
Abstract
Scheduling modeling for manufacturing system has always been a great challenge in both industrial and academic community. With the growing complexity of the manufacturing system, traditional scheduling modeling and optimization methods cannot satisfy all the demands of current manufacturing environment, so data-based methods are brought into practice. Since the popularity of the concept of cyber physical system and Industry 4.0, more information and interaction systems are applied into the manufacturing system, and more industrial big data produced during the production process can be acquired; the knowledge within these data needs to be uncovered to better schedule the system. In this article, the research progress of scheduling modeling methods for complex manufacturing system are systemically reviewed and evaluated with the semiconductor wafer fabrication environment. Then, we propose the industrial big data–based scheduling modeling framework in cyber physical system condition and discuss how to implement it for the semiconductor manufacturing system, also our demonstration unit of an intelligent semiconductor manufacturing system based on this framework is introduced. Finally, the future work of our application case is discussed.
Introduction
Production scheduling determines the machines to process jobs and their process orders, batch styles, and the assignments of other key production resources. Scheduling optimization problem studies how to optimize the manufacturing performance while meeting the process and resource constraints by scheduling. 1 Scheduling modeling, however, is the interpretation of the whole scheduling process described by formalization language and the transformation of the matter and information from the physical world to the abstract world. In 60 years, scheduling optimization problem has always been the hot issue in both industrial and academic community. With the development of computing technology and artificial intelligence, new comprehension of modeling and optimization work of complex manufacturing system have been presented.
Scheduling optimization methods have evolved from heuristic rules which are commonly applied in enterprises into mathematical programming methods. Till now all sorts of intelligence algorithms have also been put into practice including artificial neural network, swarm intelligence algorithm, and differential evolution algorithm. These methods could help obtain the optimal or near-optimum scheduling solution in the increasingly complex production environment. 2
Meanwhile scheduling modeling method progresses from queueing model to simulation model and now data-based model; it learns more characteristics of the physical manufacturing system and helps to build a mirror that reflexes how the manufacturing system functions.
With the emergence of all kinds of management systems, like manufacturing execution system (MES), enterprise resources planning (ERP), all the data (i.e. structured, semi-structured, unstructured, offline, online, equipment, products data) that are produced during production process now can be collected, exported, and analyzed. Managers can use them to make better decisions to meet all the production demands. After analyzed and processed with big data technology, these data can be applied into scheduling models so that the model should be synchronized with the physical manufacturing system.
An accurate and detailed model is the basis of optimization. Only by cooperation, will scheduling model and optimization algorithm provide a suitable solution for the future dispatch plan. In the following table, the complexity of optimization method and modeling method is presented by gray level; the darkness represents the complexity (Table 1). As the complexity of the method increases, the more complex the scheduling problem becomes, and the more difficult it becomes to solve the non-deterministic polynomial time (NP) hard scheduling problem. But, the optimization effect of the solution, however, should be better.
Optimization effect of scheduling.

In this article, semiconductor manufacturing system is taken as example to summarize the scheduling modeling methods, and an industrial big data–based scheduling modeling framework is proposed. The remainder of this article is organized as follows. In section “Traditional scheduling modeling methods,” a brief introduction of traditional scheduling modeling method is discussed. In section “Data-based modeling achievement in semiconductor manufacturing system,” we introduce some data-based modeling achievement in semiconductor manufacturing system. In section “Industrial big data–based scheduling modeling framework in CPS condition,” our industrial big data–based scheduling modeling framework in cyber physical system (CPS) condition is presented with a case. Section “Conclusion” gives conclusions and future works.
Traditional scheduling modeling methods
Research on scheduling models contributes to in-depth knowledge of its processing features, as well as improvement of the understanding and decision-making ability of the manufacturing system. Traditional scheduling modeling methods have been studied and applied in all kinds of industry communities; here, the methods of semiconductor manufacturing environment are specifically introduced as examples including queueing model, Petri net model, simulation model, and entity model. 3
Queueing theory
Discrete manufacturing system can be abstracted as queueing model. 4 In queueing theory, workpieces are waiting to be processed in front of machines; the waiting sequences are determined by workpiece priorities; the workpiece arrival and processing time should follow certain assumptions. 5 The figure below shows how queueing theory works (Figure 1). Once a queueing model is established, the optimization target like makespan can be easily derived by optimization methods while meeting all the constraints. Chen and Meyn 6 build a queueing model of a semiconductor manufacturing system for production scheduling, yet the high complexity of the system makes it difficult to work out the average performance of the steady-state; so, a numerical form of the performance is derived by approximate analysis method. Normally, the assumptions introduced by queueing theory are too weak and cannot satisfy the actual demands; it limits the application of the method in scheduling modeling of complex manufacturing system.

Diagram of queueing model.
Petri net
Petri net, which deals with dynamic discrete event system, is a directed bipartite graph, in which the nodes represent transitions (i.e. events that may occur, represented by bars) and places (i.e. conditions, represented by circles). The directed arcs describe which places are pre- and/or post-conditions for which transitions (signified by arrows). 7 A Petri net model is a simplified graphical description that presents the process state of the manufacturing system, and the mathematical and logical relationships of the system can be clearly demonstrated. It helps to establish the mathematical expression of the optimization target. Petri net can describe synchronous, concurrent, and real-time dynamic behavior of the complex manufacturing system and evaluate the accessibility and other performances of it.8–10 Figure 2 shows a classical Petri net structure. Kim and Desrochers 11 establish a time Petri net production scheduling model of a semiconductor manufacturing system; the cycle time and utilization rate of the system are analyzed within the model. Qiao et al. 12 propose a hierarchical scheduling model based on colored Petri net of semiconductor manufacturing system, and the method can effectively overcome the excessively complicated problem of Petri net model. However, when dealing with the modeling problem of complex large scale, such as semiconductor manufacturing system, this method is difficult to obtain the ideal effect.

Diagram of Petri net.
Simulation
Simulation model is one of the most extensively used operation research tools today. The method can simulate the manufacturing behaviors of the physical system virtually with all the exact configurations. It focuses on the analysis of scheduling strategy, performance evaluation; also it helps to compare and select the best dispatch plan. Simulation modeling method is often combined with heuristic rules and intelligence algorithms to improve the performance when solving scheduling problems of complex manufacturing process. Kim et al. 13 apply simulation model to the scheduling of a semiconductor manufacturing system and generates an optimized dispatch plan. However, the method lacks generality—simulation software platforms are too many, but none of them can satisfy all the scheduling modeling demands. Figure 3 presents the simulation interface of a MiniFab semiconductor manufacturing environment established by Plant Simulation software.
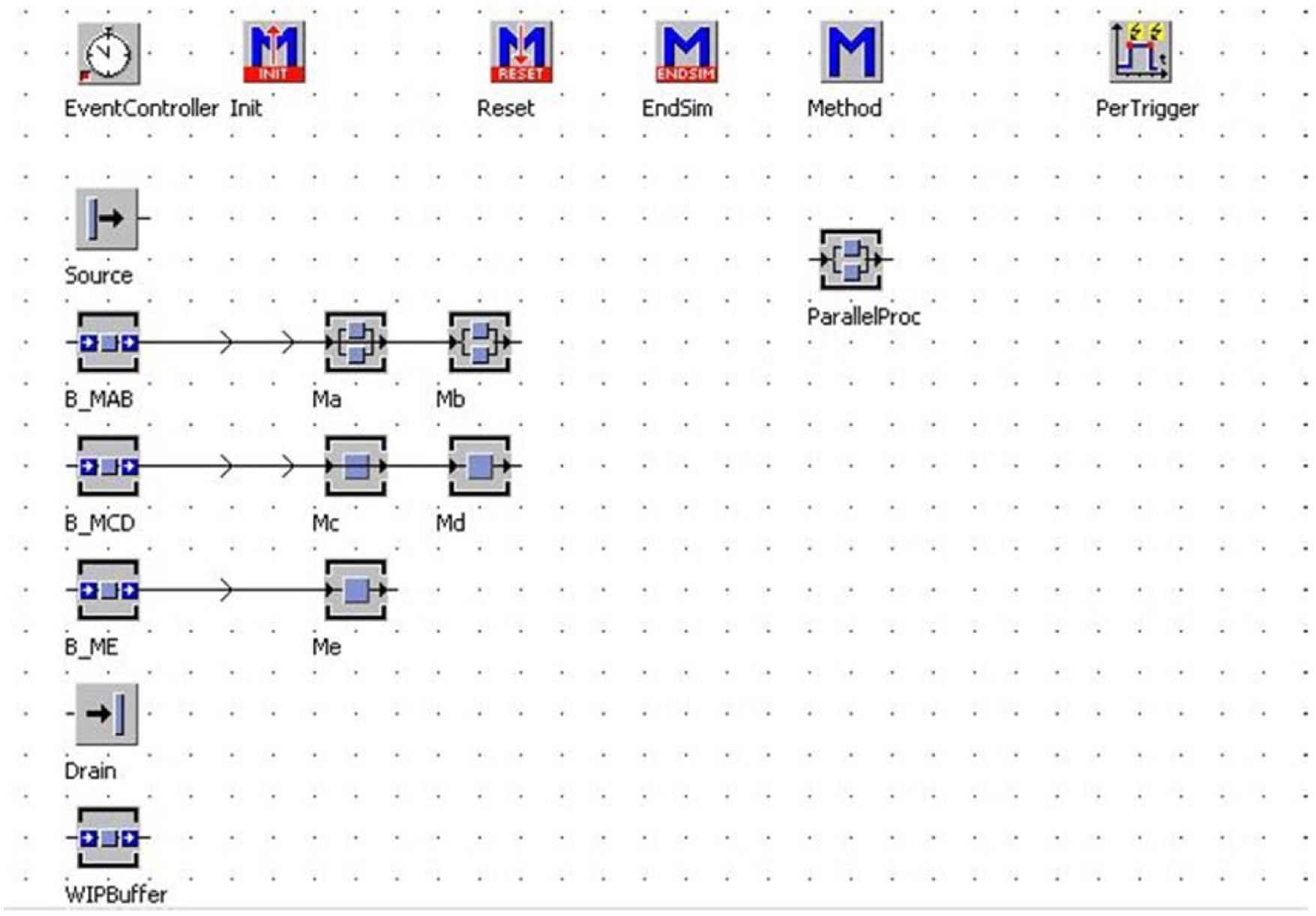
Screenshot of simulation model by Plant Simulation.
Entity model
An entity model of a manufacturing system is a highly customized copy of the production line. It is a smaller version of the physical system that can represent all the manufacturing behaviors. 14 The plan view shows a demonstration unit of an intelligent semiconductor manufacturing system owned by Tongji University, which is an entity model of MiniFab manufacturing system (Figure 4). The mechanical structure of the system consists of simulated storage location (raw material), simulated material waiting area (buffer), one simulated photolithography device, two simulated diffusion devices, two sets of simulated ion implantation device, and a KUKA robot (KR6 R900). The overall design goal of this system is to simulate the production process of semiconductor manufacturing including material release, equipment maintenance, static scheduling, real-time scheduling, and online optimization process. This system will be integrated with the information and management system in order to improve production efficiency, energy conservation, and emission reduction.

Plan view of entity model of intelligent semiconductor manufacturing system by Tongji.
Other scheduling modeling methods
Baskett et al. 15 use Kelly network model to describe semiconductor manufacturing system. Workpiece arrival of the model is Poisson distributed, and first-in, first-out (FIFO) scheduling rule is applied. However, the real manufacturing environment can hardly satisfy the assumptions of Kelly network model. Billings and Hasenbein 16 build a fluid network model of semiconductor manufacturing system. The model has made some progress in the stability of the system, while suffers a limitation in the performance analysis of the manufacturing system.
Data-based modeling achievement in semiconductor manufacturing system
With the development of information technology, there brings rich data in information systems like ERP, MES, advanced production control (APC), and supervisory control and data acquisition (SCADA). The data contain a plentiful scheduling relevant knowledge, so data-based methods grow popular to be applied to solve complex scheduling problems, that is, to extract useful knowledge from related online/offline data to help to better construct the scheduling model. Meanwhile, data-based methods are actually using history rather than exploring feasible solutions from new data space which means they can save much computing resource and calculating time.
Data-based Petri net
Gradisar and Music17,18 collect data of layout of equipment in production line and process flow information of products, then maps them as a timed Petri net model. Some heuristic dispatching rules are adapted into the model; then, the scheduling performance indicators are evaluated. Mueller et al. 19 propose a method which can turn the data mapping of semiconductor manufacturing system into an object-oriented Petri model. The basic element of the model consists of production process of equipment, process flow information, equipment, and tool information. While batch process procedure, downtime of tool and equipment, and rework job are taken into consideration in this method, it subjects to a deficiency of over-simplification of the production line, and the non-zero state of semiconductor manufacturing system cannot fit into the model.
Dynamic simulation
Limited by simulation software platform, the structure of a simulation model is difficult to be modified to adapt to the physical manufacturing environment. Ye et al. 20 overcome this problem and propose a dynamic simulation modeling method. Based on the static and dynamic information of the production line, a discrete event simulation model is constructed dynamically which can reflect the actual processing condition. Its shortcoming is that the transformation of the data to the model is restricted in Plant Simulation—a specific simulation software. The generality of this conversion method remains to be further improved.
Prediction model
Through mining the knowledge within all kinds of data from the manufacturing system, we can uncover rules and patterns related to the attributes of production line. Combined with real-time online data, future production parameters or performance indicators can be predicted. The former are predicted to describe the state of production line more accurately to make it consistent with the physical manufacturing environment, while prediction of the latter is the basis of scheduling optimization, and it can help to better guide the production dispatch.
Processing time prediction
For processing time prediction problem, Baker et al. 21 forecast the runtime of the ion etch process with the monitoring data records of gas flow rates, radio frequency (RF) power, temperature, pressure, and DC bias voltage as the input of a neural network. We have also done some research in this area. We note that processing time of one work step, which includes waiting time, equipment adjusting time, pure processing time, and visual inspection time, is determined by the state of the machine, the attributes of silicon wafers, and the workers’ operation habit. The result is validated using real production data with a support vector regression (SVR) method. 22
Failure occurrence prediction
To predict production line failure occurrence to adjust model configuration, Susto et al. 23 propose the Kalman predictor and the particle filter with Gaussian kernel density estimator prediction techniques and compare their accuracy in monitoring wafer temperature to prevent the production of defective wafers. Kikuta et al. 24 integrate relevant information such as historical data and expert experience into knowledge management system to analyze the average fault recovery time of equipment in semiconductor manufacturing to improve the efficiency of maintenance.
Cycle time prediction
Chang et al., 25 Chen,26,27 and Chang and Liao 28 combine self-organization map (SOM) with case-based reasoning (CBR), back propagation network, fuzzy rule, and other methods to effectively improve the prediction accuracy of cycle time in semiconductor manufacturing. Meidan et al. 29 successively adopt maximal conditionally mutual exclusion method and selective naive Bayesian classifier for feature selection, and extract the most important 20 out of 182 factors which affect silicon wafer processing cycle time, and the prediction accuracy is effectively increased by nearly 40%. Chen and colleagues30–33 then improve their prediction methods and further deploy them in a cloud computing environment.
Industrial big data–based scheduling modeling framework in CPS condition
With the rapid development of information techniques, especially when sensors, data acquisition facility, and other intelligent sensing-abled equipment are deployed in the workshop, data produced throughout the entire manufacturing process strongly show the characteristics of volume, variety, and velocity of industrial big data. Take the case of semiconductor manufacturing process: 34
During quality detection process, each equipment generates several MB data just examining one piece of silicon wafer; one rapid automatic detection equipment collects nearly 2 TB data per year, and a 500-equipment-scale manufacturing system can produce some 102 TB data yearly.
Data are collected in different formats, for example, the running parameters of equipment from various systems and product processing time come as structured; bill of material, numerical control(NC) programs come as semi-structured, while three-dimensional (3D) model of the manufacturing system and wafer detection images are completely unstructured data.
Large volumes of sensor data produced during the manufacturing process are collected in real time via machine-to-machine (M2M) configurations. 35 Taking the etching equipment as an example, sensors of reaction chamber monitor temperature, pressure and flow data every 0.1 s, speed of data collection in complex manufacturing can reach at several hundred KB/s. 36
Under such circumstances and with these aforementioned characteristics, production data cannot be effectively utilized by current data management system, so CPS emerges as the next generation of intelligent management system. 37 It integrates computing, communication, and controlling and is the unity of virtual process and physical process. The system interacts with physical process through man–machine interface and use network space to remotely control a physical system in real time. In semiconductor manufacturing system, the physical world is the production line, and the cyber space is the scheduling model; these two interact with each other through all the information and management systems. In the past data-based age, data that can be utilized were merely offline MES data, and the data model cannot be updated with online data. While in CPS generation, all the manufacturing data acquired can be utilized: the unstructured and semi-structured data like process information, order information, dispatch information, and constraint information are used to establish the structure of the scheduling model; the continuously produced production data and sensor data are extracted and applied to update the parameters of the scheduling model. So theoretically, the scheduling model should coincide with the physical system and present all its manufacturing state of real time. The model is precise enough, and the dispatch result based on it can actually guide the production.
Scheduling modeling for complex manufacturing system consists of three steps: the first is to classify knowledge of the physical manufacturing system and establish the mapping from physical world to cyber space; then extract features like input/output, model information, and optimization information for modeling from the knowledge and build information models; the final step is the implementation of scheduling model. Figure 5 shows our industrial big data–based scheduling modeling framework.

Industrial big data–based scheduling modeling framework in CPS condition.
Take scheduling modeling of semiconductor manufacturing system as an example, at the knowledge extraction stage. All knowledge of the manufacturing system should be sorted into principle knowledge, expertise, and industrial big data. At the abstract modeling stage, complex adaptive system theory, semantic web, and other methods are used to extract features from the static and dynamic information from the first stage and transform them automatically into modeling input information (release strategy and dispatch rules), output information (performance indicators and dispatch plan), model structure and parameters (normal and abnormal state parameters), and optimization information (optimization methods). At the model implementation stage, a discrete event simulation modeling method is adopted to establish the execution model: simulation model is established by Plant Simulation, and the software platform is further developed to accomplish dynamic updating of the model. Data interaction between simulation model and manufacturing management system is achieved by service-oriented architecture (SOA), and big data analytic module is utilized to uncover the relationship within the data.
Establishment of the integrated scheduling model
The integrated scheduling model consists of the input, main body, output, and closed-loop optimization module. The release strategy and dispatch rules together compose the input of the model; the main body is made up of structure and parameter (local-state parameter), while the output of the scheduling model includes manufacturing performance indicators (global-state parameter) and the dispatch list. The closed-loop optimization module functions to control the key performance indicators in scope by adjusting the release strategy and dispatch rules. The structure of the main body is established by simulation software, while all the parameters within the model come from the database of the physical manufacturing system which interacts in real time with the production line. After all the deployment, we assume the scheduling model can be highly consistent with the physical manufacturing system, and the optimization solution derived from the model can be used by the physical manufacturing system in time (Figure 6).

Composition of scheduling modeling framework.
Prediction framework of parameters
The complexity and uncertainty of the large-scale complex manufacturing system result in a lot of uncertain factors in the manufacturing process, which are reflected by the changing of parameters in the scheduling model. In our framework, parameters are divided into local-state and global-state. The former indicates intrinsic characteristics of manufacturing equipment and workpiece, like processing time, transportation time, visual inspection time, which reflect the normal manufacturing state of the system and failure occurrence, and equipment maintenance can reflect the abnormal manufacturing state of the system. Some of them show static configurations of the system, while the others are dynamically changing with the manufacturing environment. The latter indicates descriptions of the overall state of the production line, including cycle time, throughput, rush order acceptance. All the parameters can be predicted by uncovering relationships within all the historical data in database, combining together with the real-time field data. The technical route is as follows (Figure 7).

Prediction framework of parameters.
The study and update mechanism of the dynamic model
As the manufacturing system runs, the state of the physical system varies with time, leading to the deviation between the cyber scheduling model and the physical manufacturing system. The scheduling model needs to be updated with the data from the physical manufacturing system so that parameters of the model can be adjusted to keep the scheduling model effective and accurate, and ultimately consistent with the physical manufacturing system (Figure 8).

Parameter drifting in scheduling model.
With the utilization of real-time data produced by the manufacturing system and through data integrated analysis, the corresponding parameters can be updated. First, we need to estimate whether a new category of data distribution of one certain parameter has occurred according to the real-time data. If not, then the prediction model established can still be used to update the parameter; if there occurs a new category, we need to establish a new prediction model which adapts to the new category to modify the scheduling model. The parameters can change in multiple trends, so big data analysis needs to be applied to estimate the adaptability of them to ensure the candidate value which can best describe the future developing trend of the model which will be selected. Then, the value will be filled in the scheduling model to complete its update. The updated scheduling model will guide the optimization manufacturing of the physical system.
Closed-loop optimization based on industrial big data
In the manufacturing process, the production state can be inconsistent with the desired state or the performance indicators are not within the desired interval, which means the system is in the situation of low production efficiency. In our industrial big data–based scheduling modeling framework, there are two ways for closed-loop optimization: (1) establish the local-state parameter prediction model with historical data (period t0–t1), predict the result of the parameter with real-time production state at time point t1, then dynamically load the parameters into the simulation model. By running the simulation model, we get the key performance indicators of our scheduling model at time point tn, compare them with the indicators of the physical manufacturing system at time point tn, and the deviation between them can be used as the basis of rescheduling; (2) establish the global-state parameter prediction model with historical data (period t0–t1), predict the result of the key performance indicators at time point tn with real-time production state at time point t1, compare them with the indicators of the physical manufacturing system at time point tn, and the deviation between them can be used as the basis of rescheduling.
When the deviation reaches a certain threshold, big data analysis is run to uncover the connection among production state indicators, processing area condition, and dispatch methods. The processing area resulting in such deviation will be detected, and the dispatch rules can be adjusted at time point tn + 1 to decrease the deviation of the physical manufacturing system (Figure 9).

Closed-loop optimization methods.
Application case
A CPS environment of MiniFab manufacturing system has been established in our laboratory as shown in Figure 10. In our demonstration unit of the intelligent semiconductor manufacturing system, the entity model which has been demonstrated in section “Entity model” simulates the physical manufacturing system while a full set of information system including a 3D demonstration model, a simulation model, and data processing software comprise the cyber space.

A demonstration unit of an intelligent semiconductor manufacturing system.
The physical system is designed and established as a real semiconductor manufacturing system as it can simulate the entire manufacturing process including material release, wafer grabbing, processing route selection, wafer dispatch (in or not in batch), and process menu switch. We leave out the wafer detection part because the system is virtually manufacturing silicon wafers rather than producing real ones, so the wafers are supposed to be processed perfectly by default. The entire physical system is driven by the control and execute system by different programmable logic controller (PLC) programs.
A 3D model as shown by the monitoring system is the exact mirror copy of the physical system. It can track the moves of the entity model and demonstrate visually on the screen in real time. The simulation model which controls the actions of the entity model is established based on Plant Simulation software. The parameters are preset as the configurations of the entity model and will change according to the data produced during the simulated manufacturing process.
The physical system and the cyber system are connected by the upper and lower computer system, and data like processing status of wafers and equipment, processing time, sensor data of the robot are collected and transported into the database in real time, which in turn can be extracted and processed as the parameters of the simulation model. After determining the processing status, we can select the optimization target like equipment utilization ratio or wafer cycle time and its optimization method. The simulation model will operate to obtain an optimized dispatch plan; then, the plan will be interpreted as PLC language and executed by the entity model. Meanwhile, the data collected will also be used to drive the 3D demonstration model.
In our future work of the demonstration unit, random failures will be programmed so that closed-loop optimization module can work. Data analysis and simulation will run to derive the most suitable dispatch plan for current processing environment. And now, as the 3D demonstration unit is driven by a discrete event software, it cannot actually synchronize all the movements of the physical system because they are continuous, that is also one of our main concerns.
Conclusion
Under the circumstances of ongoing development of Industry 4.0 and CPS, the developing information technology helps to enhance the automation of complex manufacturing systems. There is an increasing number of online industrial big data collected by the management system, and massive offline data are stored in the information systems, in which useful knowledge, rules, and optimal decisions for solving their scheduling problems are contained. We propose a novel industrial big data–based modeling framework and illustrate the framework by taking a semiconductor manufacturing system as an example. Our future work is to further improve the techniques used in this framework and apply the research results to the physical production environment.
Footnotes
Academic Editor: Muhammad Akhtar
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The National Natural Science Foundation of China (Project code: 71690234).