
Abstract
There are many hyper-parameters to be tuned in both machine learning model and deep learning model, and the structure of the deep learning model is large and complicated, making it extremely difficult for fault-feature extraction and classification. In order to address these two problems, a deep learning diagnosis method is proposed in this study by combining adaptive local iterative filtering and ensemble hierarchical extreme learning machine. Adaptive local iterative filtering and entropy feature matrix are used to extract fault features, and an ensemble hierarchical extreme learning machine with deep learning architecture is proposed for unsupervised feature learning and supervised classification. The proposed deep learning diagnosis scheme is tested on fault benchmark datasets under different severity conditions to verify its effectiveness and accuracy. The test results show that the proposed method performs better than traditional extreme learning machine and other variants.
Keywords
Introduction
The bearings and other components of a rotating machine often fail in harsh environments, which can result in unexpected breakdown and considerable productivity losses. 1 A prompt and accurate diagnosis of fault type and severity is essential to prevent components from catastrophic failures and to optimize maintenance schedules. The intelligent fault diagnosis model plays a key role in machine safety operation and has become a hot research topic in recent years. 2
Fault signals usually exhibit nonstationary and nonlinear characteristics due to the nonlinearity of components, such as stiffness and clearances. 3 Conventional linear signal processing algorithms, such as kurtosis, skewness, and fast Fourier transform, may not effectively characterize fault information embedded in nonstationary and nonlinear signals. Hence, an advanced algorithm with good resolution performance in both time and frequency domains is the crux of fault signal processing and feature extraction. 4 The wavelet analysis theory (WT) is a well-known nonlinear signal processing method with a wide range of applications.5,6 A potential shortcoming of WT is that the decomposition scales rest on the designated wavelet basis function and it is not signal-adaptive. However, this can be overcome in another signal decomposition method called empirical mode decomposition (EMD). EMD is designed with a data-adaptive scheme to extract a set of AM-FM (Amplitude Modulation–Frequency Modulation) simple components named intrinsic mode functions (IMFs) from original vibration signals. 7 The iteration process of EMD is to find an intrinsic oscillatory mode represented by IMF contained in the signal. EMD and its variants perform better in extracting sensitive fault symptoms than WT.8,9 However, EMD also has some shortcomings, such as mode aliasing and endpoint effects. A novel method, adaptive local iterative filtering (ALIF), uses smooth low pass filters to decompose signals to avoid the shortcomings of EMD, and the length of smooth low pass filters is constructed adaptively by solving Fokker–Planck second-order partial differential equation.10,11 These filters satisfy the derived sufficient conditions for the convergence of the iterative filtering (IF) algorithm. Therefore, more accurate data about the components of a nonstationary signal can be obtained, and it also suppresses mode mixing. Moreover, the ALIF method has been shown to outperform EMD in fault-feature extraction.12–14
Another important issue in fault diagnosis is the construction of fault classifiers, which can be achieved by many advanced intelligent classification methods, such as Bayesian network, 15 neural network, 8 and support vector machine (SVM). 16 However, these methods based on the shallow learning theory often have some problems. Thus, much prior domain knowledge is often needed, and the representative capability of extracted features could decrease when the fault data contain different data sources or working conditions. 17 Therefore, feature learning and extraction using unsupervised manner have become a hot research topic.18–20
Recently, the deep learning (DL) model has been proposed to unsupervised learn optimal feature by extracting high-level features from low-level features. 21 In DL, nonlinear transformations are performed from the previous layer to the next layer, and the back-propagation algorithm is used to optimize the classification model and can approximate complex nonlinear functions with small training errors. DL has been widely used in fault diagnosis. Janssens et al. 22 used convolutional neural networks (CNNs) to autonomously learn fault features from raw data in several types of bearing faults. Lu et al. 23 investigated stacked denoising auto-encoder (SDA) for rotating machinery fault detection. Shao and colleagues24,25 proposed a novel deep auto-encoder fault diagnosis method for gear box and motor locomotive rolling bearing and applied improved convolutional deep belief network (CDBN) with compressed sensing (CS) for feature learning and fault diagnosis of rolling bearing. Tamilselvan and Wang 26 proposed an aircraft engine fault diagnosis method based on deep belief network (DBN). He et al. 27 applied an improved DBN for fault diagnosis of gear transmission chain. Qi et al. 28 proposed an induction motor fault classification model based on the sparse auto-encoder-based deep neural network (DNN).
Current DL-based fault diagnosis methods, although powerful, still have several apparent shortcomings: (1) there are many hyper-parameters in the DL model because of its deep and large structures, and the diagnosis results are sensitive to these hyper-parameters,29,30 and (2) the structures of DL model are large and complicated. Thus, many weights and parameters need to be tuned in the training phase, and thus, much training time is needed to tackle massive fault data. Extreme learning machine (ELM), as a mighty fault classification algorithm method, has a remarkable performance and fast training speed. 31 Unlike traditional methods, the input weights and hidden biases of ELM do not need to be tuned and randomly chosen, and the generalization performance could be improved. 32 A new H-ELM-based DL structure was proposed with multi-auto-encoder hidden layers. H-ELM used an auto-encoder feature learning method. Different from traditional DL method, the output of hidden layers in H-ELM does not need train model in the greedy layer-wise manner, and the optimal solution can also be obtained by one-shot learning. Thus, a much shorter training time is needed for H-ELM than for other DL algorithms. 33 Nevertheless, H-ELM sometimes shows unstable and nonoptimal classification results due to the randomness of assigned parameters.34,35
In this research, we proposed an intelligent fault diagnosis model to tackle the above problems. Initially, ALIF was used to decompose fault signals and extract fault features. Then, the popular entropy-based fault indicator, permutation entropy (PE) and sample entropy (SampEn), was used to obtain the fault feature of each IMF component. An ensemble hierarchical ELM with DL architectures was proposed to achieve unsupervised feature learning and supervised classification. Then, a set of H-ELM was assembled to improve its stability, which was referred to as ensemble hierarchical extreme learning machine (EH-ELM) in this article. ALIF and entropy feature matrix were used to extract fault features. A DL diagnosis method was proposed in this article by combining ALIF and EH-ELM. In addition, the effectiveness and accuracy of the proposed DL diagnosis scheme were tested on fault benchmark datasets under different severity conditions. The results showed that the proposed method performed better than traditional ELM and other variants.
The main contributions of this article are summarized as follows. (1) As a powerful time-frequency analysis technique, the ALIF method is used to obtain multi-scale SampEn and PE features. (2) An ELM-based DL diagnosis model is proposed to improve the diagnosis performance. The diagnosis model could unsupervised learn the sensitive features with multi-auto-encoder hidden layers. Compared with the traditional DL model, the proposed model requires no tuning of input weights and determination of fewer hyper-parameters, making it more suitable for practical engineering problems. Moreover, the ensemble strategy is used to improve the stability of the diagnosis model.
The rest part of this article is organized as follows. The “Background” section describes the theory of this article; “System framework and procedures” section describes the proposed EH-ELM model and the diagnosis scheme; “Performance and result analysis” section describes the effectiveness of the proposed diagnosis model; and main conclusions are drawn in “Conclusions” section.
Background
ALIF
The ALIF method is based on the IF technique, 10 and it can improve the performance of IF by adaptively calculating the moving average of signals. 11 Inspired by the EMD, the ALIF method contains two loops: the inner iteration produces a single IMF and the outer iteration captures all IMFs. The updating steps of ALIF are described as follows:
Given a nonstationary signal

where

where S is the sample point number of signal

If
In the outer iteration, the previous process should be applied to the remainder signal

The flowchart of ALIF.
PE
PE is proposed as a randomness measure tool for nonstationary time series, which can characterize the complexity of local order structure for complex system analysis. A low PE value means that the time series has regularity. Once impact fault occurs, the regularity of time series changes and the PE value increases. A PE value of N sample points
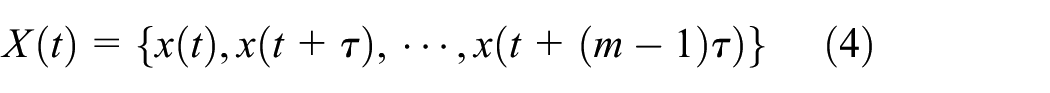
where

where

where the factor
SampEn
SampEn is a complex statistical measure for the regularity of time series.
37
Considering the time series

where m is the compared sequence length.
The distance between two such vectors is defined as
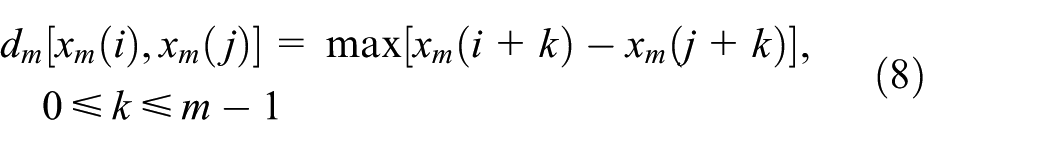
Then, SampEn is defined as

where r is the tolerance for accepting matrices;
H-ELM
ELM is a novel feed-forward network with a single hidden layer, which has the advantage of fast learning.
31
Assuming that there are N data samples


where β is the output vector of weight, T is the input training sample, and H is the hidden layer matrix.
The loss function of ELM is designed to combine training error and output weight norms, which could improve the generalization ability of ELM. Hence, β is calculated analytically as follows
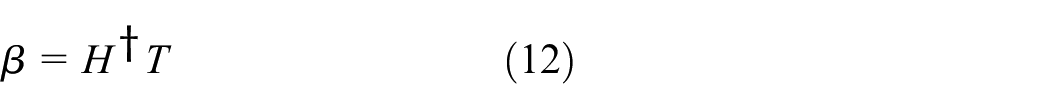
where
H-ELM is designed to expand the ELM algorithm to the DL structure. 33 The training architecture of H-ELM contains two separate stages: unsupervised feature learning and supervised classification. In the first stage, the input vector is mapped into the random feature space of ELM. In addition, the high-level sparse features are obtained through the N-layer unsupervised learning. The output vector of the hidden layer could be described mathematically

where
An ELM-based

where X is the input vector, and
The final fault classification is computed by the original ELM using the learning feature matrix. The multi-layer structure of H-ELM is shown in Figure 2.

The DL structure of H-ELM.
Ensemble method by majority voting
Due to the simplicity of H-ELM and random parameter selection, H-ELM will probably show low generalization ability in dealing with complex fault features under noisy environment and various working loads. In this article, an ensemble method is applied to improve the classification accuracy of H-ELM, which is named as EH-ELM. The majority voting has been widely applied in different ensemble learning methods due to its convenience and intelligibility. For a N-class diagnosis problem, a fault sample j should have N results which are calculated by the H-ELM classifier, and an ensemble of H-ELM classifier is constructed. The final results are combined to obtain the final diagnosis result via majority voting. More specifically, the class that receives the highest votes is considered as the predicted label, and the total vote received by each class is calculated as

where
System framework and procedures
A novel DL diagnosis scheme is proposed in this section, which consists of five main steps. In order to evaluate the performance of the developed DNN-based fault diagnosis system in feature extraction and identification, four pretreatment schemes are considered.
Step 1: The vibration fault data of machine components are collected by condition monitoring system, and ALIF is used to obtain IMFs with different frequency sub-band according to equations (1)–(3).
Step 2: The feature matrix of the first m IMFs is constructed by calculating all permutation and SampEn of sub-signals decomposed by ALIF according to equations (4)–(9).
Step 3: Various H-ELM models are initialized with the same structure and hidden node number according to equations (10)–(14). Then, the training and testing datasets are constructed from original datasets as predetermined percentage, and all H-ELM models were performed on the training process.
Step 4: The majority voting is used to ensemble the outputs of these H-ELMs, and the final result is the highest number of votes.
Step 5: Finally, an EH-ELM classier is used to identify fault types of test samples. The overall flow diagram is shown in Figure 3.

The flow diagram of the proposed diagnosis scheme.
Performance and result analysis
Experiment description
The EH–ELM diagnosis model was applied on Case Western Reserve University (CWRU) fault diagnosis benchmark datasets. 38 The rolling element bearings test stand consists of an induction motor supported on the left, a torque transducer/encoder at the center, and a dynamometer on the right. Figure 4 shows the test rig. All numerical computations were implemented in MATLAB 2015b on a laptop computer with Intel Core i7 CPU.

The bearing fault test rig.
We chose fault signals with a defect size of 0.007, 0.014, and 0.021 at 0 hp load and 48,000 Hz. To construct the feature matrix, the length of sub-signal was set to 4096. Figure 5 shows the waveform of nine fault types.

The waveform of nine faults.
Each sub-signal was decomposed by ALIF. Figure 6 shows the inner race fault waveform decomposed sub-signals. The first 10 IMFs which reached 95% of the total accumulation energy of the original signal were chosen to construct the feature matrix. And each IMF signal was calculated to obtain permutation and SampEn to represent the fault type and severity.

ALIF decomposed results.
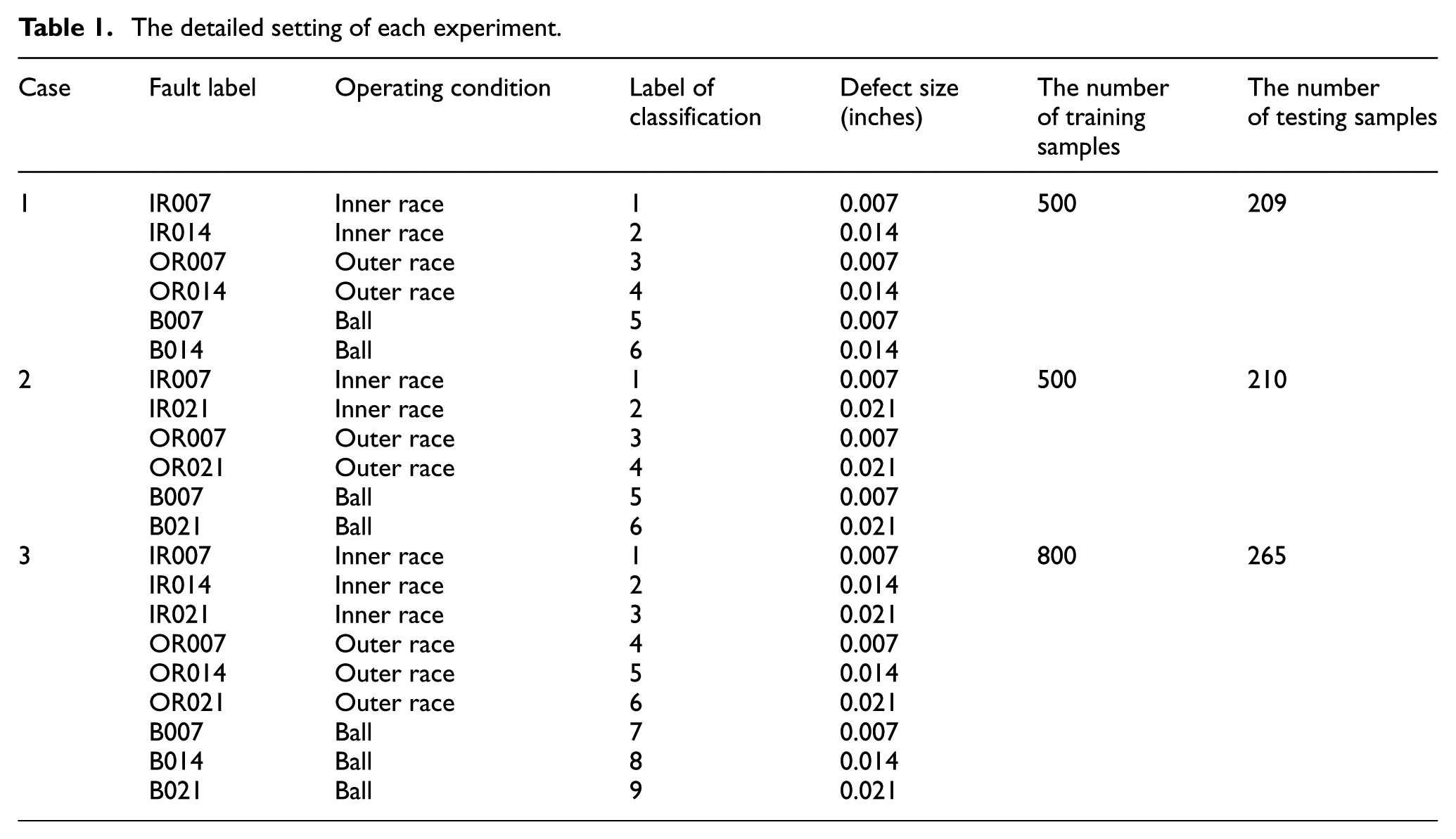
Three cases of experiments were carried out to evaluate the performance of the proposed method based on the above experimental results. Case 1 has three bearing fault types, including inner race fault, outer race fault, and ball fault with a severity level of 0.007 in and 0.014 in; Case 2 has the same bearing fault types as Case 1, except that the severity levels are set to 0.007 in and 0.021 in; and Case 3 has all the nine classes faults. In each experiment, the dataset was sorted randomly, part of which was selected as training data, and the rest of which was selected as testing data. The description of each experiment is shown in Table 1.
The detailed setting of each experiment.
Result and analysis
In this section, the performance of ALIF entropy features is verified and compared with the traditional EMD and energy feature. Moreover, the feature matrices extracted by two methods were classified by original ELM,
32
EE-ELM,
32
and DE-ELM
34
for bearing fault diagnosis. All of these methods have been applied in the same test experiment under similar working conditions. The proposed EH-ELM consists of 10 H-ELM classifiers with the same structure, and each H-ELM has two hidden layers with 40 nodes, yielding a total node number of 400. The node parameters of ELM, EE-ELM, and DE-ELM in Zhou et al.
34
are the same, and the hidden node number is 400. The average accuracy and their corresponding standard deviations of 30 trials are employed to indicate the performance of EH-ELM and other classifiers. Given the final output of fault categories


Table 2 and Figure 7 show that all classifiers using ALIF with entropy features show higher classification accuracy than the method with EMD and energy. In the three tests, the diagnosis accuracy is 98.80%, 99.85%, and 97.66% for the proposed method, and 96.33%, 99.60%, and 94.55% for the EMD + Energy method, respectively. Other classifiers show similar results.
Classification results of different algorithms.
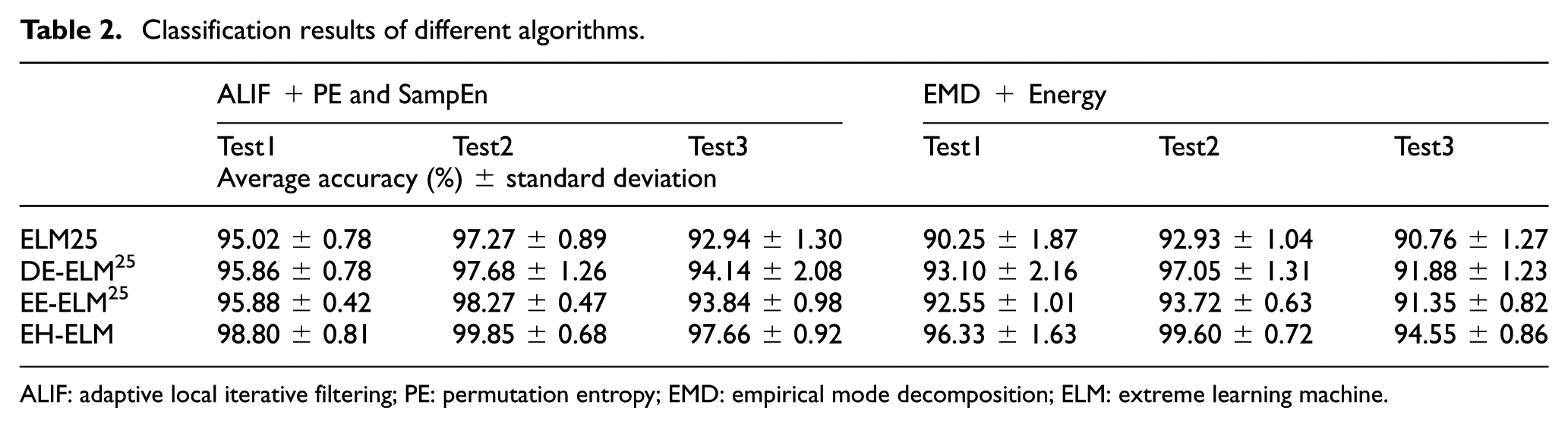
ALIF: adaptive local iterative filtering; PE: permutation entropy; EMD: empirical mode decomposition; ELM: extreme learning machine.

Comparison of results obtained by ELM and other variants.
It shows that ALIF + PE and SampEn have better representation ability. Given the same feature matrix, the rank of the four classifiers is EH-ELM, EE-ELM, DE-ELM, and ELM in every test. It explains that the generalization performance of EH-ELM is improved by the unsupervised feature learning mechanism, which is much more obvious in the large class label number classification problem. Especially, the performance is more significantly improved in Test3, indicating that EH-ELM is more suitable for multi-classification with various loads.
Our method is also compared with back-propagation neural network, multi-layer perceptron (MLP), and standard auto-encoder which use the entropy matrix extracted by ALIF as the feature vector. Table 3 shows the results of these methods with Test3 datasets. Ten trials are carried out for diagnosing each dataset in Table 1, and the results are shown in Figure 8. The average accuracy of EH-ELM and standard deep auto-encoder method is 97.66% and 97.32%, which is much higher than the other two methods (93.88% and 65.67%, respectively). Thus, EH-ELM has similar performance to standard deep auto-encoder. However, the average computation time of EH-ELM is 22.12 s, which is much shorter than the other three methods (179.74, 37.67, and 38.09 s, respectively). It can be seen from Table 3 that (1) EH-ELM shows better classification accuracy than shallow models such as MLP and back-propagation neural network, and (2) the proposed method has obvious advantages over the standard deep auto-encoder in terms of computation time.
Average accuracy and computation time of the four methods.

ELM: extreme learning machine; MLP: multi-layer perceptron; BPNN: back-propagation neural network.
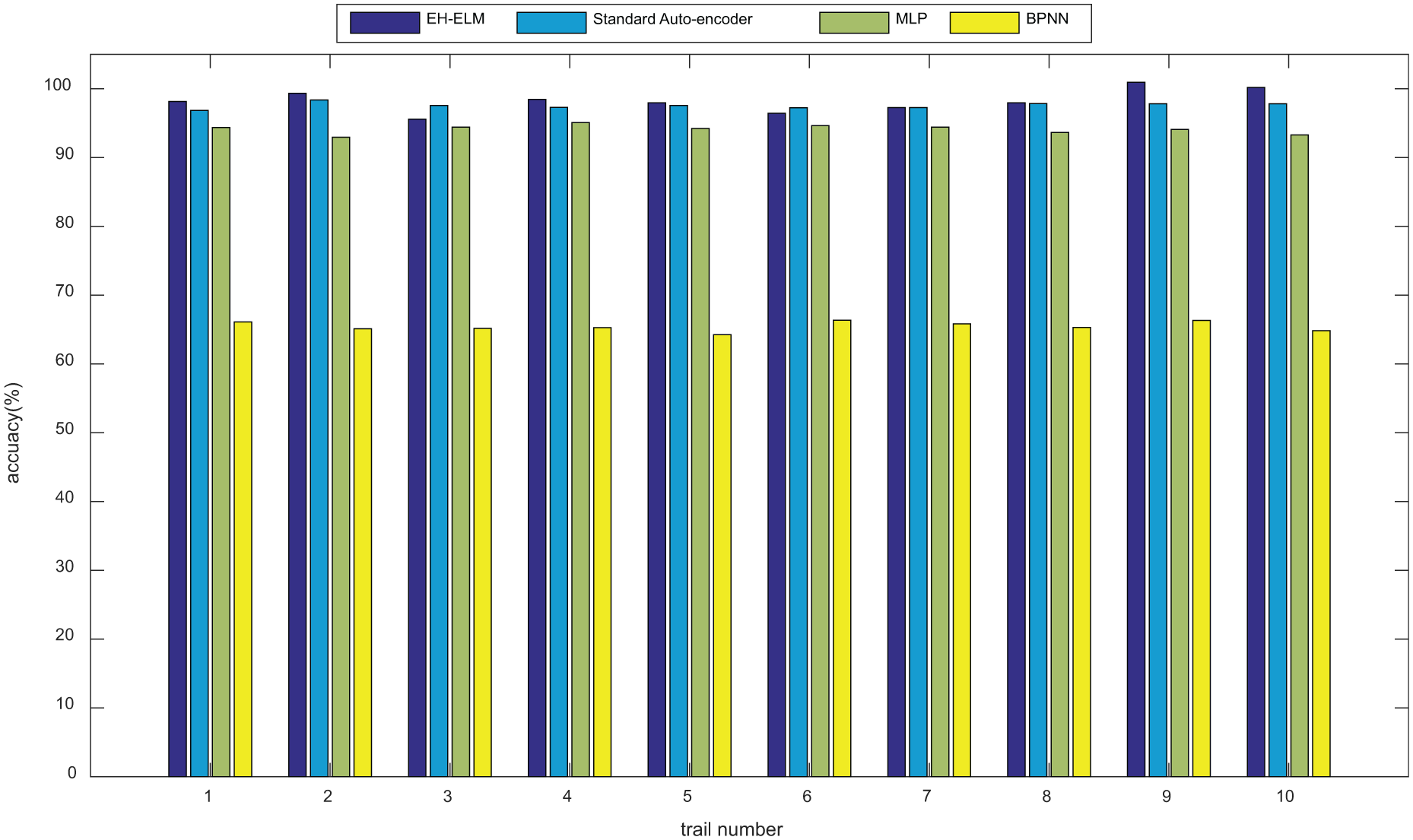
Comparison results with standard auto-encoder, BPNN, and MLP.
Finally, the intuitive classification results of EH-ELM are shown in Figure 9, where different fault types are represented by different symbols. The Y-ordinate indicates the type of fault output from the three test cases, and the X-ordinate indicates the fault sample number. It is shown that the proposed method can reliably recognize different fault categories and severity levels.

Classification results using EH-ELM: (a) Test1, (b) Test2, and (3) Test3.
Discussion
The classification results of the bearing fault diagnosis experiments show that the proposed method based on EH-ELM can significantly improve identification accuracy and generalization performance, which can be attributed to the following: (a) the DL architecture of EH-ELM could find the intrinsic fault information and increase the classification precision, and (b) the ensemble learning strategy of EH-ELM guarantees the stability of the results. Compared with the original ELM, EH-ELM results in an improvement of classification accuracy by 3.78%, 1.14%, and 4.72% on Test1, Test2, and Test 3, respectively. EH-ELM shows better classification performance when there is a relatively large number of fault types. Compared with standard auto-encoder, the proposed method has better robustness and fewer parameters to be tuned. As parameter tuning is a complex problem for machine learning engineers, EH-ELM is more suitable for practical engineering design.
Conclusions
In order to expand ELM to DL diagnosis field, a novel diagnosis scheme consisting of ALIF and EH-ELM is proposed in this study. The proposed DL diagnosis algorithm is applied on CWRU benchmark datasets under different severity conditions to verify its effectiveness and accuracy. The numerical test results demonstrate that the proposed method is more powerful and robust than other ELM variants and conventional shallow models such as MLP and back-propagation neural network. The proposed method is also advantageous over the standard deep auto-encoder in terms of computation time, indicating that EH-ELM is more suitable for practical diagnosis applications.
Footnotes
Handling Editor: ZW Zhong
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is supported by National Key R&D Program of China (2018YFC0406903), the National Science Foundation of China under Grants (No. 51609258), and the National Science Foundation of China under Grants (No. 51779268). In addition, we would be grateful to thank the CWRU center for providing bearing fault datasets.