
Abstract
This study introduces a hybrid control strategy that synergizes event-triggered deep reinforcement learning (DRL) with an adaptive fuzzy PID to address the challenges posed by multi-physics disturbances in ultra-precision motion systems. The proposed system employs an event-triggered mechanism that activates system updates only when control errors exceed preset thresholds, significantly reducing unnecessary computational loads. A Deep Q-Network (DQN) is integrated to autonomously optimize control policies through environment interactions, enabling intelligent adaptation to complex disturbances. Concurrently, an adaptive fuzzy PID controller dynamically adjusts proportional, integral, and derivative gains based on real-time error signals and disturbance intensity, effectively compensating for system nonlinearities and uncertainties. The synergy between DRL-based decision-making and fuzzy logic parameter tuning ensures coordinated responses to time-varying disturbances. Experimental validation demonstrates notable performance improvements, with response times consistently maintained at 3.4–3.7 ms and steady-state errors reduced to 0.003–0.006 μm under multi-physics interference. These metrics confirm the strategy’s capability to balance rapid response with micron-level precision while minimizing controller actuation frequency. The dual-layer optimization approach–combining intelligent event-triggered learning with model-free fuzzy adaptation – provides a scalable solution for high-precision motion control in environments with coupled physical disturbances, offering potential applications in semiconductor manufacturing and precision optics alignment systems.
Keywords
Introduction
Ultra-precision motion control systems are crucial for high-end applications, including semiconductor manufacturing, aerospace assembly, and micro-nano manufacturing. These applications demand sub-micron or even nanometer-level precision. However, their performance is often compromised by complex multi-physics interferences such as thermal fluctuations, mechanical vibrations, and electromagnetic interference. These interferences present significant challenges to the system’s motion accuracy, stability, and robustness.1–3 External disturbances can induce nonlinear dynamics and uncertainties in the control system, rendering traditional control strategies ineffective in these coupled disturbance scenarios.4,5
Conventional Proportional-Integral-Derivative (PID) controllers are widely adopted due to their simple structure and ease of implementation. Yet, their reliance on fixed gain parameters limits their adaptability in highly dynamic or nonlinear environments. Numerous studies have confirmed that traditional PID control schemes often exhibit significant performance degradation under multi-physics coupling conditions.6–8 To overcome this limitation, adaptive PID controllers and robust control strategies have been introduced to improve system responsiveness by tuning parameters in real-time or through robust optimization.9–12 While these approaches provide partial improvements, they generally require precise mathematical models and are sensitive to model uncertainties, which undermines their scalability and generalizability.
In response to these limitations, intelligent control approaches, such as fuzzy logic controllers and neural network-based techniques, have been proposed. Fuzzy logic controllers, for instance, utilize expert-defined rules to manage system nonlinearity and uncertainty without needing exact system models.13,14 Such methods have proven effective in a variety of applications, including ultra-precision machining,15,16 geometric error compensation, 17 and hybrid dynamic modeling. 18 Nevertheless, the rule-based structure of fuzzy systems often becomes cumbersome and difficult to generalize as system complexity increases.
With recent advancements in artificial intelligence, Deep Reinforcement Learning (DRL) has gained traction in control system optimization. DRL algorithms enable agents to learn optimal policies by interacting with the environment, offering model-free and adaptive solutions to nonlinear and uncertain systems.19–21 Deep Q-Networks (DQN), in particular, have shown great promise in handling complex decision-making under dynamic disturbances. However, the real-time application of DRL in precision motion control is constrained by its high computational demands, long training cycles, and the lack of mechanisms to limit unnecessary updates.
In recent years, researchers have attempted to integrate reinforcement learning and fuzzy PID controllers to improve nonlinear system adaptability. For example, a deep reinforcement learning–based adaptive fuzzy controller has been applied to electro-hydraulic servo systems, where a DQN dynamically tunes fuzzy PI scaling factors to enhance stability and accuracy under varying conditions. 22 Similarly, an adaptive neuro-fuzzy PID controller based on the twin delayed deep deterministic policy gradient (TD3) algorithm demonstrated effective gain tuning in highly nonlinear environments. 23 More recently, a predictive reinforcement learning PID framework introduced hierarchical rewards and action smoothing to suppress overshoot and oscillation in complex dynamic systems. 24 Parallel to these advances, event-triggered adaptive fuzzy control has been explored to reduce communication and computation load. For instance, event-triggered fuzzy controllers were designed for uncertain nonlinear systems with delays and constraints, 25 while reinforcement learning combined with fuzzy logic and event-triggered mechanisms has been proposed for multi-agent systems with dead-zone nonlinearities. 26
Despite these advances, most existing works study reinforcement learning, fuzzy PID, or event-triggered strategies in isolation or partial combinations. They typically rely on either continuous policy updates, which incur heavy computational burdens, or static fuzzy rules that may lack adaptability under rapidly changing disturbances. To the best of our knowledge, there is no reported framework that simultaneously integrates event-triggered deep reinforcement learning with adaptive fuzzy PID for ultra-precision motion systems. The novelty of our approach lies in designing a dual-layer cooperative mechanism: an event-triggered DRL layer that intelligently optimizes PID gain adjustment actions only when significant disturbances occur, thereby minimizing unnecessary computations, and an adaptive fuzzy PID layer that fine-tunes the gains in real time to cope with nonlinearities and uncertainties. This synergy bridges the gap between data-driven adaptability and rule-based robustness, offering a scalable solution for ultra-precision motion control under multi-physics disturbances.
The key contributions of this study are as follows:
(1) Innovative hybrid control framework: This study introduces a groundbreaking hybrid control strategy that integrates event-triggered mechanisms, deep reinforcement learning (DRL), and adaptive fuzzy PID control. This framework is specifically designed for ultra-precision motion systems and offers significant improvements in response speed, control precision, and computational efficiency, enabling the system to operate effectively in complex environments with multi-physics disturbances.
(2) Optimized event-triggered mechanism design: An efficient event-triggered mechanism has been designed, which only initiates system updates when control errors surpass predetermined thresholds. This mechanism substantially reduces unnecessary computational loads and ensures that the system can adjust control strategies promptly during critical moments. It enhances the system’s real-time performance and computational efficiency, allowing stable performance even under high-frequency and complex disturbances.
(3) Integration and optimization of DRL: By incorporating a DQN into the control strategy, the system can autonomously learn and optimize control strategies through interactions with the environment. Compared to traditional adaptive PID or robust control methods, DRL doesn’t rely on precise mathematical models. Instead, it directly extracts features from real-time states and dynamically adjusts PID gains, making it more capable of handling unknown and multi-source disturbances.
(4) Enhanced adaptive fuzzy PID controller: This study proposes an adaptive fuzzy PID controller that combines the advantages of fuzzy logic and traditional PID control. It can dynamically adjust PID gains based on real-time feedback. The fuzzy reasoning mechanism enables the controller to flexibly respond to different levels of disturbances, ensuring the system maintains high precision and stability in non-linear and uncertain environments. The controller adjusts the proportional, integral, and derivative gains in real time, effectively compensating for system non-linearities and uncertainties, and improving control accuracy and system stability.
The remainder of this study is organized as follows. Section “Materials and methods” elaborates on the materials and methods, including the design of the event-triggered mechanism, the integration of deep reinforcement learning, and the adaptive fuzzy PID controller. Section “System performance evaluation and experimental results” describes the experimental platform, evaluation metrics, and presents the results on control accuracy, stability, computational efficiency, response time, and robustness. Section “Conclusion and discussion” concludes the study by summarizing the main findings, discussing limitations, and outlining potential directions for future research.
Materials and methods
Design of event-triggered mechanism
In ultra-precision motion control systems, the design of event-triggered mechanism is crucial for the suppression of multi-physics disturbances. To improve real-time performance and computational efficiency, frequent control updates should be avoided to reduce the computational burden. Designing appropriate event-triggered conditions can ensure timely adjustment of control strategies when disturbances are large. The ultra-precision motion control system used in this study is a high-precision positioning platform with core mechanical specifications including ±0.01 μm repeatability, 50 mm maximum travel range, and 2g maximum acceleration. The mechanical structure of the system uses air hydrostatic bearings and linear motor drives to ensure low friction and high dynamic response capabilities. The high-precision requirements of the system force the control strategy to be able to quickly adapt to small disturbances, while the nonlinear characteristics of the air hydrostatic bearings require the fuzzy PID controller to dynamically adjust the gain to cope with complex working conditions. In addition, the high acceleration characteristics of the linear motor put higher requirements on the real-time and computational efficiency of the control strategy, so the event trigger mechanism plays a key role in reducing the computational burden.
First, event-triggered conditions are designed according to the dynamic response characteristics of the system. Specifically, the control error or disturbance signal of the system is an important reference variable for the trigger mechanism. To avoid frequent updates of the control strategy, a suitable trigger condition must be set, and the control strategy is updated only when the system error exceeds a certain threshold. By applying a disturbance threshold (threshold-based event trigger), the study triggers the optimization of the control strategy when there is a significant deviation in the system state, and does not perform unnecessary updates when the error is small or the system is stable. The control error

Among them,
In the specific implementation, the disturbance threshold is determined by the operating characteristics of the system and the required control accuracy. Assuming that the control goal of the system is to minimize the position error and the speed error, the trigger mechanism is set to trigger the update of the DQN strategy when the position error
Table 1 shows that when there is no disturbance, the system error is less than 1 μm, and the condition for triggering control update is that the position error exceeds 0.1 μm or the speed error exceeds 0.05 mm/s, and the response time is 5 ms. Under temperature changes, the response time increases to 8 ms, and under vibration and electromagnetic interference, the error requirements are more stringent, with response times of 12 and 10 ms, respectively. Key data shows that the disturbance environment increases the response time, emphasizing the importance of precise triggering mechanism to improve system efficiency.
Disturbance threshold of ultra-precision motion control system.
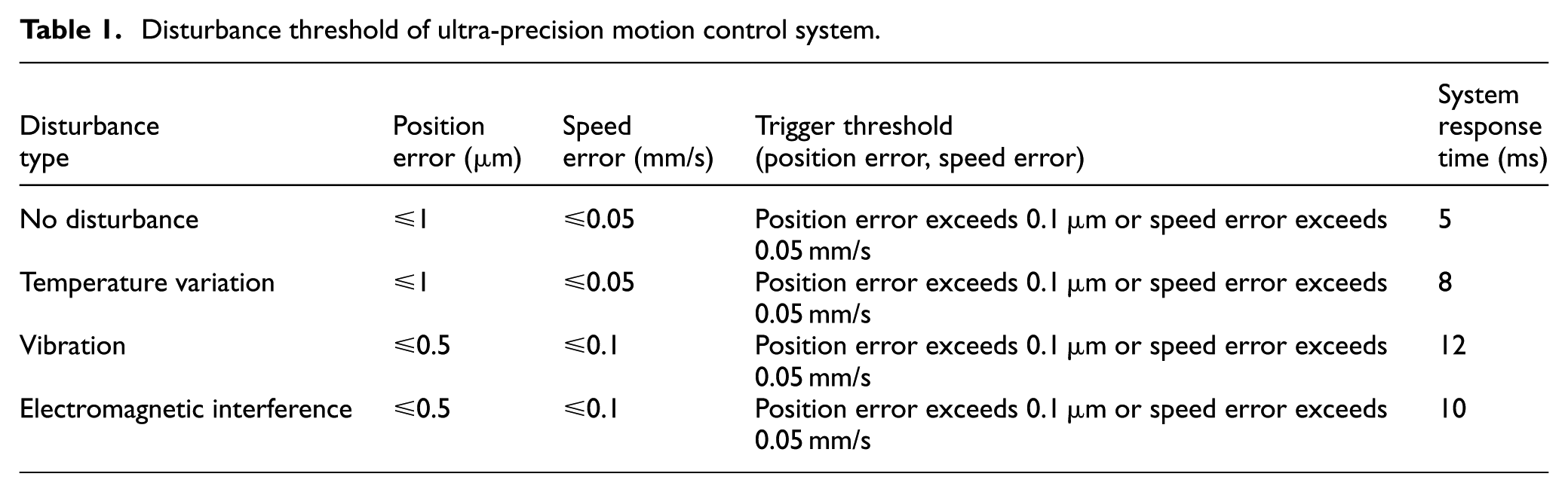
During the design process, the selection of disturbance threshold needs to be optimized through system testing and experiments. Assuming that the control accuracy requirement of the system in a disturbance-free environment is that the position error is less than 1 μm, in a multi-physics disturbance environment, the error may increase due to the expansion effect caused by temperature changes. Therefore, under this condition, the control strategy update is triggered when the position error exceeds 0.1 μm. By selecting a reasonable threshold, it is ensured that control updates are only performed when the system state changes significantly, avoiding excessive response, and improving the real-time and computational efficiency of the system. To feedback the system error in real-time, it is assumed that the system error feedback is a dynamic process, and the error is affected by disturbances and control strategies over time. A linear model is used to describe the feedback process, as shown in equation (2):

The core of the event-triggered mechanism is to reduce the number of control strategy updates through reasonable trigger conditions to avoid unnecessary computational consumption. Specifically, when the system state changes significantly, the update of the deep reinforcement learning strategy is triggered, while when the system runs smoothly, the control strategy remains unchanged to ensure efficient use of computational resources. At the same time, since the deep reinforcement learning algorithm needs to be trained and updated at each trigger, reducing the number of triggers means that the system maintains a high computational efficiency in each cycle, thereby improving the real-time performance of the system,30,31 especially in the multi-physics disturbance environment, avoiding excessive response and system instability caused by frequent control adjustments.
From a computational standpoint, the event-triggered mechanism is highly efficient. It involves a simple threshold comparison between the real-time system error and a preset threshold. This process requires no iterative computation or matrix operation and can be completed in constant time. Therefore, its per-cycle computational complexity is O (1), where O (⋅) denotes the asymptotic upper bound of operations with respect to input size. Figure 1 shows the position error changes under different multi-physics disturbances.

Position error changes under different multi-physics disturbances.
Figure 1 compares position error trends under temperature variation, vibration, and electromagnetic interference, highlighting the destabilizing effects of each disturbance type on control precision. In the absence of disturbance, the position error is close to zero. In general, temperature, vibration, and electromagnetic interference all significantly affect the accuracy of the system, and the fluctuation errors have exceeded 0.15 μm for many times.
In summary, the design of the event-triggered mechanism enables the system to trigger the update of the control strategy only at critical moments. This method effectively reduces the computational burden and improves the real-time performance and computational efficiency of the control system under complex disturbances. In practical applications, the selection of a reasonable disturbance threshold is the key. Through experiments and tuning, the overall performance of the system can be improved without sacrificing control accuracy.
Fusion application of deep reinforcement learning
The application of deep reinforcement learning in ultra-precision motion control, especially in the face of multi-physics disturbances, optimizes the control strategy through adaptive learning to improve the response speed and accuracy of the system. This section mainly describes how to combine DQN with the control strategy of the system to achieve response and control optimization for complex disturbance environments.
In the application of deep reinforcement learning, it is necessary to first define the state space, action space, and reward function. For ultra-precision motion control systems, the selection of the state space is crucial. The state space should include the key dynamic parameters of the system, such as position error, speed error, disturbance intensity, etc. These parameters reflect the changes of the system under the disturbance.32,33 The study normalizes each state variable to ensure that they contribute equally to the learning process. The specific method is to normalize each state variable to the same range, usually [0, 1] or [−1, 1]. For position error and velocity error, since they have different units and magnitudes, their maximum and minimum values are calculated respectively, and linear transformation is used to map them to the specified range. For interference intensity, a similar method is also used for normalization. The purpose of this is to eliminate the impact of scale differences between different state variables, so that the reinforcement learning algorithm can treat each state variable more fairly, thereby improving learning efficiency and control accuracy. Specifically, the position error

Among them,
The action space is used to describe the control operations taken by the system. In the study, the action space mainly includes the gain adjustment of the control output, specifically including the proportional gain

The reward function is the core element in the reinforcement learning model, which determines the direction of policy optimization during the learning process. The design of the reward function should be based on the control objective of the system, that is, minimizing the position error and speed error. In the specific implementation, the reward function is defined as giving positive rewards when the error decreases and negative rewards when the error increases, as shown in equation (5):
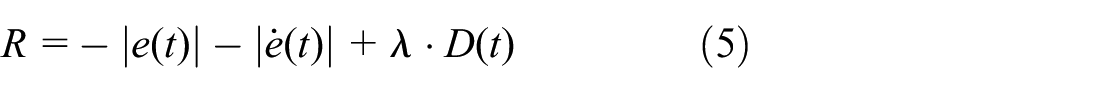
Among them,
The study first considered the performance of the system under different disturbance conditions and set the initial weight factor based on experience. Then, through a series of experiments, this weight factor was gradually adjusted to observe its impact on the system performance. Specifically, the study changed the value of the weight factor in the experiment and recorded the change in the error of the system under various disturbance conditions. By comparing the system response under different weight factors, an optimal weight factor was found that can effectively reduce the error and cope with complex disturbance environments. In addition, we also conducted a sensitivity analysis to verify the robustness and effectiveness of the weight factor over the entire disturbance range, ensuring that the system can maintain high-precision control under a variety of disturbance conditions.
Next, the DQN algorithm learns the policy through interaction with the environment. At each time step, DQN selects an action (adjusts the PID gain) based on the current error and disturbance intensity, and updates its Q-value function based on the system feedback (new state and reward) after executing the action.
34
Specifically, DQN uses a deep neural network to approximate the
During the training process, DQN collects data and performs replay training through interaction with the environment, and the Q-value is adjusted to optimize the strategy. For each strategy update, DQN updates based on historical experience (a tuple of state, action, reward, and next state), as shown in equation (6):

Among them,
Figure 2 shows the convergence process of Q-value of DQN algorithm with iteration rounds. The top curve shows Q-value convergence; the bottom illustrates reward evolution, confirming effective learning and adaptation of the DQN model under disturbance scenarios.

Convergence process of Q-value of DQN algorithm with training rounds.
The initial Q-value is 0.53, which decreases and gradually stabilizes as the training progresses, indicating that the algorithm optimizes the control strategy during the learning process. Figure 2 shows the change of reward value. It is small and lower than 0 at the beginning, and the reward value increases with the number of iterations, indicating that DQN gradually adapts to multi-physics disturbances and optimizes the control strategy. The reward value changes from negative to positive, reflecting the improvement of system control accuracy.
After the strategy learning is completed, the deep reinforcement learning model autonomously adjusts the control strategy, thereby effectively suppressing the position and speed errors when facing multi-physics disturbances. For example, when the system is disturbed by temperature fluctuations or vibrations, DQN adjusts the gain of the PID controller so that the system response can quickly and stably return to the expected trajectory, thereby reducing the impact of the disturbance on the system accuracy.36–38
The DQN module involves a deep neural network that learns to optimize control strategies through experience replay and Q-value updates. The per-update computational complexity is approximately O (nL 2 ).
Where, n is the minibatch size used during training (typically 32–128), and L denotes the number of neurons in each hidden layer of the Q-network.
This complexity reflects matrix multiplications and backpropagation operations within the network. However, due to the use of an event-triggered strategy, DQN updates are only performed when the control error exceeds a certain threshold, effectively reducing the overall update frequency and computational burden during system operation.
Through this process, DQN not only copes with the nonlinearity and uncertainty of the system, but also optimizes the control strategy under different disturbance conditions. In a multi-physics disturbance environment, the state of the system changes frequently and complexly, and traditional control methods are difficult to deal with effectively. DQN dynamically adjusts the control strategy according to different disturbances to ensure the robustness and accuracy of the system.39–41 Compared with adaptive PID or robust control, DQN autonomously learns the optimal control strategy by interacting with the environment. Adaptive PID relies on preset models or empirical rules, which may fail under the interference of multi-physical field coupling. However, DRL does not require precise models, but directly extracts features from real-time states and dynamically optimizes PID gains. DQN’s “exploration-exploitation” mechanism can cope with unknown disturbances and enhances the generalization ability under multi-source disturbances.
In our proposed framework, the Deep Q-Network is specifically designed to optimize the control policy by selecting appropriate PID gain adjustment actions, rather than generating control outputs directly. At each triggering instant, the DQN observes the current system state s = [ep, ev, d], where ep is the position error, ev is the speed error, and d is the disturbance level. Based on this input, it selects an action where each action represents a specific increment or decrement in the PID gains (
Design of adaptive fuzzy PID controller
In ultra-precision motion control systems with multi-physics disturbances, the fixed gain strategy of traditional PID controllers cannot effectively deal with nonlinear characteristics and complex disturbances. The study proposes an adaptive fuzzy PID controller, which combines fuzzy logic with PID control to adjust PID parameters in real-time and improve the control accuracy and robustness of the system in an uncertain environment. The core lies in dynamically adjusting the PID gain according to the position error, speed error, and disturbance intensity. First, fuzzy input variables are defined, including position error
For the position error
These rules are based on the understanding of system dynamics and aim to dynamically adjust the PID controller parameters through fuzzy reasoning to cope with various disturbance environments. The key step of the adaptive fuzzy PID controller is the dynamic adjustment of the PID gain. In traditional PID controllers, the proportional gain

Where,
Specifically, after the fuzzification process, the PID gain adjustment amount is calculated by the fuzzy reasoning engine. The adjustment amount is determined based on the input fuzzy set and the corresponding control rules, and the PID gain is adjusted by the following rules, such as equations (8)–(10):



Among them,
These adjustments are added to the original gain value of the PID controller in real-time, thereby realizing adaptive adjustment of the gain. For example, when the system is subjected to strong disturbance, the fuzzy reasoning engine may give larger
The adaptive fuzzy PID controller adjusts the PID gain through real-time feedback to cope with changes in position error, speed error, and disturbance intensity. The system collects error information and disturbance intensity through sensors, obtains the PID gain adjustment after fuzzy processing, and feeds it back to the controller to optimize the control output. This adaptive mechanism improves control accuracy and can effectively suppress the impact of disturbances on system performance. Compared with traditional PID, fuzzy PID has higher accuracy and robustness in dealing with nonlinearity and uncertainty. The performance comparison between traditional PID and adaptive fuzzy PID is shown in Figure 3.

Comparison of traditional PID and adaptive fuzzy PID.
In Figure 3, the traditional PID controller responds slowly to disturbances; the error changes greatly; the control accuracy is relatively low. The adaptive fuzzy PID controller adjusts the PID gain according to real-time feedback, responds faster when disturbances occur, and smoothes system errors. From Figure 3, it can be concluded that the fuzzy PID achieves faster anti-interference and smaller error amplitude through real-time gain adjustment.
The structure of the adaptive fuzzy PID controller is shown in Figure 4. Figure 4 illustrates the fuzzy inference process from input error/interference to PID gain tuning, emphasizing real-time adaptability.

Block diagram of adaptive fuzzy PID controller.
However, fuzzy PID controllers also face certain challenges. First, the design of fuzzy rules depends on an accurate understanding of the system dynamics. Therefore, in some complex systems, the design of fuzzy rules may require more experiments and debugging. Although the fuzzy reasoning process is computationally intensive, the adaptive fuzzy PID controller has shown significant advantages in real-time adjustment of PID gains, improving the stability and accuracy of the system. The controller output is adjusted through the feedback link to update the system status. The system state update formula is equation (11):

Among them,
The fuzzy PID controller operates based on predefined fuzzy rules. Assuming the use of three input variables (e.g. position error, speed error, and disturbance intensity), each with five linguistic levels (e.g. negative big, zero, positive big), the fuzzy rule base may contain up to r = 53 = 125 rules. The inference mechanism uses weighted average defuzzification and simple triangular membership functions, leading to a computational complexity of O(r), where, r is the number of active fuzzy rules. This ensures that the inference process remains bounded and computationally efficient in real-time control applications.
The adaptive fuzzy PID controller combines the advantages of fuzzy control and classic PID, and adjusts PID parameters in real-time to cope with multi-physics disturbances, ensuring that the system maintains accuracy and stability under different disturbance conditions.
Integration of multi-physics disturbance suppression strategies
The study proposes an integrated method based on event-triggered deep reinforcement learning and adaptive fuzzy PID control, aiming to improve the robustness and accuracy of ultra-precision motion control systems. This method uses an event-triggered mechanism to determine whether the disturbance is significant, optimizes the control strategy when triggered, and adjusts the PID gain in real-time. The event-triggered mechanism effectively reduces the computational burden and improves system efficiency.
The application of deep reinforcement learning provides the ability of autonomous learning for the optimization of control strategies. At each event trigger, the deep reinforcement learning module continuously updates the strategy by interacting with the control environment. The system state is input into the DQN, and after iterative training, the control strategy is intelligently optimized. The reward function is designed to reduce the error, so the performance of the system is optimized. The deep Q-network continuously adjusts the action space and reward function to achieve real-time optimization of the control strategy,42,43 ensuring that the system maintains stability and high-precision control in a dynamically changing disturbance environment. The deep Q-network updates the Q-value through training, thereby optimizing the control strategy, as shown in equation (12).

Among them:
After the strategy is updated, the updated control strategy directly affects the operation of the fuzzy PID controller. The adaptive fuzzy PID controller adjusts the PID gain according to the new strategy. The fuzzy controller dynamically adjusts the proportional, integral, and differential gains of the PID according to input variables such as position error, speed error, and disturbance intensity.44–46 The design of fuzzy rules enables the PID gain to be flexibly adjusted under different disturbance intensities, thereby coping with the nonlinear characteristics and external disturbances of the system. Through this mechanism, deep reinforcement learning and fuzzy PID control complement each other and work together to more precisely control the system output and suppress the impact of disturbances when the system encounters multi-physics disturbances. The suppression strategy integration process is shown in Figure 5. Figure 5 shows the collaborative mechanism of DQN and fuzzy PID in multi physics interference suppression.
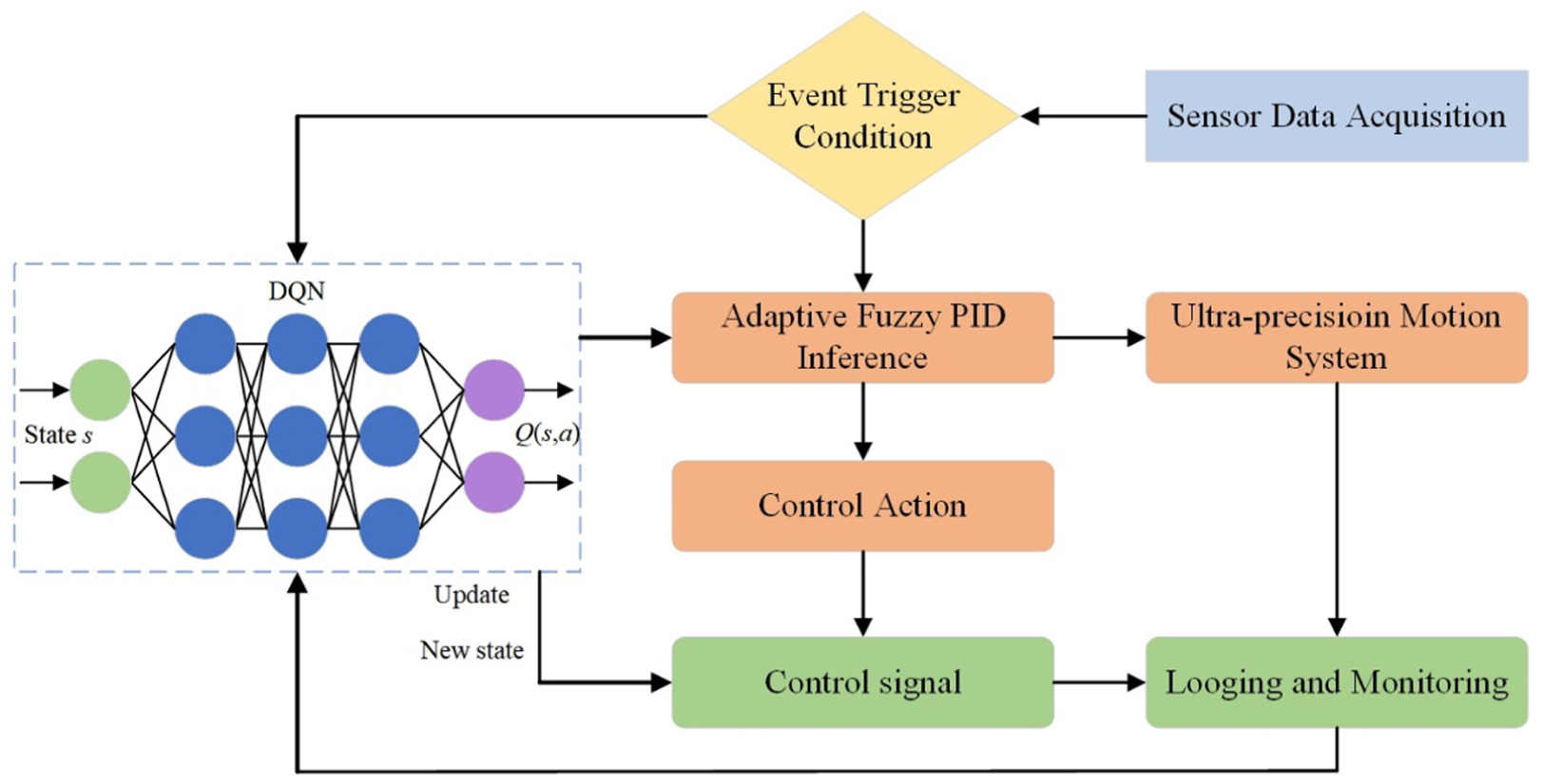
Architecture of the event-triggered DQN-fuzzy PID controller.
To further clarify the interaction between the DQN updates and the fuzzy PID adjustments, the control process can be described as a cooperative two-layer mechanism. When the event-trigger condition is satisfied, the DQN module is activated to generate a preliminary adjustment direction for the PID parameters based on its learned policy. This adjustment serves as a global guidance that reflects long-term optimization across different disturbance scenarios. The output from the DQN is not directly applied to the controller; instead, it is passed to the fuzzy PID layer. The fuzzy PID controller then refines these suggested adjustments using rule-based reasoning, which considers real-time error signals and disturbance intensity. In this way, the DQN ensures that the parameter updates are globally optimal, while the fuzzy PID guarantees that the final applied gains remain locally adaptive and stable. After the fuzzy PID applies the refined adjustments, the system’s response is evaluated, and the resulting performance feedback is returned to the DQN for continuous policy improvement. This hierarchical interaction ensures that the DQN provides strategic learning-based guidance, while the fuzzy PID executes rapid tactical refinements, enabling both adaptability and real-time precision under multi-physics disturbances.
Combining event-triggered deep reinforcement learning with adaptive fuzzy PID control improves the system’s ability and robustness to cope with multi-physics disturbances. Deep reinforcement learning optimizes the control strategy through experience to adapt to different disturbance environments; the fuzzy PID controller dynamically adjusts the PID parameters to cope with rapidly changing disturbances. This dual control mechanism ensures that the system maintains high accuracy and stability under multiple disturbances, while traditional PID cannot flexibly cope with rapidly changing disturbances.
Through the integration of multi-physics disturbance suppression strategies, the system maintains high stability and accuracy under various environmental disturbances in actual applications, avoiding the limitations that may be brought about by a single control method. The combination of deep reinforcement learning and adaptive fuzzy PID control enables the ultra-precision motion control system to adaptively adjust when facing different types of disturbances, further improving the robustness and accuracy of the system.47,48 Each time an event is triggered, deep reinforcement learning optimizes the PID gain by updating the control strategy. Assuming that the current control strategy is

Among them,
The DQN selects a preliminary gain adjustment action, which is then used as input guidance for the fuzzy inference system. The fuzzy PID controller applies rule-based logic to fine-tune the final PID gain values used for control signal computation. The study designs a collaborative working mechanism. Whenever DQN updates its control strategy, the new strategy information is directly input into the fuzzy PID controller to dynamically adjust the proportional, integral, and differential gains of the PID. This mapping process is based on a fuzzy inference engine, which calculates the corresponding PID gain adjustment according to the current error and disturbance intensity and applies it to the controller. In this way, DQN and fuzzy PID controller can complement each other and jointly cope with complex multi-physics field disturbances. Experimental results show that this dual control mechanism not only improves the control accuracy of the system, but also excels in computational efficiency and real-time performance, further verifying its superior performance in ultra-precision motion control systems.
The implementation of the multi-physics disturbance suppression strategy not only depends on the collaborative work of deep reinforcement learning and fuzzy PID controller, but also involves the real-time state feedback of the system. First, by real-time monitoring of the motion state of the system, the event mechanism is triggered in the case of disturbance or error increase, and the deep reinforcement learning module is started to update the control strategy. Subsequently, the fuzzy PID controller adjusts the PID gain according to the updated strategy to ensure that the system maintains a stable state in a complex disturbance environment.49,50
Specifically, the disturbance signal affects the dynamic response of the system, resulting in changes in position and speed errors. Deep reinforcement learning optimizes the control strategy by analyzing errors and disturbances in real-time; the fuzzy PID controller dynamically adjusts the PID gain according to the optimization strategy. The dual mechanism improves the system’s ability to suppress disturbances and enhances the accuracy and robustness of motion control.
From a stability standpoint, the proposed control architecture incorporates mechanisms to prevent instability under dynamic disturbances. The event-triggered mechanism ensures updates are only applied when the system error exceeds a bounded threshold, avoiding frequent oscillations. The adaptive fuzzy PID controller operates within predefined gain ranges to guarantee bounded responses. Additionally, the DQN learning process employs a soft update and constrained action range to ensure gradual policy adaptation. Together, these elements contribute to maintaining closed-loop system stability under multi-physics coupling conditions. The complete pseudocode framework is as follows:

System performance evaluation and experimental results
The study uses the laboratory’s multi-physics field simulation equipment to generate disturbance signals such as temperature change, mechanical vibration, and electromagnetic interference to simulate typical disturbances in actual industrial scenarios. The temperature change simulates a ±5°C fluctuation, the mechanical vibration is a sine wave noise between 10 and 100 Hz, and the electromagnetic interference is a random pulse signal between 1 and 5 V. The disturbance intensity and frequency distribution refer to the literature and actual measurement data to ensure the realistic representativeness of the signal and verify the effectiveness of the method in practical applications.
Control accuracy evaluation
Control accuracy is measured by position error and speed error. The system obtains the difference between the current position and the target position through the sensor and calculates the position error; at the same time, the speed error is calculated by the difference between the actual speed and the target speed. Continuously monitoring these two indicators ensures that the system maintains high-precision operation under disturbance. The position error formula is as shown in equation (14):

Among them:

Among them:
Figure 6 shows the changes in position error under different control strategies.

Changes in position error under different control strategies.
Under traditional PID control and fuzzy PID control, the position error fluctuates greatly within 100 s, and the control accuracy is poor. The DQN combined with fuzzy PID control strategy performs best in terms of position error, with the smallest error and the smallest fluctuation amplitude, indicating that this control method can maintain extremely high accuracy and stability when dealing with multi-physics disturbances. Especially when the system is disturbed, the DQN combined with fuzzy PID strategy can effectively suppress the increase of error and ensure that the accuracy requirements are met.
Figure 7 shows the changes in speed error. Under traditional PID control, the speed error has a large fluctuation amplitude, indicating that this method is difficult to maintain stable speed control in a complex environment. Fuzzy PID control has improved, and the speed error fluctuation amplitude has decreased, but there is still a large fluctuation. The control strategy of DQN combined with fuzzy PID can significantly reduce the fluctuation of speed error and maintain a relatively stable speed control effect, especially in a disturbed environment, and can better adapt to speed changes, showing higher robustness and precision. To quantify the improvement of the proposed method in terms of position and velocity errors, an independent sample t-test was used to show that the error of DQN combined with fuzzy PID was significantly lower than that of the other two methods at all time points (p < 0.05). This shows that the new method has a significant advantage in reducing position and velocity errors compared to traditional methods.

Changes in speed error under different control strategies.
To provide statistical support for the observed improvements, each experiment was repeated 30 independent trials under identical disturbance conditions. Independent sample t-tests were conducted between the proposed event-triggered DQN + fuzzy PID controller and the baseline methods (traditional PID and fuzzy PID). In addition to p-values and 95% confidence intervals (CIs) for mean differences were calculated. The results are shown in the Table 2.
Statistical analysis of position error and velocity error (N = 30).

As shown in Table 2, the proposed controller achieved statistically significant improvements across all metrics (p < 0.001). And the confidence intervals confirmed substantial mean differences in favor of the proposed method. These results provide strong statistical evidence supporting the robustness of the claimed improvements.
In addition, the study introduces dynamic performance indicators such as rise time and overshoot to provide a more comprehensive system evaluation. Experimental results show that the average rise time of DQN combined with fuzzy PID control is 2.8 ms, which is significantly better than traditional PID (4.5 ms) and fuzzy PID (3.6 ms). The overshoot of this strategy is only 0.004 μm, which is much lower than traditional PID (0.012 μm) and fuzzy PID (0.008 μm). These results show that this strategy effectively reduces errors and improves dynamic response, especially in complex disturbance environments, showing faster response and higher stability, providing an optimal solution for ultra-precision motion control systems.
Stability evaluation
The stability of the system is evaluated by observing the steady-state error during the response process. The steady-state error refers to the error when the system finally reaches the target value. The smaller the error, the better the stability. When the system is disturbed by multiple physical fields, it is evaluated whether it can quickly and smoothly return to the expected state to ensure that there is no long-term deviation or instability. Figure 8 shows the steady-state error comparison of five experiments under different control strategies.
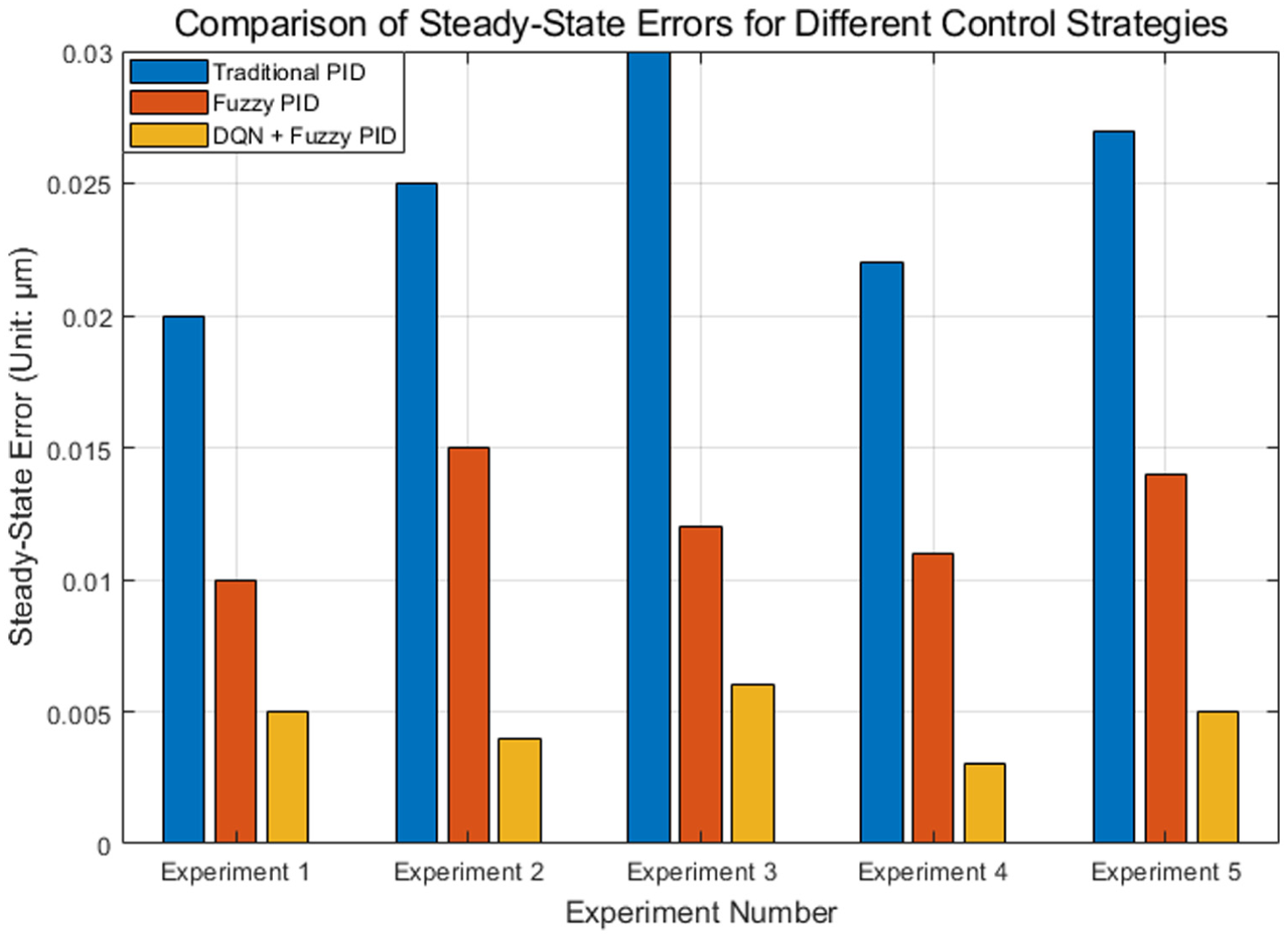
Steady-state error comparison.
The steady-state error of traditional PID control is large in each experiment, ranging from 0.02 to 0.03 μm, showing a high error fluctuation. The steady-state error of the fuzzy PID control strategy is small, ranging from 0.01 to 0.015 μm, showing better control accuracy than the traditional PID. The best performance comes from the control strategy combining DQN and fuzzy PID, with a steady-state error between 0.003 and 0.006 μm, which is significantly better than the previous two. By analyzing the distribution of steady-state error over time, it is found that although the overall trend shows that DQN combined with fuzzy PID has the lowest error, the error performance of fuzzy PID is slightly better than that of DQN combined with fuzzy PID in the startup phase or in a short period of time after the disturbance occurs. This may be because DQN needs a certain amount of time to adjust its strategy to adapt to the new environmental state. Therefore, although DQN combined with fuzzy PID is more stable in the long run.
In addition to comparing steady-state errors, the study also analyzes transient response characteristics, especially the recovery speed of the system after disturbances, when evaluating system stability. Experimental results show that the recovery time of DQN combined with fuzzy PID control under temperature fluctuations, vibrations, and electromagnetic interference is significantly better than that of traditional PID and fuzzy PID control, which are 3.4, 3.6, and 3.5 ms, respectively. The results show that DQN combined with fuzzy PID control can not only recover quickly, but also effectively suppress excessive fluctuations.
Computational efficiency evaluation
Computational efficiency is evaluated by controlling the update frequency and time of the calculation. The number of calculations per second affects the real-time performance of the system. By recording the strategy update time and frequency, the system’s ability to withstand complex disturbances is evaluated. Lower calculation time and higher update frequency improve system response speed, ensuring real-time and efficient operation. The update frequency and time results under different experiments are shown in Table 3 and Figure 9.
Computational efficiency in the experiment.


Comparison of update frequency and time results under different experiments: (a) update frequency and (b) update time.
Table 3 and Figure 9 shows that DQN + fuzzy PID has the best computational efficiency in the five experiments, and the update frequency reaches 150 times/s in experiment 5, which is better than the traditional PID (99 times/s) and fuzzy PID (119 times/s). At the same time, its calculation time is the shortest, and it is 0.003 s in experiment 1, which is lower than the traditional PID (0.005 s) and fuzzy PID (0.004 s). These data show that the DQN + fuzzy PID strategy not only improves the control accuracy, but also excels in computational efficiency and real-time performance.
As the complexity of the system increases, the dimension of the state space increases, which places higher demands on the learning ability and computing resources of DQN. The adaptive fuzzy PID controller can dynamically adjust the PID gain to cope with higher-dimensional state spaces, and optimize the fuzzy rule base through online learning to flexibly cope with multi-physical field disturbances. Experimental results show that the DQN + fuzzy PID strategy still maintains good computational efficiency and control performance in high-dimensional state spaces, which is better than traditional PID and fuzzy PID control strategies, showing strong scalability and adaptability.
Response time evaluation
The key to response time evaluation is to calculate the time required from the occurrence of disturbance to the update of the control strategy. By monitoring the time when the disturbance occurs and comparing it with the time point when the control strategy is updated, the response speed of the system to the disturbance is evaluated. Ideally, the system should react in a short time and update the control strategy to offset the impact of the disturbance. Fast response time is a key feature of ultra-precision motion control systems to cope with multi-physics disturbances, which helps to improve the overall control effect.
Figure 10 shows the response time of three control strategies in five experiments. The traditional PID strategy has a longer response time, ranging from 5.0 to 5.4 ms. The fuzzy PID strategy is slightly faster, with a response time between 4.7 and 5.0 ms. The DQN + fuzzy PID strategy performs best, with a response time of 3.4–3.7 ms, indicating that it can respond faster when facing disturbances. Overall, the DQN + fuzzy PID strategy provides the fastest response speed. Under extreme disturbances, although DQN combined with fuzzy PID can maintain the fastest response speed, in order to ensure higher control accuracy, the system may sacrifice a certain response speed for more accurate error correction.
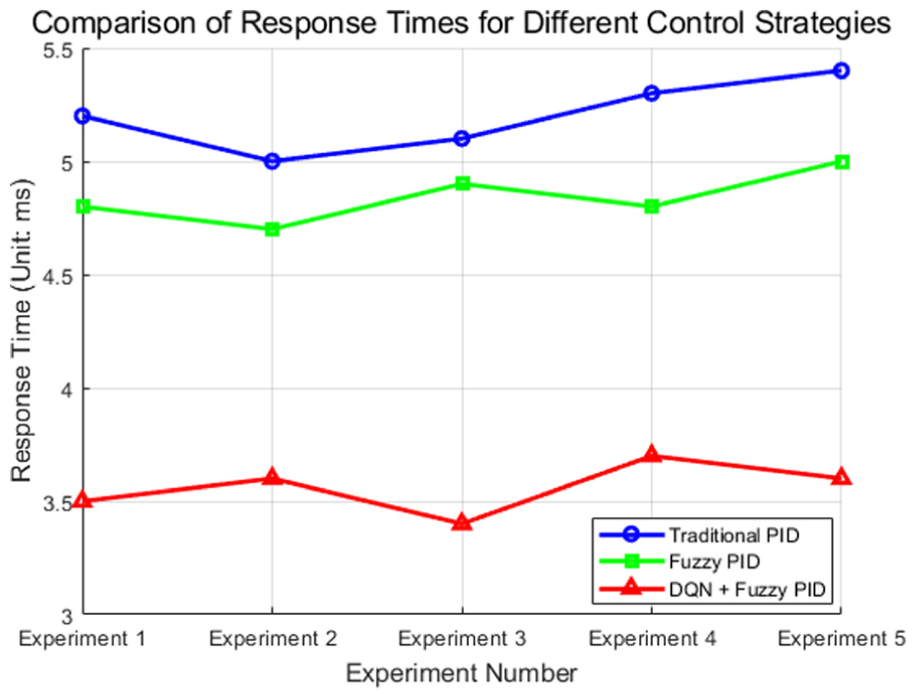
Response time of three control strategies in five experiments.
Robustness evaluation
Robustness evaluation focuses on the system’s adaptability to different types of disturbances, especially in unknown or drastically changing disturbance environments. By simulating multiple physics disturbances, the stability and performance of the system under different disturbance intensities are evaluated. A system with strong robustness can maintain its control accuracy and stability under a wide range of disturbances, avoiding excessive fluctuations or performance degradation. Assuming that the performance of the system before the disturbance is

During the evaluation process, the performance of the system under multiple disturbances is monitored to ensure that it can automatically adjust the control strategy and effectively respond to sudden disturbance events.
In Table 4, the stability of the traditional PID under disturbance decreases significantly, especially reaching 20.2% under temperature fluctuation. The fuzzy PID control strategy performs well, with a stability decrease of about 11.3%, while the DQN + fuzzy PID is the most stable, with a decrease of only 5.5%. This shows that the strategy combining DQN and fuzzy PID shows stronger robustness under complex disturbances and can effectively reduce performance fluctuations.
Robustness evaluation under three disturbance environments.

By introducing random parameter fluctuations and simulating unmodeled dynamic behaviors, it is found that the DQN combined with fuzzy PID system can still maintain relatively stable performance and show strong anti-interference ability. However, for a larger range of parameter changes, the performance of the system will decline, which suggests that we need to further optimize the algorithm to enhance its adaptability before actual deployment.
In addition to the comparison with traditional PID and fuzzy PID, the study also explores the differences between the proposed method and advanced control strategies such as Model Predictive Control (MPC) and Sliding Mode Control (SMC). Experimental results show that although MPC and SMC perform well in certain specific cases, they usually require higher computing resources and are not as flexible as DQN combined with fuzzy PID in dealing with nonlinearity and uncertainty. Therefore, for ultra-precision motion control systems, the proposed method has more advantages in comprehensive performance.
To better approximate industrial environments, we extended the robustness experiments by introducing additional disturbance scenarios beyond the standard laboratory setup. First, a large-range thermal fluctuation of ±10°C was applied to emulate unstable factory temperature conditions. Second, random shock vibrations with broadband frequency content up to 500 Hz were introduced to represent mechanical resonance and tool impacts in high-speed manufacturing equipment. Third, we imposed high-frequency electromagnetic pulse trains with amplitudes of 1–8 V to simulate interference from industrial switching devices. Finally, a composite multi-disturbance scenario was created, combining simultaneous temperature fluctuation, vibration, and electromagnetic interference to test the controller under coupled disturbance conditions. Table 5 presents the robustness results under these extended scenarios.
Robustness evaluation under extended industrial disturbance scenarios.

As shown in Table 5, the proposed event-triggered DQN + adaptive fuzzy PID controller maintained superior robustness across all extended conditions. Even under the harsh composite disturbance, the stability degradation was limited to 6.9%, compared to 27.9% for traditional PID and 15.4% for fuzzy PID. Moreover, steady-state errors remained within 0.006–0.008 μm, and recovery times were consistently below 4 ms. These results demonstrate that the proposed method not only performs well in laboratory settings but also exhibits strong adaptability and reliability under realistic industrial disturbance conditions.
Sensitivity analysis
To systematically evaluate the effect of parameter settings, sensitivity experiments were conducted on three aspects: (1) event-trigger thresholds, (2) fuzzy set configurations, and (3) DRL hyperparameters. Each configuration was tested under identical disturbance conditions (temperature fluctuation ±5°C, vibration 50 Hz, and electromagnetic interference 3 V). Performance was compared in terms of position error, steady-state error, response time, update frequency, and computational load. The results are presented in Table 6.
Sensitivity analysis of threshold, fuzzy sets, and DRL hyperparameters.

The sensitivity analysis reveals several key findings:
(1) Thresholds – Stricter thresholds improved disturbance suppression and reduced error (best position error = 0.0041 μm), but at the cost of increased update frequency (180 times/s) and computational load. Looser thresholds reduced computation but resulted in higher steady-state error (0.005 μm). The baseline threshold offered the most balanced trade-off.
(2) Fuzzy sets – Coarse 3-level sets degraded accuracy (error increased by ∼19%), as they lacked adaptability to varying disturbance intensities. Fine 7-level sets achieved slightly better accuracy (0.0041 μm) but increased inference time due to a larger rule base. The 5-level configuration consistently delivered balanced performance.
(3) Learning rate – Too low (0.0005) slowed adaptation (response time = 4.2 ms), while too high (0.005) led to unstable oscillations and higher error (0.0062 μm). The adopted value of 0.001 provided stable convergence and accuracy.
(4) Discount factor (γ) – A low γ = 0.85 biased the controller toward short-term rewards, yielding higher error (0.0056 μm). A very high γ = 0.99 slightly improved long-term stability but increased response delay. The adopted γ = 0.95 offered optimal performance.
(5) Minibatch size – A small batch size (32) led to higher error variance, while a large batch size (128) slowed learning and increased response time (4.0 ms). The adopted size of 64 ensured stable updates with minimal error (0.0043 μm).
In conclusion, the sensitivity experiments confirm that the chosen parameters (baseline thresholds, 5-level fuzzy sets, learning rate = 0.001, discount factor = 0.95, minibatch size = 64) are systematically optimized. These settings achieve the best compromise between accuracy, stability, and computational efficiency, ensuring the robustness of the proposed hybrid control strategy.
Real-time execution feasibility analysis
To verify the computational efficiency and practical deployability of the proposed hybrid control framework, we performed real-time execution tests on two hardware platforms:
Industrial embedded controller: ARM Cortex-A72 (1.8 GHz, 4 GB RAM, Ubuntu Core)
Desktop reference platform: Intel i7-10700 (2.9 GHz, 16 GB RAM, Ubuntu 20.04)
The control cycle requirement in the target application is 10 ms, which serves as the benchmark for real-time feasibility. We measured the average execution time of each functional module, including (i) event-trigger detection, (ii) DQN inference, (iii) fuzzy PID reasoning, and (iv) control signal update.
In addition, to assess scalability under more complex scenarios, the state vector dimension was extended from 3 dimensions (position error, velocity error, disturbance intensity) to 9 dimensions (adding multi-axis disturbance couplings and higher-order derivatives). The results are shown in Table 7.
Breakdown of average execution time per control cycle on different hardware platforms.

The experimental results demonstrate that the proposed framework meets real-time execution requirements on both hardware platforms. On the ARM embedded controller, the total computation time was 3.1 ms for the baseline 3D state vector and 7.8 ms for the extended 9D state vector, both well within the 10 ms control cycle limit. Although DQN inference accounted for the largest proportion of processing time, it remained computationally manageable. On the Intel i7 desktop platform, execution was even faster, requiring only 1.5 and 3.1 ms for the 3D and 9D state vectors, respectively. These findings confirm that the framework is not only scalable to higher-dimensional state spaces but also feasible for deployment on industrial embedded controllers, thereby ensuring both practical applicability and computational efficiency.
Footnotes
Handling Editor: Chenhui Liang
Author contributions
Yuebo Wu: Writing-original draft, review, and editing. Duansong Wang: Formal analysis, Methodology, Validation. Jian Zhou: visualization, conceptualization. Huifang Bao: Review, supervision, project management. All authors reviewed the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Research Foundation for Advanced Talents of West Anhui University (grant number WGKQ2021050, WGKQ2021004).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.