
Abstract
In this article, we propose a novel scheme for diagnosing intermittent faults for cloud systems. We have investigated the characteristic of high-level symptomatic behavior on top of a cloud system and identified that (1) arrival counts of high-level symptoms go up with the number of fault injections at different speeds, which may help us to differentiate one fault model from another; (2) the nested level of fatal traps is found to be an indicative of fault duration, which is helpful for fault model diagnosis; (3) fatal traps triggered by certain faulty units is explored, providing useful information for locating faults. Based on these features, an n-dimensional space taking symptom’s arrival rate (grown up skew of the arrival count) as each dimension, which formulates the diagnosis problem as a pattern recognition problem is defined. Then, a backpropagation neural-network-based online hardware fault diagnosis scheme is proposed. Experimental results show that diagnosis accuracy of fault location is 99.2%, the accuracy of fault model is 96.7%, and the latency is affordable. This scheme has been implemented in firmware so that it covers cloud software stacks (virtual machine monitor, virtual machines, and user applications) and incurs zero hardware overhead.
Introduction
The new and emerging generation of cyber-physical systems 1 such as those supported by the Internet of things (IoT) 2 posed a new set of requirements to computing systems. In these systems, the increasing use of wireless sensors that generate massive data and the need to process these data efficiently have given an enormous importance to the cloud computing paradigm. A good example of cyber-physical applications are those running in the context of vehicular ad hoc networks (VANETs). 3 In these systems, drivers are offered a set of services which might involve congestion information, parking place management, entertainment, vehicle tracking, and so on. Applications of this type need not only to run efficiently (therefore expecting fast processing and storage) but also to be reliable. These cyber-physical systems require real-time processing, efficient storage, and accessibility and other non-functional requirements such as reliability. Reliability refers to the probability of a system, including all of its hardware and software components, to perform correctly as expected.
At the same time, new trends in semiconductor technology scaling toward a nanometer regime have impelled a resurgence of interest in detecting and diagnosing intermittent faults. The driving forces 4 include shrinking geometries, smaller interconnect dimensions, lower power voltages, decreased noise margins, and so on. It has been forecasted that multicore and manycore systems, mostly often integrated in cloud systems build schemes, are more vulnerable to intermittent faults in future technologies. 5
Unlike transient faults due to single-event upset (SEU), intermittent faults occur in bursts with durations that vary across a wide range of timescales, from orders of cycles, to milliseconds, to even seconds or more. As compared with permanent faults, intermittent faults do not persist and are hard to diagnose through periodic tests because they arise in particular situations (temperature, supply voltage, voltage droops, and so on) and cannot be reproduced. 6
Error-correcting codes (ECC) or parity is generally used to protect sequential logic from intermittent fault, but they are not suitable for diagnosis or fault detection of combinational logic. Prior works such as triple modular redundancy (TMR) or hot spare systems have been shown to be effective, but are considered unaffordable in many scenarios. Online testing and SBST (software-based self-test) are promising not only for sequential logic from erratic bits 7 but also for combinational logic.8–10 However, the burst and non-recurrence features make SBST no longer effective for intermittent faults. 11
Li et al. 12 developed a set of high-level fault detection mechanisms. High-level detection techniques generally ignore faults which are masked at any of these levels, avoiding the corresponding overheads. Compared to the low-level mechanisms, it achieves low cost, low misdiagnosis rate, but longer delays. However, the effectiveness for covering intermittent faults has not been verified. And, the diagnosis version (m-SWAT) 13 incurs high overhead, and it is only suitable for permanent faults.
In this article, we propose a fault diagnosis strategy for combinational logic in processors against intermittent faults. The diagnosis strategy fundamentally depends on the answers to several key questions, which we investigate in this work:
Are detection mechanisms effective for combinational logic under intermittent faults? First, the mechanisms should cover all three fault models (transient, intermittent, and permanent). In addition, the detection delay must be reasonable to provide timing margin for diagnosis and recovery mechanisms.
Different fault models last for different time lengths, which may result in various symptoms of cloud systems. What is the relationship between fault models and symptoms we can detect? This may provide useful information for fault diagnosis.
Is there an inherent connection between symptoms and fault components? If so, understanding the connection may be helpful to determine the fault location.
To answer these questions, we have investigated high-level symptomatic behaviors by exploiting traces in fault injection campaigns, based on a cloud system simulating environment. Then, we observed three features of symptom behavior which are vital for the fault diagnosis process. Finally, an online hardware fault diagnosis system based on neural network has been devised, and it is proposed in this article. Our contributions are as follows.
Three features of symptomatic behavior have been observed from further analysis. (1) Arrival counts of fatal traps and high activities go up with the number of fault injections at different speeds, which allows defining an n-dimensional space using the arrival rate of each symptom as coordinates in which the training samples will gather into clusters. As a result, the diagnosis strategy can be treated as a pattern classification problem so that a neural network is employed. (2) Nested level of fatal traps is directly related to fault duration, which helps to distinguish fault models. (3) Dedicated fatal traps contribute to structure-level fault location.
A Backpropagation (BP)-based OnlIne hardware fault Diagnosis System has been built, named BOIDS, which is used to diagnose combinational logics in microprocessors against hardware faults (transient, intermittent, and permanent faults) in cloud computing environments. The diagnosis scheme is implemented in the firmware layer so that it can be easier to modify, thus saving cost to trade-off performance with reliability without requiring any change to the underlying hardware. It also allows the neural network algorithm to diagnose online, while the exhausting training process can be dealt offline, therefore saving significant upgrading overhead. Experimental results show that diagnosis accuracy of fault location is 99.2% and accuracy of fault model diagnosis is 96.7%, with latency favorable for hardware recovery mechanisms.
To our knowledge, this article makes the first attempt toward diagnosing hardware faults in cloud systems using neural networks. This scheme shows acceptable diagnosis accuracy and low hardware overhead which benefits from features of symptomatic behavior observed in the statistical analysis of the injection experiment. This scheme diagnoses not only fault models (transient, intermittent, and permanent) but also the fault locations in combinational logics, such as address generation unit (AGEN), decoder, arithmetic logic unit (ALU), and float point unit (FPU).
This article is organized as follows: section “Related work” describes related work; section “Features of symptomatic behavior” presents features of high-level symptomatic behaviors; section “Design of BOIDS” presents the design of BOIDS; section “Experimental results” shows the evaluation of the diagnosis scheme; and section “Conclusion” concludes the article.
Related work
In this section, we present prior research in hardware fault diagnosis. In recent years, much work has been done on studying the impact of intermittent faults on computer systems.14,15 L Rashid et al. 16 made a preliminary study of intermittent fault propagation in programs, and J Wei et al. 17 further his study. Gracia-Moran and colleagues18,19 evaluated redundancy-based fault tolerance capabilities for intermittent faults. Pan et al. 20 introduced intermittent faults vulnerability factor (IVF) to quantitatively investigate vulnerability of processor structures against intermittent faults.
Traditional fault resilient techniques are usually based on adding redundancy or using voters, such as in the IBM mainframes. 21 The IBM G5 microprocessor, for example, has redundant units for fetch/decode and for instruction execution. Some other fault-tolerant computers, such as the Stratus 22 and the Tandem S2, 23 simply replicate entire processors. An even more extreme case of using redundancy to tolerate fabrication defects is the Teramac. 24 The Teramac is designed to make use of components that are likely to be faulty and has been motivated by expected defect rates in nanotechnology. While all these systems provide excellent resilience to hardware faults, such heavyweight redundancy incurs significant costs in terms of hardware and power consumption.
Several techniques provide firmware access to the processor’s internal state in order to detect hardware faults by periodical tests. 25 However, such methods may not be effective due to the non-periodical characteristic of intermittent faults.
Symptom-based fault detection has been proposed by ML Li et al. 12 This is an effective detection technique for permanent and transient faults in an operating system scenario. Compared to our method, the effectiveness of this method remains untested neither for intermittent faults nor for the cloud computing environment. We believe that after validation of its effectiveness, the method can be introduced into our scheme as a pre-step for fault diagnosis process, and the log trace can also be used by our fault diagnosis scheme.
Several methods to continue use of a core despite permanent faults have been published. These techniques involve fine-grained diagnosis and reconfiguration of a core’s components,26,27 or attempt to match program requirements and with core capabilities, such as Core Salvage. 28 PM Wells et al. 29 believed that the ability to suspend execution on a core, in order to perform diagnosis and reconfiguration, would likely be a simplifying addition to these techniques.
S Hari et al. designed a trace-based fault diagnosis (TBFD) mechanism to diagnose permanent faults. Although the diagnosis accuracy reaches 95%, heavyweight overheads such as hardware buffers and re-executions are required. 30 Furthermore, TBFD does not show its effectiveness for intermittent faults, taking into account of the burst and non-periodical characteristics of intermittent faults.
Features of symptomatic behavior
Neural networks are widely known for their performance in the pattern recognition area due to their ability to partition a non linear sample space. We have investigated high-level symptomatic behaviors and extracted three features to employ as a fault diagnosis scheme.
Introduction of high-level symptoms
A fatal trap is a special kind of trap thrown by the trap logic unit (TLU) indicating a system in emergency. A fatal trap requires no additional hardware overhead. On Solaris, the following traps are denoted as fatal traps: Recover Error and Debug (RED) state trap (thrown when there are too many nested traps), Data Access Exception trap, Division by zero trap, Illegal instruction trap, Memory misaligned trap, and Watchdog reset trap (thrown when no instruction retires in the last 216 ticks).
High activity refers to the amount of time the execution remains in the operating system without returning to the application. This mechanism has been developed by Li et al. 12 and incurs low hardware overhead, since it primarily uses a hardware instruction counter. The threshold has been set to be 7000 instructions for hypervisor and 30,000 for operating system, which are 1.5 times the normal situation. Note that the number of contiguous instructions does not include system calls or operating system idle state.
Hang is an endless loop or waiting for an event that will never happen. Note that hang is not employed in our diagnosis system since few hangs (0.1%) take place in the detection process. The uncovered proportion is taken by silent data corruption (SDC) that represents faults that manage to survive all the detection barriers and finally result in incorrect results. We can see that longer fault durations induce greater destructive power in the high-level (e.g. in the operating system) and cause more faults to manifest such that they are detected as high-level symptoms.
Statistical methods of high-level symptoms
In what follows, we show that the arrival counts of high-level symptoms, including all the fatal traps and high activities, go up with the number of fault injections, approximately linearly with various slopes. If we setup an n-dimensional space taking the symptom’s arrival rate (grown up skew of the arrival count) as each dimension, the vectors—representing symptoms induced by different fault models and locations—may gather into clusters in the sample space, and the symptom-based diagnosis problem can be treated as a pattern classification problem.
In order to relate symptoms to training patterns, we define the notion of arrival count to represent the number of times that one symptom takes place in the fault injection history. Figure 1 shows the arrival counts of high-level symptoms. First, we made statistics on the fatal traps in fault injections. As we have two diagnosis targets here, the fault model and fault location, we lock one target and observe the change of data under another one in order to “show” the differences of the raw data. In Figure 1, the arrival counts of fatal traps are shown in a two-dimensional (2D) space and each of them are accumulated from 300 faulty traces.

Arrival counts of symptoms: (a) benchmark: basicmath, structure: decoder, transient/intermittent/permanent; (b) location diagnosis, under intermittent faults and across benchmarks.
The arrival counts of illegal_instruction (fatal trap type: 0x10) and mem_address_not_aligned (fatal trap type: 0x34) from basicmath under a faulty decoder are shown in Figure 1(a). There are three sets of data in a combination of 0x10 and 0x30 and six curves in total, which shows statistics under transient, intermittent, and permanent failures, respectively. We can see that the arrival counts go up with the number of fault injections, and the slopes of the curves are different (strictly speaking, these are not straight lines statistically). It shows us that the growing pace of fatal traps can differentiate one fault model from another, even by the same fatal trap. The T:10, representing the arrival count of fatal trap 0x10 from a transient fault, goes up slower than the I:10, and the arrival count of 0x10 from an intermittent fault (I:10) is slower than that of P:10 (0x10 from a permanent fault). We can also find the difference in fatal trap 0x34 for the three fault models. As a consequence, we can differentiate fault models using grown-up trends of arrival counts of fatal traps occurring in cloud systems in case of faults.
Figure 1(b) also shows arrival counts of fatal traps in each 300 faulty traces, which come from under intermittent faults and all three faulty structures, respectively. However, curves in this figure are the statistics (in average) of trace data generated by all the benchmarks. It can be seen that the curves in Figure 1(b) have higher linearity than those in Figure 1(a), indicating that the characteristics of arrival counts grown trend are more consistent in various user programs. Note that the arrival counts are distinguishable across fault locations, including AGEN, decoder, ALU, and FPU. The fatal trap 0x34 under a faulty decoder (Decoder:34) arrives faster than that of ALU:34, while the arrival count of fatal trap 0x10 from decoder and AGEN are relatively close. However, we can enhance the discrimination by exploiting other fatal traps, such as Decoder:34 and AGEN:10. For decoder, fatal trap 0x34 occurs more than 60 times in each 300 fault injection group, while for AGEN, there are almost none (hence not shown in Figure 1(b)); a similar situation occurred for fatal trap 0x10 for AGEN and decoder. Usually, there are tens of fatal traps in cloud systems and so we can further distinguish the fault locations by making use of more symptoms. As a result, this feature draws a more general feature of fatal traps in order to help fault location diagnosis, particularly in complex computing environments like cloud systems.
Then, if we define an n-dimensional space using the arrival rate (the grown-up skew of the arrival count) of each fatal trap as coordinates, the training samples gather into clusters. Figure 2 shows a 2D space using the arrival rates of 0x10 and 0x34 as coordinates. We can see that the fatal trap sequence, triggered in each type of failure, gathers in clusters in the sample space, and the sample space of symptomatic behavior in the cloud system can be divided if we use the arrival rate of each fatal trap as training pattern. Over all, the proposed statistical method shows the feasibility in setting up a classifier for the sample space of the high-level symptom’s arrival rates, which is the foundation for our diagnosis method.

The samples of symptoms (0x10 and 0x34) in 2D space: “0” for transient, “x” for intermittent, and “.” for permanent faults.
Nested fatal traps
Intermittent faults are caused by a variety of factors and typically last for a range of durations. In this section, we present a quantitative analysis to understand the relationship between fault models and fault durations.
From fault traces, we found another symptomatic behavior—nested fatal traps. In normal execution flows, fatal traps will not take place, not to mention nested fatal traps. However, when a fault is provoked, especially with longer durations, fatal traps may be triggered before the prior fatal trap returns. We call such cases nested fatal traps. Fault traces show that nested fatal traps take a proportion of 53% in all fatal trap symptoms.
Table 1 shows nested levels of fatal traps versus burst length (BL) for the MiBench benchmark. 31 There are seven nested levels because the maximum nested level is set to 6 in the UltraSparc system. Level “0” indicates that no fatal traps have occurred, so the figures represent the proportions of high activity. The BL column represents fault durations in fault models, in which “1” corresponds to transient faults, “∞” corresponds to permanent faults, and “2” ∼ “16” correspond to intermittent faults. We can see that the increase in the nested level is directly related to BL. All fatal traps are non-nested in case of a transient fault, while the max nested levels rise from 2 to 6 when intermittent faults occur. Even for the ALU, in which fatal trap detectors show the worst performance, the nested level goes up to 3 when permanent faults occur.
Nested levels versus burst length (MiBench).
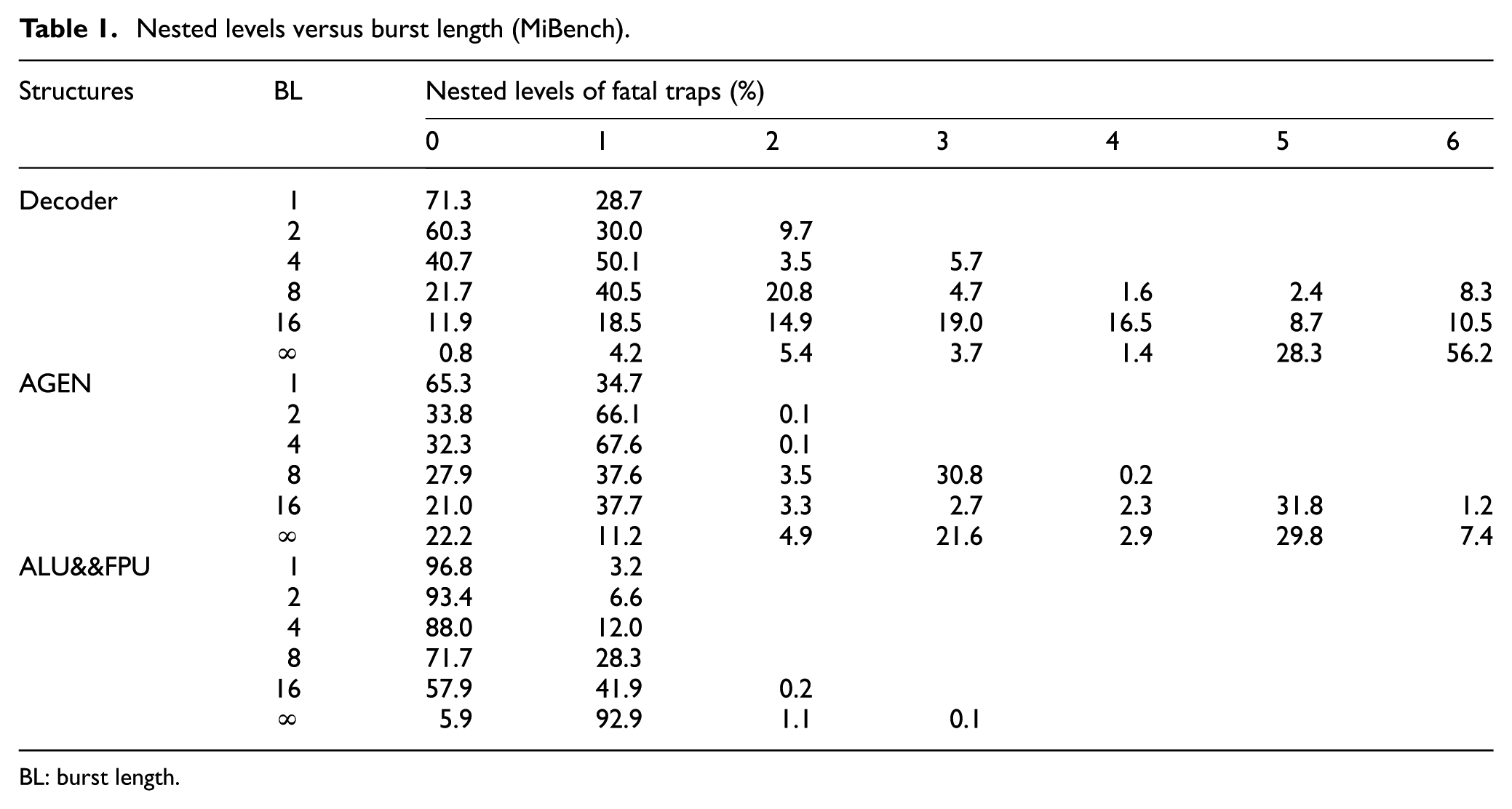
BL: burst length.
Furthermore, with the increment of fault duration, the proportion of low nested level symptoms (lower than 3) decreases sharply, whereas a reverse trend is observed for higher levels, from 3 to 6. Take decoder as an example: 40.53% of symptoms are non-nested fatal traps when the BL is 8, and the figure decreases to 18.47% when the BL goes to 16. For permanent faults, the proportion goes deep down to 4.20%. But in level 5, the proportion goes up from 2.27% to 28.27% corresponding to an increment of BL.
The above discussion shows how the maximum level and proportion in each level help to distinguish fault models. Furthermore, the speedup ratios of proportion decrement for each structure also show their contribution for fault location. The proportions of symptoms, including high activity, decrease when fault duration increases. Figures from nested level “0” show that the proportion of high activity for decoder goes down linearly. However, the curves of speedup ratio for AGEN, ALU, and FPU change in different ways.
Dedicated fatal trap
The third characteristic of symptomatic behavior is that there are some dedicated fatal traps. We define dedicated fatal traps as those fatal traps that are triggered only by a certain faulty structure (never by others), and this behavior remains inconsistent with all fault models. Obviously, this observation is helpful for fault location.
Dedicated fatal traps are shown in Table 2. In column 3, all the fatal traps dedicated to a corresponding structure are listed (five for decoder, two for AGEN, and none for ALU). For the ALU, each dedicated trap has been triggered a number of times. To show the frequency, the triggering for all fatal traps is listed in the “fatal trap” column. Although some of the frequencies are low, under the assumption that only one fault is provoked at a time, the faulty structure can be located immediately when a dedicated fatal trap occurs.
Dedicated fatal traps for SpecInt2000 (in bold) and MiBench.

Note: Bold values are statistics from testbench SpecInt2000, and unbold values in “Dedicated fatal traps” are statistics from testbench MiBench.
Note that some traps have not taken place in all fault models, but they still meet the definition of dedicated fatal trap. This is the reason why fatal traps that are triggered for zero times are still listed here. The emergence of dedicated fatal traps reveals some internal relationships between the error protection strategy and symptoms (fault manifestations). By making use of dedicated fatal trap, we will solve the diagnosis problem.
Design of BOIDS
Based on the observations of symptomatic behavior, a BP-based online intermittent fault diagnosis system, named BOIDS, for cloud computing systems has been implemented. In this section, we describe the design and implementation of the BOIDS system.
BOIDS comprises four main sub-systems: Symptom Collection Unit (SCU), BP neural network (BPNN from now on), the Arbitrator, and the Fault Recovery Unit (FRU), as depicted in Figure 3. The SCU is responsible for collecting symptoms reported by high-level symptom detectors in case of hardware faults. The SCU maintains the number of times for each symptom and then constitutes the input vector for the BPNN. In case of a fatal trap, the SCU also needs to obtain the nested level from the Trap Level Register (a status register in processor) and look up the dedicated fatal trap table to identify whether it is a dedicated fatal trap or not. The BPNN acquires symptoms from the SCU, makes the recognition, and delivers results to the Arbitrator. In each diagnostic cycle, the BPNN takes an 8-dimensional vector X as input. Each xi, i = 0 to 7, is one of the seven arrival rates (six fatal traps and high activity) or nested level of symptoms. Since there are three fault models and three candidate structures, nine fault classifications are employed. The BPNN outputs an 8-dimensional vector corresponding to nine fault classifications. In the output vector, a negative value is interpreted as a classification hit. A non-negative value is interpreted as a classification miss. The Arbitrator takes the recognition results of the BPNN as inputs and identifies the pattern of results first. If there are no positives (undiagnosed faults) or more than one positive (non-uniquely identified fault) in the pattern, the result is incorrect. In these cases, the dedicated fatal trap is used to correct the results. Otherwise, incorrect results could still exist, even if the signal pattern is correct. These cases are named uniquely diagnosed faulty results and cannot be identified simply by result patterns. In such situations, continuous symptoms will take place and be detected, and then the Arbitrator suggests adjusting the weights of the BPNN and indicates a new diagnosis cycle.

The design of BOIDS.
The cross-layer resilient framework provides a large design space by exploiting a series of state-of-the-art techniques across different system stack layers for fault validation and recovery. Mechanisms such as checkpointing,32,33 migration, 34 and reconfiguration 35 would be effective and provide enhancement in intermittent fault validation. Further analysis of these issues is out of the scope of this article, so the evaluation of BOIDS is based on the assumption that the cross-layered validation is ideal.
Experimental results
In this section, we show the diagnosis performance of BOIDS against hardware faults for cloud computing systems. We evaluate BOIDS by doing fault injection experiments on a cloud computing simulation environment, in which hardware faults in the processor can be emulated and the reaction of the diagnoser can be monitored.
Experiment methodology
The primary objective of this study is to investigate the features of high-level symptoms, if any, in order to solve the diagnosis problem. This requires simulators which can faithfully simulate system-level software stacks. While alternative field-programmable gate array (FPGA)-based emulations36–38 offer higher speed and model lower-level faults with high fidelity, their limited observability and controllability gives less flexibility than software simulations. 12 While simulated fault injections39,40 can accurately capture lower-level faults, the long simulation time of these schemes prevents detailed evaluation of the propagation of faults through the hardware and into the software. We developed a fault injection platform incorporating a full system simulator, SAM, 41 which simulates Ultrasparc T2. On top of SAM lays the cloud system software stack including hypervisor, GuestOS, and user applications. This simulation setup allows us to inject hardware faults into the ALU, AGEN, and decoder and to observe their impact on real workloads (8 SpecInt2000 and 10 MiBench) running on the cloud system.
We have adopted the most commonly used models, such as stuck-at (0, 1) for permanent faults and bit flip for transient faults. Intermittent faults are similar to transient faults, except for their burst characteristics. Once an intermittent fault is activated, every instruction passing the target structure is corrupted until burst ceases. We adopted bit flip fault models with BL s as 2/4/8/16 continuous instructions for intermittent faults.16,42 Fault injection locations of each target structure are listed in Table 3. In all cases, we have injected single bit faults.
Target units and corresponding fault locations.

Decoder: decoder unit, which is responsible for decoding instructions and generating control signals. ALU_FPU: Integer arithmetic logic and floating point unit. Note that both of integer and floating point instructions’ format are parsed in FBT and thus the evaluation covers the operations in ALU and FPU. AGEN: Address generation unit, a key unit for instruction sequence used to generate the memory address of the next executed instruction.
Representative benchmarks from SpecInt2000 and MiBench have been selected. For each configuration, 300 fault injections have been conducted. Overall, a total of 64,800 runs (300 injections × 3 structures × 18 benchmarks × 4Lburst) for intermittent, 32,400 runs for permanent, and 16,200 runs for transient faults have been conducted. The processor simulator was set in 1c1t (1 core 1 thread) configuration. Since multicore diagnosis is more complex, corresponding configurations are left for our future work.
Diagnosis accuracy
We conducted over 1,000,000 diagnosis experiments and assume that there is only one faulty structure under a specific fault model in each of them. Since this article focuses on intermittent fault diagnosis mechanisms on behalf of fatal trap symptoms, the following evaluation is under the assumption that the performance of the underlying fault validation technology is ideal.
Experimental results show excellent diagnosis accuracy of our diagnosis system. Table 4 shows the accuracies of the first diagnosis cycle since there may be more diagnostic cycles in case of misdiagnosis. In fact, the diagnosis accuracy will definitely go up when the number of diagnosis cycle increases. The statistics of five benchmarks from MiBench are listed, while others are not shown due to the scope limitation.
Diagnosis accuracy for first time diagnosis (MiBench).

From Table 4, we can see that most of diagnosis accuracies are excellent, for both fault model diagnosis (“model” column) and structure-level fault location (“struc” column). The average accuracy of fault location is 99.2% and the accuracy of model diagnosis is 96.7%.
However, the accuracy of transient faults (97.9% for locating and 84.2% for fault model) declines sharply in comparison with that of intermittent fault (99.3% and 98.1%) and permanent faults (99.6% and 97.9%). The similarity of intermittent faults with BL 2 and transient faults may be a rough reason. However, transient faults will disappear during a second-time diagnosis in case of first time misdiagnosis. Accordingly, the disappearance of symptoms will help to increase accuracy.
Diagnosis latency
Diagnosis latency is a crucial parameter since it determines the recovery strategy. According to the architecture of our diagnosis system, a diagnosis result is generated within 1 K instructions after fault detection. Accordingly, a hardware recovery mechanism is feasible.
Conclusion
In this article, we proposed an intermittent fault diagnosis system that employs neural network methods—BP in particular—as a diagnosis scheme. By investigating the characteristics of high-level symptoms, we have found that the statistical method shows the possibility of setting up a classifier for the sample space of high-level symptom’s arrival rates. This formulates the hardware fault diagnosis problem as a pattern recognition problem.
In addition, we observe that (1) the nested level of fatal traps can be used as an indicator for fault duration, which is helpful for fault model diagnosis, and (2) fatal traps triggered by certain faulty structures, named dedicated fatal trap, are useful for fault location. These two observations provide methods to improve the fault diagnosis scheme.
Experimental results show that diagnosis accuracy of fault location is 99.2% and accuracy of fault model diagnosis is 96.7%, while fault detection coverage reaches over 97.2% for SpecInt2000 and 95.1% for the MiBench benchmark. The latency of BOIDS provides opportunities for lightweight recovery techniques.
To the best of our knowledge, we have made a first attempt on intermittent fault diagnosis scheme of cloud systems using the arrival rate of high-level symptomatic behavior to setup the sample space. In a future work, we propose to expand the scheme to more complex scenarios, such as multithread computing environments and virtual machine migration processes. Finally, we would also like to couple this diagnosis framework with recovery techniques both online and offline.
Footnotes
Handling Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by the Natural Science Foundation of Beijing (4174091), Research Funds for Education Committee of Beijing (KM201711232013), and Key Research Project of Beijing Natural Science Foundation (Z16002).