
Abstract
Large-scale task processing for big data based on cloud computing has become a research hotspot nowadays. Many traditional task processing approaches in single domain based on cloud computing have been presented successively. Unfortunately, it is limited to some extent due to the type, price, and storage location of substrate resource. Based on this argument, a large-scale task processing approach for big data in multi-domain has been proposed in this work. While the serious problem of overheads in computation and data transmission still exists in task processing across multi-domain, to overcome this problem, a virtual network mapping algorithm based on multi-objective particle swarm optimization in multi-domain is proposed. Based on Pareto dominance theory, a fast non-dominated selection method for the optimal virtual network mapping scheme set is presented and crowding degree comparison method is employed for the final optimal mapping scheme, which contributes to the load balancing and minimization of bandwidth resource cost in data transmission. Cauchy mutation is introduced to accelerate convergence of the algorithm. Eventually, the large-scale tasks are processed efficiently. Experimental results show that the proposed approach can effectively reduce the additional consumption of computing and bandwidth resources, and greatly decrease the task processing time.
Introduction
The rapid development of big data1,2 has brought us many opportunities and challenges in recent years. While the problem of large-scale task analyzing and handling has become one of the vital contents in big data, the large-scale task processing approach based on cloud computing environment3,4 is an important way to solve the problem of analyzing and handling tasks for big data. A fast and efficient task processing approach can realize the reasonable allocation of tasks and the effective utilization of resources, which ensures the cooperative work of each task processing node in the cloud computing environment. In contrast, the load imbalance in the task processing is likely to appear due to the limitation of some certain traditional task processing approaches and the performance variation of each resource in heterogeneous distributed system environment 5 under normal circumstances, which will seriously affect the overall performance of the system. Therefore, a fast and efficient task processing approach is crucial to the solution of large-scale task processing problem.
Aiming at the problem of how to quickly and efficiently handle tons of tasks for big data, a great deal of work based on the heuristic algorithm has been proposed at present. However, some of the existing work aims at speeding up the processing of tasks but neglects the overall load-balancing problem. While some other work focuses on the problem of load balancing without taking into consideration the communication problem of the task processing nodes, overall, most of the current studies only take the single-objective optimization problem into account. Based on this argument, this article realizes the large-scale task processing by virtue of a multi-objective combinatorial optimization approach. 6
With the scale expansion and type diversifying of tasks in network, it is difficult to satisfy the needs of massive task processing by virtue of a single domain in current large-scale challenging applications.7,8 Sharing and collaboration in multi-domain 9 has become an effective way to process large-scale tasks. The problem of optimization in computing and communication resource overhead 10 among domains needs to be overcome urgently in the course of disposing tasks for big data.
Based on this motivation, a large-scale task processing approach for big data in multi-domain has been proposed in this article. The proposed approach can effectively improve the resource utilization rate and promote the coordination of each working node through realizing the load balancing in multi-domain, which improves the overall performance of the system. In the meanwhile, taking advantage of optimizing communication resource, it effectively decreases the extra bandwidth resource consumed by data transmission among domains and the data delay. In order to achieve the multi-objective optimization of the load balancing of the overall system and the minimization of required bandwidth resource cost, this article has proposed a virtual network mapping algorithm based on multi-objective particle swarm optimization in multi-domain. We present a novel method for fast acquisition of the optimal virtual network mapping scheme set on the basis of a fast and effective non-dominated selection method based on Pareto dominance theory. 11 We design and utilize the crowding degree comparison method 12 to acquire the final unique solution. Cauchy mutation method 13 has been used to avoid local optimum.
The rest of this article is organized as follows. In the “Related work” section, the current approaches achieving large-scale task processing for big data are introduced. In the “Proposed problem and its formulation” section, we formalize the proposed problem in this work and describe the expression of solution. In the “Proposed large-scale task processing approach” section, the architecture of the proposed approach is put forward. The design and implementation of the main algorithm are introduced in detail. Moreover, the origin of the idea of this work is expounded. In the “Performance evaluation” section, the experimental results are obtained through experiments, proving that the proposed approach can effectively overcome the problem presented in this work. Finally, the “Conclusion and future work” section concludes this article and specifies some future work.
Related work
The large-scale task processing for big data using cloud computing has always been a hot research topic nowadays.14–17 Many approaches have been proposed for the quick and efficient task processing. Generally, these approaches can be divided into two categories: single-domain methods and multi-domain methods.
In the aspect of single-domain methods for the large-scale task processing, Voicu et al. 18 have proposed a multi-objective, multi-constraint (MOMC) scheduling algorithm of many tasks in Hadoop. It makes a study on the scheduling and processing of many tasks from the two goals, avoiding resource contention and having an optimal workload of the cluster. The Million Song Dataset is used to evaluate MOMC which aims to solve the problems of the total execution time of task scheduling and the workload of the cluster. Jin et al. 19 have introduced the task allocation techniques with clustering and load balancing in the field of Internet to the field of image processing job allocation of alternative big data. A load-balancing cluster architecture has been designed and realized for the alternative big data. In the meanwhile, an improved load-balancing algorithm applicable to large-scale image processing has been presented. Kim et al. 20 have presented and implemented the approach Many-task computing On HAdoop (MOHA) which can make an effective convergence of MTC technologies and the existing big data platform Hadoop. The proposed approach is developed as a Hadoop YARN application so that it can transparently co-host existing MTC applications with other big data processing frameworks such as MapReduce in the Hadoop cluster. Hirai et al. 21 have taken into consideration the efficiency of backup tasks. They have modeled the task-scheduling server as a single-server queue, in which the server consists of a number of workers. The task is split into subtasks, and each subtask is served by its own worker and an alternative distinct worker when a task enters the server. It is explicitly derived that the task processing time distributions for the two cases that the subtask processing time of a worker obeys Weibull or Pareto distribution. The algorithms above can effectively achieve large-scale task processing for big data. Unfortunately, there is still a limitation in the abilities of processing nodes in case of using single domain for tons of task processing in big data, which may result in some phenomena such as the load imbalance and the waste of resources. In the meanwhile, the location of the resource required to perform tasks will make an impact on the processing efficiency of the single domain.
With respect to the multi-domain methods for the large-scale task processing, Gu et al. 22 have proposed a cross-domain workflow scheduling system called Arana. Herein, taking advantage of moving program close to data and integrating popular big data processing platform, this system enables users to complete computing with cross-domain data without transferring. Xu et al. 23 have introduced a structured big data management system that supports the cross-domain collaborative query, and it emphatically describes the system architecture and implementation scheme. The system integrates the advantages of HDFS (Hadoop Distributed File System) and parallel database. Through the proposed cross-domain query module, it would not be necessary to put the datasets together in one datacenter or local area network (LAN), which makes full use of the existing resources. Li et al. 24 have proposed an intermediary framework using multiple cloud environments to provide streaming big data computing service with lower cost per load. In the proposed framework, a pricing strategy has been presented to maximize the revenue of the multiple cloud intermediaries. Through the extensive simulations, it can be observed that the proposed pricing strategy can bring higher revenue than other pricing methods. Dou et al. 25 have proposed a privacy-aware cross-cloud service composition method, named HireSome-II (history record-based service optimization method), based on its previous basic version HireSome-I. In the proposed method, aiming at enhancing the credibility of a composition plan, the evaluation of a service is promoted by some of its quality-of-service (QoS) history records, rather than its advertised QoS values. In addition, the K-means algorithm is introduced as a data filtering tool for the representative history record selection. Zhang et al. 26 have proposed a strategy of partitioning group based on hypergraph (PGH) to formulate the model of sharing files. Through the proposed PGH algorithm, Bags–of–Tasks (BoTs) applications would be partitioned into several groups to minimize the time of data transferring. This work has also adopted another scheduling policy, which is called optimized task tree (OTT) strategy to handle the directed acyclic graph (DAG) workflow of massive remote sensing data processing with data dependencies. All the efforts above have been made for the large-scale task processing in multi-domain environment. But the performance of these proposed approaches is still affected by the problems of the failure of task processing nodes and the relatively high algorithm complexity. Moreover, some of them are limited to single-objective optimization, which retards the whole performance improvement of the approaches to some extent.
The proposed problem and its formulation
Proposed problem
In order to handle the large-scale tasks from users more quickly and efficiently, based on the idea of parallel computing, a novel approach has been proposed in this work that uses cooperation of multiple domains to process tasks for big data, which differs from the previous single-domain approach for processing the general tasks. Generally, the processing speed of each node in the domains depends on the speed of the computing resource and the related internal scheduling strategies. On the one hand, in general, with the continuous increase in user requests, the requested tasks will be assigned to each node of domains according to some certain algorithms, which will easily result in a large number of tasks assigned to a certain node. The resource of node in this situation may hardly satisfy the requirements of the tasks running on it, which will cause overload, a waste of resource, and extra power loss. Thereby it will lead to the load imbalance of the domain and the decrease in the throughput. Finally, it cannot meet the needs of users. Thus, it can be seen that an efficient, reasonable, and load-balancing task processing approach has become necessary. On the other hand, it is well known that in the cloud computing environment supporting large-scale task processing, the amount of data transmission among domains is so enormous that it will produce enormous pressure on the fixed network resource and increase the bandwidth cost sharply. Figure 1 gives an example of task allocation in multi-domain. In order to realize the cooperation of multiple domains to process tasks for big data, an efficient, reasonable, and load-balancing task processing approach should be proposed, and in the meanwhile, there is no doubt that minimization of bandwidth resource cost for the communication among domains also becomes an important target.
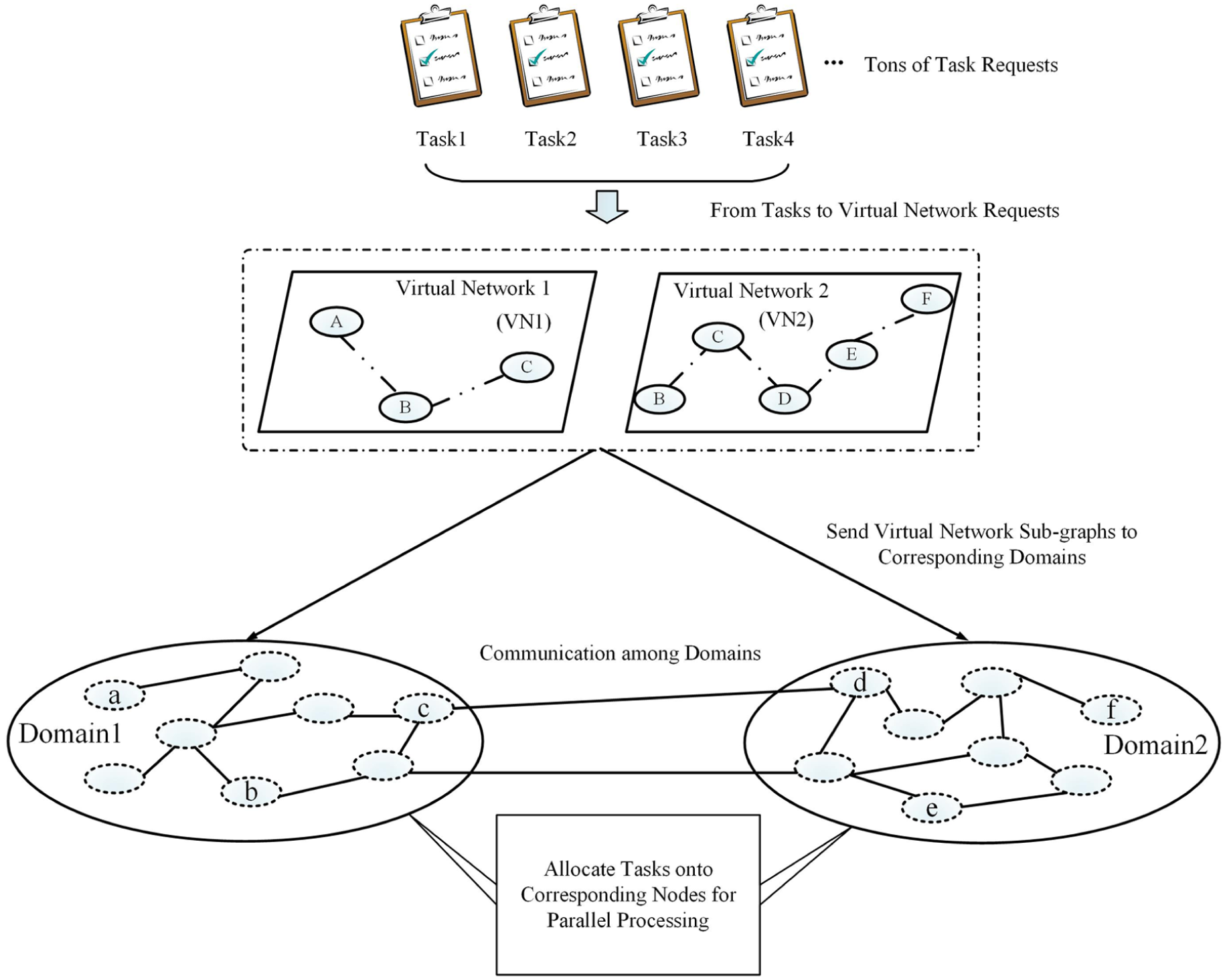
Task allocation onto physical nodes in multi-domain.
Problem formulation
The problem presented in this work can be formalized as a question that we allocate the task requests received within a time window Δt into shared physical network in multi-domain, so as to achieve the load balancing and the minimization of bandwidth resource cost for the communication among domains in the course of using the cooperation of multiple domains to process large-scale tasks in big data. In order to solve the problem, a five tuple, V = {PN, TS, Ccpu, Cmem, Clink}, is defined to describe the problem scenario, where PN represents a set of available processing nodes, PN(n,t) = {pn1, pn2, …, pnn}, here t indicates the start time of task allocation; TS represents the set of task requests from users within a Δt, TS (m, Δt, t) = {ts1, ts2, …, tsm}; Ccpu is the set of current remaining CPU resource of the n nodes in PN, Ccpu(n, t) = {
With respect to the stage of virtual network mapping for our work, based on the above content, we can formalize it as follows. A substrate network can be denoted as a weighted undirected graph Gs = (Ns, Ls), where Ns represents the set of related physical nodes and Ls represents the set of physical links in the substrate network. Similar to the substrate network, a virtual network request can also be denoted as a weighted undirected graph Gv = (Nv, Lv), where Nv is the set of virtual nodes and Lv is the set of virtual links. And the process of mapping virtual network request onto substrate network can be represented as M: Gv = (Nv, Lv) →Gs = (
The first objective function in this article is based on load balancing. We employ load-balancing degree to measure the load-balancing effect in multi-domain. The calculation approach of load-balancing degree is as follows. After finishing the allocation of all task requests based on a virtual network mapping, the load of the ith processing node in the domain can be expressed as follows
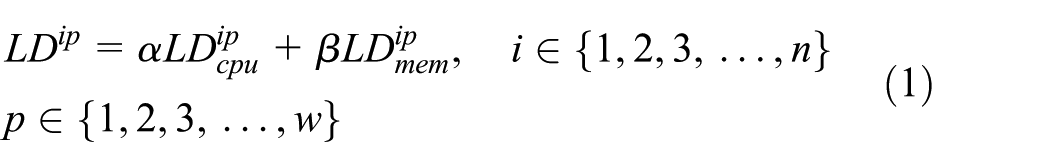

where

where


Then, we can attain the load-balancing degree, whose formula is as follows

By using the above formulas, the first objective function can be described as the following form and should be minimized

Thus, the algorithm proposed in this article can achieve load balancing by minimizing
In this article, the second objective function of the algorithm is based on the cost of required bandwidth resource for the communication among domains. In order to formalize the goal better, the mapping relationship of the tasks to the processing nodes can be represented as TM (n, m, p, t(q)), here p∈{1, 2, 3, …, w}, where p represents an arbitrary one of the w mappings and q denotes an auto-increment integer along with the allocation of tasks which represents the task allocation state of a certain time. In consideration of the original intention of minimizing the bandwidth resource cost and through the repeated demonstration in this work, we can define the total required bandwidth cost in the course of using cooperation of multi-domain to process large-scale tasks as follows

where wg,h represents the physical link weight, and it is set to α when the physical nodes g and h belong to the same domain while β when g and h belong to different domains. It can be represented as follows

When the virtual link lv (i, i′) has been successfully mapped onto the physical link ls (g, h) and allocated the required bandwidth resource,
At this point, the problem put forward in this work has been formalized as a multi-objective optimization problem with constraints. That is
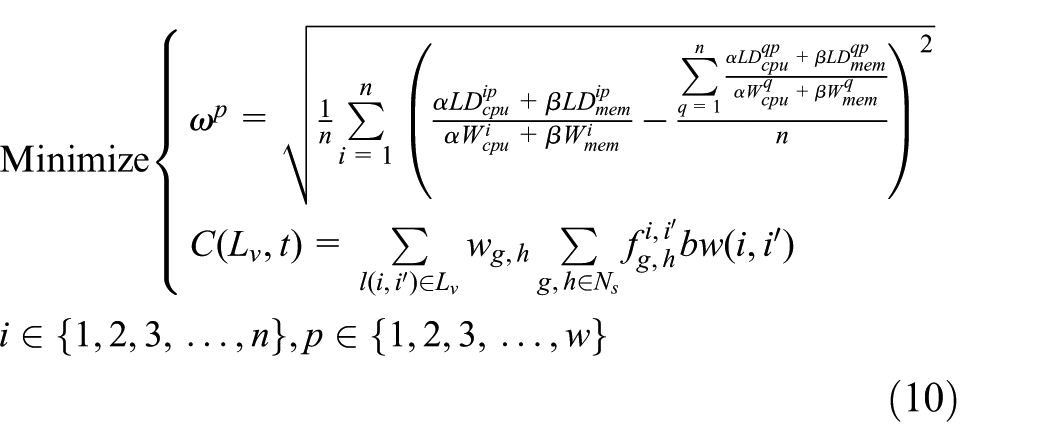
In this article, aiming at achieving the large-scale task processing effectively, we have presented a virtual network mapping algorithm in multi-domain based on multi-objective particle swarm optimization. It is worth noting that the optimal node mapping scheme should be a prerequisite for the whole optimal mapping scheme including node and link mapping. In order to find out the optimal solution vector about the processing nodes to be mapped to in all task allocations, the main problem to be solved first should be the coding method. It represents a direct correspondence of the problem space and the individual in the particle swarm optimization, which means that a particle can be expressed as a solution for a specified problem. In this article, we need to allocate m tasks to n processing nodes, thus the problem can be considered as an m-dimensional problem. The individual in particle swarm optimization will be expressed as an m-dimensional vector, and each dimension is an integer from 0 to n−1. Here, the position vector is expressed as
The proposed large-scale task processing approach
Design of system architecture
Figure 2 describes the architecture of the proposed large-scale task processing approach for big data in multi-domain (LTBM). The interaction between LTBM and other entities has been shown. First, the monitor acquires the information of resource requested by a large number of tasks as well as the status information of remaining resource amount of m available physical nodes and n available physical links in multiple domains. Taking advantage of the information acquired from monitor, LTBM generates the virtual network mapping scheme, which is transmitted to the virtual network mapping controller for the execution of mapping scheme. The allocation controller receives and carries out the task allocation strategy based on the successful node and link mapping. In the end, the task requests accumulated within a Δt are allocated to the corresponding physical nodes for processing in multiple domains.
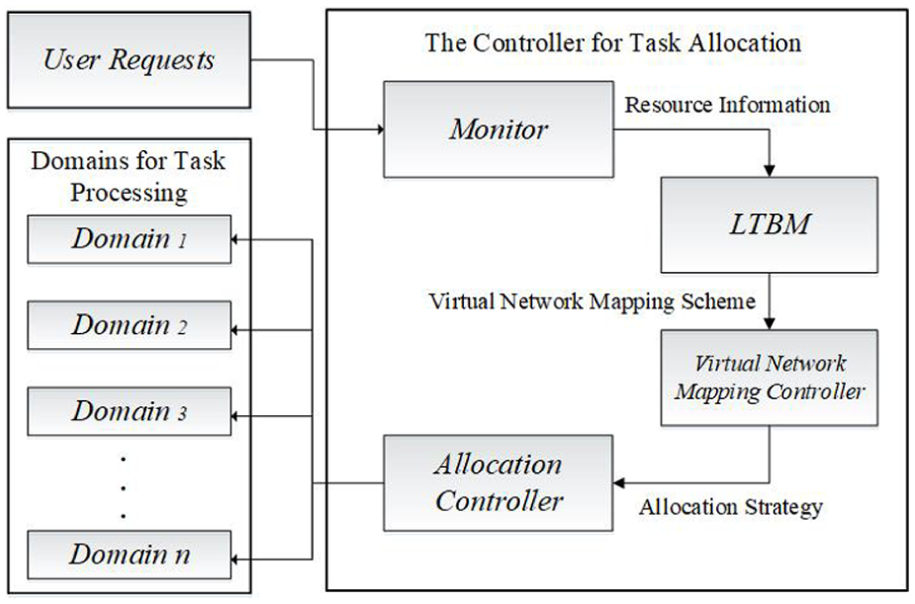
View of LTBM architecture.
Instead of the single domain with limitations such as processing capacity, resource location and type, the structure of multi-domain has been used for large-scale task processing in this work. The proposed LTBM approach can be used to achieve the multi-objective combinatorial optimization of the load balancing of nodes and the minimization of the bandwidth resource cost for communication among domains based on the architecture of using the cooperation of multiple domains to handle large-scale tasks in big data. It realizes the virtual network mapping of the proposed approach for handling large-scale tasks by cooperation of multiple domains. Tons of tasks can be quickly and efficiently processed. LTBM is a multi-objective optimization algorithm based on particle swarm optimization. The velocity and position of the particle are updated using Pareto theory for multi-objective optimization, thereby the Pareto optimal solution of the multi-objective problem proposed can be found by the particle evolution.
Different from the previous single-objective particle swarm optimization, a novel strategy is usefully employed for generating the initial population in LTBM. And the comparison of feasible solutions is realized based on Pareto dominance theory in the iterative process of algorithm. Herein, a novel method has been proposed to quickly obtain the optimal virtual network mapping scheme set in multi-domain. It is based on a fast non-dominated selection method to obtain Pareto optimal solution set, which is the optimal solution set of mapping schemes of this work. Then, we design and employ the crowding degree comparison method to get the final unique solution and guarantee the population diversity of algorithm. On the one hand, aiming at Pareto optimal solution set, Euclidean distance has been introduced to calculate the crowding degree of each optimal solution as the fitness value. The final unique optimal solution can be received by comparing their fitness values. On the other hand, the greater the distance among the feasible solutions, the more favorable to the uniform distribution of the solutions in the Pareto optimal solution set. It decreases the possibility that the population tends to form a small number of aggregates, thus the occurrence of gene drift in genetics can be avoided to a large extent. And the population diversity can be guaranteed. In addition, in order to further optimize the algorithm and avoid falling into local optimum resulting in slow convergence of the proposed LTBM algorithm, Cauchy mutation is introduced to improve the performance of global search.
LTBM algorithm
The specific process of LTBM is as follows:
Step 1. The population of the proposed LTBM algorithm should be initialized. The maximum number of iterations is set to MaxGeneration. And then, not only do we initialize the position vector of each particle, Pop[i], but we have also initialized the kinematic velocity vector of each particle, that is, Vel[i] = 0. Based on the Kruskal minimum spanning tree algorithm, the physical paths with minimum weight can be dynamically selected from the set of available physical paths in each iteration. After obtaining the minimum spanning tree, the virtual node mapping is executed and then the virtual link mapping is adjusted to output the final mapping scheme.
Step 2. Evaluate the particles in the population. The fitness values of each particle can be obtained by formulas (7), (8), and (11).
Step 3. The Pareto optimal solution set is obtained, which is the optimal virtual network mapping scheme set in this article. Under the premise of ensuring the maximum quantity of successful mapping, the archive method is introduced and used to filtrate the particles in the population to determine whether the particle can be archived. Here, we define the following rules: If the archive is empty at the beginning, the current feasible solution is archived. At this time, if the archive is non-empty and the feasible solution to be archived is dominated by certain feasible solutions in the archive, the dominated feasible solution is excluded. If there is no feasible solution which can dominate the feasible solution to be archived, the new feasible solution is archived. If the feasible solution in the archive is dominated by the new element to be archived, the feasible solution is automatically removed.
Based on the above rules, first, add the first solution of population X into the set X′. Then, the other solutions in the population X are compared with the solutions of set X′. If any individual y in the set X can dominate any individual y′ in the X′, the individual y′ is removed. If the individual y in the set X is dominated by the individual y′ in the set X′, the individual y is not retained.
Step 4. Obtain the unique optimal solution. The crowding degree comparison method is designed and employed in this work. By calculating the crowding degree of each feasible solution in the Pareto optimal solution set as the fitness value and comparing them, the final unique solution can be obtained. Then, based on the Euclidean distance formula, we calculate the diagonal length of the minimum rectangle forming around the specified point (a feasible solution), which is defined as a variable Di, called crowding degree. Specific process is as follows:
In this article, we need to overcome a multi-objective optimization problem with two objective functions. According to the definition of Euclidean distance, the formula of crowding degree of each solution is

In the calculation of crowding distance, we need to sort the individuals of population in ascending order according to the function values of the two objective functions presented in this article. And aiming at the solution on the boundary of each objective function, an infinite value of crowding degree is directly assigned. As shown in Figure 3, the crowding degree of the ith feasible solution is set as the diagonal length of the smallest rectangle in which it sits.

Calculation of crowding degree.
Step 5. Archive the personal best position vector possessing individual extremum. In this evolution, the proposed algorithm sets the own current position vector of each particle as its personal best position vector, pBest, meanwhile the current fitness value of each particle is set as its individual extremum.
Step 6. Use the loop operation to search the optimal solution. First, update the velocity of each particle by the following formula
where w represents the inertia weight; Vel[i] and Pop[i] are the kinetic velocity vector and position vector of the ith particle in the space, respectively; r1 and r2 are the learning factors which are positive numbers from 0 to 1; and pBest[i] and gBest are the personal best position vector and the global best position vector, respectively. Update the position of the particles by the following formula
Deal with the particles beyond the boundary of search space. In this article, the position vector of each particle beyond its boundary is set as the corresponding boundary value. Then, the current particle velocity is multiplied by −1 to achieve the reverse movement. Evaluate the particles in the population. Update the global best position vector and the personal best position vector.


Under the premise that the number of successful mapping can be maximized, according to the fast non-dominated sorting method introduced in this article as well as the crowding degree comparison method, we update the current global best position vector and archive it. At the same time, the personal best position vector also needs to be updated

And for the update of personal best position vector, the algorithm follows a criterion here.
If the current solution is dominated by the solution in memory, we retain the solution in memory. Otherwise, we replace the solution in memory with the current solution. And if neither of them is dominated by the other, we randomly select either of them as the current personal best position vector.
5.In this article, using the Cauchy mutation method, we carry out the mutation operation on the global best position vector gBest. The specific process is as follows:
The average velocity of particles in the jth dimension in the population is

where Velij represents the kinematic velocity of the ith particle in the jth dimension, and AvgVelj∈ [−AvgVelmax, AvgVelmax]. In this article, the value of AvgVelmax is set as 1, and PopScale represents the population size.
The Cauchy mutation operation of the particles in the population is carried out according to the following formula

where Y is a constant which controls the step size of mutation, and C(0, 1) is a random number.
Then, the expression can be transformed into the form aiming at domain of definition (Popmin, Popmax) and average velocity AvgVelj in the process of solving the problem proposed in this article

Finally, based on the above content, we carry out the mutation operation on the global best position vector gBest. And the new solution gBestmut can be obtained by the following formula

where F is a random number and (Popmin, Popmax) is the domain of definition.
6. Comparing the new solution gBestmut and the global best position vector gBest, we choose the better one to update the archive and be the leader of the particle movement in the next iteration process until the maximum number of iterations is reached.
From the macroscopic point of view, the proposed LTBM algorithm in this article aims at using multi-domain to efficiently handle large-scale tasks in big data. In recent years, the large-scale task processing has been hindered by the constraints of resource type, location, and price, as well as the traditional task processing capability resulting from the feature of large volume, multiple data types, and high speed of data updating in big data. Herein, we choose the approach of multi-domain to handle the large-scale tasks. Tons of tasks can be processed in parallel by the cooperation of multi-domain. The problem of overload in case of using the previous single domain for task processing can be alleviated, so that it contributes to realizing the load balancing of domains and then makes the task processing more rapid and efficient. From a deeper point of view, in essence, the proposed approach is realized by optimizing two problems to be solved urgently which are the load balancing of domains and the minimization of bandwidth resource cost of the communication among domains simultaneously. On the one hand, in multi-domain environment, using the nodes with strong task handling abilities to share the tasks of the nodes with poor abilities can largely avoid the situation that the overload of a certain processing node or resource contention due to assigning tasks to each node according to some certain approaches. Therefore, it is beneficial to achieve load balancing and the increase in throughput of domains. On the other hand, in this work, we evaluate the bandwidth consumption of cross-domain task processing and decrease the unnecessary bandwidth resource consumption. The limited fixed bandwidth resource of domains can be effectively utilized, which contributes to ensure the efficient transmission of the data in the course of collaboration among domains. Thus, we can achieve the goal of seamless execution among multi-domain as well as completing tasks efficiently. Furthermore, the data migration due to the constraint of resource location and type has been avoided to some extent. The computing and transmission resource have been saved, which is conducive to the energy conservation.
The proposed LTBM algorithm conforms the multi-objective particle swarm optimization which is based on the Pareto dominance theory. It is mainly because we have found that each problem in the multi-objective optimization problem presented in this article will be individually optimized and the optimal solutions are obtained according to the respective objective functions. In other words, they will struggle to optimize themselves. Generally, it is difficult to find the optimal solution aiming at all the objectives, which is due to the inherent contradiction among the objectives. Therefore, the previous single-objective particle swarm optimization can hardly satisfy the needs of the multi-objective optimization problem in this work. However, for this multi-objective optimization problem, we have presented a novel method to quickly obtain the set of optimum virtual network mapping schemes based on a fast non-dominated selection method which can be used to archive the optimal solution set (Pareto optimal solution set). It considers that it needs to compare all the individuals with each other in the population and then divide them into several levels in some non-dominated sorting methods. The time complexity of algorithm comes to O (MN3). Herein, all the solutions in the population are compared with a partially filled population according to the dominance relation, and all non-dominated individuals can be kept in the Pareto optimal solution set. The time complexity of the algorithm is O (MN2) in the worst case that all the individuals in the original population are non-dominated individuals which means all non-dominated individuals are retained in the Pareto optimal solution set. It is obvious that the latter can make the population converge to the Pareto optimal solution more quickly and efficiently. Moreover, a crowding degree comparison method is designed and used to obtain the final unique optimal solution and guarantee the diversity of the population. By adopting distance as the evaluation index of the crowding degree of the solution and using the Euclidean distance, the crowding degree of each solution in the Pareto optimal solution set can be calculated. Since the greater the distance among the solutions, the more beneficial to obtain the optimal solution, the solution with greater potential to be the final unique solution can be selected. In the meanwhile, the greater the distance among the solutions, the more conducive to the uniform distribution of solutions. Thus, to a large extent, it can avoid the situation that the population gradually tends to form a small number of aggregates, which is called as genetic drift in genetics. Consequently, it provides guarantee for the population diversity of the algorithm.
On the whole, the LTBM algorithm also conforms the idea of heuristic algorithm. This is because the solution found by the heuristic algorithm after each iteration process may not be the optimal solution. It needs to be searched and corrected through several iterations to approach the optimal solution. And this process is consistent with the target of the proposed LTBM algorithm. On the one hand, we realize the load balancing using multi-domain to process large-scale tasks in big data. On the other hand, we also realize the minimization of the communication bandwidth cost of domains. Although the final result may not reach the optimal value of a certain single-objective optimization, the result obtained in this article is very close to the optimal value of the single-objective optimization in each aspect through the search by several iterations and much experimental demonstration. Considering the feature of the fast convergence of the particle swarm optimization, the Cauchy mutation method based on the Cauchy distribution is introduced to carry out the mutation operation in order to avoid the local optimal which will result in the slow convergence of the algorithm. In a certain probability condition, the local optimal solution which seems to be the final optimal solution is obtained in a certain iteration because of the fast convergence of the particle swarm algorithm. The local optimal solution may remain unchanged in the next several iterations, so that the algorithm converges prematurely, resulting in the failure of algorithm. The Cauchy mutation operation can ensure the search area for the optimal solution of the particle is large enough at the early stage of the iterations and break through the local optimum of the algorithm with a higher probability. It makes the particles quickly converge to the final unique optimal solution in the later stage of the iterations. Taking advantage of the process of multiple iterations of the proposed algorithm, eventually this article achieves the goal of using the cooperation of multiple domains to handle the large-scale tasks for big data.
Performance evaluation
We compare the proposed LTBM approach with the existing approaches based on first in, first out (FIFO), Fair Scheduler, and Capacity Scheduler, 27 respectively, which are used for the task scheduling and allocation in big data processing. Herein, we validate the performance of these approaches in the execution time, the load-balancing effect, the bandwidth resource cost, and the external service performance.
We employ the CloudSim for the simulation of multi-domain environment in this article. And the creation of processing nodes in multi-domain is based on the Hadoop 2.0 platform. In the Hadoop 2.0 platform, three domains which can coordinate to handle tasks with a certain number of task processing nodes in each domain are created, and these nodes have different available computing resource. A total of 36 batches of jobs with different resource requirements are created and each of them is divided into 180 different tasks at most. Hereupon, the tasks can be assigned to each working node in domains for processing according to certain approaches. The proposed LTBM approach can regularly monitor and obtain the computing resource utilization of the overall system. We explore and obtain the mean results by virtue of performing several tests in each of experiments.
Comparison in execution time
In this set of experiments, we compare the LTBM approach with FIFO, Fair Scheduler, and Capacity Scheduler in execution time. The experimental results are shown in Figure 4. We can observe that the execution time will increase with the number of tasks increasing gradually. For FIFO, with the increase in the number of tasks, the growth rate of execution time increases, which implies that the task processing efficiency becomes lower. With respect to Fair Scheduler and Capacity Scheduler, the resource contention among Map tasks and Reduce tasks in running may occur when a large number of tasks are being executed simultaneously in domains, which is generally regarded as a bottleneck in big data processing. The overall task processing efficiency is likely to decline. The execution time of LTBM will also gradually grow with the increase in the number of tasks, but still less than those of the other three approaches in the condition of the same number of tasks. It is mainly because the LTBM approach will obtain an optimal virtual network mapping scheme after each iteration and assign the tasks to be processed in the corresponding task processing nodes, which conduces to the efficiency improvement of the large-scale task processing to a certain extent.
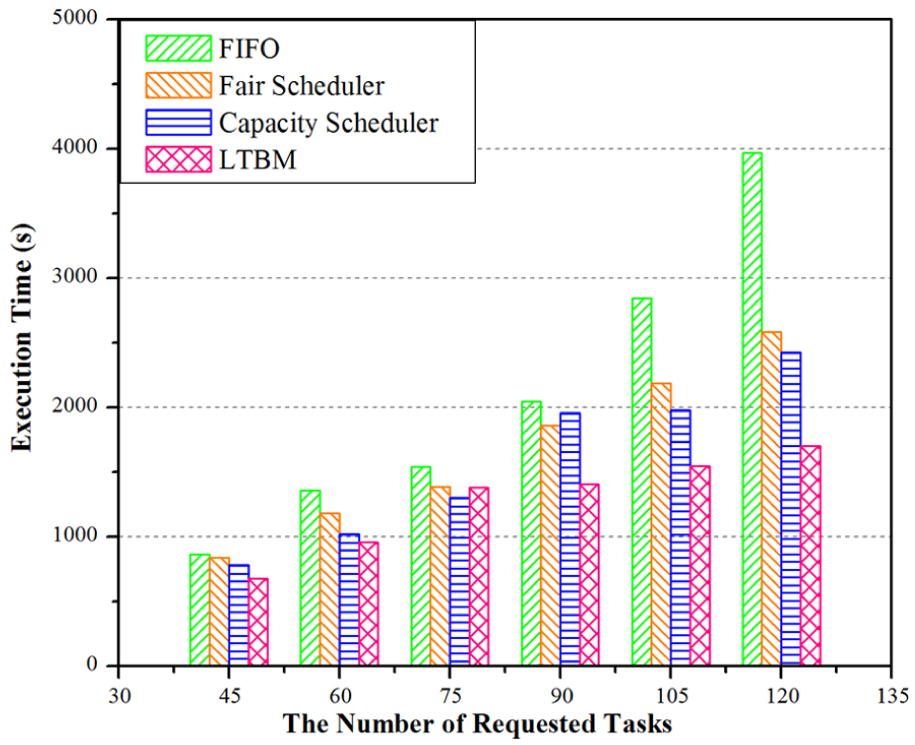
Comparison of LTBM with FIFO, Fair Scheduler, and Capacity Scheduler in execution time.
Comparison in load-balancing effect
In this section, we compare the performance of LTBM, FIFO, Fair Scheduler, and Capacity Scheduler in load-balancing effect. As shown in Figure 5, it can be observed that the standard deviation value of each approach gradually decreases with the change in time. The standard deviation value of FIFO is always higher than those of the other three approaches. And the load-balancing effect of LTBM approach is neck to neck with those of Fair Scheduler and Capacity Scheduler in the preliminary stage, and better than those of the latter two approaches in the later stage. This is mainly because the LTBM approach is able to simulate the particles in particle swarm optimization to take the global optimal position obtained from each iteration as the leader in the process of searching the optimal solution and quickly find the optimal virtual network mapping scheme in multi-domain, which conduces to searching proper task processing nodes for the corresponding tasks. It effectively guarantees resource utilization of the overall domains to a certain extent. On the whole, it can be observed that the LTBM approach possesses a decent performance in load balancing. It decreases the additional consumption of valuable computing resources and achieves the efficient processing of large-scale tasks, which improves the overall revenue of system in the long run.

Comparison of LTBM with FIFO, Fair Scheduler, and Capacity Scheduler in load-balancing effect.
Comparison in the bandwidth cost
In this scenario of experiments, we compare the performance of the above-mentioned approaches in the bandwidth resource cost in domains. As shown in Figure 6, we can observe that the FIFO approach makes less bandwidth resource cost in the early stage of the task processing. However, with the change in time, the bandwidth resource cost constantly increases. In the meanwhile, the bandwidth cost becomes higher than those of the other three approaches in the later phase. For Fair Scheduler and Capacity Scheduler, the bandwidth resource cost in domains is less in the preliminary stage, but greater than the cost of FIFO approach. When t = 500, the growth rate of bandwidth resource cost of the two approaches begin to decrease gradually, and the cost values become lower than that of FIFO in the later stage. With respect to the proposed LTBM approach, the bandwidth cost is neck to neck with those of the Fair Scheduler and Capacity Scheduler in the early stage and slightly lower in the latter stage. From the perspective of the economy of bandwidth resource for data communication in multi-domain, on the whole, the LTBM approach is slightly better than Fair Scheduler and Capacity Scheduler, although its effect is not as good as that of FIFO at first. The proposed LTBM approach is based on multi-objective combinatorial optimization, and it takes into consideration not only the economy of bandwidth resource for communication but also the load balancing in multi-domain. It has realized many optimization strategies proposed in this article and it can effectively converge to the Pareto optimal front end, besides the local optimum can be effectively avoided by employing Cauchy mutation. Compared to the other three approaches, the effect of LTBM on the bandwidth resource economy of the communication in domains is still decent. From a holistic perspective, based on the lower bandwidth cost of LTBM in the latter stage, we can consider that the LTBM approach is effective in the bandwidth resource economy for large-scale task processing among domains in the long run.
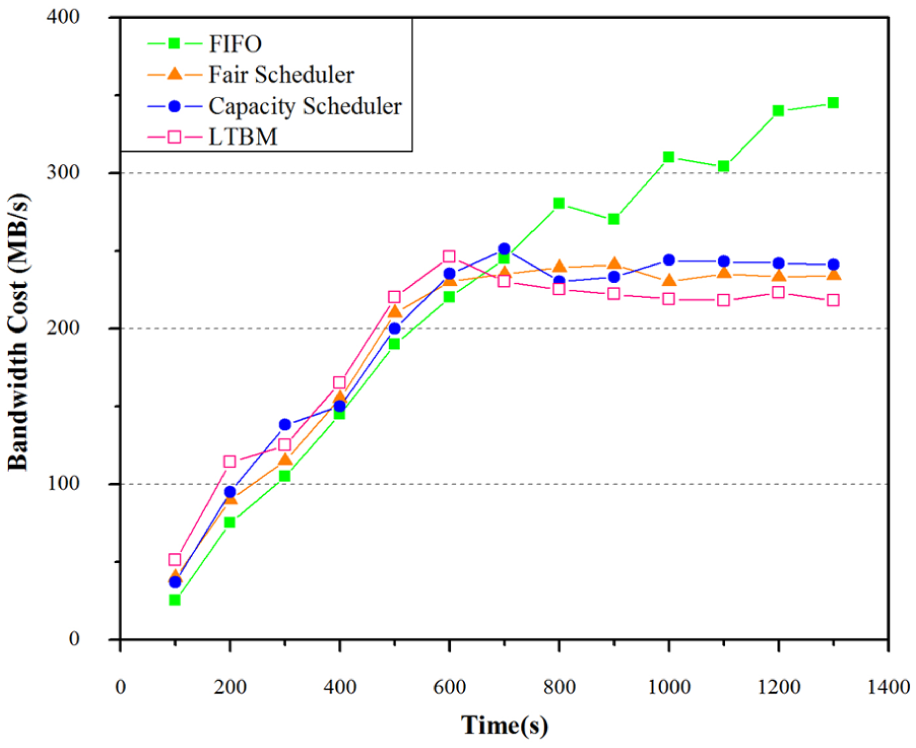
Comparison of LTBM with FIFO, Fair Scheduler, and Capacity Scheduler in the bandwidth resource cost.
Comparison in external service performance
In this section, the LTBM approach is compared with the other three approaches in the external service performance of the domains. Herein, the throughput is set as the evaluation criterion of external service performance of the system. This is because the throughput is generally regarded as the overall evaluation criterion of the capacity of processing data transmission requests for the system or its components. The relevant parameters of LTBM and other three approaches are set to the same values. As shown in Figure 7, the respective external service performance of each approach is different. For FIFO, the external service performance of the system seems to be relatively better in the early stage but instable later. With respect to Fair Scheduler and Capacity Scheduler, the throughput values are lower than those of the other two approaches in the beginning. With the change in time, the performance of system gradually becomes stabilized and slightly greater than that of LTBM. While the LTBM algorithm will allocate tasks reasonably, and its external service performance does not exceed those of the other three approaches in the early phase, with the increase in service time, its throughput value gradually tends to be stable and very close to those of Fair Scheduler and Capacity Scheduler in the later stage. Overall, we can draw the conclusion that the LTBM approach is relatively efficient and stable in the aspect of external service performance, which contributes to the high-efficient execution of large-scale tasks for big data processing.

Comparison of LTBM with FIFO, Fair Scheduler, and Capacity Scheduler in external service performance.
Conclusion and future work
This article has proposed a heuristic approach, LTBM, for processing large-scale tasks across multi-domain in big data. It realizes the multi-objective combinatorial optimization of the load balancing of the overall system and the minimization of the required bandwidth resource cost for the communication among domains. The proposed LTBM approach is a heuristic approach based on the particle swarm optimization and Pareto dominance theory. First, we present a novel and fast method to obtain the optimal solution set of the virtual network mapping schemes in this work, which is the Pareto optimal solution set in the algorithmic process. Then, the crowding degree comparison method is designed and utilized to select the final unique solution from the Pareto optimal solution set and guarantee the population diversity of the algorithm. Finally, the Cauchy mutation operation is introduced to avoid the local optimum, which contributes to improving performance of the algorithm. Hereupon, the final unique optimal solution has been obtained, which is the optimal virtual network mapping scheme. Experimental results demonstrate that the LTBM approach can quickly and efficiently achieve the task allocation as well as realize the load balancing and the minimization of bandwidth resource cost in multi-domain. The extra computing and bandwidth overheads have been effectively decreased. Moreover, the overall execution time of tasks has been shortened. It makes the overall system achieve a long-term benefit in big data analyzing and processing.
LTBM should be able to improve the capability of large-scale task processing by further optimizing the multi-objective problem proposed in this work. It is necessary to further explore the task processing by increasing the number of algorithm iterations in the future research since the selection of the maximum number of iterations is an open-ended problem. A larger scale of the experiments on the LTBM approach is also an important part of our next work. Besides, the large-scale task processing combined with deep learning and reinforcement learning for big data is an important research direction in the following work.
Footnotes
Handling Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Jilin Provincial Industrial Innovation Special Foundation Project (2017C028-4), the Jilin Provincial Education Office (the 13th Five-Year Plan Science and Technology Research Project 2016, no. 347), the Innovation Capacity Development Project (2018XJCQ035 and 2018XJCQ020) of Zhuhai College of Jilin University, the Zhuhai Premier Discipline Enhancement Scheme (2015YXXK02), and the Guangdong Premier Key-Discipline Enhancement Scheme (2016GDYSZDXK036).