
Abstract
Artificial intelligence (AI) has made a significant impact in engineering through its data analysis and interpretation capabilities. In systematic machine design, AI tools can enhance the design process, from improving quality analysis in computer-aided design (CAD) drawings to generating three-dimensional models and inverse design structures. This research proposes a methodology for using generative AI in the conceptual design phase, based on the StyleGAN2ADA architecture, an image generation model designed for high-quality synthesis with limited training data. The method aims to preserve trademark or otherwise recognizable features in the design while exploring new combinations of desired design attributes. A case study demonstrates the approach by blending visual features from cars and shoes using a combined dataset of 3667 images, with StyleGAN2-ADA trained to an optimal point of ∼4800 kimg. Across the generated samples, about 2% of generated images showed clear car–shoe feature mixing, while fewer than 2% were classified as blurred, and the full training run required on the order of 6–10 GPU hours depending on hardware configuration. These results indicate that StyleGAN2-ADA-based methods have practical potential for supporting conceptual design while also revealing limitations in mixing rate, controllability, and output quality that warrant further work.
Introduction
In recent years, the development of artificial intelligence (AI) for engineering processes has accelerated rapidly. Research has incorporated AI into automated quality analysis on computer-aided design (CAD) drawings, 1 data-driven generation of 3D models, 2 and inverse design structures with tailored properties.3,4 Despite this progress, these examples capture only a small portion of AI’s broader potential in engineering design. 5
This research aims to broaden the scope of AI in engineering design by investigating its suitability within the systematic engineering design process for mechanical structures. 6 Specifically, it investigates AI’s potential as a concept design tool during the early design stage. In the systematic design, concepts are generated in a stepwise manner based on clearly defined requirements, and candidate solutions are iteratively refined to fulfill these requirements. 6 AI has great potential to enhance conceptual design by proposing candidate solutions that designers can evaluate, adapt, and combine, thereby accelerating exploration and supporting higher-quality designs. The systematic process continues further into embodiment and detailed design, where different types of simulations are typically used to yield a feasible and functional design. For company-specific brand or nature-inspired, engineers need extensive knowledge of existing creations to create new solutions and continuously take advantage of existing designs. However, even the most creative and experienced engineers might struggle with cognitive biases, habitual thinking patterns, or just a lack of diverse or multidisciplinary perspectives. In this manuscript, a method is proposed to aid the concept design process by using generative adversarial networks (GANs), 7 enabling the rapid generation of tens to hundreds of concept variants in minutes rather than hours or days based on an existing pool of solutions and the concepts, shapes, and features that the engineer seeks to include in the new solution.
Currently, the conceptual design relies on methodologies such as the TRIZ innovation framework and quality function deployment (QFD), 8 as well as abstraction, functional structures, and morphological matrices.6,9 While these tools can be used in innovating new concepts, they are often time-consuming and limited in the number and diversity of concepts they can practically produce.
Design fixation is a persistent problem in professional design practice. Experimental work indicates that designers are up to about 1.4 times more likely to exhibit fixation when they are shown an initial example. 10 In this state, designers can become effectively “blind” during idea development, carrying over unnecessary or unintended design choices from previous solutions. The development of fixation may be encouraged by several factors, including organizational culture, the design activities employed, and prior design failures. 11 Despite ongoing efforts to address this issue, it continues to affect the design process.
GAN has been previously proposed by Chen et al. 12 as a tool to generate images that combine two contrasting concepts. They used 3772 images of spoons and 7408 images of leaves as training data, which were then trained with the GAN model for 500,000 epochs (epoch refers to one complete pass through the entire training dataset). This created a group of randomly synthesized images of spoons and leaves, which were then used as an inspiration for the designs. They offered randomly synthesized images to artists who created concept art based on the images. However, different from the methodology proposed in this manuscript, they used these images to create new concepts without keeping the original trademark design.
To leverage this approach for generating concept designs that remain consistent with a company’s brand and earlier product features, this work proposes the usage of StyleGAN2-ADA, a StyleGAN architecture designed for high-quality image synthesis with comparatively small datasets.13,14 StyleGAN learns the underlying distribution of a training image set and uses a disentangled latent space to generate new images, allowing attributes from different object classes to be combined in a coherent manner. 13 Recent work in generative design has shown that GAN-based models can support early-stage concept generation, but existing studies often assume relatively large, balanced datasets and do not explicitly target the preservation of brand identity or other recognizable product features.12,15 The typical engineering scenario instead involves small, imbalanced image collections tied to specific product families, where designers must innovate while maintaining continuity with past designs. The primary novelty of this work lies in adapting StyleGAN2-ADA to such small, imbalanced datasets to generate novel concepts that explicitly preserve brand-defining visual features, a challenge not sufficiently addressed in prior GAN-based design ideation literature.
The rest of the article is organized as follows: Section 2 gives an introduction to the systematic engineering design process, GANs, and StyleGAN2-ADA, and introduces the methodology, Section 3 presents the case study and its results, the final sections discuss the results (Section 4), and Section 5 concludes the paper and outlines directions for future work.
Theory and methods
Machine design or mechanical engineering design is an interdisciplinary part of mechanical engineering. It encompasses the mechanical engineering disciplines, such as engineering mechanics, materials science, thermodynamics, and manufacturing processes as a whole to design machines that not only perform their intended functions but are safe, reliable, cost-effective, and manufacturable. Machine design includes both the analytical part of engineering, such as stress analysis and kinematics, and the creative process to meet the design requirements.
Machine design plays an important role in developing and maintaining the modern lifestyle and well-being. It is an important activity that determines the success or failure of a company’s products and where innovation and new solutions can be developed. Even the most advanced manufacturing facilities cannot produce perfect products if the underlying design is incomplete or flawed. The design phase is where manufacturing costs and potential profits are largely determined. And therefore a defined engineering design process is important when creating new machines and technical systems efficiently and with quality. The procedure must be flexible while being verifiable, plannable, and optimizable. A design methodology is there to support the designer and engineer, provide them with guidelines, and encourage creativity. 6
The process layout differs somewhat between different principles but it typically involves a few key stages: Task clarification, concept generation, preliminary design, and detailed design.
The goal of the task clarification stage is to create a requirements list. In it, the properties and intended objectives are listed in a manner that the main objective and main characteristics can be identified. This list is then used throughout the whole process as a checkpoint to make sure the designs meet the requirements and intended properties. 6
In the concept generation phase, the first concepts are created. This can be done by abstracting the main problems to avoid the influence of fixed or conventional ideas. After that, the functions are determined which again are divided into sub-functions to lessen the complexity of the system. From this, the structure of the machine is created. 6 Another way to approach this is to already divide the main problems into smaller and less complex sub-problems before functions for them are created. 16
In the preliminary design phase, some of the many concepts generated in the concept generation phase are taken forward, for example, based on the evaluation matrix which of the concepts fulfills the best design requirements. After this, in the detailed design phase, the focus is turned to the design of the machine. This step can be defined into the system level design, detail design, and testing and refinement. 16 As a last step, the product is finalized with detailed calculations, fulfillment of requirements, for example, required standards, and preparation of manufacturing drawings.
GAN is a machine learning framework that generates images based on a given dataset. It combines two neural networks: a generator and a discriminator. In training these networks are trained simultaneously, where the role of the generator is to create fake data samples and the discriminator’s role is to try to distinguish between real data from the dataset and the fake samples generated by the generator. 7 StyleGAN was introduced in 2018 and one of its key contributions to the field of AI is the introduction of disentangled properties in the latent space. This means that the different properties of images, for example, the wheels of a car or the shape, are separated. This feature allows for more intuitive and controllable image generation. 13
Later on, Karras et al. published StyleGAN2 in 2020 17 and StyleGAN3 in 2021. 18 New versions each addressed limitations present in the earlier architectures, bringing significant improvements in image quality and architectural robustness. For instance, StyleGAN2 improved upon the original by fixing many image quality issues, and speeding up the training performance. 17 Subsequently, StyleGAN3 further advances the architecture by eliminating the aliasing artifacts, which would make StyleGAN3 more suitable for animation and video generation. 18
In 2020 Karras et al. further developed StyleGAN2 and published a model called StyleGAN2-ADA that was made for a limited dataset. The major advantage of StyleGAN2ADA is that compared to StyleGAN2 and StyleGAN3, it performs well on datasets of only a few 1000 images. In StyleGAN2 and StyleGAN3 when using too little data the training usually leads to overfitting of discriminator. This means that the discriminator starts to predict the training data accurately but not the new data used for testing. 14 In StyleGAN2-ADA this is fixed with adaptive discriminator augmentation or in other words the images given to the discriminator from the original dataset are multiplied and changed in some ways. 14 For example, an image can be mirrored, flipped to the side, or upside down, or the colors can be changed. With the adaptation they made it so that the augmentation is only done to a degree the overfitting requires it.
Proposed methodology
In this research, a novel methodology is proposed to use StyleGAN2-ADA during the conceptual design phase of engineering design. The use of StyleGAN2-ADA makes it possible to use fewer images in the dataset which is crucial because typically engineered products do not have more than a few 1000 images of one product type. StyleGAN2ADA will be used to mix two or possibly more objects using the StyleGAN’s disentangled properties.
The methodology is divided into four main parts: requirements, dataset preparation, training, and sample collection and evaluation. Figure 1 depicts the process for the methodology linked to the conceptual design phase systematic machine design process. The first part is to create the requirements for the project. These can be the amount of final samples and the dataset size. Dataset preparation is divided into dataset collection and combining them into a bigger dataset. At least two different datasets should be collected each from one object. One of the datasets should be made of the company’s or group’s products and other datasets should have objects that include the wanted features, for example, to result in the desired conception or notable brand. After this, the datasets should be combined. Ideally, the combined dataset includes at least a few 1000 images but a minimum of 3000 images to avoid overfitting and other problems that might come up with too small a dataset. However, the datasets do not need to be equally large.
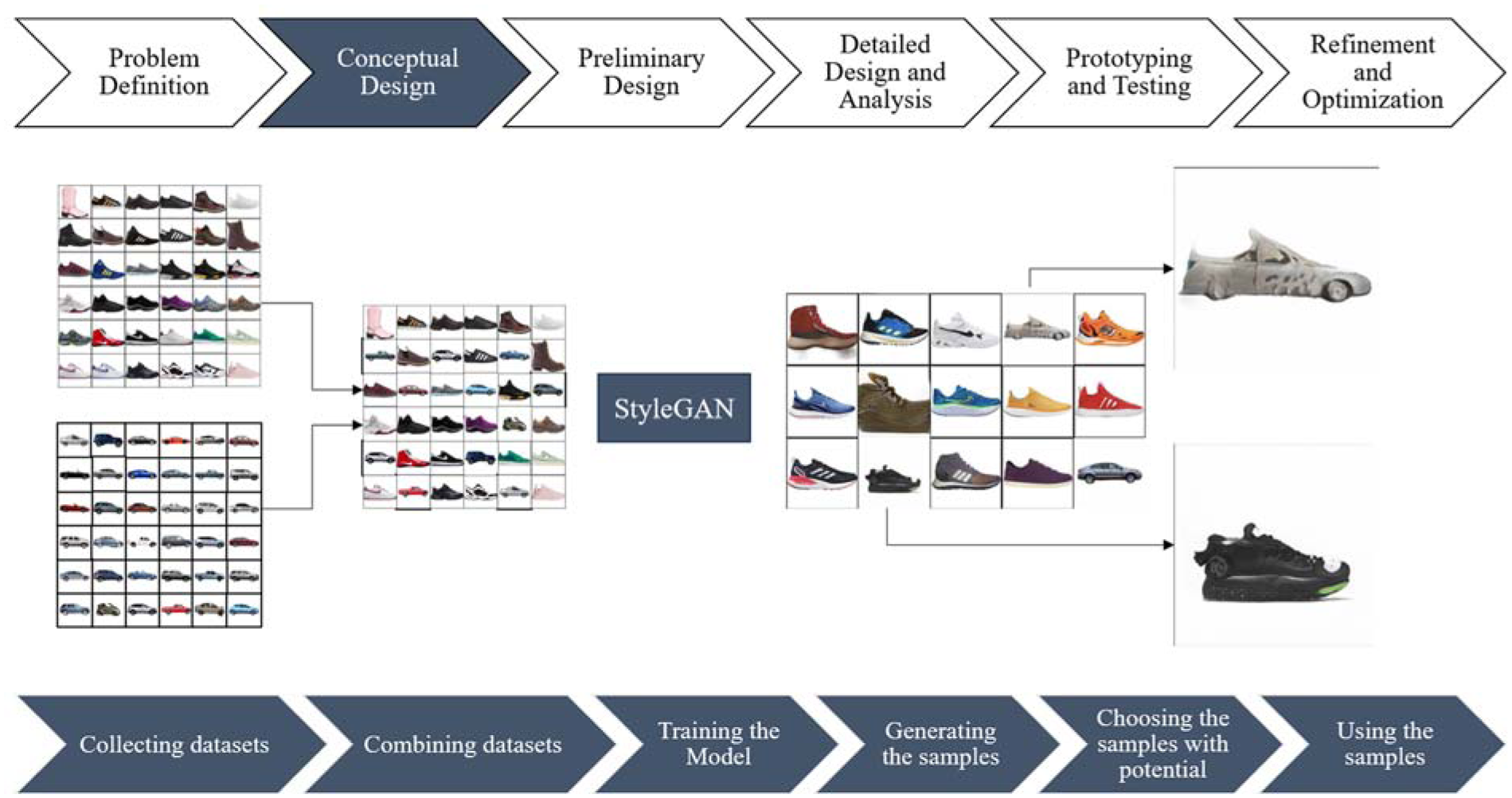
Draft for the process.
The next step is to train the model following the instructions provided on StyleGAN’s official GitHub page. The correct parameters for training depend on the computational resources and quality of images. In this methodology, the quality of images is not the highest priority, but it is good to make sure the computation resources available are used to their fullest potential. In StyleGAN, the raw training speed is measured with s/kimg, which indicates the average speed in seconds the model takes to process 1000 images from the training dataset. Consequently, kimg means 1000 images processed or the amount of training iterations. 18 The StyleGAN GitHub 19 repository mentions that a model trained until 5000 kimgs should be able to generate reasonable images. For the proposed methodology, training should not be taken far, only until 1600 kimgs which would take about 6–10 h with A100 or V100 GPUs. The kimg amount provided for this methodology is directional and the perfect training outcome depends on the configurations used for the training. The amount was obtained in the case study that will be introduced later in Chapter 3. Depending on the training results the configurations might need to be tweaked. If the model seems to start overfitting, decreasing the learning rate might be helpful, and again unstable training might need a bigger batch size or a smaller learning rate.
After the training, samples are generated. From these samples, the ones with the most potential are chosen and new samples are generated. This process is iterated until the desired amount of concept images has been collected. These are then further taken forward in the design process.
This full process can be examined in Figure 2.

Flowchart for the proposed method.
Case study
A case study is conducted to demonstrate and quantify the proposed methodology. The case study contains a car as a base object and the desired features from shoes. The final combined dataset contained mostly shoes with only 17% of cars. The goal was to test the amount of usable generated images in the final trained model and the overall performance of the StyleGAN2-ADA model. Additionally, the model is tested by training it with only one object at a time and then changing the training dataset to another.
Datasets
In the study, three different datasets were used:
Shoe dataset: Consists of 3028 images of different types of shoes.
Car dataset: Includes 639 images of various cars.
Combined dataset: A blend of shoe and car datasets yielding 3667 images, of which about 17% were cars.
The dataset was intentionally imbalanced to reflect a realistic scenario where a company has a large repository of its own product images (shoes) but a smaller set of reference images for the feature source (cars).
The shoe dataset consists of 3028 256 × 256 pixel images of shoes from different shoe brands including Adidas, Crocs, and Reebok. 20 A snapshot of this dataset can be seen in Figure 3 at the top. At the bottom of same figure, the snapshot of the Car dataset can also be seen. The car dataset was created using the Stanford Cars dataset. 21 From the dataset, only the cars, which were photographed from the side, were used. This was done to match the shoe dataset, in which, all the shoes were photographed from the side. However, the authors deem it is not necessary if both of the datasets are mixed from different angles of view. Additionally, datasets were modified by resizing them to 256 × 256, removing the background, flipping the images so that the front of the car pointed to the left, and re-centering the cars.

Images of car and shoe datasets.
Training configurations
Computation resources for this case study were provided by Puhti, a server infrastructure provided by CSC-IT Center for Science, Finland. The final training was carried out by using four Nvidia V100 GPUs simultaneously, indicating the large computational resources required for GAN training.
Training configurations were based on the recommendations provided by StyleGAN3’s official GitHub page. These recommendations are based on their extensive testing of StyleGAN in different resolutions. The specific training configurations were four GPUs, a batch size of 32, a gamma value of 0.2048, a mapping network depth of 2, generator and discriminator learning rates of 0.0025, and a channel base value of 16,384 for the synthesis network. As previously mentioned, the correct parameters depend on the computational resources and quality of images.
Based on this information the training was decided to be executed in two different scenarios:
The first training scenario: Training with the shoe dataset until 5000 kimgs, at when, the dataset is changed to the Car dataset.
The second training scenario: Training with only the combined dataset.
Both of the training scenarios were run until a total of 25,000 kimgs.
Results
In the first training scenario, where the dataset was switched from shoes to cars, the model was able to recognize cars rapidly and the generated images had no resemblance to shoes even in the earliest snapshot of 1000 kimgs. This behavior can be explained with transfer learning, where a model trained on one dataset is used as a starting point for a model training on the new dataset. This method speeds up the learning curve on new datasets. 22
In the second training scenario, from the early training process, the model started to strongly differentiate between shoes and cars, generating low-resolution images of both objects. At 1600 kimgs, only 3% of the generated images were blurred or vague and 2% were mixed between cars and shoes.
At about 4800 kimgs, the model yielded the best mixed results with the least amount of blurred images. Again, about 2% of the images had clear mixing in them, and about 1.5% were blurred. After 5000 kimgs, the model started to distinguish between cars and shoes well enough that there was no satisfactory amount of mixed images. This increasing separation of classes reflects a fundamental capability of StyleGAN2-ADA to learn and represent distinct categories in its latent space. In practice, this means that as training progresses, the generator tends to produce “pure” car or shoe images rather than intermediate hybrids, which improves class fidelity but reduces the frequency of deliberate feature blending. A snapshot from the generated images can be observed in Figure 4.

Snapshot of the images generated by StyleGAN2 in the first training scenario.
The usage of blurred images while analyzing the generated images is crucial when discerning the model’s capability in generating images. The blurred images serve as a valuable metric for the accuracy and performance of the model. Additionally, it is important to underline that the difference between clear, blurred, and mixed images is often subjective and can only be discerned through visual inspection. No clear boundaries therefore can be established (Table 1). Two images categorized as mixed images can be seen in Figure 5 and two images from the blurred category in Figure 6.
The percentages of mixed images and blurred images in the generated image samples in different training levels.


Mixed images generated by StyleGAN2-ADA in the second training scenario.

Blurred images generated by StyleGAN2-ADA in the second training scenario.
With StyleGAN2-ADA it would take ∼6 h to train the model with A100 GPU and about 10 h with V100. To reach 1600 kimgs which was based on the results completely acceptable level of quality. This is calculated based on the configuration instructions of StyleGAN3’s website. If it is wanted to train the model with only 1 GPU and want the resolution of 256 × 256 the s/kimg would be 20.84 with V100 and 12.53 with A100. Additionally, they are giving instructions to add 5% to the time, which comes from the time the model takes to create snapshots. This means that if the desired objective is to reach 1600 kimgs with V100, the required time needed for the training would be calculated with 1600 · 1.05 · 20.84/3600. This would result in the required time in hours. Adding more GPUs reduces the training time by 40%–45% while lowering the resolution decreases it by 45%–50%. 19
Discussion
The results indicate that StyleGAN has some potential when mixing datasets but the ratio or amount of mixed images is too low for it to be properly usable in the design process. Because StyleGAN works on a generative adversarial network where the training is divided into the “police” and “forger,” the mixed images do not fully go through the police because they do not resemble any of the images in the dataset and are like the name suggests a mix between two objects. Another limitation would be GAN’s inability to create completely novel ideas and therefore the images will always have some similarities to one or more of the images used in training.
Still, potential samples chosen in the last phase of the case study, which can be seen in Figure 5, clearly show that the mixing was successful and that images provide two different approaches to how shoe characteristics could be implemented in car design or the other way around. With the proposed methodology in the engineering process, the conceptual design fulfills the brand association while resulting in potential concepts that can be further developed for detailed designs and finally manufacturing. Additionally, different tools like GANSpace 23 could be used to decrease or increase specific feature’s visibility in the final samples.
Summary and conclusions
In this manuscript, a novel method was introduced to approach concept generation in systematic machine design. This method includes generating samples with StyleGAN2ADA which have been trained with company-specific products and a dataset that includes an object with features that the design engineers would like to introduce into their product. This method was then tested with a dataset of shoes and cars to quantify the results and find the optimal training time. The results suggested that StyleGAN2-ADA had potential in the concept phase of systemic machine design while still falling short in some aspects.
In conclusion, GANs can provide a basic concept of how generative methods can be used to boost the ideation process of product development. However, their computational demands and limitations in generating unique designs suggest that more advanced technologies are required to achieve state-of-the-art results. Further research and development are needed to enhance the ideation process in machine design.
In the broader context of machine design, exploring how machine learning could be useful in other parts of the process, such as aiding with automatic design drawings from 3D models, identifying critical measurements, and setting tolerances, could bring significant benefits. These possibilities suggest a promising future for integrating generative methods into machine design workflows.
Footnotes
Acknowledgements
The authors want to express their gratitude to the Symbiotic and Augmented Intelligence Laboratory and its people at Northeastern University for providing the resources and guidance for this research. Special thanks to Dr. Mohsen Moghaddam for his invaluable insights and support throughout the work.
Handling Editor: Aarthy Esakkiappan
Author contributions
Marianne Vanhala: investigation, methodology, roles/writing – original draft. Emil Kurvinen: supervision, writing – review and editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.