
Abstract
The detection of metal surface defects is crucial in the field of industrial production. However, in practical applications, challenges such as ambiguous defect directions, large scale differences, and strong background interference are often encountered. This paper proposes an improved multi-scale fine-grained object detection framework based on YOLOv11, referred to as “DA-YOLO.” Firstly, the 3D attention module (3DAM) was used to enhance the model’s ability to model spatial direction features and improve the model’s ability to perceive fine-grained structures. Secondly, a feature enhancement module (AMFEM) employing multi-scale convolution and a spatial-channel attention mechanism was constructed, significantly boosting the model’s recognition accuracy for multi-scale targets and blurry boundary defects. Furthermore, an intersection and union ratio Aware Joint Loss function (IoU-Aware joint loss, IAJ-Loss) was proposed and designed, which further enhanced the quality perception ability and stability of the model in complex detection scenarios. The experimental results show that the DA-YOLO model improved mAP@0.5 by 5.42% and 4.05% respectively on the GC10-DET and NEU-DET datasets compared to the baseline YOLOv11 model, demonstrating superior defect detection performance.
Introduction
Steel surface defect detection is crucial for shipbuilding quality. Defects including cracks, pores, inclusions, scratches, and indentations1–3 arising throughout production and processing compromise hull integrity and pose risks to structural safety and service life.
Early steel defect detection relied on manual visual inspection, which fails to meet industrial demands. While techniques like infrared and eddy current detection 4 excel in specific scenarios, they struggle to balance accuracy, stability, and real-time performance. Recent automated systems using neural networks, 5 Bayesian networks, 6 and support vector machines 7 demonstrate strong capabilities in end-to-end learning and complex feature representation.
Deep learning-based object detection comprises two mainstream approaches. Two-stage methods like Mask R-CNN 8 and Faster R-CNN, 9 Faster R-CNN first generate region proposals then perform classification and regression. In contrast, single-stage frameworks including SSD 10 and YOLO 11 achieve end-to-end recognition directly. The YOLO series excels in speed and accuracy, making it particularly suitable for metal surface defect detection, with advancements in YOLOv3, YOLOv7, and YOLOv10 providing key insights into multi-scale feature extraction and real-time performance.12–17 Recent variants include ST-YOLO 18 with sample screening strategy, EML-YOLO 19 featuring large-kernel and multi-branch fusion, and SDMS-YOLOv10 20 incorporating dynamic backbone and redesigned detection head. Despite progress, challenges remain in detection efficiency and dense defect performance.
Unlike routine detection tasks, steel surface defects exhibit distinctive characteristics including small size, irregular shape, blurred boundaries, 21 and sensitivity to background noise, significantly increasing detection difficulty. This paper proposes DA-YOLO, a novel extension to the YOLOv11 architecture that introduces two new modules: 3DAM and AMFEM. These modules address the limitations of YOLOv11 in detecting directional features and small-scale defects. 3DAM enhances directional feature modeling, while AMFEM improves multi-scale detection, especially in complex environments with blurred boundaries. The main contributions are:
The YOLOv11 backbone incorporates a 3D Attention Module (3DAM) that integrates horizontal, vertical, and channel-wise attention with multi-pooling feature statistics. This significantly improves the detection of directional defects, such as slender cracks and fine scratches.
This paper proposes an Attention-Guided Multi-Scale Feature Enhancement Module (AMFEM) that integrates multi-scale convolution, spatial-channel attention, and group gating mechanisms. AMFEM improves multi-scale defect detection while suppressing background interference, particularly enhancing accuracy for small notches with blurred edges.
An IoU-Aware joint loss (IAJ-LOSS), integrating BCE-IoU and Focal EIoU, is proposed to coordinate classification and regression branches, significantly improving the detection of challenging targets such as small defects and elongated cracks.
Evaluations on the GC10-DET and NEU-DET datasets demonstrate DA-YOLO’s effectiveness, achieving mAP@0.5 improvements of 5.42% and 4.05% over YOLOv11, respectively. This significantly enhances detection performance and demonstrates the practical application potential of DA-YOLO in steel defect inspection.
Related work
Accuracy and real-time performance are two important metrics for evaluating steel surface defect detection algorithms. In recent years, object detection technology has continuously developed, from the original two-stage detection methods to single-stage detection methods with simpler structures and higher efficiency. 22 Classic one-stage detection networks include the YOLO series,23–29 SSD series, 19 RetinaNet, 30 etc. To meet the demands of more rigorous industrial production, researchers have been exploring detection algorithms that can achieve both faster detection speeds and higher defect detection accuracy. Most of the improvements are based on the one-stage detection framework of YOLO series algorithms.
Steel surface defect detection is a small-target detection task with a complex background. Wang et al. improved a fatigue detection model based on YOLOv7 and enhanced the model’s ability to recognize key features 31 by introducing a coordinated attention mechanism. Su et al. 32 designed a new convolution-ModSConv, which effectively improves the performance of ordinary convolution in cross-channel feature interaction. Wang et al., 33 Li et al., 34 , 35 and Zhang et al. 36 all modify the base YOLO model with the goal of primarily improving the model’s ability to detect small objects.
YOLOv11, the 11th generation of the YOLO series, first proposed in 2016, was developed by Ultralytics based on YOLOv8.37,38 Its architecture (Figure 1, left) features a convolutional backbone that extracts multi-level features through progressive subsampling. The model introduces key enhancements: C3K2 improves feature extraction efficiency, SPPF enhances multi-scale context modeling, and C2PSA focuses on key regions to boost detection robustness.

Comparison between the baseline YOLOv11 and the proposed DA-YOLO framework. Newly introduced modules (3DAM and AMFEM) are highlighted with colored blocks and star markers. 3DAM improves directional feature modeling, while AMFEM enhances multi-scale defect detection in complex backgrounds.
In the neck network, YOLOv11 employs feature fusion to integrate multi-scale features from shallow and deep layers, improving detection across object sizes. It utilizes multiple C3K2 modules to efficiently extract and fuse semantic information at different levels. The detection head handles classification and bounding box regression, incorporating depthwise separable convolutions (DWConvs) to enhance class discrimination.
Although there have been a large number of research results based on YOLO defect detection model, for steel surface defects with various and complex shapes, the existing detection methods are still not enough to meet the requirements of industrial inspection in terms of accuracy and stability. With its efficient backbone network design, multi-scale fusion mechanism and excellent module scalability, YOLOv11 provides an ideal baseline for introducing attention mechanisms, multi-scale enhancement structures, and improved loss functions.
To this end, this paper improves the YOLOv11m model framework and propose a new defect detection model DA-YOLO, whose network structure is shown on the right of Figure 1. Through the module-level enhancement and improvement of the loss function, the model achieves stronger feature modeling and detection capabilities. The specific structure will be introduced in the third section.
Method
Overall network architecture
To address key challenges in metal defect detection—including ambiguous orientations, significant scale variations, blurred edges, and background interference—this paper systematically enhances YOLOv11 at both architectural and loss function levels, proposing DA-YOLO with strengthened fine-grained perception.
The framework introduces 3DAM to enhance directional perception and AMFEM to improve multi-scale feature representation in complex backgrounds. An IoU-Aware joint loss optimizes classification-regression consistency, collectively boosting accuracy on complex defects. Experiments confirm DA-YOLO’s superior robustness and stability in detecting small targets, slender cracks, and high-noise scenes, demonstrating strong industrial application potential. For clarity of notation, a comprehensive list of symbols and their definitions is provided in Appendix “Nomenclature.”
Three-dimensional attention module
Unlike the conventional convolutions used in YOLOv11, which struggle with detecting directional features, 3DAM introduces a novel approach by integrating three distinct attention mechanisms (horizontal, vertical, and channel-wise) to enhance directional feature modeling. This allows the model to effectively detect slender defects such as cracks and scratches, which are often overlooked by YOLOv11 due to its limited ability to capture fine-grained directional dependencies.
The decoupled attention mechanism, comprising three parallel branches for H, W, and C dimensions, is motivated as follows:
Separation of Spatial and Channel Dependencies: Explicitly decoupling spatial (H, W) and channel (C) dependencies allows the model to independently capture location-specific patterns (e.g. defect regions) and channel-wise attributes (e.g. texture, color). This enhances flexibility in handling defects with complex spatial layouts or diverse channel characteristics.
Dimensional Attention: The tri-branch design enables the model to assign distinct weights to horizontal, vertical, and channel dependencies, improving its focus on directional features critical for defect detection across diverse materials.
Empirical Validation: Comparative experiments demonstrate that the proposed decoupled attention mechanism (3DAM) outperforms its single combined counterpart, achieving higher mAP50 and mAP50-95 scores—particularly on defects characterized by complex spatial structures or channel-dependent features. Detailed results are presented in the Experimental Results section.
In summary, 3DAM enhances directional feature modeling and is well-suited for metal surface defect detection, where spatial and channel dependencies are best addressed separately.
Figure 2 depicts the overall structure of the 3DAM module.
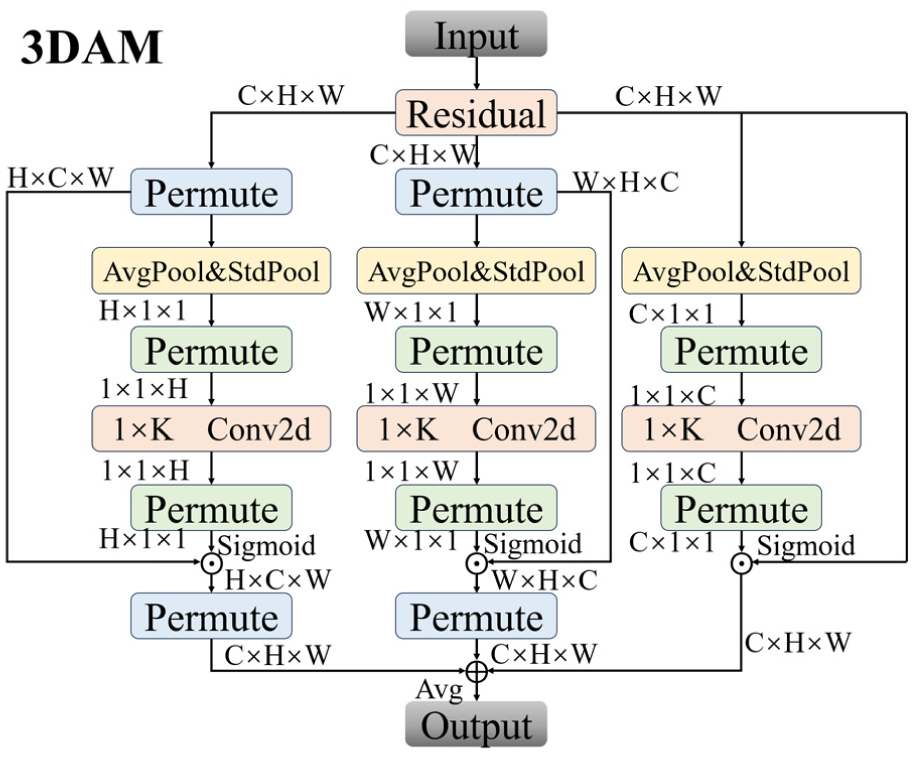
3DAM module structure diagram.
Directional attention includes the following contents:
1.Rearrange the input features
To handle the H, W, and C dimensions respectively, the input feature X needs to rearrange the tensor dimensions through the Permute operation. Take extracting the attention in the H direction as an example. The original feature needs to be transformed into:

2. Multi-pooling compression
For the features of each dimension, average pooling (AvgPool) and standard difference pooling (StdPool) are respectively adopted for statistical compression to extract the global structural features. Take the horizontal dimension as an example:

Similarly, the processing methods for the vertical dimension
3. Directional convolution generates an attention map
A

Where
4. Attention weighting and fusion
Apply the attention maps in each direction to the original feature maps respectively (through the broadcasting mechanism) and fuse them proportionally. The fusion weights of the three attention branches are controlled by the learnable parameter vector

The final fused attention feature is:

Where ⊗ represents broadcast multiplication.
5. Residual connection output
To preserve the original features and suppress the overfitting of attention to the shallow expression, the final output adopts the form of residual connection:

Here
By incorporating tri-directional spatial attention, 3DAM enhances structural feature modeling and improves representation of directional patterns.
Attention-guided multi-scale feature enhancement module
Metal surface defects present significant scale variations, from tiny scratches to large corrosion areas, posing challenges for consistent feature representation.
AMFEM is introduced to address the challenges of multi-scale detection and small defect recognition, which YOLOv11 struggles to handle due to its limited multi-scale fusion capabilities. By integrating multi-scale convolutions and spatial-channel attention, AMFEM improves the model’s ability to detect small defects with blurred boundaries, such as corrosion or scratches, in complex industrial environments. This enhancement makes DA-YOLO more robust to background noise and more accurate in detecting fine-grained defects. Positioned between SPPF and C2PSA, AMFEM participates in upsampling and cross-layer fusion of mid-to-high-level features (Figure 3). The EUCB module upsamples feature maps for fusion with prior-level MFEM features, while the LGAG module gates salient regions to recover fine spatial structures and strengthen inter-layer semantic associations.

AMFEM module structure diagram.
AMFEM comprises three sub-modules (Figure 3): MFEM for channel-spatial attention and multi-scale context fusion to improve fine-grained target detection, EUCB for semantic-preserving upsampling, and LGAG for salient region enhancement via dynamic gating. MFEM sequentially integrates CAB (channel attention), SAB (spatial attention), and MSCB (multi-scale context extraction) to boost feature discriminability.
1. Channel Attention Block (CAB)
CAB guides the model to highlight semantically relevant channel responses by modeling the importance of global semantic channels. Given the input feature map


Both vectors are mapped through shared two convolutional layers (including nonlinear ReLU activations):


The attention map is passed through the Sigmoid activation function imposed after fusion:

The final channel weighted output is:
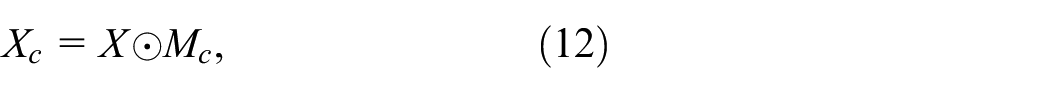
Where ⊙ stands for element-by-channel multiplication.
2. Spatial Attention Block(SAB)
SAB avoids localization offset caused by complex background by guiding the model to focus on the target area. The input feature

The spatial attention map is then generated after 7 × 7 convolution with Sigmoid activation:
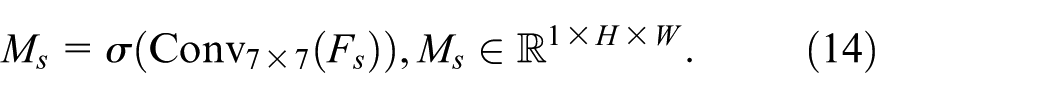
The final feature map is updated as follows:

3. Multi-Scale Convolution Block (MSCB)
MSCB extracts scale-invariant features to alleviate the perception bias of the model for small objects or large-size objects. The channels are first compressed using 1 × 1 convolutions:

Then it is fed into the multi-scale branch convolution path:

Finally, the multi-scale context was fused by BN and channel shuffling operation, and the highly expressive features
4. Efficient Up-convolution Block (EUCB)
EUCB is designed as a lightweight and semantically sensitive upsampling architecture. Firstly, it uses bilinear interpolation to upsample the feature map to the target resolution, and then performs depthwise separable directional convolution:

Normalization is then performed with nonlinearity:

Finally, the channels are compressed and fused:

The whole structure has the characteristics of few parameters, large receptive field and high localization accuracy.
5. Large Kernel Group Attention Gating Modul(LGAG)
To dynamically adjust the information fusion strategy during the upsampling process, we use the LGAG module to construct the attention gated channel. Given the main feature map x and guide feature map g, it is first processed by large kernel group convolution:


After fusion, BN, ReLU, and Sigmoid are applied:
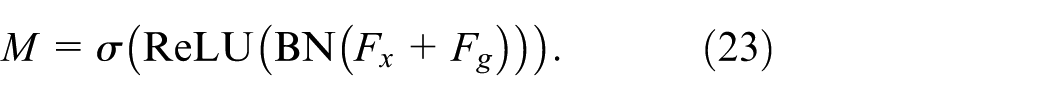
The output gating feature is as follows:
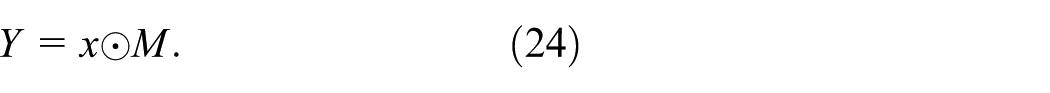
LGAG guides cross-level semantic fusion through structural information, significantly suppresses the invalid region response, and improves the attention ability of key defects.
The AMFEM module is embedded at each resolution level during feature decoding, forming a closed-loop enhancement mechanism with semantic guidance and hierarchical feedback. The specific feature enhancement process follows:
For the input feature map
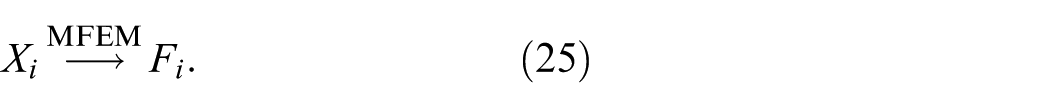
Then, the EUCB module is used to upsample


Finally,

This design maintains semantic consistency during hierarchical feature transfer.
Loss function
In object detection, classification confidence and localization quality are often decoupled, which may degrade performance on hard samples. While YOLOv11 employs BCE and CIoU losses, two limitations persist: (1) classification confidence fails to reflect localization quality due to task decoupling; (2) regression loss inadequately addresses hard samples like small or slender defects. To address these, we propose an IoU-Aware joint loss with dual-branch optimization: the classification branch uses IA-BCE Loss 39 to align confidence with box quality, while the regression branch adopts Focal-EIoU to emphasize low-quality examples. This structure enhances quality awareness and stability in complex detection scenarios without increasing architectural complexity.
Traditional BCE loss employs hard labels (0/1), ignoring localization quality differences between predicted and ground-truth boxes. This often causes high-confidence false detections with poor box quality, especially for small or dense defects. To address this, we introduce an IoU-Aware label
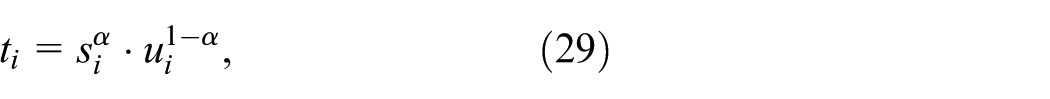
Here,

Among them, soft label
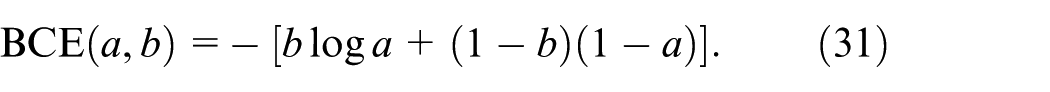
In order to further suppress the influence of low-quality positive samples, this paper introduces a decaying weight mechanism based on IoU ranking. Let the IoU rank of the ith prediction box within its true box matching group be

Here
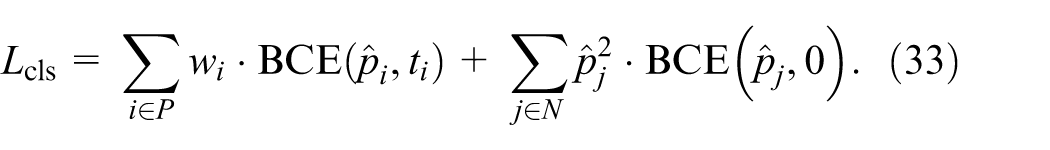
This design can significantly suppress the influence of low-quality positive samples and improve the consistency between the classification output of the model and the actual positioning quality.
YOLOv11 employs CIoU loss to measure IoU overlap, center offset, and aspect ratio difference. However, its weak gradient distribution for slender defects—particularly in low-IoU regions with sparse learning signals—often causes regression failure on hard examples. Therefore, this paper adopts Focal-EIoU loss, which incorporates a modulation factor

Here, the EIoU loss is as follows:

Here,
Finally, the training objective function of DA-YOLO is defined as:

In the experiments of this paper,
The proposed loss function introduces quality-aware classification supervision and hard-sample-focused regression, effectively bridging the gap between classification and regression tasks. This improves alignment between classification confidence and localization quality.
The results shown in the Appendix “Parameter Sensitivity Analysis” demonstrate that
Experiment
Environment and parameters
Experiments used: NVIDIA RTX 3090, CUDA 11.8, PyTorch 2.0.1, and Python 3.10. This paper employs SGD optimizer with Cosine Annealing scheduler SGD optimizer with Cosine Annealing scheduler (initial LR
Dataset
To evaluate DA-YOLO’s performance in metal defect detection, this paper uses two public industrial datasets: GC10-DET 40 and NEU-DET. 41 Both are widely adopted in industrial vision and cover diverse, challenging steel defects with strong practical relevance.
GC10-DET contains 6380 RGB images (640 × 640) with 10 defect types including cracks, scratches, and peeling. Images may contain multiple defects with imbalanced class distribution.
NEU-DET includes 1800 grayscale images of hot-rolled steel strips, featuring six defect types (roll dirt, faceting, cracks, etc.). Each class has 300 images, originally 200 × 200 and resized to 640 × 640. Its small, blurry targets effectively test small-defect detection capability.
All datasets are split 8:1:1 into training, validation, and test sets for model training, hyperparameter tuning, and evaluation.
Evaluation metrics
The main evaluation indicators included:
1. Mean Average Precision (mAP)
We use mAP@0.5 and mAP@0.5:0.95 as core metrics. mAP@0.5 measures detection accuracy at IoU threshold 0.5, while mAP@0.5:0.95 averages AP across IoU thresholds from 0.5 to 0.95 (step 0.05). Together they comprehensively evaluate model performance under varying matching strictness.
2. Precision and Recall
Precision is the fraction of samples predicted as positive by the model that are actually positive, and it measures the rate of false positives of the model. Recall is the fraction of all positive samples that the model successfully detects, and it measures the ability of the model to miss detections. They are defined as follows:


Here, TP represents the number of predictions positive and true positive, FP represents the number of predictions positive but true negative, and FN represents the number of predictions negative but true positive.
3. Frames Per Second (FPS)
FPS measures how many frames the model can process per second, reflecting its real-time performance, crucial for fast decision-making in industrial applications.
4. Computational Complexity (FLOPs)
FLOPs quantify the computational cost per image, indicating the number of floating-point operations required. This metric is key for assessing model efficiency and deployment feasibility, especially on resource-constrained hardware.
Ablation experiment
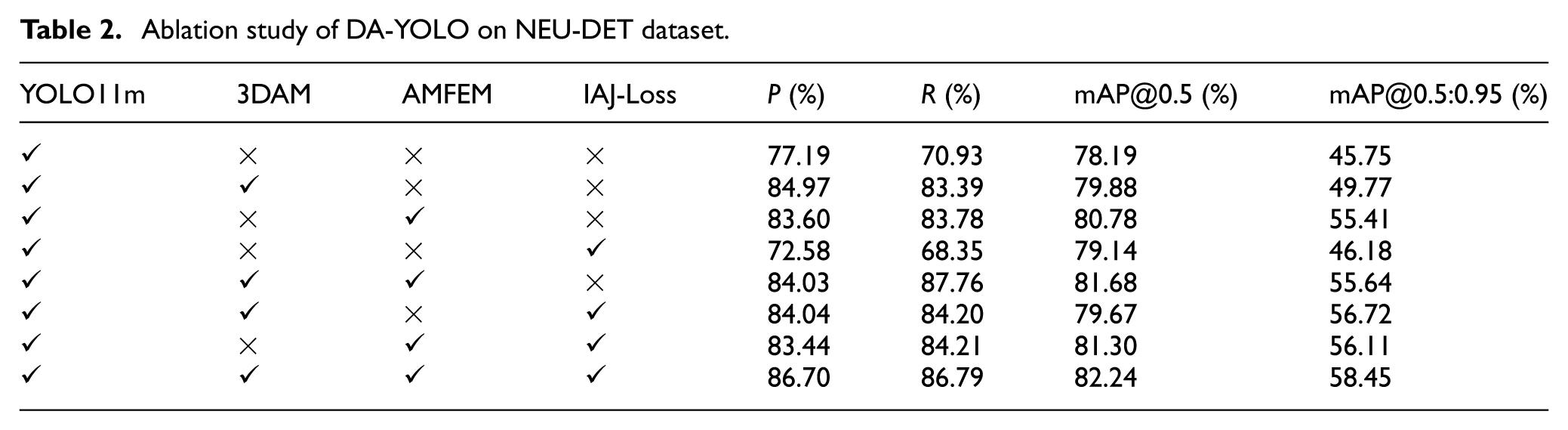
This paper performs ablation studies on GC10-DET and NEU-DET to evaluate individual contributions of DA-YOLO’s key modules. Using YOLOv11m as baseline, we progressively add 3DAM, AMFEM, and IAJ-Loss, with results shown in Tables 1 and 2.
Ablation study of DA-YOLO on GC10-DET dataset.

Ablation study of DA-YOLO on NEU-DET dataset.
As shown in Table 1, 3DAM boosts accuracy and mAP by +2.38% mAP@0.5, demonstrating its structural adaptability to diverse targets. AMFEM improves recall and overall accuracy, particularly for small and blurry defects. IAJ-Loss enhances classification-regression consistency, raising mAP@0.5 to 77.83%—outperforming the baseline individually. The full combination achieves the best performance with a 5.42% mAP@0.5 gain, confirming module complementarity.
Table 2 shows consistent improvements on small grayscale images, with AMFEM + IAJ-Loss achieving the highest gain (+3.1% mAP@0.5), confirming its efficacy for small defect recognition. The full combination yields the best performance (+4.05% mAP@0.5), demonstrating strong versatility and robustness.
Across both datasets, 3DAM, AMFEM, and IAJ-Loss enhance structural modeling, multi-scale fusion, and loss alignment respectively. Each module contributes stable gains individually while showing complementary effects when combined, forming a structural foundation for high-accuracy, robust metal defect detection in DA-YOLO.
Contrast test
Figure 4 compares DA-YOLO with YOLOv11m on both datasets: the top two groups show GC10-DET results, the bottom two NEU-DET. DA-YOLO improves all metrics across both datasets.

Comparison on the GC10-DET dataset and NEU-DET dataset.
Through comparative experiments with the most advanced defect detection algorithms on the GC10-DET and NEU-DET datasets, the performance of the DA-YOLO model is more comprehensively verified. These models include Faster-RCNN, 42 TOOD, 43 YOLOX, 44 RDN, 45 CenterNet, 46 DCAM-NET, 47 ADE-YOLO, 48 PCP-YOLO, 49 and various YOLO modules. 50
Tables 3 and 4 compare DA-YOLO with recent detection methods on GC10-DET and NEU-DET, showing it achieves state-of-the-art results on both datasets.
Main metric comparison on the GC10-DET dataset.

Main metric comparison on the NEU-DET dataset.
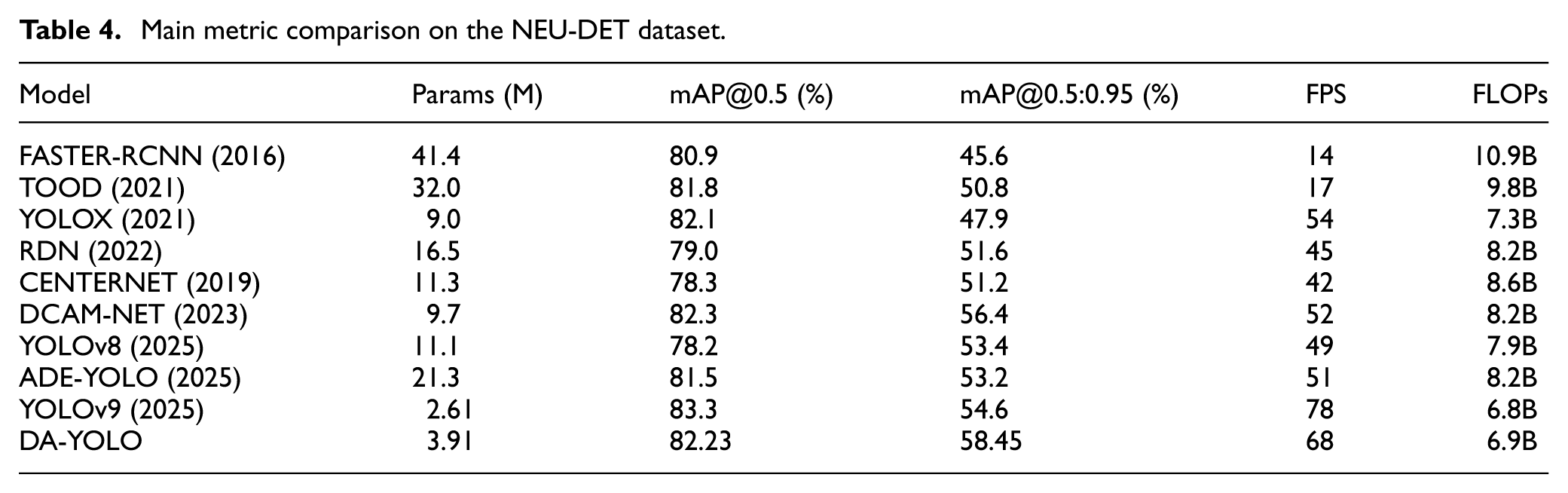
These comparisons demonstrate DA-YOLO’s effectiveness for industrial metal defect detection. It significantly outperforms YOLOv11m in convergence speed, accuracy, and stability, while also achieving leading performance among mainstream methods, exhibiting stronger generalization and robustness.
Visualization
To visually demonstrate DA-YOLO’s detection performance, we select representative samples from both GC10-DET and NEU-DET datasets for analysis, with results shown in Figure 5.

Visualization of DA-YOLO detection results on GC10-DET dataset and NEU-DET dataset.
Visualizations on both datasets demonstrate DA-YOLO’s accurate localization of diverse steel defects. It maintains stable detection under challenging industrial conditions, confirming its superiority and practical applicability in real manufacturing environments.
Analysis of deployment feasibility
To further address the industrial applicability of DA-YOLO, we analyze its deployment feasibility on resource-constrained edge devices. As shown in Tables 3 and 4, DA-YOLO achieves 70 FPS on GC10-DET and 68 FPS on NEU-DET, surpassing the typical industrial requirement of 30 FPS. The model’s memory footprint is 15 MB in FP32, reduced to under 5 MB when quantized to INT8, making it suitable for low-power devices like NVIDIA Jetson Nano. With 6.9B FLOPs, DA-YOLO balances high accuracy and efficient deployment, making it ideal for real-time industrial defect inspection.
Discussion and conclusion
This paper proposes DA-YOLO, an enhanced YOLOv11 framework that incorporates two novel modules: 3DAM and AMFEM. These modules improve the model’s ability to detect small defects, slender cracks, and blurred boundary defects in industrial environments. 3DAM enhances directional perception, while AMFEM improves multi-scale feature representation, allowing DA-YOLO to outperform YOLOv11 in challenging detection scenarios. This method not only enhances the spatial feature perception ability of the model, but also improves the detection ability of the model for objects of different scales.
The experimental results on GC10-DET and NEU-DET datasets show that the proposed model has good detection results, especially in identifying small targets and weak contrast defects. However, we recognize that both datasets exhibit class imbalance, with certain defect types having significantly fewer samples. This imbalance could affect the model’s performance, particularly for rare or small defects.
To address this, we plan to incorporate Conditional GANs to generate synthetic data for underrepresented defect types and Transfer Learning to improve the model’s generalization on small sample datasets. 51 These strategies have demonstrated significant success in similar tasks and are expected to greatly mitigate the impact of class imbalance.
In the future, our research will further make the model design more lightweight to improve the real-time performance of the model in industrial use scenarios, and incorporate multimodal information to improve the adaptability of the model in complex detection situations. Additionally, we will test the model on a broader variety of datasets, including those with different defect types and materials, to validate DA-YOLO’s generalization capability across various industries.
Footnotes
Appendix
Acknowledgements
The authors are deeply grateful to the editor and referees for their careful review and valuable suggestions, which have significantly contributed to enhancing the overall quality of the paper.
Handling Editor: Aarthy Esakkiappan
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.