
Abstract
Determining prognosis for rotating machinery could potentially reduce maintenance costs and improve safety and availability. Complex rotating machines are usually equipped with multiple sensors, which enable the development of multidimensional prognostic models. By considering the possible synergy among different sensor signals, multivariate models may provide more accurate prognosis than those using single-source information. Consequently, numerous research papers focusing on the theoretical considerations and practical implementations of multivariate prognostic models have been published in the last decade. However, only a limited number of review papers have been written on the subject. This article focuses on multidimensional prognostic models that have been applied to predict the failures of rotating machinery with multiple sensors. The theory and basic functioning of these techniques, their relative merits and drawbacks and how these models have been used to predict the remnant life of a machine are discussed in detail. Furthermore, this article summarizes the rotating machines to which these models have been applied and discusses future research challenges. The authors also provide seven evaluation criteria that can be used to compare the reviewed techniques. By reviewing the models reported in the literature, this article provides a guide for researchers considering prognosis options for multi-sensor rotating equipment.
Keywords
Introduction
Rotating machines are widely used in different engineering fields, including the oil industry, aviation industry, mining industry and transportation industry. These machines typically operate under adverse conditions, such as high load and high temperature, and are thus subject to performance degradation and mechanical failure. Failure of the rotating equipment results in the catastrophic collapse of the entire system, thereby reducing productivity and reliability. This, in turn, causes unplanned downtime and economic losses and may even lead to health and safety problems. 1 Therefore, it is necessary to implement effective maintenance strategies that provide incipient fault diagnoses in the early stages of performance degradation, such that practitioners can predict and control the progression of an incipient fault to system failure. 2 Maintenance strategies that are commonly used in industry can be classified into the following three categories: corrective maintenance, preventive maintenance and condition-based maintenance (CBM). 3 In corrective maintenance, actions only occur when a system breaks down. In contrast, preventive maintenance involves a series of checks, replacements and overhauls that are implemented in a planned manner. The frequency of these maintenance actions is determined by analysis of the system failure rate. Although preventive maintenance significantly reduces the probability of catastrophic failures, this method seems overly conservative and inefficient in real-world situations because it is often unnecessary to replace a component after it is checked. 3
CBM is a predictive maintenance strategy that continuously surveys the working conditions of the machine to determine the timing and type of required maintenance. 4 CBM uses condition-monitoring information obtained from data-acquisition systems to enable diagnoses of impending faults and prognoses regarding the machines remaining useful life (RUL). If the detected failure is catastrophic, operators can shut down the machine immediately. Otherwise, operators can choose to continue operating the system under faulty conditions until the end of the predicted RUL. 5 Therefore, CBM allows maintenance actions to be scheduled on an as-needed basis, an attractive alternative to traditional strategies. This article focuses on the techniques and models that have been developed to determine the fault prognosis of rotating machines in the CBM framework.
Over the last decade, increasing interest in fault prognostics has resulted in many studies addressing the theoretical considerations and practical implementations of prognostic models. The literature6,7 divides prognostic models into three main groups: model-based prognostics,8–14 data-driven prognostics15–18 and experience-based prognostics.7,19 These studies have focused on univariate reliability prediction using monitoring information obtained from a single sensor. However, because of advances in sensing technology, various condition-monitoring data, such as oil debris, pressure values, temperature values and vibration, are commonly available for complex industrial machines. 20 The availability of such multi-sensor condition data permits the development of multidimensional prognostic models for rotating machines. By considering the possible synergy within data gathered by diverse sensors, multidimensional prognostic approaches can provide more accurate health prognoses than approaches that use single-source monitoring information.
Many papers reviewing prognostic techniques for engineering systems have been published in past decades.6,7,21–23 However, only a limited number of these papers have highlighted multidimensional prognostic options for rotating machinery. To address this gap, this article reviews the prognostic models that have been used to predict the failures of multi-sensor rotating machinery using multidimensional prognostic methods.
Definition of multidimensional prognostics
Multidimensional prognostics refers to the synergistic combination of measurements from multiple sensors to provide an estimation of the RUL of a system. It enables evaluation of the reliability of complex machines equipped with multiple sensors. By considering the possible synergy among signals gathered by diverse sensors, multidimensional prognostics can yield a more accurate prognosis than methods using single-sensor information. In addition, if multiple failure modes (occurring at different defect points) are considered in a system, the effects of different faults on a single sensor can be similar. Thus, in this situation, single-source prognostics can fail to distinguish between different types of failures. Multidimensional prognostics overcomes this limitation by investigating the effects of the faults on diverse sensors, enabling the identification of different fault categories.
However, multi-sensor information can increase the complexity of system modelling analysis compared with single-source measurements. To implement multidimensional prognostics, the following factors must be considered:
1. The location and types of sensors selected. Selection of an optimum sensor location and sensor types poses an important problem that must be solved before reliability models can be built for a particular system. Sensor placement determines the extent to which a prognostic model can represent the fault deterioration process; the types of sensors determine the ability of a model to distinguish between various failure modes. 24 For instance, perturbations in signals can be seriously diminished if the sensor is placed too far from the fault location, leading to low detectability of the prognostic model. In addition, since it can be difficult to identify different faults with a single type of sensor, the sensor network should include a wide range of sensors to ensure that various failures are distinguishable from each other. Therefore, sensor placement and sensor types are two important factors that should be considered before building a prognostic model.
Sensor positioning/placement problem for reliability assessment has attracted considerable attention from researchers in the past few decades. Padula and Kincaid 25 provided a comprehensive review of journal articles addressing sensor and actuator placement problems. Xu and Jiang 26 proposed a systematic analysis for where to pick up the best signal for the purpose of diagnosis. Raghuraj et al. 27 proposed a directed graph (DG) model for the problem of sensor location for identification of faults. Recently, an improved graph-based approach was developed by Wang et al. 28 The authors used this approach to optimize sensor locations to ensure the observability of faults, as well as to obtain a maximum possible fault resolution. For more information about sensor placement problem, the reader is invited to refer to Zhang. 24
The emphasis of most reliability assessment approaches is mainly on procedures to perform fault detection and prediction given a set of sensors. Little attention has been paid to the selection of sensor types to maximize prognosis performance. It is because many mechanical systems have sensors on board already when they were installed and adjusted properly by the supplier (for the purpose of measurement and control). More studies investigating the optimum sensor selection problem are required.
2. Which sensor(s) will be included in the analysis? Although more sensory information improves the estimation, in practice, the computational complexity increases dramatically as the number of sensors increases. 29 In addition, when there exist non-ideal multiple sensors with possible failures, signals from different sensors may exhibit different trends of evolution, making it difficult to obtain accurate predictions. Therefore, it is necessary to select appropriate sensors for inclusion in the analysis.
Wei et al. 30 provided an index-based sensor selection method for RUL prediction. The selection of sensors is analysed to satisfy the desired performance index for uncertainty requirements. The proposed method can be utilized to balance the number of sensors selected and the prediction accuracy. However, the authors pointed out that when there exist non-ideal multiple sensors with possible fault evolvements, the prediction problem would become more complicated. To solve the problem of sensor failures, Sharifi and Langari 31 proposed a mixture of probabilistic principal component analysis (MPPCA) model for sensor fault diagnosis. The results show accurate detection of sensor faults of a fully instrumented Heating, Ventilation and Air Conditioning (HVAC) system. Hu et al. 32 utilized a statistical data-cleaning method to remove outliers caused by faulty sensors for obtaining high-quality training data. More recently, Liu et al. 33 developed a model using kernel principal component analysis (KPCA) to realize sensor selection and data anomaly detection. The effectiveness of this model was proved using data sets from Commercial Modular Aero-Propulsion System Simulation (C-MAPSS).
3. Which algorithm will be used to perform RUL prediction? After identifying the sensors to be included in the analysis, a prognostic technique can be chosen to model the system under study. Multiple numerical prognostic models have been proposed in the literature, and sections ‘Definition of multidimensional prognostics’ and ‘Discussion on multidimensional prognostic models’ of this article will help researchers select the most appropriate prognostic model for a particular application.
4. Which method will be used to fuse the information from multiple sensors? In addition to the prognostic technique (i.e. the algorithm that has been chosen to model the degradation process and predict future behaviours), researchers must select a method to fuse the multi-channel measurements for subsequent prognostic modelling. According to Safizadeh and Latifi, 34 three types of approaches have been used in the literature for multiple sensor fusion: (a) Data-level fusion: all raw data measured by a number of sensors are combined directly to produce more informative data than the original data. 34 Techniques that are frequently used to perform data-level fusion include state-space model20,35 and principal component analysis (PCA). 36 Lu et al. 35 modelled the multivariate performance measurements using a state-space model. Then, recursive forecasting was carried out by adopting Kalman filtering. Wang and Christer 20 used the multidimensional observations to build a state-space model and predicted the system residual time. Caesarendra et al. 36 used a PCA to transform multi-channel data into a lower dimensional data matrix for subsequent RUL prediction. (b) Feature-level fusion: features extracted using signal processing techniques from diverse sensors are fused together for subsequent analysis. Lei et al. 37 constructed a health indicator (HI) named weighted minimum quantization error with mutual information from multiple features and predicted the RUL of a bearing. (3) Sensor-level fusion: prognosis is first performed using information from each sensor and then the weights of the different sensors are adjusted. Wei et al. 38 applied the stochastic filter approach for RUL estimation of each sensor and then combined the results to form a system-level RUL prediction. Since there is no universally accepted selection criterion to help determine the best fusion strategy, the selection of the above-mentioned methods depends on the sensor fusion application.
5. The starting point for performing RUL prediction. The degradation process of a mechanical system (e.g. bearing) generally consists of two stages, that is, the normal operation stage and the failure stage. 39 The main task in the first stage is to continuously monitor the condition of the system and perform fault detection and diagnosis. Fault diagnosis is the starting point of prediction of RUL in a faulty system. Once an incipient fault is detected, the prognostic process is triggered, and the fault evolution and RUL are predicted in the second stage. An inappropriate starting point can result in interference noises in the predicting process leading to inaccurate RUL prediction. 39 A number of studies for selecting starting point for prognosis have been reported in the literature. Li et al. 39 proposed an adaptive first predicting time (FPT) selection approach for determining the optimum starting point of prediction of fault evolution. The authors tested the capabilities of the proposed method using bearing vibration signals. In Ruiz-Carcel et al., 5 the effectiveness of the canonical variate analysis (CVA) for detection of incipient faults was tested using multidimensional monitoring data acquired from a compressor test rig. Similarly, Jiang et al. 40 proposed a CVA-based model for fault identification of industrial processes. A variety of techniques for determining the starting point for RUL prediction are discussed in Jiang et al., 41 Yunus and Zhang 42 and Alkaya and Eker. 43
This article aims to assist researchers in addressing the problem of selecting the most appropriate prognostic model (algorithm) for a particular application. Various algorithms and models are discussed in greater detail in the following sections.
Discussion on multidimensional prognostic models
The prognostic approaches reviewed in this article can be divided into the following eight categories: distributed Kalman filters (DKFs), particle filters, stochastic filters, hidden Markov models (HMMs) and hidden semi-Markov models (HSMMs), support vector machines (SVMs) and relevance vector machines (RVMs), proportional hazard models (PHMs) and similarity-based models (see Figure 1). The theory and basic functioning of these techniques, their relative merits and drawbacks and how these models have been used to predict the RUL of a machine are discussed in detail in the following sections.

Models categories for RUL prediction.
Kalman filter–based models
Many complex mechanical systems use a large number of sensors to monitor their operations. Because multivariate measurements are involved, an important practical problem affecting such systems is the identification of a system health estimator. To address this problem, a dynamic state-space model that uses a state vector to describe the state of health of a system is often constructed. Under a state-space structure, Kalman filtering is one of the best-known filtering algorithms to estimate the unknown state of a dynamic system. The Kalman filter estimates the system states by dividing the state-space model into two parts: a state transition model and a measurement model. The former is responsible for projecting forward the current state estimations and error covariance to obtain a priori estimations for the next estimation. The latter is responsible for feedback, that is, incorporating a new measurement into the a priori estimations to obtain an improved a posteriori estimation. The process is repeated with the previous a posteriori estimation used to predict the new a priori estimation. Hence, the Kalman filter performs state estimation in a recursive manner.
Suppose now that we have a dynamic system equipped with a sensor network in which each sensor node can share information with all others. If all local sensors can transfer their measurements to a fusion centre, then the centralized Kalman filter (CKF) can be performed to provide a global state estimation for the system. Then, the global estimation is sent back to the local sensors for the next step in the estimation. Therefore, the estimation process carried out in the CKF is identical to that of the traditional Kalman filter. 44 The problem with centralized solutions is that a large communication bandwidth, which is difficult to obtain in practice, is required for information transformation. 45
The limitations of the CKF have motivated researchers to develop novel state estimation methods that require lower communication bandwidth for sensor networks. DKFs constitute a class of filtering techniques that require fewer communications between nodes and may offer more robust performance,
46
making them an attractive alternative to CKFs. DKFs partition the measurement model into i blocks (
Although DKFs have been extensively used to estimate the state of a system via multiple sensors, only a limited number of publications have addressed its applicability for RUL prediction of rotating machines. Wei et al. 30 proposed an online RUL prediction model, anticipating that multiple sensors would improve performance for dynamic systems. In developing this method, a state-space model was first constructed to describe the dynamics of the system. A Wiener process was utilized to model system state evolution, and then, a DKF and the expectation–maximization (EM) algorithm were used to recursively estimate the state and model parameters, respectively. Online measurements from a milling machine were used to validate the effectiveness of the model, and the prediction result is highly accurate. The filter used in this example is based on the feedback version of the conventional DKF developed by Zhu et al., 50 which can be equivalent to the corresponding CKF in terms of estimation accuracy while lowering the computational costs. Furthermore, the distributed sensor fusion structure used in this study allows uncertainty management of the RUL estimation, thereby enabling users to balance the prediction accuracies and construction costs of sensor networks.
The problem with the DKF is that this method is governed by a linear differential equation. Thus, the uncertainty management necessary for satisfactory performance is much more complicated when used to make predictions via a nonlinear model. 30 Additionally, many existing DKF methods only apply to systems with identical sensor measurement matrices, further limiting the application of DKFs to real-world problems. Therefore, more effort is required to apply heterogeneous multi-sensor fusion strategies, as detailed in Olfati-Saber, 51 to machinery prognostics.
SVM and RVM
SVM
The SVM is a supervised learning method that was originally formulated for classification problems 52 and was later extended to regression problems. 53 In classification problems, the task is to find an optimal separation surface (often designated as a hyper-plane) that separates multidimensional data points into two categories. New observations are then predicted to belong to one class or the other based on the calculated hyper-plane. When handling nonlinear classification problems, a kernel function is used to project the input data points into a higher dimensionality feature space, making the transformed data points linearly classifiable, 52 although the hyper-plane may remain nonlinear in the original input space. The effect of kernel functions is illustrated in Figure 2. In regression problems, instead of searching for a maximum separation classifier, the SVM seeks to find a minimum margin fit for the input data points. 55 Similar to the classification SVM, when the regression SVM is applied to nonlinear regressable data points, a kernel function is often used to map nonlinear inputs into a higher dimensional feature space, after which a linear minimum margin fit can be constructed in that space to perform function estimation. SVMs have many different configurations based on the different kernel functions used to perform feature space transformation. The most commonly employed kernel function is the radial-based function (RBF). 56

Kernel effect: mapping from input data to a higher dimensional feature space.
An advantage of the SVM is its good ability to manage its generalization capability. 57 Specifically, to avoid over-fitting, SVMs use the structural risk minimization (SRM) principle to achieve a trade-off between model complexity and the quality of fit to its training data. 58 Other machine learning techniques, such as neural networks, construct decision functions by relying principally on minimizing training errors and, therefore, are more likely to encounter over-fitting problems. 57 SVMs are excellent for addressing prognostic problems regarding complex rotating machinery because there are no limitations on the dimensionality of the input vectors and because the computational burden is relatively low. 59 Moreover, SVM-based models have been reported to be capable of handling situations that are highly nonlinear. 60
However, a standard method for choosing an appropriate kernel function for SVMs does not exist, which is problematic. 6 Efforts should be made to choose appropriate kernel functions and estimate appropriate parameters. Another disadvantage of SVMs is their lack of probabilistic outputs, which makes managing prediction uncertainties in real-world applications difficult. 61
Several prognostic models based on classification or regression SVMs have been developed to predict the RULs of rotating machines. Louen et al. 57 proposed a RUL prediction framework that uses a SVM classifier to measure the distances between the separation hyper-plane and sensor measurements. A Weibull function is then adopted to model the resulting distance distribution. The performance of this model was tested using a turbofan engine simulation data set. In contrast, Garcia Nieto et al. 62 developed a RUL estimation model based on the particle swarm optimization (PSO)-RBF-SVM technique. A SVM-based regression method was employed to predict the RUL for observed multivariate measurements, and PSO was used to optimize the SVM parameters. The results show that the proposed prognostic model accurately predicts the engine RULs based on a simulation data set.
Traditional SVM was extended in Lu et al. 63 to predict the degradation of bearings. The authors first used the PCA algorithm to fuse both the time domain and frequency domain features obtained from vibration measurements. Subsequently, the least squares support vector machine (LSSVM) was employed to predict the bearing degradation trend. LSSVMs are least squares versions of SVM and involve solving a set of linear formulas that are easier to solve than the quadratic programming used in standard SVMs. 60 Compared with traditional SVM, LSSVM can lead to better performance, particularly in addressing nonlinear, small sample problems. 64 Recently, Niu and Yang 60 combined two nonlinear regression models (SVM and Dempster–Shafer regression (DSR)) to predict the degradation process of a methane compressor. The authors first extracted features from vibration signals and then inserted the features into a neural network to create a fused degradation indicator. Next, degradation predictions based on DSR and SVM were fused to form a hybrid degradation index.
RVM
Although SVM has achieved remarkable performance with regard to both classification and regression, it has some shortcomings, such as its lack of probabilistic outputs. The RVM solves this problem by providing probabilistic interpretation of its outputs in a Bayesian framework. In addition, RVM can achieve comparable performance with fewer kernel functions than standard SVM models while offering a number of additional benefits, such as the ease of using arbitrary kernel tricks and the automatic approximation of model parameters. 65 Meanwhile, update rules for the hyper-parameters can extend the training time required for RVM, leading to increased computational costs. 65 Caesarendra et al. 36 first employed a logistic regression method to assess the failure degradation process of a bearing using simulated data. The determined degradation was subsequently used as the training data for a RVM, and then, the trained RVM was employed to predict the failure probability of the bearings.
Particle filter
As discussed above, when multivariate measurements are available, a system state model can be constructed to make inferences regarding system dynamics. Such a model consists of two parts: a state model describing the evolution of the system state over time and a measurement model linking multidimensional observations with the state. To be incorporated into a filtering framework, these models are commonly available in probabilistic form 66


where
According to the literature, 69 the implementation of particle filters for prognostics is via the following steps:
Defining the initial state and model parameters;
Predicting and updating the state and model parameters;
Performing particle weighting and resampling;
Making the long-term prediction of the RUL.
It is worth noting that the particle filter is actually a state estimation method but is not good at long-term RUL prediction. 70 This is because filtering techniques cannot function properly without new observations, and thus, developing tools that project particles into the future in the absence of measurement updates is necessary. According to Jouin et al., 70 two types of solutions have been presented in the literature: projecting particles and artificially generating measurements. The first aims to project the last particle distribution at the end of learning through all possible future paths with associated weights that can be determined using the state model. Examples of methods that employ particle projection can be found in Hu et al. 71 and Baraldi et al. 72 The main idea underlying the second method is to use complementary algorithms to predict future measurements after the last update. Algorithms that have been used for measurement generation include LSSVM 73 and neural networks. 74 These models are trained to recursively estimate the future value of each variable.
The benefits of applying particle filters to RUL prediction are summarized as follows: (1) particle filters allow information fusion such that data collected from multiple sensors can be employed collectively; 73 (2) particle filters are suitable for dynamic processes with nonlinear and non-Gaussian characteristics; 75 (3) particle filters provide probabilistic outputs that facilitate managing prognostic uncertainties; 73 (4) particle filters enable the joint estimation of state and model parameters, thereby enabling more precise state estimations; 76 and (5) particle filters can handle the high level of uncertainties in long-term predictions. 77
However, one limitation of particle filtering is that a large number of samples may be required to accurately approximate state distributions, which may cause the filtering system to collapse. A good approach to solving the collapse problem is to adopt the efficiency monitoring method of filtering proposed by Carpenter et al. 78 Furthermore, several researchers have noted that the final outputs of particle filters are largely dependent on the particles obtained in the initial process. 73 In other words, errors generated by the initial state estimation would likely propagate and accumulate over time, increasing the uncertainty of the resulting prediction.
Numerous studies have applied particle filters to rotating machine prognostics. Wang 79 presented an engine wear estimation model based on particle filtering. In his work, the relationship between condition-monitoring measurements and system degradation was modelled using the concept of a floating scale parameter. PCA was employed to produce a one-dimensional representation of the monitoring data, which was then processed using a particle filter to obtain the density function of the systems wear. Butler et al. 80 developed a prognostic framework for the main bearing of a wind turbine. A residual, which was generated using a bearing temperature model, was extrapolated using a particle filter to produce the probabilistic RUL distribution. Recently, Sun et al. 81 applied a state-space model embedded with a particle filter to a gas turbine monitoring data set obtained via simulation. A HI, inferred using a linear regression method, was used to represent the latent degradation of the engine. The authors combined the state estimation with model parameter estimation to reduce the prognostic uncertainty. Their study also demonstrated the robustness of particle filters with regard to long-term RUL predictions. Wang and Gao 82 proposed a degradation prognostic model for jet engines based on regularized particle filtering (RPF). This model enables continuous tracking of both gradual and transient degradation. Recently, Baraldi et al. 72 combined a particle filter and a physical model to provide RUL predictions of a turbine blade seeded with creep damage. Their results demonstrate particle filters accuracy and superior uncertainty control capabilities with regard to predicting machine failures. More recently, Li et al. 39 developed an improved exponential model for rolling element bearings. The authors proposed a novel FPT selection approach for the detection of incipient faults. Once an FPT is decided, particle filter is utilized to predict the fault evolution and RUL. Lei et al. 37 proposed a particle filter-based method for RUL prediction of bearings. In this work, a fusion HI, inferred using a self-organizing map (SOM), was used to reflect the degradation process. The indicator was then input into a state-space model for RUL prediction. The results indicate that using the novel HI, which was constructed by fusing mutual information from multiple features, this model is able to provide more accurate RUL prediction than tradition methods.
HMM and HSMM
HMM
In state-space modelling, a dynamic system can be described at any time as being in one of a set of discrete states. The system evolves through a finite number of states until reaching the final state (failure) in accordance with a set of transition probabilities associated with the states. If the states in the above stochastic process are unobservable and responsible for producing a sequence of observations, we can call the state-space model a HMM.
83
The objective of implementing HMMs in prognostics is to forecast the evolution of the state of health of a system from its current state to its ultimate failure based on both observations and the model. A HMM is characterized using the following elements: the state transition probability distribution
Three problems associated with HMMs must be solved for a HMM to be used in real applications: 83 (1) given a model and an observation sequence, how well do the observations match the model? (2) given a model and an observation sequence, how do we find the state sequence that most likely results in the observation sequence? and (3) given the observations, how do we optimize the model parameters such that the model best matches the observation sequence? Theoretically, problem 1 can be solved by enumerating every possible state sequence with the same length as the observation sequence. However, in practical situations, this is computationally unfeasible. 83 Therefore, a more efficient solution is required for problem 1. Fortunately, such a method exists, and it is called the forward-backward (FB) algorithm. This algorithm efficiently calculates the required values in two passes: a forward pass and a backward pass. For more information, see Schuster-Böckler and Bateman. 84 Problem 3 allows us to adjust the model parameters to maximize the likelihood of the given observations. In practice, the Baum-Welch EM algorithm is commonly used to solve this problem by iteratively adapting the parameters to the measurements until convergence is achieved. 83 For problem 2, we can use the Viterbi algorithm to find the state sequence best associated with the observation. Details regarding this technique can be found in Viterbi. 85
HMM has been used extensively in the literature86–88 to estimate health states and diagnostics. However, taken collectively, the results indicate that standard HMM invokes a heavy computational burden because of the competitive learning process. This situation may worsen when HMM is applied to multidimensional observations, such as those typically collected from complex rotating machines. 87 Although additional sensors would improve overall performance, it has been recommended that developers consider the negative effects of sensor fusion, such as the computational complexity involved when using regular HMMs. 87 Another problem with standard HMMs is that they do not provide the tools required to calculate state transition probabilities because each HMM represents a unique health state. 88 To estimate the RUL, we must incorporate additional techniques into the model. Bunks et al. 86 proposed a solution to this problem based on prior information regarding the frequency of occurrence of each heath state. However, this method cannot provide satisfactory RUL predictions when true information regarding underlying health states is not available. In order to solve the above-mentioned difficulties, Chinnam and Baruah 88 proposed three feasible RUL estimation methods. The first method involves predicting RUL based on the state transition probabilities learned via the training process. The probability distribution of RUL can be calculated as the mean and variance values from a large simulation sample generated by the Monte Carlo technique. The second method predicts RUL by jointly considering the RUL distribution and the state log-likelihood. The third method employs a regression model to estimate RUL as a function of the state log-likelihood. The authors also compared the performances of the three methods and found that the first and the third method performed better than the second method in the presence of high-dimensional observations.
The standard HMM has been successfully used in prognostics. Camci and Chinnam 89 implemented a regular HMM for health state identification and RUL prediction. The state transition probability-based method (the first method mentioned above) was used together with Monte Carlo simulations to estimate the remaining lifetime of a computer numerical control (CNC) drill machine. The results indicate that standard HMM can provide reasonable diagnostics and prognostic accuracy based on multivariate sensory data. Recently, Giantomassi et al. 2 proposed a hybrid model to estimate the health and prognoses of turbofan engines. In this instance, an artificial neural network (ANN) was first employed to extract features from multivariate observations, and then, a HMM-based prognostic model was used to determine the RUL. Unfortunately, an RUL estimated in this way always contains a large error, which persists until the end of the prediction.
To overcome the difficulties in implementing regular HMMs for RUL prediction, Fine 90 developed a modified algorithm called the hierarchical hidden Markov model (HHMM). HHMM is an extension of HMM that contains several sub-HMMs designed to facilitate RUL estimation. 90 Each sub-HMM of a HHMM is composed of several hidden states, and a system can transition between hidden states within a given sub-HMM. HHMMs have a number of advantages over HMMs. First, top-level model states can be used to represent underlying system states, whereas sub-level model states enable modelling of the systems non-stationarity. In addition, HHMMs enable us to model all system health states using only one model. Thus, the heavy computational burden required by competitive learning can be avoided. Most importantly, HHMMs directly capture state transition probabilities, which is not possible with regular HMMs. 89 Camci and Chinnam 89 applied a two-level HHMM to monitor the drill-bits on a CNC machine. Their results show that the proposed model is a very promising tool for effective RUL prediction.
Another extension was proposed by Soualhi et al. 91 The authors incorporated the estimation of the imminence of a fault into standard HMMs. The risk of the imminent appearance of a fault was modelled as a function of the state transition probability, the emission probability and the forward variable resulting from the FB algorithm. The results indicate that a large horizon of prediction can be achieved using the proposed model.
HSMM
One problem with the HMM models discussed above is that they do not consider state duration modelling. Thus, another extension to HMM, HSMM, was developed to improve the accuracy of RUL estimations. HSMM applies grid-based techniques to estimate health state–related probability distributions. 92 HSMMs assume that a system usually goes through a number of distinct health states before reaching failure, and the unobservable health state is continuous but can be partitioned into N segments. The probability distributions of the durations of each health state can be estimated using statistical inference. Estimated state duration probabilities can be subsequently employed to predict the RUL. HSMM has been extensively applied to prognostics. Dong and He 93 developed a prognostic framework based on HSMM for pumps. Discriminant function analysis was employed to determine the weightings of different sensor signals. The calculated health state duration probability distributions were used to predict the RULs of the pumps. Recently, Liu et al. 94 proposed an integrated diagnostic and prognostic model for multi-sensor systems based on the adaptive hidden semi-Markov model (AHSMM). The results demonstrate the low computational complexity of the AHSMM and show that it can obtain accurate RUL prognostics for equipment with multi-sensor information. Chen et al. 95 proposed an improved HSMM (multi-sensor mixture HSMM) to provide better representations for non-stationary, non-Gaussian multidimensional time series. In this model, the duration of each health state is modelled as a single Gaussian distribution and is obtained during training. Once the current state of the system is identified, the RUL can be calculated using a backward recursive process. Although multi-sensor fusion can be successfully achieved using this model, the assumption that the system always has a fixed degradation mode may not hold true in real-world applications.
HSMMs are excellent for distinguishing the different degradation stages of a machine. However, this methodology has some drawbacks. First, it may be difficult to relate the artificially defined state transition points to the actual degradation process because of difficulties with regard to the physical observation of the evolution of the fault. 7 Moreover, as the number of health states increases, the computational cost of HSMMs becomes extremely heavy. 96 Future efforts should be made to improve the computational efficiency of this method.
Stochastic filter
Most of the existing filtering-based models use a state vector to describe the health condition of the system under investigation. One disadvantage of these models is that they need to find an appropriate failure threshold to determine the remaining lifetime. In order to overcome the limitations of traditional filtering methods, Wang and Christer
20
developed a state-space prognostic model embedded with a stochastic filtering technique. In this model, they define the condition of a mechanical system as its condition residual time (CRT), namely, the time lapse from any time point that condition monitoring data is captured to the time that a failure may occur. The term CRT can be also referred to as RUL if no maintenance action is carried out during the time lapse. Having defined a new measure of system health state, the authors then seek to predict the CRT of an asset based on the following formulae:

Various extensions have been developed and applied to rotating system prognostics based on the above framework. A revision of this stochastic filtering was applied to the lifetime data and monitored oil analysis data collected from an aircraft engine. 97 PCA was first employed to obtain a weighted average of the original monitored data. The RUL was then predicted from the transformed monitored observations. A similar model is presented in Wang et al. 98 in which the authors combined lifetime data and accumulative metal concentration data to estimate the RUL of a diesel engine. Again, PCA was employed to reduce the dimensions of the input data. Similarly, Wang and Hussin 99 developed a stochastic filtering-based prognostic model and applied it to two data sets: engine lubricant and contaminant analysis data and metal concentration data. Instead of the commonly used PCA, they employed independent component analysis (ICA) to fuse the model inputs. The results indicate that higher accuracy can be achieved when the lubricant and contaminant data sets serve as the basis. Another extension of Wang’s stochastic filtering was reported in Wang, 100 which extended the original filtering in terms of two aspects: (1) the concept of a two-stage life model was introduced to achieve both fault detection and prediction and (2) a combination categorical and continuous hidden Markov chain was used to model the underlying health state transitions. The authors suggested that a PCA algorithm can be used in combination with the proposed model to address multidimensional data in complex rotating systems. Recently, Wei et al. 38 proposed a stochastic filter-based model to use the multi-sensor information for better RUL prediction. They also compared two sensor fusion approaches with the results obtained from a single sensor and found that a higher prediction accuracy can be achieved by the stochastic filtering-based model.
Although the above stochastic filtering techniques could make predictions without setting a failure threshold, they have some limitations: (1) to apply the above model, one pre-requisite is that the initial value of
ANN-based models
Recently, ANNs have been widely used to model degradation processes. An ANN is a computing system that can capture, represent and compute mapping from the input multi-variable space to the output space. 101 ANNs comprise a large number of processing elements (known as neurons) that are connected to each other by weighted interconnections. 102 These neurons are organized into distinct layers, and their interconnections are determined using a training process. This network training involves presenting data sets collected from the degradation process. Subsequently, the network parameters are adjusted to minimize the errors between the model output and the desired output. 101 Once the training is finished, ANNs process new input data to make predictions about the outputs.
Network architectures that have been used for prognostics can be classified into two types: feed-forward and recurrent networks. 103 In feed-forward networks, the signals flow in one direction; therefore, the inputs to each layer depend only on the outputs of the previous layer. However, applications in signal processing and prognostics should consider the system dynamics. Recurrent networks is such a method that can provide an explicit dynamic representation by allowing for local feedbacks. 104 Researchers have extensively applied two types of networks multi-layer perceptron (MLP) and recurrent neural networks (RNNs) (Figure 3 shows the architecture of a simple RNN) which are discussed below:
MLP. MLPs are one of the most popular feed-forward neural networks used for prognosis. MLPs utilize the back-propagation (BP) learning technique in conjunction with an optimization method such as gradient descent and Levenberg–Marquardt for training. 105 At completion of a training process, the MLP is capable of giving output solution for any new input based on the generalized mapping that has been developed. 106
RNN. Feed-forward neural networks have limitations with regard to identifying temporal dependencies in time series signals. 107 RNNs overcome this problem by including local or global feedback between neurons. Thus, they are suitable for a wide range of dynamic systems, such as time-varying and nonlinear systems. 107 However, the drawback of RNNs is that their accurate long-term predictions are limited because of the frequently used gradient descent training algorithm. 107
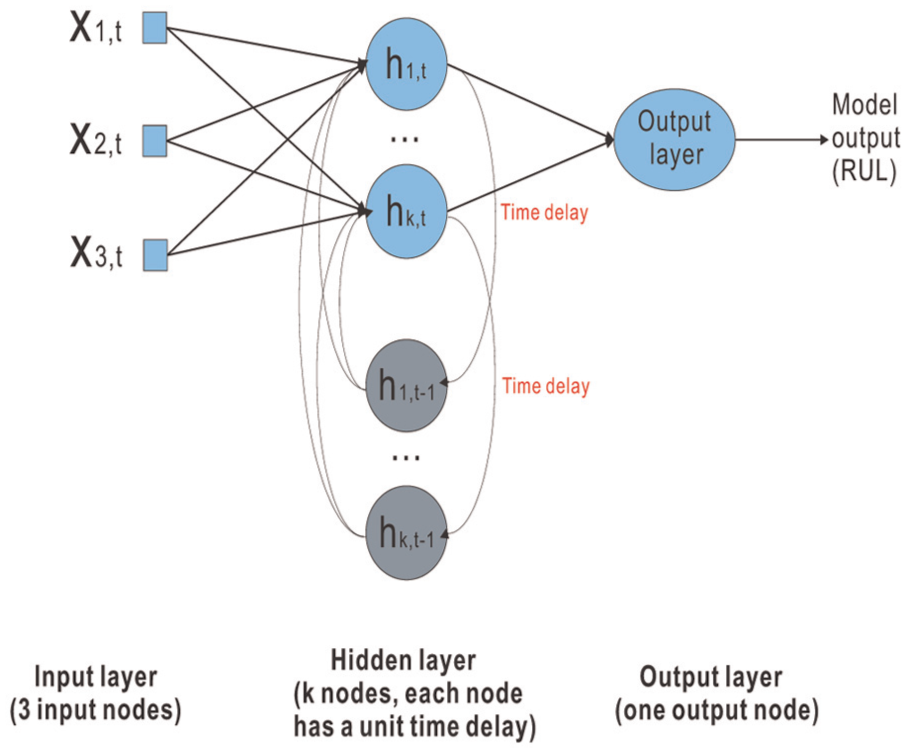
Architecture of a simple RNN.
ANNs can represent and build mappings from experience and historical measurements to predict RULs and adapt them to unobserved situations. The strong learning and generalization capabilities of ANNs render them suitable for modelling complex processes, 102 particularly systems with nonlinear and time-varying dynamics.106,108,109 In addition, ANNs are superior in capturing and presenting relationships between variables in high-dimensional data space, making them powerful tools for multidimensional interpolations,102,109–111 whereas RNNs are suitable for approximating dynamic dependencies. 107 These distinct characteristics make ANNs promising candidates for modelling degradation processes in rotating machinery.
Xu et al. 112 successfully employed RNNs, SVMs and DSR to estimate the RUL of an aircraft gas turbine. An echo state network (ESN), which is a variant of RNNs, was employed by Peng et al. 113 to predict the RULs of engines using National Aeronautics and Space Administration (NASA) repository data. Their results indicate that the ESN significantly reduces the computing load of traditional RNNs. ANNs have also been used in combination with Kalman filters and extended Kalman filters114,115 to predict failures in aircraft engines.
Although ANNs have been shown the superior power in addressing complex prognostic problems which have multivariate inputs, there are some limitations. For example, the majority of the ANN prognostic models aim to assume a single failure mode. Moreover, the models rely on a large amount of data for training. The prognostic accuracy is closely dependent on the quality of the training data. 112 Furthermore, ANNs allow for few explanatory insights into how the decisions are reached (also known as the black box problem), which has become concerning to modellers because causal relationships between model variables are essential for accurate descriptions of fault evolutions. 116 Attempts to solve the black box problem can be found in Sussillo and Barak. 117 Moreover, ANNs lack a systematic approach to determine the optimal structure and parameters of the network to be established. 110 And in practice, the number and size of layers (especially hidden layers) are determined by testing a number of different combinations of numbers of layers and nodes, which is obviously time consuming. Thus, future studies should focus on establishing this systematic approach.
PHMs
Machine failures can be predicted by analysing either condition monitoring data or historical service lifetime data.118,119 Developing appropriate prognostic models using a combination of condition-monitoring data and lifetime data would be useful. The PHM, proposed by Cox,
120
attempts to utilize both types of information for RUL prediction. The basic assumption of this method is that the failure rate of a machine depends on two factors: the baseline hazard rate and the effects of covariates (different condition monitoring variables). Hence, the hazard rate of a system at service time t can be written as
PHMs have been applied to many complex problems regarding the failure prediction of rotating machinery. Jardine et al. 124 developed a PHM and employed it to estimate the RULs of aircraft engines and marine gas turbines. The baseline hazard function was assumed to be a Weibull distribution and was estimated using lifetime data. The levels of various metal particles, such as Fe, Cu and Mg, in the oil were used as the covariates in both cases. The influence of the condition-monitoring variables on the equipment RUL can be properly interpreted by this PHM. The authors also used the PHM to estimate the RUL and optimize maintenance decisions regarding haul truck wheel motors in Jardine et al. 122 In this study, the key covariates related to failures were identified from 21 monitored oil analysis variables using the developed PHM. The results show that significant savings in maintenance costs could be achieved by optimizing the overhaul time as a function of lifetime data and oil analysis variables. However, the above models are based on the assumption that the system under study is subject to a single failure mode. In practice, most complex mechanical systems consist of multiple sub-systems with various failure modes. 118 Therefore, a prognostic model that determines only one type of failure mode cannot properly estimate the overall system failure time. Recently, Zhang et al. 118 proposed a mixed Weibull proportional hazard model (MWPHM) to assess the reliabilities of complex mechanical systems. In this model, the overall system failure probability density is determined by mixing the failure densities of various failure modes. The influences of multiple monitoring signals on different failure modes are integrated using the maximum likelihood estimation algorithm. Real data from a centrifugal water pump were combined with lifetime data to test the robustness of the model.
The main problem with using PHMs for failure prediction is that they require a large amount of lifetime data to determine the parameters of the baseline hazard function and the weighting of covariates. 119 This requirement may limit the applications of PHMs because, in many cases, the amount of lifetime data may be insufficient for various reasons, including missing or non-existent records and transcription mistakes. 125 Another drawback of PHMs is that they depend on the failure thresholds chosen for RUL prediction. Thus, the threshold must be continuously updated when system maintenance is conducted. 118 In addition, it is noteworthy that only the latest monitoring data rather than the whole observed history is used for RUL prediction, which may misdirect maintenance decision making. 20
Similarity-based models
Similarity-based prognostic models are essentially pattern matching approaches. 126 They are suitable for situations in which abundant run-to-failure data for a mechanical system are available. 127 The basic structure and working principle of such approaches is depicted in Figure 4.
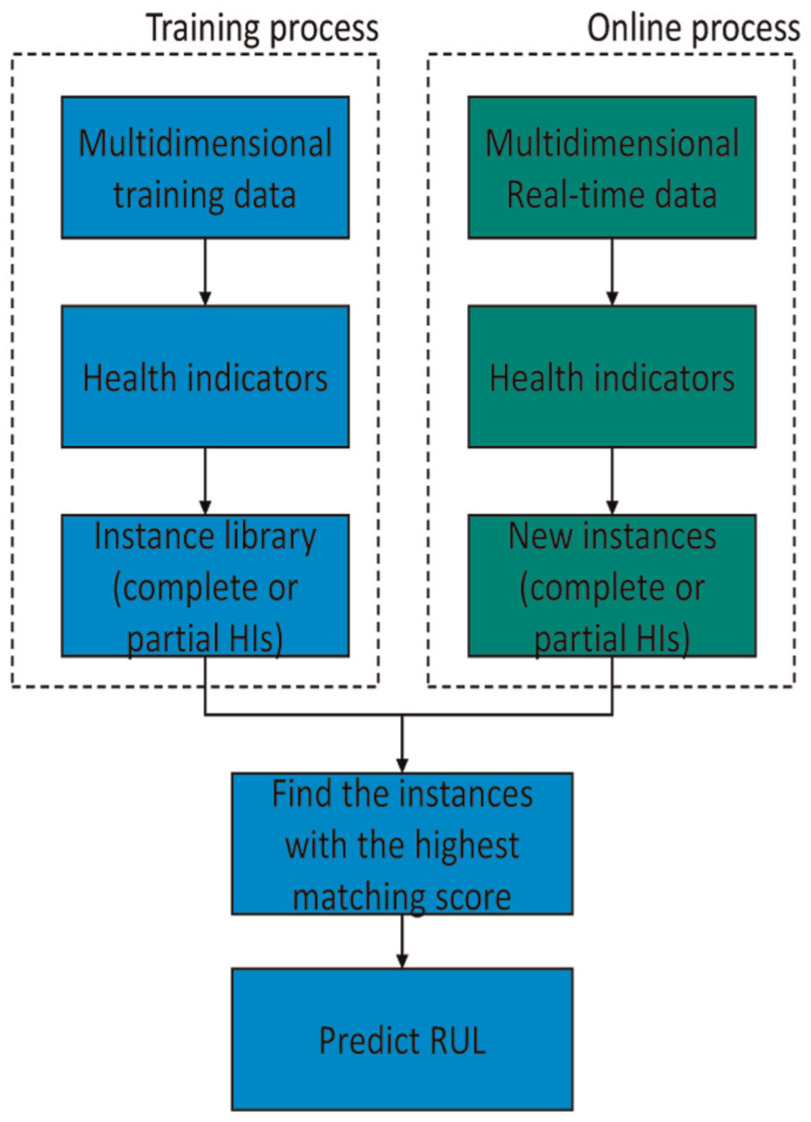
General framework of similarity-based prognostic models.
Multidimensional condition monitoring data collected from various operating conditions are first processed (e.g. noise reduction, feature extraction and multi-sensor data fusion) to produce a HI. This indicator represents the fault evolution using HI trajectories and is often a one-dimensional time series. Implementing the same processing operations to all training data sets, each multidimensional training series can be converted into a unique HI trajectory. Hence, a library of HI trajectories can be obtained during the training process. To predict the RUL using a new data set, the same processing operations are applied to the data to produce a new HI. Then, this new trajectory is compared with the library of HIs to determine which trajectory have the best matching scores (i.e. the most similar cases). 128 Those HIs with the highest similarities are subsequently used to predict the RUL.
Similarity-based methods differ from traditional prognostic models in that instead of fitting a curve for a system and extrapolating it, the sensory data are transformed into a HI trajectory and then compared to a library of HIs. The purpose of doing this is to match the new HI trajectory to a certain life period of a certain trajectory in the library. Then, the remnant life of the test component is calculated using the real life of the matching component subtracting the position of the matching life period. 127
The ability to accommodate multidimensional sensory measurements collected from various failure patterns makes similarity-based methods suitable for determining the prognostics of complex rotating machinery. Examples are given below to demonstrate how various similarity-based models have been used for RUL prediction.
Similarity model based on shapelet extraction
Malinowski et al. 128 developed a RUL prediction technique that employs the shapelet extraction process to extract failure patterns from multivariate data obtained from a turbofan engine simulation program: C-MAPSS. The RUL is calculated as the weighted sum of the failure patterns, which are highly corrected with the residual life.
Similarity model based on normalized cross correlation
Zhang et al. 129 applied a prognostic method based on the similarity of the phase space trajectory to the monitoring data collected from a pump with six distinct degradation modes.
Similarity model based on PCA and K-NN classifiers
Mosallam et al. 130 employed PCA and empirical mode decomposition (EMD) algorithms to construct HIs from turbofan engine deterioration data. Then, K-nearest neighbour (K-NN) classifiers were used to determine the most similar HIs for RUL prediction.
Similarity model based on belief functions
A method based on belief functions was proposed by Ramasso and colleagues.131,132 These authors only matched the last points of the trajectories with tested ones because the last points are more likely to be closely related to the degradation state.
Similarity model based on linear regression and Euclidean distance measurement
Wang et al. 127 proposed a prognostic model in which the HI is obtained using linear regression. The best-matching instances are selected by examining the Euclidean distance between test and stored instances. This method has been applied to engine monitoring data to predict the RUL.
Similarity model based on support vector regression
Wang et al. 133 have improved upon the previous models by incorporating uncertainty information into the RUL estimation. Towards this end, they estimated HI degradation curves using RVM. Challenge data were employed to test the effectiveness of this method.
The advantage of similarity-based approaches is that they can deal with data collected from various failure modes and varying operating conditions. Furthermore, they can produce satisfactory and accurate predictions using abundant run-to-failure data. However, such data are commonly scarce in reality. 126 Additionally, many similarity-based prognostic techniques suffer from computational inefficiency in terms of sorting a large amount of training data. 131 Hence, efforts should be made to extend these approaches to situations where limited training data are available and to reduce the computation complexity of such methods.
Summary of prognostic models of rotating machinery
In Table 1, the authors provide seven evaluation criteria that can be used to compare the prognostic techniques reviewed in this article. These criteria for each technique include the following:
Its ability to deal with nonlinear and non-stationary data.
Does this technique require large amounts of historical failure data?
Does this technique require a failure threshold?
Is this technique able to produce probabilistic results?
Is an analytical model a pre-requisite?
Requirements of historical condition monitoring data.
Prediction horizons (see column 2 of Table 2).
Comparison of different prognostic approaches.

Applications of multidimensional prognostic models.

RUL: remaining useful life; SVM: support vector machine; PSO: particle swarm optimization; RBF: radial-based function; PCA: principal component analysis; HMM: hidden Markov model; ANN: artificial neural network; ICA: independent component analysis; RNN: recurrent neural network; DSR: Dempster–Shafer regression; ESN: echo state network; PHM: proportional hazard model; K-NN: K-nearest neighbour; HSMM: hidden semi-Markov model; AHSMM: adaptive hidden semi-Markov model; MWPHM: Weibull proportional hazard model; DKF: distributed Kalman filter; HHMM: hierarchical hidden Markov model; LSSVM: least squares support vector machine; FPT: first predicting time.
Readers can use the listed criteria to compare different prognostic techniques according to practical needs.
Table 2 summarizes the applications of different RUL prediction models to various multi-sensor rotating machines and the machines common available data types. Furthermore, the reviewed articles (those appearing in Table 1) are classified based on the type of data employed in the article:
Simulated data collected from simulation programs, such as C-MAPSS;
Field data (real-world condition-monitoring data);
Data collected from experimental test rigs.
Figure 5 summarizes the types of data used in the studies reviewed.

Type of data used in studies regarding various reviewed rotating machines.
According to the reviewed articles, the RUL estimate of gas turbine engines is the main application field. Moreover, about 50% of studies use simulation and experimental data for RUL analysis. This is because obtaining sufficient field data from operating machines is difficult and because inaccuracies may arise when applying these models to real-time data.
Conclusion
This article reviews multidimensional prognostic models for predicting the RULs of rotating machines. The prognostic models reviewed herein make predictions based on condition-monitoring information obtained from multiple sensors. Relevant theories are discussed, and the merits and limitations of the main prognostic model classes are detailed. Examples are given to explain how these approaches have been applied to predict RULs of multi-sensor rotating machinery. From the literature reviewed herein, a number of observations and suggestions can be made as follows:
The prognostic models reviewed herein can predict RULs accurately based on multi-source information. Compared to single-source prognostics, these models can provide more accurate results by considering the multi-source nature of the information. Therefore, they are particularly suitable for complex rotating systems because data from a single sensor cannot provide sufficient information to accurately analyse the degradation process.
In practice, the implementation of the models reviewed remains in the nascent stage, although a considerable number of studies have been performed based on simulated and experimental data. Therefore, efforts should be made to validate the effectiveness of these models using real-world data.
Although we may achieve more accurate prognostics using more sensor information, balancing the prediction accuracy and computational complexity remains challenging in practice. In addition, current sensor selection relies mainly on the developers’ observation of the raw condition-monitoring data (e.g. only variables exhibiting consistent trends or those acquired in components where a fault occurs are selected for further analysis). However, sometimes, the surrounding variables that are eliminated may also contain information relating to malfunctions because the system always operates as a whole entity. Therefore, future research should focus on developing (a) prognostic models with higher computational efficiencies and (b) sensor selection techniques that can automatically determine the optimum number of sensors for RUL prediction.
Many of the prognostic models reviewed provide probabilistic results to manage the estimation uncertainty caused by the stochastic nature of the degradation process. However, limited numbers of papers have studied the effects of performance deterioration in the multiple sensors. Hence, efforts should be made to quantify the influence of sensor degradation on uncertainties in RUL estimations.
In addition, future research should develop prognostic models that better adapt to continuously changing operating conditions (e.g. varying operating speed, input gas pressure and flow rate) during the degradation process.
Most of the techniques reviewed herein were originally designed for a signal failure mode occurring at a single defect point; therefore, future work should be focused on developing prognostic models that can be applied to multiple failure modes.
Most existing prognostic models consist of two phases: a learning phase, during which the analytical model is trained using run-to-failure data, and a testing phase, during which the trained model is employed to assess the state of the current system and to predict the systems RUL. However, few of these include a diagnostic model. Additional work is required to combine a multivariate diagnostic technique with the existing prognostic models, thereby allowing for online diagnosis and prognosis and real-time maintenance scheduling.
Footnotes
Academic Editor: Yonghui An
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by London South Bank University.