
Abstract
We present a novel pedestrian count estimation approach based on global image descriptors formed from multi-scale texture features that considers spatial distribution. For regions of interest, local texture features are represented based on histograms of multi-scale block local binary pattern, which jointly constitute the feature vector of the whole image. Therefore, to achieve an effective estimation of pedestrian count, principal component analysis is used to reduce the dimension of the global representation features, and a fitting model between image global features and pedestrian count is constructed via support vector regression. The experimental result shows that the proposed method exhibits high accuracy on pedestrian count estimation and can be applied well in the real world.
Keywords
Introduction
Among all the objects involved in a transportation system, pedestrians are the major participants. Pedestrian count estimation plays an important role in the management and control of urban traffic, which can bring potential benefits to optimize the design of traffic infrastructure for pedestrian safety.1,2 In addition, pedestrian count is a crucial identification parameter of crowd status and is fundamental for the analysis and simulation of pedestrian evacuation behavior.3,4 Therefore, an efficient and accurate pedestrian count estimation method can potentially enhance the safety and mobility of pedestrians; moreover, it has important practical value for crowd surveillance.
Recently, video surveillance equipment has been widely installed in urban roads and public areas, providing an effective way for pedestrian counting. Various pedestrian counting solutions are available in the visible spectrum, which are generally categorized into individual detection-based approaches and crowd amount estimation-based approaches. Moreover, a number of comprehensive survey studies have been published in this field.5–8 The individual detection-based approach is a pedestrian count estimation method based on individual detection or tracking in the scene.9–11 These methods typically use pre-trained classifiers to scan images in possible locations and scales to determine whether the scanning window contains a pedestrian. Haar feature and boosting classifier were used in Viola et al. 12 Meanwhile, the histograms of gradient feature and support vector machine (SVM) classifier were used in Dalal and Triggs. 13 In previous studies,14–16 several novel features or substantially powerful classifiers were utilized for multiple pedestrian detections. In addition, some approaches rely on tracking methods to detect pedestrians within sequential frames. Each independent pedestrian is detected by clustering interest points of motion region. These detection- or tracking-based pedestrian count estimation methods rely on an individual pedestrian in a scene to determine the total number via a cumulative sum. These methods can achieve good performance in the count estimation of a sparse crowd in normal scenes. However, their performances in crowded scenes are far from satisfactory because of heavy occlusions and the complex spatial relationship among different pedestrians.17,18
For crowd amount estimation-based approaches, the crowd is selected as the study object, and regression-based methods are used to estimate the number of pedestrians in a scene by extracting the statistical features of crowds in an image. 19 Regression models are built based on the crowd features computed from images and the number of pedestrians in the crowd. The method based on crowd feature analysis can overcome the effects of a complicated background and heavy occlusion, which is suitable for the count estimation of a dense crowd. Davies et al. 20 assumed that a linear relationship existed between the number of pedestrians and foreground pixels. The number of pedestrians can be obtained according to linear regression fitting. However, this method can only be applied to a sparse crowd. The literature 21 proved that a non-linear relationship existed between the number of pedestrians and foreground pixels in a dense crowd.
Image distortion may occur because of the effects of the capture angle and capture distance of the camera, which can vary pedestrian scales at different depths. Therefore, some methods have adopted spatial constraint and perspective rectification of images for pedestrian estimation. Lempitsky and Zisserman 22 focused on spatial constraint to study the spatial density of objects in an image by iteratively adding bounding boxes with the largest error. Chan and Vasconcelos 23 extracted a set of gray-level co-occurrence matrix (GLCM) from segmented image regions with perspective normalization and estimated the number of people per segment using Bayesian regression. Wu et al. 24 proposed a perspective projection model to produce improved density estimation in a crowded scene. The literature19,25,26 used a series of texture features to express a crowd as well as utilized perspective correction and camera calibration for weighting and correcting the foreground features of a crowd.
From the literature review, several achievements of pedestrian count estimation have already been established. However, camera calibration should be performed in advance because the algorithm only works at a certain position. If the capturing position, direction, or angle of the camera changes, then the camera should be recalibrated. 27 In this study, we present a novel pedestrian count estimation approach based on global image descriptors formed from multi-scale texture features that considers spatial distribution. Histograms of multi-scale block local binary pattern (HMBLBP) are used as local descriptors, which are capable of encoding texture information from local regions of crowd images. Subsequently, the obtained local features are concatenated to form global features. Furthermore, a model based a global image descriptor and pedestrian count is built via support vector regression (SVR) to achieve an effective estimation of pedestrian count.
Proposed method
A number of methods have attempted to predict pedestrian count using regressions trained with low-level features. These methods are suitable for crowded environments and are computationally efficient. Our method comprises four parts: region of interest (ROI) extraction, local feature representation, global image feature representation by considering spatial information, and pedestrian count regression model construction. Instead of perspective rectification and camera calibration, spatial representations of local texture features are utilized to reduce the effects of image occlusions and distortions caused by the capturing angle or position of the camera.
ROI extraction
In general, a pedestrian traffic image has numerous contents captured from the sidewalk or campus road. The image scene does not only include the road but also several buildings, landscapes, and infrastructure. For pedestrian count estimation, we only focus on the sidewalk. The rest of the image contents can be neglected because they do not affect pedestrian counting. First, the ROI of crowd images should be extracted to enhance efficiency and reduce the computational cost of the algorithm. A piece of sequential images with pedestrian-free traffic flow should be selected. From the sequential images, k frame samples with a fixed time interval are chosen. Then, we calculate the standard deviations of each pixel value in the k frames. Furthermore, the entire image is divided into m × n cells. The standard deviations of all the pixels in a cell are cumulated. Accordingly, a mean value, which reflects the foreground variety of a cell, can be obtained. For a crowd image, two parts are considered: the foreground and the background. The background is the ROI that we focus on. In this study, k-means clustering is used to distinguish the background from the foreground. In this way, the ROI of a traffic image can be extracted using a simple method.
Local feature representation
Several local descriptors for image texture analysis and image classification are available. In this study, an improved version of the local binary pattern (LBP) for local feature representation, namely, HMBLBP, is utilized. LBP
28
is a non-parametric kernel that summarizes the local structure around a pixel. LBP is known to be a highly discriminative operator and has been successfully applied in classifying various types of textures.
29
A texture T in a local neighborhood of a monochrome texture image is defined as the joint distribution of the gray levels of

where

For each

where

A unique

When P = 8 and R = 1,

The basic LBP descriptor LBP8,1.
The multi-scale block local binary pattern (MBLBP) is the extendable descriptor of LBP8,1 with respect to neighborhoods of different sizes. 30 In MBLBP, the comparison operator among single pixels in LBP is replaced with the comparison among average intensities of sub-regions. Each sub-region is a block that contains neighboring pixels. An MBLBP descriptor is composed of nine blocks, as shown in Figure 2. In this manner, an output value of MBLBP can be obtained


where

The 9 × 9 MBLBP operator construction (including nine blocks, with 3 × 3 pixels in each block).
Compared with the basic LBP, MBLBP can capture large-scale structures that may be the dominant features of images. In addition, MBLBP can be calculated rapidly using an integral image method, 13 which is more costly than the basic 3 × 3 LBP operator.
Two MBLBPs with different block scales both have 256 bin histograms. Thus, for a local region, MBLBPs with different block scales have the same feature dimensions. Figure 3 provides examples of MBLBP with different block scales for a local region of images. As shown in this figure, the local micro patterns of a crowd structure are well-represented on a small scale, which may be beneficial for discriminating local details. However, using average values over blocks can reduce noise, which results in a substantially robust representation.
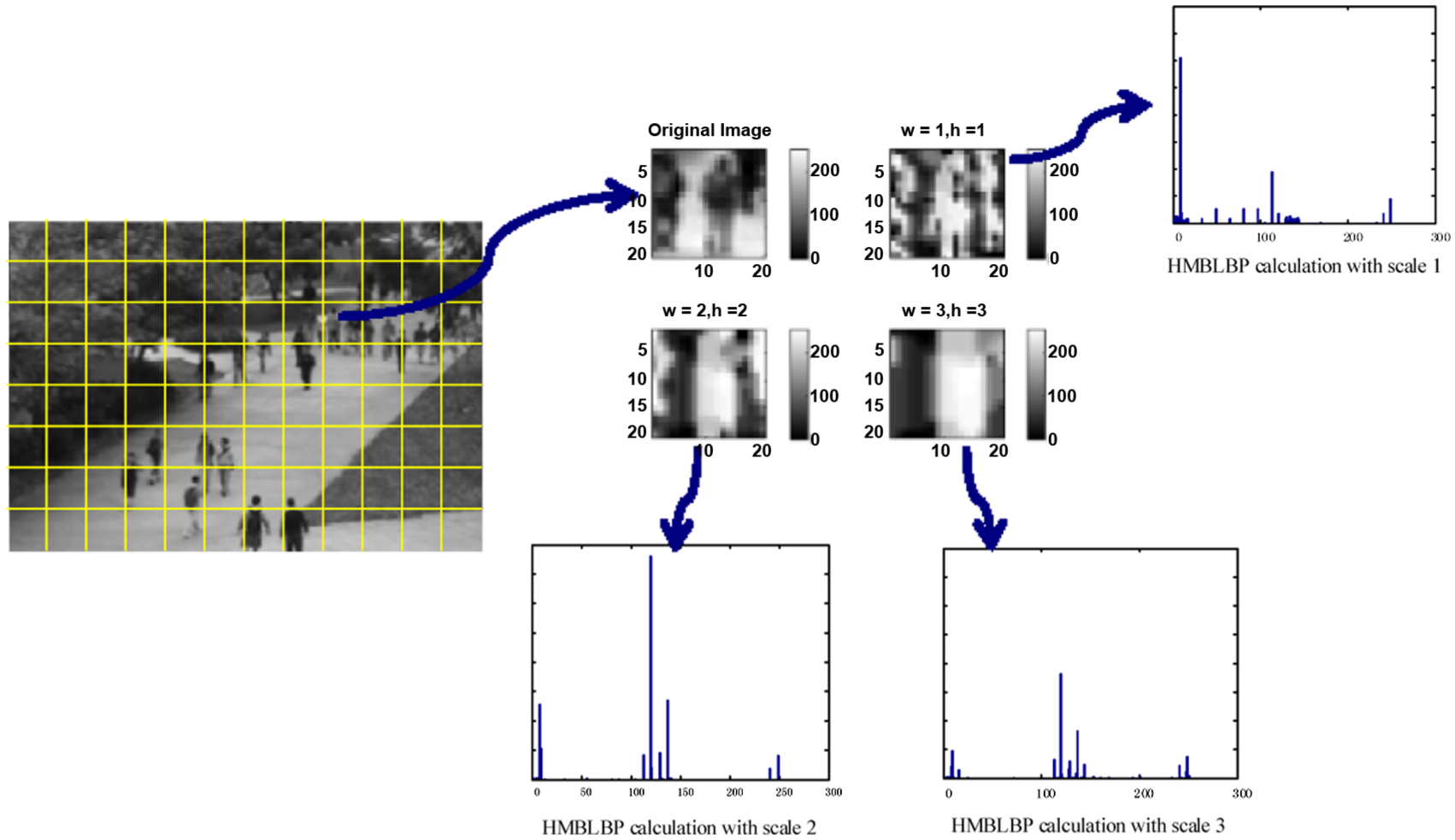
A cell’s HMBLBP with scales 1, 2, and 3.
A joint descriptor with different local descriptors of scales is typically used for a cell to reflect the comprehensive characteristics of a local feature. The feature dimension of an HMBLBP of a cell is equal to num_S × 256, where num_S represents the number of scales used in the HMBLBP of a cell.
Global feature representation
Image distortion may occur because of the effects of the capture position and capture angle of a camera, which can result in varying pedestrian scales at different depths. Accordingly, the crowd that is far from the camera area appears dense, and thus, occlusion can easily occur. Therefore, an effective global feature representation that considers spatial information is crucial to improve pedestrian count performance. In this study, we construct global descriptors with several local descriptors in the ROI and use the dimension-reduced HMBLBP based on principal component analysis (PCA) to represent crowd image.
In general, pedestrians are frequently localized to specific areas of the entire image, which is important in encoding spatial location. In addition, the context provided by the overall appearance of the crowd is also crucial for correct representation. Therefore, both micro and macro patterns should be represented. Similar to the dense grid framework, which has been successfully applied in challenging scene classification tasks, a global spatially distributed feature representation is used, which provides spatial organization in conjunction with multi-cell descriptors. The global descriptor construction stages are illustrated in Figure 4.

Stages in constructing a global image descriptor with ROI.
Histogram descriptors have been proven to be an effective means to aggregate local intensity patterns into global discriminative features. For each cell of pixels, we calculate HMBLBP to represent the statistical distribution of different micro patterns. HMBLBP features in different scale blocks are calculated, and thus, the distribution of both micro and macro patterns can be obtained. The feature dimension of the HMBLBP of a cell is num_S × 256, where num_S is the number of the scales used in HMBLBP calculation. If num_R cells are present in ROI, then a dimension of the global feature will be num_R × num_S × 256. The concatenation of histograms from each cell to form the global feature vector results in a relatively high dimension. Hence, we should perform dimensionality reduction to save computational cost. In this study, the PCA method is adopted to obtain the principal components and reduce the dimensions of global representation features.
Regression model
After computing the global features of crowd images, we use SVR to build a non-linear regression model based on global features and pedestrian count. SVM can be easily generalized because it uses structural risk minimization to consider the fitness and complexity of the training sample. The global feature vector (ROI + HMBLBP + PCA) of a crowd image is constructed from the data set samples and is used as the input for the regression model. The pedestrian count of each image is annotated manually. The optimized parameters c and g of SVR are selected with cross-validation using the grid search method to improve regression performance. Then, the non-linear regression relationship between the crowd global feature vector (
Experimental results
The University of California, San Diego (UCSD) pedestrian data set with crowded scenes 19 is tested to evaluate the performance of the proposed pedestrian count method. The UCSD data set is a public pedestrian database that is commonly used for pedestrian count and anomaly detection. The data set contains a crowded scene captured from a perspective that overlooks a pedestrian walkway in UCSD using a stationary camera. The UCSD pedestrian data set is captured from an oblique view of a walkway and includes a large number of people, as shown in Figure 5. The data set comprises 10 video clips, with each clip containing 200 sequential frames of video images. The maximum value of the pedestrian count in the image sequences is 45, whereas the minimum is 12. The resolution of the images is 238 × 158. To utilize our ROI extraction method, the images should be resized to 240 × 160. All 2000 images are annotated with the number of pedestrians, which are used as ground truths.

UCSD pedestrian data set.
We conduct a systematic comparison of several configurations of our system to choose which types of features, dimensionality reduction methods, and numbers of training samples for predicting pedestrian count should be used. The mean absolute error (MAE) and the root mean squared error (RMSE) are used as the evaluation metrics between the predicted pedestrian count and the ground truths

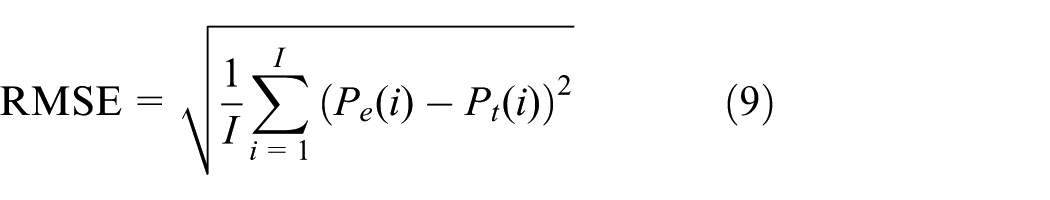
where I is the total frame number of test images,
At first, 100 frame samples with five frame interval selected from the third to the sixth clip files are chosen to extract ROI, which could reflect a good performance of the foreground variety. Figure 6 shows the result of ROI extraction of UCSD pedestrian data set (image resolution is 240 × 160, m = 12, n = 8). Then we attempt to extract HMPLBP-based global features and use SVR to estimate the crowd counts of the UCSD pedestrian data set. We selected the third to the sixth clip files as the test set and the rest as the training set. In all, 800 frames are employed as the training data and the remaining 1200 frames as the test data. The block scales of HMBLBP, namely, 1, 2, and 3, are represented as local details. In this study, the image is divided into 12 × 8 sub-regions for ROI extraction. A total of 21 cells can be obtained using our proposed ROI extraction method. The feature dimension of the HMBLBP of a cell is num_S × 256, where num_S is the number of the scales used in HMBLBP calculation. In this manner, for an HMBLBP with three scales, the dimensions will be 21 × 3 × 256 = 16,128 dimensions. The global feature vector results in a relatively high dimension. When PCA is utilized, the dimension of the global representation features can be reduced to 1364 dimensions. The estimation results of the proposed method are illustrated in Figure 7.

Result of ROI extraction: (a) original image and (b) ROI (gray cells’) extraction.
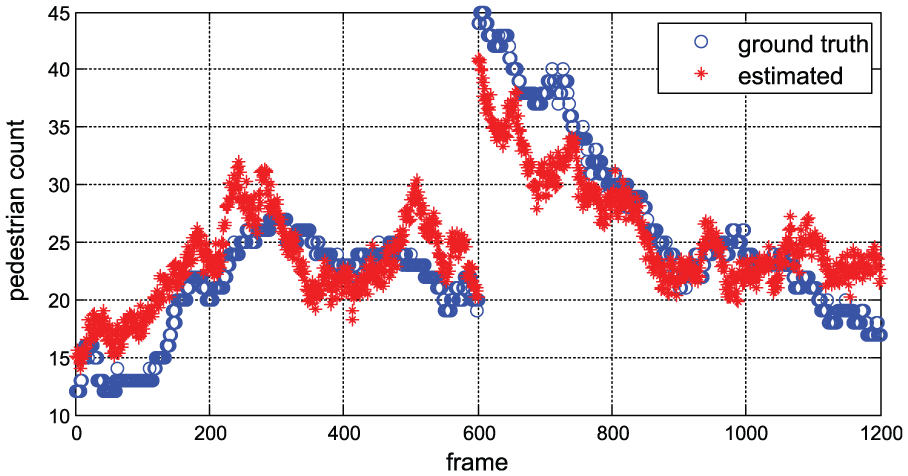
Estimation result of the UCSD pedestrian data set.
The tests have shown that the proposed pedestrian count estimation method exhibits high accuracy. When only HMBLBP feature with scale 1 is used, an MAE of 3.11 and an RMSE of 3.99 are obtained. In contrast, when HMBLBP feature with scale 3 is used, an MAE of 3.76 and an RMSE of 4.59 are obtained. The result achieves the best performance for HMBLBP with scale 3 that is in conjunction with the local descriptors. The MAE and RMSE are 2.98 and 3.58, respectively. To validate the performance of HMBLBP as local features, we compare them to other feature representation methods based on several popular descriptors such as GLCM 23 and scale-invariant feature transform (SIFT). 30 When GLCM + ROI + PCA are used, the MAE and RMSE are 3.7 and 4.68, respectively. Meanwhile, the MAE and RMSE are 3.7 and 4.68, respectively, when SIFT + ROI + PCA are used. The experiment results show that our pedestrian estimation method achieves improved performance by incorporating additional space distribution information (Table 1).
Evaluation of pedestrian count estimation algorithms.

MAE: mean absolute error; RMSE: root mean squared error; HMBLBP: histograms of multi-scale block local binary pattern; ROI: region of interest; PCA: principal component analysis; GLCM: gray-level co-occurrence matrix; SIFT: scale-invariant feature transform.
The effect of varying training set size is also examined using subsets of the original training set. Figure 8 shows the plot of RMSE versus training set size. The algorithm is developed and tested on MATLAB platform. The computer is powered by 3.6 GHz Intel Core™ i7 and has 4 GB RAM. We use the LIBSVM Toolbox to build the SVR regression model. 31 The radial basis function is used as the kernel function of the model. The model parameters are optimized via cross-validation before model training. In addition, the average feature computation time is approximately 0.1 s, and the average prediction time of each image is approximately 0.021 s (Figure 9). Therefore, estimating the number of pedestrians per frame takes 0.12 s. This estimation method can be used in practical applications given the effects of other application programs that are simultaneously running in the system.

Estimation results for different training set sizes.
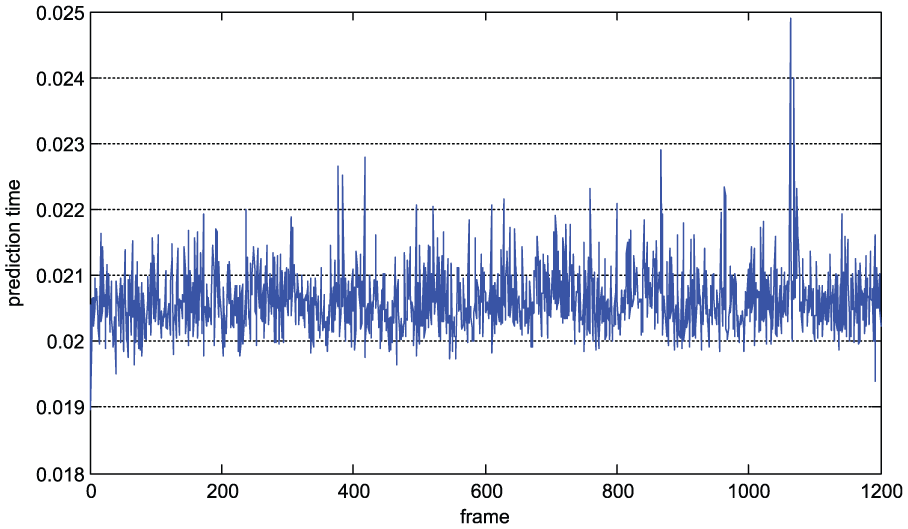
Prediction times of the SVR model.
Conclusion
Pedestrian count estimation plays an important role in public security, traffic control, and other aspects. This study presents a pedestrian count estimation method that considers the spatial distribution characteristics of local features. First, the ROIs of crowd images are extracted to enhance the efficiency of the algorithm. Then, an LBP-based descriptor is proposed as the local texture features. A joint descriptor with multiple local descriptor scales is used to reflect the comprehensive characteristics of the local features. MBLBP is generally used for a cell. Moreover, a global spatially distributed representation feature, namely, HMBLBP, is used to provide spatial organization in conjunction with multi-cell descriptors. PCA is used for dimensionality reduction. Subsequently, a fitting model is constructed via SVR. Finally, the UCSD pedestrian data set with crowded scenes is tested to evaluate the performance of the proposed pedestrian count method. Future works should focus on learning specific motion patterns of pedestrians and designing an adaptive traffic control for pedestrian crossing.
Footnotes
Academic Editor: Teen-Hang Meen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation of China (nos U1564214 and 51675224).