
Abstract
Rolling element bearings and gears are the most common machine elements. As they are extensively used in rotating machinery, their health conditions are crucial to the safe operation. The signals measured from rotating machines are usually affected by the working conditions and background noises. Thus, identifying faults from the mixed signals is a challenging and important task. Deep learning is initially developed for image recognition. Recently, it has attracted increasing attention in machinery fault diagnosis research. However, the generalization ability of the default classifier of it is not very satisfying. Thus, combining the feature learning ability of deep learning and the existing classifiers with satisfactory generalization ability is necessary. In this article, a hybrid technique based on convolutional neural network and support vector regression is proposed. The former part is used to promote feature extraction capability, and the latter part is used for multi-class classification. The efficiency of the proposed scheme is validated using the real acoustic signals measured from locomotive bearings and vibration signals measured from the automobile transmission gearbox. Results confirm that the method proposed is able to capture fault characteristics from the raw data, and both bearing faults and gear faults can be detected successfully.
Keywords
Introduction
The rotating elements such as bearings and gears are the essential parts of the rotary machine. Their health conditions influence the running state of these machines significantly. Rolling bearings and gears, which are the most fundamental and important elements of rotating machinery, are widely used in various industrial machines and are thus usually subjected to harsh working conditions. The faults of bearings and gears often cause machine breakdown, which subsequently stops the production and leads to catastrophic economic loss or even a disaster, so fault diagnosis is a challenging problem that has been continuously studied.1,2 The efficiency of fault diagnosis plays a highly consequential role in increasing the stabilization and the reliability of machinery and preventing catastrophes. Consequently, improving the methods for mechanical fault diagnosis has attracted considerable attention. Various condition-monitoring techniques, either through traditional signal processing algorithms or through newly up-to-date algorithms, are thus continuously produced.3,4
Traditional algorithms ordinarily include the following three essential processes: feature extraction, selection of sensitive fault feature, and identification of the fault pattern. 5 Feature extraction is the basis of fault diagnosis methods and is generally the first step in traditional algorithm. 6 Typically, the features extracted are statistical parameters. The dimensions of these parameters should be reduced so that the parameter can be processed further. In this regard, the principal component analysis (PCA) is one of the primary strategies that reduces dimensions as well as an unsupervised dimension reduction algorithm. Yang and Wu 7 employed PCA for the selection of a few significant principal components to present the dominated gears’ nature. The results showed that PCA can simultaneously enhance the diagnosis accuracy and reduce the feature. Six types of gear faults were used to verify the proposed method and showed that the PCA process exhibited a high accuracy in diagnosis and enhanced the computational efficiency of the artificial neural network (ANN). PCA was also used by Jiang et al. 8 when they presented the Gaussian mixture model and optimal principal components–based Bayesian method to generate lower dimension and be more efficient evidence. The former studies indicate that PCA generally serves as a fundamental method and research on it is significant. Other frequently used methods for the reduction of feature dimensions are the independent component analysis (ICA) and the distance evaluation technique (DET). 9 Han et al. 10 used ICA-based method to develop a fast algorithm which had a faster convergence speed and higher precision. That algorithm was integrated with the wavelet packet energy spectrum and can accurately recognize the slight damage and fracture of a bearing. Meanwhile, Guo et al. 11 proposed an adaptive fault diagnosis algorithm for rotating machinery. That method could acquire the segment of the signal which has the most demanded characteristics. These strategies are typically used to extract useful features, which can reflect the healthy state of the machine. Finally, the accuracy of the identification process for machine health conditions in the selected sensitive fault features can be further enhanced using diagnosis methods, such as wavelet transform, decision tree, and fuzzy logic. Classical methods based on wavelet theory have achieved considerable progresses in the last 20 years. Wavelets-based fault diagnosis methods including wavelet packet transform (WPT), discrete wavelet transform (DWT), and continuous wavelet transform (CWT) and their applications were already reviewed by Yan et al. 12
Although the fault diagnosis methods based on signal processing work effectively under actual applications, these methods rely on diagnostic expertise. Fortunately, artificial intelligence–based fault diagnosis schemes can potentially address this problem.
Recently, machine learning has become a significant topic of research. Machine learning provides many intelligent tools that can perform recognition and diagnosis, and it does not rely on an assumption of data normality. Current intelligent methods include boosting, 13 bagging, auto-encoder,14,15 support vector machine (SVM), 16 and deep learning, 17 such as deep belief network (DBN). 18
Studies on deep learning theory started to substantially increase after 2006. In this year, new age studies on deep learning were instigated when GE Hinton et al. 19 published his famously article. Deep learning is a class of techniques that can be used to identify objects, and deep learning methods usually have several or even hundreds of hidden layers. From each layer, the features containing fault characteristic information can be extracted and collected and then used as the input for the subsequent layer. 20 An advantage of nonlinear relation between input and output is the automatic transformation of the feature with low dimension into a corresponding abstract representation with high dimension. 21 Deep learning overcomes the reliance on prior knowledge for the extraction and selection of the suitable features and the diagnostic expertise. This automatic feature extraction capability can reduce the need for human labor and enhance the effectiveness and competitiveness of deep learning.
Convolutional neural network (CNN) is one of the principal models of deep learning. 22 Traditional CNN belongs to supervised learning and is a forward pass neural network. It is normally trained by the back-propagation (BP) algorithm, which may be computed using a stochastic gradient descent (SGD) technique. In a CNN model, the units belonging to a map undergoes weight sharing, that is, they share the same filter bank. Weight sharing, which is the highpoint of CNN, is used to increase the calculation and efficiency. CNN can obtain higher-level features through its deep architecture which is stacked hierarchically layer-by-layer. Similar to ANN architectures, the last but one layer of CNN is a fully connected layer. CNN is extensively used in diverse domains, such as image classification, 23 speech recognition, 24 language understanding, 25 fault diagnosis, 26 and other application fields. 27 However, these classic CNN models usually use a softmax classifier, which has a common generalization ability, as its top layer. 28
The SVM and its extension support vector regression (SVR) are commonly used in machine learning. In 1995, Vapnik 29 introduced the supervised learning computational approach, SVM, to analyze data and recognize patterns. The SVM classification algorithm is a promising method because it has been successfully applied in various engineering fields, such as data mining and mechanical fault diagnosis. It has a powerful generalization capability even without a large number of samples. Jegadeeshwaran and Sugumaran 30 used descriptive statistical features and SVM for fault diagnosis of the automobile hydraulic break system. In that article, the statistical features were extracted first and then were selected in the order of importance by a decision tree, which needed much more additional work. Erfani et al. 31 developed a hybrid model based on deep learning and a one-class SVM for high-dimensional and large-scale anomaly detection. In that article, the deep learning algorithms including the DBN and the auto encoder are studied. The one-class SVM-based hybrid model performed well but the one-class SVM had a limitation in the face of multi-class classification. Sun et al. 32 predicted the life of a bearing using an SVR-based process. The vibration signal features were also selected first before input to the SVR, although the proposed method is applied to the actual bearing data with a good performance. Qin et al. 33 optimized the parameters of SVR by adopting the particle swarm optimization and they applied the optimized method to the prognostic of lithium-ion batteries degradation experiment data. The results showed the improvement of the robustness and generalizability from limited data to long-term prediction. As a summary, SVR, as a classifier, has shown its great generalization ability.
CNN has shown its powerful ability to extract information and useful features. But the default classifier, softmax classifier, has a common generalization ability while the SVR has a relatively better performance. So it is necessary and meaningful to carry out such a research on these two methods. Hence, a novel supervised intelligent fault detection technique combined with CNN and SVR is proposed. The former part of this new model is worked as a feature extractor and the latter part worked as a classifier. This hybrid architecture is constructed by replacing the top layer of the traditional CNN with an SVR classifier. The signals are first processed by the CNN to obtain the features, which are extracted from the last hidden layer of the CNN. The extracted features are then inputted to the SVR, which is situated at the top of the model for classification. The new model is applied to detect the fault patterns of real acoustic signals measured from locomotive bearings and vibration signals measured from a gearbox. The performances of the CNN and SVR have improved in rotating machine fault detection when they were combined. Compared with the results of fault recognition obtained by traditional CNN, the results confirm that the proposed method is able to obtain the generic underlying characteristics of the raw data and achieve a high accuracy for both bearing fault detection and gear fault detection.
The remainder of this article is organized as follows. In section “Theoretical background,” the basic theories of the CNN and the SVR are presented concisely. Section “Proposed hybrid method” presents the proposed hybrid structure in detail. The experimental validation tests using bearing and gearbox data sets and a comparison between the proposed method and the traditional CNN are demonstrated in section “Effectiveness of the proposed algorithm.” The conclusion is summarized in section “Conclusion.”
Theoretical background
CNN
The CNN is as a prominent deep architecture of deep learning. CNN includes multiple layers of representations. Due to this deep structure, CNN can automatically obtain the representation characteristic from the raw data through nonlinear transformations and approximate nonlinear functions.
A typical CNN structure consists of a feature extractor which is composed of several convolutional layers usually followed by pooling layers and a softmax classifier. The convolutional layer extracts signal features, whereas the pooling layer reduces the dimensions and thus further reduces the computation time. This architecture can attain a form of regularization by itself. The features extracted are then put into the top softmax layer for classification. The theoretical basis of automatic feature extraction is described in the following.
Feedforward process
The supervised multi-class problem which CNN is going to solve is described as follows: let

where
However, the space of hypotheses is restricted to some set F to minimize the set of all functions from S to Y easily

CNN solves equation (2) through several stages. In the first stage, S passes through a series of convolutional filters and simple non-linearity. Data S is first put into the convolutional layer, and each subsequent layer


where

Mj represents the jth layer map.
The second stage of the solving process is using a subsampling layer applied pooling function. The aim of the pooling layer is to merge features of the same semantics into a single feature. Through this merging, the dimensions are reduced. After pooling, although the size of the feature map is reduced, the number of feature maps is unchanged. The subsampling function is

where down(·) represents a subsampling function;
At the top of a classical CNN model, there are a fully connected layer and a softmax classifier. Figure 1 has shown the architecture of a classical CNN.

Architecture of a CNN.
BP process
The optimization problem of CNN is highly nonconvex, and thus, the BP algorithm is usually implemented to compute gradients. In addition, the SGD is used to update the weights
The errors calculated by BP from the network can be regarded as sensitivities. It is the gradient of each unit and is defined as follows
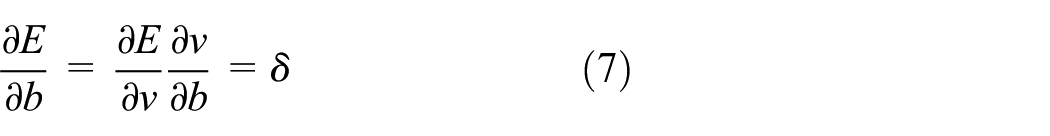
This is the key point of the back algorithm propagated from higher layers to lower layer. The calculations of the gradients for the lth layer (l < L) and layer L are shown in equation (8) and equation (9).


where ∘ denotes the element-wise multiplication.
Then the weight can be updated using the


where
The BP algorithm is briefly described in the flowchart in Figure 2.

The flowchart of the BP algorithm.
SVR
The SVR can be adopted as a multi-class classification strategy. In contrast to SVM, it can address multi-classification problems. The SVM is developed by Vapnik 36 and is proven to be an extremely robust and accurate supervised learning modus. Notably, the SVM has a fine theoretical foundation rooted in statistical learning theory. Nevertheless, the SVM is designed for two-class learning problems. It requires complementary strategies for multi-classification processes, and thus, the diagnosis becomes complicated. The SVR is an upgraded version of the SVM, and it is suitable to deal with the time series prediction. The theory of SVR is developed based on the basis of the SVM principles. 37
Let
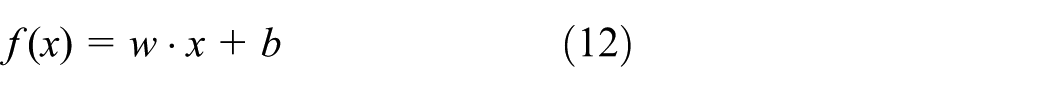
where x is the support vector, w is the weight parameter representing the orientation of the hyperplane, and b is the bias, which means a scalar threshold.
The ε-insensitive function in equation (14) is introduced into the support vector model to promote a robust estimator insensitive to slight changes, such as ineffective performance due to the presence of outliers. A kernel strategy is used to deal with nonlinear tasks. Through the kernel function, data can be mapped to a feature space with higher dimensions, and then it can be regarded as linear. In this research, the kernel function is the radial basis function (RBF). 38 Its calculation formula is expressed as follows

where

where
The optimal problem of SVR is
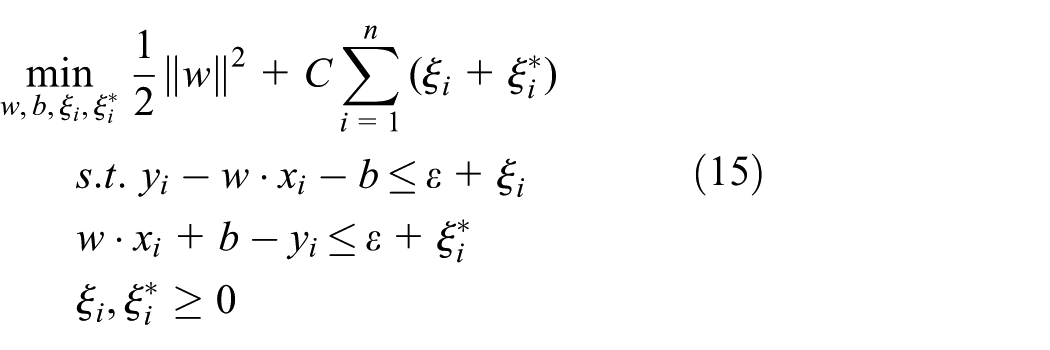
where w is the weight vector,
The Lagrange multipliers are introduced to solve the previous problem. At this point, a Lagrange function is constructed as follows

where
Differentiating

The problem becomes a convex quadratic programming optimization problem by substituting equation (17) into equation (16) and transforming the problem into its corresponding dual problem, as follows
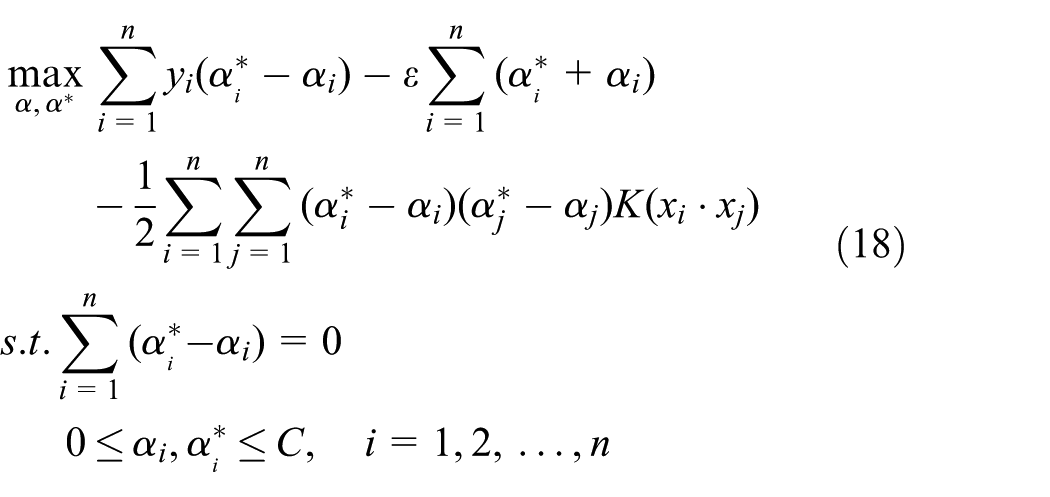
The convex quadratic programming optimization problem in equation (18) can transform into a global optimum issue by adopting the sequential minimal optimization (SMO) algorithm which is an optimization technique. 39 Simultaneously, the Karush–Kuhn–Tucker (KKT) condition is satisfied. As a result, the convex optimization approach is a notable property of SVR. This approach ensures that a local solution is also the global optimum. That enables the SVR a better generalization ability which can achieve a high accuracy for the training and testing samples.
The f(x) which is the discriminate function that can predict the output

Based on the assumption that samples from the same pattern have similar outputs from the SVR, an SVR classifier can be constructed and the tested sample can be classified to class m when the tested sample satisfies the following function

Proposed hybrid method
The proposed hybrid model named CNN-SVR for fault diagnosis is a combination algorithm based on CNN and SVR theories. The CNN part is used as a feature extractor and the SVR as a classifier. In this model, constructing the hybrid architecture is the first step. During the construction, the top layer of the traditional CNN is replaced with an SVR classifier.
The new model is stacked layer-by-layer with convolutional layers and pooling layers inside. As shown in Figure 3, the structure combined of 10 layers totally, including the input layer, three convolutional layers, three pooling layers, two full-connected layers, and a support vector regressive classifier as the top layer.

Structure of the hybrid CNN-SVR model.
In Figure 3,
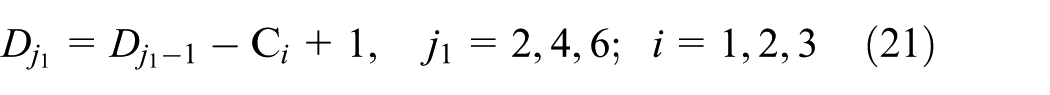


where
In the particular CNN-SVR model, the parameters are set as follows: the input layer size
The raw signal from the data set is used as the input. At the start of the training stage, the raw data from the original data set are transformed into a matrix with several dimensions, and then the matrix is inputted to the visible first layer. The progress of the feature maps is the same as that defined in equation (5) of section “CNN.” The pooling layer next to the convolutional layer uses the max-pooling rule, that is, the pooling layer selects the largest coefficients over each sampling cell to reduce the dimensions by half. The feature map of the pooling layer is generated through equation (6) of section “CNN.” Other convolutional and pooling layers are constructed through the same procedures. The output from the last pooling layer is inputted to a full-connected layer with an output of 100 dimensions. Moreover, this output is used to extract features from the original signals. The learning process of this layer by layer-by-layer network can be reduplicated many times according to the requirement.
To specially note that in the proposed method, a sparse regularization penalty
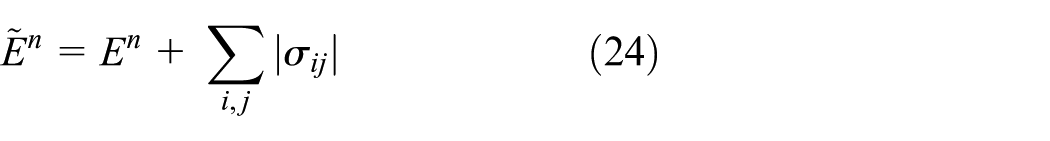

Figure 4 shows the algorithm flowchart of this method. A summarized CNN-SVR algorithm involves the following steps:
Step 1. Input the data from the prepared data set and convert the signal vector into a matrix.
Step 2. Initialize the parameters, such as the total numbers of layers, the maximum epoch of iteration, the learning rate, the matrix of W, and the vector of b.
Step 3. Implement convolution and pooling.
Step 4. Fine-tune the stacked model using the optimized algorithm.
Step 5. Finish the optimization and acquire the features of the data set.
Step 6. Use the extracted features for classification by SVR.

Algorithm flowchart of the CNN-SVR.
The fine-tune approach is conducted by the BP algorithm as described in section “BP process.” In detail, the supervised SGD is used to adjust the parameters of the hybrid model. Specifically, it first calculates the error between the output vector and the actual target vector, then obtains the loss function and the error of parameters. Using the SGD algorithm to get the gradients of the loss function and update the weights in corresponding layers. In addition, the SGD can further reduce the training error and promote the classification accuracy. In this study, stochastic gradient descent with mini-batches (MSGD) is accepted to make the learning process more efficiently.
In the proposed CNN-SVR model, the other related critical parameters are set as follows: the learning rate is 0.01, the total epoch iteration is 6000, and the mini-batch size is 100. The weight is randomly initialed and trained for optimization.
Effectiveness of the proposed algorithm
Experiment 1: locomotive bearing fault diagnosis
The rolling element bearing is the most common and essential component of rotating machinery. For the verification of the effectivity of this scheme, the bearing data measured from the locomotive are used.
Experiment equipment and data set
The rolling bearing data are obtained from an experimental platform, as shown in Figure 5. This experimental device consists of a laptop, a microphone, a testing bearing, a mechanical loading unit, a drive motor, a load display, a signal conditioner, and a data acquisition system (DAS). The bearing for testing is a kind of cylindrical roller bearing. Its type is NJ (P) 3226X1. It is mounted on the outer race. In its radial direction, an adjustable mechanical loading unit is installed. 40 Table 1 lists the specifications of the bearing. The acoustic signals are collected through a 4944-A type microphone produced by the Brüel & Kjær Company (Copenhagen, Denmark). The microphone is placed near the bearing in a radial direction.

Experimental platform for bearing test.
Specifications of the testing bearing.

In this experiment, one normal bearing and three faulty bearings have been tested. The defect introduced into each faulty bearing is an artificial mark with a width of 0.18 mm. The defect is marked at the inner race, the outer race, and the rolling element, as shown in Figure 6. The collected acoustic signals were designated according to the kinds of rolling bearings, as follows: normal bearing (Norm), bearings with inner race fault (IF), rolling element fault (RF), and outer race fault (OF). All the signals are tested under the following conditions: rotor speed of 1430 r/min, 2.5 t loading, sampling frequency of 20 kHz, and sampling rate of 5000 points per second.

Defect setting of (a) inner race, (b) outer race, and (c, d) rolling element of the test bearing.
A group of experimental data constructed the Bearing Dataset. The composition of this data set is illustrated in Table 2. In total, 300 samples for each bearing condition are obtained. Of the 300 samples in each condition, 150 are selected randomly for training and 150 are selected for testing. Overall, 600 samples are used for training and 600 samples are used for testing.
Information of the Bearing Dataset.

Norm: normal bearing; IF: bearings with inner race fault; RF: rolling element fault; OF: outer race fault.
Diagnosis results
The time domain signals of different bearing statuses are shown in Figure 7. The differences among the four signal shapes are evident. However, distinguishing the condition of the bearing directly according to these variances is difficult. Therefore, the proposed method is used to analyze the fault patterns of the automotive bearing set.

Acoustic signals of different bearing health conditions.
The current experiment is performed under different health conditions. The performance under each bearing condition is shown separately in Figures 8–11 for clarity. Only two samples in the testing process of the normal bearing are misevaluated. All the other samples are categorized correctly both in training and testing processes. Moreover, the gather degree is quite higher. The average accuracy of the 10 times repetitions of the bearing data set is listed in Table 3. The average accuracies of the training and testing processes using the proposed method are both extremely high. Moreover, the accuracy of each condition is also listed in Table 3. The testing accuracy of the normal bearing is slightly lower. Nearly all of the data samples are classified correctly as indicated by the high accuracies. The new method not only digs generic fault characteristics of the rolling element bearings from different statuses adaptively but also exhibits a robust classification capability, thus producing good results.

(a) Training and (b) testing results of normal bearing (Norm).

(a) Training and (b) testing results of inner race faulty bearing (IF).

(a) Training and (b) testing results of rolling element faulty bearing (RF).

(a) Training and (b) testing results of outer race faulty bearing (OF).
Accuracy of different bearing conditions.
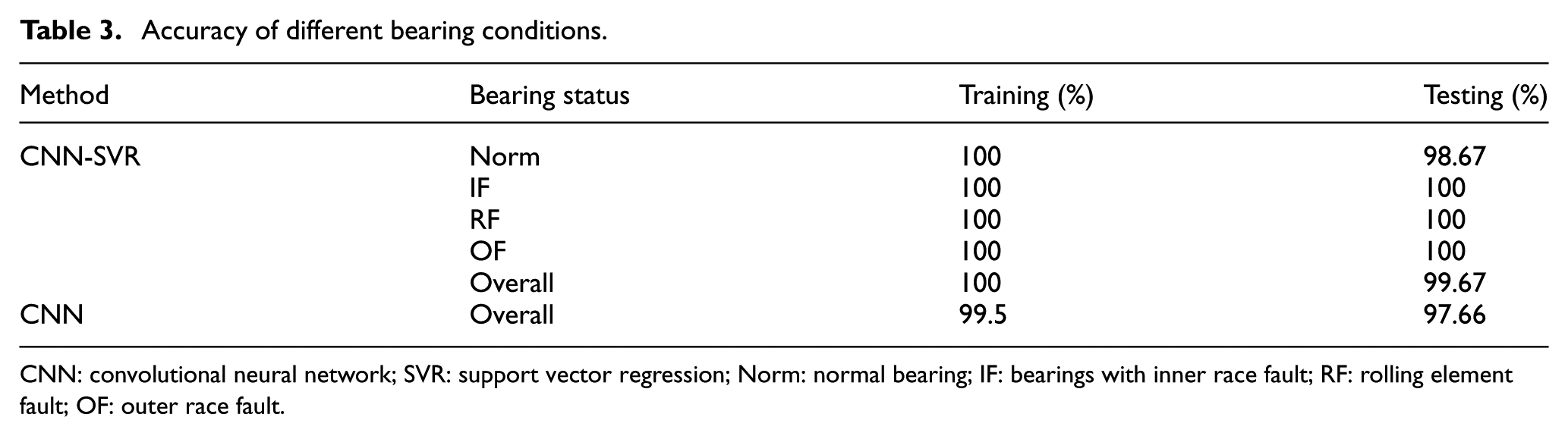
CNN: convolutional neural network; SVR: support vector regression; Norm: normal bearing; IF: bearings with inner race fault; RF: rolling element fault; OF: outer race fault.
For comparison, the traditional CNN, which contains a softmax layer as its classifier, is also used to deal with this data set. In addition, four bearing types, abbreviated as Norm, IF, RF, and OF correspondingly, are used. Similarly, half of the data are randomly selected for training and the other half are used for testing. The CNN has the same architecture as that of the proposed method, and thus, it can be trained using the same parameters. The accuracies of the training and testing processes are 99.5% and 97.66%, respectively, as shown in Table 3. The overall accuracies of the proposed technique are 100% for training and 99.67% for testing. For the visualization of the comparison, the diagnosis results of the training and testing processes using CNN are shown in Figures 12 and 13. The above results and comparison show that the new method can accurately identify the bearing fault categories and exhibits superior accuracy.

Diagnosed results of training samples by CNN.
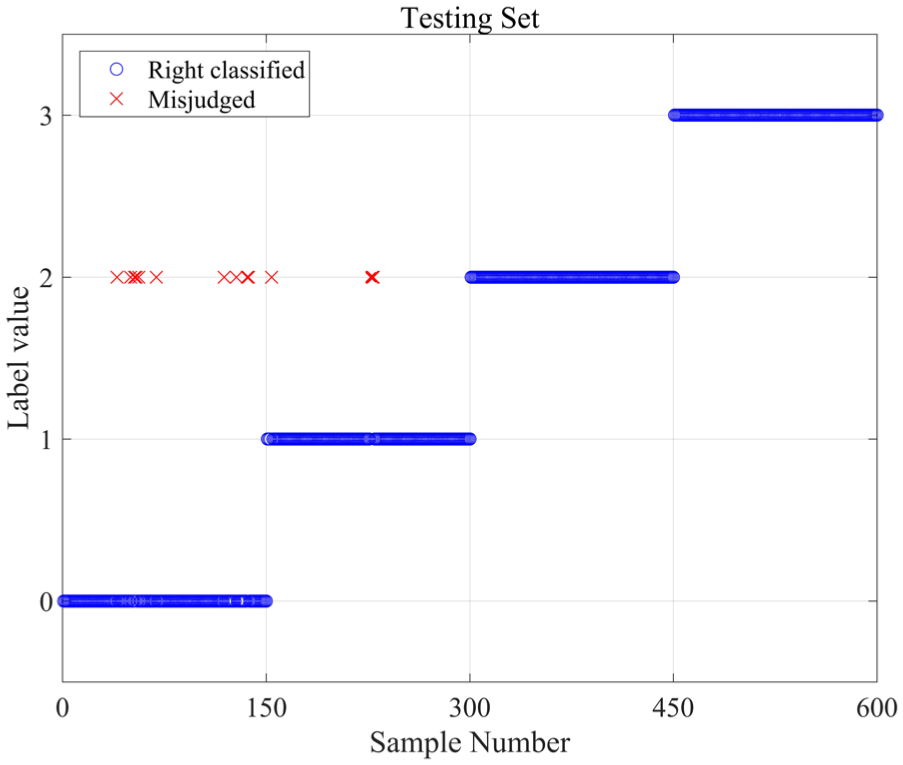
Diagnosed results of testing samples by CNN.
Experiment 2: automobile transmission gearbox fault detection
Experiment equipment and data set
The CNN-SVR algorithm is also validated using the gear fault data of an automobile transmission gearbox, as shown in Figure 14. The gearbox consists of one backward speed and five forward speeds. The vibration signals are measured by an accelerometer, which is mounted on the gearbox shell. The number three gears are used as testing gears for the wear process. The signals are measured during the forward motion of the automobile. The third gear teeth numbers of the driving gear and driven gear are 25 and 27, respectively. Their corresponding meshing frequency is 500 Hz. The rotating speed is 1600 r/min, and the sampling frequency is 3000 Hz. Five different running periods of the gearbox are listed in Table 4.

Experimental platform for gear test.
Information of gearbox under different running periods.

The Gear Dataset consists of four different status gear states. The four kinds of fault components are slight wear, medium wear, broken tooth, and normal wear, which are labeled as 1, 2, 3, and 4, respectively. Half of the samples in each condition is randomly selected for training and the other half is for testing. For each condition, the training and testing processes each uses 30 samples. The information of the Gear Dataset is shown in Table 5. The time domain signals of each gear state are shown in Figure 15. Judging the fault types directly from time domain signals is difficult.
Information of the Gear Dataset.

Vibration signal for different gear conditions: (a) slight wear, (b) medium wear, (c) broken tooth, and (d) normal wear.
Diagnosis results
The diagnosis results obtained through the proposed algorithm are shown in Figures 16 and 17. All the samples of the training and testing processes are classified to the right fault type correctly. Although several samples are slightly decentralized from the actual label distribution, they have been judged to the right class eventually. This fine performance is mainly due to the generalization capability of SVR classifier. The overall accuracy is the average accuracy of 10-time repeats of this learning procedure. The average overall accuracies are 100% for both training and testing processes. The results imply that this model has a good ability to achieve high accuracy for gear fault diagnosis.

The diagnosed results of training samples of Gear Dataset.

The diagnosed results of testing samples of Gear Dataset.
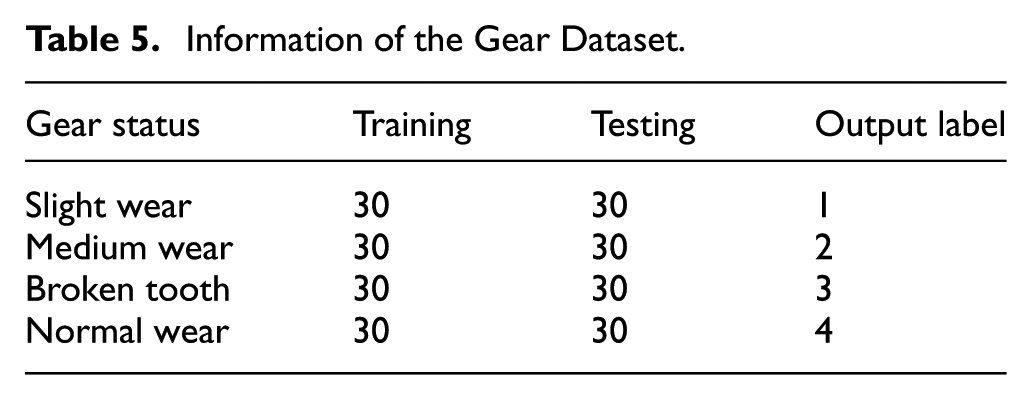
Similarly, the traditional CNN using a softmax classifier is used to distinguish the fault types for algorithm comparison. The results are shown in Figures 18 and 19. The overall accuracies are 99.16% for the training process and 98.33% for the testing process. The contrast results of the separate conditions are also contrasted, as shown in Table 6. The results imply that both of these two methods can achieve a high accuracy when detecting the gear faults. The CNN-SVR model obtains a higher diagnosis accuracy and shows better robustness compared with the traditional CNN model.
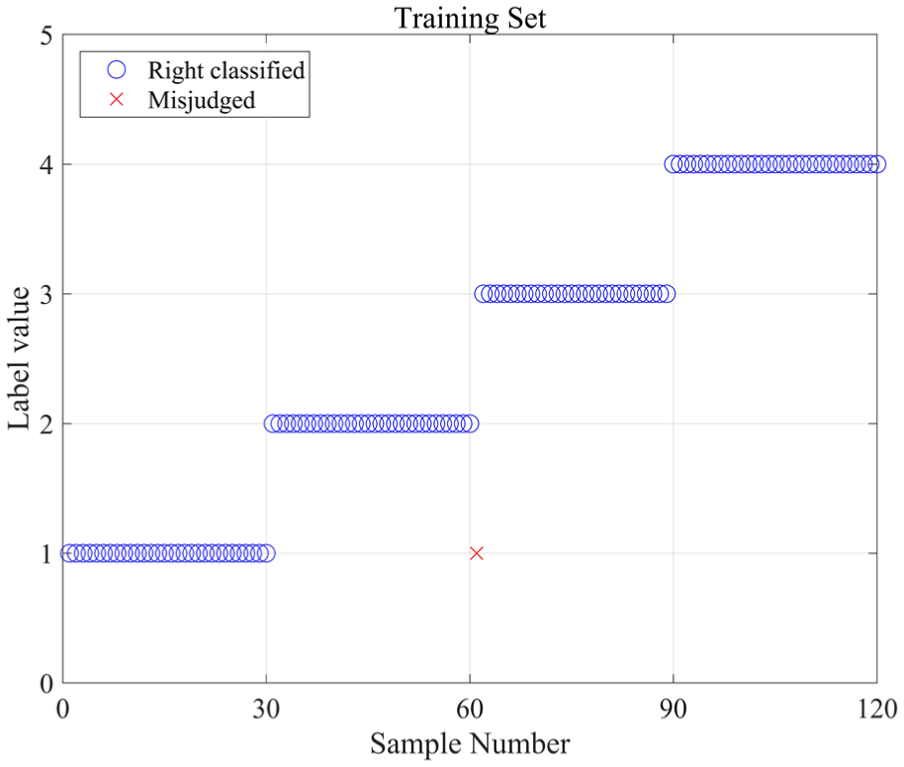
The diagnosed results of training process by CNN.
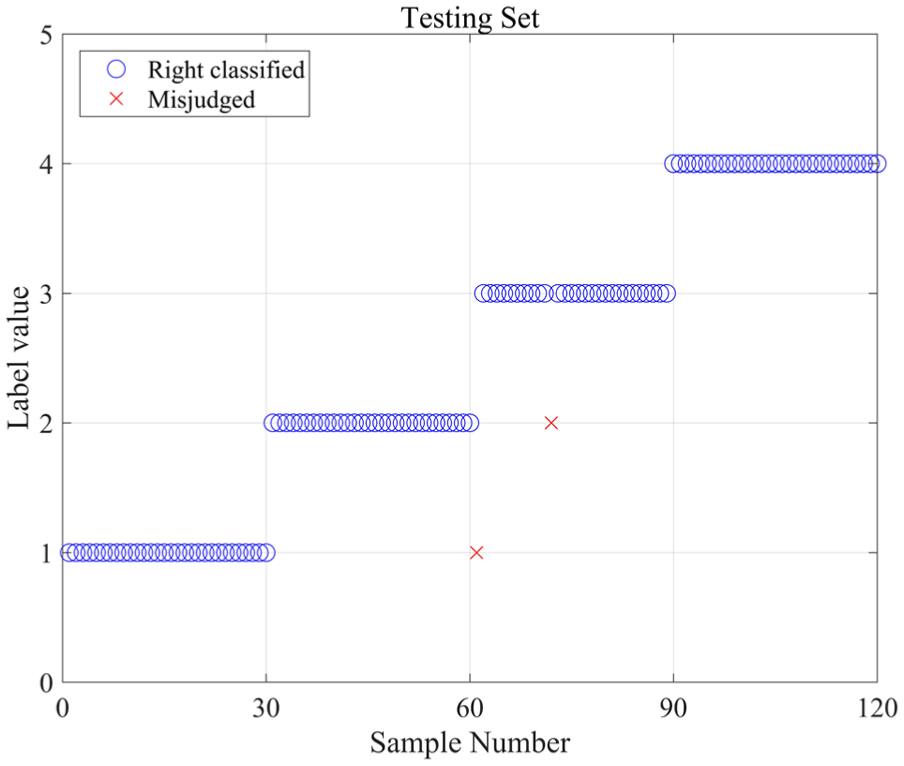
The diagnosed results of testing process by CNN.
Accuracy of different gear conditions.

CNN: convolutional neural network; SVR: support vector regression.
Conclusion
In this article, a hybrid intelligent technique based on CNN and SVR is proposed for fault pattern recognition in rotating machinery. This is a new combination of CNN and SVR which utilize the advantages of both methods. Then, from the raw time domain signals, features are extracted directly for the diagnosis of either bearings or gears. It saves a lot of manual work to extract and select the features and further accelerates the computation. Specifically, the effectiveness of the proposed fault diagnosis method is verified by both rolling element bearings data and gearbox data. The rolling bearing data are acoustic signals measured from real locomotive bearings, while the gear data are vibration signals measured from an automobile transmission gearbox. The results of the diagnosis show that CNN-SVR method is capable to extract the generic underlying characteristics from raw signal data. Moreover, this model can successfully distinguish the health status of the rotating elements. The validation results show that this new method can achieve a high precision for both the bearing fault diagnosis and the gear fault diagnosis. It is more accurate than the original CNN model. The good performance of the CNN-SVR method is mainly due to the superiority of the hybrid method, which combines the strong points of deep neural architecture and the powerful generalization of SVR. In summary, this hybrid technique has a good capability to extract useful features from raw time domain signals and exhibits a strong robustness in fault diagnosis. Last but not least, due to its ability to mine the fault characteristics from original time domain signals mechanically, the proposed approach does not rely on manual labor or the prior knowledge of signal processing manners and diagnostic expertise. Therefore, fault diagnosis applications of rotating machine can be achieved easier using the proposed method.
Footnotes
Acknowledgements
The authors would like to appreciate two anonymous reviewers for their constructive comments and suggestions.
Academic Editor: Dong Wang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was financially supported by the National Natural Science Foundation of China (grant nos 51505311 and 51375322), the Natural Science Foundation of Jiangsu Province (no. BK20150339), and the Innovative Research Project for Postgraduates in Colleges of Jiangsu Province (project no. KYZZ16_0085).