
Abstract
A systematic research of steady state for the dynamic job shop scheduling problem with jobs releasing continuously over time has been conducted in this article. A simulation scheduling test for the purpose of factor analysis is designed and carried out first and then another simulation scheduling test for the purposes of disciplinarian investigation is conducted. The heuristic dispatching rule algorithm is adopted in the simulation scheduling. The test data are processed and analyzed using SPSS13.0. The results indicated that the dominant factor that can characterize the shop steady state is the shop utilization level. Besides, the relationship between the number of jobs arrived at the shop and the steady state of the shop can be described by a quadratic curve preferably. Results obtained in this article make significant sense for the study of simulation scheduling of dynamic job shop scheduling problem and also for the optimum design of the shop system.
Keywords
Introduction
The job shop scheduling problem (JSP) is one of the most important problems in manufacturing informatization and automation technology, and it is also an important research topic in advanced manufacturing technology and one of the hot issues in operations research. The semantic description of classical JSP in manufacturing systems can be stated as follows: there are n different jobs waiting to be processed in a shop that includes m different machines. Each job consists of a set of operations, and the operation sequence on each machine is prespecified. Each operation is characterized by a specified machine and a fixed period of processing time. Different jobs consist of different operations and operation sequences. The objective is to find out processing sequences on each machine which can make the performance measures related to the manufacturing system achieve optimal or near optimal while satisfying the conditions mentioned above.
The JSP can be divided into static and dynamic JSPs according to the scheduling environment. The classical JSP usually consists of a series of assumptions, such as all jobs arrive at the shop simultaneously, no preemption is allowed and no machine failures occur during the processing time, and the buffer is infinite, so it belongs to the static JSP. However, the static JSP is not consistent with most of the practical scheduling problems in the manufacturing system. Therefore, many scholars and engineering researchers put forward some extensions on the basis of the classical JSP, such as taking the machine failure into account and the jobs arrived at the shop continuously instead of simultaneously, and this kind of problem is often called dynamic JSP. 1 In many practical manufacturing systems, the jobs arrived at the shop in succession. Much more is this the case in the order-oriented manufacturing system. Therefore, it is important to give consideration to the dynamic JSP. In this article, we discussed the dynamic JSP in which the jobs arrived continuously over time and explored the steady state of the shop in simulation scheduling that aims at providing the basis for the critical technical key points in solving such kind of problems.
Simulation scheduling and steady state of shop
Algorithms for solving JSP are usually divided into two broad categories: accurate algorithms and approximate algorithms. Accurate algorithms, such as mathematical programming methods 2 and branch-and-bound method,3,4 can only be used effectively in some simple and small-scale scheduling problems. Approximate algorithms include genetic algorithm, 5 ant colony algorithm, 6 particle swarm optimization algorithm,7,8 simulated annealing algorithm,9,10 tabu search algorithm, 11 other intelligent algorithms, 12 and heuristic priority rule 13 algorithms. Approximate algorithms have been widely used to solve the scheduling problems, although usually they cannot obtain the global optimal solution, but with less complexity and cost to obtain the near-optimal scheduling schemes to meet the actual requirements, they are also a hot spot in algorithm research in recent years.
Studies on JSPs in which jobs arrive at the shop continuously over time, that is, the dynamic JSP, is increasing. The effective algorithm for solving this kind of problem is the heuristic priority rules in which the selection and design are critical. Different scheduling rules lead to different scheduling schemes and directly affect the performance of the scheduling scheme. The greatest advantage of heuristic priority rules lies in its adaptation to the constructive of the dynamic job arrivals, algorithms of low complexity, and its rapid response. However, the biggest disadvantage of dispatching rule is that it depends on the characteristics of scheduling problems seriously. There is no mathematical analysis as criterion for the relationship between dispatching rules and scheduling models or scheduling objectives so far.
Blackstone et al. 14 mention that the study of job shops by analytic techniques, such as queuing theory, becomes extremely complex even for small-scale problems. Therefore, the use of simulation for analyzing this problem is unavoidable. Due to the same difficulty in examining the heuristic algorithms for solving dynamic job shop scheduling problems (DJSPs), we also rely on simulation to study the problem. The method of simulation scheduling for testing the dynamic JSP has the advantage of ease implementation and cost saving in justifying the validity of approaches. But its biggest shortcoming lies in that it does not have the universality which means that when a small change occurred in the scheduling scenario, the conclusions obtained before cannot be adapted to the new situation, so the results drawn through simulation scheduling are vulnerable to the influence of disturbance. Overall, simulation scheduling test on dynamic JSP is the most effective method, and it was widely used by scholars and researchers at home and abroad in dealing with the problem of dynamic JSP.
As a virtual test procedure, simulation scheduling includes two key segments: experimental design and the processing and analysis of the experimental results. In addition, the key points of design techniques for the simulation scheduling test include two aspects: the generation of the scheduling test data and the determination of the test parameters. In the simulation scheduling test, the main parameters are the number of simulation runs (equivalent to the number of samples), the number of jobs in each simulation (equivalent to the length of the samples), and the start sampling point.
In the simulation of JSP in which jobs arrive continuously, it is usually assumed that all machines in the shop are idle in the initial state and then jobs arrive at the shop according to a certain probability distribution of time intervals. It is clear that the shop utilization level (or shop load level) is slightly lower in the initial stage, and it will gradually rise as the jobs continuously arrive. After a certain period of time, that is, after a certain number of jobs arrived, the state of the shop tends to be dynamic steady, along with the shop utilization level and other shop indexes.
In the experimental study of simulation scheduling, sampling usually begins when the shop reaches a steady state, that is, the time the shop reaches the steady state as a starting point for sampling so as to make the experimental data statistically meaningful. In the simulation scheduling section of the literature, 15 all jobs arrived at the shop continuously, and samples were in batches which included 1000 jobs in each batch. The article pointed out that the first batch of 1000 jobs corresponding to the sampling point should be deleted, so that the start sampling point was 1001, which means that the shop reaches a steady state from the second batch. In the literature,16–19 several shop parameters (such as shop utilization level and the average flow time of job) during the scheduling process were observed to determine the time when the shop reached the steady state, and the result indicated that the shop reached steady state after 500 jobs arrived at the shop. Then, the literature 20 showed that it was after 250 jobs arrived at the shop that the shop reached steady state. The simulation scheduling in Sha et al. 21 was calculated by the unit of days in which the sampling data were from the 151th after 150 days of preheating, which means that the 150th day was regarded as the starting point of steady state. As can be seen, the findings of the literatures mentioned above were varying, and there are no detailed data and analysis to support the results. In this article, we tried to explore the time the shop reaches steady state in simulation scheduling for the purpose of solving this kind of problem more accurately and effectively in future.
Design of simulation scheduling experiment
This article studied the dynamic JSP using the priority dispatching rules. Simulation scheduling was conducted with the configuration of different shop scheduling system parameters to investigate the factors that can represent the steady state of the shop and the arrival time (or the corresponding number of jobs) the shop reaches the steady state. The literature 22 indicated that the shop utilization level, the number of operations of jobs, and their processing times would affect the performance of the shop in a certain extent, whereas other parameters such as the number of machines and the distribution of job arrival time would not.
The model framework of the dynamic JSP is as follows: there are 10 machines in the shop; jobs arrive at the shop by the time interval of exponential distribution; the number of operations of each job and the processing time of each operation is generated according to the discrete uniform distribution; the operations of the same job has precedence constraints; and the processing machine of each operation is selected randomly in 10 machines in probability way, but the processing machine for each operation is unique and the processing machine for the adjacent operation of the same job is different.
In order to study the steady state of the dynamic job shop scheduling systematically, the scheduling experiments were performed in two steps. First, different model instances were obtained by configuring different parameter sets according to the model framework. By doing so, the factors influence the steady state of the shop and its influencing degree is explored through results processing and analyzing. In addition, the main influencing factors were found out, and the exploration of their influence trends and the law were summarized.
The structure of the parameter set for the model instance is as follows

where
Let
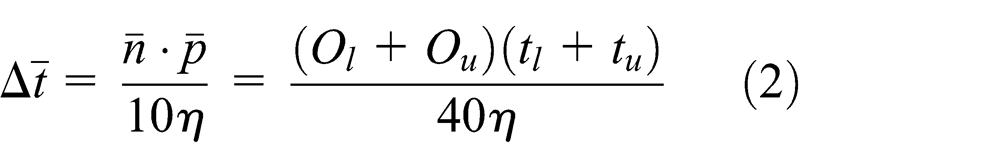
And the interval time for the continuously arrived jobs can be obtained by the following equation

where
The parameter sets for the first step of scheduling experiment are as follows

The scheduling experiment was run 10 times under each parameter set, and the samples obtained through the 10 experiments were independent and identically distributed in a sense of probability because they shared the same parameter set and model. The samples for each run were obtained in the way of point sampling mode, that is, sampling was carried out each time a job arrived at the shop. The sampling length is 2000, that is, 2000 jobs would arrive at the shop. In order to evaluate the steady state of the shop, four indicators, namely, the work in process inventory, the average flow time of the job, the average waiting time of the job, and the real-time shop utilization level, were taken as sample observations.
The design of the parameter set for the second step of the scheduling experiment is based on the results of the first step. The influencing trend and law are studied through the refinement of the parameters corresponding to the main influence factors while keeping other parameters constant.
The algorithm for the dynamic scheduling is the heuristic dispatching rule, 23 and the scheduling rule is operation due date (ODD), that is, priority is given to the operation with the smallest remained completion time.
Analysis of the simulation scheduling experiment
Results of simulation scheduling experiment
Experiment data processing
The results of the scheduling experiment can be processed according to the following procedures:
Let

For the 10 ensemble average that belong to each parameter set

Take the job arrival order i as the independent variable and the ensemble average
Results of simulation scheduling experiment
The job number–ensemble average diagram was obtained by independent development of the Java application program, according to the scheduling method in the literature. 9
Effects of shop utilization level. The simulation scheduling was performed under three parameter sets, namely,
Effects of the number of operations and operation processing time. The combination of the number of operations and processing time for the job operations can directly reflect the influence on the total processing time of jobs, so it was studied as a combination of these factors. Let both the number of operations and operation processing time change under three different shop utilization levels to obtain parameter set

Scheduling results under the parameter set of

Scheduling results under the parameter set of
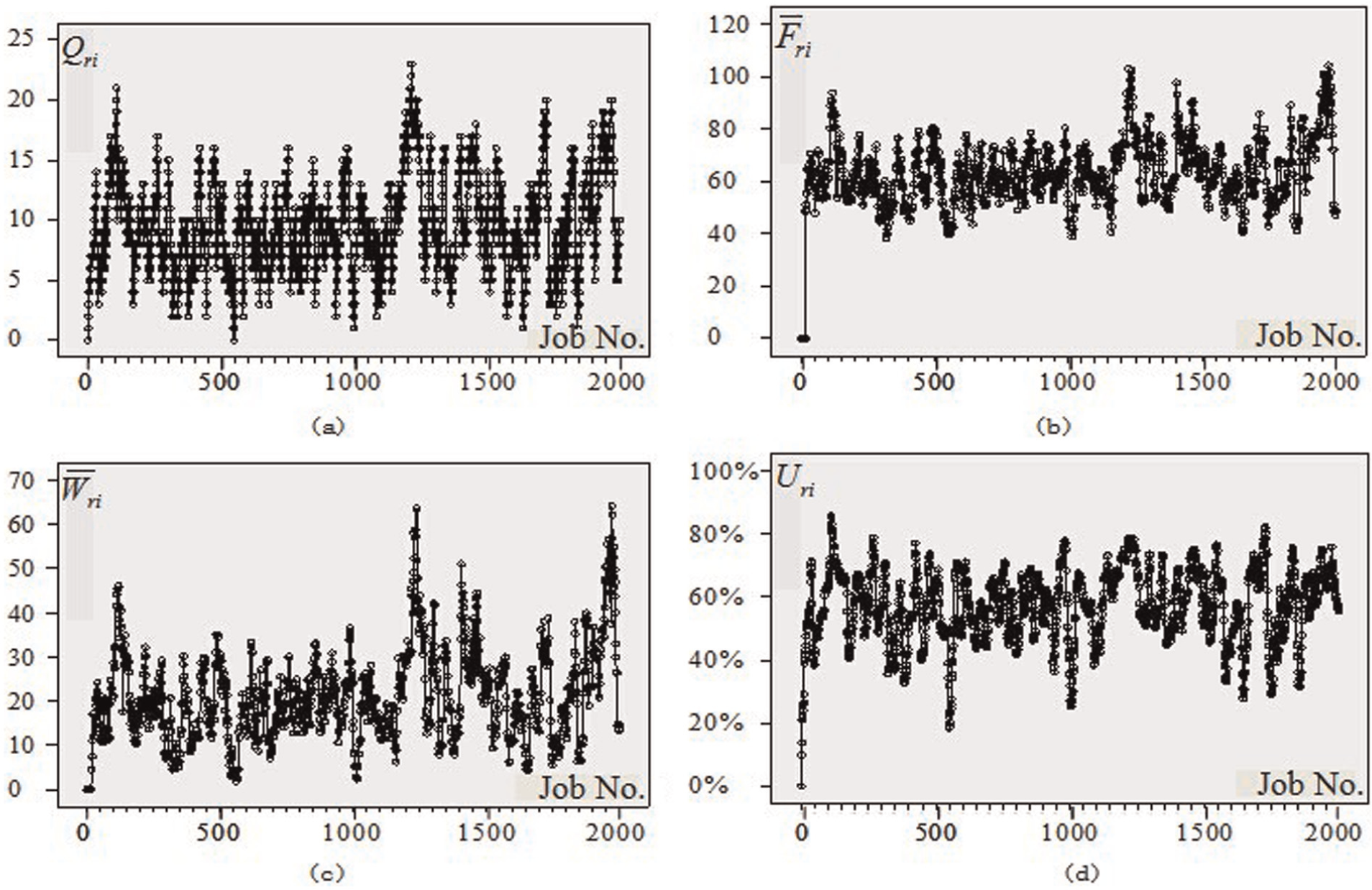
Scheduling results under the parameter set of

Scheduling results under the parameter set of
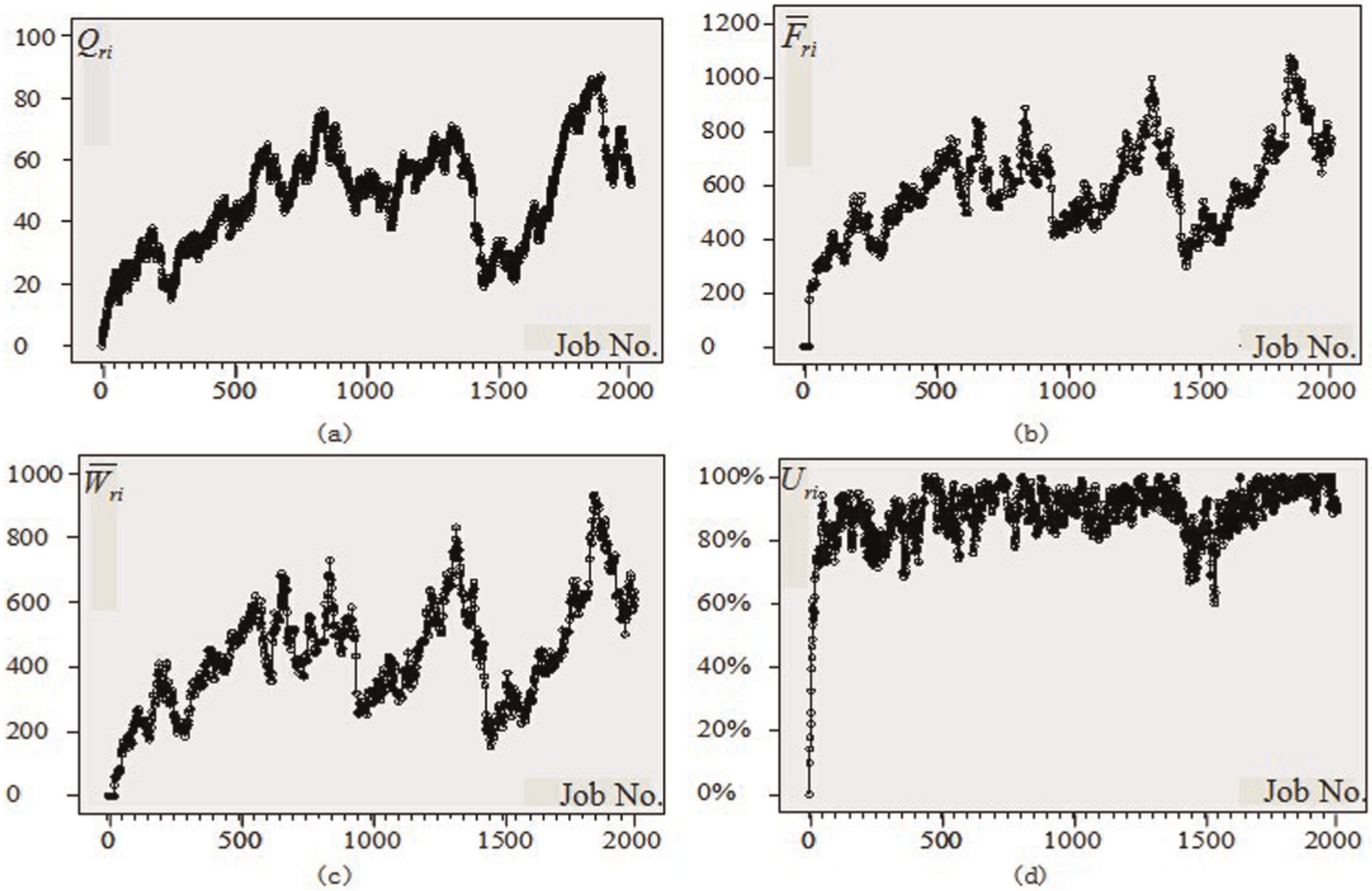
Scheduling results under the parameter set of

Scheduling results under the parameter set of
Analysis of scheduling experiment results
In Figure 1, the trend of the four indicators, namely, the work in process inventory, the average flow time of the job, the average waiting time of the job, and the real-time shop utilization level, is roughly the same for the same parameters set. The trend sharply rises in the initial phase and then becomes stable, but the stability is not so obvious because significant fluctuations exist. At the same time, the phenomenon that the real-time utilization level of the shop from initial suddenly rose to steady is very obvious. Results under other parameter sets also show the same rule.
Comparing the trend of the same indicators under parameter sets of different shop utilization level according to Figures 1–3, we can draw the conclusion that it is obvious the shop utilization level can be used as an indicator to characterize the steady state of the shop. In Figure 1, when the shop utilization level is set 95%, the shop reaches the steady state slowly, but the shop can quickly reach the steady state when setting the shop utilization level to 50% as shown in Figure 3.
Comparing Figure 1 with Figure 4, Figure 2 with Figure 5, and Figure 3 with Figure 6, we can see that the changing trends of the observation indicator are not so obvious when the number of operations of jobs and operation processing time are different while keeping the shop utilization level as the same. Thus, we can conclude that the indicator that can characterize the steady state of the shop is the shop utilization level.
Research on the influencing trend
Conclusions can be drawn from the previous section that the shop utilization level is the main indicator that can characterize the steady state of the shop. For further study on the influence trend and the rule, we refine the setting of the shop utilization level while keeping the number of job operations and operation processing time constant. The addition of the parameter sets is as follows after refinement

Taken the real-time shop utilization level as the examine indicator, simulation scheduling was carried out under six parameter sets, namely,

Real-time shop utilization level under parameter set

Real-time shop utilization level under parameter set

Real-time shop utilization level under parameter set

Real-time shop utilization level under parameter set

Real-time shop utilization level under parameter set

Real-time shop utilization level under parameter set
From Figures 7–12, we can see that when the shop utilization level decreases, the shop reaches the steady state faster, that is, the lower the shop load level, the faster the shop reaches its steady state. The relationship between the shop utilization level and the number of the jobs arrived at the shop at its steady state is shown in Table 1.
Relationship between the shop utilization level and the number of jobs arrived at the shop at its steady state.

According to the data in Table 1, curve estimation is conducted for the preselected linear (Linear), the logarithmic curve (Logarithmic), quadratic curve (Quadratic), cubic curve (Cubic), and compound curve (Compound). The fitting results are shown in Table 2.
Fitting results of the curve.

Conclusions can be drawn from Table 2; the R2 determination coefficients of the quadratic curve and cubic curve were the maximum. Among them, the corresponding value of the quadratic curve was larger which demonstrates that its fitting degree was the best. Then, from the significant degree, the fact that the corresponding value of the quadratic curve was smaller than the cubic’s indicated that the parameter estimation of the quadratic curve was more significant. Therefore, the quadratic curve was selected to express the relationship between the setting of the shop utilization level and the number of the jobs arrived at the shop at its steady state
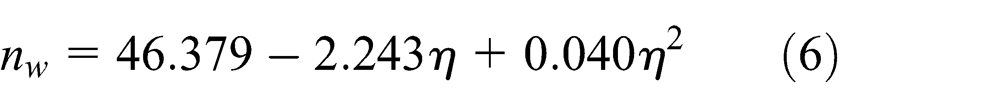
where
Conclusions can also be drawn from Figures 7–12, that is, the higher the value of the shop utilization level, the greater the stability under the steady state. And with the decrease in the shop utilization level, the volatility of the shop in steady state increases.
Conclusion and discussion
Conclusion
Simulation scheduling is the main method in studying the dynamic JSP, so data sampling is an important part as a simulation random test. In order to ensure the statistical significance of the data sampling, the start point of sampling (i.e. the number of the jobs arrived at the shop at its steady state) is one of the important factors to consider. From the simulation scheduling and data processing results above, some conclusions can be drawn from it:
Many literatures15,17 assumed that the number of jobs was 500 when the shop reached its steady state in simulation scheduling, but the systematic simulation scheduling experiments indicated that the number of jobs and the time the shop reaches its steady state were different under different shop parameter sets. However, 500 jobs were large enough to ensure that the shop had already reached its steady state.
When the simulation scheduling was conducted under the same parameter set, the trend of the four indicators, namely, the work in process inventory, the average flow time of the job, the average waiting time of the job, and the real-time shop utilization level, was roughly the same. Among the three parameter sets of the shop utilization level, the number of operations, and the processing time, the influence of the shop utilization level is the most obvious, so it is the main indicator that can characterize the steady state of the shop.
Through curve estimation, the relationship between the shop utilization level and the number of jobs arrived at the shop is quadratic curve. According to the corresponding equation, the number of jobs and the time the shop reaches its steady state under different shop utilization levels can be calculated.
Analysis and discussion
From the standpoint of theoretical study’s significance, the results of the study in this article can provide a theoretical basis for the simulation scheduling of dynamic JSP and avoid blindness in data sampling so as to ensure the rationality of the simulation scheduling results.
In engineering practice, the simulation model of the shop system can be built first among the three cases including the design of the shop system, the matching of optimization resource, and the evaluation of the shop performance. The process and method of simulation scheduling in this article can provide an important and a rational theoretical basis for the building of the simulation model.
The study of the last section in this article aims at the indicator of the real-time shop utilization level. In the research of the classical dynamic job shop scheduling, the indicators that need to optimize usually are the average flow time, the maximum flow time, and other due date–related indicators. The study of the steady state under these indicators can be investigated using the same method and procedures described in this article.
Footnotes
Acknowledgements
The authors would like to express their gratitude to the anonymous reviewers, whose discussion with them was advantageous to improve the quality of this article.
Academic Editor: Duc T Pham
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research was supported by the National Natural Science Foundation of China under grant no. 71271160 and also by Research Foundation of Education Bureau of Hubei Province (China) under grant no. D20121102.