
Abstract
Long-term traffic forecasting has become a basic and critical work in the research on road traffic congestion. It plays an important role in alleviating road traffic congestion and improving traffic management quality. According to the problem that long-term traffic forecasting is short of systematic and effective methods, a long-term traffic situation forecasting model is proposed in this article based on functional nonparametric regression. In the functional nonparametric regression framework, autocorrelation analysis (ACF) is introduced to analyze the autocorrelation coefficient of traffic flow for selecting the state vector, and the functional principal component analysis is also used as distance function for computing proximities between different traffic flow time series. The experiments based on the traffic flow data in Beijing expressway prove that the functional nonparametric regression model outperforms forecast methods in accuracy and effectiveness.
Keywords
Introduction
With the rapid urban development and gradually increase in the number of vehicles, traffic congestion has been heavily fixed eyes on. Numerous methods are used to alleviate the problem of congestion. Nowadays, advanced traffic management system (ATMS), advanced traffic information system (ATIS), dynamic route guidance system (DRGS), and other intelligent transportation systems are being applied more widely. Accurate and reliable traffic forecasting, as the basic requirement and key technology of these systems, has also attracted more and more attention. Research on traffic flow forecasting has important theoretical significance and application value.
Traffic forecasting is to speculate the traffic state in the future by analyzing traffic flow data. According to the forecast period, it can be divided into short-term forecasting and long-term forecasting.1,2 The former refers to the forecast period is short, usually less than 30 min, while the latter means that the forecast period is longer, such as a day, a week, or even longer.
In the early time, forecast methods mainly included time series models, exponential smoothing model, Kalman filter model, and so on.3,4 With the deepening of the work, some new methods were applied to traffic forecasting, such as nonparametric regression, neural network, support vector machine, wavelet analysis, and others.5–12
Vlahogianni et al. 13 briefly discussed the existing research since the early 1980s and then offered information on 10 areas where they believed that the technological and analytical challenges lie for the next generation of short-term forecasting research. Haworth and Cheng 14 employed a nonparametric spatio-temporal kernel regression model to forecast the future values of road links in central London. The model used spatial neighborhood information under the assumption of data that is missing not at random due to sensor failure. Dong et al. 15 divided traffic state into six modes according to the level of service. On the basis of Autoregressive Integrated Moving Average model (ARIMA), the time-delay error in the ARIMA was adjusted dynamically using a dynamic correction function. The analysis showed that the multimode traffic volume prediction model provides a better performance than ARIMA model. Sun et al. 16 provided a multimode maximum entropy model (MME) to deal with regional traffic state. In the research, the different state behaviors were divided into 14 traffic modes defined by average speed according to the date-time division. The experiments proved that the MME models outperform the already existing model in both effectiveness and robustness. Classifying traffic condition states as congestion and non-congestion, Dong et al. 17 proposed multivariate state space models for network flow rate and time mean speed predictions. The study suggested the Non-congestion State Space model (NSS) is better for flow rate prediction under non-congestion conditions, and the Congestion State Space model (CSS) is better for time mean speed prediction under congestion conditions. Min and Wynter 18 provided an extended time-series–based approach of speed and volume predictions over 5-min intervals for up to 1 h in advance. Tchrakian et al. 19 formulated and demonstrated the use of a technique based on spectral analysis for within-day real-time traffic flow forecasting, and the choice of step, historical data, and forecasting horizon were discussed with numerical results. Many prediction methods lead to inefficient predictions when current or future time series data exhibit fluctuations or abruptly change. In order to deal with this problem, Chang et al. 20 introduced a dynamic multi-interval traffic volume prediction model based on the k-nearest neighbor nonparametric regression (KNNNPR). Qiao et al. 21 used traffic and weather data from multiple data sources to develop an integrated model that could predict travel times under various weather conditions, especially severe weather conditions. Considering traffic flow data reveals seasonal trend. Hong 22 presented a traffic flow forecasting model that combines the seasonal support vector regression model with chaotic immune algorithm (SSVRCIA), to forecast inter-urban traffic flow. Chrobok et al. 23 organized the historical traffic data into four basic classes and a matching process that assigns these sets into their class automatically is proposed and then proposed two models for short-term forecast: the constant and the linear model. The results show that the constant model provides a good prediction for short horizons whereas the heuristics is better for longer times. In general, throughout the literatures mentioned above, it is true that many researchers have paid attention to traffic forecasting, and many fine prediction methodologies have been reported. Most of the references are limited to focus on short-term traffic forecasting (over 5-min intervals for up to 1 h in advance), especially focus on improving the forecasting accuracy and developing methodologies that can be used to model traffic characteristics such as volume, density, and speed, or travel times, but a little focus on long-term forecasting and lack in the study of the long-term trend of traffic flow. Furthermore, it is turned out that the prediction methodologies work very well for short-term traffic forecasting, in particular accuracy, effectiveness, and stability; however, it is be worth further discussing whether they are suitable for long-term forecasting. Finally, accurate long-term traffic forecasting plays a positive role in improving the quality of traffic management and service. It can provide useful reference not only for increasing efficiency of the limited traffic management resource, such as making reasonable arrangements for police resource upon the long-term forecasting results, but also for helping travelers make plans for a long term in advance to avoid congestion. Hence, long-term traffic forecasting can be considered as the key to achieve traffic management from passive adaptation to active response.
For these reasons, and with the goal of enabling a method to predict the traffic situation in a long term, this work proposes a functional nonparametric regression (FNR) model to predict urban expressway traffic situation over a long term in advance. In the FNR framework, the nonparametric kernel regression is applied to forecast Beijing freeway traffic flow, in which the state vector is selected by analyzing the autocorrelation coefficient of traffic flow. In addition, the application of functional principal component analysis (PCA) to deal with seasonal trend of traffic flow have been used as distance function for computing proximities between different traffic flow time series. The article is structured as follows: the importance of long-term traffic forecasting is emphasized in section “Introduction.” In section “Model,” a mathematical description and the modeling process of the FNR model is given. In section “Case study,” the model has been tested in practice on a Beijing expressway section and the results are analyzed in detail. Finally, we make some conclusions with discussions on future directions in section “Conclusion.”
Model
Functional data analysis (FDA) is a branch of statistics that analyzes data providing information about curves, surfaces, or any other mathematical object. Models and methods for FDA may resemble those for conventional multivariate data, including linear and nonlinear regression models, PCA, and many others.
In order to analyze data with complex structures, the FNR model combines nonparametric regression and FDA, and in such a way that the prediction problem of time series turns to be a standard regression problem.
Traffic is a continuous time stochastic process, time series of traffic flow will be considered as discrete time realizations of a continuous time stochastic process. Since people travel with regularity, traffic flow is a seasonal process. The traffic flow curve of each period can be denoted as equation (1)
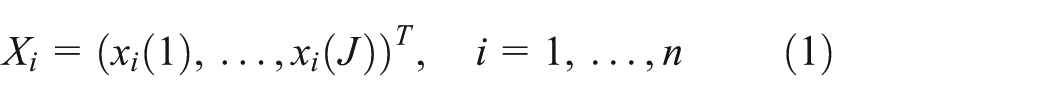
where

Equation (2) states that the probability distribution of a future value of the process given only depends on the time series of the last period. That is, the estimation of
According to the basic idea for forecasting above, this article uses historical data for forecasting traffic flow in the future based on nonparametric regression method; generally, it can be expressed as follows

where
Nonparametric regression method is to use the given X in the observation
In the FNR model, the estimation of

where Y is one-dimensional observation vector and X is m-dimensional independent variable. A N-W type estimator is defined by equation (5)

where K is the kernel function, d is the distance function, and h is the bandwidth.
On the basis of equation (2), assuming that observation

Equation (6) states that the value of the time series
Therefore, based on nonparametric regression and N-W type estimator, the long-term traffic forecasting model can be expressed by
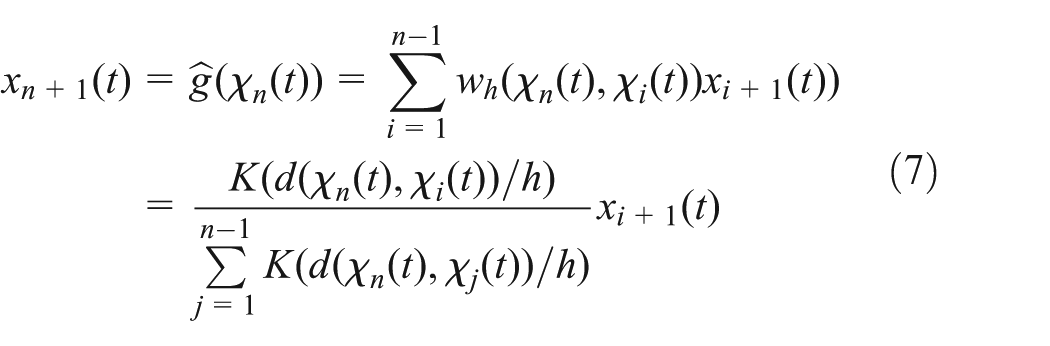
where
To forecast the traffic flow data, many principal factors, such as the state vector, distance function, kernel function, in the FNR model are important. Finally, the framework and process of the FNR model is represented in Figure 1:
Choose the state vector χ using autocorrelation analysis;
Compute distance function d by the functional PCA;
Select the kernel function K;
Feed into equation (7) to obtain the forecasted values.

Framework and process of the FNR model.
Choice of state vector
The state vector
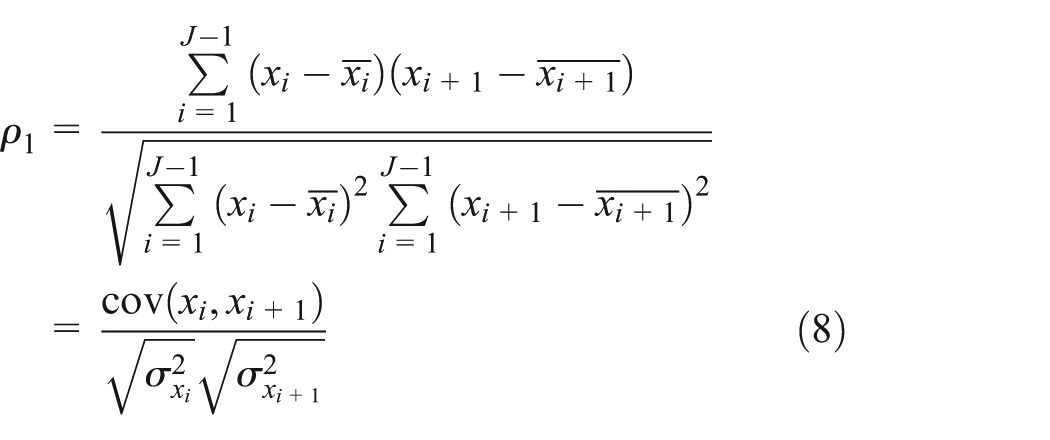
In the same way, the time series divided into

For stationary time series whose expectation is a constant, its observations fluctuate around the expectation; therefore, the variance is also a constant and the k-order autocorrelation coefficient can be expressed as follows

In accordance with the theory of autocorrelation analysis, when autocorrelation coefficient is in the range of

Result of autocorrelation analysis as an example.
Distance function computing
In many multivariate situations, the PCA is considered as a useful tool for displaying data in a reduced dimensional space. More recently, the PCA methods were extended to FDA.25–27 Here, the functional PCA is used as distance function for computing proximities between different traffic flow curves.
As long as


Now, equation (11) makes the equation

minimum, at that time


Note that in practice, we can only observe a discretized version

Therefore, the integral can be approximated as follows

where

where

In summary, the parameterized class of semi-norms has a widely application in computing proximities using the functional PCA. Its biggest advantage is that it will be still applicable when the curves are rough relatively. Of course, it also has some defects, that is, each the observations must be in the same time every period, otherwise it will not be able to use the functional PCA.
Kernel function selecting
There are many kernel functions, such as Boxcar kernel, Gaussian kernel, Triangle kernel, and Epanechnikov kernel. 28 The Epanechnikov kernel is selected in this model:
Boxcar kernel:
Gaussian kernel:
Triangle kernel:
Epanechnikov kernel:
Case study
Experiment scenario and data set
Since people travel with regularity, the traffic flow data with certain rules, there are four different scenarios in 1 week to characterize the rules:
Monday: which is the first day of a week with a high demand, where traffic is large during morning peak and increases significantly; evening peak tends to normal as little difference as usual;
Tuesday to Thursday: which is workday, where traffic is significantly reduced compared to Monday during morning peak and then traffic tends to be basically normal;
Friday: which is the last workday of a week, where traffic is relatively similar to that of the previous day during morning peak, but dramatic increase in evening peak which come too late to go early;
Saturday and Sunday: which is the rest day of a week, where the traffic is small with basically relatively balanced all day.
The FNR model is applied to the four different scenarios (Monday, Wednesday, Friday, and Saturday) for 1-week ahead and 1-day ahead traffic flow forecasting in this work, so the seasonal length of traffic flow defined in equation (1) is 1 week and 1 day, respectively, in the case study.
As mentioned with reference to Figure 3, the target is an expressway section called M1 from Madian Qiao to Anhua Qiao on the inner loop of North 3rd Ring Road Middle in Beijing. Traffic flow data analyzed in this article are collected from the Expressway Traffic Information Detection System in Beijing and obtained daily from the microwave detectors on the expressway. For the survey data sets, the modeling and forecasting are performed on traffic flow data aggregated at 10 min discrete time intervals. Note that

Beijing expressway section M1 location.
One-week ahead forecasting
As listed in Table 1, the data between 16 May 2011 and 10 July 2011 (a total of 8 weeks) are split into two parts. The first 7 weeks data of the scenarios (Monday, Wednesday, Friday, and Saturday) are used as historical data, respectively, while the data on 4 July (Monday), 6 July (Wednesday), 8 July (Friday), and 9 July 2011 (Saturday) of the last week as test data to verify the model’s accuracy. Note that
Historical and test data of 1-week ahead.

One-day ahead forecasting
As listed in Table 2, the data between 20 June and 10 July 2011 are split into two parts. The data of 14 days before Monday, Wednesday, Friday, and Saturday are used as historical data, respectively, while the data on 4 July (Monday), 6 July (Wednesday), 8 July (Friday), and 9 July 2011 (Saturday) as test data to verify the model’s accuracy. Note that
Historical and test data of 1-day ahead.

Benchmarks and performance measures
In order to verify the accuracy and effectiveness of the FNR model, forecasts obtained by means of the Seasonal ARIMA model, Back Propagation (BP) network, and Least Squares Support Vector Machine (LSSVM) based on the same date sets mentioned above will be used as benchmarks in this case study.
ARIMA is one of the most popular models for forecasting univariate time series data. When seasonal behavior is included in the model, it can be called Seasonal ARIMA model formed as SARIMA (p, d, q) (P, D, Q).29–32 BP network33,34 is a kind of multi-layer network with an input layer, one or more hidden layers and one output layer, which can simulate nonlinear input–output relations and become one of the most widely used neural network model for forecasting. LSSVM35,36 is an extension of the standard support vector machine, and the calculating speed for forecasting is improved by changing the inequality problem into equation problem.
Five different measures of accuracy and effectiveness are used in this research for evaluating the performance of the FNR forecasting model: mean absolute percent error (MAPE), root mean square error (RMSE), consistency index (D), 37 correlation coefficient (R), and statistic test (S1) 38 defined by as follows. MAPE is calculated to understand the overall performance of the FNR model; RMSE is useful for understanding the deviation between actual and forecasted values for each forecasting output; D and R are computed to identify the relationships between actual and forecasted values (i.e. the closer the value to 1, the better the performance of the model); and S1 is a statistic for testing the null hypothesis of no difference in the accuracy of two competing forecasts



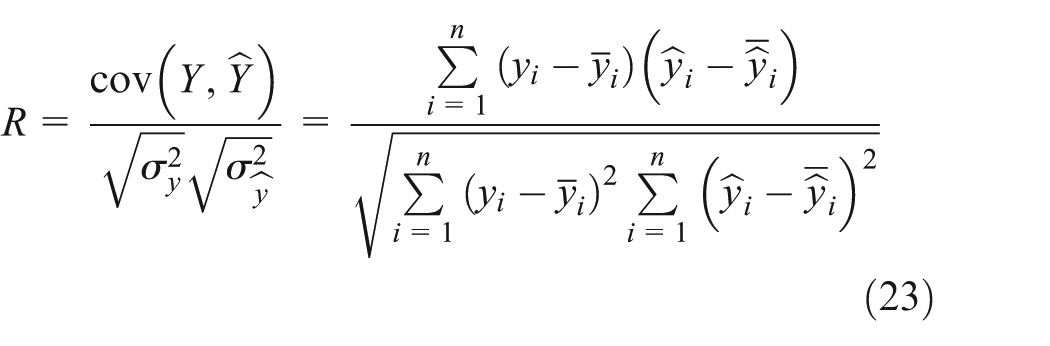
where

where
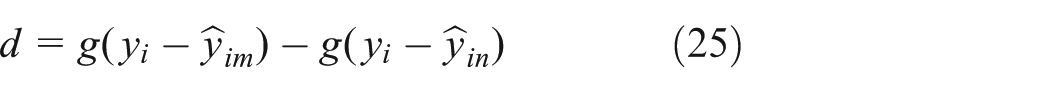
is a loss differential series
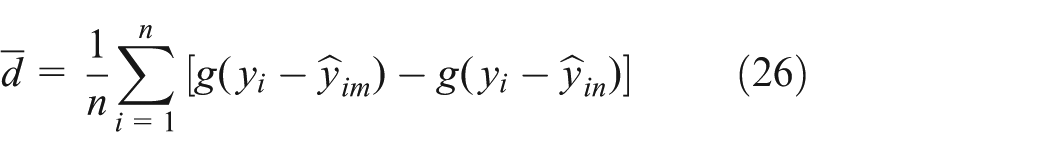
is the mean loss differential,

is a consistent estimate of the spectral density of the loss differential at frequency zero

is the autocovariance of the loss differential at displacement

For the sample, if S1 is in the range of [−1.96, 1.96], we should accept the null hypothesis that the population mean of the loss differential series is 0, that is, there is equal forecast accuracy for two forecasts.
Results on 1-week ahead forecasting
Upon the traffic flow data from the microwave detectors split into two independent samples, the learning process is initiated to ensure the effectiveness of the original traffic data and consider pruned curves before applying the FNR model to reduce the problem of outlier effect. In this study, as shown in Figure 4, the process of the case study can be described as follows:
Data preprocessing to identify and repair traffic flow fault data (including missing and abnormal data).
Getting the pruned curves of the historical traffic flow curves.
Select the state vector using the autocorrelation coefficient between any two times of the pruned curve.
Get the forecasted values Xn + 1 with different h by FNR model.
Compute the MAPEs with different h.
Choose the forecasted values when MAPE is the smallest as the final results.

Process of the case study.
Missing or abnormal data are unavoidable in practice, so it is necessary for data preprocessing to ensure the effectiveness of the original traffic data. In the research, the fault data were removed and repaired by estimating data from values of neighboring detectors or historical data. 39 Then, more specifically, the historical traffic flow curves could be pruned in the following way: 40
Taking the median in
Taking the median in
Forming a new smoothing processing
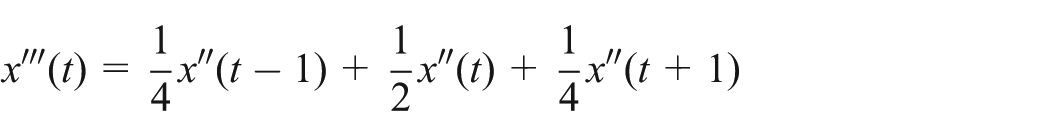
Figure 5 shows the pruned curves from the historical traffic flow data corresponding to the four scenarios.
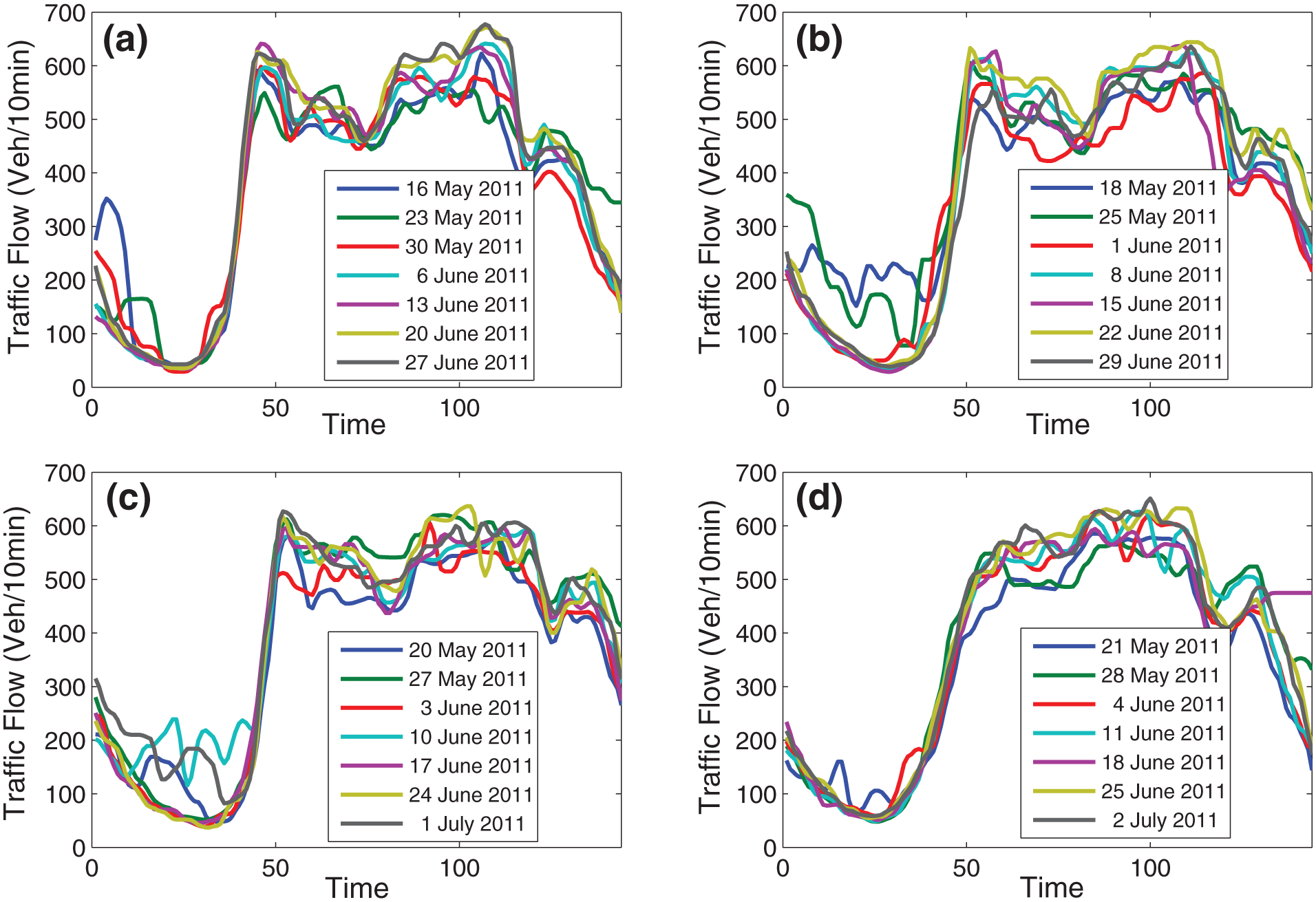
Pruned curves from the historical traffic flow data for 1-week ahead forecasting corresponding to the four scenarios: (a) Monday, (b) Wednesday, (c) Friday, and (d) Saturday.
In the FNR framework, autocorrelation analysis (ACF) is introduced to select the state vector

Traffic flow autocorrelation coefficient, after first differencing, for the four different scenarios: (a) Monday. The first four autocorrelation coefficients are not within the limit; (b) Wednesday. The first-order coefficient is not within the limit; (c) Friday. The first-order coefficient is not within the limit; and (d) Saturday. The first-order, second-order, and third-order coefficient are not within the limit.
Equations (30)–(33) give the choice of the state vectors for FNR model 1-week ahead forecasting on Monday, Wednesday, Friday, and Saturday, where
Model state vector on Monday as follows
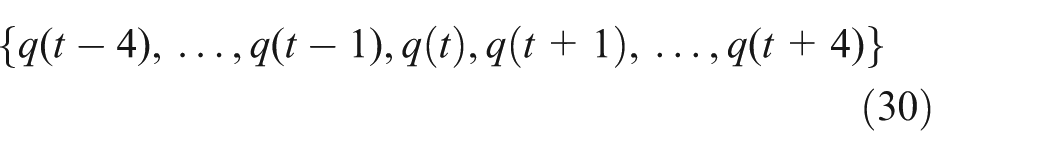
Model state vector on Wednesday as follows

Model state vector on Friday as follows

Model state vector on Saturday as follows

Using the FNR model for forecasting, the bandwidth h is a relevant parameter for the good asymptotic and practical behavior of the model. Here, the optimal bandwidth h could be determined through the performance of MAPE. Figure 7 shows the MAPEs of FNR model 1-week ahead forecasting with different values of h corresponding to the four scenarios. Based on the results, we can choose the optimal bandwidth h as follows: h = 566.2 on Monday, h = 479.4 on Wednesday, h = 424.2 on Friday, and h = 237.4 on Saturday, when the MAPE is the smallest.

Performance of MAPE for 1-week ahead forecasting varying with the different h: (a) performance of MAPE on Monday, (b) performance of MAPE on Wednesday, (c) performance of MAPE on Friday, and (d) performance of MAPE on Saturday.
In order to obtain the performance of the FNR model in different times, the forecasting accuracy is measured according to two periods: 0:00–24:00 and 6:00–22:00. In addition, SARIMA model, BP network, and LSSVM are used for comparison. Figures 8–11 display the traffic flow comparisons between actual and 1-week ahead forecasted values of the four scenarios.
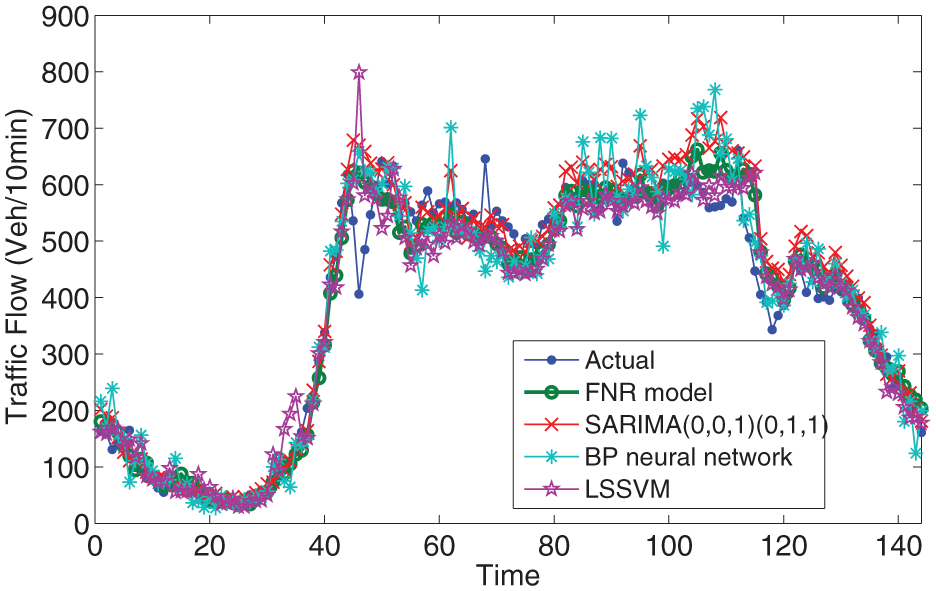
Traffic flow comparisons between actual and 1-week ahead forecasted values on 4 July 2011 (Monday).

Traffic flow comparisons between actual and 1-week ahead forecasted values on 6 July 2011 (Wednesday).

Traffic flow comparisons between actual and 1-week ahead forecasted values on 8 July 2011 (Friday).

Traffic flow comparisons between actual and 1-week ahead forecasted values on 9 July 2011 (Saturday).
Table 3 gives the 1-week ahead forecasting performance (MAPE, RMSE, D, R) comparisons of the FNR model and other models according to two periods: 0:00–24:00 and 6:00–22:00. In general, the results in this table show the good behavior of the FNR model. The FNR model gives slightly better results than the others do. As an example, the FNR model produces a relatively high accuracy of less than 10% error in MAPE. MAPE of the FNR model measured from 0:00 to 24:00 are 9.76% on Monday, 9.32% on Wednesday, 7.99% on Friday, and 7.67% on Saturday, while SARIMA model are 11.12% on Monday, 11.01% on Wednesday, 23.05% on Friday, and 10.59% on Saturday.
Forecasting accuracy comparisons of the FNR model and other models according to the two periods: 0:00–24:00 and 6:00–22:00.
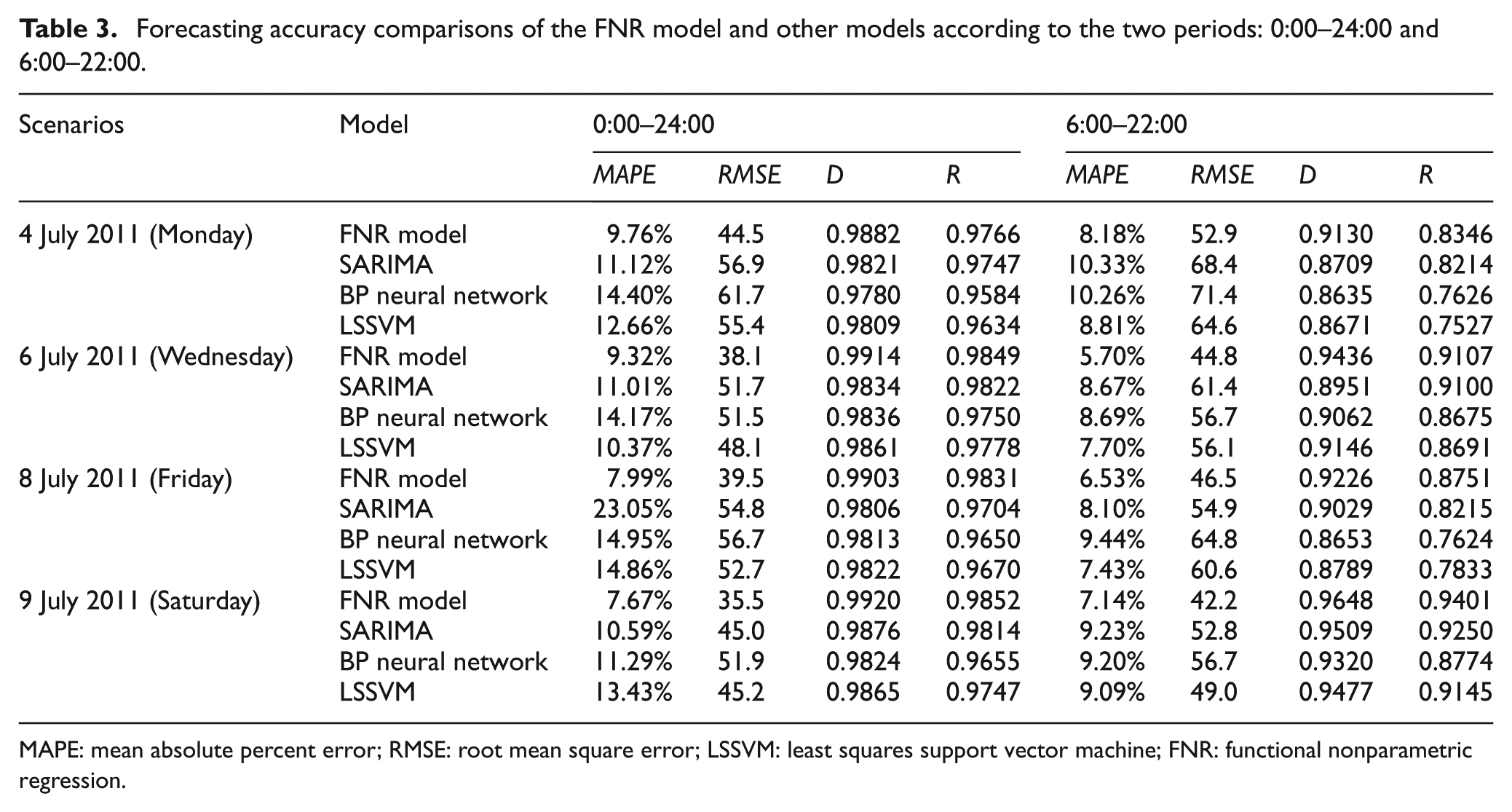
MAPE: mean absolute percent error; RMSE: root mean square error; LSSVM: least squares support vector machine; FNR: functional nonparametric regression.
Table 4 shows the statistic test S1 of 1-week ahead forecasted values between the FNR model and benchmarks. Since S1 is not in the range of [−1.96, 1.96], it could be said that there is significantly difference in the forecasting accuracy between FNR model and benchmarks.
Statistic S1 of 1-week ahead forecasted values between the FNR model and benchmarks according to the two periods: 0:00–24:00 and 6:00–22:00.

LSSVM: least squares support vector machine; FNR: functional nonparametric regression.
Figure 12 displays a visual comparison of MAPE corresponding to each model for 1-week ahead forecasting. Although the four models exhibit comparable results, the best behavior of the FNR model is also evident from this plot.
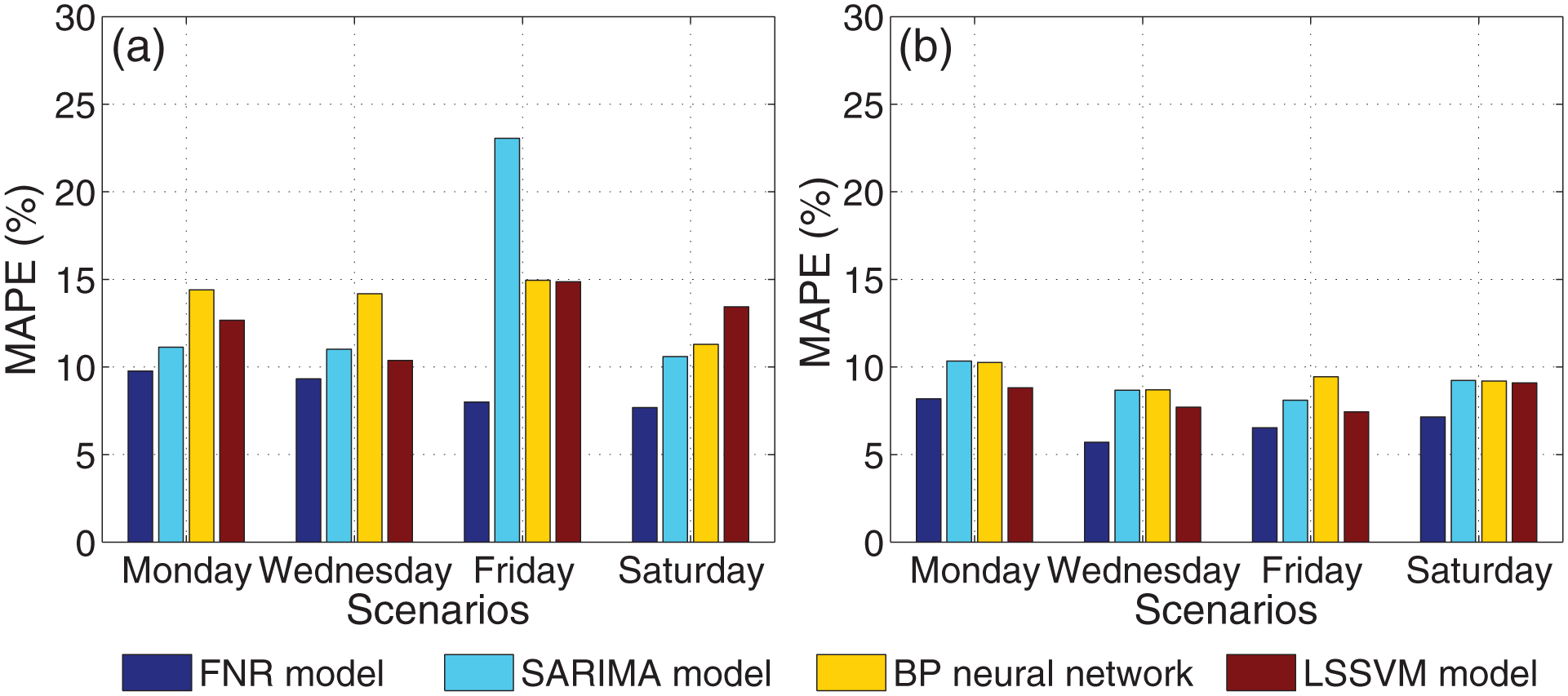
Comparison of MAPE corresponding to each model for 1-week ahead forecasting: (a) measured from 0:00 to 24:00 and (b) measured from 6:00 to 22:00.
Results on 1-day ahead forecasting
In accordance with the process shown in Figure 4, a similar study is conducted in this section for traffic flow 1-day ahead forecasting. In addition, the benchmarks and measures to evaluate the performance of FNR model are also the same as the previous 1-week ahead forecasting.
Figure 13 shows the MAPEs of FNR model 1-day ahead forecasting with different values of h corresponding to the four scenarios. Based on the results, we can choose the optimal bandwidth h as follows: h = 356.3 on Monday, h = 304.3 on Wednesday, h = 388.0 on Friday, and h = 212.6 on Saturday, when the MAPE is the smallest.

Performance of MAPE for 1-day ahead forecasting varying with the different h: (a) performance of MAPE on Monday, (b) performance of MAPE on Wednesday, (c) performance of MAPE on Friday, and (d) performance of MAPE on Saturday.
As the same as the 1-week ahead forecasting, the forecasting accuracy of 1-day ahead forecasting is also measured according to two periods: 0:00–24:00 and 6:00–22:00, SARIMA model, BP network, and LSSVM are also used for comparison. Figures 14–17 display the traffic flow comparisons between actual and 1-day ahead forecasted values of the four scenarios. Table 5 gives the 1-day ahead forecasting performance (MAPE, RMSE, D, R) comparisons of the FNR model and other models according to two periods: 0:00–24:00 and 6:00–22:00. Table 6 shows the statistic S1 of 1-day ahead forecasted values between the FNR model and benchmarks. Finally, Figure 18 displays a comparison of MAPE of the four models for 1-day ahead forecasting.

Traffic flow comparisons between actual and 1-day ahead forecasted values on 4 July 2011 (Monday).

Traffic flow comparisons between actual and 1-day ahead forecasted values on 6 July 2011 (Wednesday).

Traffic flow comparisons between actual and 1-day ahead forecasted values on 8 July 2011 (Friday).

Traffic flow comparisons between actual and 1-day ahead forecasted values on 9 July 2011 (Saturday).
Forecasting accuracy comparisons of the FNR model and other models according to the two periods: 0:00–24:00 and 6:00–22:00.

MAPE: mean absolute percent error; RMSE: root mean square error; FNR: functional nonparametric regression; LSSVM: least squares support vector machine.
Statistic S1 of 1-day ahead forecasted values between the FNR model and benchmarks according to the two periods: 0:00–24:00 and 6:00–22:00.
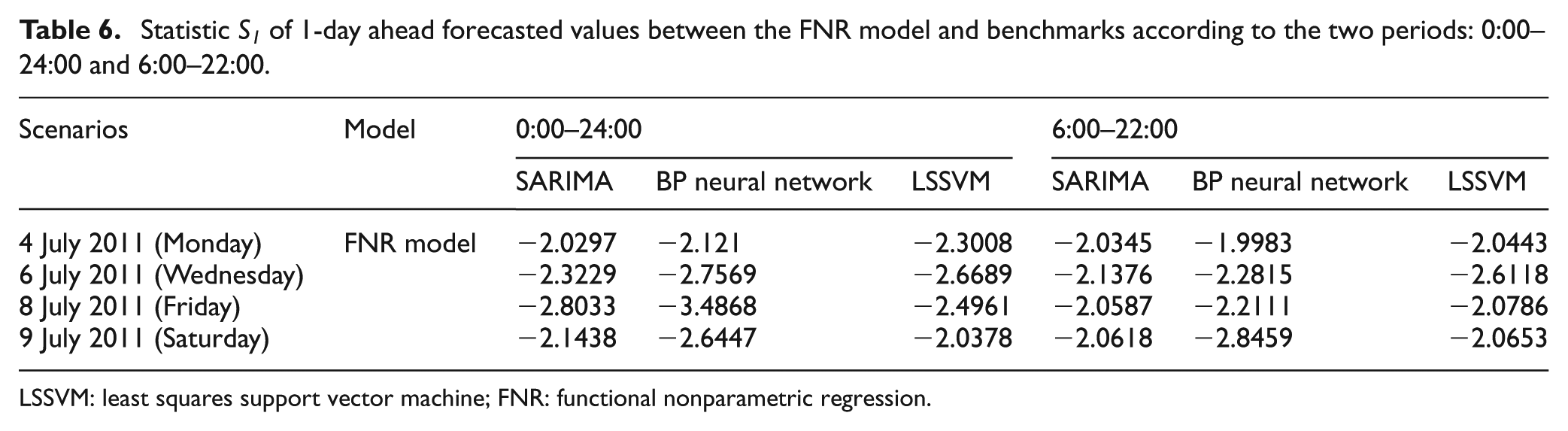
LSSVM: least squares support vector machine; FNR: functional nonparametric regression.

Comparison of MAPE corresponding to each model for 1-day ahead forecasting: (a) measured from 0:00 to 24:00 and (b) measured from 6:00 to 22:00.
Examining those table and figures above, the following statements could be drawn:
Table 5 gives the 1-day ahead forecasting performance (MAPE, RMSE, D, R) comparisons of the FNR model and other models according to two periods: 0:00–24:00 and 6:00–22:00. It is also clear that the FNR model is a very competitive one for traffic flow long-term forecasting. In this case, the FNR model produces a relatively high accuracy in MAPE. MAPE of the FNR model measured from 0:00 to 24:00 are 10.45% on Monday, 8.95% on Wednesday, 7.95% on Friday, and 8.93% on Saturday, while SARIMA model are 16.07% on Monday, 11.20% on Wednesday, 13.64% on Friday, and 13.58% on Saturday.
Table 6 shows the statistic S1 of 1-day ahead forecasted values between the FNR model and benchmarks. It is clear that there is difference in the accuracy between FNR model and others.
Figure 18 displays a comparison of MAPE of the four models for 1-day ahead forecasting, and the competitive behavior of FNR model is also clearly seen from this figure.
In summary, the proposed FNR model is generally better than other models in both accuracy and effectiveness and performs well in the 1-week ahead and 1-day ahead forecasting. Complementary, it can be easily applied to other frequency data (e.g. 2 min data, hourly data) whenever they become available.
Conclusion
Long-term traffic forecasting of urban freeway has become a basic and critical work in the research on road traffic congestion. It plays a positive role in improving the quality of traffic management and service. On one hand, it is helpful for increasing efficiency of the limited traffic management resource, especially, making reasonable arrangements for police or other management resource. On the other hand, it can provide useful reference for travelers to make plans for a long term in advance to avoid congestion. The goal of this work is to develop a highly accurate method for traffic situation long-term forecasting. The FNR model is introduced, and that goal is clearly achieved by this effort. The advantages of the FNR framework are as follows:
Temporal features of traffic flow are considered. In the FNR framework, in order to select the state vector of FNR model, the common variation characteristics are analyzed by the autocorrelation coefficient between any two times of traffic flow data.
The differences of long-term change trends are got from the historical traffic flow data by computing proximities based on the functional PCA.
Moreover, the experiments based on the traffic flow data in Beijing expressway show that the FNR model performs better than other models in both accuracy and effectiveness. Complementary, it can be easily applied to other frequency data whenever they become available. All these features make this approach appealing and with plenty of potential for improving. The next steps of this work are to refine the model incorporating spatial features of traffic flow and summarize long-term forecasting of the road network under the FNR model.
Footnotes
Academic Editor: Chin-Lung Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Science & Technology Pillar Program (Grant No. 2014BAG 01B02).