
Abstract
Autonomous manipulation has enabled a wide range of exciting robot tasks. However, perceiving outside environment is still a challenging problem in the field of intelligent robotic research due to the lack of object models, unstructured environments, and time-consuming computation. In this article, we present a novel robot grasp detection system that maps a pair of RGB-D images of novel objects to best grasping pose of a robotic gripper. First, we segment the graspable objects from the unstructured scene using the geometrical features of both the object and the robotic gripper. Then, a deep convolutional neural network is applied on these graspable objects, which aims to find the best graspable area for each object. In order to improve the efficiency in the detection system, we introduce a structured penalty term to optimize the connections between multimodality, which significantly mitigates complexity of the network and outperforms fully connected multimodal processing. We also present a two-stage closed-loop grasping candidate estimator to accelerate the searching efficiency of grasping-candidate generation. Moreover, the combination of a two-stage estimator with the grasping detection network naturally improves detection accuracy. Experiments have been conducted to validate the proposed methods. The results show that our method outperforms the state of the art and runs at real-time speed.
Keywords
Introduction
Robotic grasping is a core feature for intelligent robot to accomplish many kinds of autonomous manipulation tasks. 1 Meanwhile, the visual perception capability of robotic grasping tasks is still a challenging problem despite the great progress in the area of mechanical design of dexterous robotic hands. 2
The most intuitive approach to perceive the graspable part of an object is to convert the perception problem into a model-matching task. This requires a three-dimensional (3D) model of the grasping object in advance, which can be difficult to construct and time-consuming. In the computer vision community, numerous methods have been utilized which use hand-design visual features to solve this problem. However, quality visual features are very difficult to design, especially in an unstructured environment. Some recent researches have attempted to use deep learning methods to predict the graspable area of an object. The obvious advantage of these methods is that features are learned automatically. This avoids the time-consuming effort associated with feature designing.
In this article, we present a complete robot grasp detection system that maps a pair of RGB-D images, containing a set of novel objects, to best spatial grasping pose of a robotic gripper. Considering computational requirements and similarities between color image and depth image, we have designed a deep convolutional neural network (DCNN) model to perceive the best graspable area of an object. The relative grasping pose of the robotic gripper is estimated based on this best graspable area. In contrast with separated feature learning 3 and fully connected feature learning, 4 a multimodal information fusion method is utilized to improve the efficiency of the multimodal information processing. By introducing a structured penalty term to optimize the connections between multimodalities, which significantly mitigates complexity of the network and outperforms fully connected multimodal processing, we improve the efficiency of the detection system dramatically. An example scene used in our robot grasp detection system is shown in Figure 1.

Robot grasp detection scene is a cluttered lab table with several objects lying on. Left: raw three-channel color image. Right: aligned one-channel depth image.
Unlike traditional recognition problem in computer vision area, robot grasp detection used for robot manipulation has strict requirements on computational speed and accuracy. Inspired by reinforcement learning, we used a three-step detection system to simultaneously improve the grasping detection accuracy and computational efficiency. In order to accomplish tasks such as cleaning a table and arranging objects in an unstructured environment, we segmented objects and discriminated graspable objects in the first step. Then, a two-stage graspable candidate estimator was utilized to roughly estimate a set of initial grasp candidates from these objects. And, these estimates were used to initialize the grasp detection framework. Finally, we generated graspable probabilities of these candidates which were fed back to the estimator. In this way, the searching intensity around the qualified grasping candidates is enhanced which improves the efficiency of the graspable candidate estimator.
Considering the complexity of our DCNN, the scale of the grasping dataset used for training is very essential to generalize our model. However, an adequate human-labeled RGB-D grasping dataset can require a vast number of man-hours due to the variant ways to grasp even a single object. To mitigate this problem, we trained our model on a mixed dataset: Cornell Grasp Detection Dataset 5 and Washington RGB-D Object Dataset. 6 In contrast to the 25,000 unlabeled grasp images in Washington dataset, the Cornell dataset contains only 885 ground-truth-labeled grasp images. The considerably mixed dataset is utilized to perform unsupervised pretraining which is crucial to generate useful, generalizable multimodal features for successive grasping detection.
In summary, the contributions of this article lie in the following aspects: (1) we introduce a complete robot grasp detection system that maps a pair of RGB-D images of novel objects in unstructured scene to best grasping pose of a robotic gripper; (2) we propose a new multimodal DCNN model to find the best graspable area in an object, which fuses multimodal information and outperforms the state of the art both in accuracy and computation; (3) a hierarchical training method is presented to train our model on mixed dataset which magnifies generalization capability; and (4) we present a two-stage closed-loop grasping candidate estimator to accelerate searching efficiency of grasping candidate generation. Our experiments indicate that our method outperforms the state-of-the-art grasping detection both on the grasping dataset and ground-truth objects.
The remainder of this article is organized as follows. In the following section, we will discuss some related work. The overview of our system is presented in section “System overview.” Next, we describe the method to segment and discriminate the expected objects in unstructured scene in section “Discriminate graspable segments.” The details of our grasping detection model are discussed in section “Grasping detection description,” and the reprojected 3D pose method for gripper is presented in section “Reprojected 3D pose of robotic gripper.” We describe the experiment and result in section “Experiments” and then give the conclusion in section “Conclusion.”
Related work
Robotic grasping is a major research branch in the field of intelligent robotics. Grasp synthesis mainly contains two kinds of methodologies: analytic- and learning-based approaches. 1 Analytic-based approaches usually utilize simplified contact model assumptions to achieve partial or complete form-closure or force-closure of an object. And, learning-based approaches use visual representation, semantic perceptual, and pose estimation to infer how to grasp objects. In this article, we mainly focus on the latter approach which has shown its advantages in numerous robotic grasping tasks.
In many robotic grasping tasks, the model of the manipulated object is assumed to be known beforehand, including visual information or entire 3D model. Therefore, the grasping detection problem can be converted to a matching problem of finding the best matching part between the object and the model. Papers by Hubner and Kragic 7 and Przybylski et al. 8 applied a box-based shape approximation approach which utilized the box and spheres shape information to estimate the graspable object. Meanwhile, a rapidly exploring random tree method was presented to infer the best grasping area. However, a major issue is that the algorithms are only tested on simulated images, ignoring complicated real-world objects. Recent methods9,10 find that the generic grasping measurement method in simulation is not a precise description for successful real-world object grasping. More importantly, generalization capabilities of these full model-based methods are a major concern because of the numerous unpredictable model objects in our daily life.
Some researchers have used visible-light features to address detection problems. Using color, texture, shape, and local two-dimensional (2D) appearance features, Felzenszwalb et al. 11 proposed a deformable part model to detect objects. Saxena et al. 12 proposed a system that applied logistic regression to infer grasping point in an object using raw 2D images. However, they encountered difficulties in perceiving the shapes because of variations in illumination.
With the spread of consumer 3D devices (such as Microsoft Kinect) which obtain depth maps of objects easily, a wide variety of techniques for object detection and recognition have been developing very fast. Compared to a visible-light visual feature descriptor, the combined RGB-D descriptor provides complementary cues about target object even under varying lighting conditions. Many researches have shown the advantage of using this hybrid information. Using RGB-D information, Li et al. 13 and Rao et al. 14 segmented objects and estimated 3D pose of an object excellently. Bo et al. 15 presented a hierarchical matching pursuit method which fused color, texture, geometry, and 3D shape features. The object classification results demonstrated the state of art performance on their dataset. However, these works need to hand-design visual features and hand-code grasping rules, which are difficult to apply in massive objects like our real world.
In recent years, deep learning approaches have shown the advantages in learning useful features from data automatically. A large amount of tasks have achieved great success in the field of image classification, semantic scene understanding, and object detection.16–18 Lenz et al. 5 proposed a four-layer deep learning architecture to detect grasping area based on RGB-D information. Finn et al. 19 used convolutional neural network (CNN) to estimate visual feature points in a distinct object. These visual feature points were utilized to construct a guided search policy for robotic manipulation. Redmon and Angelova 20 used CNN for real-time detection of the grasping area of an object. However, the amount of required training data is substantially less than the number of model parameters, which means it may fail to generalize to new unseen objects.
Some works tried to use reinforcement learning method to detect robotic grasping area.21,22 In order to overcome a large amount of uncertainty inherent to the grasping detection task, Kroemer et al. 23 combined reinforcement learning methods with a reactive grasping control law. Levine et al. 24 tried to combine reinforcement learning methods with CNN to perform special manipulation tasks. In Levine et al., 24 CNN was utilized to estimate the pose of target object and reinforcement learning was used to instruct a manipulator to approach the object. While classification algorithms in computer vision can be trained with comparatively modest data sets, the labeled data necessary to learn a grasping model is very large and not easily generated. The generalization capability of these methods is a major bottleneck due to the incompatible scale between model parameters and training data.
System overview
In the field of robotic manipulation, to clear a table of randomly placed item is still a difficult task. The crucial part is how to perceive best graspable area of an object efficiently and accurately. In this article, we present a novel robot grasp detection system that maps a pair of RGB-D images of novel objects in unstructured scene to best grasping pose of a robotic gripper. Our system contains three parts: graspable object segmentation, grasping area detection, and 3D pose estimation. The robot grasp detection pipeline is showed in Figure 2.

Robot grasp detection pipeline for ground-truth object. First, we segment graspable object. Then, some areas of the object are regarded as graspable candidates. Using DCNN model learned from mixed training data, we optimized best grasping area of the object.
In an unstructured environment, a robotic grasping detection algorithm may infer potential grasp areas which are geometrically incompatible with the robotic gripper. Attempts to retrieve an item from these grasp points will fail, and in some cases may damage the gripper. Therefore, we segment the graspable objects from a cluttered scene at the beginning. Using geometric features, we eliminate the ungraspable objects in subsequent procedures.
The multimodalities provide many kinds of information about objects which are useful for robot grasp detection and it is crucial for meeting the requirement of computational speed. In this article, we design a novel deep learning model that adds a structured penalty term into optimization function to learn connections among different modalities. We also present a two-stage closed-loop grasping candidate estimator to accelerate searching efficiency of grasping candidate generation.
In order to accomplish a real-world robotic grasping, the surface normal information of these rectangular areas are utilized to estimate the main orientation of the best grasping area. Then, the relative pose between the best graspable area and the robotic gripper is estimated.
Discriminate graspable segments
Data preprocessing
In our system, we use three kinds of modal information as input data. These are color, depth, and surface normal of the image. Due to the limitations of infrared structured-light depth reconstruction, shaded or glistening surfaces can fail to yield data points. Since these missing depth data are prone to be grouped, the generic retrieving methods which estimate missing data from neighboring points cannot adequately interpolate the real values for these points. The unreal retrieved data will decrease the accuracy of the grasping detection. To fully leverage the power of multimodalities, we simply fill the missing depth data with zero, rather than retrieve the missing points.
The statistics of the three kinds of input features vary widely, especially in the depth and surface normal channels. Therefore, it is inappropriate to use a generic whitening method for the multimodal input data. In order to avoid learning features from just one single modality, we use a variant whitening method to regularize the multimodal information.
We subtract mean values of each channel individually as generic whitening method. We rescale depth and normal data by dividing deviation of these three channels. In this way, the statistics of the three kinds of input features are adjusted to compatible level

where
Segmentation and discrimination
Image segmentation is still a key research area in the computer vision community. Given a pair of RGB-D images, it is essential to segment graspable objects in an unstructured scene for successive graspable detection. Therefore, in this section, we demonstrate how to segment interested objects and discriminate graspable objects.
In an unstructured environment, there are many objects in the field of view. In order to determine the objects of interest within the image, we first use a random sample consensus (RANSAC) plane fitting method 25 to find the plane of table using depth information. After obtaining a set of points belonging to the table plane, we are able to separate objects from this plane by choosing the points that lie above it. The grouped points which lie above the plane are regarded as segmented objects. However, some small objects may be lost due to the noise of depth sensor and RANSAC plane fitting. We use an extended graph-based segmentation algorithm designed by Rao et al. 14 to find small objects like flash drive

where
Once we segment all the objects, we are able to discriminate the graspable objects from the segmented objects. According to human grasping experience, 26 grasping capability depends on the size of hands and shape of objects. Therefore, we use geometric features such as length, width, and height of the segmentations to infer graspable segmented objects. The length and width of a segmented object are roughly obtained from depth information. The average height of a segmentation area is viewed as height of the object, which is the difference between the plane of the table and segmented area. We segmented objects with rectangular bounding boxes. Figure 3 shows the segmentation and discrimination results of two examples cases.

Example cases of segmentation and discrimination. Left column: RGB images before segmentation. Right column: RGB images after segmentation. The green rectangles show the discriminated graspable objects, and the red rectangle shows the discriminated ungraspable object.
Grasping detection description
Problem description
Given a pair of RGB-D images of a novel graspable object, we need to determine which part or area of the object is the best place to grasp. Inspired by Lenz et al. 5 and Huang et al., 26 we used a four-dimensional representation to define the grasping rectangle configuration in an image. The representation gives center location (x, y), opening length (h), and orientation angle (α) of the grasping rectangle. The width of the opening size is determined in advance by the configuration of robotic gripper.
We can address the final approaching pose of robotic gripper in real world using multimodal information in the rectangle. The details of reprojection are discussed in section “Reprojected 3D pose of robotic gripper.”
Formulation
We formulated grasping detection problem as a structured prediction problem using a DCNN model. The architecture of our model is shown in Figure 4. Our network has three convolutional layers, followed by two fully connected layers, and a logistic classification output layer. Rectified linear function is used as activation function and max-pooling is used for pooling layers.

Architecture of our deep convolutional neural network model. Pooling layers are not shown for brevity. The part within dotted line shows the multimodal information fusion structure in the first and second layers.
A set of raw data in rectangle area, including nine-dimensional channels: color, depth, and surface normal information, is used as the input of our network. The input image patch is set as 96 × 96 which gives 9 × 96 × 96 = 82,944 raw input features. The first three channels are R, G, B color information, followed by X d , Y d , and Zd depth information. The last three channels are the surface normal information, X n , Y n , and Zn, which are computed from depth channel.
Multimodal information fusion
As for multimodal information processing, many works just ignore the relationship among multimodalities and learn the different features of each channel separately. This method is reasonable when the gap between input modalities is huge, because it is very difficult to learn the connected features in these modalities,27,28 such as the relationships among visual, language, and speech modalities. However, it cannot learn statistical connections among the modalities whose properties are similar to each other.
In order to obtain the related features between different modalities, some works attempt to simply consider multimodal information as the same information. However, fully connected model generates a large amount of parameters which can lead to a heavy computational load and increased risk of model overfitting. Considering the requirements of our system, we cannot simply connect all the modalities.
We propose a new method to handle this dilemma by optimizing the connections between different modalities. The original relationship between different modalities is analyzed, and a structured penalty term is introduced to mitigate the complexity of the first layer.
There are nine channel features (three different modalities: color, depth, and surface normal) in our network. The color and depth information are similar and highly related because they share same dimension and represent image features of object, which are quite different to normal information computed from depth information. Therefore, in the first convolution layer, we learn the related features between color and depth modalities by adding a set of shared weight filters. These shared weight filters are used both on the color and depth modalities. Meanwhile, we learn the surface normal feature individually. The part within the dotted line of Figure 4 shows our multimodal information fusion structure in the first and second layers.
We also introduce a structured penalty term to mitigate model complexity. To address the phenomena that generic regularization methods used for deep neural networks cannot control the connection number of the network, such as L1 regularization and L2 regularization, Lenz et al. 5 regularized their model by restricting the number of parameters. However, the magnitude of nonzero weights was uncontrolled. We integrate max-norm penalty and L2-term penalty to restrict the scale of parameters and mitigate the risk of overfitting. The regularization terms can be expressed as follows

where
The structured penalty term is added to the optimization function which is solved during optimized learning. Our method can enhance the highly correlated features between color and depth modalities with minimized sets of filters and discourage the weak correlations. This method is utilized when we pretrain the parameters of multimodalities in the first layer.
Model and pretraining
Given a set of rectangle candidate represented by
We use rectified linear unit
29
As for the convolutional layers, we calculate feature maps of each layer as follows

where
As for the fully connected layers, the units can be calculated as follows

where
Output of the network indicates graspable probability of the input grasping rectangle. Therefore, in the inference procedure, we maximized the output probability y at the top of our network to find the best grasping rectangle for robotic gripper
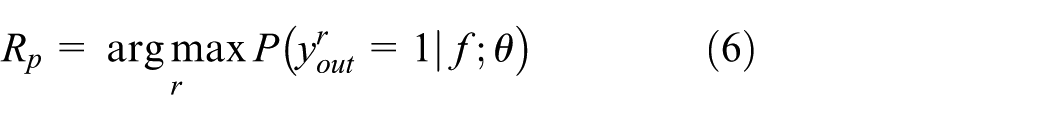
where r is the input rectangle,
Pretraining has shown its great power to avoid gradient vanishing and initialize network in massive deep learning tasks.30,31 In our DCNN, we use unsupervised stack sparse auto-encoder (SSAE) to pretrain the parameters of each layer. The greedy layer-wise pretraining procedure is applied to train each layer in turn, which means the outputs of each three-layer network are wired to the inputs of successive layer initialization (Figure 5).

A three-layer auto-encoder structure. The input of the each three-layer auto-encoder structure is the output of the former structure. The input of the first three-layer structure is the input data of our model.
In Figure 5, X is the input, h is the hidden unit,
Two-stage closed-loop grasping candidate estimator
Our proposed network needs a rectangular patch image as the input to infer whether this area is graspable. Therefore, it is essential to collect reasonable candidate rectangles from objects. The generic sliding window detection framework is inefficient to generate useful candidate grasping rectangles because numerous small patches need to be delivered to the network for graspable testing. In order to improve the efficiency of candidate generation, we propose a two-stage closed-loop grasping candidate estimator to generate grasping candidate efficiently.
Inspired by reinforcement learning methods and data aggregation techniques, our estimator reuses the result of the former grasping detection. We infer a set of initial grasping candidates based on the spatial features and prior information. 26 Then, our network is utilized to estimate the graspable probabilities of these candidates. We pay more attention on the candidate areas whose corresponding graspable probabilities are highly ranked. The feedback of grasping detection improves the searching efficiency of the candidates dramatically. The framework of two-stage closed-loop grasping candidate estimator is showed in Algorithm. 1.

Reprojected 3D pose of robotic gripper
Using proposed grasping detection method, the best graspable rectangle of the objects can be found. In order to obtain the spatial pose of robotic gripper, we use the depth information in best grasping area to reproject 3D pose of robotic gripper.
The grasping rectangle area usually consists of two parts: candidate grasping part in object and plane table background. The normal of plane table is fixed and reversed to the direction of gravity. Therefore, we treat plane table points in the area as noise and just use the points in graspable object. Then, one-third of the central points of the remaining rectangle are used to estimate the surface normal information of this area. Once we obtain the surface normal, the opposite vector is taken as the approaching direction of the robotic gripper. Then, the 3D spatial orientation angle of the robotic gripper can be transferred from the approach vector. And the 3D grasping position can be obtained from the subarea directly.
Experiments
Data
In grasping detection experiment, the biggest problem is the lack of labeled training data which is critical to train a complicated neural network. In contrast to the importance of the labeled training data, it is a quite difficult and dull job to label a large amount of reasonable grasping rectangles in images. Therefore, we use a mixed dataset to train our model: the labeled Cornell Grasp Detection Dataset and the unlabeled Washington RGB-D Object Dataset.
The Washington RGB-D Object Dataset is a huge RGB-D image dataset which contains 25,000 object images with only category labels. The Cornell Grasping Detection Dataset consists of 885 labeled ground-truth grasp images in which each image marks 1–4 reasonable grasping rectangles and 1–4 ungraspable grasping rectangles. In order to enlarge the labeled Cornell grasping dataset, we performed a rotation transformation to generate new labeled grasping data. The Cornell images were rotated by
We use the unlabeled Washington dataset to pretrain the network in the beginning, which learns the color, depth, and surface normal features. Then, a part of the labeled enlarged grasping data is utilized to pretrain the network for the second time. The aim of second pretraining is to learn more useful features of the graspable and ungraspable areas and the first pretraining learned parameters are used as the initial parameters in second time pretraining. Finally, we use the rest of the grasping data to fine-tune our grasping detection network which is essential for the generalization capability of the model.
Training
To make candidate rectangles compatible with the input requirement of our network, we rotated the rectangle candidates to make their vertical edges correspond to the grasping orientation and rescaled rectangle candidate images to fit input requirement of our network.
To evaluate the correctness of our predicted best grasping rectangle, we made a comparison between the predicted best grasping rectangle and labeled input ground-truth grasping rectangle. We considered a predicted rectangle as a correct grasp when it fits two metrics. First, the overlapping area between the predicted rectangle and the ground-truth grasp rectangle should overtake 30% of the ground-truth area. Second, the difference in the orientation between these two rectangles is within 30°. We evaluate the correctness of the prediction using these metrics.
It is worth noting that our grasping detection system is trained and tested on a PC with i7-975 CPU 3.3 GHZ and GeForce GTX 980 graphics card. Actually, our network is computed on the graphics processing unit (GPU) which has shown its powerful computation capability in a large amount of vision tasks. And, the Microsoft Kinect sensor is used to capture the raw RGB-D images in the real-world test.
Results and discussions
In order to validate our model, we compared our algorithm against several other approaches. We evaluated our model on both the Cornell dataset and a set of real-world novel objects. In our experimental setting, we suppose a two-finger parallel gripper as the end-effector to perform robotic grasping.
Given a pair of RGB-D images which had segmented the graspable objects, we compare our algorithm to other approaches. The graspable detection comparison results of the algorithms evaluated on the Cornell grasping dataset and the ground-truth objects are given in Table 1. Our model achieves approximately 82% accuracy on enlarged Cornell grasping test dataset containing 1062 pairs of images (10% of the whole enlarged dataset) and 69% accuracy on 20 ground-truth novel objects with 1200 (20 × 5 × 12) pairs of enlarged images.
Grasping detection results of various learning algorithms.

The bold values show the best results among the algorithms.
The chance performance in this scenario means randomly selecting a rectangle and check the rectangle is graspable or not. Because of randomly selecting a rectangle, the accuracy of the chance performance is almost zero in real world and detection speed is meaningless. Our grasping detection algorithm outperforms the current state of the art. Compared with hand-engineered feature method from Jiang et al., 32 the accuracy improved by up to 18% in dataset and 24.8% in real-world examples. Compared to fully connected deep learning method from Lenz et al., 5 the accuracy improved up to 10.6% in dataset and 16.3% in real-world examples. Compared to CNN-based method from Redmon et al., 20 we found that our detection accuracy in real-world examples is much higher than Redmon et al., 20 despite the matchable accuracy in the dataset. Furthermore, as the accuracy in the dataset is much higher than the real-world example, we have no reason to doubt the overfitting problem studied in Redmon et al. 20
The model without adding a structured penalty shows weak detection performance indicating that without the structured penalty, the model is too complex to reach a reasonable local minimax. A model trained on the Cornell dataset also shows an overfitting problem like the one in Redmon et al. 20
However, our algorithm runs at real time which is essential in robotic manipulation task. We tested the computation speed of our algorithm on the Cornell dataset which contains one single object for each image. Our aim was to determine that how long it will take to find the best graspable area of the object. Table 2 shows a computation speed comparison between different algorithms. At test time, our model runs in 7.1 fps with one given graspable object faster than Lenz et al. 5 and Redmon et al. 20 The hand-engineered feature method from Jiang et al. 32 cannot be tested in real-world scenarios because of lacking object detection. The main contributors to this speed increase are the transition from a scanning window classifier–based approach to our two-stage closed-loop grasping candidate estimator, our multimodal information fusion method, and our usage of GPU hardware to accelerate computation.
Computation speed comparison between different algorithms.

The bold values show the best results among the algorithms.
We also made a comparison to show the influence of our two-stage closed-loop grasping candidate estimator method on the Cornell dataset. Table 3 shows the results when the estimator is used or not. When the two-stage estimator is utilized in our model, the improvement is obvious in terms of computational efficiency which boosts around eight times than the generic sliding window searching method. In addition, the accuracy is also increased by 1.3% due to the enlarged candidate numbers around the interested areas.
The influence of the two-stage closed-loop grasping candidate estimator on computation.

Examples of object grasping detection on the Cornell dataset are shown in Figure 6. The bottom row in Figure 6 shows that our model does not treat the small area in the objects as the best graspable part. For instance, the handle of the cup or finger hole in the scissors are not selected. The reason is that the graspable area must be compatible with the scale of the robotic gripper. Therefore, some parts that are graspable for humans may not be suitable for a robotic gripper.

Examples of object grasping detection on Cornell dataset. The green and red edges correspond to the length and width of the robotic gripper plates, respectively.
Our model can also be generalized to new unseen objects, and one notable advantage is the capability to perform multi-object grasping detection in an unstructured environment. The multi-grasping detection capability of new unseen objects is shown in Figure 7. We placed seven novel objects on a plane wooden table: a notebook, a telecontroller, a flash disk, a glass box, a blower, a cylindrical container, and a red hat. The notebook is the only one which is ungraspable for robotic gripper. Figure 7 shows that our system detected the graspable objects and corresponding grasping areas. By contrast, the ungraspable book was ignored because of the incompatible sizes and height.

Multi-object grasping detection. The green and red edges correspond to the length and width of the robotic gripper plates, respectively. The notebook is ignored by our detection system because of incompatible sizes and height.
Our algorithm focuses on the problem of grasp detection using auto-learned features. Our detection system has not performed experiments with a real robotic gripper yet because of the hardware restrictions. However, as our robot grasp detection system is complete including object segmentation, object recognition, and best graspable area detection, the integration of grasping detection system and robotic arm control system will be accomplished in future work. However, our algorithm can be easily extended to other type of grippers, such as dexterous HIT/DLR five-finger hand, 33 which requires large amounts of training data labeled with grasping position of each finger.
Please contact the corresponding author if you want to download the source code and experimental data of our work.
Conclusion
In this work, we presented a novel robot grasp detection system that mapped a pair of RGB-D images of novel objects to best grasping pose of a robotic gripper. In this system, we linked graspable object segmentation, grasping area detection, and spatial pose estimation together to achieve a complete, fast, and accurate pipeline for the autonomous robot grasp detection task. Our experiments and results, both on dataset and unseen novel objects, showed the robustness of our detection system and the significant improvements in terms of both accuracy and speed.
We also proposed a novel multimodal information fusion method to handle multimodalities of color, depth, and surface normal, which significantly mitigated the complexity of the network, reducing the risk of overfitting. A two-stage closed-loop grasping candidate estimator was presented to accelerate the searching efficiency of grasping candidate generation. The superior results showed that our multimodal information fusion method and staged candidate searching policy were essential to the real-time robot grasp detection task.
Footnotes
Acknowledgements
The authors would like to thank Professor Zhaodan Kong for useful discussions and Gregory Bales for revising the expression of the whole article.
Academic Editor: Nasim Ullah
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the State Key Development Program of Basic Research of China (973 program; no. 2013CB733105).