
Abstract
The purpose of this article is to improve the convergence efficiency of the traditional efficient global optimization method. Furthermore, we try a graphics processing unit–based parallel computing method to improve the computing efficiency of the efficient global optimization method for both mathematical and practical engineering problems. First, we propose a multiple-data-based efficient global optimization algorithm instead of the multiple-surrogates-based efficient global optimization algorithm. Second, a novel graphics processing unit–based general-purpose computing technology is adopted to accelerate the solution efficiency of our multiple-data-based efficient global optimization algorithm. Third, a hybrid parallel computing approach using the OpenMP and compute unified device architecture is adopted to further improve the solution efficiency of forward problems in practical application. This is accomplished by integrating the graphics processing unit–based finite element method numerical analysis system into the optimization software. The numerical results show that for the same problem, the optimal result of the multiple-data-based efficient global optimization algorithm is consistently better than the multiple-surrogates-based efficient global optimization algorithm with the same optimization iterations. In addition, the graphics processing unit–based parallel simulation system helps in the reduction of the calculation time for practical engineering problems. The multiple-data-based efficient global optimization method performs stably in both high-order mathematical functions and large-scale nonlinear practical engineering optimization problems. An added benefit is that the computational time and accuracy are no longer obstacles.
Keywords
Introduction
Currently, optimization design is widely used in the automotive industry to optimize production or to test the behavior of the product before a prototype is built or real-life tests are performed.1,2 However, since a number of function evaluations are repeatedly performed, a practical engineering optimization is time-consuming. Therefore, a surrogate-based optimization (SBO) algorithm has been suggested as an effective approach for designs using time-consuming models. Within SBO, an iterative process that involves the creation, optimization, and updating of a fast and analytically tractable surrogate model is proposed to replace the direct optimization of the computationally expensive model.3,4 The surrogate model is used to visualize input–output relationships, search for an optimum candidate, and finally to analyze the improved design. 5 The common surrogate models include response surfaces, 6 Kriging,7,8 support vector machines, 9 and space mapping. 10 For the automobile industry, various kinds of surrogate models are widely applied to the structural and parameter optimization of the sheet-metal forming process11,12 and crash-safety design. 13 This article focuses on a modern SBO methodology called the efficient global optimization (EGO) algorithm, which is proposed by Jones et al. 14 The EGO algorithm favors high convergence efficiency for global optimization by using both estimated prediction and estimated uncertainty to provide the next sampling point. It is especially good for nonlinear, multimodal functions that often occur in industrial applications. Since more robust and accurate approximation can be achieved by the use of an ensemble of surrogates, a multiple-surrogate efficient global optimization (MSEGO) algorithm is presented. 15 This algorithm adds several design points per optimization cycle and is benefitted by the use of multiple surrogates. Numerical results show that the MSEGO algorithm can reduce the number of iterations required for convergence, thus reducing the number of function evaluations. 15 Unfortunately, since the best surrogate of most black-box problems is not known beforehand, the ensemble of surrogates is necessary to extract more information from the data to ensure its robustness. However, several surrogates, such as the support vector machine (SVM) and radial basis neural network (RBNN), will consume more resources than the Kriging model. It is also difficult to choose suitable surrogates to generate diversity, although some selection strategies have been presented, and the results may become even worse in some cases when the number of surrogates increases. 4 In this article, we propose a multiple-data-based efficient global optimization (MDEGO) algorithm, using a set of multiple data to generate diversity. The MDEGO algorithm uses multiple data to replace multiple surrogates by adding several infill points in each optimization cycle, and it suggests that the multiple data come from the globally sampled data. Compared with the multiple surrogates method, multiple data is easier to obtain by simply choosing a subset of optimization according to a special selection strategy. Furthermore, the multiple-data strategy is well suited for parallel computing.
In recent years, graphics processing units (GPUs) have become a novel parallel tool since they offer a tremendous amount of computing resources not only for graphics processes but also for general-purpose parallel computations.16,17 Actually, one of the promising trends in the field of parallel global optimization is the use of GPUs to enhance the speed of computation. 18 For example, Barkalov et al. 19 presented a parallel global optimization algorithm combined with a dimension reduction scheme. Of course there are many other GPU-based parallel global optimization algorithms, including the fine-grained parallel particle-swarm optimization method, 20 the genetic algorithm, 21 the differential evolution algorithm, 22 shuffled complex evolution method developed at The University of Arizona (SCE-UA) method, 23 and the simulated annealing algorithm. 24 Furthermore, a review of modern methods of parallel global optimization can be found in the work of D’Apuzzo et al. 25 On the other hand, GPU is widely used to accelerate the implementations of finite element (FE) applications, including Monte Carlo simulation, 26 dynamic explicit FE analysis, 27 electromagnetic analysis, 28 and so on. Based on these studies, the parallel computing approach has been studied to improve the computing efficiency of optimal design based on the MDEGO algorithm.
The rest of this work is structured as follows. In section “EGO algorithm,” the EGO method is briefly reviewed. In section “General-purpose computing on GPU,” the general-purpose computing by GPU is briefly introduced. The MDEGO algorithm based on multiple data and its parallel implementation are presented in section “MDEGO and its parallel implementation.” In section “Numerical examples,” some numerical examples are given to demonstrate the effectiveness and efficiency of the MDEGO algorithm. Section “Conclusion” offers some conclusions and discusses some remaining challenges and opportunities.
EGO algorithm
In the context of the EGO algorithm, the response function can be expressed as the sum of two terms

where b(

where
According to the Kriging model, the response value

where
The Kriging prediction variance can also be estimated and should be minimized in order to obtain a good approximation
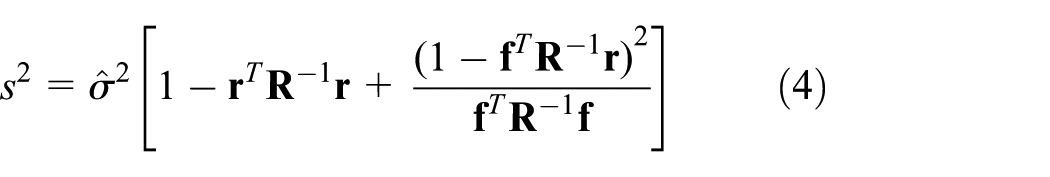
where
EGO iteratively adds points to the data set in order to obtain an improvement for the current best function value

The expression is a random variable, since the response function y(

In the above,
General-purpose computing on GPU
Driven by the insatiable market demand for real-time, high-definition three-dimensional (3D) graphics, the programmable GPU is designed as a parallel device with single-instruction multiple-data (SIMD) classification, which is well suited for problems that can be expressed as data-parallel computations with high arithmetic intensity. The compute unified device architecture (CUDA) is hardware and software architecture for issuing and managing computations on the GPU. CUDA allows developers to use C as a high-level programming language.
A typical GPU computing platform based on a normal personal computer is shown in Figure 1. It mainly includes an arbitrary central processing unit (CPU) and one or more CUDA-enabled GPUs. Generally, the CPU hands the performance of parallelizable computations in applications off to the GPUs. In order to implement a parallel code on GPU with CUDA, usually four steps are needed. 29 First, initial works including memory space allocation should be done on host; second, the input data should be translated from host to device; third, the kernels are executed on GPU by streaming multiprocessors (SMs); and finally, translate the output data from device to host.
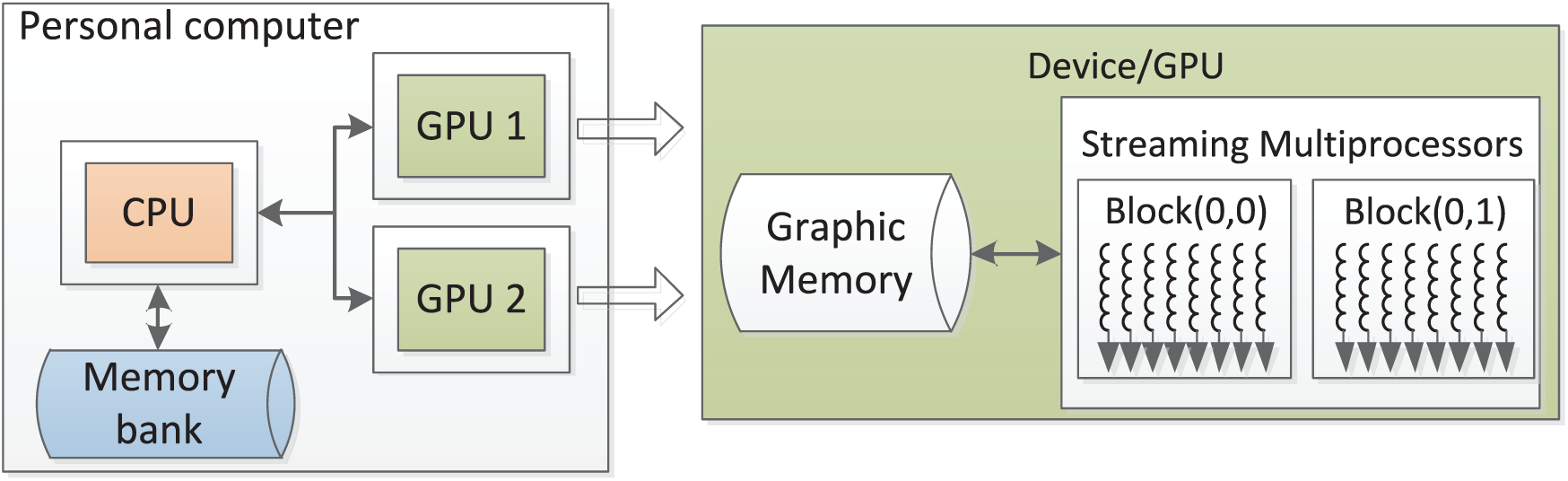
GPU-based general-purpose computing platform.
By means of SIMD, the most common approach to realize GPU parallel computing is to decompose a problem into well-defined, thread-level work units. In CUDA, kernels are for the computing subroutines with parallel computing code, which will be concurrently performed by many CUDA threads. As shown in Figure 1, all CUDA threads are divided into three levels for management, namely threads, blocks, and grids. The threads in one block can communicate and synchronize with each other by synchronization functions. Furthermore, a multiple-levels device memory system is constructed to fully use the memory bandwidth. First, all CUDA threads can access a same global memory space. Second, threads in one block can share data through a special shared memory. Third, each thread has a private local memory and a set of registers, which provide high access speed.
Although CUDA itself is a C language environment, it is designed to work with programming languages such as Fortran, 30 Python, 31 Ruby, 32 and so on. In addition, MATLAB"s Parallel Computing Toolkit (PCT) supports GPU computing from the r2014 release, which makes it easier for developers to use GPUs to accelerate their applications than using C or Fortran. More than 100 built-in MATLAB functions can be directly parallel-performed on a GPU by providing an input argument of the type GPUArray, a special array type provided by PCT. 33 Furthermore, the MEX compiler in MATLAB allows software developers to call CUDA-based parallel computing libraries in MATLAB functions.
Furthermore, in order to improve the computational efficiency of the code, there are many manuals for reference, including the official guide 34 and the corresponding literature.35,36
MDEGO and its parallel implementation
Concept and basic flow
Instead of the use of multiple surrogates, the MDEGO algorithm uses multiple data to provide diversity. As shown in Figure 2, it starts by sampling the initial points employing the design of experiments (DOE) technique like the Latin hypercube
37
function lhsdesign in MATLAB. The set of initial points is then evaluated sequentially to obtain an initial data set (

Flowchart of the MDEGO algorithm.
Extraction strategy of sub-data
In the MDEGO algorithm, the extraction strategy of the sub-data is improved to be suitable for multiple data. In detail, with the MDEGO algorithm, given the initial global data set (

where
Selection strategy of infill points
In the context of the MDEGO algorithm, each sub-data is fitted by a Kriging model, and one infill point is provided by maximizing the expected improvement. The information about the distance between the infill point and the existing points is used by the selection criterion, determining whether the infill point will be added to the original global data or sub-data for the next optimization cycle. If the distance is greater than a small tolerance

where dim denotes the dimension of the design variable and

Selection strategy: (a) selection strategy for sub-data and (b) selection strategy for global data.
Parameters for selection strategy.

For simplicity, in this article, the value of the small tolerance
Accelerated MDEGO algorithm by parallel computing
According to the above analyses, we found that the MDEGO algorithm can achieve better results than the original MSEGO algorithm. However, it still has potential drawbacks that must be improved, especially for high-order and large-scale problems in practical applications. Since parallel computing is increasingly used in modern simulations, research on the parallel computing scheme of the MDEGO algorithm is further considered.
GPU-based parallel multi-data strategy
As mentioned above, parallelizability is a major advantage of this algorithm. For example, to a large extent, extracting and updating different sub-data can be performed independently of each other, so these calculations can be easily conducted in parallel by mapping sub-data to CUDA thread with a one-to-one relationship. That is, a CUDA thread performs a calculation of sub-data. For example, the GTX970 series GPUs used in this work have 1664 CUDA cores and can execute 1664 CUDA threads concurrently. Therefore, theoretically, 1664 sub-data can be calculated at the same time. The parallelisms of the multi-data used for our MDEGO algorithm are described as follows.
Step 1: Parallel-extract multiple sub-data
Step 2: Parallel-fit a Kriging model for each sub-data
Step 3: Parallel-update each
Step 4: The host CPU updates the global data set by the set of new points if these points do not superpose any existing points within the global data.
Step 5: Repeat steps 1–4 until the maximum number of optimization cycles is achieved.
Since a modern CUDA-enabled GPU usually contains more than 1000 CUDA cores, this fine-grained parallelism could apply to most high-order and large-scale problems.
Parallel computing of forward problems
The efficiency and stability of forward problems are important in practical engineering optimum design. Therefore, two kinds of parallel computing strategy are presented in this article to shorten the time of calculation of direct problems.
First, for function optimization problems, the direct problems can be easily expressed as data-parallel computations, and the computational granularity is small enough for GPU-based fine-grain parallel computing. As shown in Figure 4, the parallel strategy is to map the response values of direct problems to parallel processing threads, one by one, and then one CUDA thread is assigned to calculate one response value.
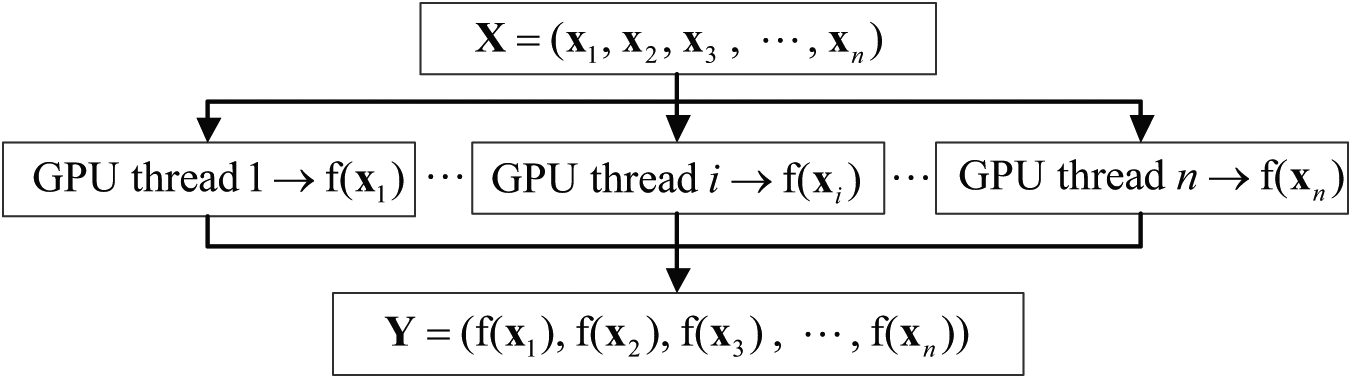
Parallel computing of repose values based on GPU.
Furthermore, a special dynamic parallel computing method is proposed for complex polynomial functions. Take a D-dimensional function for example and let the number of initial data be
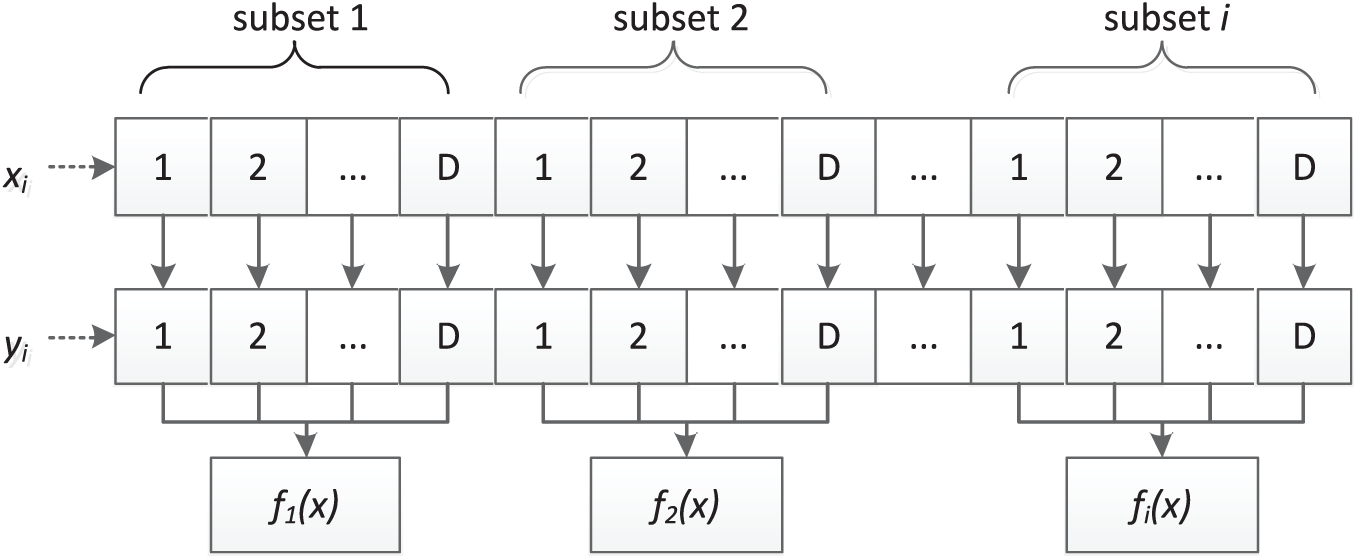
Dynamic parallel computing of a high-dimension function.
Second, the practical optimization problems usually involve many repeated full FE analyses, and the simple GPU thread-level parallelism is no longer applicable. Therefore, this article involves a hybrid parallel computing approach using open multi-processing (OpenMP) and GPU. This hybrid approach contains two stages. The first stage is the multithreads parallel computing based on a multi-core CPU using OpenMP. In other words, all of one core of a multi-core CPU is proposed for the solution of one subset, and therefore, all subsets can be solved in parallel. This parallel computing is very easy to realize. We only need to invoke subroutine calls from OpenMP thread libraries and insert the OpenMP compiler directives. 39 However, a simple OpenMP-based parallel computing is not powerful enough to clearly improve the performance of FE analysis. Therefore, a series of GPU-based parallel FE simulation systems are introduced as the second stage. These high-efficiency simulation systems include intellectual property rights and involve many fields of solid mechanics.17,29,40 All in all, this hybrid parallel strategy uses one OpenMP thread to calculate one subset and control one GPU to solve one forward problem.
Flowchart of the parallel MDEGO algorithm
In this section, the flowchart of the parallel MDEGO scheme is illustrated in Figure 6. The evaluations are performed by hybrid parallel strategy with one GPU assigned to accelerate one FE analysis or function computation. In addition, the EGO iterative calculation is fine-grained, performed in parallel by the GPU.
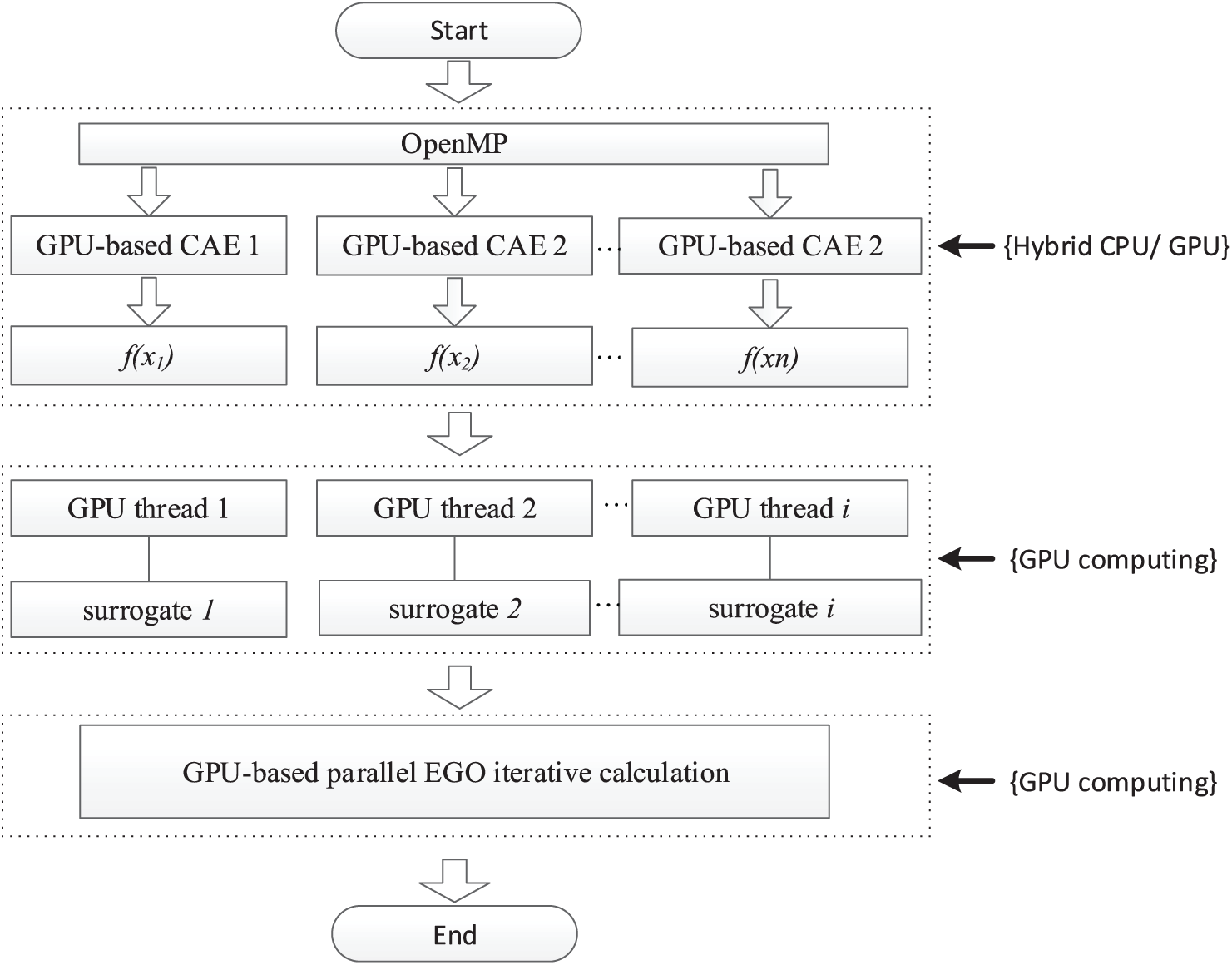
Diagram of parallel the MDEGO approach.
Numerical examples
In this section, the MDEGO algorithm is applied to both functional and automotive optimal design problems. The mathematical problems are selected to test the convergence of the proposed multiple-data approach. The examples for automotive design are used to test the computational efficiency of the parallel MDEGO algorithm.
Function tests
First, three widely used global optimization functions are selected to test the predictive capabilities of the MDEGO algorithm, including the Ackley function, the Hartman function and the Dixon & Price function. To guarantee the validity of test, the number of subsets used in the MDEGO algorithm is as large as the number of surrogates employed in the MSEGO algorithm for most cases. However, since too many surrogates will dramatically increase the computation cost for high-order functions, only three surrogates are considered for the Dixon & Price function. The detailed test method is put forward in Table 2.
The detailed test methods.

MSEGO: multiple-surrogate efficient global optimization
The Ackley function
The Ackley function is described as follows
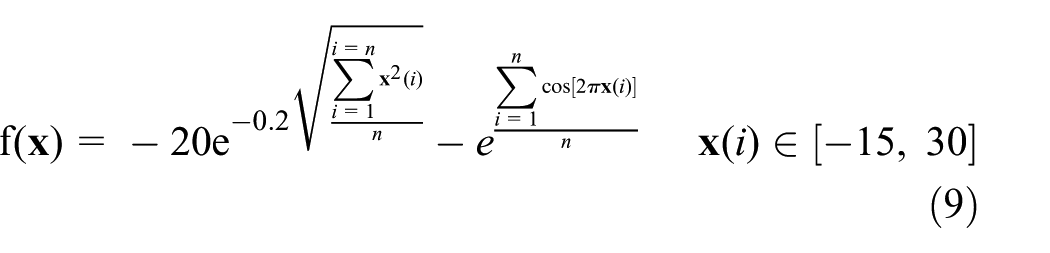
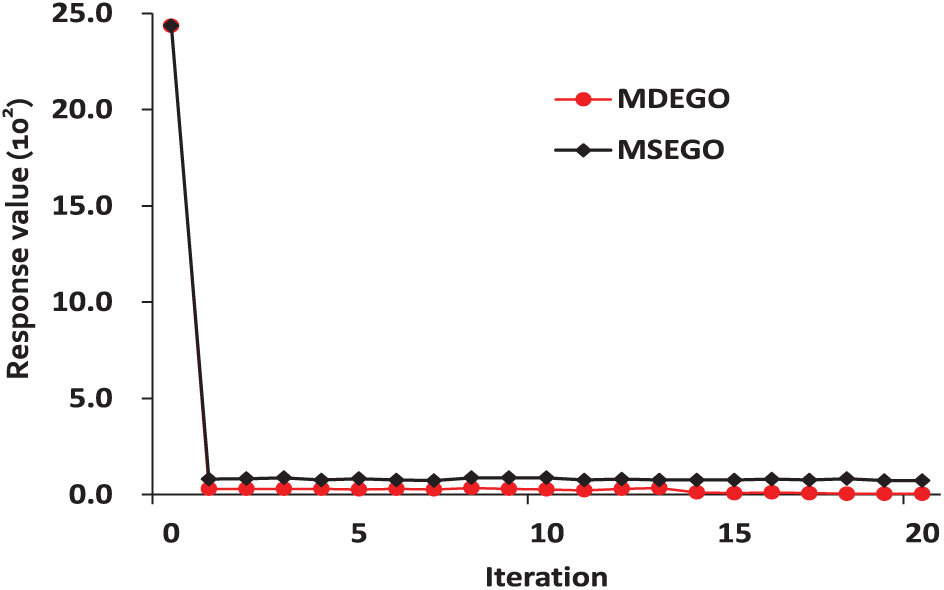
Figure 7 shows the convergence of the Ackley function. It can be seen that the MDEGO algorithm has a better convergence property than the MSEGO algorithm with the same optimization iterations. In detail, the response value of the MDEGO algorithm is always better than the MSEGO algorithm at every iterative step. More importantly, the response value of the MDEGO algorithm at the 4th iterative step is already better than the MSEGO algorithm at the 21st step. Since additional six infill points are added in every iterative step of the MDEGO algorithm, the evaluations are completely performed 126 times the same as by the MSEGO algorithm; therefore, the number of evaluations does not grow.

Convergence of Ackley’s function.
Dixon & price function
The Dixon & Price Function is described as follows

The convergences of the two-dimensional (2D) case and the 10-dimensional (10D) case are shown in Figures 8 and 9, respectively. It is easy to see that these conclusions are similar to Ackley’s function. The MDEGO algorithm consistently finds the global minimum quicker than the MSEGO algorithm. Note as well that there is less difficulty in the calculation of multiple initial points than in the construction of multiple surrogates, so the computation cost for these functions is effectively reduced.
Convergence of 2D Dixon & Price function.

Convergence of 10D Dixon & Price function.
Hartman function
Finally, the Hartman function is considered as follows
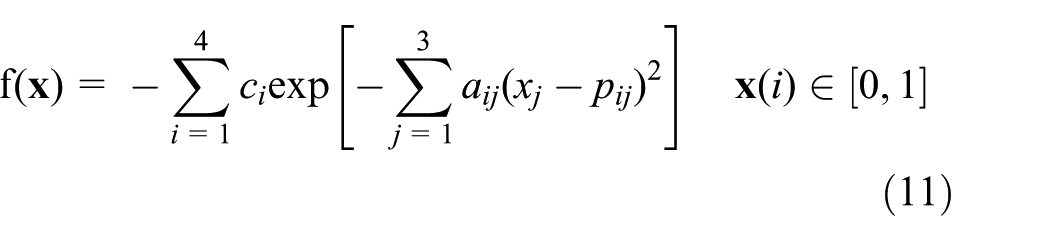
The convergence of the six-dimensional (6D) case is shown in Figure 10. Unlike the above conclusions, the response values of the MDEGO algorithm are not always better than the MSEGO algorithm during the iterations. In the beginning, the convergence of the MSEGO algorithm is better than the MDEGO algorithm, and then as convergence is approached, a better response value is finally obtained by the MDEGO algorithm. Moreover, the MSEGO algorithm does not achieve the optimal value at the same point as the MDEGO algorithm.
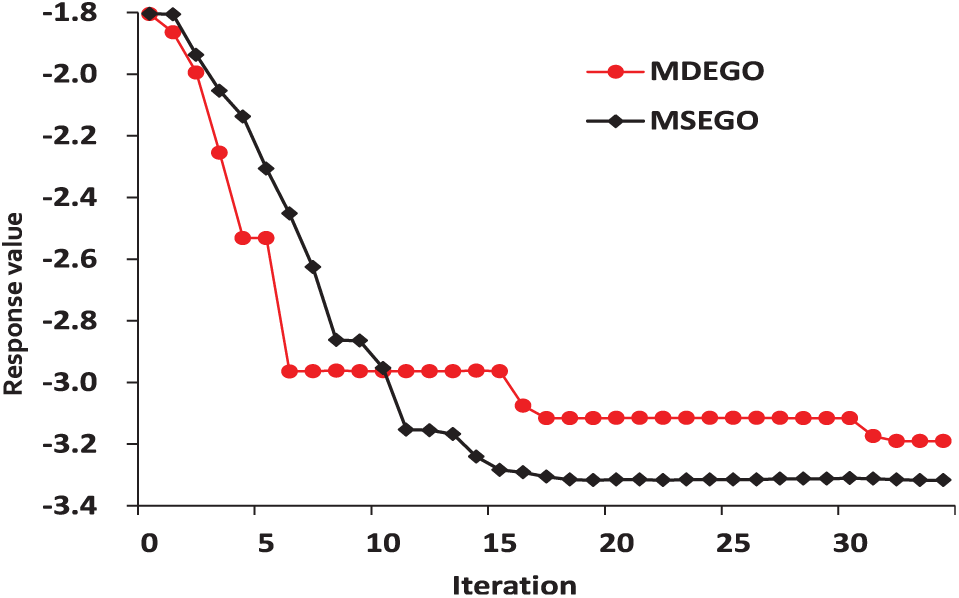
Convergence of the 6D Hartman function.
Automotive optimal design optimization
In this section, the parallel MDEGO algorithm is applied to two practical engineering optimization problems. As mentioned above, our GPU-based FE analysis systems are introduced to improve calculation efficiency. These comparisons are performed on a personal computer containing one Intel Core i7-930 CPU and two NVidia GTX 970 GPUs. The GTX970 are equipped with 1664 CUDA cores running at 1.114 GHz and sharing 4 GB of global memory. Furthermore, the parallel program is written in CUDA, version 7.0, and the NVIDIA GPU driver version is 347.62.
Automobile B-pillar
First, an optimization example for an automobile B-pillar is performed with the target function being the three-point bending stiffness of the part. The FE model of this optimization problem is shown in Figure 11. The FE model is composed of 2472 nodes and 7118 elements, involving 42,708 degrees of freedom (DOFs). The modulus of elasticity is E = 200 GPa, and Possion’s ratio is v = 0.3. The thickness of the car body is t = 1.0 mm. As shown in Figure 11, concentrated force with the value of 600 N is applied vertically downward on the red node, and all DOFs of the green nodes are constrained. The downward concentrated forces are loaded on the red nodes, and the simply supported constraints are loaded on the green nodes.

FE model of the automobile B-pillar.
As shown in Figure 12, the optimization goal is to get the optimal three-point bending stiffness by modifying the shape of its section lines. The shape of these section lines is controlled by several key points, including point A and point B; therefore, this case takes the position of using points A and B as the design variables. The Ω A and Ω B regions in Figure 12 are the design spaces where A and B are respectively located.

Optimal model and its optimal result: (a) section line and (b) optimized region and optimal result.
In this case, six initial points are calculated in the MDEGO algorithm, and three surrogates are constructed in the MSEGO algorithm, including Kriging, svr_Gaussianrbf, and shepard. The convergence of the parallel MDEGO algorithm and the MSEGO algorithm for this case is shown in Figure 13. The optimal result of the MDEGO algorithm is clearly much better than that of the MSEGO algorithm. The final optimal shape line is shown in Figure 12.

Comparison for an automobile B-pillar.
In addition, in order to confirm the calculation efficiency of the parallel MDEGO algorithm, the original serial MDEGO algorithm is performed. According to the performances, a 31-fold increase in speed is obtained, where the increase in speed is calculated by dividing the CPU consumed time for the original serial process by the total GPU consumed time for the parallel process.
Automobile door lightweight design
In this case, a design problem for a lightweight automobile door is considered. A lightening hole is drilled to decrease the weight. The FE model is shown in Figure 14. The FE model includes 86,895 nodes and 170,282 elements that involve 521,370 DOFs. The boundary condition is described as follows: restrain the translational motion along x, y, and z directions for nodes at the location of the hinges and restrain the translational motion along y direction for the node at the location of the key cylinder. A force with the value of 800 N is applied vertically downward on the node at the location of the key cylinder. The modulus of elasticity is E = 200 GPa, and Possion’s ratio is v = 0.3. The thickness of the car body is t = 1.5 mm. The optimization goal is to maximize the stiffness and minimize the weight by modifying the diameter of the lightening hole.

FE model of automobile door.
Similarly, the convergence of the MDEGO algorithm and the MSEGO algorithm is compared in Figure 15. The MDEGO algorithm still shows better convergence than the MSEGO algorithm. Furthermore, a 95-fold increase in speed is obtained for this case, because the FE model is more complex than the B-pillar case.

Comparison for lightweight automobile door design.
Conclusion
In this article, a multiple-data-based optimization method and its parallel implementation are proposed for global optimization problems. In terms of the accuracy for various mathematical test functions, the MDEGO algorithm excels in all categories. Furthermore, since the ultimate purpose of this work is to improve the usability of the global optimization technique for automotive body design, a B-pillar and a car door optimal design problem are treated. The optimal results demonstrate that, compared to the MSEGO algorithm, the performance of the suggested MDEGO algorithm is better suited for both mathematical and practical engineering problems. More importantly, according to the inherent parallelism of the MDEGO algorithm, a parallel GPU-based MDEGO algorithm is proposed. This method uses OpenMP to perform parallel calculate of each sub-data and uses the GPU to perform parallel calculate of response values. Among them, GPU-based parallel computing uses a fine-grained parallel computing strategy by mapping CUDA threads to sub-data. At the same time, for the engineering optimization problem, this article also uses GPU to accelerate the calculation of positive problems. Examples show that the calculation time for the practical problems are clearly shortened by a hybrid OpenMP and CUDA parallel computing scheme proposed for the MDEGO algorithm. An increase in speed of nearly 31-fold is obtained for the simple B-pillar optimal design problem and an increase of approximately 100-fold in speed is obtained for the automobile door lightening case.
The remarkable advantages of this parallel MDEGO algorithm mainly include: (1) this algorithm makes full use of the diversity of array grouping, and it has higher convergence speed than MSEGO algorithm based on multiple models and (2) this algorithm is very suitable for parallel computing. It can increase the calculation speed while ensuring the convergence speed, so that the algorithm can be applied to most high-order and large-scale problems.
In the near future, we will investigate other more complex cases by hybrid message passing interface (MPI), OpenMP, and CUDA, such as performing the optimization of an entire vehicle body structure with the MDEGO algorithm in a short time.
Footnotes
Handling Editor: Michal Kuciej
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China under grant number 11702090 and the Project of the Key Programme of the National Natural Science Foundation of China under grant number 61232014. The Project is supported by the State Key Laboratory of Materials Processing and Die & Mould Technology.