
Abstract
Load extrapolation is the paramount step in compiling load spectra of the mechanical components. To avoid the limitation of the stationary processes in parametric extrapolation methods, the non-parametric extrapolation method is widely investigated in recent years. However, the accuracy of kernel density estimation of the large load cycles in existing non-parametric methods should be still improved. Aiming at this issue, a non-parametric rain-flow extrapolation method based on load extension is presented. In this method, combining with non-parametric extrapolation model and Markov chain Monte Carlo method, the measured load–time histories for semi-axle in different operating sections are extended and extrapolated. The extrapolated load spectra curves and the relative damage ratio are compared with the results obtained by the existing rain-flow extrapolation methods. The results show that the proposed method can realize the reasonable extrapolation of load–time histories.
Keywords
Introduction
Engineering vehicles such as mining truck, wheel loader, excavator, and pump truck are widely used for material exploitation and industrial construction. These vehicles always undertake heavy tasks and work in harsh environments. Particularly, the wheel loader will experience load change frequently during the operation of spading and loading. Hence, fatigue failure of the components of wheel loader often occurs. 1 Fatigue life test and prediction based on the load spectra are topics that have received continuous attention. Since the load measurement for wheel loader is very time consuming and of high cost, only short-term load–time histories (L-THs) can be obtained. However, the short-term L-THs do not contain the full-load characteristics in the whole service life. In order to use the measured L-THs to the fatigue test, load extrapolation is indispensable in the process of load spectra compilation.
The rain-flow counting method 2 is used to convert the measured L-THs into load cycles in rain-flow domain before load extrapolation. Recently, there are a variety of extrapolation methods for load cycles, such as parametric method and non-parametric method. 3 For the parametric rain-flow extrapolation (PRFE) method, probability distributions of load range and mean should be known.4,5 Considering the limitation of unimodal distributions in describing load statistical characteristics accurately, multi-modal distributions were applied to load extrapolation.6,7 Along with the wide use of non-parametric density estimation methods, a non-parametric rain-flow extrapolation (NPRFE) method based on kernel density estimation (KDE) was put forward. 8 To extrapolate large load cycles, extreme value theory was applied and a limiting rain-flow extrapolation (LRFE) method was proposed.9,10 Furthermore, an NPRFE method which involves the modification of extrapolated load values was studied. 11 In the modification process, Weibull distribution was used to fit load spectra curves. Besides, an evaluation criterion based on multi-criteria decision-making technology was provided to select the most appropriate model from the existing KDE models for NPRFE. 12
Compared with parametric models in the PRFE and LRFE, KDE model may be more suitable for the extrapolation of complex and random loads. It is data-driven as it does not need to make a hypothesis distribution for load samples and then the probability density of estimation point is obtained. However, the accuracy of KDE will be decreased if the load samples are not enough. 13
In order to extrapolate the measured L-THs with different amplitudes reasonably, NPRFE method based on load extension is proposed. First, considering the choice of kernel function, adaptive bandwidth matrix, and bandwidth calculation method, NPRFE model based on full bandwidth matrix (FBM) is built. Then, Markov chain Monte Carlo (MCMC) method is applied to extend the measured L-THs to obtain the optimal probability density by KDE. Based on this optimal probability density, the measured L-THs can be extrapolated with the anticipative fold. Furthermore, the measured L-THs for the semi-axle of a wheel loader are extrapolated. The validity of proposed method is evaluated through the extrapolated load spectra curves and relative damage ratio (RDR).
NPRFE modeling
The density estimation of the measured L-THs based on KDE is a critical step in NPRFE. Suppose that f is the probability density of d-dimensional random vector

where
Selection of kernel function
The standard probability distribution functions are often selected as kernel functions. The shapes and expressions of univariate kernel functions, which are commonly used, are shown in Figure 1 and Table 1. They express the influence extent of data near the density estimation point. To select an appropriate kernel function, a mixed normal density function is estimated by different kernel functions with adaptive bandwidth calculated by L-stage direct plug-in (LDPI) method. 14 Obviously, the KDE results (see Figure 2) are almost the same. Here, Gaussian kernel is selected in KDE model for load extrapolation. The expression of bivariate Gaussian kernel is

With equations (1) and (2), the KDE of


Shapes of different univariate kernel functions.
Expressions of different univariate kernel functions.


KDE by different kernel functions with adaptive bandwidth values.
In order to study the influence of different bandwidth values on KDE accuracy, the above mixed normal density function is estimated based on Gaussian kernel and different bandwidth values. As shown in Figure 3, the estimated densities are close to the real values only when bandwidth is adaptive and reasonable; otherwise, it would result in a great error. In fact, the selection of bandwidth value cannot guarantee that the deviation and variance of KDE decrease at the same time. If the bandwidth value is too small, the data near estimation point will get a large probability, which will lead to small deviation but large variance. While the bandwidth value is too large, a wide range of data will have an effect on estimation point, which will lead to small variance but large deviation. 9 Since a bandwidth that is too large or too small will result in the decrease of KDE precision, the bandwidth is a key parameter in KDE model.
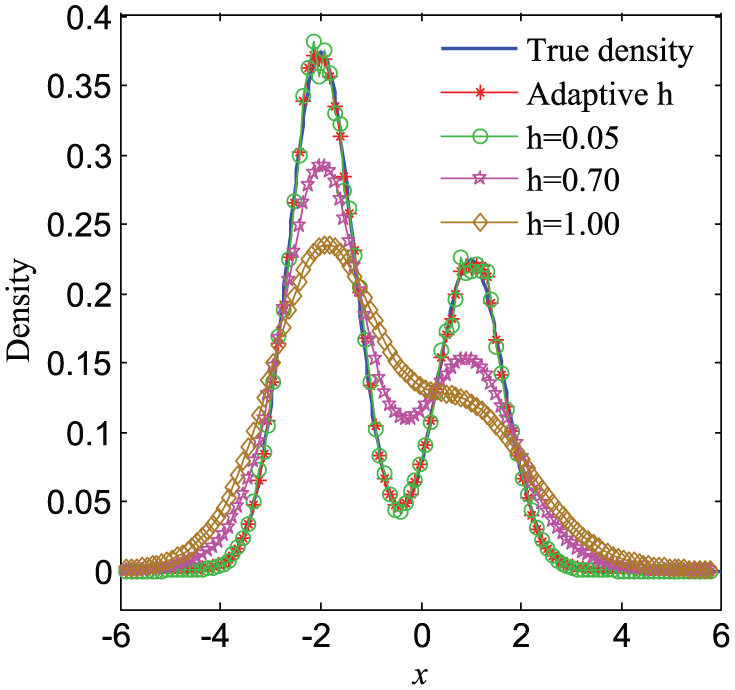
KDE by Gaussian kernel with different bandwidth values.
Determination of adaptive bandwidth matrix
The bandwidth matrix in bivariate KDE model can be selected from the following three forms: 15
Single bandwidth matrix (SBM):
Double bandwidth matrix (DBM):
FBM:
Comparing with



where
To guarantee the KDE precision of the measured L-THs, bandwidth values should be different in the sparse and dense areas. Thus, an adaptive factor

where
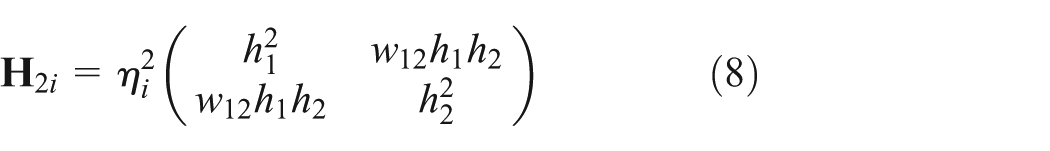
With equations (3) and (8), the adaptive KDE model is given by

Comparisons of the calculating methods of bandwidth
To select the optimal calculating method of the bandwidth values
First, samples with size N (N = 20, 50, 100, 200, and 500) are generated randomly from the above four bivariate density functions. Then the densities are estimated by KDE with 100 repetitions. The results are shown in Table 2. It is observed that the mean values of root-mean-square error (RMSE) in ROT are larger than those in other calculating methods. To compare the calculation results of the above methods visually, the box plots of
Mean values and standard deviation values of RMSE in parentheses based on 100 repetitions for four bivariate density functions.

RMSE: root-mean-square error; LSCV: least squares cross-validation; BCV: biased cross-validation; ROT: rule-of-thumb; LDPI: L-stage direct plug-in.

Box plots of
In addition, the comparison of computation time of four calculating methods is shown in Table 3. It shows that LDPI and ROT are less time consuming than LSCV and BCV. Combining the KDE accuracy and the computational efficiency, LDPI method is selected to calculate the parameters
Comparison of computation time of four calculating methods.

LSCV: least squares cross-validation; BCV: biased cross-validation; ROT: rule-of-thumb; LDPI: L-stage direct plug-in.
NPRFE method based on load extension
The KDE precision and load extrapolation accuracy are influenced by load samples as well as the NPRFE model. Only when the load cycles are enough, the KDE precision can be guaranteed. Compared with medium and small load cycles, large load cycles will lead to a large amount of fatigue damage although it does not occur frequently (see Figure 5). Thus, MCMC simulation is used to extend the measured L-THs to improve the KDE precision and extrapolation accuracy of load cycles.
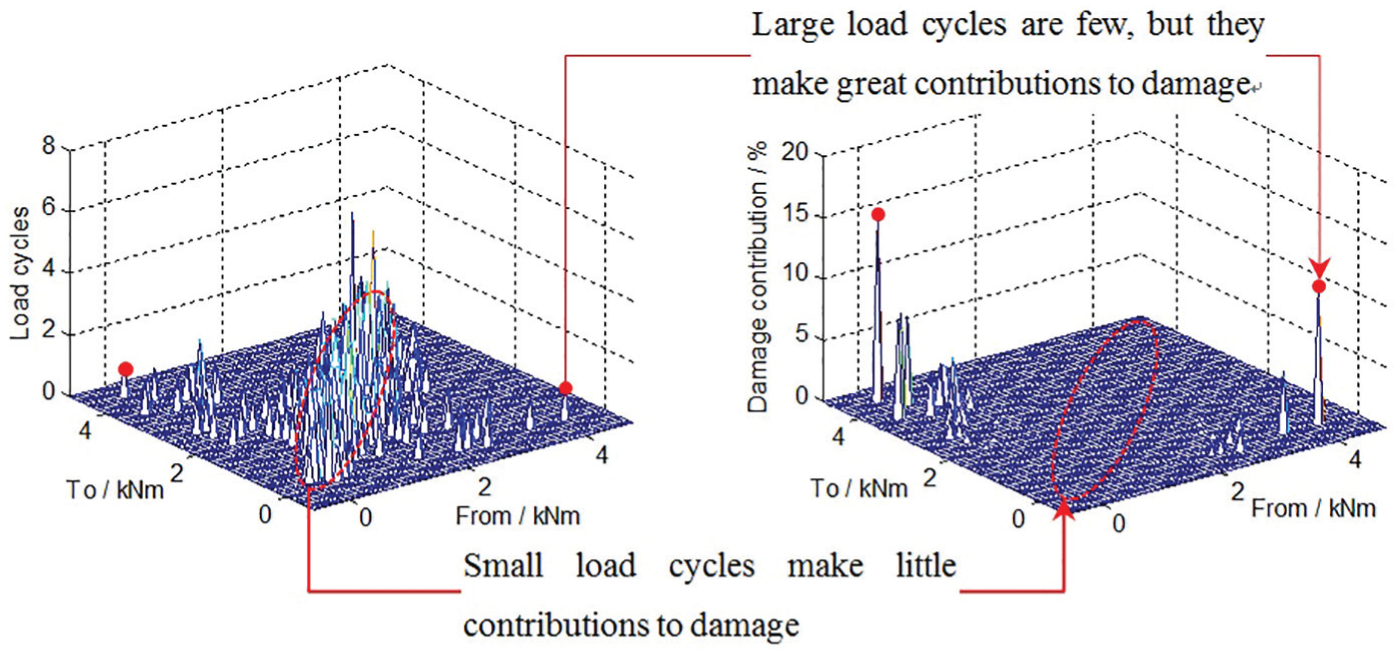
Damage contributions of different load cycles.
Brief overview of MCMC simulation
For arbitrary

where

Thus, the homogeneous one-step state transition probability
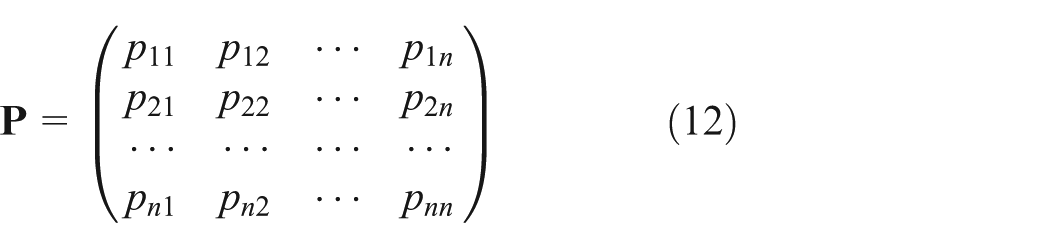
Regarding the measured L-THs for semi-axle, the Markov chain model can be created by extracting turning points 26

where
According to the load cycles counting, Markov matrix

Then the stationary distribution of Markov chain model is created by calculating the one-step transition probability, and the extension of random load samples based on Monte Carlo is obtained.
Extrapolation of the extended load
The steps of NPRFE method based on load extension are shown as follows.
Load extension. The turning points of the measured L-THs are extracted. Then, new turning points are generated through the MCMC simulation process until the new samples meet the demands of extrapolation.
Load preprocessing. The new turning points are converted into load cycles in rain-flow domain by rain-flow counting method. Considering that the small load cycles have little effect on fatigue damage, the load cycles below a certain threshold should be filtered. For example, the load cycles with a range less than 10% or 50% of the maximum load cycle can be eliminated,27,28 or the 50% of the material endurance limit can be set as the filtering threshold. 29 The 10% of the maximum load cycle is selected as the threshold to remove small load cycles.
Density estimation. The density of load cycles in rain-flow domain is estimated according to NPRFE model created at section “NPRFE modeling”, and the optimal probability density of load samples can be obtained.
Rain-flow matrix (RFM) extrapolation. According to the optimal probability density, Monte Carlo method is used to generate new load cycles randomly, and the RFM is extrapolated with certain folds.
The flowchart of NPRFE method based on load extension is shown in Figure 6.

Flowchart of NPRFE method based on load extension.
Case study
This article takes wheel loader as an example to verify the proposed NPRFE method. The measured L-THs for semi-axle in spading section and back section with full load are selected (see Figures 7 and 8). Through rain-flow counting and small load cycles filtering methods, rain-flow matrices (RFMs) in two operation sections are obtained (see Figure 9).

L-THs for semi-axle in spading section.

L-THs for semi-axle in back section with full load.

RFMs of the measured L-THs: (a) spading section and (b) back section with full load.
Direct NPRFE for L-THs
To demonstrate the performance of the FBM-based NPRFE model, the densities of the measured RFMs are estimated by direct NPRFE method which only uses the FBM-based NPRFE model without load extension. Then the measured load cycles are extrapolated with 10 folds and the results are shown in Figure 10. Compared with RFMs shown in Figure 9, the extrapolated RFMs include a lot of new load cycles. However, it is difficult to evaluate whether they are reasonable or not.

RFMs extrapolated by direct NPRFE with 10 folds: (a) spading section and (b) back section with full load.
Here, load spectra curve is applied to describe the effect of extrapolation. At the same time, the measured load cycles are also extrapolated by the existing SBM-based NPRFE model and “mileage extrapolation” method which means that the measured load cycles are only duplicated for several folds. The comparisons of different extrapolation curves in two sections are shown in Figure 11. Compared with the SBM-based NPRFE curve, the FBM-based NPRFE curve is more close to mileage extrapolation curve in medium and small load cycles. Thus, it can be deduced that the FBM-based NPRFE model is more reasonable and accurate than the SBM-based NPRFE model.
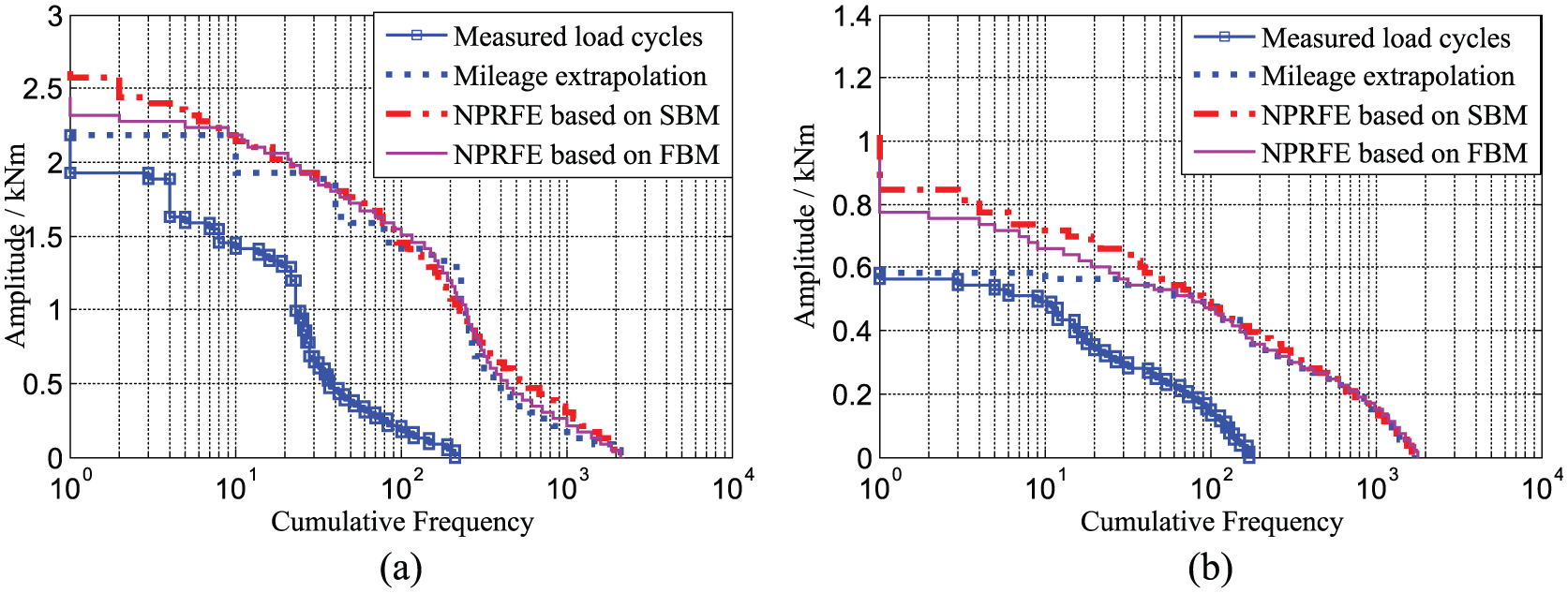
Load cycles extrapolated by different models with 10 folds: (a) spading section and (b) back section with full load.
Considering that the LRFE method can obtain a good extrapolation effect in large load cycles, the direct NPRFE method should be compared with it, especially in large load cycles. The load spectra curves extrapolated by LRFE method and direct NPRFE method with 10 folds are shown in Figures 12. For both the sections, the extrapolation of the measured load cycles by direct NPRFE method is repeated 10 times, and 10 different load spectra curves are obtained. According to the part of the large amplitude in load spectra curves, almost all of the amplitude values extrapolated by direct NPRFE are larger than those extrapolated by LRFE. Therefore, the direct NPRFE method is not very perfect for extrapolating large load cycles.

Load cycles extrapolated by LRFE and direct NPRFE with 10 folds: (a) spading section and (b) back section with full load.
NPRFE method based on load extension for L-THs
Aiming at improving the extrapolation effect of large load cycles, the NPRFE method based on load extension is applied and verified. When more load samples are extended, then higher accuracy of KDE can be guaranteed. However, the extrapolated results are perfect when the measured load samples are extended with 100 folds in this case. Extension more than 100 folds is time consuming and meaningless. Considering computation time, the extended fold is set to 100 here.
After extension, load preprocessing, density estimation, and extrapolation with 10 folds for the measured L-THs for the semi-axle in spading section and back section with full load, the RFMs are obtained and shown in Figure 13.

RFMs extrapolated by NPRFE based on load extension with 10 folds: (a) spading section and (b) back section with full load.
Similarly, the LRFE method is used as reference. The load spectra curves extrapolated by LRFE method and NPRFE method based on load extension with 10 folds are shown in Figure 14 (the NPRFE method based on load extension is repeated 10 times). According to the part of the large amplitude in load spectra curves, all of the amplitude values obtained by proposed NPRFE method are similar to LRFE results. Compared with the results shown in Figure 12, the extrapolation performance for large load cycles is obviously improved.

Load cycles extrapolated by LRFE and NPRFE based on load extension with 10 folds: (a) spading section and (b) back section with full load.
To verify the validity of extrapolation effect of this new method further, extrapolation with 100 folds is also simulated (see Figure 15). Compared with direct NPRFE, NPRFE method based on load extension is more reasonable because its extrapolation results are more close to LRFE results in large load cycles.

Load cycles extrapolated by different methods with 100 folds: (a) spading section and (b) back section with full load.
Similar to the load spectra curve, the damage is another evaluation indicator for the validity of proposed NPRFE method. Nominal stress method is commonly applied for fatigue life calculation of mechanical components. For the measured L-THs, the nominal damage is calculated. Basquin’s equation of Waller curve is

where

where

where
L-THs for semi-axle are extrapolated by LRFE, direct NPRFE, and NPRFE method based on load extension with fold x (x = 10, 20, …, 100), and then the RDR values caused by these extrapolation load cycles are acquired. Figure 16 shows that the RDR values calculated by NPRFE method based on load extension are more close to LRFE results than those calculated by direct NPRFE. Thus, NPRFE method based on load extension can realize a reasonable extrapolation.

RDR values calculated by different extrapolation methods: (a) spading section and (b) back section with full load.
Discussion
As previously stated, both the extrapolation model and the size of the measured L-THs are critical in the process of NPRFE. To achieve the reasonable extrapolation of the measured L-THs, these two factors are taken into account in this article.
LRFE method has the advantage in extrapolating large load cycles. In this method, large load cycles’ extrapolation is based on peak over threshold model. Generalized Pareto distribution is used to fit the large load cycles above a threshold, and then the probability distribution is obtained. Through probability multiplied by total frequency, the extrapolation load cycles are obtained. When the threshold and parameter estimation method in that model are the same, the load spectra curve after extrapolation will not change.
NPRFE method based on load extension does not need to assume that the load samples obey a certain distribution. In this method, MCMC method is used in load extension, and Monte Carlo method is used in RFM extrapolation to generate new load data randomly. When the NPRFE method based on load extension is repeated 10 times, the load spectra curves are diverse (see Figure 14). It reflects the randomness of load samples. Compared with LRFE method, NPRFE method based on load extension can obtain a reasonable extrapolation, and the superiority of data-driven property of KDE is retained. Thus, NPRFE method based on load extension may be better than LRFE method for the extrapolation of random and complex L-THs.
The L-THs analyzed here are obtained from the load measurement for the semi-axle of a wheel loader. In the process of measurement, 100 data points are gathered per second, and the total time of each section is 750 s. Thus, 75001 data points were gathered and used for analysis. They satisfy the demands of MCMC simulation, and the final extrapolation effect is perfect. However, if the load samples are too small and cannot reflect their distribution characteristics, the extrapolated results are unreasonable even though MCMC simulation is done in the process of extrapolation. If the load samples are large enough and meet the demands of KDE, MCMC simulation seems to be unnecessary for load extrapolation. Therefore, further research may be emphasized on the load extrapolation considering the influence of the size of original samples.
Conclusion
Load extrapolation is the crucial step in compiling the long-term load spectra of mechanical components for fatigue life prediction and bench test loading. NPRFE method based on KDE was gradually investigated in recent years as its extrapolation process is data-driven. However, the estimation accuracy of this method in large load cycles is limited and still needs to be improved. To overcome this problem, this study proposed an NPRFE method based on load extension.
The measured L-THs for the semi-axle of a wheel loader in spading section and back section with full load were used as an example to verify the reasonability and effectiveness of the proposed method. The comparison results between the FBM-based NPRFE curve and the SBM-based NPRFE curve show that NPRFE model greatly influences KDE precision and extrapolation accuracy. The comparison results between direct NPRFE and NPRFE method based on load extension show that the size of load samples has a great effect on the extrapolation of the measured L-THs. Based on load extension, the proposed method, which takes NPRFE model and the size of load samples into account, can realize a reasonable extrapolation for large load cycles as well as other cycles. Because any parametric distribution is not applied for fitting load samples in the proposed NPRFE method, it can decrease the subjectivity and prejudice. Besides, as NPRFE method based on load extension is not restricted by sample distribution, it may be flexibly used in the extrapolation of random and complex loads.
Footnotes
Academic Editor: Filippo Berto
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (grant nos 51375202 and 51265020) and the Graduate Innovation Fund of Jilin University (project 2016074).