
Abstract
Fault diagnosis is important for the maintenance of machinery equipment. Due to the randomness and fuzziness of fault, the relationship between fault types and their characteristics are complicated. Therefore, the determination of fault type is a challenging part of machinery fault diagnosis with the traditional method. To tackle this problem, a fault diagnosis approach based on the technique for order performance by similarity to ideal solution with Manhattan distance is presented in this article. First, the similarity measure between the fault model and the detection sample is constructed based on the Manhattan distance. Then, the similarity is transformed into intuitionistic fuzzy set and the generated intuitionistic fuzzy set is fused by the intuitionistic fuzzy weighted averaging operator. On this basis, the technique for order performance by similarity to the ideal solution approach is utilized to obtain the final rank to ascertain the fault type. The proposed method can handle an intricate relationship between multiple fault types and their various fault characteristics and better express uncertain information. Finally, a fault diagnosis example of the machine rotor and comparative study are conducted to illustrate the application and the effectiveness of the proposed method.
Keywords
Introduction
With the development of modern large-scale production, the complexity of machinery equipment is increasing. Machinery equipment fault diagnosis technology is one of the basic measures to ensure the safe operation of equipment, which can take early warning of the development of equipment fault, make judgment on the causes of fault, propose countermeasures and suggestions, and avoid or reduce the occurrence of accidents. Therefore, the fault diagnosis technology has received great attention, and it has become one of the highlight research directions in the self-control community, such as expert system, neural network, and fuzzy logic–based system. 1 Fault can be understood as at least one important characteristic or variable in the system deviates from the normal range. Broadly speaking, fault can be considered as any abnormal phenomenon of the system, which causes the system to show undesirable characteristics. 2 In the process of fault diagnosis, due to the randomness and fuzziness of fault, the relationship between fault and its characteristic is complicated. One fault often can show various characteristics, and the same characteristic can be caused by different faults. Therefore, it is necessary to comprehensively use various characteristics to determine the fault type.
In general, the fault diagnosis approach can be classified into three categories: signal processing–based, 3 analytical model–based, 4 and knowledge-based 5 approaches. In the signal processing–based approach, signal models such as correlation function, spectrum, autoregressive moving average, and wavelet transform are used to directly analyze measurable signal and extract features such as variance, amplitude, and frequency, and therefore the fault type is determined. 6 The analytical model–based approach uses the certain mathematical method to process the measured information based on the clear mathematical model of diagnosis. 6 Usually, difficulty occurs in building the accurate mathematical model of the object, which greatly limits the scope of using the analytical model–based method. Moreover, knowledge-based approach requires a large amount of historical data, comparing with the mathematical model or signal pattern. 7
The knowledge-based fault diagnosis approach is also called the data-driven fault diagnosis approach. 8 Knowledge information can be obtained based on qualitative or quantitative characteristic. Therefore, knowledge-based fault diagnosis method can be classified into the qualitative and quantitative methods. 7 The qualitative method includes the expert system–based method.9,10 The quantitative method can be roughly divided into statistical analysis–based and non-statistical analysis–based methods. 11 The former is mainly composed of principal component analysis (PCA),12,13 partial least squares (PLS),14,15 independent component analysis (ICA),16,17 analytic hierarchy process, statistical pattern classifiers, 18 reliability analysis, 19 and the most recently developed support vector machine (SVM),20–22 whereas the latter includes complex network,23–26 fuzzy logic,27–37 information fusion,38,39 evidential reasoning,40–44 and multiple decision making.45–49
The notion of intuitionistic fuzzy set (IFS) can be viewed as a natural generalization of usual fuzzy set. In general, available information is not sufficient for the definition of an imprecise concept by means of an ordinary fuzzy set. 50 IFS characteristics are simultaneously concerned with the degree of membership, the degree of non-membership, and the hesitancy degree, while an ordinary fuzzy set is characterized by only the degree of membership. Therefore, IFS is a more effective way to deal with vagueness than an ordinary fuzzy set. Recently, IFS is studied and utilized in the domain of fault diagnosis, which is typically a data-driven approach. Hung et al. 51 handled the turbine fault diagnosis problem with improving cross-entropy measure under the intuitionistic fuzzy circumstance. This method can overcome the situation in which the value of the amplitude ratio of the turbine vibration signal is uncertain. Miao and Wang 52 demonstrated that the intuitionistic fuzzy fault tree analysis to solve the problem that accurate data concerning the likelihood of failure of a given component are unavailable and the estimation of experts are usually linguistic and uncertainty. Kumar and Yadav 53 proposed weakest t-norm based on intuitionistic fuzzy fault tree analysis to calculate the fault interval of system component by integrating expert’s knowledge and experience. The approach is proposed to find the most critical system component that affects the system operation. In order to handle the uncertainty situation and vague information, Chu et al. 54 extended the concept of fuzzy set by the idea of Atanassov’s intuitionistic fuzzy set (AIFS) and then utilized the similarity measure by which the rank of fault diagnosis can be obtained. Liu et al. 55 combined IFS and ordered weighted averaging operator to put forward a new type of fuzzy petri net (FPN) model for the problem of fault diagnosis in an aircraft generator. The model enhanced the knowledge representation and reasoning capability, and overcame the deficiencies of the former FPN model. Sun et al. 56 introduced rough set and IFS, based on which an intuitionistic uncertainty-rough set was presented and the reduction algorithm was improved to enhance the accuracy and rapidity of fault diagnosis. Darong et al. 57 analyzed hidden Markov model (HMM) algorithm and improved the algorithm for fault diagnosis of motor equipment of urban rail transit. The authors had designed an online fault classification system with an adaptive model and achieved a good rate recognition in motor equipment.
From the above analysis, the existing methods established the corresponding fuzzy model through different algorithms for fault diagnosis. There is difficulty in establishing a fuzzy model when dealing with the complex relationship between multiple fault types and their various fault characteristics, so the aforementioned methods cannot reflect the uncertainty of the fault information well, and the calculation process is troublesome. In order to solve those problems, the aim of this article is to develop a fault diagnosis method based on the technique for order performance by similarity to ideal solution (TOPSIS) with Manhattan distance under the IFS. The proposed method is able to deal with the complex relationship between multiple fault types and their various fault characteristics in a more flexible and effective manner. A concept of IFS developed by Atanassov 58 is introduced in this article to handle the uncertainty, imprecision, and incompletion of information. The degree of membership and the degree of non-membership of the IFS are fuzzy values rather than exact numbers. In the case of considering the intuitionistic fuzzy value, the IFS is generated according to the similarity measure. The similarity measure between the fault model and the detection sample is constructed based on the Manhattan distance. Then, the generated IFS is fused by the intuitionistic fuzzy weighted averaging (IFWA) operator. Afterwards, the fault type can be determined by the application of the TOPSIS method. The proposed method takes into account the similarity measure and converts similarity into intuitionistic fuzzy information, which can not only handle an intricate relationship between multiple fault types and their various fault characteristics, but also better express uncertain information to improve the reliability of fault diagnosis.
The remainder of this article is set out as follows. In section “The proposed method,” the proposed method is presented and the procedures are illustrated in detail. In section “Diagnostic experiment,” practical application for machine rotor and comparison analysis are given to illustrate the effectiveness and feasibility of the proposed methodology. Some summary remarks are given in section “Conclusion.” The concept of IFS, the TOPSIS method, the IFWA operator, and Manhattan distance are introduced (see Appendix 1).
The proposed method
In this section, a method is proposed to determine the fault type of the detection sample. The flowchart of the proposed method is presented in Figure 1.
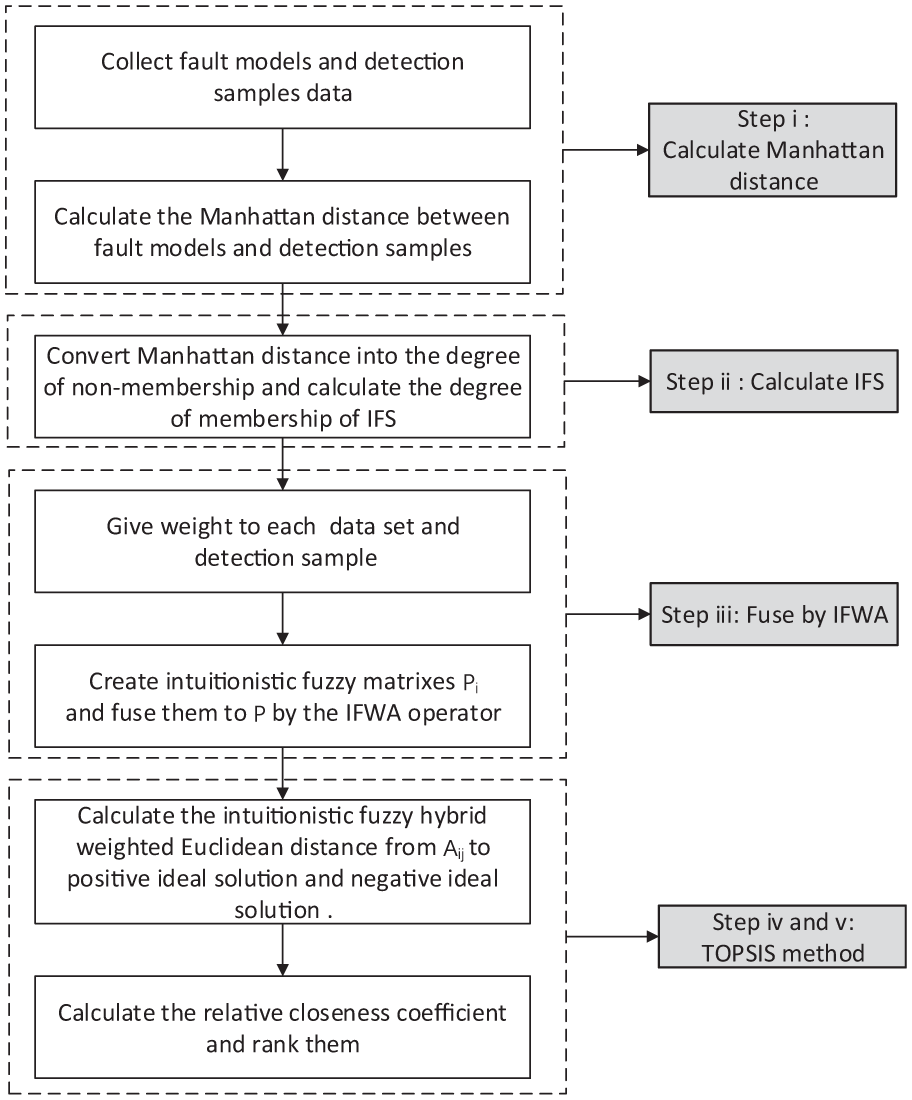
The flowchart of the proposed method.
Then, the detailed steps for the proposed method are explained as follows:
1. Let

where
The distance matrix

2. Determination of the degree of non-membership of IFS is a key step for the proposed method. The degree of non-membership is generally determined by practical experience and fuzzy statistic. Manhattan distance

Then the degree of membership

3. In the actual work, the fault type analysis is insufficient, and the law of fault occurrence is not found. Therefore, the weight of each fault type is not counted. In this case, the statistical mean method is usually used to determine the weight of each fault type, that is, the weight of each fault type is proportionate. This method embodies the random ambiguity of weight, which is simple and easy to use, and is more commonly used in practice. In this article, without loss of generality, the weight of each data set of fault type is denoted as

4. Calculate the intuitionistic fuzzy hybrid weighted Euclidean distance from

where
5. Calculate the relative closeness coefficient between the fault model and the detection sample by equation (25). The relative closeness coefficient indicates proximity between the fault model and the detection sample. It is obvious that the greater value of
Diagnostic experiment
Experimental settings
This section verifies the effectiveness of the proposed method using the example of ZHS-2 machine rotor fault diagnosis. The experimental equipment is a ZHS-2 multi-functional flexible rotor test bench. The vibration displacement and acceleration sensors are, respectively, placed in the horizontal and vertical directions of the rotor support. The measurement of the rotor vibration signals is transmitted to the upper computer through an HG-8902 collection box. The fault characteristic can be extracted from these signals by HG-8902 data analysis software under LabVIEW environment. The vibration acceleration frequency of the rotor and the average amplitude of vibration displacement were used as the fault characteristics. 59
Three typical fault types of the machine rotor system are considered: rotor imbalance
The diagnostic process and results
The procedure for the determination of fault type contains the following steps:
1. Calculate the Manhattan distance of the same characteristic between the fault model and the detection sample by equation (1). For example, assuming that

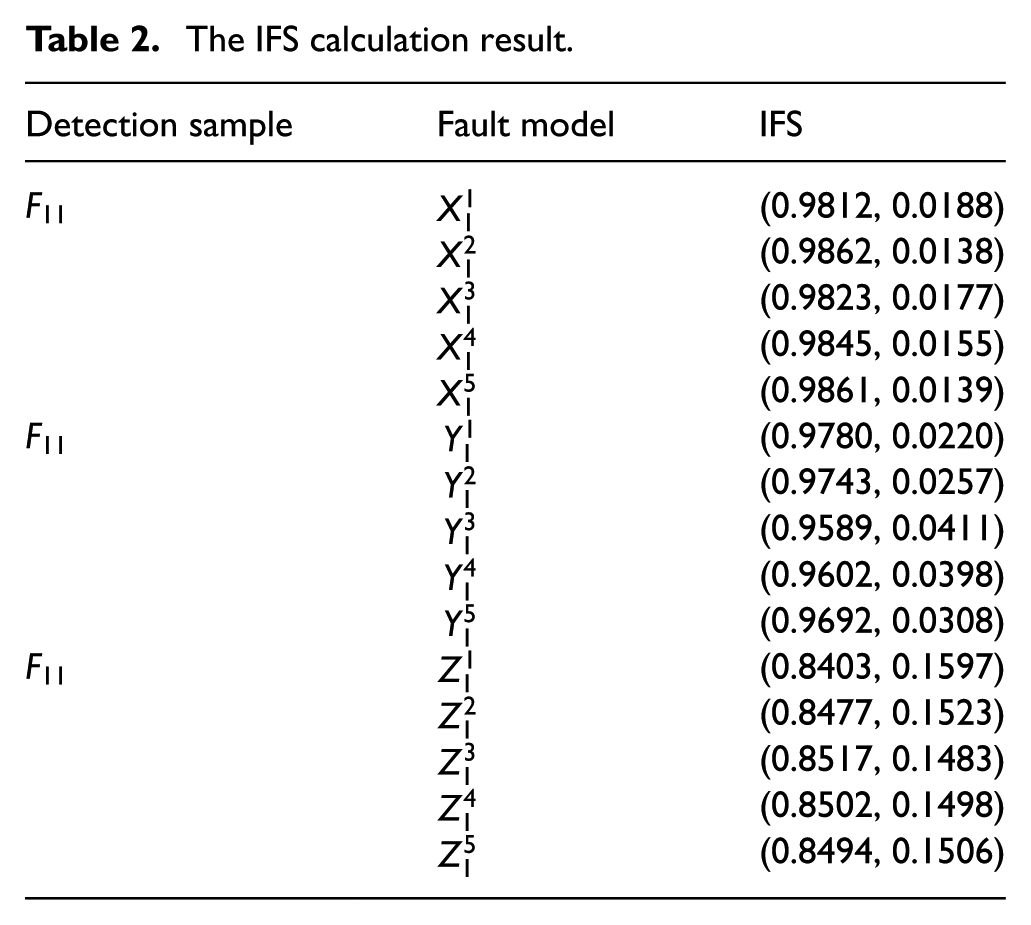
2. Transform the Manhattan distance into the degree of non-membership of IFS by equation (3), and then the degree of membership of IFS can be calculated via equation (16). Taking the distances in Table 1 as an example, the obtained IFSs are listed in Table 2 and some calculation procedures are as follows

3. The weight of the five data sets of each characteristic are denoted as

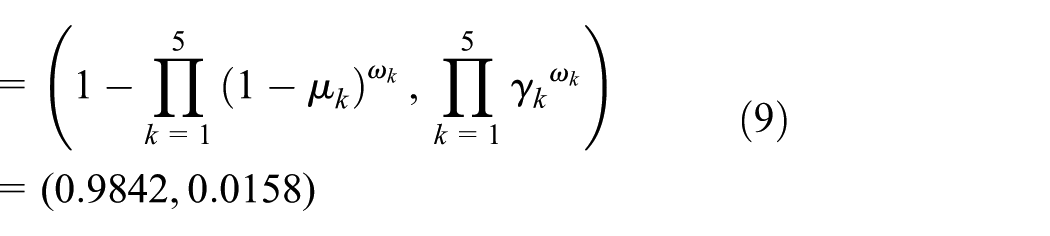

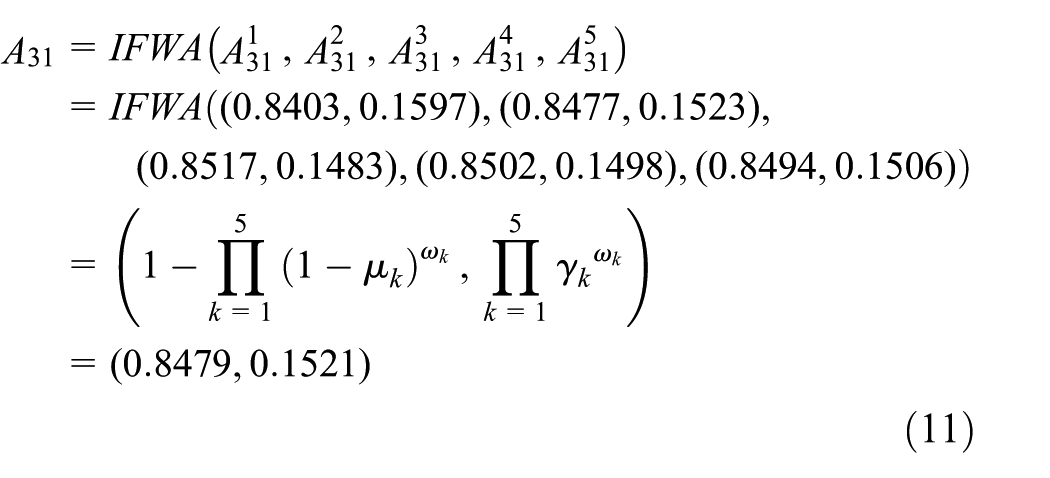
The distance calculation result.

The IFS calculation result.
In the same way, other fusion results between the fault models and the detection samples are obtained, as shown in Table 3. From Table 3, taking

4. Calculate the intuitionistic fuzzy hybrid weighted Euclidean distance from


5. Calculate the relative closeness coefficient by equation (25). The relative closeness coefficient

The fusion result of

Calculation results of

The relative closeness coefficient and rank by the proposed method.

Analysis and comparison
From Table 5, it can be seen that the diagnostic results of detection samples are correct, that is, these detection samples belong to the corresponding fault types. The relative closeness coefficient
To further illustrate the effectiveness of the proposed method and compared it with that of the other existing method. Taking the motor rotor fault diagnosis as an example, the diagnostic results of the proposed method and the existing method are shown in Table 6.
A comparison between the existing method and the proposed method.
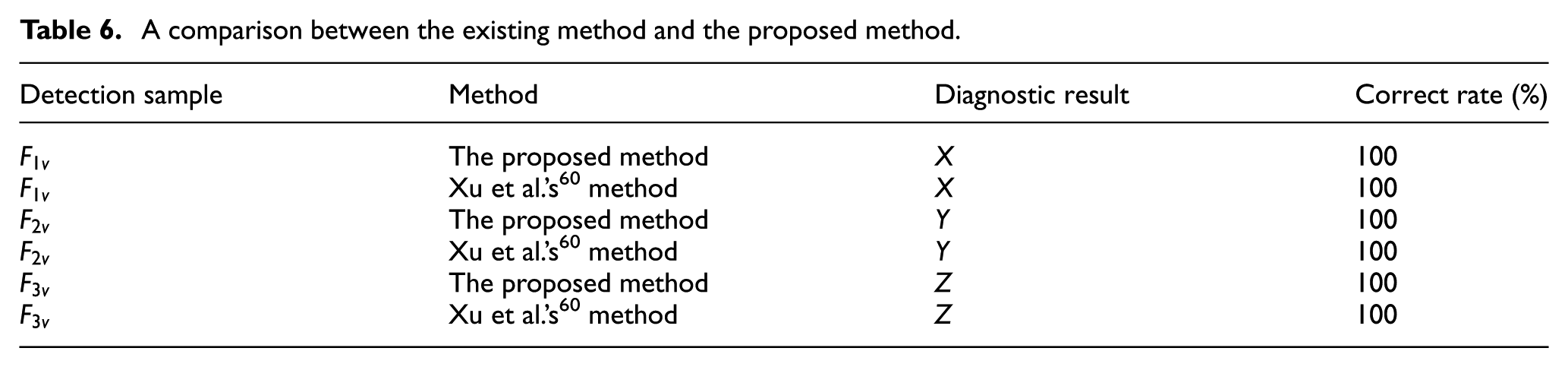
From the results shown in Table 6, it can be seen that the diagnostic results of the proposed method are consistent with those of Xu et al.’s
60
method. The detection samples
Conclusion
The determination of fault type is the key issue in machinery fault diagnosis. In this article, a method based on TOPSIS with Manhattan distance for fault diagnosis is presented. First, Manhattan distance is used to calculate the similarity between the fault model and the detection sample. Then, the IFS is determined based on the distance and the IFWA operator is used to fuse the generated IFS. Finally, the ranking order can be obtained by TOPSIS to determine the fault type. This study has contributed by presenting the Manhattan distance and the existing TOPSIS method to adopt to the complex relationship between multiple fault types and their various fault characteristics based on the IFS. And the intuitionistic fuzzy numbers under the same fault characteristic can be obtained by Manhattan distance, in which not only the original information can be fully utilized, but also the uncertainty of multiple sets of sample data can be processed. Using the IFWA operator to fuse different data under the same fault characteristic, the uncertainty of fault information is more accurate and the accuracy of fault diagnosis is improved. Furthermore, the ranking order can not only reveal the most possible type of fault occurred, but also point out the rank of fault diagnosis. The machine rotor fault diagnosis example is carried out to verify the proposed method in this article, and the results illustrate that the proposed method can effectively diagnose the fault type of an unknown detection sample. And this methodology is computationally simple and its basic concept is reasonable and comprehensible, and thus the application of the proposed methodology to more complicated case studies is also suggested to further demonstrate and verify the method proposed in this article.
Further research will mostly focus on the following directions. First, the attribute weight coefficient can be obtained by arranging, calculating, and analyzing the existing objective information. Second, in the actual work, the effect of weighted average fusion is not optimal. Therefore, more efficient fusion algorithms combined with the proposed method need to be developed.
Footnotes
Appendix 1
Handling Editor: Vesna Spasojević Brkić
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Foundation of China (Program Nos 61671384 and 61703338) and the Natural Science Basic Research Plan in Shaanxi Province of China (Program No. 2018JQ6085).