
Abstract
With increasing competition in the fast-moving consumer goods industry, cigarette manufacturers face challenges such as multiple product types, small batch sizes, and rapid delivery. Traditional scheduling relies on human experience, struggling to handle complex constraints dynamically, leading to resource waste and low efficiency. This paper proposes an intelligent scheduling method that integrates knowledge graphs with an improved Non-dominated Sorting Genetic Algorithm II (NSGA-II). By constructing two-layer knowledge graphs for monthly planning and cigarette packaging machines, implicit knowledge is made explicit. A scheduling optimization algorithm based on heuristic rules and non-dominated sorting is presented. The model considers equipment capacity, changeover time, production continuity, and inventory levels, forming a multi-objective, multi-constraint optimization problem. To address NSGA-II’s slow convergence and limited population diversity, a two-level chromosome encoding and adaptive mutation strategy are introduced, enhancing Pareto front exploration. Experiments based on real production data from ZCT show the method reduces monthly finished goods inventory by 16.23%, increases equipment utilization by 11.4%, and decreases manual intervention. The study provides theoretical and practical support for intelligent manufacturing transformation in the cigarette industry and offers a generalizable methodology for process industry scheduling optimization.
Keywords
Introduction
Research background and challenges
As competition within the global fast-moving consumer goods market intensifies, the tobacco industry—a key component of this sector—is undergoing profound transformation driven by consumer demand. 1 The market is shifting from traditional mass-production and standardization toward a new normal characterized by personalization and diversity: ‘multiple varieties, small batches, and rapid delivery’. This transition not only imposes unprecedented demands on production planning flexibility but also places significant strain on conventional production scheduling systems.2,3
Traditional production scheduling methods rely heavily on manual expertise, often proving inadequate when confronted with complex dynamic constraints such as fluctuations in raw material supply, real-time changes in equipment status, and the insertion of urgent orders. The shortcomings of this approach are increasingly apparent: firstly, scheduling efficiency is low, as manual decision-making struggles to process vast volumes of production data and constraints within short timeframes; secondly, resource wastage is severe, with ill-conceived production schedules frequently leading to equipment idling or overloading, while also increasing unnecessary changeover costs; Finally, delivery cycles lengthen, hindering rapid market responsiveness and eroding core competitiveness. 4
Take our collaborative partner, China Tobacco Central, as a case in point. Its production scheduling challenges are particularly illustrative. Historically, the enterprise relied on high inventory levels to buffer against market demand uncertainty. However, in recent years, adjustments to national industrial policies have prompted a fundamental shift in the company’s inventory strategy, resulting in a precipitous decline in finished goods inventory, which now stands at less than 100,000 cases. This strategic realignment has fundamentally altered the boundary conditions for production operations, triggering a series of chain reactions: under the ‘low inventory’ operating model, the production system demands exceptional precision and responsiveness in scheduling, with any scheduling error potentially leading directly to order delays; To meet diverse short-cycle demands, ‘order splitting’ production has become necessary. This has dramatically increased equipment changeover (plate change) frequency, significantly raising downtime and energy costs while severely compromising overall production stability and economic efficiency.
Core issues and research gaps
A thorough analysis reveals that the current scheduling model faces fundamental challenges, rooted in the heavy reliance of high-quality scheduling decisions upon the tacit knowledge of a small number of experts. This invaluable expertise represents the crystallization of wisdom accumulated through years of practical experience. However, it typically exists in the form of natural language within the experts’ minds or scattered across fragmented working documents. This constitutes the core bottleneck in the ongoing intelligent transformation, manifesting in three primary difficulties:
(1) Difficulty in knowledge consolidation and succession: Experts’ tacit knowledge exhibits highly personalized and contextual characteristics, rendering it challenging to effectively record and manage through traditional IT systems. With the retirement or reassignment of senior scheduling personnel, these valuable knowledge assets face significant risks of loss, undermining the quality and stability of scheduling decisions. 5
(2) Difficulty in quantifying and computationalising knowledge: Computer optimization models require precise, structured mathematical expressions, whereas expert experience (e.g. ‘Orders for this product code are urgent; prioritize them on the most efficient machine’) is qualitative and ambiguous. A substantial semantic gap exists between natural language descriptions and mathematical models, preventing these valuable heuristic rules from being directly utilized by algorithms.
(3) Human decision-making struggles with dynamic and high-dimensional complexity: Modern production scheduling constitutes a complex multi-objective, multi-constraint optimization problem, requiring trade-offs between conflicting goals such as inventory, efficiency, cost, and delivery times. In dynamically changing environments, human decision-making not only suffers from slow response times but also frequently becomes trapped in local optima within high-dimensional decision spaces, making it difficult to identify globally optimal scheduling solutions. 6
Currently, academia and industry are actively exploring how artificial intelligence technologies can empower manufacturing within the wave of Industry 4.0 and smart manufacturing. 7 While existing research has applied knowledge graphs and machine learning to manufacturing, most work in production scheduling has separated knowledge management from algorithmic optimization. This has created a critical research gap: there remains a lack of a systematic framework capable of deeply integrating structured expert rules from domain knowledge graphs with core components of multi-objective evolutionary algorithms, such as population initialization and search direction guidance.
Research approach and key contributions
To address the aforementioned research gap, this paper proposes an intelligent production scheduling method based on knowledge graphs and an improved NSGA-II algorithm, aiming to construct a knowledge-driven intelligent decision-making system. The core approach of this study is as follows: first, transform ‘non-computable’ expert knowledge into a ‘computable’ knowledge base through knowledge graph technology; Subsequently, this knowledge base guides and optimizes advanced multi-objective evolutionary algorithms, enhancing their ‘intellect’ when solving complex scheduling problems, ultimately achieving the co-evolution of knowledge and algorithms.
The principal contributions of this study may be summarized as follows:
(1) A knowledge graph for cigarette production scheduling has been constructed, achieving the explicit representation and structuring of scheduling domain knowledge. Addressing the challenge of computerizing scheduling expertise, this work analyses structured and unstructured data. Employing knowledge extraction and fusion techniques, it constructs a comprehensive production scheduling knowledge graph encompassing all elements of the ‘human-machine-material-method-environment’ framework. 8 This solidifies tacit expert knowledge into a machine-understandable, reasonable knowledge base.
(2) Proposes a knowledge graph-driven enhanced NSGA-II algorithm, achieving deep integration between knowledge and algorithm. Addressing the shortcomings of the standard NSGA-II algorithm in complex scheduling problems, such as slow convergence and dependence on random initialization, this paper proposes an improvement method. This method utilizes heuristic rules from the knowledge graph to optimize the algorithm’s initial population, providing high-quality search starting points. Simultaneously, by enhancing the non-domination sorting method, it improves the algorithm’s performance under multiple constraints. 9
(3) The method’s efficacy was validated in real industrial scenarios, yielding significant optimization results. Two scheduling scenarios—static and dynamic—were constructed, with comprehensive experimental validation conducted using real production data from Zhongyan Tobacco. Results demonstrate that the proposed method outperforms traditional approaches and other comparative algorithms across multiple core metrics, including inventory levels, equipment utilization, and rebranding losses. It achieved a 16.23% reduction in monthly finished cigarette inventory, proving its practical effectiveness and potential for broader application.
Related works
This chapter aims to systematically review three core domains pertinent to the research topic: production scheduling optimization methods, the application of knowledge graphs in intelligent manufacturing, and the NSGA-II algorithm along with its enhancements. By analyzing the current state of research, technical methodologies, and existing limitations, it clarifies the positioning and innovative value of this study.
A review of production scheduling optimization methods
Production scheduling constitutes a core function within manufacturing, aiming to optimize one or more performance metrics—such as minimizing production lead times, maximizing equipment utilization, or minimizing inventory costs—by rationally allocating production resources while satisfying diverse constraints including delivery deadlines, equipment capacity, and material supply. Owing to its inherent combinatorial complexity, production scheduling is predominantly recognized as an NP-hard problem, rendering traditional exact algorithms incapable of solving large-scale instances within reasonable timeframes.
Consequently, heuristic and meta-heuristic intelligent optimization algorithms have become the mainstream research approach in this field. Scholars have proposed diverse methodologies to tackle complex scheduling challenges. For instance, Li introduced the Multi-faceted Collaborative Evolutionary Algorithm (MCEA) to address multi-objective, multi-modal optimization problems. 10 Zhang developed an Improved Migratory Bird Optimization (IMBO) for the Flexible Job Shop Scheduling Problem (FJSP), enhancing solution quality through multiple initialization rules and neighborhood search strategies. 11 Domestically, Yuan modeled and optimized the cigarette production process in two distinct phases—tobacco processing and rolling/packing—demonstrating a hierarchical optimization approach. 12 Meanwhile, Xiong et al. proposed a data-driven scheduling methodology, leveraging historical and real-time data to inform decision-making. 13
However, while these general-purpose intelligent optimization algorithms demonstrate outstanding search capabilities, they often fail to effectively harness the ‘tacit knowledge’ inherent in specific production domains. They typically abstract scheduling problems into purely mathematical models, making it difficult to incorporate the valuable, unstructured experience and rules accumulated over time by scheduling experts. Consequently, the generated scheduling solutions may sometimes be ‘theoretically optimal’ yet ‘practically unfeasible’, or exhibit insufficient robustness when confronted with dynamic disturbances.
The application of knowledge graphs in intelligent manufacturing
To address the aforementioned challenges, knowledge graph technology has garnered significant attention within the intelligent manufacturing sector as an effective paradigm for knowledge representation and management. Through its structured graph network format, knowledge graphs efficiently integrate and manage multi-source heterogeneous data encompassing personnel, machinery, materials, methods, and environment. This approach renders implicit knowledge—such as expert experience, process flows, and equipment constraints—explicit and structured, thereby providing a robust foundation for intelligent decision-making.
Research in knowledge graph construction and reasoning primarily focuses on two aspects: (1) Knowledge Graph Construction: The core lies in automatically extracting entities, relationships, and attributes from multi-source heterogeneous data to form knowledge triples. As demonstrated by Yang et al.’s research, extracting knowledge triples from text represents one of the key technologies. (2) Knowledge Inference: Building upon the constructed graph, inference techniques are employed to uncover implicit knowledge. Common inference methods include Rule-Based Reasoning (RBR) and Case-Based Reasoning (CBR). The former excels in scenarios with clear logical structures, while the latter adeptly leverages historical experience to resolve novel problems.
Recent studies have further expanded the scope of knowledge graphs in manufacturing. For instance, Stavropoulou et al. 7 successfully integrated Knowledge Graphs with Digital Twins to model intelligent manufacturing processes, enhancing data interoperability and monitoring capabilities. Similarly, Jiang et al. 14 constructed an equipment management system for the tobacco industry, utilizing graph reasoning for fault diagnosis. However, a critical analysis of these works reveals a common limitation: they predominantly utilize knowledge graphs for data integration, status monitoring, or post-event analysis. The potential of utilizing the structured semantic reasoning capabilities of knowledge graphs to directly drive prescheduling decisions or to constrain the search space of optimization algorithms remains largely unexplored.
NSGA-II algorithm and its improvement research
The Non-Dominated Sorting Genetic Algorithm II (NSGA-II) stands as one of the most classical algorithms for addressing multi-objective optimization problems (MOPs). Its core strengths lie in rapid non-dominated sorting, crowding distance computation, and elite retention strategies which achieve a favorable equilibrium between convergence and diversity. Consequently, it finds extensive application in domains such as production scheduling. However, the standard NSGA-II exhibits certain limitations when addressing highly constrained and knowledge-intensive scheduling problems. These include convergence issues within complex search spaces where the algorithm may prematurely converge to local optima, insufficient diversity maintenance where crowding distance fails to ensure uniform solution distribution, and a heavy dependence on initial populations where random initialization often generates numerous infeasible solutions.
To mitigate these issues, scholars have undertaken extensive refinement studies on NSGA-II in recent years. These investigations primarily focus on improving initialization strategies by incorporating heuristics, optimizing genetic operators through adaptive strategies, and enhancing selection mechanisms. In the specific domain of algorithmic enhancement, Ding and Li 8 optimized the NSGA-II for Digital Twin manufacturing systems by adjusting crossover probabilities, while Wang et al. 15 proposed a multifaceted collaborative evolutionary strategy to handle multimodal constraints.
Despite these advancements, a systematic gap persists as existing research often treats knowledge management and algorithmic optimization as separate endeavors. Most improved algorithms still rely on random initialization or mathematical heuristics and fail to effectively understand and utilize the structured expert rules accumulated in industrial practice. This defines the core research gap and innovation of this study. Unlike previous works that use knowledge graphs merely as a database, this paper proposes a deep integration framework where the knowledge graph actively participates in the evolutionary computation process. Specifically, we utilize graph-based reasoning to transform implicit expert rules into computable constraints to guide the population initialization and mutation operators of NSGA-II. This approach achieves the co-evolution of domain knowledge and algorithmic search, addressing the cold start and convergence issues in high-dimensional scheduling problems.
Knowledge graph construction and reasoning
Multi-objective, multi-constraint production scheduling for roll packaging machinery
The core focus of this study centers on the critical bottleneck within the cigarette production process: production scheduling issues in the rolling and packaging workshop. The overall business process of cigarette production constitutes a hierarchical sequence extending from market demand forecasting to workshop execution, as illustrated in Figure 1. Initially, the enterprise formulates a macro-level monthly production plan based on demand forecasts from the marketing department and nationally mandated production targets. 16 This plan specifies the total output required for each cigarette brand within the current month.

Production scheduling business process overview.
Subsequently, this monthly plan must be broken down into daily production schedules executable at the workshop level, specifying tasks down to the day and individual machine. This decomposition and execution process primarily occurs within the rolling and packaging workshop. The physical production flow of cigarettes, as illustrated in Figure 2, comprises three core processes: rolling and joining (forming tobacco strands into cigarette sticks), packaging (packing sticks into cartons and boxes), and case sealing. These processes are completed on highly automated rolling and packaging machinery (as depicted in Figure 2). Consequently, the efficient and rational allocation of monthly production targets to each rolling and packaging machine within the workshop, alongside the arrangement of their daily production sequence, is pivotal in determining the overall efficiency, cost, and inventory levels of the production system.

Cigarette production process.
However, this production scheduling process is not merely a straightforward task allocation but confronts a series of complex technical challenges and practical constraints, manifested in the following aspects:
(1) Equipment heterogeneity and production constraints:
The wrapping machines within the workshop are not entirely identical, exhibiting significant variations in production speed, functionality, and applicable brands. As shown in Table 1, machine attributes vary considerably. For instance, Machine A01 is an ultra-high-speed unit with a capacity of 300 cartons per day, capable of producing only the NY1 brand. Conversely, Machine B01 is a medium-speed unit with a capacity of 120 cartons per day, yet it can manufacture both NY1 and NY3 brands. This heterogeneity necessitates precise ‘task-machine’ matching during production scheduling.
(2) High changeover costs and continuous production requirements:
Roll-wrapping machine attributes.

Switching a machine from producing Grade A to Grade B is not instantaneous. It requires shut down for a series of complex mechanical and parameter adjustments, termed a ‘changeover’. This process incurs significant time and capacity losses. Using Table 1 as an example, when Machine A02 switches grades, it requires 4 h of downtime, directly resulting in a loss of 56 boxes of production capacity. To avoid these high costs, scheduling must prioritize production continuity—ensuring a single machine produces the same grade continuously over a period to minimize changeover frequency.
(3) Complexity of Multi-Objective Decision-Making:
Roll-packing machine scheduling presents a classic multi-objective optimization problem, requiring decision-makers to balance multiple conflicting goals. For instance:
Objective 1: Reduce inventory. Production plans should closely align with market demand to prevent overproduction and accumulation of finished goods stock.
Objective 2: Minimize changeover losses. Maximize equipment utilization by avoiding unnecessary changeovers.
Objective 3: Balance machine utilization. Distribute production tasks evenly across machines to prevent overloading some while others remain idle.
These objectives inherently conflict: for instance, strict demand-driven production (Objective 1) may necessitate frequent grade changes, thereby increasing changeover losses (conflicting with Objective 2).
In summary, the production scheduling problem for roll packaging machines can be defined as follows: subject to the constraint of meeting the monthly total production requirement, determine the optimal sequence of decisions regarding’ which time period, which machine, which grade, and how much to produce’ while comprehensively considering multiple constraints such as equipment heterogeneity, changeover costs, and production continuity. This aims to achieve overall optimization across multiple objectives including inventory levels, changeover losses, and load balancing.
To address this complex problem, the following section establishes a mathematical model. This translates the aforementioned operational constraints and optimization objectives into precise mathematical language, laying the groundwork for subsequent algorithm design and solution.
Knowledge graph construction methods
This study adopts a top-down construction method where domain experts define the ontology structure while integrating data from ERP and MES systems to construct production scheduling knowledge graphs.10,11 To effectively bridge the gap between strategic planning and workshop execution, we designed a hierarchical two-layer knowledge graph structure. The macro-level monthly planning layer focuses on global production targets derived from market forecasts, encompassing core entity classes such as Monthly Plan, Product Brand, Total Demand, and Delivery Deadline. This layer captures the strategic logic regarding production targets and delivery timelines. Complementing this is the micro-level machine execution layer, which models the physical constraints and capabilities of the workshop floor. This layer includes entities like Machine, Daily Task, Maintenance Slot, Capability, and Changeover Cost to determine production feasibility based on physical resource limits.
A critical innovation lies in the semantic connection between these two layers, where the Monthly Plan entity in the macro layer is mapped to specific Machine entities in the micro layer through a decomposition and constraint mechanism. A Monthly Plan node is decomposed into multiple Daily Task nodes via specific relationships, while the allocation of a Daily Task to a Machine is strictly governed by capability relationships. For example, a task for a specific brand can only be linked to a machine if a valid production capability path exists between them. Additionally, Daily Task nodes are constrained by Maintenance Slot entities to ensure no tasks are scheduled during planned downtime windows.
The graph construction process consists of four stages as shown in Figure 3, including concept modeling, entity extraction, relationship construction, and graph storage. First, interviews with cigarette industry scheduling experts help formalize the specific scheduling logic described above to define the core concepts and relationships. 17 Second, based on the defined ontology framework, structured data from ERP and MES systems, along with semi-structured tables and log information, are collected and cleaned. Third, redundant information across multiple systems is merged using knowledge fusion methods with unified naming conventions. Finally, graph data is stored and managed using the Neo4j graph database to support efficient querying and updating.
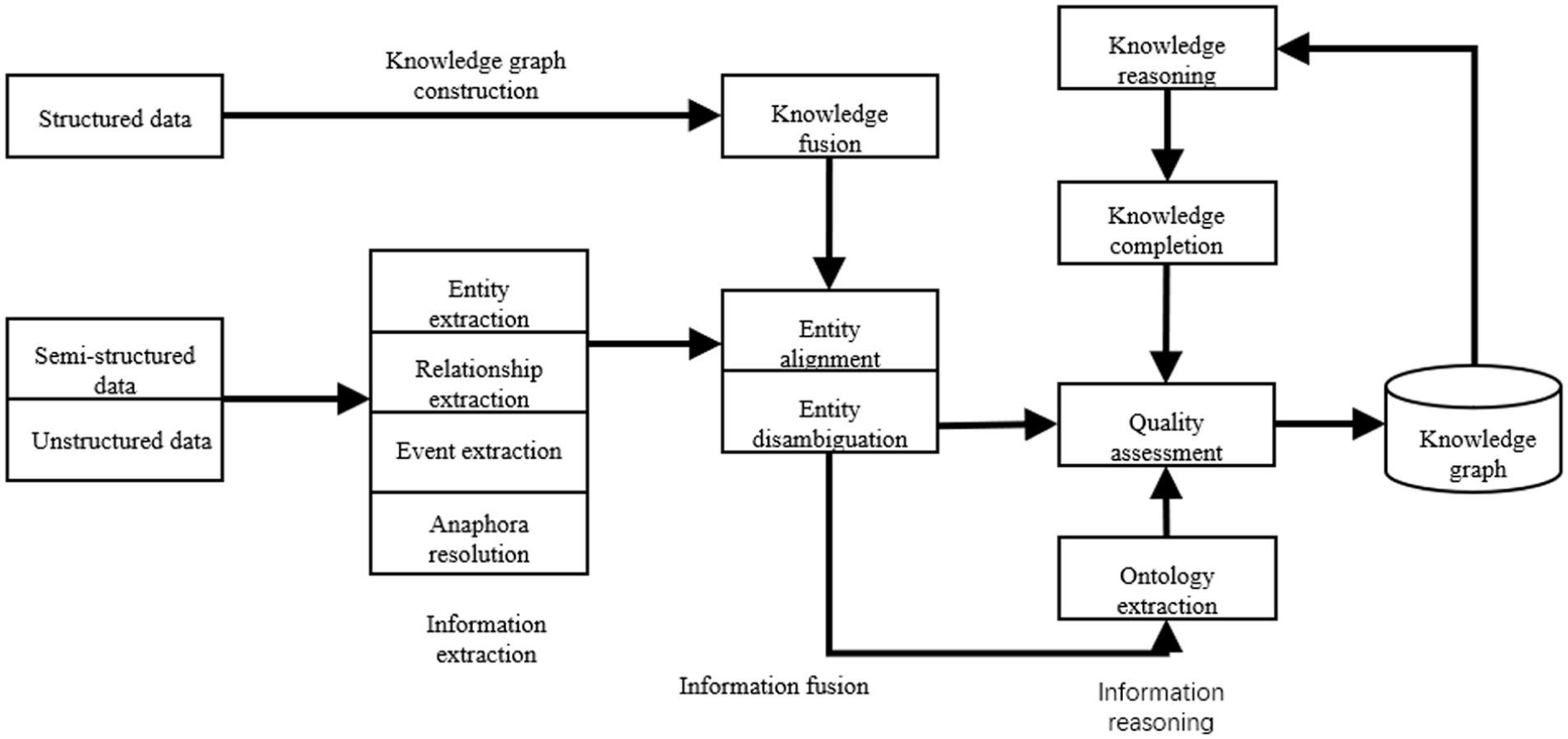
Knowledge graph construction flowchart.
Compared to traditional relational databases, graph databases are more intuitive and efficient in expressing these complex, multi-level, and multi-dimensional relationships. This makes them particularly suitable for scheduling scenarios involving multiple entities, constraints, and associations. Once constructed, the graph transforms the production scheduling problem into a path-finding and subgraph matching problem. It can be queried using the Cipher query language to perform graph traversal, path search, and constraint validation, thereby providing flexible and interactive data support for the subsequent optimization algorithm.
Knowledge extraction and fusion
A bidirectional long short-term memory (BiLSTM) combined with a conditional random field (CRF) model is employed for entity extraction and relation extraction on semi-structured and natural language data, forming a triplet structure. 12 Bi-LSTM comprises two directions of LSTM: the forward LSTM reads the sequence from left to right to capture information from previous time steps, that is, past information; a backward LSTM, which reads the sequence from right to left to capture information after the current time. The model’s input includes manually recorded text by schedulers, product process documents, production logs, etc. By identifying key entities (such as brands, order quantities, production cycles) and relationships (such as ‘belongs to’, ‘depends on’, ‘precedes’), the model automatically extracts scheduling knowledge from unstructured text.
Since Bi-LSTM relies on the sequential information of the input sequence, it is highly sensitive to changes in the order of inputs and struggles to establish relationships between labels, resulting in lower recognition accuracy. CRF finds the globally optimal label sequence by maximizing the conditional probability of the entire sequence, rather than simply identifying the best label at each position. CRF can be seamlessly integrated with Bi-LSTM to enable end-to-end training. This integration leverages the powerful feature extraction capabilities of deep learning models while utilizing CRF’s label dependency modeling capabilities.
The specific calculation process of CRF is as follows:
Step 1: Feature extraction and emission score calculation:
(1) Input a sentence sequence (2) After the Bi-LSTM layer, obtain the emission score vector (3) The total score expression of the label sequence

where
Step 2: Convert to probability representation: (1) CRF converts the score function into probabilities using the SoftMax function, as shown in equation (2); (2) The results of the SoftMax function are shown in the allocation function (3).


Step 3: Model Training and Prediction:
(1) By maximizing the logarithmic conditional probability of the correct label sequence
(2) Equation (5) is the output sequence, which is the prediction result, and


Knowledge extraction involves selecting and storing knowledge from data information through processes such as identification, analysis, selection, and generalization, thereby forming a knowledge repository. 13 In cigarette production scheduling, entity identification must first be performed. The entities involved in cigarette production scheduling include equipment, work orders, brand names, materials, etc.
During the data fusion stage, methods such as entity disambiguation, attribute alignment, and semantic mapping are used to address issues such as synonyms and ambiguous terms in heterogeneous data sources. For example, ‘switching frequency’ and ‘card replacement frequency’ express the same concept in different systems and need to be unified through context alignment. Additionally, to enhance the expressive power of the graph, this paper introduces time attribute modeling and context-aware mechanisms, enabling the knowledge graph to support dynamic evolution records and historical comparison analysis of production scheduling strategies. To improve cross-system compatibility, a cross-factory semantic mapping model is also constructed to support multi-source knowledge transfer at the ontology level. During semantic extraction, a scheduling rule vocabulary was also constructed based on scheduling scenarios, including domain-specific core terms such as equipment IDs, process switching rules, maintenance windows, and order priority levels. Regular expression templates and a rule matching engine were designed to assist in knowledge structuring extraction.
Knowledge inference mechanism
This paper integrates Case-Based Reasoning (CBR) and Rule-Based Reasoning (RBR) methods to achieve graph-based production scheduling strategy recommendation and constraint verification.7,17 CBR calculates the semantic similarity between the current scheduling task and historical cases to retrieve the most similar solution for experience reuse, while RBR relies on logical rules defined by expert experience to perform conflict detection and strategy selection through graph traversal. To make the reasoning logic explicit and computable for the optimization algorithm, we formalized three specific categories of inference rules. First, hard constraints serve as the baseline for physical feasibility; for instance, if a machine’s type attribute diverges from a brand’s required production type, the production relationship is marked as invalid, thereby strictly forbidding this assignment. Second, heuristic rules are employed to address optimization priorities, such that if an order is flagged with an urgent priority and is matched with a machine possessing a high-speed attribute, the recommendation score is significantly incremented. Third, continuity rules aim to minimize operational loss by stipulating that if the brand scheduled at the current time step is identical to that of the previous step, the calculated changeover cost is nullified.
Crucially, these formalized rules play a pivotal role during the population initialization phase of the NSGA-II algorithm. By applying these logical filters before the evolutionary search begins, the system effectively eliminates invalid solutions that violate hard constraints and guides the initial population toward high-quality regions favored by heuristic scores. Furthermore, considering the structural complexity and implicit patterns of knowledge graphs, this paper introduces a graph neural network (GNN) model to utilize adjacency information in graph structures for embedding learning. This achieves vectorized representations of entities and uncovers potential dependencies among scheduling constraints. The GNN output results serve as feature inputs for subsequent scheduling optimization models, improving model initialization quality and evaluation accuracy. To further enhance the autonomous evolution capabilities of the knowledge reasoning system, this paper proposes the construction of a reinforcement learning (RL) combined with a rule-constrained intelligent scheduling mechanism. This involves training the scheduling agent using Deep Q-Learning to optimize scheduling actions based on historical cases and reward feedback while supporting dual-layer verification of soft and hard constraints to enhance system robustness and adaptability.
Production scheduling optimization models and algorithms
Multi-objective scheduling model
In the cigarette production scenario, production scheduling tasks must not only meet the timeliness requirements of order delivery but also be completed while minimizing production changeover costs and maximizing resource utilization. Therefore, this paper constructs a multi-objective, multi-constraint production scheduling optimization model encompassing three core objectives:
(1) Minimize brand changeover frequency: Frequent brand changes lead to increased equipment setup time, higher material wastage, and adverse effects on production rhythm;
(2) Minimize inventory and production plan deviations: Controlling production lead times or delays helps achieve on-time delivery and inventory optimization;
(3) Maximize equipment utilization: Avoid equipment idling and resource waste as much as possible to achieve balanced capacity allocation. 18
The monthly production volume of cigarettes must exceed the planned production volume. However, to reduce inventory, while meeting the planned demand, it is necessary to minimize the excess of finished cigarettes over the planned demand, as shown in equations (6) and (7).

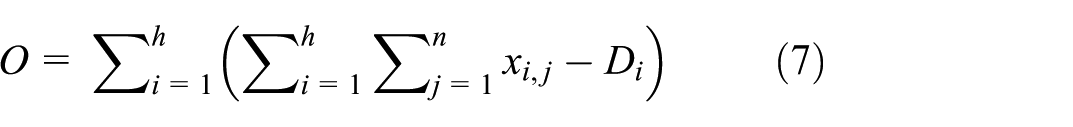
where
Improvements to the NSGA-II algorithm
NSGA-II, as a classic multi-objective evolutionary algorithm, demonstrates good performance in searching for multi-objective Pareto optimal solutions. However, it typically suffers from local convergence and strong initialization dependency when applied to high-dimensional scheduling problems. To enhance the algorithm’s performance for the specific problem studied in this paper, we implemented three systematic improvements centered on knowledge integration and search efficiency.
The primary improvement focuses on population initialization optimization driven by the knowledge graph. To avoid the high proportion of invalid solutions caused by completely random initialization, we introduce a knowledge-guided decision mechanism. As illustrated in the logic flow below, this mechanism actively filters and corrects solutions before they enter the evolutionary cycle:
(1) Generation: The algorithm generates a preliminary candidate solution based on random assignment.
(2) KG Query: The system queries the ‘Machine-Brand’ compatibility relationships (e.g. (Machine A)-(cannot produce)->(Brand B)) within the knowledge graph constructed in Section 3.
(3) Decision & Correction: If the candidate solution violates a hard constraint extracted from the graph, the mechanism triggers a correction function. It retrieves a list of valid machines for the specific brand from the graph and reassigns the task to a compatible machine; otherwise, the infeasible solution is discarded.
(4) Output: The process ensures that the initial population consists of high-quality, feasible individuals. Experiments indicate that this knowledge-driven method improves the average fitness of the population by 8.4% compared to random initialization.
Complementing this is the optimization of the chromosome encoding mechanism where a two-layer structure is adopted. The product sequence and machine allocation are encoded separately, with one layer representing the production sequence for each machine and the other representing the machine allocation corresponding to each product. Crossover and mutation operations are applied independently to these two encoding layers, enabling a more efficient and granular search of the solution space.
Finally, to address the issue of boundary solution clustering often seen in original NSGA-II quick sort methods, we improved the non-dominated sorting and crowding calculation. This paper introduces a local density adjustment function to modify the calculation method for distances between individuals in the population. This enables the algorithm to maintain elite solutions while enhancing population diversity and avoiding premature convergence. Additionally, a dynamic crowding distance recalculation strategy is employed to update the crowding degree evaluation metrics in a timely manner during each generation’s population evolution, thereby improving the stability and uniformity of the non-dominated front solution set.
Algorithm flow
The improved NSGA-II overall process is as follows:
(1) Generate partial heuristic initial solutions based on knowledge graph reasoning;
(2) Perform non-domination sorting and crowding degree calculation;
(3) Perform elite selection, crossover, and mutation operations;
(4) Dynamically update the population, save the Pareto solution set, until the iteration termination condition is met.
The pseudo code is shown in Figure 4:

Algorithm 1: NSGA-II.
Solution set evaluation method
This paper employs the following two multi-objective optimization evaluation metrics: Spread (expansion degree): measures the breadth and uniformity of the solution set distribution; Hypervolume (hypervolume): measures the volume covered by the non-inferior solution set in the objective space. The above improvements aim to enhance the balance, feasibility, and quality of the solution set in scheduling optimization, providing theoretical support for the subsequent deployment of scheduling systems. Future work will explore integrating reinforcement learning strategies into population evolution mechanisms to achieve adaptive dynamic adjustments to scheduling rules, and attempt to migrate this optimization framework to multi-workshop collaborative scheduling scenarios to enhance its applicability and intelligence. 19
Experimental verification and application
Data and scenario settings
To validate the practical feasibility and applicability of the proposed method, we utilized real-world production data from Zhongyan Tobacco. As shown in Table 2, the primary dataset consists of market demand forecasts for NY1 to NY5 cigarette brands in April. To further assess the algorithm’s robustness beyond a single month’s data, we employed Monte Carlo simulation based on the statistical distribution of the April data to generate two additional stress-test datasets. The first is Scenario A representing a high-load condition where the simulated total order volume is increased by 20% to test capacity limits. The second is Scenario B representing a high-variety condition where the frequency of small-batch, multi-variety orders is increased by 30% to test flexibility.
Monthly rolling forecast demand data for each cigarette brand.

Based on these datasets, three experimental environments were constructed. First, a static production scheduling environment is established where all order information is fully known at the beginning of the production scheduling process, which is suitable for traditional rolling planning environments. Second, a dynamic production scheduling environment is constructed based on the April dataset but with specific stochastic disturbances introduced. These disturbances include urgent orders inserted at a frequency of one every 3 days and a random equipment failure with a duration of 4 h occurring once per week, thereby more closely resembling actual production environments. Third, a stress testing environment applies the algorithm to the simulated Scenario A and Scenario B datasets to evaluate generalizability.
The order data used in the experiment includes brand, specifications, daily production requirements, and delivery time, while the equipment data covers information such as the model of the roll packaging machine, production capacity, and maintenance cycle. To achieve unified modeling, all raw data is converted into a unified format during the preprocessing stage and stored in knowledge graph entity nodes for algorithm access and matching.
Model constraints include equipment capability constraints such that certain brands can only be processed on specific roll packaging machines. Process continuity constraints ensure that brands of the same type are scheduled consecutively to reduce switching. Time window restrictions require that production must be completed before the delivery time. Factory calendar constraints involve considering non-working days such as public holidays and maintenance shutdowns. Finally, inventory capability constraints involve considering the maximum inventory limits and available quantities of raw material and finished product warehouses.
For the experimental platform, the optimization algorithm framework is implemented using Python with evolutionary operation modules built using the DEAP library. The knowledge graph component uses the Neo4j graph database for graph queries and knowledge access. The runtime environment consists of an Intel i7-12700H CPU, 16 GB of memory, and the Windows 11 operating system.
Experimental design
To comprehensively evaluate the effectiveness of the method proposed in this paper, the following three sets of control experiments were designed: Baseline 1: Expert Rule-Based Scheduling, where experienced schedulers manually arrange production schedules based on process rules and experience; Baseline 2: Traditional NSGA-II algorithm, without incorporating a knowledge graph, relying solely on evolutionary search for multi-objective optimization; Baseline 3: Deep Reinforcement Learning Scheduler (DRL-S), 20 a state-of-the-art machine learning approach representing a different optimization paradigm, included to benchmark against non-evolutionary methods. Proposed: Improved NSGA-II + Knowledge Graph method, combining expert knowledge with multi-objective optimization strategies.
All methods were run on the same dataset and under the same parameter conditions. The algorithm parameters were set to a population size of 100, 100 iterations, a crossover probability of 0.8, and a mutation probability of 0.2.
Quantitative evaluation and comparison of algorithm performance
To transcend visual observation of the Pareto frontier and provide a more objective, quantifiable performance assessment, this section employs multi-objective optimization performance metrics—Hyper Volume (HV) and Inverted Generational Distance (IGD)—to conduct a quantitative analysis. The analysis compares the proposed improved NSGA-II algorithm against four state-of-the-art comparative algorithms in the context of a cigarette production scheduling instance. The comparative algorithms are: MOEA/D, NSGA-III, MA, and a recently developed Deep Reinforcement Learning-based Scheduler (DRL-S). 20
The DRL-S algorithm represents a different paradigm from evolutionary algorithms. To ensure a fair comparison, its application to this multi-objective problem required a specific methodology. The DRL agent was trained to optimize a scalarized reward function, which is a weighted sum of the core objectives (inventory level, equipment utilization, and changeover loss). To generate a set of non-dominated solutions comparable to a Pareto front, the trained DRL-S agent was executed multiple times, each time with a different, randomly sampled weight vector for the objectives. The collection of unique, non-dominated solutions from these runs constitutes the final solution set for DRL-S. This approach allows the decision-making policy learned by DRL-S to be evaluated across a range of objective trade-offs, thus ensuring its comparability with the population-based Pareto fronts generated by NSGA-II, MOEA/D, and NSGA-III.
The mathematical definition and computational process for the metrics are as follows:
(1) The SC metric serves as an indicator for measuring the extent to which a solution set covers the problem space. In multi-objective optimization problems, solution set coverage can be employed to evaluate the diversity and representativeness of the solution set, as expressed by the equation in (8):

Where:
When
(2) The IGD metric comprehensively evaluates an algorithm’s convergence and distribution by calculating the normalized spatial distance between the true Pareto frontier P* and the solution set S generated by the algorithm, as expressed in equation (9):
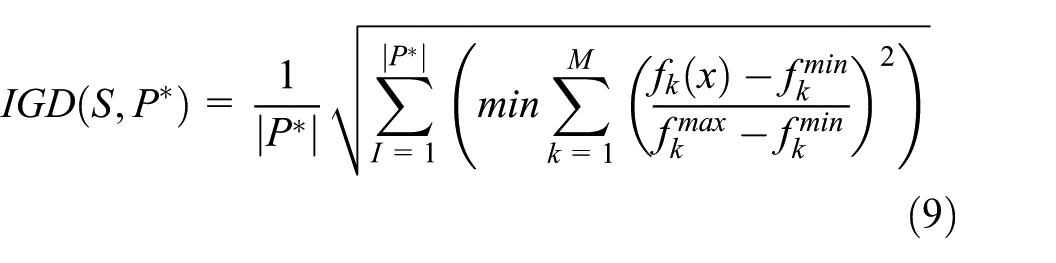
Where: M denotes the target dimension, and
A smaller IGD value indicates superior algorithmic performance in terms of both accuracy in approximating the true frontier and uniformity in the distribution of the solution set.
(3) The HV metric comprehensively evaluates the convergence and distribution of solution sets by calculating the hypervolume enclosed by the non-dominated solution set and the reference point within the objective space. Its mathematical definition is shown in equation (10):
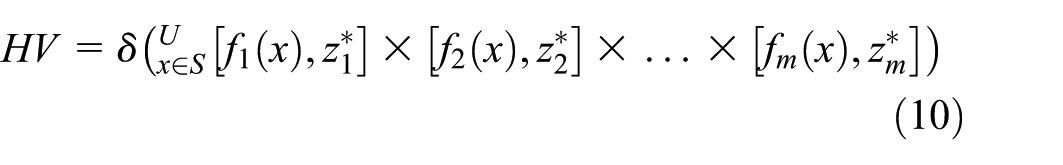
Where: S denotes the algorithmically generated Pareto solution set, z* =
To ensure fairness and reliability of results, each algorithm was independently run 30 times. The table below records the average values for each algorithm across the two metrics: HV and IGD. A smaller IGD value indicates superior comprehensive performance (convergence and diversity) of the algorithm’s solution set; a larger HV value signifies broader volume coverage of the solution set within the objective space and thus superior overall performance.
The results in Table 3 clearly demonstrate that:
(1) Regarding the IGD metric, the proposed improved NSGA-II algorithm achieved the lowest mean value (0.00158), significantly lower than the other three comparison algorithms. This indicates that the Pareto frontier obtained by the proposed algorithm is, overall, closest to the true theoretical optimal frontier.
(2) Regarding the HV criterion, the improved NSGA-II algorithm likewise achieved the highest mean value (0.925), indicating that its solution set dominates the widest area within the objective space, thereby providing superior trade-off solutions across all objective dimensions.
Multi-objective performance metrics comparison (mean values).

Compared to DRL-S, the strongest performer among the baseline methods, the proposed method still exhibits significant advantages on both IGD and HV, demonstrating the superiority of the knowledge-driven evolutionary framework for this problem
Statistical significance test
To further validate that the aforementioned performance advantages are not attributable to random factors, this section employs statistical methods to conduct a significance analysis of the experimental results. 15 We employed one-way analysis of variance (ANOVA) to test whether significant differences existed in the performance metrics across the four algorithms. Tukey’s HSD (Honestly Significant Difference) post-hoc test was then applied to compare performance differences between each pair of algorithms. The significance level for all statistical tests was set at α = 0.05.
Table 4 presents the key results of Tukey’s HSD test. Analysis reveals that when comparing the improved NSGA-II algorithm against the remaining four algorithms (including the latest DRL-S 20 across both IGD and HV metrics, all p-values fall below 0.05. This indicates that we can conclude with over 95% confidence that the proposed improved NSGA-II algorithm demonstrates statistically significant superior performance over all comparison algorithms, providing robust statistical evidence for its superiority
Tukey’s HSD post-hoc test p-values.

Ablation study
This paper introduces two core enhancements to the standard NSGA-II algorithm: A. Knowledge-based heuristic initialization (KI) and B. Improved non-domination sorting and crowding degree computation (IM). To independently validate the contribution of each enhancement to the algorithm’s overall performance, ablation experiments were designed in this section. Four algorithm variants were constructed for comparison:
(1) Baseline: The original standard NSGA-II algorithm.
(2) NSGA-II + KI: NSGA-II employing only heuristic initialization.
(3) NSGA-II + IM: NSGA-II utilizing only the improved non-domination sorting and crowding degree calculation.
(4) Proposed Algorithm (KI + IM): The complete model incorporating both enhancements.
By analyzing the ablation experiment results in Table 5, the following conclusions can be drawn:
(1) Effectiveness of Initialization Improvement: Compared to the Baseline, NSGA-II + KI demonstrates significant improvements in both IGD and HV metrics. This demonstrates that utilizing domain knowledge from knowledge graphs to generate high-quality initial populations can substantially accelerate the algorithm’s convergence speed and guide it toward exploring more favorable solution space regions.
(2) Effectiveness of core algorithm improvements: Compared to the Baseline, NSGA-II + IM also exhibits notable performance gains. This confirms that the improvements to non-domination sorting and congestion calculation proposed herein are effective, better handling the complex constraints of this problem while maintaining solution diversity.
(3) Synergistic Effects of Dual Improvements: The complete algorithm (combining KI and IM) achieved the best performance across all variants, outperforming any single improvement. This indicates a positive synergistic effect between heuristic initialization and core algorithm optimization, where their combination maximizes the algorithm’s overall problem-solving capability.
Ablation study results (mean).

Analysis of experimental results
Based on the improved NSGA-II algorithm process and the production scheduling example of Zhongyan, the initial parameters were set with a population size of 100 and 100 iterations to optimize the production scheduling plan. The resulting Pareto optimal solution set is shown in Figure 5, compared against MOEA/D, NSGA-III, MA, and DRL-S. The results clearly demonstrate the superior performance of the proposed Improved NSGA-II method indicated by red crosses, as its solutions consistently dominate those from other algorithms forming the effective optimal frontier. Notably, the newly introduced DRL-S algorithm indicated by black squares proves to be a highly competitive baseline, outperforming MA and NSGA-III and performing comparably to MOEA/D. However, it is still consistently outperformed by our knowledge-graph-enhanced NSGA-II. This visual evidence strongly supports the quantitative metrics in Table 3, confirming that our proposed method achieves the best trade-offs among minimizing inventory, reducing changeover losses, and balancing machine load.
Pareto front for multi-objective optimization.
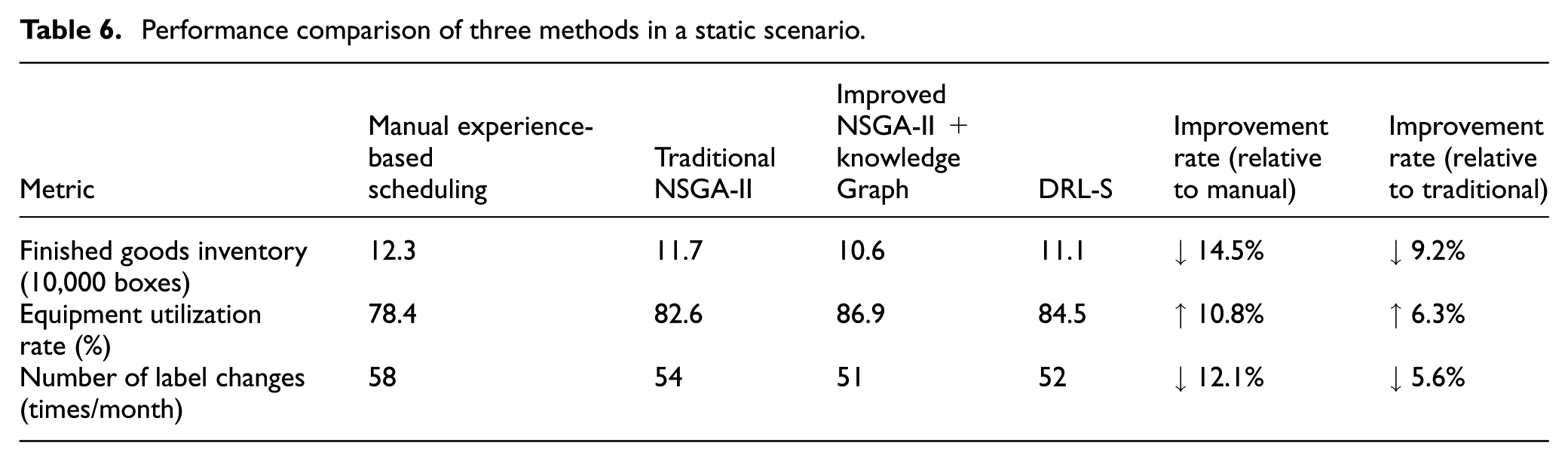
To validate the performance of the proposed method under deterministic conditions, this study first conducted comparative experiments in a static scheduling scenario. The comparison includes manual experience-based scheduling, the traditional NSGA-II algorithm, DRL-S, and the improved NSGA-II + knowledge graph method proposed in this paper. The results of each method across three key metrics are shown in Table 6. The results in Table 6 show that the proposed method achieves the best performance across all three metrics. It reduces finished goods inventory by 14.5% compared to manual scheduling and 9.2% compared to traditional NSGA-II. Notably, while DRL-S outperforms traditional NSGA-II, the proposed knowledge-graph-enhanced method still surpasses DRL-S, achieving lower inventory, higher utilization, and fewer label changes.
Performance comparison of three methods in a static scenario.
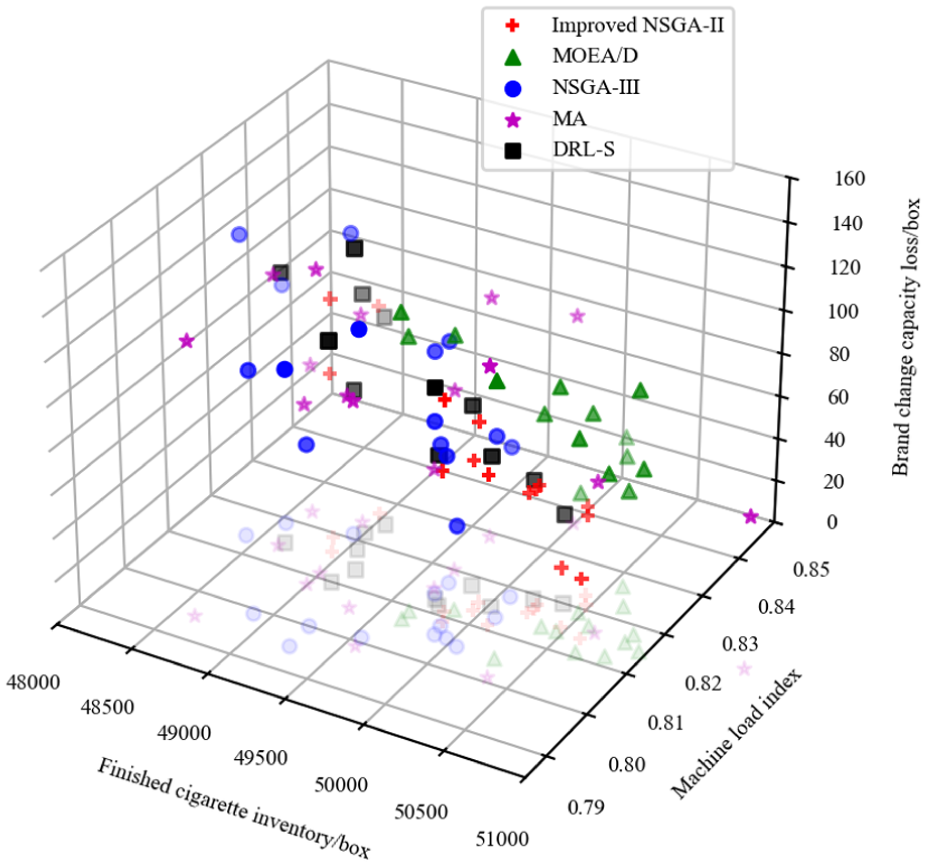
Under production scheduling considering machine maintenance, the three evaluation criteria—minimizing finished cigarette inventory, balancing cigarette packaging machine load, and minimizing production capacity loss due to brand changes—are used for multi-objective, multi-constraint optimization. The Pareto solution set is shown in Figure 6, and comparisons with the MOEA/D and NSGA-III,DRL-S algorithms are also included. The visualization reaffirms the superiority of the proposed Improved NSGA-II method (red crosses), which establishes a dominant and clearly superior Pareto front compared to all baseline algorithms. The DRL-S algorithm (black squares) once again demonstrates its capability as a strong benchmark, performing on par with MOEA/D and significantly outperforming NSGA-III and MA. Despite the strong performance of DRL-S, the knowledge-graph-driven approach of our proposed method enables it to discover a set of demonstrably better solutions, highlighting its robustness and effectiveness across different scenarios.

Pareto chart considering the protection of the roll packaging machine wheel.
To address concerns regarding the generalizability of the method beyond a single month’s data, we further evaluated the algorithm under the simulated stress scenarios defined in Section 5.1. The proposed Improved NSGA-II demonstrated exceptional stability under these conditions. In Scenario A which represents a high-load environment, our method maintained a feasible solution rate of 100% despite the increased capacity demand, whereas the traditional NSGA-II failed to find feasible schedules in 15% of the runs. In Scenario B which demands frequent changeovers due to high variety, the advantage of our method was even more pronounced. The knowledge-graph-driven initialization effectively grouped compatible brands resulting in a changeover frequency that was 18.7% lower than the DRL-S baseline. These results confirm that the proposed method is not merely overfitting the April dataset but possesses the robust generalizability required for varying production intensities.
To further assess the robustness and adaptability in actual complex environments, this study conducted tests in a dynamic production scheduling scenario characterized by specific stochastic disturbances. These disturbances were rigorously defined as random urgent orders inserted at a frequency of one every 3 days and a simulated breakdown of Machine B01 occurring on the 10th day requiring a 4 h repair window. The comparison results in terms of finished product inventory, equipment utilization, changeover frequency, and average response time are shown in Table 7. In this highly variable environment, the proposed method again demonstrates superior performance. Specifically, when the designated failure of Machine B01 occurred, the knowledge graph engine swiftly retrieved alternative production resources based on explicit same-type entity relationships. This inference mechanism effectively pruned approximately 90% of the invalid search space instantly by excluding incompatible machines. Consequently, the algorithm achieved an average response time of 10.3 min per adjustment, which is 32.2% faster than manual adjustments and 18.3% faster than traditional NSGA-II. While modern machine learning methods like DRL-S show significant improvements over traditional algorithms, the deep integration of explicit domain knowledge in our proposed method allows it to achieve the best balance between optimization quality and rapid responsiveness.
Performance comparison of three methods in dynamic scenarios.

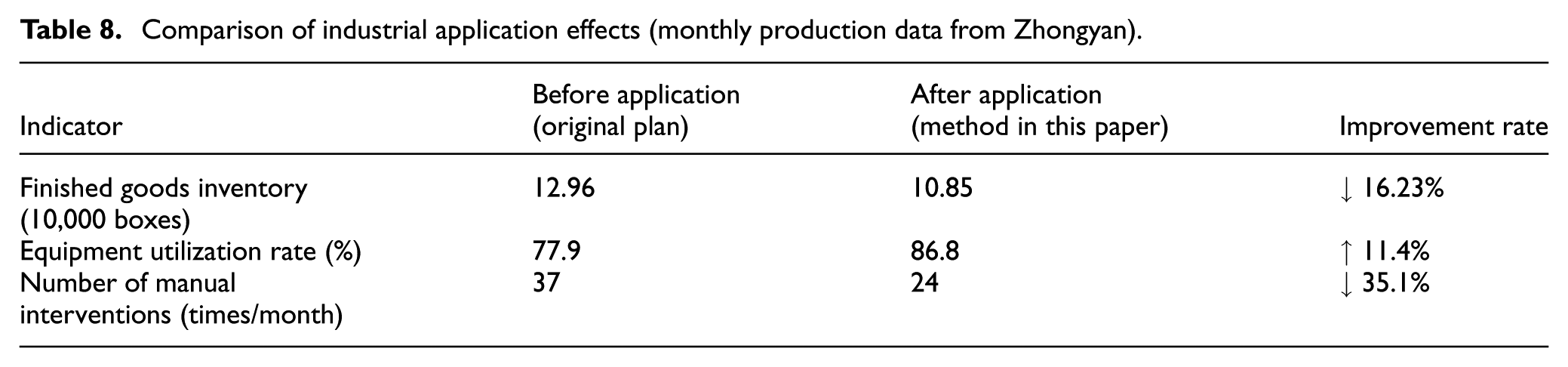
To validate the rationality and engineering application value of the proposed scheduling method, this paper deployed it in the actual production environment of Z Tobacco Company and conducted a 1-month application test combined with the company’s actual allocation data for analysis. As shown in Figure 7, under the premise of meeting market demand, the optimized production scheduling scheme based on the improved NSGA-II algorithm reduced the total inventory level by 16.23% compared to the original production scheduling scheme and outperformed the optimization results of the MOEA/D algorithm. Table 8 presents the comparison results of production data before the original scheduling scheme and after the application of this paper’s method. It can be seen that this method not only significantly reduces finished goods inventory but also improves equipment utilization and reduces the number of manual interventions. Practical application demonstrates that this method effectively enhances scheduling efficiency, alleviates the workload of scheduling personnel, and exhibits good economic benefits and promotional prospects in production practice.

Cigarette inventory optimization data.
Comparison of industrial application effects (monthly production data from Zhongyan).
Discussions
This chapter aims to conduct a deeper analysis of the experimental results presented in Chapter 5, exploring the underlying mechanisms that underpin the effectiveness of the proposed methodology. It examines its practical application value in industrial settings while objectively reviewing the limitations of this research, thereby providing insights for future research directions.
In-depth analysis and implications of experimental results
The experimental findings presented in Chapter 5 consistently demonstrate, whether through visual comparisons of the Pareto front or via quantitative metrics alongside statistical significance tests, that the proposed ‘Knowledge Graph + Enhanced NSGA-II’ methodology significantly outperforms traditional NSGA-II, other mainstream multi-objective optimization algorithms, and a state-of-the-art Deep Reinforcement Learning scheduler (DRL-S). Its core advantage stems from the deep synergistic mechanism between explicit domain knowledge and the optimization algorithm, a synergy that even powerful data-driven models like DRL-S struggle to replicate entirely.
Firstly, the knowledge graph-driven initialization strategy is pivotal for the algorithm’s efficient convergence. 13 As demonstrated by the ablation experiment results (Table 5), merely introducing heuristic initialization (NSGA-II + KI) yields substantial performance improvements. This reveals the ‘cold start’ dilemma faced by traditional algorithms in strongly constrained problems. Our method addresses this by leveraging knowledge graphs to translate experts’ valuable experience into structured heuristic rules, providing the initial population with a high-quality ‘first push’ and significantly accelerating convergence.
Secondly, the core mechanism of the improved algorithm enhances exploration capabilities under complex constraints. Ablation experiments also demonstrate that refining the non-domination sorting and crowding degree calculation methods (NSGA-II + IM) yields substantial performance gains. This indicates that the proposed improvement method better evaluates solution quality and distribution within the multidimensional objective space, effectively maintaining population diversity and avoiding premature convergence to local optima. 16
Thirdly, and most significantly, the comparison against the DRL-S scheduler provides profound insights. While DRL is exceptionally powerful at learning complex policies from data, our results (e.g. Table 6, Figure 5) demonstrate its performance was surpassed by our knowledge-driven approach. This suggests a critical takeaway: for complex, heavily constrained industrial problems, explicit, structured domain knowledge, as captured by our knowledge graph, provides a more effective and reliable optimization guide than what can be learned implicitly from historical data alone. Our method leverages decades of human expertise directly, guiding the search process in a way that is more efficient and robust. In essence, while DRL-S learns the ‘what’ from data patterns, our knowledge graph provides the crucial ‘why’ from the outset, preventing futile searches in known infeasible regions.
Practical significance of the research
The findings of this study possess not only theoretical value but also clear industrial practical significance, offering tangible application benefits for Z Tobacco and similar manufacturing enterprises:
(1) Decision Support Tool: The proposed system functions as an ‘intelligent scheduling assistant’, rapidly generating a series of high-quality, feasible Pareto-optimal solutions and intuitively presenting trade-offs to decision-makers. 18
(2) Knowledge Management Platform: Through the constructed knowledge graph, enterprises can centralize and structurally manage scheduling expertise, mitigating the risk of knowledge gaps arising from the departure of key personnel.
(3) Enhanced Operational Efficiency and Economic Benefits: Experimental results demonstrate a 16.23% reduction in inventory, alongside decreased changeover losses and improved equipment utilization rates. These improvements, validated not only against traditional methods but also against a competitive DRL-based scheduler, directly translate into tangible economic gains for the enterprise.
Research limitations and future prospects
Although this study has yielded positive outcomes, certain limitations remain, which also point the way forward for future research.
Research Limitations:
(1) Static Nature of Knowledge Graphs: The production scheduling knowledge graph constructed herein is primarily based on historical data and expert experience. It cannot automatically learn and evolve from new production data without manual updates.
(2) Algorithm Independence: While this study successfully compared our method against a separate DRL-based scheduler, it did not explore deeper hybridization. The full potential of combining the global search strengths of our knowledge-driven evolutionary algorithm with the rapid, policy-based decision-making of reinforcement learning in a single, unified framework remains an open question.
(3) Model generalization capability: The proposed method was validated solely on real-world data from one enterprise. Its applicability and generalizability to other tobacco enterprises or process manufacturing sectors requires further validation.
(4) Response to real-time dynamic events: While the experiments considered dynamic scenarios focused on planned rescheduling, the framework’s response speed for sudden, millisecond-level events (e.g. unexpected equipment failures) still holds room for improvement compared to the purely reactive nature of some DRL agents.
Future Prospects: Given the aforementioned limitations, future research may explore the following avenues:
(1) Constructing Dynamically Evolving Knowledge Graphs: Incorporate graph neural networks (GNNs) and online learning techniques to enable knowledge graphs with self-learning capabilities, allowing them to autonomously discover new knowledge and update rules from real-time production data streams.
(2) Expanding Application Domains and Validation: Extend the proposed ‘knowledge graph + optimization algorithm’ framework to broader process manufacturing sectors and construct cross-industry generic scheduling knowledge models to enhance its universality.
(3) Developing Hybrid Knowledge-Driven Reinforcement Learning Schedulers: Our comparative analysis showed that while a standalone DRL-S is powerful, our knowledge-driven approach was superior. This points to a promising future direction: tightly integrating these two paradigms. Future research could explore using the knowledge graph to shape the DRL agent’s reward function, constrain its action space to valid production choices, or even use a DRL agent to dynamically select the best crossover and mutation operators for NSGA-II at each step. Such a hybrid system could potentially combine the explicit expertise from the knowledge graph with the adaptive learning power of DRL, creating a truly intelligent and robust real-time scheduling agent.
Conclusion
This paper proposes a novel intelligent production scheduling method that synergizes a two-layer knowledge graph with an improved NSGA-II algorithm, specifically tailored for the complex constraints of cigarette rolling and packaging workshops. By constructing a structured knowledge base encompassing monthly planning and machine-level execution, this study successfully transforms implicit, unstructured expert experience into computable heuristic rules. This approach effectively resolves the ‘cold start’ problem of traditional evolutionary algorithms and enhances global search capabilities under high-dimensional constraints, bridging the gap between theoretical optimization and practical engineering feasibility.
Experimental validation based on real-world industrial data demonstrates the significant practical value of the proposed method. Compared to traditional manual scheduling, the proposed framework reduced monthly finished goods inventory by 16.23% and increased equipment utilization by 11.4%, while significantly minimizing brand changeover losses and manual intervention frequency. Furthermore, the comparative analysis confirms that the proposed knowledge-driven method outperforms state-of-the-art baselines, including DRL-S and MOEA/D. These results validate the hypothesis that embedding domain knowledge into the evolutionary search process not only ensures solution feasibility but also significantly improves convergence quality and robustness.
Despite these achievements, this study has limitations, particularly regarding the validation scope which relied on production data from a single manufacturing plant. Future research will focus on two key directions to address this: first, expanding the experimental validation to multi-factory and cross-regional production scenarios to rigorously test the model’s generalizability and scalability; second, exploring the deeper integration of Reinforcement Learning (RL) into the knowledge reasoning mechanism. This aims to achieve adaptive parameter tuning and faster responses to millisecond-level disturbances, ultimately transitioning the system from ‘automated scheduling’ to truly ‘autonomous cognitive scheduling’ for the broader process manufacturing industry.
Footnotes
Handling Editor: Divyam Semwal
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.*