the adaptability of grouping the subproblems, a reward-based RM is constructed to reflect the long-term utilities of variable interactions. The underlying assumption is that if a subset of variables optimized in the same window yield improvement on the optimization results, then they will have higher probabilities being interacted. For optimization of the subproblems, that is, the subsets of variables covered by the window, a self-adaptive differential evolution (SaDE) operator is adopted.
The rest of this article is organized as follows. The “Related works and background” section reviews the CC and DE (differential evolution). The “CoDE-AG” section describes the details of the CoDE-AG. The “Experimental studies” section presents the experimental studies, and the “Conclusion” section concludes this article.
Related works and background
The optimization problem considered in this article is formulated as follows

where
This work is related to cooperative optimization and DE. In this section, we first review the prevailing cooperative optimization algorithms and then present the background with regard to DE.
CC
CC is performed by decomposing the high-dimensional problem into a set of small-scale subproblems and then optimizing each subproblem according to a standard optimization metaheuristic. During the process, a context vector is constructed and updated by using a representative individual (e.g. the best individual) provided by each subcomponent. The cooperation takes place by the context vector. 16 In the framework of CC, how to decompose the problem plays a crucial role. 12 Hereafter, we review the state of the art cooperative optimization algorithms along different categories of decomposition strategies.
The algorithms belonging to the first category conduct decomposition tasks without considering the variable interactions. This includes two original decomposition methods: the one-dimensional based and splitting-in-half strategies.12,17 Some algorithms decompose problem arbitrarily.18,19 While optimizing, the decomposition strategy is kept unchanged, and each subproblem is optimized using a round robin strategy. Some algorithms decompose problem dynamically.3,20 While optimizing, the decomposition strategy is changed adaptively, and each subproblem is optimized using a measured stagnation. In the preliminary work of this article, we propose a simple circular sliding window strategy to decompose a large-scale problem into small-scale subproblems. However, it does not consider the variable interdependencies. 21 It has been demonstrated that this category of algorithms is effective for separable problems, but the performance degenerates for the problems with interacted variables. 22
The algorithms belonging to the second category conduct by exploring variable interactions explicitly. In Sun et al., 14 a statistical model is proposed to quantify the degree of interactions among variables. With the interactions, the problem is optimized under a CC framework. In Omidvar et al., 15 a differential grouping algorithm is proposed for capturing the variable interactions. As the differential grouping can only identify decision variables that interact directly, an extended differential grouping method is proposed to cater for different forms of interactions, 23 and a global differential grouping method is proposed to identify independent subproblems. 24 But the process of differential discrimination requires intensive computation efforts for fitness evaluations. Moreover, differential grouping is based on the assumption that the oscillation of the second order derivatives of the problems across the whole feasible search space is not violent. The new developed strategy DG2 25 addresses the burden to an acceptable level on problems with thousands of variables by increasing the utilization rate of the trial data. Yet, such attempts for reducing the resource requirements have not solved the problem of scalability. In Chen et al., 26 an evolutionary learning algorithm is proposed to examine the interactions of each decision variable with other decision variables in a pairwise fashion. The optimization is then conducted using a DE optimizer. The learning algorithm consumes up to 60% of the computational efforts. The results show that a near-optimal decomposition is beneficial in solving large-scale global optimization problems with up to 1000 decision variables. Generally, the algorithms belonging to this category provide opportunities to solve nonseparable problems. However, an essential drawback is that they require intensive computational efforts. More specially, the expensive nature of objective function in real-world problems and the difficult nature of large-scale nonseparable problems require the algorithm to avoid incurring extra computational burden.
The algorithms belonging to the third category conduct by exploring variable interactions implicitly. Some algorithms capture the variable interactions by using random grouping strategy. Representative works are EACC-G 5 and MLCC. 27 The EACC-G uses a randomization method which divides the decision variables into several groups according to a predefined group size, with each constituting a subproblem. For co-adaptation, they apply weights to the subproblems, and the subproblems and their weights are optimized separately. The MLCC applies several problem decomposers with different group sizes to construct a decomposer pool; the decomposers in the pool indicate different interaction levels. The extended random grouping strategies make more frequent random grouping and adopt self-adaptation of subproblem sizes. 28 Although the random grouping strategy achieves a measure of success, the probability of grouping interacted variables in one subproblem will decrease as the scale of the problem increases. It has been shown that random grouping is ineffective when the number of interacted variables grows more than five. Some algorithms capture the variable interactions by investigating the relationship between the objective functions and the candidate solutions.29,30 During the optimization process, the decomposition and the optimization strategies are adapted according to the obtained interactions based on the top 50% solutions of the population. These algorithms might fail to effectively capture the variable interaction because of lacking efficiency guidelines and heuristics in the whole evolutionary process. They might have limited scalability to large-scale problems. Therefore, it is desirable to design new heuristics that are capable of exploiting the structure of a problem to find a suitable decomposition without incurring extra computational burden.
DE algorithm
Under the CC framework, each subcomponent is optimized using a standard optimization metaheuristic. The widely used optimizers are based on natural inspired phenomena, such as genetic algorithm,31,32 ant colony optimization, 33 DE,34,35 particle swarm optimization,36,37 and memetic algorithm. 38 The DE is a population-based stochastic algorithm and is characterized by easy in implementation, and efficient in performance. In each iteration of the DE, for each target individual, the algorithm first constructs a differential vector subtraction using two or more other individuals from the population. The difference vector is then multiplied by a scaling factor and added to the current target individual to construct a new individual. Finally, the variation of the individual and the target individual will undergo crossover and selection operations for the next generation. After the initialization of the algorithm settings, the algorithm repeatedly executes mutation, crossover, and selection until the termination criteria are satisfied.
Population representation and initialization: The population is represented by
Mutation: After initialization, mutation is applied to produce a mutant vector

where
Crossover: After mutation, crossover operation is applied to target vector

where
Selection: The selection determines whether

where
Field search capability is an important indicator to evaluate an evolutionary algorithm.
39
DE is a competitive evolutionary optimizer for continuous search spaces. However, the performance of classical DE depends on the evolution strategies and their control parameters. It has been shown that the control parameters and learning strategies are highly problem-dependent.
40
It is time-consuming to tune parameters manually for different problems. SaDE
41
and SaNSDE (self-adaptive differential evolution with neighborhood search)
42
use multiple strategies adaptively based on the success during previous generations with adaptive values of
CoDE-AG
CSC
In the controller, the window covers several adjacent variables, only the variables in the window can be optimized at each optimization process, and other variables are taken from context vector and kept constant. After optimizing, the context vector is updated with the optimized variables and the window will slide forward
The details of the “circular sliding window” strategy are as follows. For an n-dimension optimization problem, the variables are arranged in an end-to-end loop; the window starts from the beginning of the loop and slides
Set
Initialize the starting position and select a window size from the window size pool;
Optimize the variables in the current window and record the number of success
Identify the activity of subregions and update the context vector;
If
Record the best optimization results of current cycle. Terminate the algorithm if the stop condition is satisfied, else turn to step 7;
Re-calculate the selection probability for the selected size of the window;
Randomly permute the order of the decision variables in inactive regions and go to step 1 for a new evolutionary cycle.
Figure 1 shows an illustrative example for the “circular sliding controller.” The objective problem is regarded as an end-to-end n-dimension vector
How to determine the size of the window. At the beginning, assign an alternate set of window size Assign a parameter to each
where Select the sliding window size of the next cycle using roulette strategy
This strategy is inspired by the works of Yang et al.;
27
it provides a high probability for a window size with better performance being selected and provides opportunities for other window size being selected, thus ensures the window size diversity.
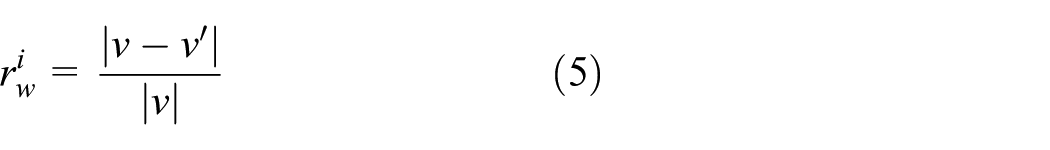

How to identify the activity of subregions and determine the sliding step. At each sliding window, for subregions
Mark the activity to each variable in the current subregion and accumulate the values of the activity for the variables in the overlapping windows. Partition the decision variables into three different regions: active region, regular region, and inactive region according to the activity. The first 30% high-activity variables are denoted as active regions (A), the last 30% active variables are denoted as inactive regions (I), and the rest of the variables are denoted as regular regions (R).

When the window center covers the active region, the sliding step is taken as
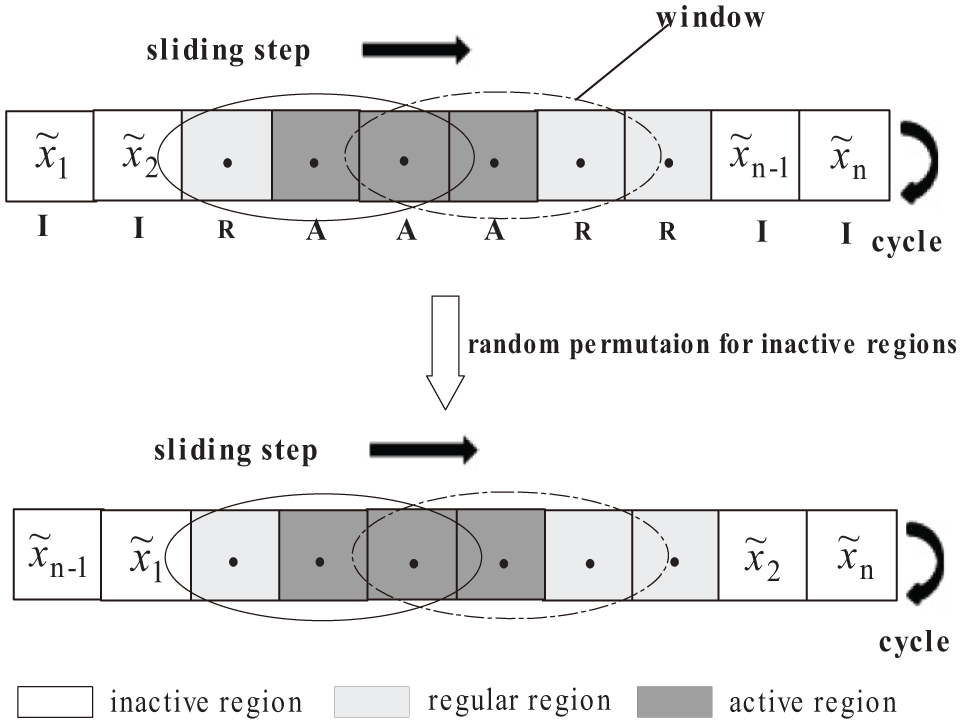
Illustration example for circular sliding controller.
Under the framework of CSC, the variables in inactive regions will be randomly permuted because the variables with low activity means that their current adjacent relations may be inappropriate. Moreover, multiple individuals can be produced in this process of random permutation for the inactive regions. This method is one of the divide-and-conquer methods, and the CSC is one of the grouping strategies. The main differences between this method and the methods that divide all variables into some subgroups and optimize each subgroup are summarized as follows:
The window covers a subset of variables, with the variables in the window being optimized at each optimization process. Each variable is marked with an activity. As the window slides across the variable set, the variables can be overlapped, so that the interacting variables have higher probabilities to be optimized together when the variables are in active regions. On the other hand, the variable in inactive regions will be randomly permuted to reduce the probabilities of grouping unrelated variables together.
The entire decomposition process is conducted automatically. The sliding speed and the size of the window are adjusted dynamically, so that the computational efforts can be self-distributed according to the activities of different regions and the performance of previous cycle.
Grouping based on RM
In the CSC, the heuristics of the selection of window size, the selection of sliding step, and the identification of different regions are conducted based on current evaluations, but not consider the variable interactions on the basis of the long-term utility. This limits the performance of the algorithm.
In this section, a RM
Algorithm framework
In this subsection, we present the framework of the proposed CoDE-AG. The algorithm conducts by executing the CSC and the RM-based grouping alternatively. When the circular sliding executes for a predefined number of cycles, the algorithm switches to execute the RM-based grouping. On the other hand, when the activity of the RM-based subgroup becomes lower than a given threshold

Flowchart of cooperative differential evolution with utility-based adaptive grouping.
Complexity analysis
Consider an optimization problem with
Experimental studies
Test case and experimental setup
To evaluate and analyze the performance of the proposed CoDE-AG, we perform experiments on the CEC2008 and CEC2010 benchmarks, which are designed to test the performance of algorithms on large-scale optimization problems. The benchmarks simulate various real-world optimization problems and ensure that the optimization algorithms proposed by researchers are the same efficient in practical scenarios. The CEC2008 benchmark has seven functions. Among the functions, three of them (
In the experiments, the parameters are determined concerning the quality of the results and the computational efforts incurred. The alternative set of window size is taken as
Simulated results and discussions
Results and discussions for CEC2008 benchmark
This subsection presents the results of the CoDE-AG for CEC2008 benchmarks. The dimensionality of the functions is taken as 1000. The results are presented following the instructions reported in the literature associated to the CEC2008.
46
For each run, the experiment is repeated 25 times, and the results after
Results of the 25 independent runs for CEC2008 benchmark functions

FEs: function evaluations; SD: standard deviation.

Plots of evolution curves of the CoDE-AG for CEC2008 benchmarks. The results were obtained from 25 independent runs of the algorithm: (a) f1, dim = 1000; (b) f2, dim = 1000; (c) f3, dim = 1000; (d) f4, dim = 1000; (e) f5, dim = 1000; (f) f6, dim = 1000; and (g) f7, dim = 1000.
For the purpose of comparison, we first select the MTS 48 and the LSEDA-gl, 49 whose reported results are top-ranked in the CEC2008 competition. The MTS uses multiple agents to search the solution space concurrently. Each agent does an iterated local search using one of the three optimizers. It adopts multi-optimizer strategy, and the optimizer that best fits the landscape of a solution’s neighborhood is selected. The LSEDA-gl adopts three strategies on the Estimation of Distribution Algorithm (EDA), that is, the sampling under mixed Gaussian and Levy probability distribution strategy, the standard deviation control strategy, and the restart strategy. Then we select relatively new algorithms that yield high-quality results on CEC2008 benchmarks, that is, the CSO 50 and the CCPSO2. 51 The CSO introduces a pairwise competition mechanism, where the particle that loses the competition will update its position by learning from the winner. The CCPSO2 is a cooperative coevolving particle swarm optimization algorithm based on random grouping. The position update rule relies on Cauchy and Gaussian distribution to sample new points. We compare the results of the CoDE-AG with the reported results associated with the algorithms in the original paper. We further select the LSHADE-cnEpSin, 52 which is one of the winning DE variants in CEC2017 competitions for moderate-scale optimization problems. The LSHADE-cnEpSin introduces two major operators to enhance the performance, that is, the ensemble of sinusoidal approaches based on performance adaptation and the covariance matrix learning for the crossover. In the original paper of LSHADE-cnEpSin, only the results of 10-D, 30-D, 50-D, and 100-D problems of the benchmarks are reported. For comparison with our algorithm, we extend it to solve 1000-D problems.
Table 2 presents the results from the 25 runs of the CoDE-AG and the results of MTS, LSEDA-gl, CSO, CCPSO2, and LSHADE-cnEpSin. As recommended in the CEC2008 technical report, all the results are taken at
Comparison results of CoDE-AG and other algorithms for CEC2008 benchmark functions
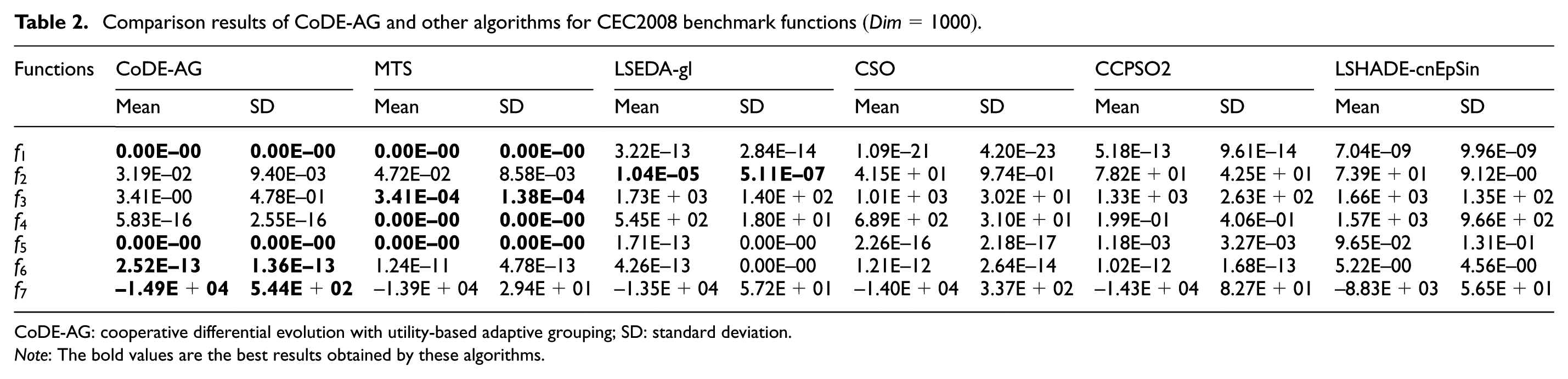
CoDE-AG: cooperative differential evolution with utility-based adaptive grouping; SD: standard deviation.
Note: The bold values are the best results obtained by these algorithms.
Results of the Friedman test and Holm test
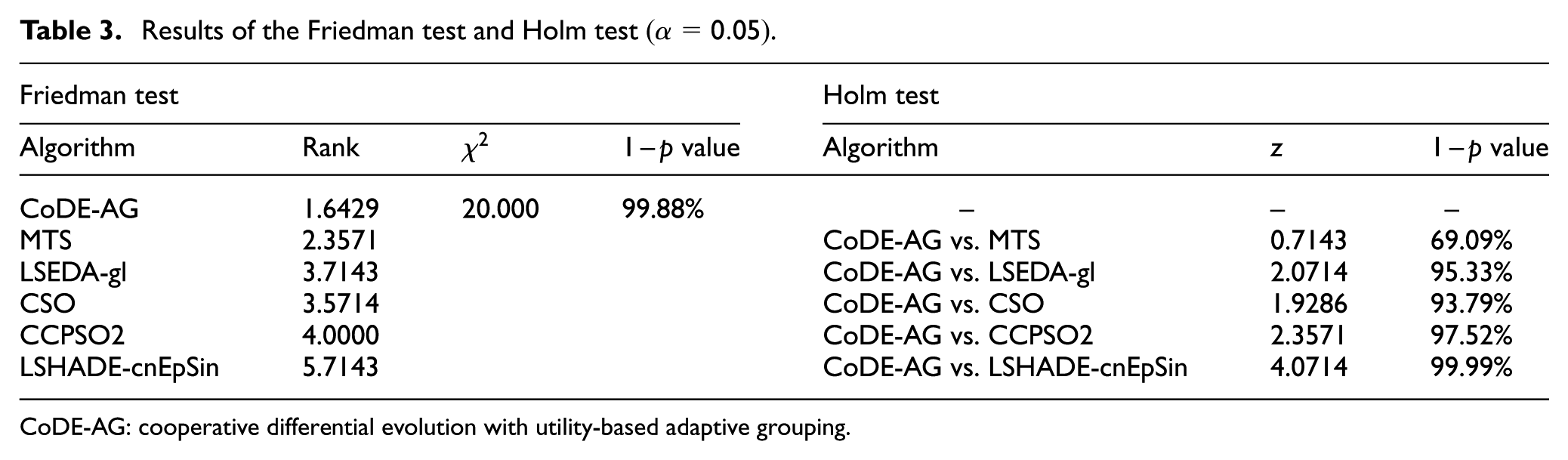
CoDE-AG: cooperative differential evolution with utility-based adaptive grouping.
From Table 1, it can be seen that the CoDE-AG achieves consistently good results on all the functions with 1000 dimensions. From Figure 3, it can be seen that the algorithm can improve the quality of the results steadily until the algorithm halted. From Table 2, it can be seen that the CoDE-AG achieves the best results on three functions (
Results and discussions for CEC2010 benchmark
This subsection presents the results of the CoDE-AG for CEC2010 benchmarks. The dimensionality of the functions is 1000. The results are presented following the instructions reported in the literature associated to the CEC2010.
47
For each run, the experiment is repeated 25 times, and the results after
Results of the 25 independent runs for CEC2010 benchmark functions

FEs: function evaluations; SD: standard deviation.

Plots of evolution curves of the CoDE-AG for CEC2010 benchmarks. The results were obtained from 25 independent runs of the algorithm: (a) f2, dim = 1000; (b) f5, dim = 1000; (c) f8, dim = 1000; (d) f10, dim = 1000; (e) f13, dim = 1000; (f) f15, dim = 1000; (g) f18, dim = 1000; and (h) f20, dim = 1000.
For the purpose of comparison, we first select MA-SW-Chains 38 and DMS-PSO-SHS, 53 whose reported results are top-ranked in the CEC2010 competition . The MA-SW-Chains assigns each individual a local search intensity, and several local search optimizers are applied to perform optimization tasks based on the intensity. The DMS-PSO-SHS divides the population into sub-swarms, then regroups the sub-swarms using regrouping strategies. The information is exchanged among the particles in the whole swarm. Then we select relatively new algorithms that yield high-quality results on CEC2010 benchmarks, that is, the DECC-DG 15 and the DECC-XDG. 23 The DECC-DG adopts a differential grouping strategy and uses DECC to perform CC. The DECC-XDG proposes an extension of differential grouping to identify decision variables with indirect interaction and uses DECC to perform CC. We compare the results of the CoDE-AG with the reported results associated with the algorithms in the original paper. We further select the LSHADE-cnEpSin. For comparison with our algorithm, we extend it to solve 1000-D problems.
Table 5 presents the results from the 25 runs of the CoDE-AG and the results of MA-SW-Chains, DMS-PSO-SHS, DECC-DG, DECC-XDG, and LSHADE-cnEpSin. As recommended in the CEC2010 technical report, all the results are taken at
Comparison results of CoDE-AG and other algorithms for CEC2010 benchmark functions

CoDE-AG: cooperative differential evolution with utility-based adaptive grouping; SD: standard deviation.
Note: The bold values are the best results obtained by these algorithms.
Results of the Friedman test and Holm test

CoDE-AG: cooperative differential evolution with utility-based adaptive grouping.
From Table 4, it can be seen that the CoDE-AG achieves consistently good results on
Results for the RM-based grouping strategy
This subsection aims to show the performance of the RM-based grouping strategy. The experiments are conducted on CEC2010 benchmarks. For each function, the experiments are conducted with and without the relation-based grouping strategy, respectively. The experiments with RM-based grouping strategy are repeated three times, with the maximum number of cycles taken as 5, 8, and 10, respectively. For each run, the experiments are repeated 25 times. Table 7 presents the mean error and standard deviation of the 25 runs.
Results of experiments with different RM settings.

CoDE-AG: cooperative differential evolution with utility-based adaptive grouping; RM: relation matrix; SD: standard deviation.
Note: The bold values are the best results obtained by these algorithms.
It can be seen from Table 7 that for the separable functions
CoDE-AG for material optimization of dome structure
In order to validate the effectiveness of the proposed CoDE-AG for the large-scale optimization problems in real-world scenarios, the CoDE-AG is applied to the material volume optimization of dome structures. In the example adopted in this article, the dome structure is composed of truss beams and some vertical pillars. It is a double spherical structure of concentric double spheres with inner spherical radius of

The top view and flat view of dome after adding load and fixed nodes.
Assume that the specific design load is a snow load of


where
The objective is to optimize the distribution of the cross-sectional area of the materials under the condition that the stress does not exceed the maximum. The fitness function can be taken as follows

where

Given the cross-sectional area of each material group, the maximum stress of the dome structure can be obtained by the displacement of the connecting rod using the finite element toolkit. The maximum number of fitness evaluation is taken as
Comparison results on material optimization of dome structure.

SD: standard deviation; Total-MaterVol: total volume of materials for the optimal scheme; Max-DeforDist: maximum deformation distance of the connecting rod; CoDE-AG: cooperative differential evolution with utility-based adaptive grouping.
Note: The bold values are the best results obtained by these algorithms.
Discussions
The results of the CoDE-AG can be summarized as follows:
On the CEC2008 and CEC2010 benchmarks, the Friedman test results indicate that the CoDE-AG obtains the best overall rank.
On the CEC2008 and CEC2010 benchmarks, the Holm test results indicate that the CoDE-AG yields better results than the compared algorithms, and the differences are statistically relevant with different certainty.
The RM strategy is effective in capturing the variable interactions without incurring extra computational burden to the algorithm, thus facilitating the algorithm to decompose a large-scale problem into small-scale subproblems .
The proposed CoDE-AG is effective for the practical engineering application problems, such as material optimization of dome structure.
The reason that the CoDE-AG obtains such results relies on the following issues. First, the CSC considers the variable interactions on the basis of short-term utility, and the RM-based grouping strategy considers the variable interaction on the basis of long-term utility. Thus, the interacted variables have high opportunities to be optimized in the same subproblem, which facilitates the divide-and-conquer of CC optimization. The experiments here illustrate the usefulness of the proposed algorithm and provide a guideline for researchers when designing related algorithms.
Conclusion
To solve optimization problems, especially large-scale optimization problems, it is essential to decompose the problem into small-scale subproblems and to optimize the subproblems cooperatively. For problem decomposition, a CSC and an RM-based grouping strategy are proposed. In the controller, the circular sliding window slides across different regions of the variable blocks and provides baselines for the subproblem optimizer. Moreover, the sliding speed and the size of the window are adaptively adjusted according to the performance of the latest optimization cycle and the activeness of different regions of the variable blocks. The RM strategy groups the variables and provides opportunities for interacted variables being grouped adjacently. The proposed two strategies are executed alternatively so that the short-term and long-term utilities of the variable interactions can be utilized. The contributions lie with the fact that they decompose the problem concerning the variable interactions as well as avoid incurring extra computational burden to the algorithm. The performance of the proposed algorithm is tested on the CEC2008 and CEC2010 benchmarks, and practical scenarios. Simulated results show that the proposed algorithm can perform well on the large-scale optimization problems, especially when the problem is partially independent.
Footnotes
Handling Editor: Wanli Li
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors are grateful to the support of the National Natural Science Foundation of China (61572104, 61103146), the Fundamental Research Funds for the Central Universities (DUT17JC04), and the Project of the Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Jilin University (93K172017K03).