
Abstract
With the explosive growth of surveillance data, exact match queries become much more difficult for its high dimension and high volume. Owing to its good balance between the retrieval performance and the computational cost, hash learning technique is widely used in solving approximate nearest neighbor search problems. Dimensionality reduction plays a critical role in hash learning, as its target is to preserve the most original information into low-dimensional vectors. However, the existing dimensionality reduction methods neglect to unify diverse resources in original space when learning a downsized subspace. In this article, we propose a numeric and semantic consistency semi-supervised hash learning method, which unifies the numeric features and supervised semantic features into a low-dimensional subspace before hash encoding, and improves a multiple table hash method with complementary numeric local distribution structure. A consistency-based learning method, which confers the meaning of semantic to numeric features in dimensionality reduction, is presented. The experiments are conducted on two public datasets, that is, a web image NUS-WIDE and text dataset DBLP. Experimental results demonstrate that the semi-supervised hash learning method, with the consistency-based information subspace, is more effective in preserving useful information for hash encoding than state-of-the-art methods and achieves high-quality retrieval performance in multi-table context.
Keywords
Introduction
Except for post hoc analysis, in Internet of Things (IoT), video surveillance is supposed to respond to unhandled exceptions. The level of human surveillance cannot adapt to such a massive volume of data. Processing IoT, video image is an application of the multiple attributes recognition research field. In 2016, the market of Video Surveillance has grown to 96.2 billion with merging into IoTs more deeply. Monitoring equipments are the essential eyes for IoT perception. Huge number of monitors form Articulated Naturality Web and generate hundreds of millions of video data, which is redundant and costly to save. With the explosive growth of data, exact matches become much more difficult for its high-dimensional and wide storage spaces. Except for post hoc analysis, video surveillance is supposed to respond to unhandled exceptions, for example, fire warning, crowd situation awareness pre-warning, and intelligent traffic management. Traditional video surveillance system cannot satisfy real-time monitoring and warning has to be given manually. Moreover, the level of human surveillance cannot adapt to such a massive volume of data.
Therefore, approximate nearest neighbor (ANN) search has attracted much attention over the past decades. Owing to its good performance in solving the balance between retrieval performance and computational cost, hash learning techniques are widely used in solving the ANN problems. The core of hash learning is to map the original high-dimensional data into binary hamming space. Its application includes, but not limited to, image retrieval, document search, and data mining. Different from standard metric learning, hash learning is a discrete optimization problem, which is NP hard. 1 The first efficient ANN search in high-dimensional space is introduced by Indyk and Motwani. 2
The target of hash encoding is to analyze and extract information from massive unstructured data to detect the goal automatically. For instance, in real IoT scenarios, a video file consists of image frames, which are snapshots of real-world scenarios and every image contains abundant information. Therefore, to encode these frame images, hash method should take multiple semantic properties into account. In real networks, it is intuitive that one vertex may demonstrate various latent aspects when interacting with different vertexes. In other words, similarity between entities usually is non-transitive since they could be similar due to different invisible reasons.
As shown in Figure 1, straight line denotes that two frames have similar elements and dotted line means dissimilarity relationship. Picture Pa contains two elements, car and human; clearly the alike elements between Pa and Pb is car, while between Pa and Pc is human. Even though Pa and Pc have the common neighbor Pa, they are dissimilar with each other. Nevertheless, in previous hash metric researches, the latent multiple semantic properties are neglected and projected into a single hamming space. As a result of projecting entity-level similarity into a single binary hamming space, previous metric methods are difficult to preserve latent attribute similarities.3,4 In order to solve this problem, we measure the similarity at attribute level.

Simulation results for the network.
In previous hash methods, the learning target is to compact semantic features and numeric neighbor distribution in full measure. This indicates that there exists a low-dimensional subspace where all hash functions segregate the data points well. 5 Therefore, the goal of hash learning is to learn a best subspace, in which the most identification information is contained, and then being compacted into binary codes.
To simultaneously boost the discriminative power of all hash functions, researchers simplify the procedure into data dimensionality reduction and quantification, with the downsized subspace connecting original and hamming spaces. The down-sized information subspace generated by dimensionality reduction is widely used in many hashing methods, such as principal components analysis (PCA)–based hashing (PCAH) 6 and iterative quantization (ITQ), 7 in which the latent hypothesis is that the goal of dimensionality reduction and hash learning is the same. PCAH generates the project function with PCA method, through which the former K principal components of training data are extracted. However, PCA treats every principal component equally and neglects the difference between each other. To solve this, ITQ learns an optimization rotation angle to balance the difference of every dimension to reduce the quantization error. Similarly, the former two aim to preserve numeric features into a single hamming space and assume that the semantic neighbor distribution can be represented by the numeric neighbor relationship in hamming space. Nevertheless, in previous works, the latent consistency hypothesis has not been guaranteed.
To solve the former two problems, we propose a novel semi-supervised hash learning method with consistency-based dimensionality reduction (SemiNTH for short). SemiNTH compresses high-dimensional data into lower dimensional space by unifying numeric local distribution structure and semantic neighborhood relationships, and then, embeds the attribute-level similar relationship into multiple separate hash tables. The method aims to preserve the values of semantic attribute similarity into the numeric distances of hash code. In similar retrieval scenario, a query entity will be mapped into low-dimensional subspace and then be encoded into a hash vector by several independent hash tables. The result set contains entities for which the hamming distances are short and with which at least one common attribute exists.
The rest of this article is organized as follows. In “Related work” section, we briefly review the related works on dimensionality reduction and hash learning. The next section explains the semi-supervised hash learning method. “Experiments” section presents experimental results that validate the effectiveness of our algorithm. Finally, the conclusion and future work are given in “Conclusions and future work” section.
Related work
With the rapid growth of large-scale networks, metric learning, that is, hash learning, has been proposed as a critical technique for big data analysis tasks.
Latent Semantic Hashing (LSH) 2 method, first proposed to solve (r, c)-nearest neighbor problem in 1998, is being widely used in large scale high-dimensional retrieval field, for example, information search and computer vision. Despite the effectiveness of the nearest neighbor query results of the LSH method is guaranteed by Johnson–Lindenstrauss 8 lemma its learning objective and the criterion of hash function selection are independent of training data. To solve these problems, many hash learning methods have been proposed.
With respect to learning model, methods can be classified as unsupervised, supervised, and semi-supervised. In terms of unsupervised learning model, with none but numeric features available, hashing method integrates data distribution or structure property into hashing codes, such as Spectral Hashing method which is based on data distribution 9 and Graph Hashing method which is based on potential epidemic structure of data. 10 Shen et al. 11 propose an asymmetric binary code learning framework based on inner product fitting, which generates binary codes that reveal the inner products between original data vectors. Supervised hashing method provided with relationship tags encodes hash coding through kernel learning, metric learning, or deep learning.12–14 Li et al. 15 propose a deep pairwise-supervised hashing method simultaneously performing feature learning and hash-code learning for applications with pairwise labels. Liu et al. 16 propose a deep supervised hashing method, which employs a convolutional neural network architecture that takes pairs of images as training inputs and learns compact similarity-preserving binary code. Shi et al. 17 propose a simple kernel-based supervised discrete hashing method via an asymmetric relaxation strategy, which reduces the accumulated quantization error between hashing and linear functions with preserving the hashing function and the relaxed linear function simultaneously. To solve the high time consumption of projection operators, Xu et al. 18 propose a supervised hashing method for implementing a sparsity regularizer, which reduces the number of parameters of the projection matrix and helps avoid overfitting problem. Semi-supervised method learns hash functions with numeric distribution and semantic tags on subset simultaneously, such as semi-supervised hashing system (SSH).19,20 SSH minimizes the empirical error based on labeled data, meanwhile maximizes the distinction ability of coding bits with information theory. The best numerical nearest neighbors are not necessarily the most semantically consistent ones, 7 but it is important to apply dimensionality reduction to capture the numeric distribution structure. In most semi-supervised methods, however, the inconsistency between numeric neighbor distribution and semantic similarity, which comes from labeled data, is ignored.
With respect to subspace dimensionality reduction, many applications have proved the effectiveness of inner subspace, such as classification 1 and feature learning. 21 Due to the fact that hash learning can be seen as a special kind of dimensionality reduction problem, the idea of inner subspace has been adopted to improve hashing preference.7,19,22 However, those several classic researches are demonstrated to be incomplete. 23 The random selection of hash function, leading the precision of LSH subspace, cannot be guaranteed. Failing to optimize the efficiency of partition hamming space, PCAH focuses on minimizing data rebuilding error. To achieve relatively good result, SH requires too many assumptions (i.e. orthogonal constraints of hash functions, uniform distribution of data) that are unsuitable for real applications. Different from the above methods, ITQ places special emphasis on finding the subspace to minimize the quantification loss in hash learning, and finally embed the numeric local nearest neighbor distribution structure into a hamming space. Even though ITQ obtains the best performance, the multiple label constraint and preference limit its scalability. Therefore, those dimensionality subspaces fall short in narrowing the gap between original semantic and final metric spaces.
In real social network, different types of relationships produce various unrelated interactions. This phenomenon and the importance of non-triangular equivalence relations have been deeply studied in theory. 24 Traditional metric learning, however, treats different relations the same and projects multi-attribute data into a single hamming space without thinking about the non-transmission of their attribute similarity3,20 and the latent reasons why semantic connections are built.24–26 Considering the attribute, respectively, similarity components analysis (SCA), Changpinyo et al. 3 propose a probabilistic graphical model to discover similar attributes called “latent components.” SCA defines separate component similarities and then generates composite similarity with OR gate. The experiment indicates that SCA receives excellent accuracy in both multi-way classification task and link prediction task. Multi-Component Hashing (MuCH), a similar hashing method with relatively low complexity, employs multiple hash tables in describing latent attribute similarities. Even though it obtains superior behavior in both semantic description and search efficiency performance than unsupervised methods, the consistency of numeric and semantic similarities is not guaranteed.
Semi-supervised hash learning method with consistency-based dimensionality reduction
As shown in Figure 2, SemiNTH consists of two learning stages, that is, a consistency-based dimensionality reduction stage and a hash learning stage. In particular, the former stage learns a similar matrix R to unify the unsupervised numeric neighbor distribution and the supervised semantic similar relationship into a low-dimensional subspace. The unsupervised numeric features are extracted from the high-dimensional original space, and the supervised semantic features are obtained from hand marking. After this stage, the composite features that can be used to identify different entities are extracted. And in the downsized subspace, the attribute-level similar entities are mapped in nearby locations with each other. Subsequently, the latter stage learns hash functions to project the composite attribute similarities into multi-hamming spaces. In a nutshell, the whole learning process corresponds to a space compression procedure and a following transformation procedure. At the stage of compression, with labeled supervision entities, we aim to confer the semantic relationships of different entities to their numerical distributions. Therefore, the numeric features that express the semantic labels will be captured from the original space. To express attribute-level similarities, the second stage transforms the downsized subspace into multiple binary spaces. An entity will be encoded by several independent binary hash tables where each corresponds to a binary space. Notably, two entities nearby in one binary space may be far from each other in another space. The reason is that two entities may be similar in some of their attributes but dissimilar in the others. Thus, the generated multiple binary spaces describe the latent similarities between entities.

The framework of SemiNTH.
The learning process composes two components: (1) retentive neighborhood relationship matrix, which ensures hash codes to be consistent with hidden attribute semantics, and (2) similarity relationship constraint component, which aims at preserving the attribute semantic similarity into the distance of hash codes. In the next section, we will introduce the subspace learning process of consistency-based dimensionality reduction and latent similarity learning process, respectively.
Notation
Given a set of N training entities, denoted as
Consistency-based dimensionality reduction with subspace learning
A high-quality dimensionality reduction method should preserve the most original semantic relationship information into binary hash codes, which is designed to correspond with the target of hash learning task.
Definition 1: Numeric feature
The numerical characteristics of the component elements of an entity. These are intuitive representations that can be extracted from the original data, for example, the size of picture and term frequency-inverse document frequency.
The semantic similarity relationships of entities are expressed by their labels that are given by whether they are similar from one or more semantic standpoints, as shown in Figure 2. Thus, for two entities, there are no consistent guarantees in their semantic similarity relationships and the distance of their numeric features.
Definition 2: Consistency-based dimensionality reduction
The process that projects high-dimensional numeric features of the entities into downsized subspace, in which the distance of the low-dimensional vectors are corresponding to their semantic similarity relationships.
Thus, the goal of consistency-based dimensionality reduction is to learn a mapping matrix
Dimensionality reduction function with uniform feature subspace
With a reduction matrix

where the value range of standard sigmoid function is expanded to

where
Final objective
The target of dimensionality reduction process is to preserve the most useful original semantic information into numerical distance by the least dimensions. The loss function is composed of two components: consistency learning item and regularization item. To minimize the loss due to dimensionality reduction, one natural way is to optimize the learning formula, which aims at penalizing pairs of items with same semantic are mapped faraway in Euclidean distance. The penalty degree is monotonic decreasing with the Euclidean distance between a couple of similar items. Therefore, the penalty item can be described by logistic function especially for the function’s nice probabilistic interpretation. Therefore, the minimum value of consistency function loss (maximum-likelihood of logistic loss) can be represented as

where

where

where

where
Attribute-level hashing with latent similarity learning
Each dimension of the vector obtained in the dimensionality reduction process corresponds to a linear partition of the original space. Therefore, each partition is created according to a subset of the semantic features and the corresponding generated dimension expresses whether two entities are similar from this certain semantic perspective. One or more partitions are combined to describe whether the entities are similar, and these partitions formed a semantic attribute. The L partitions obtained from the optimization process cover all the semantic attributes, and there are as many differences as possible between these partitions. However, the distinguishable features of different similar attributes are mixed together in the reduced vector.
Multi-table similarity
With the numerical and semantic similarity being unified, by “Consistency-based dimensionality reduction with subspace learning” section, we propose a method to combine these two kinds of similarity information into hash encoding. In particular, multiple independent hash tables are adopted to express the latent similar attributes. The goal is to project one of the attribute similarities, which is described by a subset of semantic features, into K hash code bits in one of those several hash tables. For the

where
Final objective
In the downsized subspace
Different from the former non-transitive supervised hash MuCH,
20
our method, SemiNTH, provides unsupervised consistent numeric-semantic information that complements to strengthen the description ability of the final hash codes. The supervised semantic relationships and unsupervised neighbor distribution are denoted as matrix

where
The objective of this process is to minimize a matrix W with which hashing codes satisfy the properties that

where


where
Optimization
Directly minimizing the objective loss function in equation (10) is intractable because the hash function in equation (7) is not continuous. Therefore, equation (7) is relaxed in the same way as equation (1). With the relaxation, Block Coordinate Descent (BCD) is applied to solve these two optimization problems.
As Algorithm 1 shows, first of all, the unsupervised numeric feature matrix X, supervised semantic feature matrix R, and parameters of the final hash spaces (i.e.

The gradient of consistency-based dimensionality reduction objective function LR is

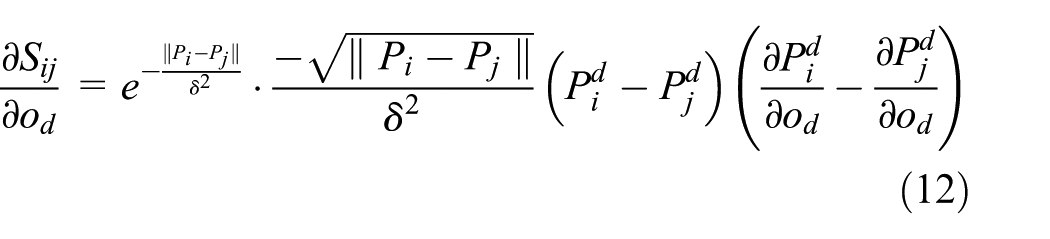
For hash learning, the gradient of objective function LS is similar to Ou et al. 20
Experiments
In our experiments, we use two real-world labeled public datasets to evaluate the proposed SemiNTH method, and the semantic similarity comes from the intersection of their labels.
Dataset and settings
NUS-WIDE is a web image dataset, dataset that contains 269,648 images, being crawled from Flickr and associated to 81 concepts. Each image belongs to at least one concept and is regarded similar to those of the same concepts. The features are formed by concatenating five kinds of low-level features, that is, 500-D bag of word of scale-invariant feature transform (SIFT). In this article, we take into consideration the top 10 concepts and total 1134-D features. We randomly select 10,000 images as training set and 2000 for query test. In addition, one-tenth of the training set are randomly selected as supervision samples, with their non-transitive paired similarity visible. DBLP is a digital bibliography of major computer science community. Similar to MuCH, 20 we select authors who have published at least three papers in 31 conferences, which belong to 11 specific fields. From 5934 authors and their 30,646 papers, 3900 authors are randomly selected as training sample and leaving 1500 as testing. Two authors, coming from 390 supervision samples, are labeled similar if they have ever published in the same filed, otherwise they are dissimilar. The document of every author is formed by connecting titles and abstracts of their papers and then represented by 150-D LDA (Latent Dirichlet Allocation) feature.
The sample distributions are different in the two datasets. In NUS-WIDE training set, over 93.92% of samples belong to single concept and over 5.8% belong to double concepts. By comparison, DBLP is more disperse in concept number distribution. In detail, 34.5% belong to double concepts and 17% belong to more concepts. The detail statics are listed in Table 1.
Statistics of Datasets.

In our semi-supervised hash learning method, the relationship matrix R is generated by categories those training samples belong to. Obviously, there are two sets, one of which is composed of tagged samples and the other not. For an element in R, the relationship is marked with 1 in the situation if they have at least one common concept, otherwise it is marked with −1. In the context that one sample is tagged while another is not, the mark is set to 0. The scale parameter
Baseline and evaluation metrics
We aim to optimize hash coding properties of similarity maintenance ability and retrieval efficiency. Three widely used retrieval strategies are adopted in our experiments: (1) retrieving top Nq list, (2) hamming radius equals 2 (radius = 2), and (3) hamming radius to search,
20
that is,
We compare our hash method (SemiNTH) with MuCH 20 and other three state-of-art hashing methods, that is, ITQ, 7 PCAH, and LSH. 2 Finally, all results are averaged from 10 runs on a workstation with 2.6 GHz Intel Xeon CPU and 62 GB RAM.
Results and analysis
Four set of experiments are conducted on both datasets to evaluate the performance of SemiNTH with class labels as ground truth. To evaluate the retrieval accuracy of multi-tables, we vary number of hash bits and hash tables in Figure 3. The subfigures of Figure 3 depict the query performance from two points of view, the first retrieval strategy with Nq = 200 and the mean average precision, respectively.

Retrieval performance of SemiNTH on NUS-WIDE. Different hash bits of each hash table {8, 16, 24, 32} and different hash tables {1, 2, 3, 4} are tested: (a) precision of top 200 samples and (b) mean average precision at radius = 2.
In Figure 3(a), the horizontal axis represents number of hash tables, and the vertical axis means the precision of the set of top 200 samples. The four lines in each sub-figure stand for the results obtained by SemiNTH with different bits in single hash table, respectively. As shown in Figure 3(a), the precisions improve with the increased number of hash tables and 32-bit hash table maintains the highest precision mostly. Similarly, Figure 3(b), in which horizontal axis stands for the number of hash bits and vertical axis stands for the mean average precision with radius = 2, depicts the results of different hash tables in four lines and shows that the values of precision increase when more hash tables are adopted. It indicates the existing attribute-level similarity and verifies the performance of multi-table hash method. Due to the fact that the sample distribution in DBLP training set is more disperse (as shown in Table 1), availability of multi-table which is shown in Figure 4 is more obvious. Therefore, it illustrates that multi-table is necessary in preserving the original similar relationships into hamming space.
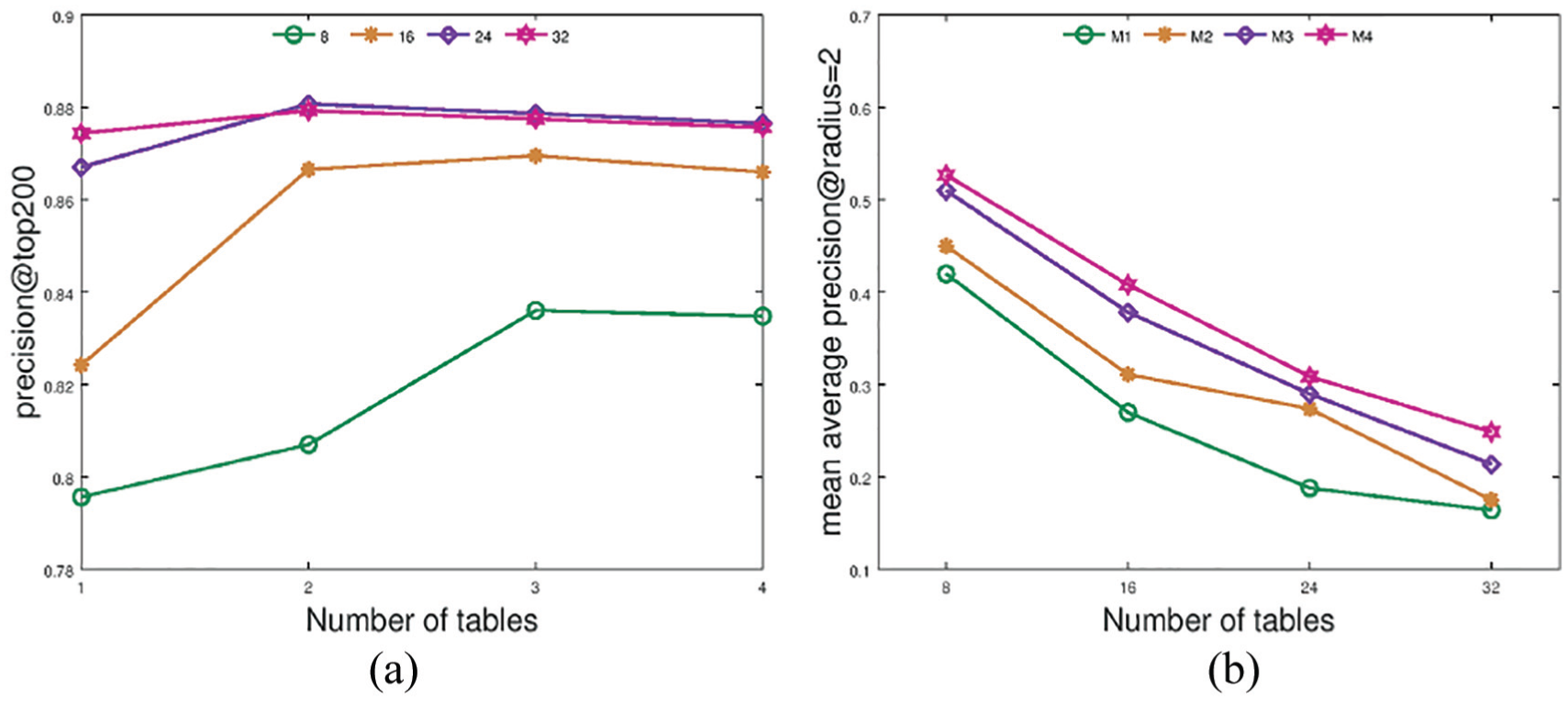
Retrieval performance of SemiNTH on DBLP. Different hash bits of each hash table {8, 16, 24, 32} and different hash tables {1, 2, 3, 4} are tested: (a) precision of top 200 and (b) mean average precision at radius = 2.
In Figure 5, the horizontal axis indicates number of bits in single hash table,while vertical axis indicates the precision and recall of retrieved samples when radius equals 2, respectively. The six lines, with different legends, denote results of six hash learning methods specifically: unsupervised hash methods ITQ, 7 LSH, 2 PCAH, 6 and MuCH 20 (the number is fixed to be 2 for its experimental best performance), and our consistency-based semi-supervised method SemiNTH (SemiNTH2 and SemiNTH4). Here, the number 2 in SemiNTH2 represents number of hash tables adopted in SemiNTH, where the bit number of every hash table equals to that of the comparative methods. As displayed in Figure 5(a), PCAH outperforms all the other methods, and ITQ and SemiNTH have a consistent advantage over LSH and MuCH. This might be because LSH and MuCH do not rely on PCA, which helps to preserve semantic consistency for the smallest code sizes. 7 Compared to experiments on NUS-WIDE, the significantly better performance of MuCH on DBLP is illustrated in Figure 5(b). Note that in Figure 5(b), the phenomenon that LSH plots a strongly upward trajectory with increasing bit size may be due to its theoretical convergence guarantee. The major precision gap of MuCH between NUS-WIDE and DBLP verifies our assumption that in entity level, numeric features may not be inconsistent with semantic features. The results prove that multi-table is necessary to preserve the original similar relationships into hamming space.

Precision at radius = 2 on two datasets: (a) precision on NUS-WIDE and (b) precision on DBLP.
Figure 6(a) and (b) show the retrieval performances on DBLP dataset of recall at radius = 2 and the values of MAP when testing by the first retrieval strategy with Nq = 200, respectively. It can be seen that the retrieval performance of SemiNTH is always superior to others and the performance of MuCH is acceptable. It is intuitive that multi-table methods obtain obviously better performance and state the effectiveness of numeric and semantic consistency method (SemiNTH).
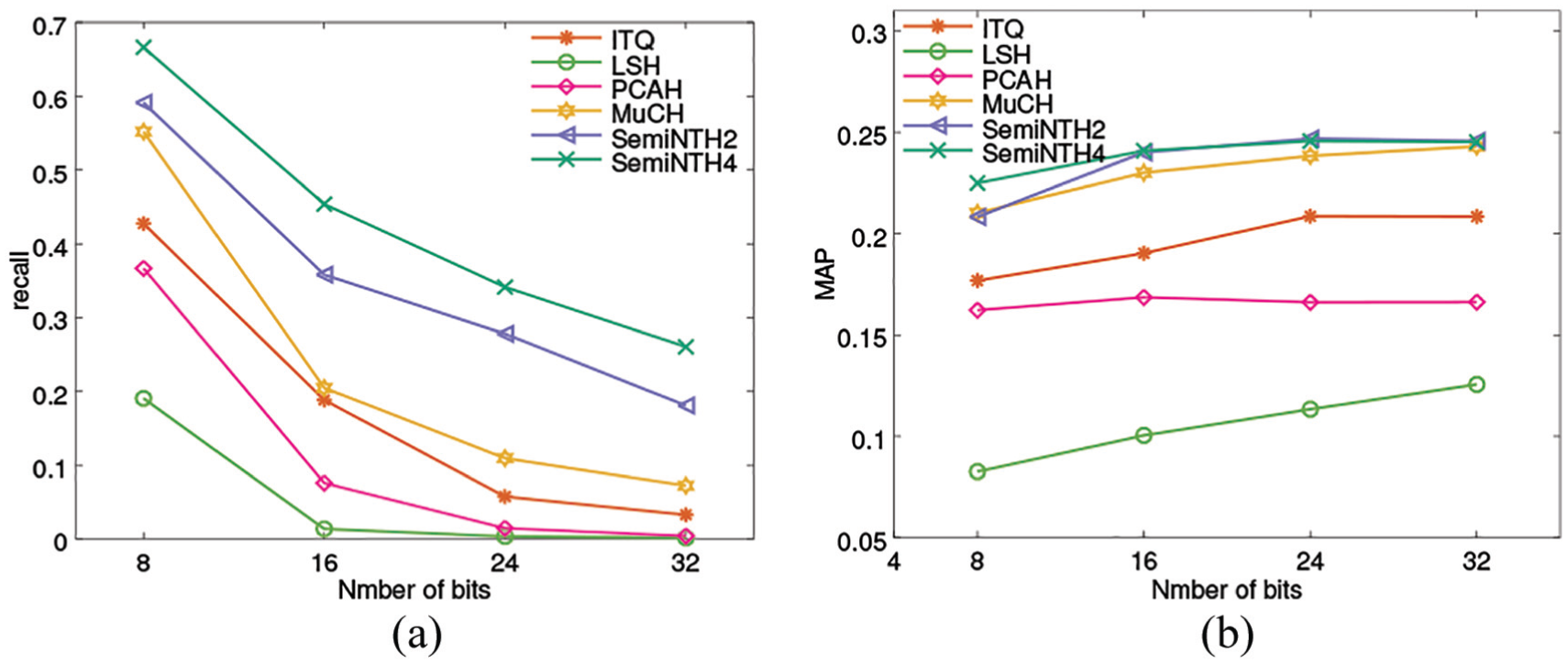
Two different retrieval performances on DBLP: (a) recall at radius = 2; (b) mean average precision at Nq = 200.
Figure 5(a) shows that the performance of those methods is stable with different hash bits. Therefore, we take retrieval performance of the top 500 samples when bit number equals 16 as example to illustrate the retrieval accuracy and search efficiency of SemiNTH, which can be seen in Figure 7. Every line represents a method, plotted by different volume of returned samples on the horizontal axis and performance metrics on the vertical. Figure 8(a) and (b) display that SemiNTH4 maintains stable highest precision and recall. What is more; as shown in Figure 7(c), although SemiNTH4 increases with three times more storage, its search efficiency is still comparable with the best competitor ITQ. Therefore, our SemiNTH is proved more suitable in datasets that are associated with multiple correlated semantic labels. To further demonstrate the superiority of SemiNTH, we adopt the same experiments on DBLP whose distribution of label number is more uniform.
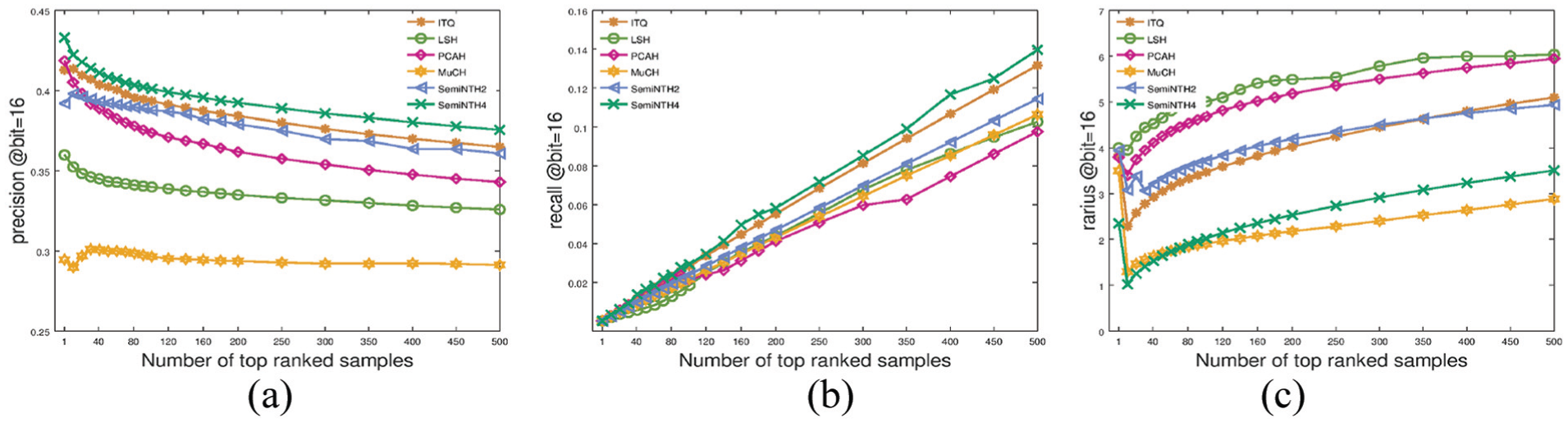
Retrieval performance of top 500 on NUS-WIDE with 16 bits hash table: (a) precision of top 500 at bit = 16; (b) recall of top 500 at bit = 16; and (c) radius of top 500 at bit = 16.
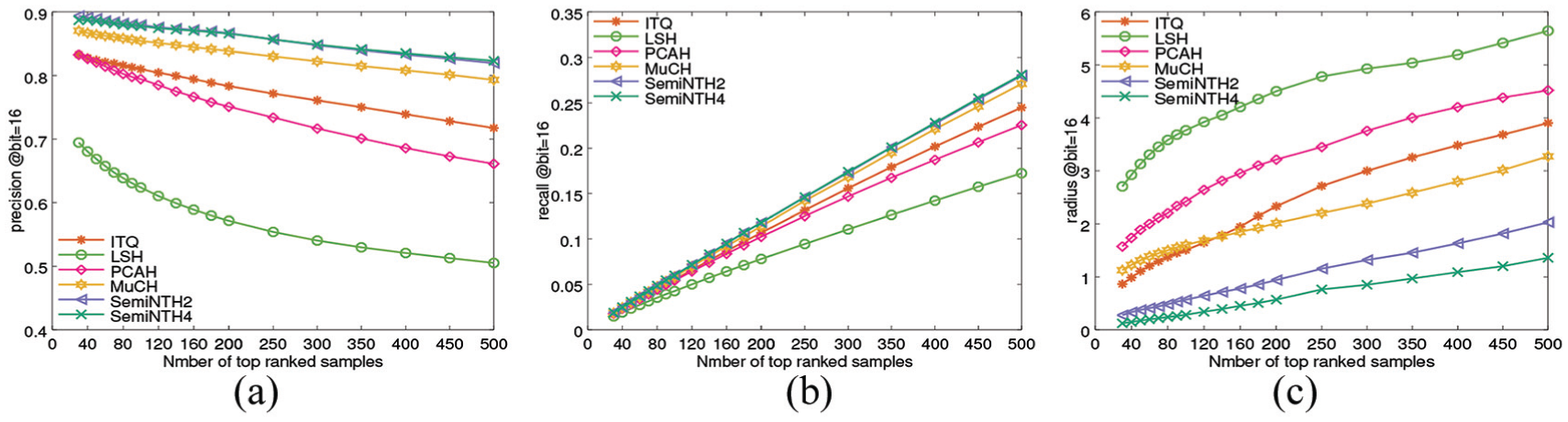
Retrieval performance of top 500 on DBLP with 16 bits hash table: (a) precision of top 500 at bit = 16; (b) recall of top 500 at bit = 16; and (c) radius of top 500 at bit = 16.
Figures 5(b) and 6(a) reveal the outstanding performance of SemiNTH, especially versus MuCH, which certifies that utilizing both numeric local distribution structure and semantic similarity relationship can faithfully overcome the difficulty of nearest neighbor search. The hash retrieval efficiency of SemiNTH, which seems to be limited by storage space, can be guaranteed since its search radius decreases exponentially (seen in Figure 8(c)).
Finally, SemiNTH proves our hypothesis that the numeric and semantic features may not be consistent with each other. Being complemented with semantic consistent numeric features, SemiNTH preserves the most differentiated information into multiple hamming spaces and receives the best retrieval performance. That verifies the existence of attribute-level similarity yet again.
Conclusion and future work
In this article, we propose a numeric and semantic consistency hash learning method SemiNTH to unify the numerical features and supervised semantics into a low-dimensional space before hash coding. Specifically, we improve a multiple table hash method (MuCH) with local distribution structure and conduct experiments on two public datasets. Experimental results demonstrate that SemiNTH is effective in preserving useful information for hash encoding with the consistent low-dimensional subspace. Besides, SemiNTH can obtain high-quality retrieval performance in multi-table context in which the similarities can be attribute level.
In practical applications, the similarity search on heterogeneous sources is a hard problem for its multiple similar components. Therefore, in the future work, we would like to expand our method to metric multi-source similarity.
Footnotes
Acknowledgements
We are grateful to Mingdong Ou for providing the Matlab code of the MuCH method. Thanks for the support of HABIR, an open source project, provided by Yong Yuan. We thank Pengfei Liu for his guidance on initial drafts of the paper.
Handling Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by National Key Research and Development Program of China (grant No. 2016YFB0800802 and grant No. 2017YFB0801804), Frontier Science and Technology Innovation of China (grant No. 2016QY05X1000), and Key Research and Development Program of Shandong Province (grant No. 2017CXGC0706 and No. 2016ZDJS01A04).