
Abstract
With the purpose to offer simple and convenient assistance for the elders with disabilities to take care of themselves in activities of daily living, we present a motion primitives learning method based on robot learning from demonstration to improve the intelligence and adaptability of the wheelchair-mounted robotic arm. This method adopts the beta process autoregressive hidden Markov model to segment the demonstrations of related task, acquire the contained motion primitives, and recognize the repeated motion primitives. After that, it adopts the dynamic movement primitives to adjust the related motion primitives according to the task instructions by the wheelchair-mounted robotic arm users, so as to replay the demonstrated task in a new environment. This learning framework is validated on a 6-degree-of-freedom JACO robotic arm, performing the tasks of drinking water from the bottle through a straw and pouring water from the bottle to the cup.
Keywords
Introduction
Wheelchair-mounted robotic arm (WMRA) is a typical assistive robot, which is designed to help the elders with disabilities to take care of themselves in activities of daily living (ADLs).1–4 However, the control process of the WMRA 5 is often too tedious, requiring numerous steps and complex sequences to achieve the desired movement of the robotic arm to reach, align, and safely grab an object. This is a big challenge for the elders, especially for those with disabilities such as upper limb extremity impairments. Additionally, the WMRA users hope that the robotic arm can accomplish a task autonomously following their instructions. 6 Although it is possible for the expert to program a robot to accomplish a specific task, it requires the expert a great deal of knowledge and costs him a lot of time. How to provide a simple, user-friendly method of programming the robots to deal with the large numbers of tasks existed in domestic environments is still a problem.
In order to solve the above questions, much recent work has focused on robot learning from demonstration (LfD). 7 It offers a simple and user-friendly teaching framework for the robots to learn new skills just through imitating the actions of humans and other agents. That is to say, the user can teach a robot how to accomplish a specific task, then the robot can reproduce the process just the same as the user has just demonstrated. Compared to other programming methods, LfD has the advantages that it does not require expert knowledge of the domain dynamics so as to avoid the problem of performance brittleness resulting from model simplifications, and non-robotics experts can participate in the development of control strategy for LfD does not require any relevant expert domain knowledge.8–10
However, demonstrations are often simply treated as trajectories to be mimicked to accomplish the specific tasks,11,12 losing the information of the task or the related environment. So, it is difficult for the learned policies to generalize well to the new situations, especially for the complex tasks. Additionally, the work environment of the WMRA is a typical unstructured environment. The reproduction environment (such as the position of the WMRA or goal object) will not always remain the same as the initial task demonstration setting. When it comes to similar tasks with different initial conditions, the contained motion primitives are quite similar. So, considering that much of human movement is thought to be composed of motion primitives,13,14 some researchers have tried to segment the demonstration trajectory into a sequence of motion primitives. In this way, the task can be learned and generalized easily as a whole, and the learned motion primitives can be easily reused in other multi-steps task in unstructured environment.
Nevertheless, to segment the complex tasks by hand or to provide individual motion, primitive demonstrations are still associated with many problems. To divide a natural, whole demonstration trajectory into some component motion primitives is a time-consuming, difficult process. To obtain the effective and reasonable segments requires prior knowledge of the robot’s internal representations, kinematic properties, existing skill competencies, as well as task constraints.11,12 The complex tasks in the unstructured working environment of WMRA which contain many repeated motion primitives also enhance the difficulty of manual segmentation. For the above reasons, much effort has been focused on automating the segmentation process. The existing approaches for motion segmentation are mainly as follows: 15 (1) classification based on existing motion primitives used for training, whose major drawback is in need of prior knowledge; (2) looking for changes in a variable, 16 such as zero crossings or other changes in a variable compared with a known state, which is sensitive to the variables encoded while one needs to find a way that would ensure optimal segmentation across all task dimensions; (3) clustering similar motions by means of unsupervised learning, such as hierarchical Dirichlet process–hidden Markov model (HDP-HMM) 17 and the Realtime Overlapping Gaussian Expert Regression (ROGER). 18 Considering the complex, multi-step tasks existed in domestic environment, it is not suitable to offer sufficient prior knowledge or changes in a variable. So, the unsupervised learning is an effective approach, especially for the activities of daily life.
Recently, S Niekum et al. 11 adopted the beta process autoregressive HMM (BP-AR-HMM) algorithm proposed by E Fox et al.,19,20 which is a typical unsupervised learning approach, to segment a learned motion into a sequence of skills and mainly validated this approach in simulation environment. Additionally, the autoregressive HMMs (AR-HMM) can capture the temporal dependencies present in the data set. This advantage is very suitable to explain the motion of robotic arm, which is a complex dynamic phenomenon. In this article, we mainly focus on the learning of motion primitives from the segmentation of demonstration using the BP-AR-HMM algorithm. The recognition of repeated motion primitives is also accomplished during this process. Then, considering the replay process is based on one demonstration, we use the dynamic movement primitives (DMPs)13,21 to adjust the learned motion primitives to quickly replay the demonstrated task. Additionally, the Stable Estimator of Dynamical Systems (SEDS) approach 22 is also an appealing method with excellent trajectory generalization ability. It can learn from multiple demonstrations and can be also suitable to replay the demonstration task.
The framework of this article is organized as follows. The background of the related work, including the existing research about WMRA, BP-AR-HMM algorithm, and the DMPs is introduced in section “Background.” Section “Learning from demonstration” mainly describes the framework of LfD. The robot experiments of drinking water from the bottle through a straw and pouring water from the bottle to the cup are carried out in section “Robot experiment.” Section “Conclusion and future works” discusses the conclusion and future trends.
Background
WMRA
The WMRA is a kind of assistive robot which can enhance the manipulation capabilities of the elders and the disabled and reduce dependence on human aids.1,2,23,24 The concept of WMRA 4 comes from the fact that more and more disabled people and older people resulted by the aging society have difficulty in carrying out ADLs and wish to enhance their manipulation ability with some assistive devices. Just as its name implies, the WMRA is a robotic solution which contains an electrical wheelchair fixed with a lightweight robotic arm, different kinds of sensors, and the corresponding control system. It has the advantages of possessing both the mobility performance of electric wheelchair and the operational performance of the robotic arm, which attract a lot of attentions from both the users and academic society. With the developments of commercial available robotic arms: iARM 25 (produced by Exact Dynamics®) and JACO 26 (produced by Kinova®), a lot of researchers both at home and abroad carried out a series of studies, such as the FRIEND series robots 27 in the University of Bremen, the WMRA-I and II 28 in the University of South Florida, the wheelchair-mounted robotic manipulators (WMRMs) in Purdue University, 29 and the WMRA system “WIM”3,4 in Waseda University.
At present, the researches on the WMRA mainly focus on the following categories: (1) develop a variety of human–robot interaction interfaces that can satisfy the motor ability of different users, particularly for the disables;1,4,30–32 (2) adopt the visual servo technology or learn from demonstration to control the motion of robotic arm, so as to reduce the physical and mental burden of the users;27,33,34 (3) design a new structure of robotic arm in order to improve the safety of the user, for the users are in the working space of the robotic arm; 35 and (4) develop the integrated WMRA with two or more above characteristics. To develop the WMRA with the characteristics of high safety, high intelligence, and operational ease is the developing trend in the field of assistive robots.
BP-AR-HMM
Hidden Markov model (HMM)12,19,20 is a dual stochastic process based on a potential discrete-valued state sequence, which is modeled as Markov. Based on this state sequence, the observations are seen as independent states in the model. Obviously, HMM is suitable for the time series analysis and has been widely used in the fields of speech recognition, movement recognition, and artificial intelligence but with the premise of a first-order Markov hypothesis. That is to say, the state of time t is only in relation to the state of time t − 1. However, HMM adopts the maximum likelihood estimation which is easy to make the model overfitting or low-fitting and it requires the number of implicit states must be set in advance. Obviously, this requirement does not meet the majority of natural conditions of the data form and consequently limits the application of HMM. Additionally, when the HMM observation state is a series of complex dynamic behavior, its dynamic behavior itself is also interrelated in the time series. But they are still regarded as independent observations in HMM; this will be insufficient to obtain the interdependence in data sets.
The BP-AR-HMM11,12,20 is a Bayesian nonparametric model which can provide principled solutions to the shortcomings of HMM. This algorithm is similar to the sticky HDP-HMM and it also learns duration distributions from the related data. In order to improve the HDP-HMM mechanism so as to share modes across time series, a beta process prior represented with an infinite feature is used by BP-AR-HMM. In this way, each time series can exhibit a subset of discover modes and switch among these modes. Thus, this algorithm can construct a potentially infinite library of modes in a fully Bayesian way. This mode will be helpful to share flexibly between time series and infer the appropriate number of modes directly from the data without the information of model selection. 12 Given consideration to the feature space (autoregressive parameter set) and time dynamics (transition distribution set) as a separate dimension, one can think of the BP-AR-HMM as a spatio-temporal process including a beta process in space and discrete-time Markovian dynamics in time. Compared with other segmentation methods, the BP-AR-HMM has the following advantages. (1) It uses a beta process prior to decide the number of the skills in a fully Bayesian way. This allows the complex motion process to be represented by a potential infinite number of skills. (2) It allows the obtained segments to be represented as switching vector autoregressive (VAR) processes and explained by a set of latent skills with skill-dependent noise characteristics. So, the robot can recognize repeated skills and share them in a variety of situations. (3) The BP-AR-HMM provides reliable inference with only a few free parameters. For this reason, it is suitable to a wide range of initial settings. The graphical representation of the BP-AR-HMM 20 is shown in Figure 1, which mainly contains three portions: beta process, HMM model, and VAR model.

Graphical representation of the BP-AR-HMM.
The generation process of the BP-AR-HMM is shown as follows. The random measure B in equation (1) defines a set of weights on the global collection of behaviors. The feature-inclusion probabilities ωk and VAR parameters θk are created from the beta process for the potentially infinite number of states, as shown in equation (2)


The beta process is conjugate to a class of Bernoulli process, denoted by Bep(B). A Bernoulli process realization Xi determines the subset of features allocated to time series i, which is shown in equation (3). Informally, the beta process can be defined as the coin probability with an infinite set, and the realization of each Bernoulli process is the result of an infinite coin flipping sequence based on the coin weight determined by the beta process. 20 The Bernoulli process realization Xi shown in equation (4) implicitly defines the feature vector fi for the time series i, indicating which set of globally shared behaviors that time series has selected. The model reduces to a collection of N switching VAR processes. In this way, the BP measure B can not only allow the Xi to share similar features in many time series but also allow the Xi with much variability


The generative process of transition distribution
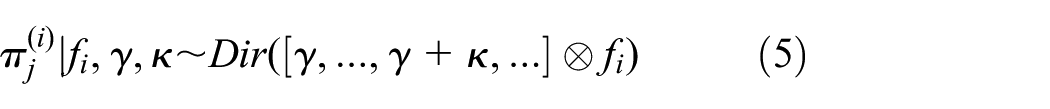
The time series i can only select among dynamic behavior

The observed values

DMPs
The core of DMPs12,21,36,37 is to describe a series of nonlinear differential equations with attractive points. Especially, this approach is to start with a simple dynamical system, such as a series of linear differential equations, and then use the dynamic characteristics of the specific attractor to convert it to a nonlinear system through the autonomous learning process. We can realize any complex behavior through using the point attractor or limit cycle attractors. In this article, we mainly adopt the modified DMPs 21 and study the point attractor to encode the discrete movement.
The discrete movement can be constructed by the combination of the following differential equations. This can be described as a linear spring system under the disturbance of the external force. The transformation system is shown in equations (8) and (9) 21


In the above equations, K acts as the spring constant, D is the damping constant, xg is the target position, x0 is the initial position, s is the phase, xg − x0 refers to the scale factor of the trajectory shape which is used to scale the trajectory shape when the new target point is far from the demonstration initial point, τ is the temporal scaling factor which affects the speed of action generation; equation (8) is called as transformation system. One degree of freedom corresponds to a separate transformation system, where f is nonlinear interference force, which can be learned to generate a specific shape of the trajectory. The nonlinear function is shown in equation (10)


In equation (10), ψi(s) is the Gaussian basis function with ci as the center and hi as the width. Through adjusting the weight ωi, we can obtain any shape trajectory. α is a constant, s is the phase parameter with initial value 1 and converged to 0, which means that the external force is getting smaller and smaller during the process of closing the goal position. Equation (11) is called the canonical system, which can be used to achieve the couple between multiple degrees of freedoms and does not directly depend on time.
When the demonstration trajectory information is obtained, we can adopt the LfD to learn the above values so as to identify these weights. The weight ωi can be identified by minimizing the error J, which is described in equation (12)

We convert time to phase with the help of equation (11) and readjust equation (8) with the appropriate variables in the demonstration, so as to obtain the following equation (13) 21
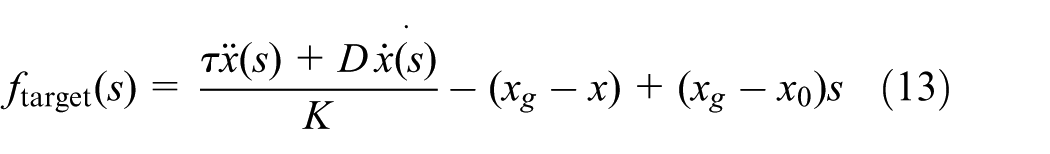
Learning from demonstration
In this article, we mainly provide a new approach that can easily teach the WMRA to learn new motion primitives just from demonstration and replay them in new situation later. This approach will fasten the learning process, reduce the difficulty of learning, and be very helpful to the application of WMRA in domestic environment. The structure of WMRA in our laboratory is mainly built with the electrical wheelchair—Express (produced by Vermeiren) and the robotic arm—JACO (produced by Kinova®) (Figure 2). The robotic arm—JACO is installed on the right side of the wheelchair, which is inconsistent with the operation habits of most people.
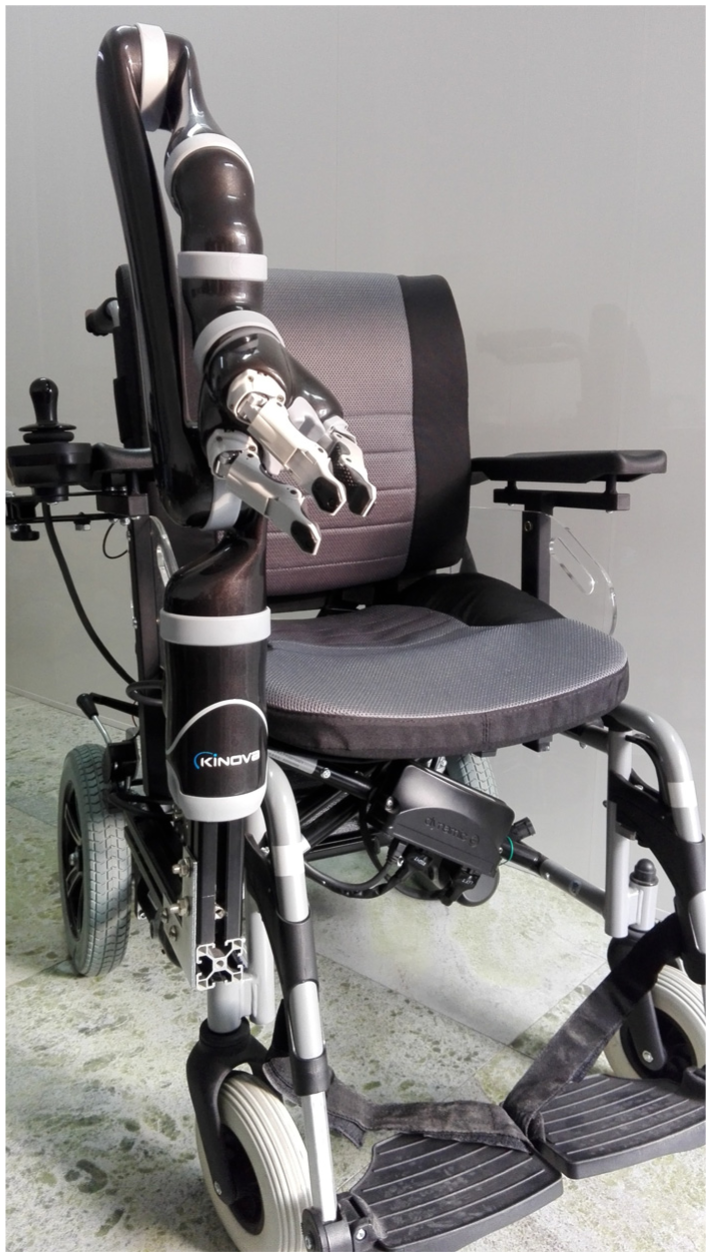
WMRA with Express electrical wheelchair and JACO robotic arm.
In this article, we mainly focus on the motion primitive learning of the robotic arm to accomplish some specific tasks. Figure 3 shows a framework of the robotic arm’s motion primitive learning approach. In the following sections, each step will be described in detail.

Overview of the robotic arm’s motion primitive learning approach.
Task demonstrations
The end users can teach the robots to learn new motion primitives or complete a task through a variety of teaching interfaces. The teaching interface used to provide demonstration plays a key role in the gathering of demonstration information. There are many different teaching interfaces to teach the robot to accomplish the specific task. 9 At present, the common teaching interfaces are as follows: (1) handle control mode, which requires the user can flexibly manipulate the handle to control the movement of the robot; (2) kinesthetic teaching, which requires the teacher to use more degrees of freedom to move the robot than the number of degrees of freedom they want to control; (3) directly recording human motions, such as the visual, exoskeleton, or wearable sensor, which requires a good solution to the correspondence problem especially when the teacher and robot are dissimilar; and (4) teleoperation mode, which requires the design and learning of the corresponding remote control equipment.
In this article, the robot is required to accurately output the relevant motion information as the original motion primitive learning data. Additionally, considering the WMRA will mainly be used in domestic environment, it is better to adopt an easy manipulation mode without any extra effort for the teacher to teach the robot. For the above reasons, we choose the handle control mode. Although this mode requires flexible manipulation of the handle, it may be difficult for the elders or the disabled but will be very easy for the teacher with sound athletic ability. In order to facilitate the acquisition of demonstration data, we also design a demonstration interface using the original code of the JACO robotic arm to automate the data acquisition process. With the help of this interface, we just have to gather a few key points of the trajectory that we need; the robot can follow the key points latter and export the related motion information of the demonstrated trajectory. Meanwhile, we can easily modify the speed of movement as well as monitor the relative movement information during the demonstration process.
In this way, the motion information of the hand and the gripper can be accurately recorded as the most original trajectory information. Additionally, the position information of the goal object will be also recorded as the initial information.
Motion segmentation
The BP-AR-HMM algorithm is used to segment the motion information collected from the demonstration. This algorithm is first made available by E Fox et al.19,20 to segment the data from CMU motion capture database and improved by S Niekum et al.11,12 to learn and generalize a multi-step task on the PR2 mobile manipulator. In this article, we mainly made some modifications based on S Niekum’s code to meet the actual application requirements of the WMRA. During the segmentation process, the robot is only given the demonstration trajectory in Cartesian space without any other knowledge about the nature of the task.
Following the original instruction of E Fox, the obtained demonstration data are preprocessed so that the first difference in each dimension of the data is 1, and the average value is 0. In the paper of E Fox, she mainly analyzed the data set captured from a human exercise motion. This situation is similar with the situation we face in the domestic environment. So, we adopt the identical parameters and choose the autoregressive order of 1, just the same with the parameters chosen by E Fox. Considering the principled statistical techniques of the BP-AR-HMM, we set the Markov chain Monte Carlo (MCMC) sample times to be 15 and the iteration times to be 1500 to segment the demonstrations, producing 15 segmentations. We select the segmentation with the highest log likelihood of the feature settings in the 15 runs and deem the corresponding segmentations as the motion primitives of the task demonstration.
After running the program of the BP-AR-HMM algorithm, we can obtain the segmentation with the highest log likelihood of the feature settings from the 15 segmentations. In addition to the graphical representation of the segmentation results, we can obtain the HMM’s latent dynamical state sequences, which is explicitly expressed with a series of different repeated number, such as 1 1 1 3 3 3 3 2 2 … It is correlated with the values in order in the demonstration trajectory. The different numbers represent the motion primitives contained in this time series, and the consecutive repeated number series is the VAR dynamical mode, which constructs the corresponding motion primitives. To obtain the motion primitives through the segmentation of demonstration trajectory is really a simple and practical approach. This will simplify the tedious demonstration of motion primitives and learn the motion primitives’ order of the related task simultaneously.
During the segmentation process, the demonstrated task information will be stored in the task library, along with its order of contained motion primitives. The learned motion primitives obtained from segmentation will be stored in the motion primitive library. Let us take an example to explain the demonstration information storage process, which is shown in Figure 4. Task 2 is composed by motion primitive 2, motion primitive 3, motion primitive 6 in order. The related motion primitives are selected from the motion primitive library.

Demonstration information storage in computer.
In addition, each segment must be checked to infer the corresponding coordinate frame in which it occurs. Even if they are allocated to similar motion primitives, they may occur in different frames of reference. The detection of the coordinate system will help to replay the task robustly in the new situation, so that the goals of the DMPs can be generalized correctly.11,12 In this article, we defined a coordinate frame centered on each object, including the JACO arm. The final point of each segment is converted to the above coordinate frame with the help of coordinate transformation. Then, the last point of each segment is drawn in the upper coordinate system, and we use the clustering method to detect each coordinate system in order to find out the correlative coordinate frame that the final points cluster. It should be noted that not all the points will be clustered in the above coordinate frame. The singleton clusters will be discarded. If the endpoint belongs to clusters in more than one frame, it is simply assigned to the frame corresponding to the largest cluster. In this way, the motion primitives obtained from the segmentation can be associated with the object, and the repeated motion primitives can be identified.
Task replay
The ultimate goal of the WMRA research is to replay the demonstrated task in a new configuration without user’s participation. The new configuration refers to the position of goal object is different from the one in the process of demonstration. In order to realize this purpose, we just have to input the task instruction to the computer without any other information. This is the first and important step in the process of replaying the task. Then, the robot searches the task library to find out the task instruction and its contained primitive motions. The related object information with the selected primitive motions is also gathered by the robot. We adopt the DMPs to modify the primitive motions to meet the requirements of the new environment. The related primitive motions will be modified by equation (12), which is shown in section “DMPs.” If the primitive motion is in the coordinate frame of the robot, it does not have to do any modification. Finally, the modified DMPs are implemented following the sequence of the task demonstration. Following the above steps, the robot can automatically generate new plan to accomplish the learned tasks in a new configuration.
Robot experiment
Experiment 1: drinking water
The first experiment is to drink water from the bottle through a straw, aiming to demonstrate the ability of the JACO robotic arm in our framework to learn motion primitives contained in the demonstration task and identify the repeated primitives.
Considering the fact that the wheelchair remains stationary during the process of WMRA accomplishing most of tasks in daily life, we decide to install the JACO on the table so as to simplify the complexity of the WMRA in this experiment. This simplification will have no impact on the study in this article. The JACO is predefined as the right-hand configuration at the bottom right corner of the table. This installation mode is consistent with the most human operating habits and the installation mode of WMRA in our laboratory. Additionally, considering the structure of WMRA, the mouse position of the user will be relatively above the table on the left side of the JACO base. So, we only choose a spatial point to represent the position of the mouth.
In the experiment, we carry out six drinking water task demonstrations for three different locations of the bottle, which are shown in Figure 5 with round papers indicated with numbers. The installation location of the JACO at home configuration is also shown in Figure 5.

Initial experiment configuration of drinking water from the bottle through a straw. Demonstration locations: 1, 2, 3; new location: 4; demonstration 1: from 1 to 0; demonstration 2: from 2 to 0; demonstration 3: from 3 to 0; replay task: from 4 to 0.
We assume the spatial point about 300 mm above the number 0 is the mouse position. The numbers 1, 2, and 3 indicate different initial locations for the task demonstrations, which will be placed with the bottle in turn. The number 4 indicates a new location for the learned task replaying, which is obviously different from the demonstrations. As to the locations of numbers 1, 2, 3, and 4, they are randomly arranged on the table with one requirement that they are in the workspace of the JACO. We do twice task demonstrations at each location, so the total demonstration number is 6. The whole process of drinking water through a straw with the help of JACO is shown in Figure 6.

Demonstration process of the drinking water through a straw: (a) home configuration, (b) reach the bottle, (c) grasp the bottle, (d) pick up the bottle, (e) move to the mouse position, and (f) put down the bottle.
Figure 7 shows the segmentation results of the above drinking water demonstrations. The top row shows the segmentations of different motion primitives with one colored bar per primitive, while the bottom row shows the motion primitive divisions overlaid on a plot of each of the demonstration data. In Figure 7, the first two pictures indicate the demonstration 1 (from the number 1 to 0); the second two pictures indicate the demonstration 2 (from the number 2 to 0); and the last two pictures indicate the demonstration 3 (from the number 3 to 0).

BP-AR-HMM segmentation of the six demonstrations (top) and segmentation lines overlaid on the demonstration data (bottom).
From the results, we can easily find that the segments and colored bars are essentially the same in Figure 7 and draw the conclusion that the BP-AR-HMM can recognize the motion primitives contained in the demonstration as well as identify the repeated motion primitives, even though they occur at different locations. The color, width, and order of the colored bars existed in the segments are essentially the same as others, except the second colored bar existed in the third and fourth segments with different colors. This may be caused because the location of bottle is a little low for the robot to grasp, causing the waist joint angle to suddenly change compared to its set value.
We take the first segment, for example: the first bar colored with cyan corresponds to the reaching motion primitive, the second bar colored with yellow corresponds to the grasp motion primitive, the third bar colored with cyan corresponds to the pickup motion primitive, the fourth bar colored with blue corresponds to move the bottle to the mouth, and the fifth bar colored with cyan refers to the put down the bottle. The bars are inconsistent with the demonstration process in Figure 4. As the first, third, and fifth bars are in the same color, which means that the motion primitives are seen as the same primitives, for these motion primitives mainly describe the movement of robotic arm in the vertical direction, without the movement of wrist or fingers.
During the segmentation process, the task information is also stored in the task library, along with its order of the contained motion primitives. In this experiment, the drinking water task demonstration contains five segments with three different motion primitives and two repeated ones. Additionally, each motion primitive obtained from the segmentation of the drinking water demonstration is also examined to infer the corresponding coordinate frame in which it occurs.
In the replay phase, we adopt the DMPs to modify the learned skills to accomplish the related task in the new location 4, which is shown in Figure 3. Given the related information of location 4, we apply equation (12) shown in section “DMPs” to adjust the related parameters of each motion primitives contained in the demonstration trajectory, so as to accomplish the drinking task just as demonstrated in positions 1, 2, and 3. The successfully replaying the task indicates that the robot has learned the task of drinking water through a straw.
Experiment 2: pouring water
This experiment is to pour water from the bottle to the cup, aiming to learn the motion primitives contained in the task demonstrations. Figure 8 shows our configuration of the pouring water task. During the demonstration process, the demonstrator sat in the wheelchair and operated the joystick to control the JACO to accomplish the pouring water task. In the experiment scene, JACO stays at the home configuration; numbers 1–4 represent the initial locations of the bottle for the task demonstration, number 0 represents the position of the cup, and location 5 is a new location of the bottle for the learned task replaying. We do twice task demonstrations of pouring water from the bottle to the cup at each initial location. Additionally, it is important to keep in mind that the JACO is installed on the wheelchair not on the table during this experiment.

Initial experiment configuration of pouring water from bottle to cup. Bottle locations: 1, 2, 3, and 4; cup location: 0; demonstration task: from 1 to 0; replay task: from 5 to 0.
The whole process of task experiment with the help of WMRA is shown in Figure 9. It mainly contains the following steps: (1) home configuration, (2) grasp the bottle, (3) pick up the bottle, (4) move to the cup, (5) pour the water, and (6) put down the bottle.

Demonstration process of the pouring water from the bottle to the cup: (a) home configuration, (b) grasp the bottle, (c) put up the bottle, (d) move to the cup, (e) pour the water, and (f) put down the bottle.
Figure 10 shows the segmentation results of the above demonstration of the pouring water task. The top row shows the segmentation results of the eight pouring water demonstration processes, while the bottom row shows the divisions of the motion primitive overlaid on the plot of each of the original demonstration data. In Figure 10, the first and second pictures indicate the demonstration 1 (from number 1 to 0), the third and fourth pictures indicate the demonstration 2 (from number 2 to 0), the fifth and sixth pictures indicate the demonstration 3 (from number 3 to 0), and the last two pictures indicate the demonstration 4 (from number 4 to 0).

BP-AR-HMM segmentation of the two demonstrations (top) and segmentation lines overlaid on the demonstration data (bottom).
From the top row of Figure 10, we can easily draw the conclusion that the BP-AR-HMM can recognize the motion primitives contained in the eight demonstrations of the task. The segments in Figure 10 are exactly the same in color, width, and order. This may contribute to the character of the BP-AR-HMM algorithm, for it is based on the statistical analysis. When the number of demonstrations increases, it is easier to obtain the common motion primitives contained in the task demonstrations.
We take the first segment picture, for example, to explain the exact demonstration process. The first bar colored with yellow corresponds to the motions of grasping the bottle and putting up the bottle. The motion of putting up the bottle gets rolled into the first motion. This may be caused because the height of putting up the bottle is too small and the time is also very short. The second bar colored with blue represents the motion primitive of moving to the cup. The third bar colored with cyan corresponds to the motion primitive of pouring water process. The fourth bar colored with red corresponds to the put down of the bottle. The last bar colored with cyan is an extra part. In the real demonstration process, the WMRA remains stationary in this phase. From the bottom first picture of Figure 10, we can easily find that all the curves in this phase are horizontal lines, indicating that the robot arm is still during this phase. So, we identify this phase as an extra phase. Overall, except the movement of picking up the bottle getting rolled with the grasping movement, the other motion primitives are recognized exactly as the demonstration process shown in Figure 9. Additionally, the task-related information is saved and each motion primitive is also examined to infer the corresponding coordinate frame in which it occurs.
In the replay phase, we adopt the DMPs to modify the learned motion primitives to accomplish the pouring water task in the new location 5 shown in Figure 8. Given the related information of location 5, we set the spring constant K as 100 and the damping constant D as 20, according to the relative equations to adjust the trajectory of each motion primitives in the demonstration trajectory. According to the order of task demonstration process, the modified motion primitives are executed in order. The comparison of the original learned trajectory and the DMPs modified trajectory is shown in Figure 11. Through the figure, we can easily draw the conclusion that the shapes of the trajectories are similar, but the two trajectories are toward different goal locations. The WMRA can successfully replay the task indicating that it has learned this task and it can help the elders and the disabled to accomplish some ADLs.

Comparison of modified trajectory and learned demonstration trajectory of DMPs.
Conclusion and future works
In this article, we mainly describe the learning framework for the JACO robotic arm of WMRA to quickly learn motion primitives and related tasks without tedious programming process. Using the BP-AR-HMM algorithm, we can obtain the related motion primitives contained in the demonstration task directly. Meanwhile, the task and its motion primitives are learned during this phase. With the help of DMPs, the learned motion primitives can be modified to replay the task in a novel configuration. The experiments of drinking water and pouring water show that our learning framework can recognize the repeated motion primitives and speed up the learning process of ADLs so as to enhance the intelligence and adaptability of the WMRA. This achievement will be very helpful for the WMRA to assist the elders and the disabled to accomplish related tasks autonomously under their instruction.
Future work will consider the following directions. (1) A more intelligent method must be developed to manage the learned skills which are growing over time. For the WMRA has to assist the elders and the disabled to perform activities of daily life, the number of tasks will be huge. (2) To improve the quality of the task demonstration, such as integrating the force information during the demonstration of related tasks. Additionally, more intelligent methods can be applied to the learning framework to improve the intelligence to WMRA.
Footnotes
Handling Editor: Chenguang Yang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the Key Project of Science and Technology of Weihai (no. 2016DXGJMS04), Weihai Robot and Intelligent Equipment Industry Public Innovation Service Platform (no. 2015ZD01), and the Key Research Project of Science and Technology of Shandong Province (no. 2016GGX101013).