
Abstract
Pedestrians in the vehicle path are in danger of being hit, thus causing severe injury to pedestrians and vehicle occupants. Therefore, real-time pedestrian detection with the video of vehicle-mounted camera is of great significance to vehicle–pedestrian collision warning and traffic safety of self-driving car. In this article, a real-time scheme was proposed based on integral channel features and graphics processing unit. The proposed method does not need to resize the input image. Moreover, the computationally expensive convolution of the detectors and the input image was converted into the dot product of two larger matrixes, which can be computed effectively using a graphics processing unit. The experiments showed that the proposed method could be employed to detect pedestrians in the video of car camera at 20+ frames per second with acceptable error rates. Thus, it can be applied in real-time detection tasks with the videos of car camera.
Introduction
As one of the basic city functions, transportation links the social and economic movement of a city. Nowadays, with the change of urban structure, the urban traffic is getting more complex. Safety, congestion, and other issues have become increasingly prominent. Driver behavioral algorithms and simulation of traffic situation have been studied to solve the mentioned problems. Wang et al. 1 developed a simulation modeling of driver’s safety approaching behavior by considering the variability of vehicle’s speed situations.
For a long time, pedestrian safety has been neglected. In 2014 in China, there is around 34,292 deaths and 160,000 injured victims in road accidents in which pedestrians or electric cyclists collide with a car. Pedestrian accidents represent the second largest source of traffic-related injuries and deaths. At present, pedestrian protection has become a vital issue in urban traffic. Thus, the pedestrian real-time tracking becomes a hotspot, especially in the field of safety driving assistance and vulnerable road user protection.
Broggi et al. 2 proposed the method for detecting pedestrian via the ARGO prototype vehicle. Gavrila et al. 3 first presented large-scale field tests on vision-based pedestrian protection from a moving vehicle. The system called PROTECTOR, which combines pedestrian detection, trajectory estimation, and risk assessment with driver warning. Tons et al. 4 studied the short-range sensor capability for the pedestrian detection in the range up to 30 m based on the famous project SAVE-U (sensors and system architecture for vulnerable road user protection). Jiang et al. 5 studied the time-to-collision in vehicle–pedestrian conflict on urban midblock crosswalk.
Pedestrian detection methods can be divided into two main categories. Histogram of oriented gradients (HOG) + support vector machines (SVM) and integral channel features (ICF) are the two most popular pedestrian detection methods utilizing single part template.6–8 ICF can perform better than HOG + SVM. 9 Deformable part models (DPM) is the representative method based on multiple part templates and mixture models. 10 So far, the ICF and DPM are most widely used in pedestrian detection. Although the latest version of the DPM slightly outperforms the ICF, the performance of ICF is also acceptable for most tasks and has the higher computation efficiency. Therefore, ICF is a more practical detection method for real-time tasks such as the pedestrian detection using car camera video.
In this article, we proposed a real-time scheme of pedestrian detection based on an improved ICF and graphics processing unit (GPU). We first employed the improved scheme of ICF proposed by Benenson et al., 9 which reduced the number of classifiers by approximating the multi-scale models using several canonical ones. Then we accelerated the computation of detection window scores by constructing a new larger image. The image consists of each detection window without overlapping. The scores of all detection windows can be computed simultaneously through the dot product of the larger image. Meanwhile, a matrix created from the detector. The dot product could be computed very fast using a GPU, which could greatly accelerate the detection. The experiment used car video camera based on ARM and CUDA. It showed that the proposed method could process 20+ frames (320 by 240) per second with acceptable error rate. In the following sections, we firstly briefly analyzed the baseline detector, the ICF, and the improved detector based on GPU in section “Methodology”; then we analyzed the experimental results in section “Experiments and discussion”; and the conclusions are given in section “Conclusion.”
Methodology
Analysis of baseline detector
The ICF detector was proposed by Dollár et al. 8 This detector yields state-of-the-art results and is on a par with the popular DPM detectors. 10 As a detector based on single part templates, it significantly outperforms HOG + SVM 11 and is superior to the initial versions of part-based detectors. This method is inspired by the detection framework proposed by Viola and Jones. 12 For ICF, several channels are first obtained by linear and nonlinear transformation of input image. Then the first-order features, the sum of the elements in a certain region of a channel, may be computed efficiently with the integral image. By combining multiple first-order features in multiple channels, the second-order features were constructed. The first- and second-order features can express the richness and diversity of image information. ICF shows the high performance in object detection, particularly in the pedestrian detection. The gradient histogram in six orientations, the magnitude of gradient, and the L, U, V color channels were employed. 8 The candidate features were computed by randomly selecting the index of channels, size, and position of the region for the local sums. Totally, 5000 candidate features were obtained and 1000 weak classifiers and two decision trees were used to train a boosted classifier. The state-of-art results were obtained in INRIA and Caltech Pedestrian datasets.
The entire procedure of detecting pedestrian using ICF method could be summarized in the following steps:
Step 1: Select and construct, if needed, channels of the input image for computing features. In the original ICF method, 8 the L, U, V color channels were selected and the gradient histogram in six orientations and the magnitude of the gradient were computed to construct the 10 channels for computing object features.
Step 2: Randomly selecting N local windows with different index of channels, size, and position for computing the features.
Step 3: Computing the first- and second-order features for the selected windows. The first-order features are the sum of the elements in a certain region of a channel and could be computed efficiently with the integral image. The second-order features can be constructed by combining multiple first-order features in multiple channels. For example, the first-order horizontal difference of a window centered at (x, y) could be obtained by subtract the window with the same size centered at (x − 1, y) in the same channel. The number of the features computed in ICF method is usually around 5000.
Step 4: Construct weak classifiers for multiple combinations of the features. The number of the weak classifiers is usually around 1000. Finally, a boosted classifier is trained using decision trees from the weak classifiers.
Although the ICF can be used to detect pedestrians with a low error rate, the computational efficiency should be improved greatly to meet the application requirements of real-time detection tasks. In this article, we improved the ICF based on the scheme proposed by Benenson et al. 9 The details were described as follows.
Proposed method
In the procedure of object detection with ICF, the input image needs to be resized by multiple times to detect the object in different scales and this is computationally expensive. To eschew resizing, Benenson et al. 9 proposed the approach to train the classifiers in multiple scales. To detect the objects in multiple scales, the size of the input image is fixed and scanned by the trained multi-scale classifiers. 9 To further improve the efficiency, only N/K (N > K) canonical classifiers are trained in N scales. The classifiers for other scales are approximated with those trained canonical classifiers.
It has been proven that the feature response of the ICF in different scales could be approximated by estimating a set of factors 13 as follows

where r(s) is the ratio between a feature response at scale 1 versus scale s and au, bu, ad, bd are parameters empirically estimated for up- and down-sampling.
The strong classifier of the ICF is built from a set of decision trees and each decision tree contains multiple weak classifiers. A weak classifier only handles the features from a certain channel by a decision threshold T. Because the feature response could be approximated, the thresholds of the weak classifiers in different scales can be approximated by multiplying the scale factor r(s). For N scales, we only need to train K < N classifiers and the others could be approximated. Thus, the resizing is moved to training from test. The architecture is shown in Figure 1. The input image is fixed and most of the classifiers are approximated with several canonical ones.

Difference between the ICF and the improved ICF at multiple scales: (a) scheme of ICF and (b) scheme of the improved ICF.
In ICF, we adopted the commonly used object detector architecture and the sliding-window type. The detector is required to scan all the detection windows in the input image one by one. The scanning procedure is computationally expensive. Here, we proposed a new scheme to compute the scores for all the detection windows simultaneously with GPU.
In the proposed scheme, a larger image consisting of all the detection windows without overlapping was constructed. For a given image I with the size of M, the sizing scale was N, for a detector D whose size was m, the sizing scale was n. We created a larger image I′ whose size was

where g was the overlap length of two detection windows. In the larger input image, each m-by-n partition was a detection window copied from the original input image. In I′, there was no overlap between detection windows. Then we created a new detector D′ whose size was the same with I′ and the each m-by-n partition was just a copy of the original detector D. By computing the dot product of I′ and D′, the scores for all the detection windows could be computed simultaneously. The computation of the dot product could be implemented using a GPU, which could greatly accelerate the detection. Figure 2 shows the scheme of the proposed approach. The convolution of input image and the detector is converted into a dot product of the larger image and the matrix constructed by copying the detector to corresponding partition.

Proposed scheme for computing detection scores with GPU.
The scale of the detector is 40. The overlap length of two detection window is 20. Other parameters for training the detector are from previous reports.8,9Figure 3 shows the flowchart of the proposed method and ICF.

Flowcharts of the ICF and the proposed method: (a) flowchart of ICF and (b) flowchart of the proposed method.
Experiments and discussion
The algorithm was first simulated and tested on a desktop with GPU and CUDA, so a platform with embedded processor and GPU was then employed to test it. An implementation using FPGA could be much more effective and we are still developing it currently. In this article, we show the experiments and result using GPU. The algorithm was tested in NVIDIA JETSON system which was composed of a Kepler GPU with 192 CUDA cores, an ARM Cortex-A15 4-core CPU, and 2 GB memory.
The video for experiments was captured by a car camera with the resolution of 320 by 240 in 30 frames per second (FPS). Two groups of videos including urban and country roads are tested (seven videos of urban road and six videos of country road). The videos of urban road are captured in Yanqing Town, Beijing, China. The videos of country road are captured in Liugou Village, Beijing, China.
Tests on the videos of the urban road
The proposed method was tested on the seven videos captured on urban road. With the best configuration of the parameters of the algorithm, the average error rates of false positive (FP) and false negative (FN) are 11.01% and 8.15%, respectively. The maximum FP and FN rates are 14.34% and 11.68%, respectively. For most test videos, the proposed approach ran at 20+ FPS. The average FPS is 21.4 and the minimum FPS is 19.7. Table 1 shows the FPS, FP rate, and FN rate of the proposed method for urban road videos. Figure 4 shows the detection results obtained in two frames of the urban road videos.
Performances of the proposed method for the urban road videos.
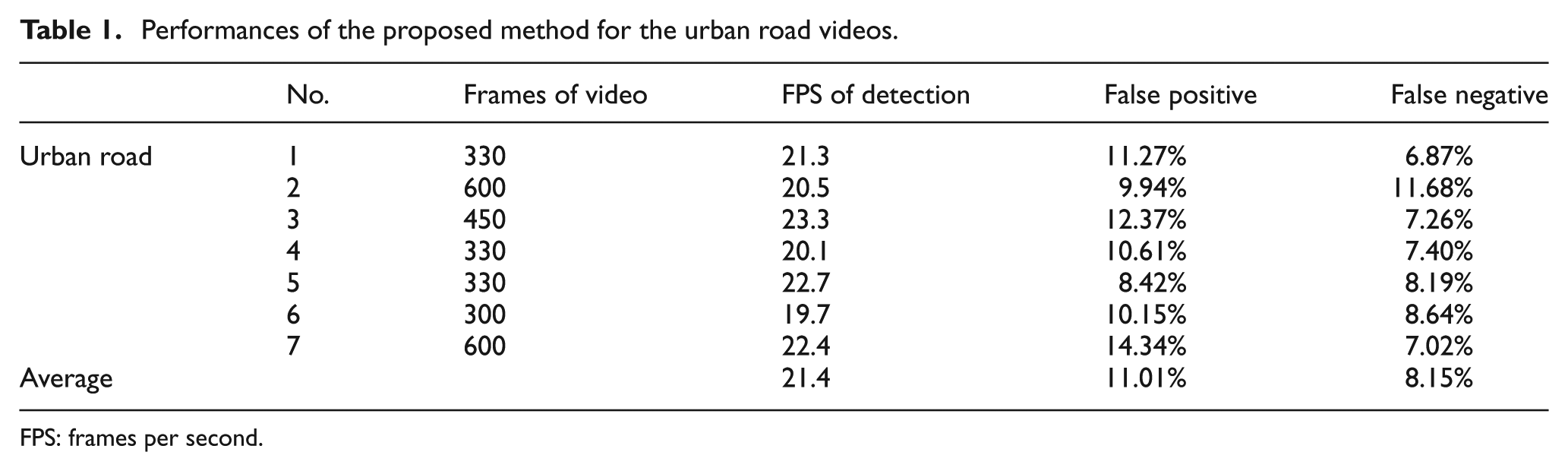
FPS: frames per second.

Pedestrian detection result obtained with urban road video.
To compare the proposed method to existing ones, we conducted pedestrian detection on urban road videos with DPMs and ICF in the same hardware system. The average FPS of the detection results obtained with DPMs and ICF are 2.9 and 5.1, respectively. The ICF is 1.75 times faster than the DPMs because the DPMs employ multi-part templates which are much more computationally expensive than the ICF’s single part template. The proposed method is four times faster than the ICF and it is the fastest one among the tested methods. This is because the proposed method benefits from the parallel computation capability of GPU and the improved scheme of score computation.
The average FP rate and average FN rate of the result of the ICF for urban road videos are 12.55% and 7.67%, respectively. The maximum FP rate and maximum FN rate are 14.34% and 11.68%, respectively. The error rates of ICF for urban road videos are close to those of the proposed method because the structure of the proposed method is almost the same with that of the ICF except for the scheme of creating multi-scale detectors.
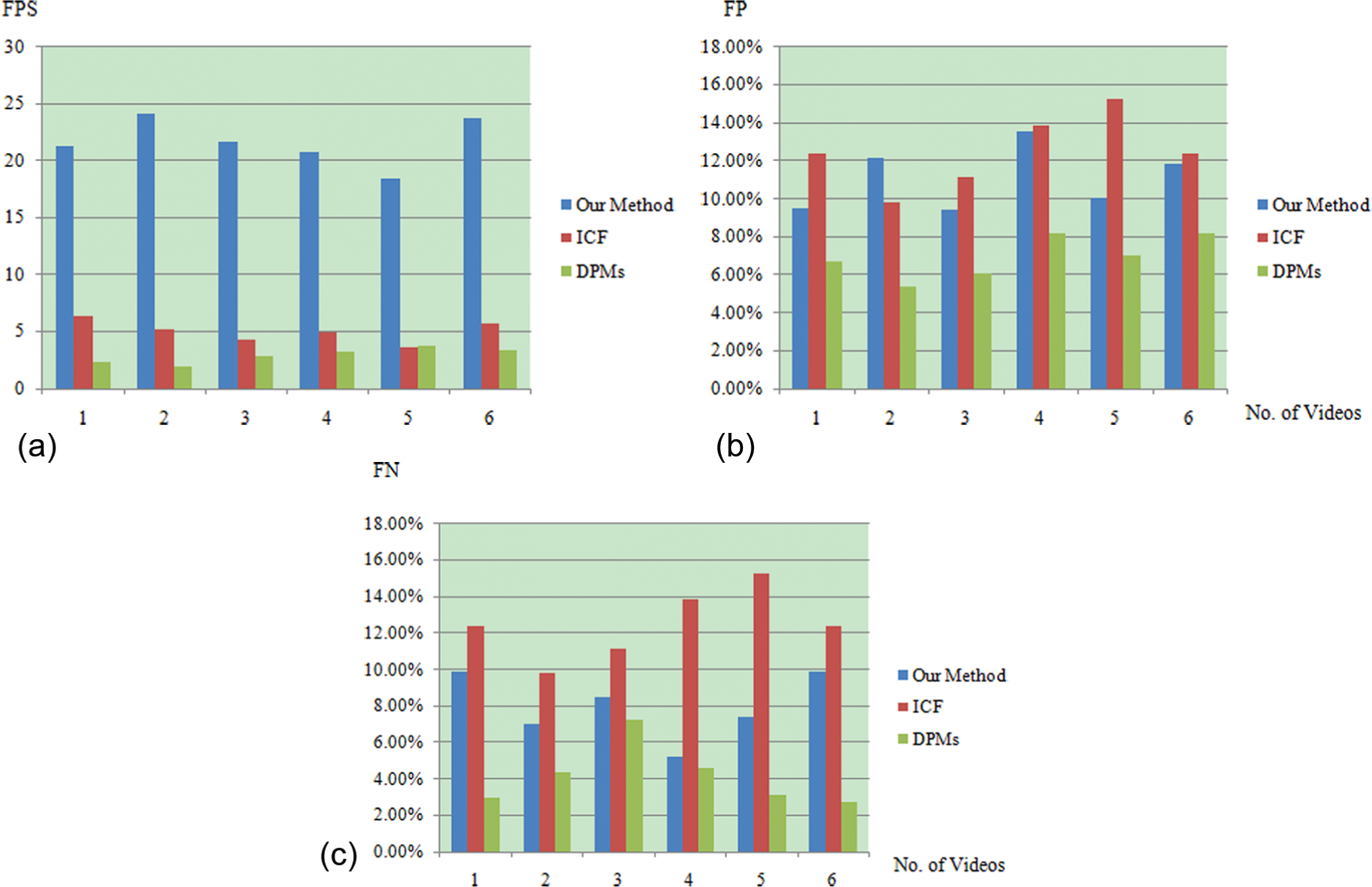
The average FP rate and average FN rate of the result of DPMs for urban videos are 6.7% and 4.46%, respectively, which are better than those of the proposed method. The adoption of the complex multi-part template led to the better performance of DPMs. However, the proposed method has a reasonable trade-off between speed and quality, which makes it a better detector than DPMs for real-time pedestrian detection for urban road videos. Table 2 shows the performance comparison among the proposed method, the ICF, and DPMs for the urban videos. Figure 5 shows the comparison among the FPS, FP, and FN.
Comparison of the performance of various methods for urban videos.

FPS: frames per second; FP: false positive; FN: false negative; ICF: integral channel features; DPM: deformable part models.

Bar charts of the comparison of (a) FPS, (b) FP, and (c) FN for urban road video.
Based on the analysis and the comparison, we can find that the proposed method is a good trade-off between the speed and quality of the pedestrian detection and can detect pedestrian well in the urban background consisting of high buildings, automobiles, traffic lights, and so on.
Tests on the videos of the country road
For the videos captured on country roads, we tested our method and compared it with ICF and DPMs. For the proposed method, the best average FP rates and the best average FN rate are 11.07% and 7.99%, respectively. The maximum FP rate and maximum FN rate are 13.52% and 9.92%, respectively. For most of the tested videos, the proposed approach ran at 20+ FPS. The average FPS is 21.65 and the minimum FPS is 18.4. Table 3 shows the FPS, FP rate, and FN rate of the proposed method for urban road videos. Figure 6 shows the detection results in two frames of country road videos.
Performance of the proposed method for the country road videos.

FPS: frames per second.

Pedestrian detection result obtained with testing videos of country road.
The average FPS of the detection with DPMs and ICF are 2.9 and 5.0, respectively. The ICF is 1.72 times faster than the DPMs. Because the computationally expensive multi-part templates employed in DPMs led to the low computation speed. The proposed method is 4.3 times faster than the ICF and is the fastest one among the tested methods. The faster computation is due to the parallel computation capability of GPU and the new scheme of score computation.
The average FP rate and average FN rate of the result of the ICF are 15.26% and 10.96%, respectively, which are close to those of the proposed method. The average FP rate and average FN rate of the result of DPMs are 8.20% and 7.23%, respectively, which are better than those of the proposed method. The adoption of the complex multi-part template led to the better performance of DPMs. Table 4 shows the performance comparison of the above three methods for the country road videos. Figure 7 shows the comparison of the FPS, FP, and FN.
Comparison of the performance of methods for country videos.

FPS: frames per second; FP: false positive; FN: false negative; ICF: integral channel features; DPM: deformable part models.
Bar charts of the comparison of (a) FPS, (b) FP, and (c) FN for country road videos.
According to the experiments and the comparison for country road videos, compared to the ICF and DPMs, the proposed method has an acceptable detection quality and the much faster detection speed. Moreover, the proposed method is able to detect pedestrian well in the country background consisting of trees, small buildings, and so on.
Evaluation of the proposed scheme
To evaluate the proposed scheme of score computation for the detection windows, we compared our method to the implementation of ICF using GPU presented by Benenson et al. 9 The proposed method is 1.6 times faster than the Benenson’s implementation. The average FPS of our implementations is 21.5. Meanwhile, the average FPS of Benenson’s implementation is 13.3. Table 5 and Figure 8 show the comparison of FPS for all the 11 test videos.
Comparison of the FPS of the proposed implementation and another one.


Comparison of the proposed implementation and another one 7 of ICF using GPU.
Conclusion
The result shows that the proposed method could detect pedestrian in 20+ FPS with error rates of FP and FN around 10% and 8%, respectively. For videos captured by car camera at 30 FPS, this method could detect every two frames with acceptable error rates. Thus, the proposed method is able to apply at real-time pedestrian detection task running on an embedded system with NVIDIA CUDA GPU. The test video captured from urban and country road shows that this method performed well for both of them. Compared to ICF and DPMs, the proposed detector is of a better trade-off between speed and quality. The proposed scheme for computing scores of the detection windows using a dot product in GPU is effective and the proposed method is 1.6 times faster than the state-of-art implementation of ICF.
Footnotes
Academic Editor: Geert Wets
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.