
Abstract
In this article, we study the economic lot and delivery scheduling problem for a four-stage supply chain that includes suppliers, fabricators, assemblers, and retailers. All of the parameters such as demand rate are deterministic and production setup times are sequence-dependent. The common cycle time and integer multipliers policies are adapted as replenishment policies for synchronization throughout the supply chain. A new mixed integer nonlinear programming model is developed for both policies, the objective of which is the minimization of inventory, transportation, and production setup costs. We propose a new hybrid algorithm including a modified imperialist competitive algorithm which is purposed to the assimilation policy of imperialist competitive algorithm and teaching learning–based optimization which is added to improve local search. A hybrid modified imperialist competitive algorithm and teaching learning–based optimization is applied to find a near-optimum solution of mixed integer nonlinear programming in large-sized problems. The results denoted that our proposed algorithm can solve different size of problem in reasonable time. This procedure showed its efficiency in medium- and large-sized problems as compared to imperialist competitive algorithm, modified imperialist competitive algorithm, and other methods reported in the literature.
Keywords
Introduction
The coordination of the chain members is one of the important objectives of supply chain since members of each stage have different and even opposite profit. Synchronization can increase coordination among the chain members. The synchronization causes balance between decision making for internal production scheduling and the external delivery in the chain. One of the prevalent problems in the literature that examines these two cases simultaneously is economic lot and delivery scheduling problem (ELDSP).
Hahm and Yano 1 studied a supply chain consisting of one supplier and one assembler and could determine the interval between production and delivery for a single item. They developed this problem for multiple items and presented a heuristic algorithm for determining the common cycle time. 2 Khouja 3 studied this problem with the assumption of rework cost for achieving the required quality and also variable production rate. Jensen and Khouja 4 presented a heuristic algorithm for achieving the optimal solution in polynomial time. Their work is developed by Clausen and Ju. 5 They proposed a heuristic algorithm to find the optimal solution of large-scale problem at a shorter time.
Torabi et al. 6 studied a two-stage supply chain including one supplier and one assembler and multiple items with the common cycle time. They proposed a hybrid genetic algorithm (GA) for the solution of ELDSP. Nikandish et al. 7 examined a three-stage supply chain including one supplier and multiple assemblers and multiple retailers with common cycle time and presented the optimal solution for medium scale problems. Osman and Demirli 8 studied a three-stage supply chain, including multiple suppliers at the initial and middle stages and a single assembler at the final stage. They proposed a hybrid algorithm (HA) for the solution of ELDSP.
In this article, a four-stage supply chain, including multiple suppliers, fabricators, assemblers, and retailers for multiple items, is studied. The objective is to determine the common cycle time and production sequence, so that the inventory, transportation, and production setup costs minimize. In the literature review, the optimal solution for the defined problem has not been presented. We have proposed a mixed integer nonlinear programming (MINLP) model for ELDSP. The problem is solved, after linearization, by proposing a hybrid modified imperialist competitive algorithm (MICA) and teaching learning–based optimization (TLBO).
Problem defining and modeling
In this article, we have focused on the coordination among the members of a four-stage supply chain. The supply chain includes suppliers, fabricators, assemblers, and retailers.
The suppliers convert raw materials into components. Fabricators transform these components into items which are applied for the production of final products by assemblers. At the end of the chain, retailers respond to customers based on the anticipated demand of each product.
Other assumptions are as follows:
Each node has a single production line at the stage of suppliers, fabricators, and assemblers.
The carried quantity of each stage’s node is as much as demand of the next stage.
Just one shipment is allowed to be sent at the end of each cycle time.
The values of demand and production rate are fixed and certain.
The holding cost of each item per unit time is fixed and certain.
The delivery cost is fixed.
For suppliers, fabricators, and assemblers stage, the setup time is sequence-dependent, while the setup cost can be assumed sequence-independent.
Ordering cost is fixed for each retailer.
The objective of this study is to achieve coordination among the members. Therefore, synchronization is necessary. Two types of synchronization, full synchronization by applying the common cycle time policy and the partial synchronization by applying the integer multipliers policy, are selected. The parameters and variables of the model are defined as follows.
Indices
s index of suppliers,
f index of fabricators,
a index of assemblers,
r index of retailers,
i
index of items in each facility
Parameter
q sequence position in each facility,
Dri demand rate of ith item at rth retailer
Psi production rate of ith item at sth supplier
Pfi production rate of ith item at fth fabricator
Pai production rate of ith item at ath assembler
HBsi holding cost per unit of ith unprocessed item per unit time at sth supplier
HBfi holding cost per unit of ith unprocessed item per unit time at fth fabricator
HBai holding cost per unit of ith unprocessed item per unit time at ath assembler
Hri holding cost per unit of ith item per unit time at rth retailer
HAsi holding cost per unit of ith processed item per unit time at sth supplier
HAfi holding cost per unit of ith processed item per unit time at fth fabricator
HA ai holding cost per unit of ith processed item per unit time at ath assembler
ds transportation cost per delivery at sth supplier
df transportation cost per delivery at fth fabricator
da transportation cost per delivery at ath assembler
dr transportation cost per delivery at rth retailer
csi production setup cost of ith item at sth supplier
cfi production setup cost of ith item at fth fabricator
cai production setup cost of ith item at ath assembler
cr ordering cost at rth retailer
tsij production setup time of ith item after processing of jth item at sth supplier
tfij production setup time of ith item after processing of jth item at fth fabricator
taij production setup time of ith item after processing of jth item at ath assembler
Variables
Xsiq 1 if item i is assigned to qth position at sth supplier, otherwise 0
Xfiq 1 if item i is assigned to qth position at fth fabricator, otherwise 0
Xaiq 1 if item i is assigned to qth position at ath assembler, otherwise 0
T basic cycle time
m 1, m2, and m3 the integer multipliers for the integer multipliers policy (i.e. the cycle time at any retailer is T, m1T at any assembler stage, m2m1T at any fabricator stage, and it equals m3m2m1T at any supplier stage also if m3 = m2 = m1 = 1 then the common cycle time policy is accomplished).
Equations (1)–(13) represent ELDSP. The objective function calculation will be explained in Appendix 1. Equations (2)–(4) ensure feasibility of cycle time under the assumption of sequence-dependent setup times, in the suppliers, fabricators, and assemblers. At the supplier stage, equations (5) and (6) guarantee assigning, in sequence, each item only to one position and each position just to one item. Equations (7)–(10) guarantee these conditions for each fabricator and assembler. Equations (11)–(13) represent binary variables
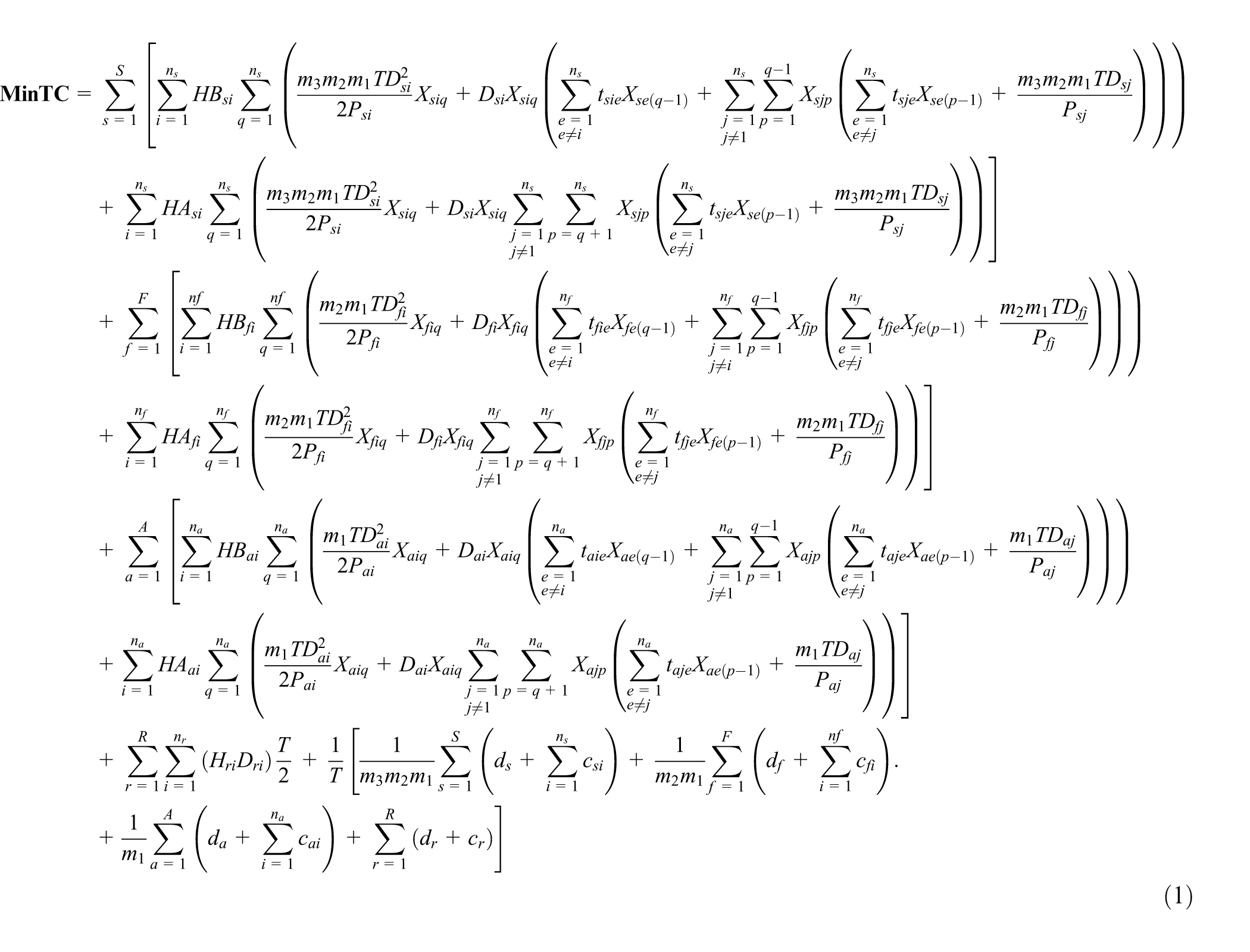
Subject to

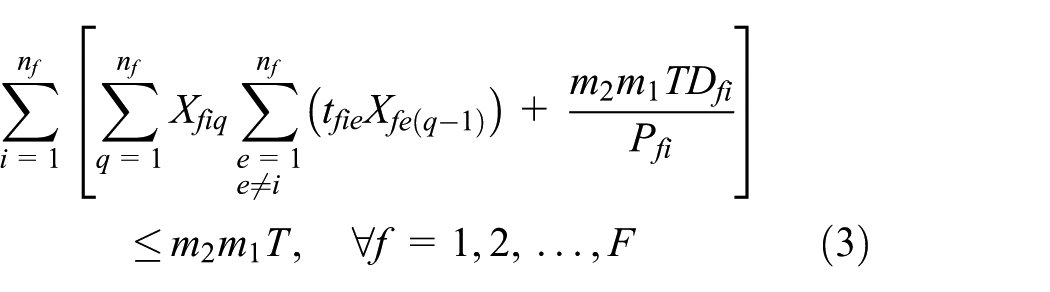

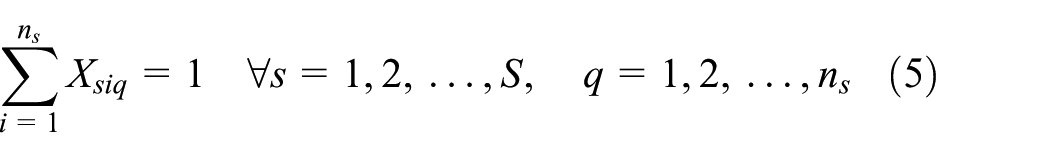


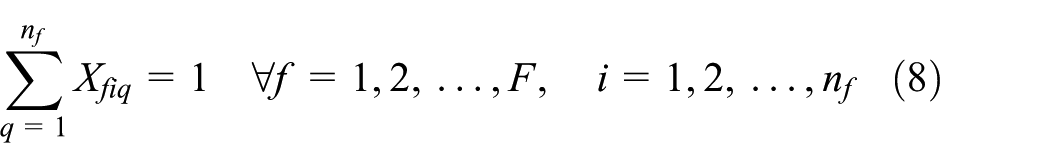



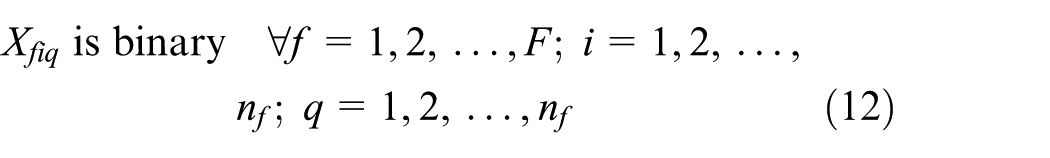

Linearization
We consider equation (1) to linearization of the objective function. We use the Hahn et al.
9
method to linearization type one. The auxiliary variable





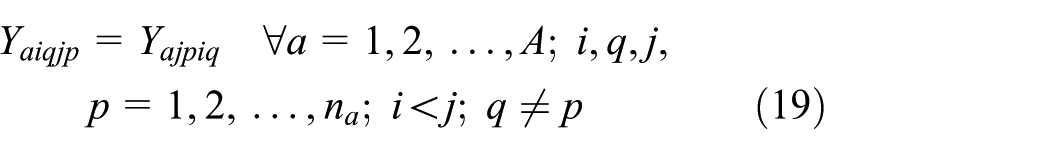
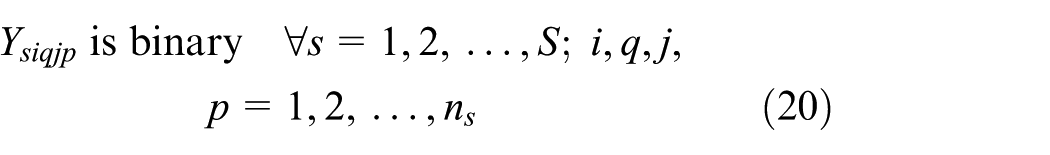


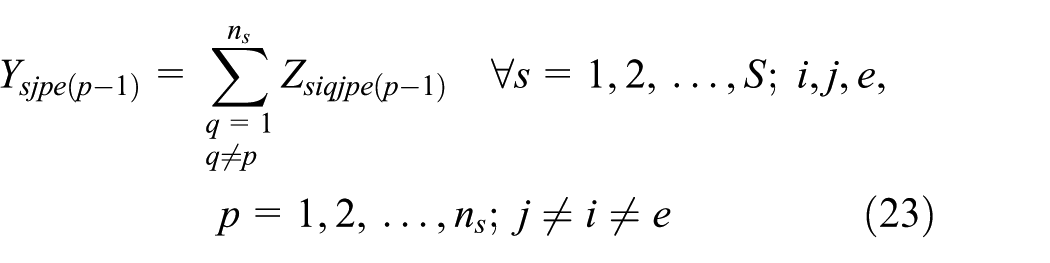
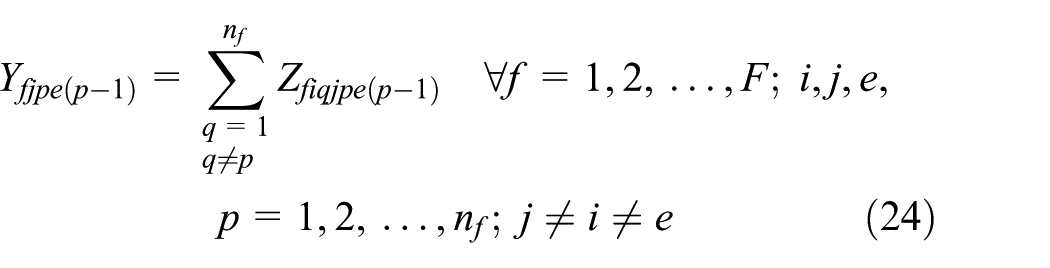

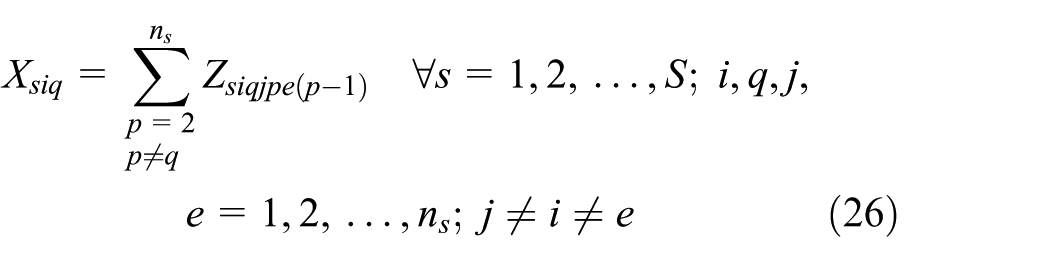

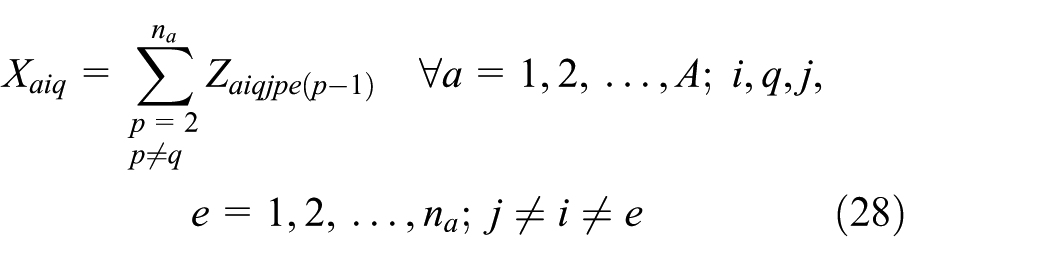

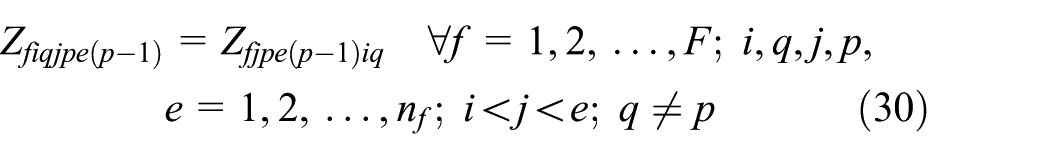

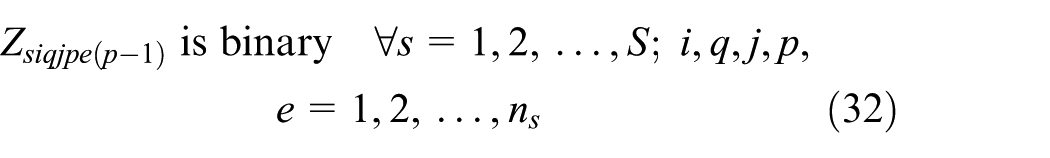


We use the Adams and Forrester
10
method for linearization of multiplying continuous variable T by one binary variable. For example, we replace

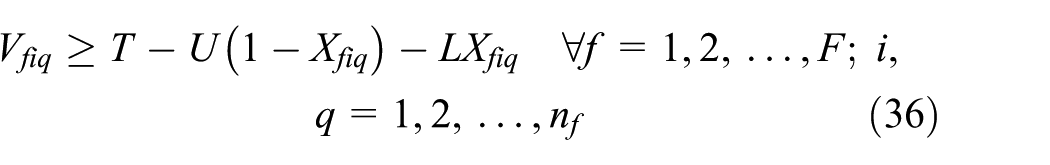







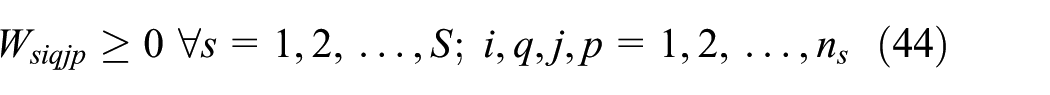

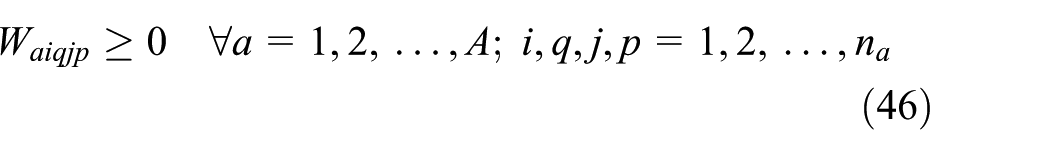
Equation (1), with making these changes, becomes equation (50). In equation (50), L the lower bound of variable T is equal to the minimum value that satisfies equations (47)–(49) and U the upper bound of variable T is equal to planning horizon time


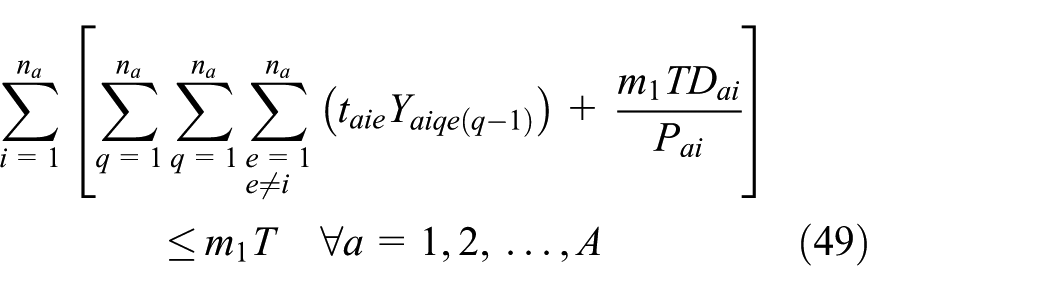
After linearization, we represent the original objective function by equation (50). The linearized model includes two sets of new equations: equations (14)–(34) and equations (35)–(46), and also equations (5)–(13) belong to the original model. Furthermore, because of linearization, we replace equations (2)–(4) by equations (47)–(49)

subject to equations (5)–(49).
Proposed algorithms
Imperialist competitive algorithm
One of the novel socio-politically evolutionary algorithms that has been presented for treating with several optimization problems recently is an imperialist competitive algorithm (ICA). 11 The suitable performance and applicability of the algorithm in both convergence rate and achieving near optimal solutions are the advantages of the ICA. 12 The algorithm commences with an initial population and each individual of the population is called a country. 13
At first, the imperialist states are created by some of the best countries, then the remainder of the countries organize the colonies of these imperialists. In other words, all the colonies of initial population are divided among the mentioned imperialists based on their power. The power of each country has an inverse relation with its cost in the objective function. The imperialist states and their colonies establish some empires.13,14 The total power of an empire is calculated by the sum of the total power of imperialist country and a percentage of mean power of its colonies. The colonies of each empire start to approach the related imperialist country, after constructing the primary empires. 14 Figure 1 shows flow chart of ICA.

Flow chart of ICA.
The ICA is explained in the following subsections.
Solution representation
The representation of a solution is one of the most important parts of a meta-heuristic design to provide efficient search of the space. There are two different representations in the literature.15,16 We used one of them. 15 We have two suppliers (suppliers 1 and 2), one fabricator (fabricator 1), and two assemblers (assemblers 1 and 2), whereas those that are used in the previous literature are 6 and 4, 5 and 4, and 5 items, respectively. In Figure 2, the code of the individual corresponding solutions is 3-5-4-2-1-6 at supplier 1, 1-3-2-4 at supplier 2, 5-4-1-2-3 at single fabricator, 1-3-4-2 at assembler 1, and 2-1-4-3-5 at assembler2.

A sample chromosome.
Generating initial empires
Each evolutionary algorithm starts with an initial solution. To form the initial solution, an array of variable values is created. The array is called “country” in the ICA. In an N-dimensional problem, a country is presented by a 1 × N array. The mentioned array is defined by

The cost of a country is gained by defining the objective function TC at the variables (P1, P2, …, PN). Then, the cost of a country is calculated by

The optimization procedure is started by generating an initial population of size

where TCn is the TC of the nth imperialist and
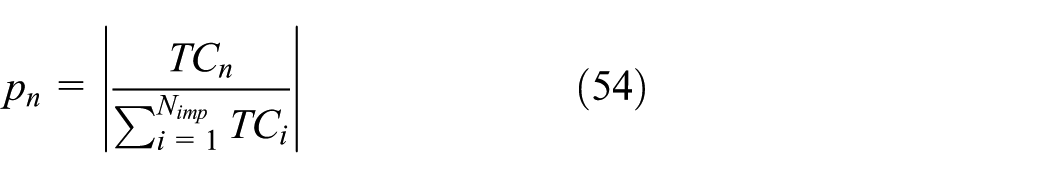
The normalized power of each imperialist will affect on the number of colonies that belong to that empire. To calculate the initial number of colonies of the nth empire, the following relation can be considered

where
Searching space
Three steps (assimilation, crossover, and revolution) are used to find a better solution during the search process. Those steps are described as follows.
Assimilation
In the ICA, the uniformity of colonies culture and social structure toward their imperialist is achieved by the assimilation policy. In this step, the colony moves toward the imperialist by x units, in which x is a random variable with a uniform distribution

where d is the distance among colonies and imperialist.

where

Movement of colony toward their relevant imperialist.
Crossover
Using the crossover operator in this step, the colonies share their information with each other to modify themselves. Colonies with lower cost have more opportunity for sharing their information under a binary tournament selection. Three various kinds of crossover operators (one point, two points, and uniform crossover) are adapted to encoded parts of solutions. 17
Revolution
Revolution is defined as a basic and sudden change in the power structure and sociopolitical characteristics of a country. Instead of being assimilated by an imperialist, the position of the colony is randomly changed in the sociopolitical direction. The advantages of revolution can be considered as follows: (1) increasing the search of the algorithm in solution space and (2) preventing the early convergence of countries to local minimums. The percentage of the colonies in each colony which will randomly change their position is defined as the revolution rate. A very high value of a revolution will result in decreasing the exploitative power of algorithm and can reduce its convergence rate.13,18 In this article, three kinds of revolution strategy are applied to the encoded parts of solutions, consisting of (1) swap, (2) reversion, and (3) inversion. For more details, see Mohammadi et al. 17
Exchange positions of the imperialist and a colony
Moving toward the imperialist, the position of the imperialist and the colony is exchanged if a colony reaches to a position with a lower cost than the expense of the imperialist. Then, the ICA is kept by the new imperialist and the colonies move toward the new imperialist in the new position.13,14,18
Uniting similar empires
Some imperialists might be situated on the same positions. The integration of these empires will form a new empire if the distance between the two imperialists becomes less than threshold distance. The colonies of the new empire are established by all the colonies of two empires and one of the two imperialists will be chosen as the new imperialist.13,18
Total power of an empire
The power of an imperialist and its colonies are the two influential factors in calculating the total power of an empire. But the imperialist power is the main power in one empire. Therefore, the total cost (TTC) of the nth empire is computed by

where TTCn is the total cost of the nth empire and
Imperialistic competition
In the ICA, each empire attempts to take possession of colonies of other empires. Finally, the power of stronger empires will be increased and the power of weaker ones will be decreased or they will be eliminated. The power of each empire plays an important role in succeeding in this competition. Therefore, the stronger empires have greater opportunity to take possession of the weakest countries in weakest empires. In other words, these colonies may not be possessed by the strongest empire, but this empire will own it with a higher probability. The possession probability of each empire is computed based on its total power. Normalized total cost of nth empire is obtained by

where

To distribute the colonies among empires according to the possession probability of them, a new procedure with less computational stages is used rather than simple Rolette Wheel selection. At the beginning, vector

Then a vector

Then, vector

Referring to vector
Eliminating the powerless empires
When the weak empire loses all its colonies, the empire collapse and the colonies of that empire are distributed among the other stronger empires. 18
Convergence
Finally, the imperialistic competition ends (stop condition) if all the colonies will be under the control of most powerful empire and other empires will collapse.12,18
Modified ICA
In the general ICA, the uniformity of colonies culture and social structure toward their imperialist is achieved by the assimilation policy. Moreover, in the real world, the imperialist countries will also move toward the most powerful imperialist countries which they realize themselves weak or even the associated imperialists will outdistance the greater imperialist.
Figure 4 shows this modification of ICA (MCIA). The


The act

Movement of imperialist country toward stronger imperialist.
Figure 5 shows the new assimilation policy, in which first imperialists move toward the strongest imperialist to increase their power, and then colonies will pull to their imperialists.
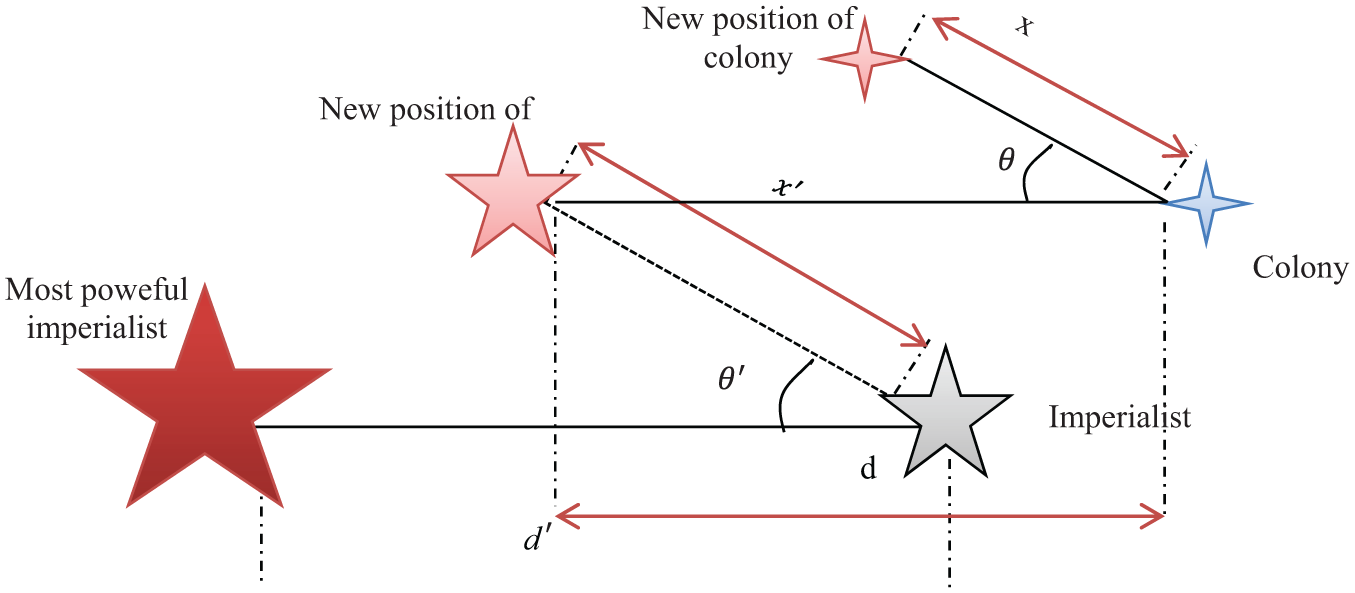
The mechanism of assimilation policy in MICA.
Teaching learning–based optimization
A nature-inspired algorithm which is a population-based technique known as “teaching learning–based optimization” (TLBO). In TLBO, a population of solutions as learners is used to reach the global solution based on the effect of the instruction of teacher on the learner’s grade that is equivalent to the “fitness” value of the optimization problem. The teacher is examined as the best solution obtained so far. 19
The procedure of TLBO is divided into two phase: (1) teacher phase, which is learning from teacher and (2) learning phase, which is learning through interchange of information between learners. These phases are described as follows.
Teacher phase
In this phase, the teacher position is allocated to the best individual
The position of each individual (Xi) solution is improved, as Xnew, according to the difference between the current and the new mean value as follows

where

Learner phase
In this phase, self-organized learning between the individual
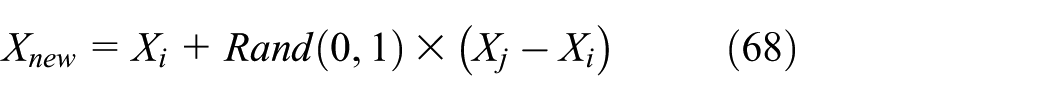

At the end,

Flow chart of TLBO algorithm.
Hybrid MICA–TLBO
We propose a hybrid algorithm including MICA and TLBO technique (MCIA–TLBO) to solve defined problem in the common cycle time and integer multipliers policy. We use TLBO to increase convergence rate and improve the final response of MICA. Figure 7 shows a flow chart of teaching and learning phases for MICA-TLBO. In each empire, imperialist plays the role of teacher and its colonies are considered as students. In teacher phase, the imperialist improves its colonies based on equation (70). In learner phase, two colonies of the same imperialist randomly select to increase the power of colonies and improve. According to which one is better than another, equation (71) or (72) can be obtained

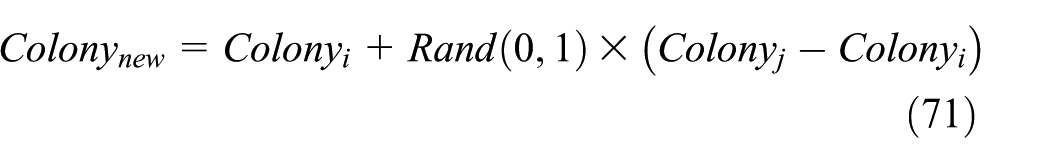


Flow chart of teaching and learning phase for MICA–TLBO.
The two colonies will switch their positions if a colony reaches a better position than its imperialist. In MICA-TLBO, the solution time is decreased by increasing power of each empire and improving the position of imperialist and colonies. Hence, the convergence rate of the MICA-TLBO in comparison with ICA and TLBO is higher, which is shown in the results section. Figure 8 represents the flow chart of the proposed MICA-TLBO.

Flow chart of MICA–TLBO.
Computational results
As shown in Table 1, 15 instances that have a different configuration and size of supply chain are presented to evaluate the proposed algorithms. For each instance, 10 problems are randomly generated and the average of the results is calculated.
The configuration of supply chain for instance problems.

The results of computational experiments for the common cycle time and integer multipliers policies are described in two next subsections. The results are achieved on the laptop with an Intel (R) core (TM) 2-2.00 GHz CPU and 2G RAM.
The results of common cycle time policy
In the common cycle time policy, we propose MICA–TLBO and it is compared with GA relative to the solution time and solution quality. Furthermore, we adapt a hybrid algorithm (HA) which proposed by the Clausen and Ju 5 . The results represented by Table 2.
The results of computational experiments for the common cycle time policy.

HA: hybrid algorithm; CPU: central processing unit; GA: genetic algorithm; ICA: imperialist competitive algorithm; MICA: modified imperialist competitive algorithm; MICA–TLBO: modified imperialist competitive algorithm and teaching learning–based optimization; RPD: relative percentage deviation.
In HA, we obtain the optimal solution with the different average solution times (ASTs; Ave. CPU time) in each instance. As shown in the second column of Table 2, ASTs are severely increased with problem size and after ninth instance, the ASTs are >120 min. The AST is very high in HA, so we proposed hybrid algorithm. We calculate the relative percentage deviation (RPD) as solution quality. Let
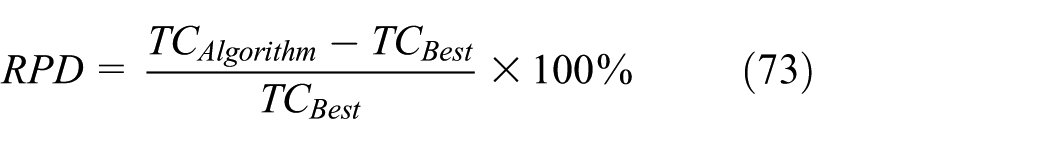
As shown in Figure 9 and 10, the results of MICA–TLBO outperform other algorithms relative to RPD and AST in all instances.

The results of RPD values for common cycle time policy in each algorithm.

The average CPU time for common cycle time policy in each algorithm.
The maximum value of AST is obtained from 15th instance. In 15th instance, maximum and minimum value are 218.97 in GA and 108.43 s in MICA–TLBO, respectively. Figure 11 illustrates the convergence of the algorithms for the objective function in 15th instance. As shown in this figure, the convergence rate of the proposed algorithm, that is, MICA–TLBO, is better than other algorithms.
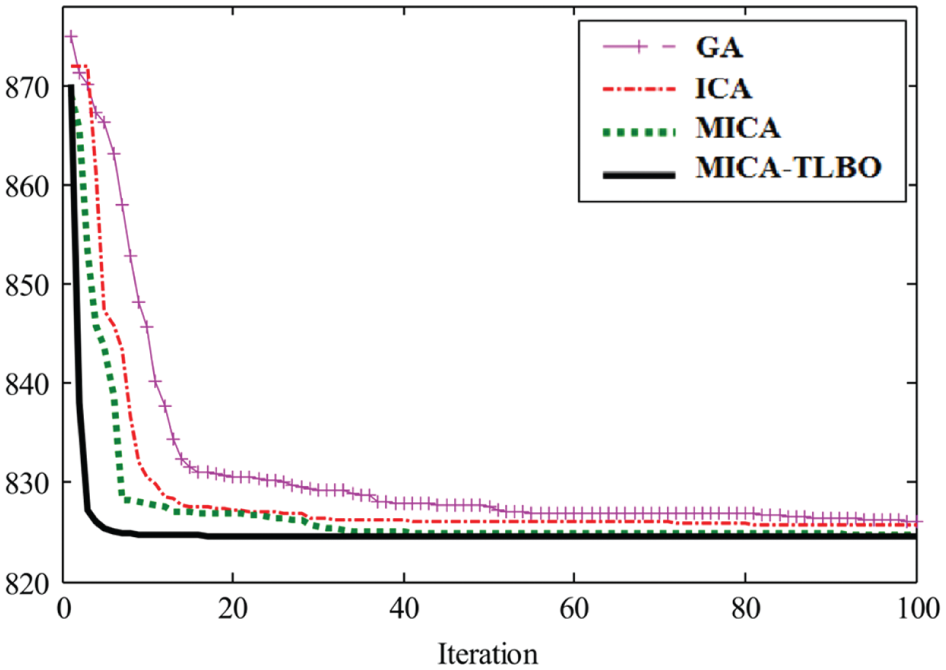
Convergence of algorithms for common cycle time policy in 15th instance.
The result of integer multipliers policy
The results of applying the integer multipliers policy are shown in Table 3. Also, it is observed from Figure 12 and 13 that the MICA–TLBO algorithm is effective in comparison to the others relative to RPD and AST.
The results of computational experiments for the integer multipliers policy.

GA: genetic algorithm; ICA: imperialist competitive algorithm; MICA: modified imperialist competitive algorithm; MICA–TLBO: modified imperialist competitive algorithm and teaching learning–based optimization; RPD: relative percentage deviation; CPU: central processing unit.

The results of RPD values for integer multipliers policy in each algorithm.

The average CPU time for integer multipliers policy in each algorithm.
The maximum value of AST is obtained from 15th instance. In 15th instance, maximum and minimum value are 241.23 in GA and 135.96 s in MICA–TLBO, respectively. As shown in Figure 14, the convergence rate of MICA–TLBO is higher than other ones.

Convergence of algorithms for integer multipliers policy in 15th instance.
The last column of Table 3 demonstrates the percentage of cost savings attained by applying the integer multipliers policy. The maximum percentage of cost savings is observed in 31.2%, which is obtained from the 10th instance. As shown in this table, the integer multipliers policy outperforms the common cycle time policy in all instances.
Conclusion
In this article, we investigate a four-stage supply chain including suppliers, fabricators, assemblers and retailers. The common cycle time and integer multipliers policies are used to synchronize the chain. We have developed a new MINLP model with objective function of minimizing inventory, transportation and production setup costs. After linearization of the model, we propose a hybrid MICA–TLBO for defined problem. The hybrid MICA–TLBO has better results in comparison to other algorithm based on RPD and AST measures in both replenishment policies. The cost saving is increased up to 31.2% by using the integer multipliers policy instead of the common cycle time policy.
For future research, we can consider other synchronization policy like power-of-two policy. Also, we can study uncertainly demand or production rate. We can investigate supply chain by different configuration, various delivery cost and multiple shipping instead of one shipment.
Footnotes
Appendix 1
Academic Editor: Wu Naiqi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.