
Abstract
Rational traffic flow forecasting is essential to the development of advanced intelligent transportation systems. Most existing research focuses on methodologies to improve prediction accuracy. However, applications of different forecast models have not been adequately studied yet. This research compares the performance of three representative prediction models with real-life data in Beijing. They are autoregressive integrated moving average, neutral network, and nonparametric regression. The results suggest that nonparametric regression significantly outperforms the other models. With Wilcoxon signed-rank test, the root mean square errors and the error distribution reveal that the nonparametric regression model experiences superior accuracy. In addition, the nonparametric regression model exhibits the best spatial-transferred application effect.
Keywords
Introduction
Intelligent transportation system (ITS) has been widely implemented around the world, and it supports proactive transportation management. In order to control the system in a proactive manner, ITS must have a predictive capability.1–4 To accomplish this, a wide range of traffic flow forecasting approaches has been studied for more than three decades.
Traffic forecasting has been viewed from different perspectives: as a time series, 5 a pattern recognition problem, 6 a nonparametric regression problem, 7 or even combination of the above. 8 However, none of them is a universal model that is suitable for all circumstances. Hence, comparing both modeling specifications and results is imperative to justify the effectiveness of a proposed forecasting approach. Karlaftis and Vlahogianni 9 found that most transportation research regard the estimation error as a measure of effectiveness in short-term traffic forecasting, while overlooking some important issues such as parameter stability and error distribution. It is also suggested that most comparisons conducted are not always fair, particularly when comparing complex nonlinear to simple linear models. Furthermore, there is a thin line among model accuracy, simplicity, and suitability. Kirby et al. 10 suggested that accuracy is of great importance but should not be the only determinant in selecting the appropriate methodology when predicting. Two measures of model performance, namely, the mean absolute error (MAE) and the mean absolute percentage error (MAPE) have been adopted to evaluate the prediction results.11–14 Other evaluation indicators should be considered, including time and effort required for model development, transferability of results, skills and expertise required, adaptability to changing temporal or spatial behavior, to name a few.10,15–17
In this study, the performance of three representative modeling approaches is compared with real-life data in Beijing. They are autoregressive integrated moving average (ARIMA) which is a representative model of statistical time series model and attempts to develop a mathematical model explaining the past behavior of a series, neural network which is a mathematical modeling approach developed in the field of artificial intelligence, and nonparametric regression which attempts to identify groups of past cases which are similar to the state at prediction time. In addition, the applicability of the three prediction models is discussed with a new perspective in which coefficient of variation (CV) is adopted to describe the characteristics of the data.
The structure of this article is as follows: section “Data collection” illustrates the data source adopted in modeling process, section “Models” presents the methodologies of the three modeling techniques, section “Model comparisons” presents model application comparison with five proposed performance indices, and section “Conclusion” summarizes the accuracy and applicability of three prediction models and proposes the directions for further research.
Data collection
Study location
All the traffic data used in the three models are obtained from the Intelligent Transportation Control System of Beijing. The system has thousands of remote traffic microwave sensors (RTMS) installed on expressway in order to monitor traffic conditions and facilitate rapid responses to incidents. The traffic volume, speed, and occupancy data are collected every 5 min over 24 h and transmitted to the computer for analysis. Two sites are selected for the study. They are Jianguomen Bridge (02051) and Jimen Bridge (03056), which are located near the North 2nd and 3rd Ring Road in Beijing, as shown in Figure 1. Unfortunately, RTMS in a harsh environment that always results in missing data and fault data. The data have been enriched and completed by data filling techniques.

Study sites (Map Source: Google Maps).
Data description
The data adopted in this article include traffic speed, which denotes an average speed based on the average travel time of vehicles to traverse the defined roadway length. The travel time embeds stopped delays due to traffic congestion. For each site, traffic speed data were collected every 5 min in 24 h from January to October in 2012, which result in 86,400 data points. Since the traffic speed patterns are different between weekdays, weekends, and holidays, data collection was limited to weekdays only and except National Day in this study.
The traffic speed data of five consecutive Mondays from the same road are shown in Figure 2. The correlation coefficient is up to 0.94, indicating that the weekly traffic speed data fluctuation is largely repeatable on the same road segment, which is called weekly similarity. Therefore, traffic speed prediction is possible based on this weekly similarity.

Observed traffic speed data of five consecutive Mondays.
Models
ARIMA model
ARIMA model is one of the commonly used approaches for forecasting. It attempts to estimate model parameters through time series in the past and then uses the estimated model to forecast future time series values. Wang and Liu 18 applied it to forecast traffic flow conditions and found the method an excellent prediction method in stochastic time series analysis. Lee and Fambro 19 used autoregressive moving average (ARMA) and ARIMA models on freeway traffic flow forecasting and found that ARIMA model outperformed other time series models.
The ARIMA model can only be applied to stationary time series, and it relies on an uninterrupted series of data. If the time series is nonstationary, it is necessary to convert the data to stationary time series using the differences or transformations. The common arithmetic form of an ARIMA (p, d, q) model can be written as

where
For this study, the ARIMA model is developed based on traffic speed data for morning peak, flat day, and evening peak on each Monday during September and October (except National Day), with no missing data.
Back-propagation neural network model
Back-propagation (BP) is one of the techniques for artificial neural networks that are able to capture various nonlinearities in the data. In Figure 3, the most common BP neural network is shown. The BP learning algorithm can be divided into two phases: forward propagation and backward propagation.
Phase 1: forward propagation—The neurons receive inputs at the input layer, pass the weighted inputs to the hidden layer and then output signal at the output layer after passing through the activation function imposed in the neurons.
Phase 2: backward propagation—If the outputs do not reach the error level specified, the errors are propagated backward from the output nodes to the input nodes. After adjusting the weights, the error will propagate forward. Therefore, BP neural networks can learn by changing the weights connecting among the neurons to adjust the outputs in the output layer. 13
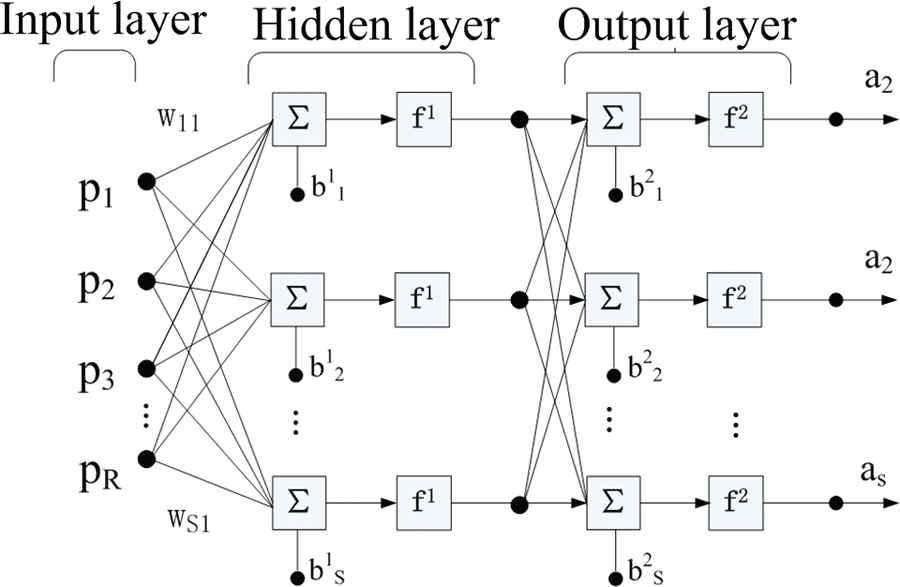
Back-propagation neural network.
Repeat phases 1 and 2 until the performance of the network is satisfactory. The complete algorithm for a three-layer network (only one hidden layer) is presented in Figure 4.

Back-propagation algorithm.
At present, there is no exact formulation to calculate the number of neurons in the input layer and the hidden layer. To optimize the prediction structures, a vast range of optimization tests must be conducted. In this article, BP neural network with 16 input neurons is the most appropriate to represent the traffic speed data of the consecutive Mondays by iterative trial. Of the 16 input neurons, 10 accepted the data before the current time, and others received historical data which were obtained at the same time on the previous day. The model is not retrained at the other location. This decision was made based on the fact that it would be highly unlikely that so many skilled personnel will be able to train neural network at different sites.
Nonparametric regression model
Nonparametric regression performs in a sense that it requires less computation and data overhead the ARIMA model and BP model. This approach does not need any prior training but instead performs prediction based on a group of similar past cases in the history database around the current input state at prediction time.
The similar past cases are referred as the nearest neighbors. In this research, a typical nonparametric regression method k nearest neighbors (KNN) is utilized, in which the underlying principle is to choose the KNN based on a distance measure, such as Euclidean distance. 21 However, a suitable value for k must be determined by several attempts and then the one that gives the smallest prediction error is chosen. 22 Once the neighbors are identified, the prediction is a weighted average of the KNN. The value of weight is then determined by the inverse of their distance. The complete algorithm is presented in Figure 5.

Nonparametric regression algorithm.
In this research, the state vector

where x(t) is the traffic speed at the current time t, x(t − 1) is the traffic speed during the previous 5-min interval, and x(t + 1) is defined as the output of X(t). The data collected through the 10-month period constitute the development database.
Model comparisons
Performance indices
In order to fully evaluate the performance and potential for field implementation of the three forecasting approaches, a performance index system is established, as shown in Figure 6. The performance is evaluated in terms of two parts: quantitative index and qualitative index. The quantitative index consists of four components: absolute error (AE), root mean square error (RMSE), error distribution, and model portability. The qualitative index refers to the ease of implementing a forecasting model, which is evaluated based on the personal experience gained in developing the models.

Performance indices.
AE
The AE describes how much the predicted values deviate from the actual values. To measure the statistical significance of difference between absolute average errors of the models, the Wilcoxon signed-rank test is used (Figure 7). The nonparametric statistical hypothesis test is used 15 when comparing paired sample cases which are not normally distributed. 23 In this research, the pairs can be defined as the AE experienced by the two models at a given prediction time. In general, the test procedure of the Wilcoxon signed-rank test can be seen in Figure 7. Tables 1–3 describe the results of the Wilcoxon signed-rank test in Jianguomen Bridge.

Procedure of the Wilcoxon signed-rank test.
Wilcoxon signed-rank tests—morning peak.
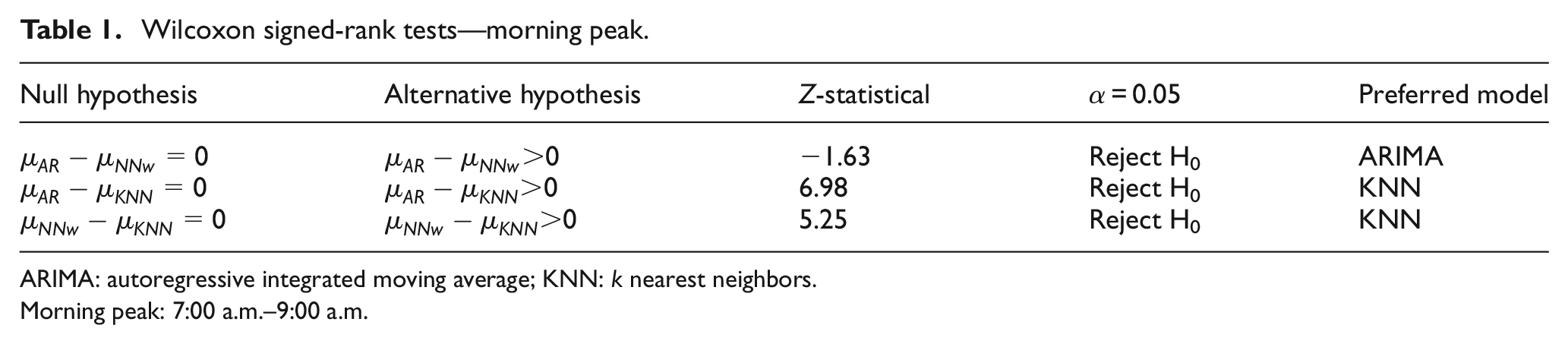
ARIMA: autoregressive integrated moving average; KNN: k nearest neighbors.
Morning peak: 7:00 a.m.–9:00 a.m.
Wilcoxon signed-rank tests—nonpeak.

Nonpeak: 12:00 a.m.–2:00 p.m.
Wilcoxon signed-rank tests—evening peak.

ARIMA: autoregressive integrated moving average; KNN: k nearest neighbors.
Evening peak: 5:00 p.m.–7:00 p.m.
Tables 1–3 illustrate the results for the Wilcoxon signed-rank test. It is clear that average AEs by the KNN model are significantly lower than those from the other two models in morning peak and evening peak. However, they are statistically equal in nonpeak time.
RMSE
The RMSE is defined as the square root of the mean of the squares of the deviations between the actual and predicted values, as illustrated below. RMSE is a good measure of accuracy. It only compares forecasting errors of different models for a particular variable but not between variables, as it is scale dependent. 24 The RMSE serves to magnify the relative difference between errors because of the square, so it is helpful to estimate which model carries the larger error point. The RMSE of Jianguomen Bridge on the three tests is represented in Figure 8


RMSE comparison.
where
As shown in Figure 8, the BP model gives the largest error in all three tests, whereas the ARIMA model and KNN model lead to comparable error results on morning peak and evening peak, and ARIMA model is more accurate on nonpeak time. In other words, the BP model has the larger error point. It is most likely due to the network training process.
Distribution of error
The distribution of error serves to evaluate the proportion of predicted values within a specified threshold (Table 4), and it can be used to describe how reliable the predicted values are. In this article, two thresholds are defined: predicted values higher and lower than 10% of the actual values. Moreover, the higher the proportion, the better the prediction accuracy.
Error distribution.

ARIMA: autoregressive integrated moving average; BP: back-propagation; KNN: k nearest neighbors.
Comparing the error distribution in Table 4, the BP model gives the least accurate results, whereas the error distributions of the ARIMA model and KNN model are almost equal on morning peak. However, three models have the same error results on nonpeak time. On the whole, the KNN model has the highest proportion at 48%, as compared to 36% and 31% for the other two models.
Model portability
Model portability refers to the consistent performance of a model at different sites. Once a model is developed for one site, it should perform comparably at other sites where it is deployed. This component of the quantitative performance index is measured by comparing the difference in the errors experienced by the three models at two different sites. The errors are represented in Tables 5–7.
Error measures—morning peak.
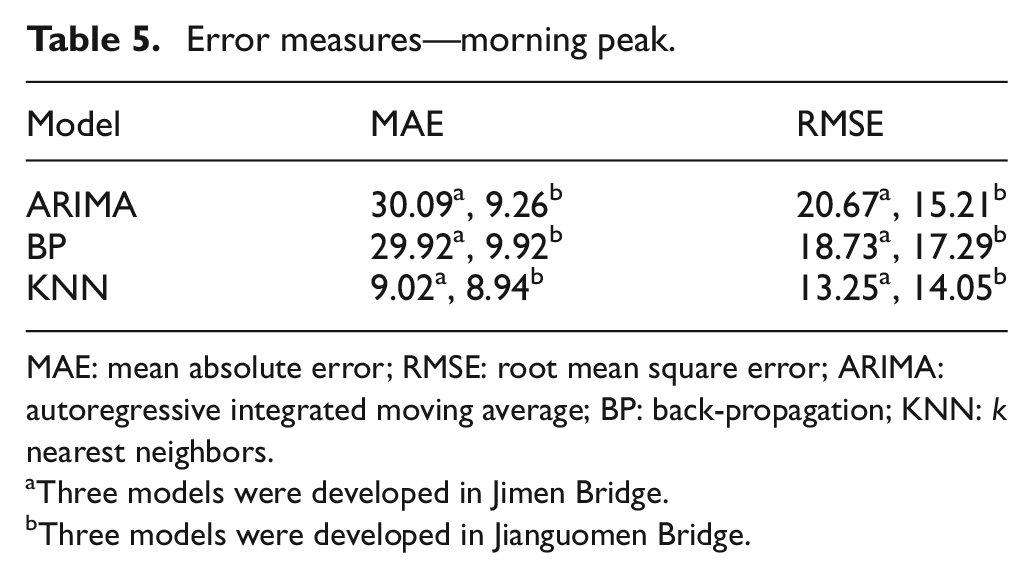
MAE: mean absolute error; RMSE: root mean square error; ARIMA: autoregressive integrated moving average; BP: back-propagation; KNN: k nearest neighbors.
Three models were developed in Jimen Bridge.
Three models were developed in Jianguomen Bridge.
Error measures—nonpeak.

MAE: mean absolute error; RMSE: root mean square error; ARIMA: autoregressive integrated moving average; BP: back-propagation; KNN: k nearest neighbors.
Three models were developed in Jimen Bridge.
Three models were developed in Jianguomen Bridge.
Error measures—evening peak.
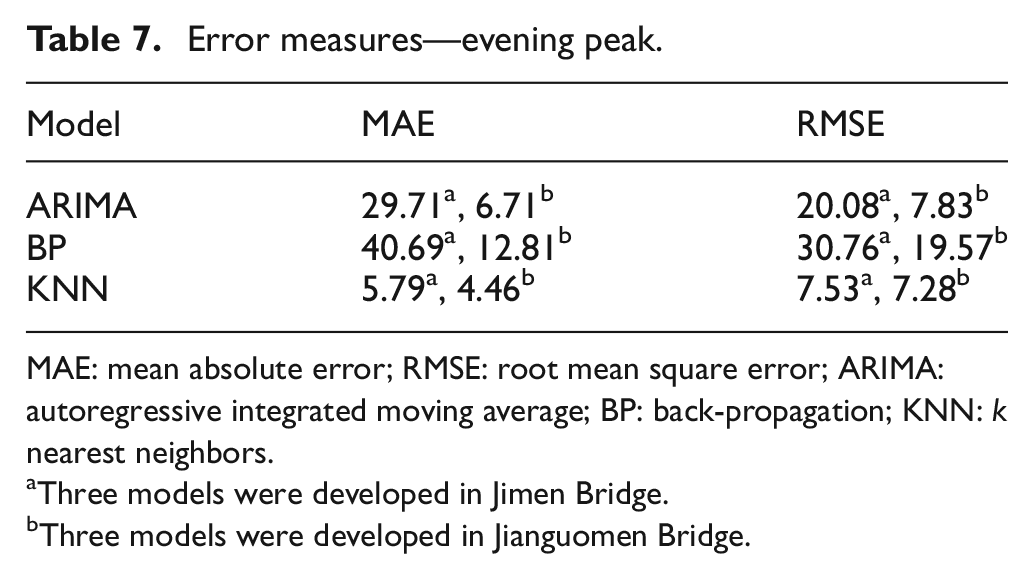
MAE: mean absolute error; RMSE: root mean square error; ARIMA: autoregressive integrated moving average; BP: back-propagation; KNN: k nearest neighbors.
Three models were developed in Jimen Bridge.
Three models were developed in Jianguomen Bridge.
As shown in Tables 5–7, the ARIMA model and the BP model experience significantly high error at Jimen Bridge. The average MAE value and RMSE value of ARIMA model on three tests is 3.97 times and 1.78 times higher than those for Jianguomen Bridge, respectively. Similarly, the BP model gives 3.38 times and 1.35 times higher error than those for Jianguomen Bridge in MAE and RMSE values. However, the errors of KNN model are comparable to that calculated at Jianguomen Bridge on three tests.
The results suggest that the ARIMA model and the BP model exhibit a poor portability, as a result of the fact that different sites have different traffic characteristics over the same data collection period. Fitting parameters and training networks need to be conducted at a new site. However, because of the capability to exploit information contained with a large set of data, in which similar states always exist, KNN model thus has the best portability.
Ease of model implementation
The ease of implementing a traffic flow forecasting model carries a significant impact in ITS. Simple operation does not require a large number of professionals to conduct models for different sites. Otherwise, if the modeling need complicated parameter definition and training process, it is likely that the model will never be generalized. This qualitative performance index has certain subjectivity (Table 8).
Implementation comparison.

ARIMA: autoregressive integrated moving average; BP: back-propagation; KNN: k nearest neighbors.
Comparative analysis
In order to describe the extent of fluctuation in the data, the CV was used, which is defined as the ratio of the standard deviation (SD) to the mean. 25 This parameter was used in place of a more traditional statistics parameter of SD because the SD of data must always be understood in the context of the mean of the data. In contrast, the actual value of the CV is independent of the unit in which the measurement has been taken, so it is a dimensionless number. For comparison between datasets with widely different means, the CV was selected to describe fluctuation of the data. The CV of actual values is shown in Table 9. Moreover, the smaller the CV, the smaller the fluctuation of data.
CV comparison.

CV: coefficient of variation.
On examining Tables 1–3, the results illustrate that KNN model outperforms the other models when the time series fluctuate considerably (morning peak and evening peak), and the performance of the three models is similar when the time series fluctuate gently (nonpeak). Similarly, Table 4 describes the distribution of error at the Jianguomen Bridge site, and the three models produce identical accuracy on nonpeak because of the lower CV.
As shown in Tables 5–7, the results clearly show that the ARIMA model and BP model are not portable. They were developed at a different site (Jimen Bridge), where the performance deteriorates in the estimation of future traffic data because of a lack of capability to capture a “universal” underlying relationship between the system’s current status and its future status. However, it is clear that for the models to be effective, they must be developed with data collected at each site where they will be used.
It is clear that the ARIMA model and BP model require extensive data calibration, but the KNN model can be employed without such overhead, and it can be implemented easily. However, the weakness of the KNN model is the complexity of the search to identify the “neighbors.” On the whole, the KNN model has the most accurate prediction results, compared to the ARIMA model and BP model.
Conclusion
This article discussed three representative short-time prediction models of the traffic speed data at 5-min interval. They are ARIMA, neutral network, and nonparametric regression. To evaluate the performance and potential for field implementation of these models, a performance index system including AE, RMSE, error distribution, and model portability is introduced. The performance of the three models is compared with real-life data in Beijing.
The results suggest that the ARIMA model, BP model, and KNN model will have the same prediction accuracy when the time series fluctuate gently. However, the KNN model seems to be more robust for extensive applications in practice.
The three models produce very similar level of error on nonpeak time. However, the KNN model experienced significantly less error than the other two models when the time series fluctuate dramatically. Moreover, the KNN model does not require parameter fitting and structure training, which makes it easier to implement.
Furthermore, the KNN model was successfully applied at multiple sites. This is demonstrated by the comparable error characteristics of the model produced in the development tests at two different sites. This advantage is most likely due to the theoretical foundation that the model can exploit information contained with a large set of data. Finally, if the time series vary gently and have a large number of professionals, the three models are all comparable. Otherwise, the KNN model is a better choice.
The results presented in this article point to the potential for further research. Because the KNN model requires more complex process to identify the “neighbors,” it is necessary to investigate suitable means to improve the search speed. Besides traffic conditions are associated with various factors, more data in terms of traffic volume and occupancy should be included to develop a multivariate nonparametric regression.
Footnotes
Academic Editor: Xiaobei Jiang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by National Basic Research Program of China (2012CB725406) and National Natural Science Foundation of China (71131001).