
Abstract
Fault diagnosis for turnouts is crucial to the safety of railways. Existing studies on fault diagnosis depend on human experiences to select reference curves and require fault type information beforehand. Therefore, we proposed a turnout fault diagnosis method, named similarity function and fuzzy c-means based two-stage algorithm to detect faults and identify fault types in real time. First, the reference curve is selected from current curves representing turnout actions by K-means algorithm; then, a similarity function called Fréchet distance is used to distinguish normal and abnormal curves. Second, an improved fuzzy c-means algorithm is employed to cluster curves automatically. To be more specific, it can double-confirm the normal curves recognized in the first step as well as divide the abnormal curves into different types. Furthermore, possible causes for each fault type are inferred according to their curves. Our approach integrates fault detection and fault classification into one model and would better help the diagnosis of turnouts. The analysis results based on the similarity function and fuzzy c-means based two-stage algorithm algorithm indicate that the analyzed turnout fault types can be diagnosed automatically with high accuracy. Furthermore, since the proposed similarity function and fuzzy c-means algorithm does not need to know fault types in advance, it is applicable in identifying new fault types.
Keywords
Introduction
High-speed railway (HSR) has developed rapidly in China over the past several years, 1 and the operation and maintenance departments of HSR have faced an increasing requirement for transportation safety monitoring. 2 Meanwhile, many monitoring systems have put the emphasis on the reliability of turnouts 3 because turnouts are a crucial part for the safety of a whole railway network and 4 they are easier to be broken. First of all, the blades of turnouts hold a much weaker mechanical strength than regular rails do, and their mechanical properties are more likely to change. Any tiny transformation of blades might result in excessive forces on turning points or even derail a train. Second, turnouts are exposed in complex environments and unexpected accidents might happen, e.g., blades being stuck. Thus, the normal operation of the turnout is still a challenge.
A typical railway signal monitoring system works in two steps: first, it captures current values, which are produced by turnout movements, with an interval of 40 ms; second, it shows the captured current values in a current-time plane, which using time as the horizontal axis and current values as vertical axis. 5 Therefore, the curves can help to analyze turnout actions and attract most studies on fault diagnosis.6–8
Technically, fault diagnosis is different from fault detection. The former is not only to identify irregularities/faults from normalcies, but also to sort out different types of faults, while the latter is only to identify faults. Intelligent fault detections and diagnoses for turnouts have attracted many researchers. Huang et al. 9 developed an intelligent diagnosis method for railway turnout using dynamic time warping. Atamuradov et al. 10 utilized expert systems to conduct turnout fault diagnosis. Wang et al. 11 presented a failure prediction model based on Bayesian network to evaluate the effect of weather on railway turnouts. Vileiniskis et al. 12 presented a one-class support vector machine classification to predict possible failures in the system. Asada and Roberts 13 utilized wavelet transforms and support vector machines to realize turnout fault detection and diagnosis. Kim et al. 14 proposed a fault detection method based on dynamic time warping for railway point machines. Ross 15 designed a monofocal camera–based fault detection for turnouts. J Lee et al. 16 presented a data mining solution that utilized audio data to efficiently detect and diagnose railway faults. Zhao et al. 17 applied gray theory to turnout fault diagnosis.
Although the above studies are elegant, there is still some room for improvement. First of all, they all require a training set with labels and known curves as well as failure types as references. 18 However, all the labels, the optimal reference curves and reasonable fault types are determined based on human experiences, which means the accuracy of fault diagnosis has to entirely depend on the most unstable and complicated factor. Furthermore, turnout actions are affected by complex factors, like locations, weather, and working hours; therefore, its normal actions are not fixed and may slightly change, and new types of faults may emerge. Nevertheless, the above research cannot update their reference curves and fault types in real time. Third, when a new fault type emerges, chances are high that it cannot be recognized if a reference curve has not been known beforehand.
Therefore, we present similarity function and fuzzy c-means based two-stage (SF-FCM-TS) algorithm, a fault diagnosis method, to select the reference curves independently from human aid and to identify new fault types without prior information.
Methodology
SF-FCM-TS consists of two stages: fault detection and then clustering and verification. Fault detection in SF-FCM-TS works in this way: first, the reference curve is selected by K-means algorithm from a bunch of none-label curves, which were obtained from field turnout action monitoring systems. Second, the similarity between sample curves and the reference curve is calculated based on the Fréchet distance. Finally, a reasonable threshold for fault is determined.
In the second stage, an improved fuzzy c-means (FCM) algorithm is proposed to cluster sample curves automatically and identify fault types. Furthermore, it verifies the selection of the reference curve and the accuracy of fault detection in the first stage.
These two stages are integrated into one model and the second stage also serves as a double check for the first stage. Sample curves are divided into the normal and the abnormal categories in the first stage. In the second stage, the normal ones are confirmed and the abnormal ones are divided into different types. The workflow of the proposed approach is shown in Figure 1.

Similarity function and fuzzy c-means based two-stage algorithm.
The first stage—fault detection
Since turnouts work normally most of the time, we assume that the majority of curves of a certain turnout are normal within a certain period of time. Fault detection in SF-FCM-TS includes three steps: selecting a reference curve, calculating similarities, and determining fault threshold.
Selecting reference curve
Three steps are designated to ensure the final selected reference curve is representative and standard: pretreatment, point analysis, and line analysis.
Pretreatment
Pretreatment is to select those curves which contain the highest number of repetitious sampling time points.
The set of original test curves consists of n curves denoted as


H is the number of sampling time points of each curve in
U represents the highest repetition number in H. If

Point analysis
Point analysis aims to obtain the clustering center of each sampling time point by K-means algorithm.
The current value of each sampling time point is denoted as C

where
The set of sampling time points is denoted as

And the set of the jth sampling time point

Then, the clustering centers of sampling time points are denoted as

where

Figure 2 illustrates how to obtain clustering center

Process of obtaining clustering center
Then, the intervals of the clustering centers can be denoted as

where

where
Line analysis
Line analysis is to figure out the number of clustering centers involved in each curve, therefore to identify the representation for each curve.
Suppose curve li is

where

where
Calculating similarity
The Fréchet distance
Distance space, also known as the Fréchet distance, is first proposed by Maurice Fréchet, a French mathematician, in 1906. It extends the concept of distance in real world to general set, providing a theoretical base for measuring distances between abstract spaces.
Suppose

and

are two planar curves, and ∥·∥ the Euclidean norm. Then the Fréchet distance
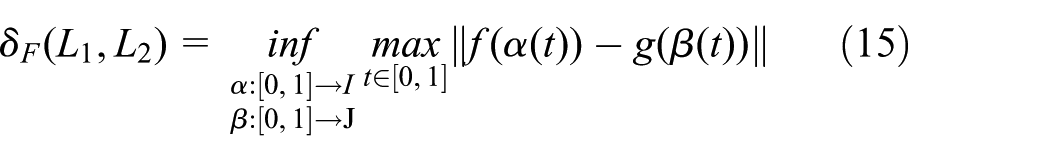
where
We adopt the discrete Fréchet distance, for the convenience of digital processing. Thus, the distance between curves
Step 1: The first curve

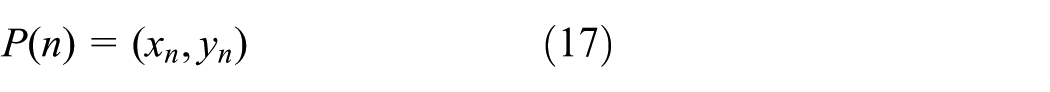
where n is the number of the sampling points and
Step 2: The second


where m is the number of the sampling points and
Step 3: The Euclidean distance D between the sampling points

where

is the Euclidean distance between the mth sampling point of
Step 4: The maximum value of D is denoted as

Step 5: In equation (20), if

where
Step 6: A set

is constructed with the limit of

where
Step 7: If the construction of R fails, let
Step 8: The discrete Fréchet distance between

Similarity between normal curves and the reference curve

Therefore, the similarity between the sample curves and the reference curve

where
Determining threshold
Few fault curves may still stay in the sample curves and each of them may contain the same number of sampling points as the reference curve does. However, these possible fault curves are far less similar with the reference curve than other normal curves. Therefore, the especially small ones in S are removed, and the minimum of the rest is denoted as

where k is the adjustment factor set based on actual condition. Here, we set k as 0.95.
The threshold
The second stage—clustering and verification
Data preprocessing
Data preprocessing includes data normalization and data dimensionality reduction. Since different turnouts’ movements may last differently, curve lengths are different, and a single curve may contain hundreds of data points, leading to a large data dimension and poor clustering results. Therefore, the original data need to be normalized so that each curve could contain the same number of data points. The normalization is performed as follows:
Step 1: Construct H as described in equation (2). And assign each curve a vector of its data, that is, N curves, N vectors.
Step 2: Compare each
Step 3: Subtract the average of a certain curve from each data value in the curve.
After normalization, principal component analysis (PCA) is used to reduce the dimension.
FCM algorithm
Fuzzy c-means (FCM) algorithm is a kind of cluster analysis. Cluster analysis, or clustering, is the process of categorizing a set of objects so that objects in the same category, or cluster, are more similar in certain aspects to each other than to those in other clusters. Clustering is known as unsupervised learning since no labeling information is required.
FCM algorithm was developed by JC Dunn 20 and improved by JC Bezdek. 21 The basic idea of FCM algorithm is to update the clustering center and membership degree matrix repeatedly 22 until the objective function achieves the minimum value. Thus, the data classification is completed based on the maximum membership degree principle.
FCM aims to minimize an objective function 23

where m is any real number greater than 1 and usually set as 2;
Equation (30) is constrained by

Equation (31) is substituted into equation (30) by Lagrange multiplier method and then the partial derivative is calculated. The cluster center

The

The FCM algorithm follows next steps:
Step 1: Determine the number of the clusters (c). Initialize m,
Step 2: At i-step, calculate
Step 3: Update
Step 4: If
Improved FCM algorithm
Basic FCM algorithm cannot determine the number of the clusters automatically. Therefore, Silhouette_Score (SS), the mean Silhouette Coefficient of all samples, is adopted to measure the clustering effects. The Silhouette_Score for each sample is calculated as
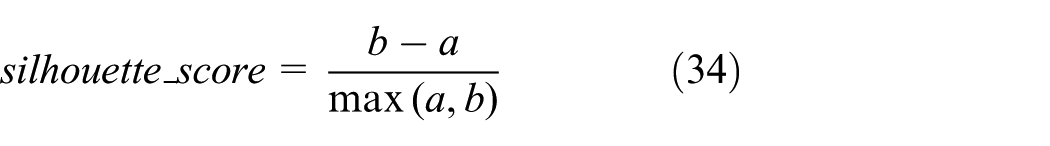
where a is the mean intra-cluster distance and b the mean nearest-cluster distance, 24 a distance between a sample and its nearest neighbor cluster. The larger the value of SS, the better the clustering effect. Therefore, when SS achieves max, the corresponding number of clusters is the optimal. Figure 3 illustrates the workflow of finding the optimal number using the improved FCM algorithm.

Improved FCM algorithm flowchart.
Verification and classification
The second stage involves Verification and Classification.
First, the normal curves selected in the first stage are clustered by FCM algorithm. If they all fall into the same cluster, that is, they are all normal; the reference curve selected in the first stage is verified.
Second, the abnormal curves classified in the first stage are also clustered by FCM algorithm, and different types of faults can be obtained. And the reason for each type of fault can be analyzed consequently.
Application
Testing data
We chose ZD6 turnout’s data for our application and validation of the proposed methodology, considering its wide application. And the turnout’s data were gleaned in the Jinan Railway Station from 12 December 2017 to 10 January 2018. It is a total of 817 curves of four turnouts.
Testing results
We selected 70% of the 817 curves gleaned in the Jinan Railway Station from 12 December 2017 to 10 January 2018, that is 572, as test curves and kept the rest 30% for verification. We used MATLAB 2014 to implement the application in first stage and we used python 3.5 to implement the application in second stage.
Fault detection
First, we conducted pretreatment on the test curves and obtained the distribution of the number of sampling time points of each curve, as shown in Figure 4. The most repetitious number of sampling time points was 236. Thus, we selected 109 curves for test form the total sample, whose sample size was 236. The rest curves were used for later analysis.

Distribution of the number of sampling points.
Second, we utilized the K-means algorithm to calculate clustering centers of each of the 236 sampling time point. For example, the clustering center of the 15th sampling time point was 1.949, as the interval radius
Then we counted the number of clustering centers of each sample curve, as exhibited in Figure 5. The 52-th curve held the largest number of clustering centers, 75, which means the 52-th curve was the most representative and selected as the reference curve.
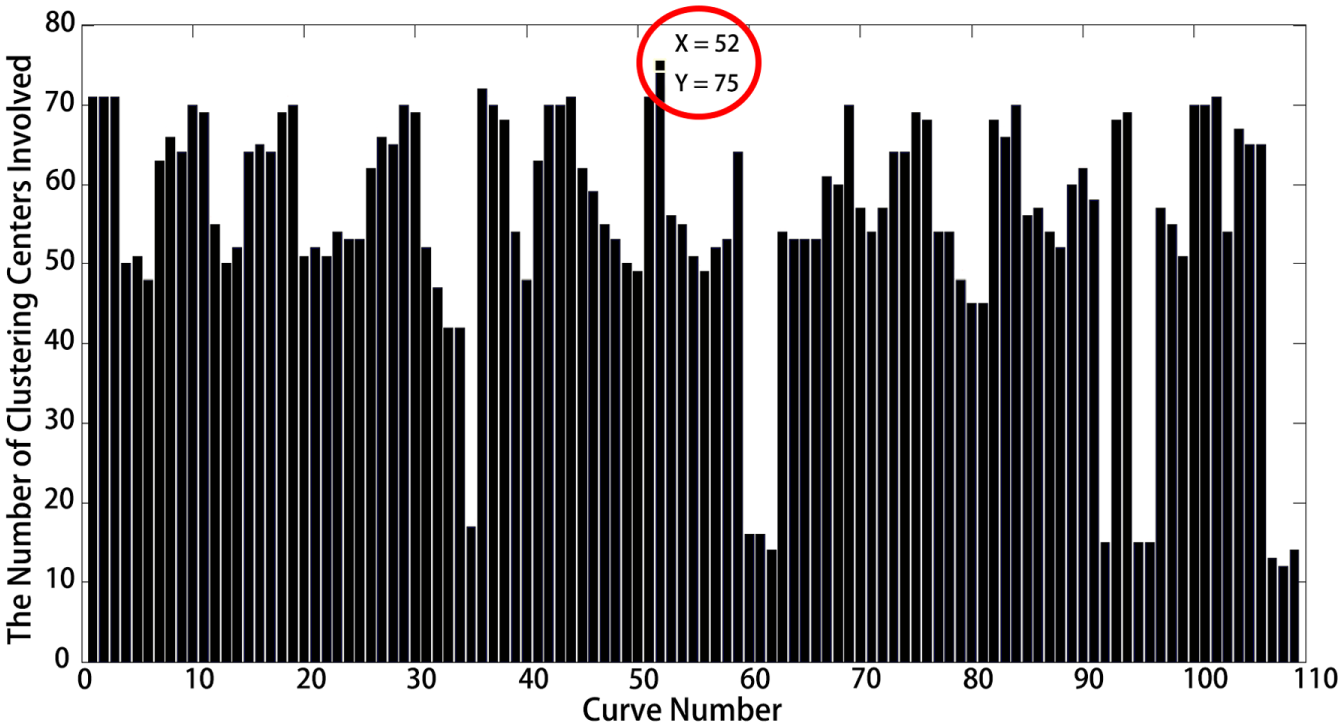
Number of clustering centers included in each curve.
Figure 6 depicts the reference curve, that is, the 52-th curve.

Reference curve.
The reference curve can be split into four phases 25 according to typical movements of turnouts:
Unlocking (t0–t1): motor starts with large current value and torque, and the current rises rapidly.
Conversion (t1–t2): the turnout moves smoothly, and so does the current.
Locking (t2–t3): the switch rail moves to the other side until it is close enough to the stock rail when the current reduces to zero.
Slow-releasing (t3–t4): the relay releases slowly and the current remains zero.
Third, there were 108 sample curves, except the 52-th reference curve. And we calculated the similarity between each individual sample curve and the reference curve, based on the Fréchet distance, as shown in Figure 7. All the similarities fell within the range of [3.8, 4.1] and the minimum similarity


Similarity between the normal curves and the reference curve.
Finally, we calculated the similarity between the reference curve and each individual of the total 571 test curves, including 108 sample curves, and compared each result with the threshold
Fault diagnosis
Classification Step
First, we normalized the dimension of each abnormal curves selected in the first stage as 200 and reduced it to 4 using PCA. The whole process is illustrated in Figure 8.

Normalization and reduction of curve’s dimension.
Second, we run the loop function shown in Figure 3 to find the optimal number of clusters. As shown in Figure 9, SS first dropped when k changed to 4; thus, the optimal number was set as 3.
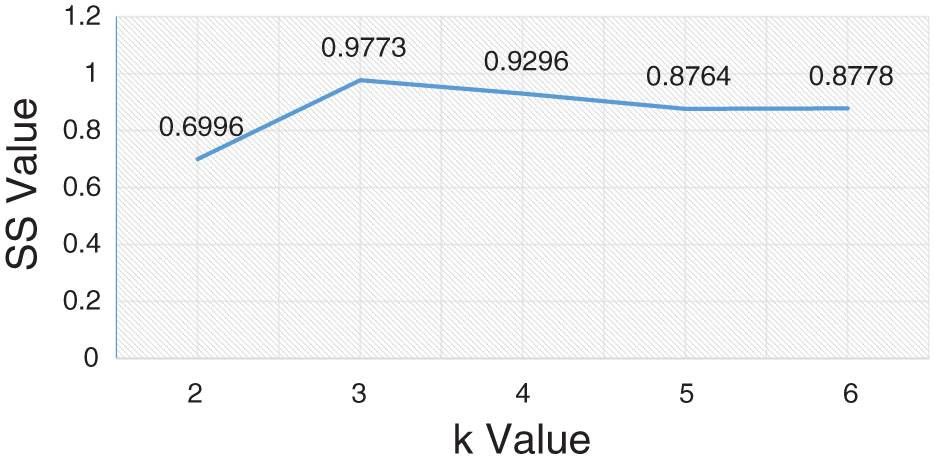
Value of SS (Classification Step).
Then we obtained the results of clustering curves (Figure 10) and their corresponding original ones (Figure 11).
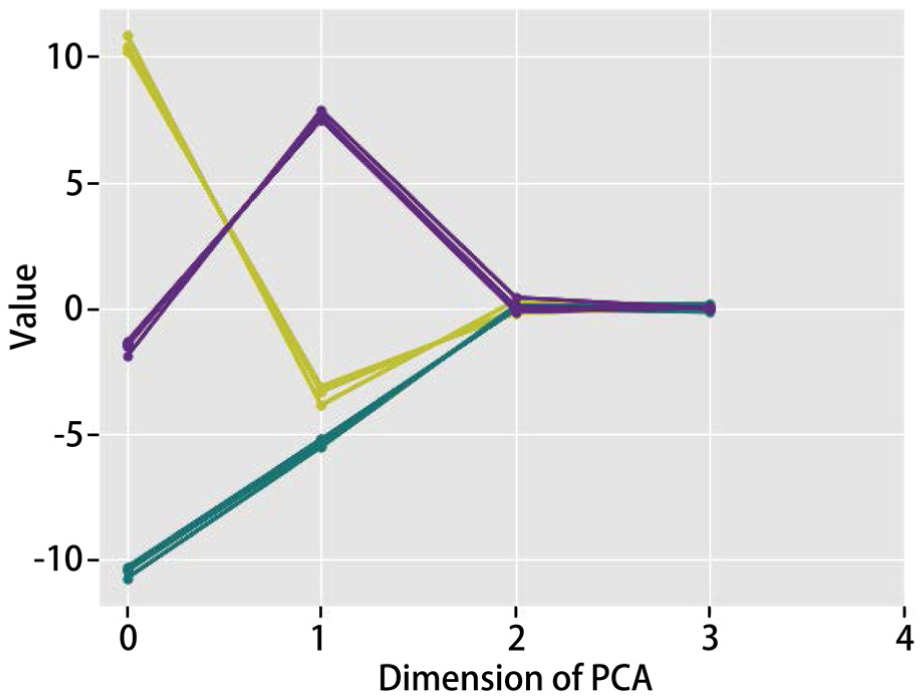
Clustering results (Classification Step).
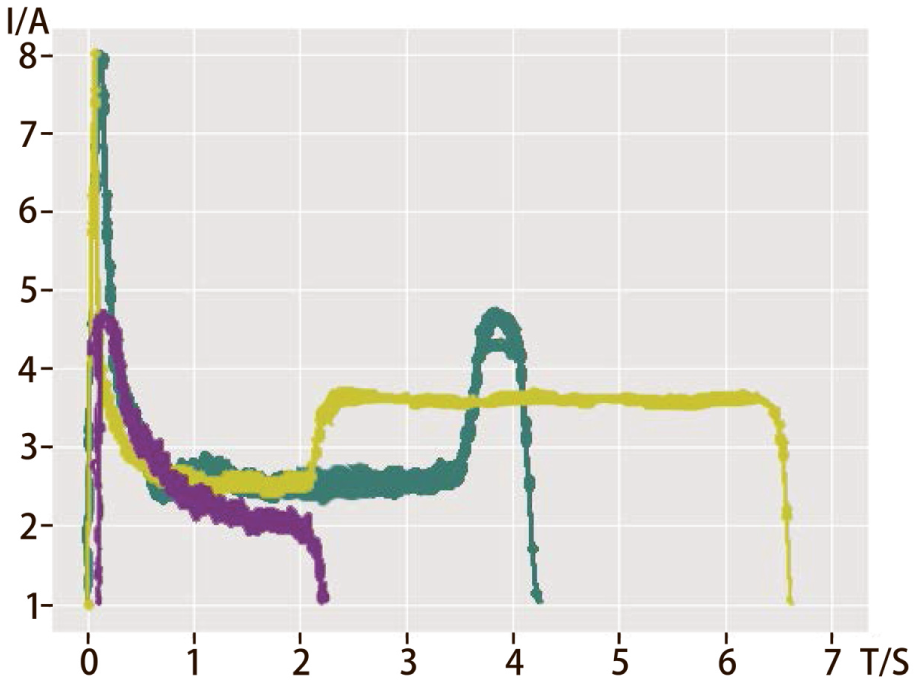
Corresponding curves of the clustering results (Classification Step).
These clusters, type green, type yellow, and type purple, were determined to be abnormal, but each of them held its unique feature, as analyzed below:
1. Type GREEN
In Type GREEN curve (Figure 12), the current rises sharply in the locking stage, possibly caused by an excessively tight turnout.

Type GREEN curve.
2. Type YELLOW
Type YELLOW curve exhibits a longer locking line and higher current values, as depicted in Figure 13, possibly because that the automatic actuator is not flexible.

Type YELLOW curve.
3. Type PURPLE
In Type PURPLE curve, the conversion time lasts shorter and the locking line does not even exist, as shown in Figure 14. The reason may lie in a sudden stop of the turnout’s movement.

Type PURPLE curve.
Verification Step
Considering that the value of SS cannot be calculated when k = 1, we added a default set of curves in Verification Step. In this default set of curves, each curve has 200 sampling time points and the value of each sampling time points is −1. Obviously, when the normal curves and the default curves were clustered by FCM algorithm, if the number of clusters is two and only the normal curves selected in the first stage all fall into the same cluster, that is, they are all normal, the normal curves selected in the first stage is verified.
First, as Classification Step, we normalized the dimension of each normal curves and the default curves as 200, and reduced it to 4 using PCA. Second, we run the loop function shown in Figure 3 to find the optimal number of clusters. As shown in Figure 15, SS has been decreasing from k = 2 to k = 5; thus, the optimal number of clusters was set as 2.

Value of SS (Verification Step).
Then, we obtained the results of clustering curves (Figure 16) and the corresponding original normal curves, the Type ORANGE curves (Figure 17).

Clustering results (Verification Step).

Type ORANGE curve.
Finally, by contrast, we found that the number and the serial number of each Type ORANGE curves obtained by our fault diagnosis method in Classification Step were exactly the same as those obtained by our fault detection method, which verified the reasonability of the reference curve and the accuracy of the previous fault detection.
Verification
We also calculated the similarity between the reference curve and each of the left 245 curves, 30% of the original 817 curves gleaned in the Jinan Railway Station from 12 December 2017 to 10 January 2018, and got 216 normal ones and 29 abnormal ones.
Then we clustered the 216 normal curves using the reference curve and the results indicated that all of them belonged to the same cluster, which verified the accuracy of the previous fault detection.
Finally, we clustered the 29 abnormal curves using the central curves of the three types of fault curves and obtained 13 of type green, 10 of type yellow, and 9 of type purple, which was also identical to the fault type in test samples.
Furthermore, our fault diagnosis method can identify new type of fault, when the number of clusters grows during clustering. And it can be applied to a real-time fault diagnosis system. For example, if a single curve is input, it will be added to the test curves and processed with them throughout the complete workflow.
Results and discussions
Finally, we got a bunch of normal curves and three types of fault curves. Not surprisingly, the similarity between each of the normal curve and the reference curve was larger than the threshold
Moreover, the results imply other advantages of our SF-FCM-TS. First of all, fault type does not need to be known in advance. Second, new type of fault can be identified along with fault classification and diagnosis.
Conclusion
In this study, we proposed a turnout fault diagnosis method named SF-FCM-TS algorithm based on similarity function and improved FCM algorithm. The approach works in two stages. First, it automatically selects a reference curve and cluster abnormal curves based on the similarity of curve features. Second, it utilizes the improved FCM algorithm to verify the reasonability of the selection of the reference curve and the accuracy of fault detection in the first stage.
Our approach is independent from human experiences and can determine reference curve and fault types in real time. Even if the turnout action current curve changes slightly with location, weather, and working hours, the turnout fault can still be diagnosed. Also, the accuracy of fault detection is double-checked in the second stage, which will further enhance the safety of railway operation.
The proposed method can identify new fault types along with the clustering. And the introduction of Silhouette_Score to the fundamental FCM can directly provide the number of clusters. Therefore, our approach is fairly effective.
Furthermore, the proposed method is applicable to all types of turnouts as long as the action curves of the turnout can be obtained. Therefore, the applicability of this method is good.
We will focus on increasing effectiveness by trying other algorithms to define the similarity and by improving the FCM algorithm. In addition, we are exploring the robustness evaluation of the proposed method when weather or other transient conditions change.
Footnotes
Acknowledgements
The authors are grateful for the reviewers’ helpful comments and suggestions.
Handling Editor: Sunday Ojolo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Key R&D Program of China (2016YFB1200402) and the National Natural Science Foundation of China (61703308).