
Abstract
With the development of Internet of Things, many applications need to use people’s location information, resulting in a large amount of data need to be processed, called big data. In recent years, people propose many methods to protect privacy in the location-based service aspect. However, existing technologies have poor performance in big data area. For instance, sensor equipments such as smart phones with location record function may submit location information anytime and anywhere which may lead to privacy disclosure. Attackers can leverage huge data to achieve useful information. In this article, we propose noise-added selection algorithm, a location privacy protection method that satisfies differential privacy to prevent the data from privacy disclosure by attacker with arbitrary background knowledge. In view of Internet of Things, we maximize the availability of data and algorithm when protecting the information. In detail, we filter real-time location distribution information, use our selection mechanism for comparison and analysis to determine privacy-protected regions, and then perform differential privacy on them. As shown in the theoretical analysis and the experimental results, the proposed method can achieve significant improvements in security, privacy, and complete a perfect balance between privacy protection level and data availability.
Introduction
In recent years, Internet of Things (IoT) has gradually become a popular guide in people’s lives, thus forming a large number of applications related to its background scene. 1 In the current era of the Internet, various communication and interconnection devices are developing rapidly. With the development of the IoT, information communication between devices becomes more frequent. In order to provide better services to users, these devices often collect some private information, which causes the user’s privacy disclosure. 2 As a result, the open interconnected environment brings many threats to the society. Nowadays, people are paying attention to the privacy problems in a serious attitude. 3
Location-based service (LBS) 4 is a hot topic in current mobile terminal services which is widely used in the current mobile application market. In the shopping application, using the LBS to obtain the user’s location not only omits the cumbersome process of manually inputting the location information but also provides the basis for the location information of the distribution warehouse. When considering the navigation background, the LBS obtains the location information of the user in real time and returns information to the user, making the acquisition and query of road condition information more intuitive and simple; in addition, in various social applications such as social, weather, taxi, group purchase, and travel, LBS plays an important role.5,6 The geographic location information provided by LBS can enrich the functionality of the application and greatly enhance the user experience.
However, while improving the user experience, the LBS application needs to collect the user’s geographic location information. Body sensor network (BSN) 7 is a perfect way to make use of LBS. It forms a huge database by collecting real-time uploaded information data from various portable devices. For example, people use their smart phones to submit their location anytime and anywhere. However, these data brought by people can be easily stared by various attacker. 8 Therefore, it is essential to propose a strategy for BSN.
We found that location information can outline the general characteristics of a person. If we get some important information, we can analyze the address, work location, and so on of the target person. At the same time, the study found that people’s activities have a strong regularity. Thus, obtaining people’s location information not only infringes on the privacy of people at the current moment but also helps predict the future location. This is also the purpose of the attackers. Therefore, for geographical location information obtained from BSN, more and more people think that it is part of personal privacy and should not be obtained and analyzed by others. Based on the above issues, we should provide the external statistical data for analysis in Industrial Internet of Things (IIoT), 9 while ensuring that the privacy of any individual will not be analyzed.
We can simply divide these sensitive information into two parts: 10 disclosure based on location and disclosure based on data. The first threat is generated when the portable device collect our location information. The other is non-location information submitted by us. This article mainly focuses on the first threat. Figure 1 shows the location distribution of users.

Location distribution in IoT reality.
We usually use differential privacy (DP) 11 to achieve the protection of location information, which is a proper method of location-based privacy in the scenery of IIOT as we described. We can make the statistical data queried and analyzed under the privacy environment. It can ensure that for a single individual included in a dataset, the result of statistical query will not change regardless of this existing individual. In short, this means the attacker cannot judge any individual’s data by the statistical result. DP focuses on shortcomings compared to the traditional privacy model (such as encryption algorithm 12 and k-anonymity 13 ). First, DP proposes the definition based on strict mathematics, which means we can provide privacy for the datasets in different layers. Second, DP is assumed that attacker knows the maximum background knowledge including all other records expect the target record. As a result, the DP can neglect the attackers’ background knowledge. Above all, we argue the DP model can provide the most suitable privacy-preserving method for location-based information.
In the description of this article, we can easily observe that DP model can protect any individual. However, DP also has its drawbacks. 14 In case of considering every single individual, the protect mechanism must be very strict, which means that the usability of query data may be affected. We need to not only avoid the disclosure of data privacy but also improve the credibility of data analysts for querying data. Thus, the balance between data availability and privacy protection degree is becoming a serious issue in the DP model.
Before the appearing of big data in IIoT, for common location data privacy, researchers have proposed a variety of algorithms to satisfy privacy guarantees. But after the emergence of big data, the original method has more or less defects in efficiency or usability. As a result, experts face a huge issue of privacy protection. So in this article, we propose our privacy strategy based on the LBS with BSN.
The specific contributions are as follows:
We introduce a planar structure to represent the location data in sensor networks according to the distribution and real-time position of location data;
We present a selection algorithm based on density threshold, which is with lower time complexity in partition algorithm;
We apply an advanced exponential mechanism into selection algorithm in this article in detail;
We conduct extensive experiments in both public databases, demonstrating that the presented algorithm always performs better than the state-of-the-art approaches in IIOT.
The rest of this article is described as follows. Section “Related work” presents the essential previous related work. Section “Preliminaries” introduces the preliminary knowledge. Section “The proposed noise-added selection method” details the proposed location privacy protection method. The real-world IoT datasets and experimental results are presented in section “Evaluation,” and conclusions are given in section “Conclusion.”
Related work
Evolution of the privacy model
With the growing popularity of location-based applications, lots of researchers proposed location models 15 to protect privacy. We simply divide it into two categories. 16 One is traditional anonymization, which encrypts sensitive private location information and data. And the other is the protection model of DP, which neglects the background knowledge of the attacker. 16
Anonymization
Anonymization has always been a traditional and important method in location privacy protection.13,17–19 In the static anonymous policy, the data issuer needs to process the quasi-identification code in the data, so that the multiple records with the same code can be combined. The record sets having the same quasi-identification code combination are called equivalent groups. Wong et al.
17
proposed the k-anonymity method and also a large number of methods based on k-anonymity. The k-anonymity technology means that the number of records in each equivalence group is k. When attacker targeting big data performs a link attack, the attack on any record is also associated with other
The l-diversity anonymity strategy
18
ensures that the sensitive attributes of each equivalence class have at least one different value. The l-diversity allows the attacker to confirm the sensitive information of an individual by a maximum probability of
The t-closeness anonymous strategy 13 measures the distance between sensitive attribute values by expected maximum distance (EMD) and requires that the difference between the distribution characteristics of sensitive attribute values in the equivalent group and the distribution characteristics of sensitive attribute values in the entire dataset be as large as possible. On the basis of l-diversity, the distribution problem of sensitive attributes is considered, and the distribution of sensitive attribute values in all equivalence classes is required to be as close as possible to the global distribution of the attributes.
Based on the static anonymous policy, a dynamic m-invariance anonymous strategy 19 is proposed: while supporting new operations, it supports data redistribution to delete historical datasets.
However, these strategies may cause a large loss of information, which may cause the user of the data to make a false judgment.
DP
DP is a powerful privacy model that can be implemented by adding randomized noise to aggregated query results to protect individual entries without significantly changing the results of the query. DP algorithm guarantees that the personal data that an attacker can obtain is almost the same as what they can get from a dataset that no one has recorded.
Partitioning strategy
A more representative example of data-independent tree partitioning for two-dimensional data is quadtree. 20 We can also extend it to high-dimensional, that is, use octree and other structures to represent data. Their distinguishing feature is that the partitioning method is set in advance and only depends on the attribute domain. Compared to the error of the average distribution of privacy budgets, the query error of this method grows slowly 21 and partially adds noise to the statistical data in the time period by filtering.
Data-dependent tree partitioning relies mainly on input, and the more representative structures are kd-tree 22 and Hilbert R-trees. The main construction process of kd-tree is divided into two steps: one is to select the dimension k with the largest variance in the k-dimensional dataset, and then select the median m as the pivot to divide the dataset in the dimension. Then two sub-collections are obtained. At the same time, create a tree node to store the total count value. The second is to repeat step 1 for the two sub-collections until all sub-collections can no longer be divided. If a sub-collection cannot be subdivided, the data in the sub-collection are saved to the leaf node. We focus on the construction of kd-tree and the process of combining with DP. The algorithm that uses DP based on kd-tree is called kd-standard. The privacy budget of kd-standard is divided into two parts: one is to determine the median, because if the differential process is not used to protect the segmentation process, the segmentation line may leak the true value of the median. Second, privacy budget is used to add Laplace noise to each level of the kd-tree. Kd-standard may also have two aspects of the above quadtree: inconsistent query results and nonuniform distribution of privacy budgets. The solution is the same as quadtree.
R-tree 23 is a spatial partitioning structure consisting of nested rectangles that may overlap. The hybrid tree combines data independence and data-dependent tree-partitioning methods. This method sets the partitioning process in advance. The algorithm complements the advantages and disadvantages of the two tree-partitioning methods, so the query results are more accurate.
UG partitioning 24 is a relatively simple way to divide the space. This method divides the data domain into equal-sized grids, and then adds noise to the count value of each grid, where the size of the grid minimizes noise. The sum of the error and the uniform hypothesis error are obtained. The disadvantage of UG partitioning is that all areas of the dataset are treated equally. Whether the area is dense or sparse, it is divided in the same way. If there is less data point in a region, this method will result in many fine divisions of the region, which increases the noise error and hardly reduces the uniform hypothesis error.
The AG partition 24 first performs uniform grid division. Because there is a second layer partition, the granularity of the first partition is smaller than the UG partition. The AG partitioning then further adaptively selects the partition granularity of the second layer of mesh for the noisy count value of the first layer of mesh.
Preliminaries
We will introduce the definition of DP and partitioning in detail.
DP protection model aims to perturb the data by random noise before it is published. Thus, even if an attacker knows all the other records except the target one, the individual’s private information cannot be inferred through data mining and analysis. Hence, the DP protection model has been studied and perfected by scholars since its being proposed. Now that DP is defined on neighbor datasets, and it is necessary for us to show the definition of neighboring datasets. 25
Definition 1: Neighboring dataset
For two datasets
For neighbor datasets mentioned in the above definition, we add that a data difference in two datasets not only means data have been changed but also data are deleted or data increased.
On this basis, we list the definition of DP. 11
Definition 2: ε-DP
A randomized algorithm B gives ε-DP, for any pair of neighboring datasets

We call
Achieving DP generally adopts two mechanisms: the Laplace mechanism and the exponential mechanism. These mechanisms contain the definition of sensitivity. To make these definition understand easily, we give an introduction of global sensitivity. 26
Definition 3: Global sensitivity
For a function
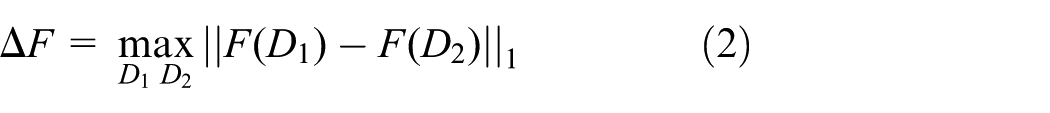
where D refers to the dataset,
Global sensitivity represents the change in the output of the algorithm when changing any record in the dataset.
There are two common mechanisms to complete the DP model, namely, the Laplace mechanism 27 and the exponential mechanism. 28 They mainly add noise to statistical data. There is also a significant difference between them. The Laplace mechanism mainly adds noise to the numeric query result to complete. The exponential mechanism has its own scoring function and finally publish the data according to the level of the score. We give their definitions below respectively.
Definition 4: Laplace mechanism
Given a function

where
Figure 2 shows the distribution of Laplace noise function.
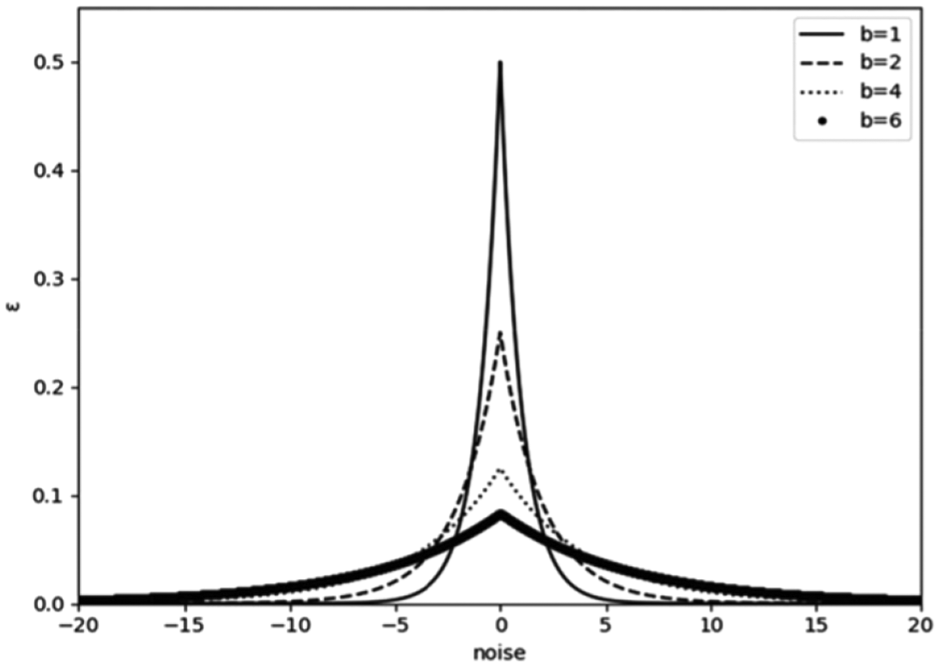
Laplace distribution function with different value b.
In some cases, the result of the dataset query is an entity object, so the exponential mechanism is proposed to complete it. It is mainly used in the case where the output of the algorithm is a non-numeric data. In some application scenarios, we need to choose a better result output among multiple results, and the exponential mechanism determines the pros and cons of each result of the algorithm output by defining an availability function.
Definition 5: Exponential mechanism
Given a random algorithm B whose input is dataset D and output is an entity object
Where the global sensitivity of usability function
User location information is preserved by hiding it and the sanitized data are released by adding Laplace noise to the statistical results of each cell. Definitions 6 and 7 29 show that the proposed data release method that satisfies various DP.
Definition 6: Sequential composition
Suppose we have a set of privacy mechanisms
Definition 7: Parallel composition
Suppose we have a set of privacy mechanisms
When we understand the privacy of the underlying operations, composition theorem of DP can help us understand and calculate the privacy of a complex algorithm.
Through the above theorems and definitions, it is not difficult to come to a conclusion that the lower the degree of protection when
In addition, according to parallel composition, if we make a separate privacy distribution for each region’s query value, it is undeniable that this will definitely achieve a perfect balance between query availability and privacy protection, but in this separate. However, the time spent in the privacy allocation process will be several times the previous average allocation method, which is not acceptable to us.
The proposed noise-added selection method
In this section, we propose our main method in location privacy protection. For a real-time dataset containing the user’s geographic location information in IIOT, we first convert it into a two-dimensional dataset, perform a slider screening on the dataset, and then we perform an exponential mechanism on the filtered collection by giving it a scoring function and selecting k data according to probability. Finally, a Laplace noise addition mechanism is implied on these data and updates it to the original dataset.
We transform Figures 1–3, which means that we convert the geographic map into a mathematical lattice map. Think of the map as a huge white background area where each user’s location information is transformed into a point in the area based on latitude and longitude. In Figure 3, blue points and the square replace the actual distribution of users in Figure 1.

Flattened dataset.
Problem definition and assumption
Notations
Let D denote the domain of all user’s location.
Notations of involved symbols.

Problem description
For a BSN service application, at a certain moment, a geographically implemented location distribution is needed to provide better service to the customer. At this point, the app is too unreliable and dangerous for the user to get the user’s real location. However, it must also complete the service to the user. In this case, the trusted third party needs to protect the location information submitted by the user and process these information. Then, it can release sanitized statistical data to application while ensuring the availability of the sent location to avoid deviations in the BSN service.
First, we need a trusted third party to perform the process of adding noise and selecting process. The framework is as follows: First, users of this application are persuaded to submit their real-time position to the third party. Second, the third party processes the location data they collected and leverages a selection mechanism to select their target regions. We treat each area as a block of data so that these areas constitute a dataset. Next, we filter the data in this dataset and find the appropriate ones to execute noise addition. In the end, we will restore the changed data to the original location map and update it, so we have reached the goal of achieving privacy protection.
We believe that users are willing to do this for two reasons. One is that, the third party is absolutely safe so that nobody will use the data of individual without user’s permission. The other is that, the method we execute is a DP model whose concept is very strong. That means whether the individual give his or her permission to the third party or not, attackers may still have chances to discover his or her private information. But this risk will be nonexistent if people submit their location to the third party. So we propose our algorithm. We should do some extreme hypothesis to make the result clear. First, we assume that the third party is completely safe. Second, we argue that the attackers are smart and vicious, which means they understand how to use differential attacks and have the most background knowledge.
Construction of screening algorithm
For a dataset constructed by a map that implements monitoring, the content has many kinds including the user’s number and position. If it is placed on the coordinate system, the x-axis represents the latitude and the y-axis represents the longtitude, then each user’s location will correspond to a coordinate. For easy understanding, we propose our process in Figure 4.

Total algorithm flow chart.
The process is detailed succinctly as follows. Databases are transformed into coordinate system to make region selection whose final result is a plurality of coordinate system square of the dataset and each square contains many data points. Then, these squares are selected by exponential mechanism. The carefully selected squares are the added noise by Laplace mechanism. Finally, we reload the noise-added small blocks into the original dataset, enabling DP protection. The noise-added selection (NAS) algorithm is shown in algorithm 1.

As presented in step 2 of algorithm 1, the square enables the function of detecting useful data which satisfies the condition. Let the small square traverse the horizontal axis of the coordinate axis first, and then traverse the vertical axis. The detailed process is shown in algorithm 2 and Figure 5.


Process of region selection (the horizontal axis represents the longitude and the vertical axis represents the latitude).
As shown in step 1 of algorithm 2, we set the point in the lower right corner of the square to the traversal point. Dataset
Selection method using exponential mechanism
We propose the selection method based on the exponential mechanism mainly because of the strong privacy it offers. First, the data we have filtered is a huge number that makes plenty of privacy budget. The appearance of exponential mechanism reduces the risk of privacy disclosure. Second, it selects the location data that include more sensitive information, so it can monitor the disclosure situation by adjusting different privacy budget. Third, it can control the number of data selected each time according to the algorithm. Combining these advantages, we propose algorithm 3.

First, step 2 of algorithm 3 calculates the number of records in dataset. Then, we use the score function to calculate the points of each record in step 3. The formula is

where


where
The probability is obtained in step 5 and sorted in descending order in step 6. Finally, we finish our selection with p data and construct the
Added Laplace noise
As previously mentioned, the noise count is added to disturb the statistics of the query. In this part, we will add Laplace noise to the query result. Algorithm 4 shows the details of this release.

Here,
Choice of parameter
In this article, we denote threshold q and s whose functions are detailed before. Now, we will discuss the process of obtaining these parameters and reasons to set.
As detailed in algorithm 2, to detect the distributed spots, NAS needs two parameter values, q and s. These values specify the minimum accessed density and the area of the square that used to detect, respectively. Therefore, we need to determine these values privately due to the dangerous reason that these values can leak the information about the underlying dataset.
To solve the above issue, we set these parameters based on the average density of the whole region. We suppose the number of position points are L and the area of the region is S. So the average density can be obtained by the calculation formula
After that, we now choose the value of s. Intuitively, two parameters q and s together determine the selection of data point spots. Accordingly, if the selection square is relatively small, the time complexity may be larger. However, if we give a bigger square, we may inadvertently lose a lot of accuracy and miss some satisfying spots. Therefore, we propose the limit condition as follows: first,
Evaluation
Experimental settings
Dataset
We leverage the check-in dataset from the Gowalla (Gowalla total-check-in dataset), which has a huge amount of data and records about the information of the users. The experimental dataset is presented in Table 2.
Information on datasets.

Environment and parameter
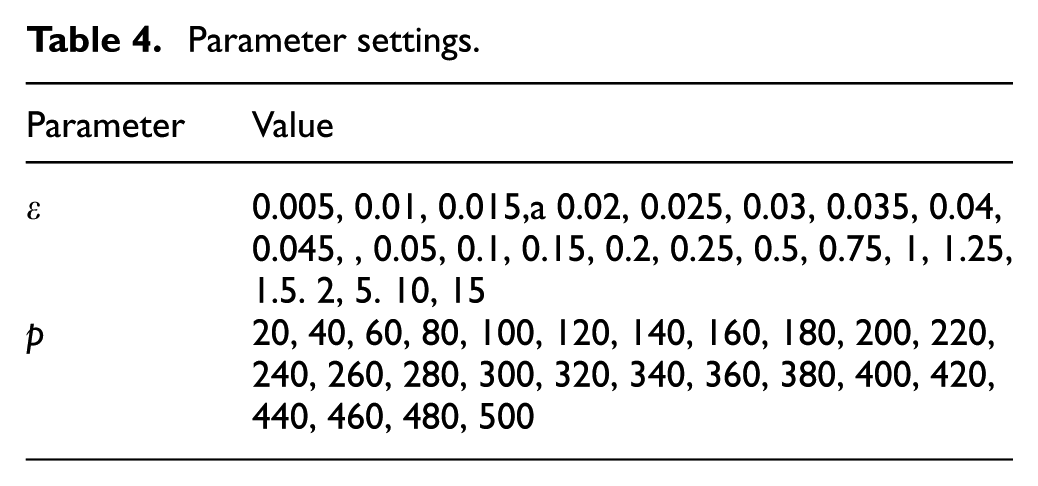
The configuration information and parameter settings are shown in Tables 3 and 4, respectively.
Configuration information.

Parameter settings.
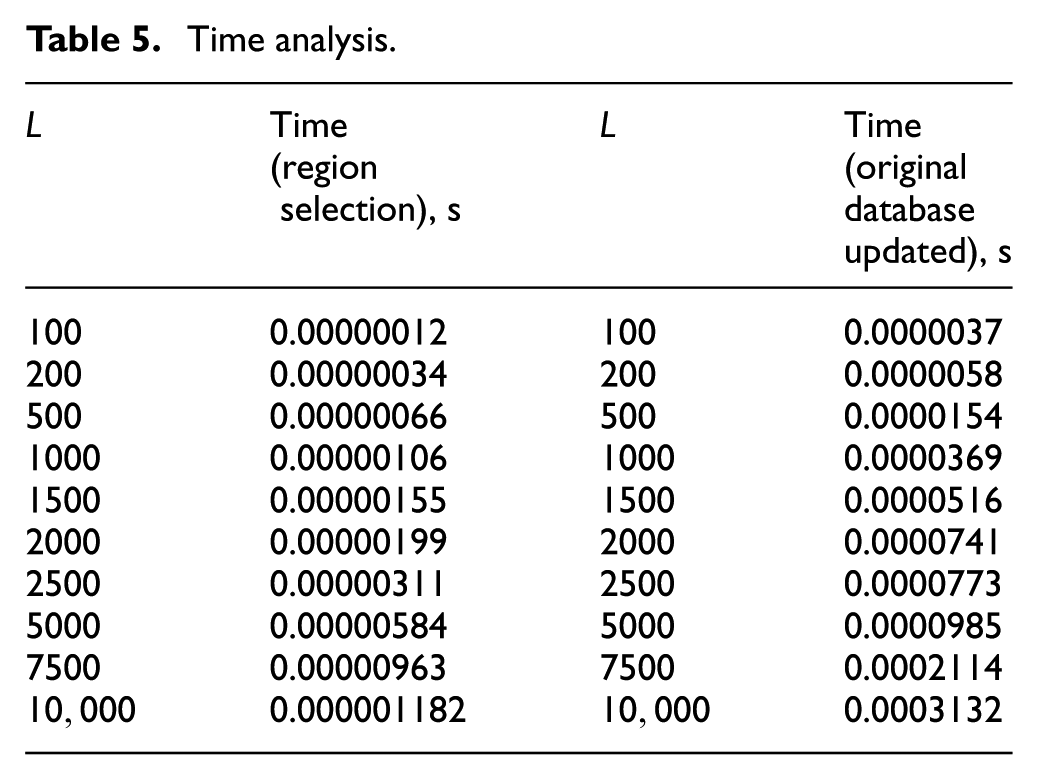
Time analysis
We mainly analyze and calculate timeliness in two aspects:
Timeliness of constructing region selection area;
Timeliness of exponential selection method and updating original dataset after the addition of Laplace noise.
Table 5 shows the results of testing. We assume the parameters p, L, and
Time analysis.
Experiment and availability analysis
This article chooses 500, 1000, and 2000 data points from Gowalla. The black dots represent the insensitive locations and the red ones indicate the sensitive locations. The experimental results are shown in Figures 5–8.

500 data points before NAS.

500 data points after NAS.

1000 data points before NAS.
In the condition of 500 data points, there are 151 red sensitive points and 349 black insensitive points in Figure 5. There are 195 red sensitive positions and 305 black insensitive locations in Figure 6 after protection. According to the 1000-point situation, there are 219 red sensitive points and 781 black insensitive points in Figure 7. After NAS protection, there are 244 red sensitive positions and 756 black insensitive locations in Figure 8. The same situation appears in 2000 data points. There are 299 red sensitive points and 1701 black insensitive points in Figure 9, while there are 322 red sensitive positions and 1678 black insensitive locations in Figure 10 after protection, which shows that the sensitive locations have increased. Table 6 presents the statistical results of the data utility.

1000 data points after NAS.
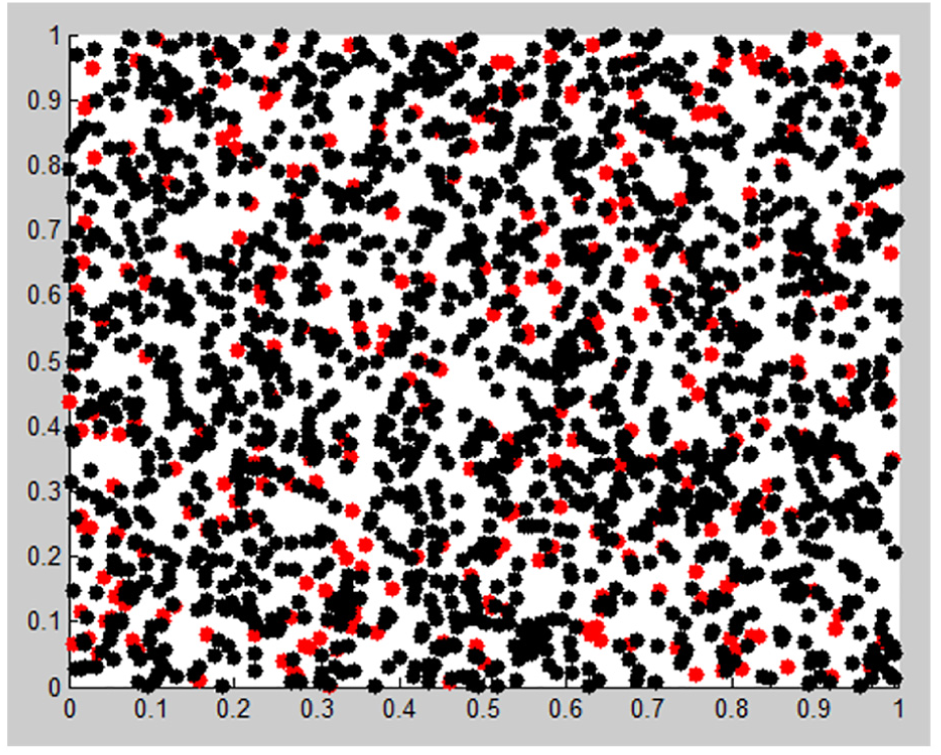
2000 data points before NAS.
Test results.

We compare the proposed method with three methods UG, AG, and KDT. We construct a table of these main methods in Table 7.
Information of method.

The formula of the evaluated standard RER (relative error rate) is given as
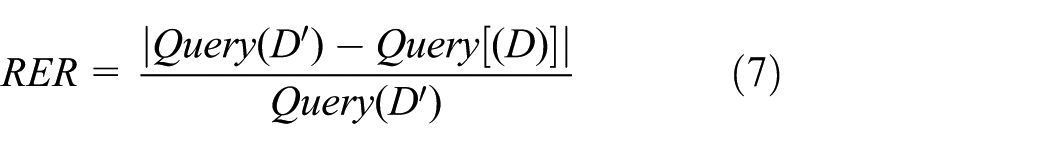
where
With the increase in privacy budget
The results of UG, AG, and KDT methods show that when privacy budget becomes larger, they will make a better effectiveness. However, if
Parameters we need to consider are, respectively n,

2000 data points after NAS.
We present the variable control method to explore the relationship between a variable and the resulting value while determining the value of other variables. Next, we will do the experiment according to the method described above and organize the experimental data into several tables to summarize the rules:
As represented in Table 8 and Figure 12, we can observe that with the increasing privacy budget parameter
As shown in Tables 9 and 10, we argue that the number of data points and selection region affect RER significantly. When we increase the data points, the Laplace part
Relation between


Relative error rate comparison of previous and proposed methods.
Relation between p and RER.

Relation between L and RER.

Overall, the proposed method NAS has obvious advantages both in the level of location privacy protection and the effectiveness and availabily of the algorithm.
Conclusion
In this article, we proposed a location data releasing method based on DP, called NAS. This method enables the LBS application to continuously provide convenience for users while protecting their privacy data by strong privacy guarantee. Besides, the proposed method increases the availability of the released data. Specifically, the NAS first partitions the location dataset into pieces of location data using a region selection algorithm. Then, it uses the score function to evaluate the selection result with exponential mechanism and obtains a new selection set. Next, we use Laplace noise releasing method to change the selected statistical data count. Finally, we update the original dataset with changed data to supply the query. We evaluated the proposed method through extensive experiments, and the results prove that our method achieves a better availability with the same privacy guarantee.
Footnotes
Handling Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Nature Science Foundation of China (nos 61370198, 61370199, 61672379, and 61300187).