
Abstract
A variety of nonlinear control design methods have been proposed for controlling severe nonlinear processes over the past three decades. The vast majority of approaches take a nonlinear affine representation of the system dynamics. It appears that many system dynamics can also be represented by a state-dependent model structure. Control of state-dependent systems has been investigated resulting in design methodologies such as state-dependent Riccati equation approach, state-dependent parameter and proportional–integral–plus approach, and the nonlinear generalized minimum variance approach. This article describes yet another approach based on a receding horizon strategy. Important results on optimal control are obtained. Implementation issues are also discussed. The proposed approach is validated through its application to a 25-tray binary distillation column process.
Introduction
Nonlinear systems theory has developed rapidly over recent decades including concepts such as zero dynamics and normal forms, 1 passivity and dissipativity, 2 and nonequilibrium theory. 3 As a consequence, a number of nonlinear control design techniques have been well established, for example, feedback linearization, 1 recursive designs including backstepping and forwarding, 4 energy-based control design for nonholonomic dynamical systems, 5 and nonlinear model predictive control (NMPC), 6 to name just a few. A central theme in nonlinear control design is to take advantage of every potential of the system to improve control quality, for example, in the energy-based control design, the Lagrangian/Hamiltonian structure is utilized to generate Lyapunov functions to guarantee system stability; (exact) feedback linearization cancels the nonlinear dynamics in the closed loop and then takes advantage of the already well-established linear design methodologies. Recently, another linearization technique is proposed that utilizes a quasi-linear state-dependent model structure;7–9 the nonlinear system is represented by a linear state-space-like description but the system matrices (state, input, output, and feed-through matrices) are functions of states. At each sampling instant, the system matrices are constant and the nonlinear system becomes linear but is different from the Jacobian linearization. This state-dependent representation of nonlinear systems is very general that may even include chaotic processes and bilinear systems.10,11 More importantly, systematic identification methods have been developed by Young and colleagues12–14 in a series of papers.
Control design for state-dependent systems has attracted extensive research interests and several design methodologies have emerged: the state-dependent Riccati equation (SDRE) approach (see Banks et al. 15 and references therein), the state-dependent parameter and proportional–integral–plus (SDP-PIP) control,11,16 and the nonlinear generalized minimum variance (NGMV) control. 17 In the SDRE approach, it involves in a parameterization to transform the original nonlinear system to a linear structure with state-dependent coefficient matrices, and then a standard linear quadratic regulator (LQR) problem is solved based on the “frozen” Riccati equation. The SDRE approach has been successfully applied to space systems, 18 autopilot design, 19 and robotics, 20 see also the comprehensive article. 16 The SDP-PIP control is different from SDRE approach, in that it takes a special PIP control structure, which can be interpreted as an extension of conventional proportional–integral (PI)/proportional–integral–derivative (PID) methods. 21 The PIP controller parameters are then determined by either linear quadratic (LQ) cost function 21 or pole assignment. 22 However, it is noted that in the former case, the PIP control design also results in the solution of an algebraic Riccati equation closely related with the SDRE approach. The SDP/PIP control has also found a wide variety of applications, for example, to handle large disturbances in a microclimate test chamber or nonlinearities for a full-scale vibrolance system on a construction site (see Taylor et al. 21 and references therein). In the NGMV approach, however, the control law is obtained by the minimization of a generalized minimum variance (GMV)-type cost function. The formulation is based on an operator approach to nonlinear control and is a straightforward extension to the previous results. 23
In this note, the problem of controlling state-dependent systems is tackled using a receding horizon strategy. The presentation is structured as follows. In section “System representation and problem formulation,” the state-dependent system representation is described and the problem to be solved is formulated; the optimal control is then obtained for the receding horizon control strategy; and to enhance the system performance, the issue of integral action is also analyzed. It happens that the state-dependent structure possesses a flexible representation and this may have significant implication to implementation, and this issue is discussed in section “Exploring design flexibility.” Section “Design example” then provides a case study to validate the proposed design method. In section “Constraint Handling and Stability,” the problems of constraint handling and stability are briefly discussed, and finally, section “Conclusion” concludes the article.
System representation and problem formulation
State-dependent model
The nonlinear state-dependent dynamics will be represented by the following state-space model

where
To simplify the notation in the expressions for future prediction,

where the algebra of
Hence, the prediction of the output values

or
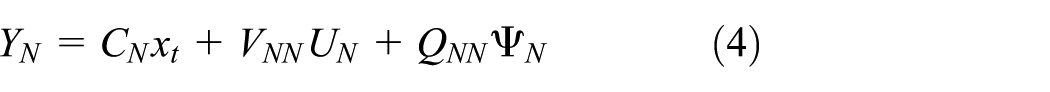
where



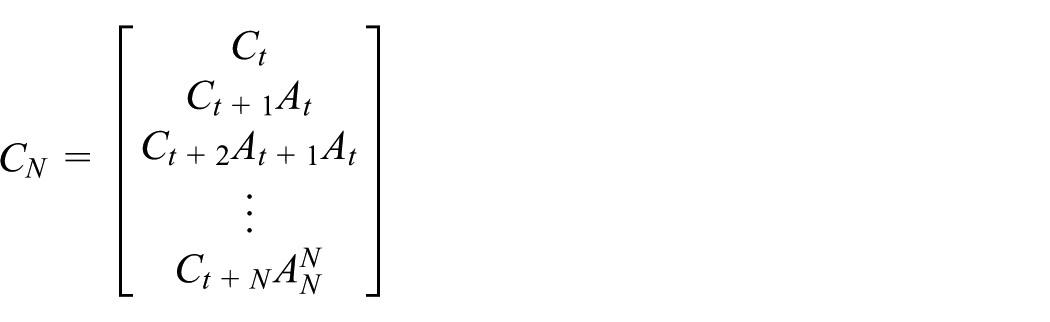


Reference model
The reference signal is assumed to be generated by the following linear time-invariant stochastic system

where

where the signal vectors are



and the matrix
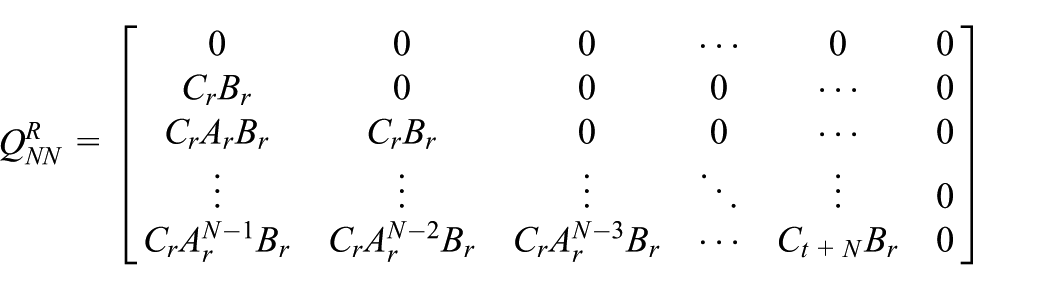
Problem formulation and solution
To formulate the problem, the performance index that is commonly used in the conventional generalized predictive control (GPC) will be minimized

where
Using the notations in equation (4), the performance index (7) can now be rewritten as

where
To minimize J, the procedure for optimizing the deterministic signals can be utilized, and this results in setting the gradient of the cost function (with respect to control vector

In order for the optimal control signal vector

These results can be summarized as follows.
Proposition 1: optimal receding horizon control law for state-dependent systems
For the state-dependent system model (1) and reference model (5), the optimal control signal vector
Initialization;
At time instant t, measure or estimate the current states
Load the control signal vector
From
Solve the optimal control law (10), which provides a new updated control signal vector
Apply the receding horizon principle, for example, only apply the first element
Proof
The first part of the proposition can be proved by collecting the results up to (10). Then, by assuming
Integral action
Integral action can cause detrimental effects on closed-loop system performance, leading to windup phenomenon. This has sparked extensive investigation to prevent the windup problems called Anti-Windup control. However, in many cases, integral action is often required for benefits, for example, eliminating the steady-state error. It is therefore necessary to develop a mechanism to include integral action into the state-dependent receding horizon control framework. The following simple result provides an answer.
Proposition 2: receding horizon control of state-dependent systems with integral action
The integral action can be included by augmenting the state-dependent model (1) as follows

where
Then, the application of the algorithm developed in Proposition 1 naturally results in the integral action.
Proof
It is seen that (11) is obtained by defining
It remains to see that it is very convenient to introduce integral action as it can be obtained by a simple augmentation of system dynamics.
Remark
This “augmentation” idea is very important, and in many situations, it can also be utilized to handle some constraints such as finite memory structure with respect to input and output (see Ahn et al. 24 )
Exploring design flexibility
In both SDRE and SDP/PIP approaches, the system matrices of the state-dependent model depend only on the state

Then, the state-dependent model (1) can be rewritten as
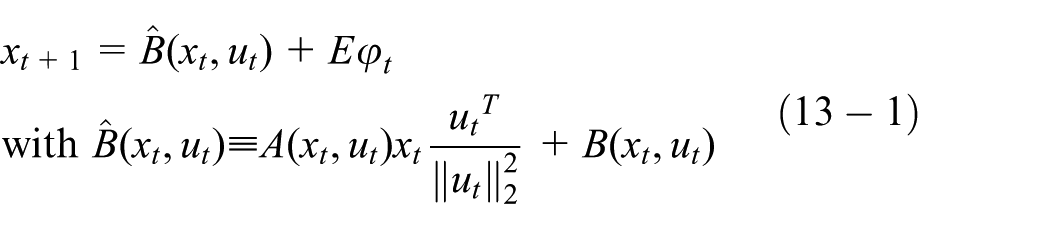
Or alternatively

This effectively simplifies the original model (1) to

and

respectively.
Hence, either the input matrix

And this is equivalent to the minimization of a GMV type performance index

Hence, the receding horizon control law now reverts to a GMV control law, revealing their close relationship in the minimization of a finite horizon quadratic performance index. This result is summarized as follows.
Proposition 3: equivalence to GMV control
For the state-dependent system (1) with either the input matrix
Proof
The result can be easily proved by following the results leading to (15).▪
This is an important result for a state-dependent system as its representation can often be expressed in an infinite number of ways. This design flexibility can be exploited to substantially reduce the computational complexity. The resulting control can be even more effective with a dynamic weighting by defining
Remark
The issue of nonuniqueness can play an important role in simplifying the computation, but it may also influence the controllability of the parameterized pair (
Design example
Consider a 25-tray binary distillation column process described by the following model 25
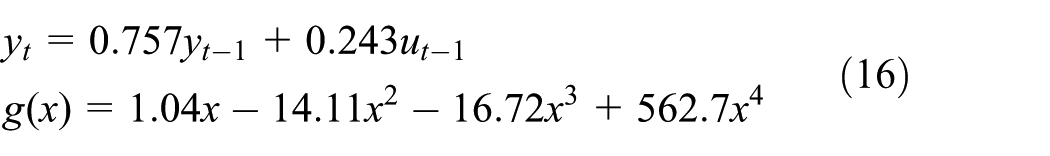
where y (%) is the top column composition and u (mol/min) is the reflux flow rate. Both of them are defined as deviations from their nominal values. 27
Define

It has been shown in Cheng and Chiu
28
that a PI controller with parameters
The objective now is to design a receding horizon controller to achieve good tracking response over the whole operating range

PI and receding horizon control performance: (a) output y and (b) control u.
The performance for varying prediction horizon N is shown in Figure 2. In this study, the control weighting parameters

Controller performance for varying prediction horizon N.
Now rewrite the state-dependent model (17) as follows

Define

with

This is simply a static-state feedback controller with a constant gain
Now choose a simple dynamic weighting

PI and generalized minimum variance control performance: (a) output y and (b) control u.
Constraint handling and stability
When calculating the current optimal control signal, it is seen from Proposition 1 that all the predicted control from previous iteration must be utilized. Hence, starting from a feasible solution, for example, satisfying the constraints, feasibility cannot be guaranteed at the next iteration. As a consequence, constraints will be handled implicitly via numerical experiments or simulation studies in the proposed framework. This is not a deficiency compared with the methods that explicitly incorporate constrains in the design phase, as it can reduce the computational complexity once a design satisfying the constraints is verified.
In fact, computational burden in NMPC also comes from trying to provide an a priori stability guarantee as in infinite-horizon NMPC, 29 quasi-infinite horizon NMPC, 30 contractive NMPC, 31 approximation NMPC, 32 sparse numerical approach NMPC, 33 and so on. Excellent reviews of existing stability-guaranteed NMPC techniques can be found in previous studies.6,34,35 These researches have substantially improved the understanding of stability issues in NMPC, but the resulting approaches can be difficult to implement in certain circumstances.31,33 Furthermore, the results are obtained for the regulation problem and do not readily be generated to the tracking problem, which is more frequently encountered in practice. In fact, no method exists for global tracking with guaranteed stability. This justifies the proposed framework where stability is checked through simulations.
Conclusion
Although lack of features such as constraints handling and stability guarantee (both are achieved through simulation), the method presented here does provide an easy-to-use methodology to deal with a very general class of nonlinear systems. Within the state-dependent system literature, the approach presented here represents a new and powerful design methodology, different from the usual LQ and pole-assignment framework.
Footnotes
Academic Editor: Hamid Reza Shaker
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors are grateful for the financial support of the Natural Science Foundation of Jiangsu Province (no. BK20140829) and the Fundamental Research Funds for the Central Universities (no. NS2016024).